







TabTransformer:使用上下文嵌入的表格数据建模
1.代码
链接: code
// An highlighted block
var foo = 'bar';
2.论文
链接: paper
2.3puss3
如果要是我来写这篇文章,我会如何组织这个结构?
问题是怎么提出的、如果是我来做这个事情的话该怎么办,我应该可以用什么方法来实现、
实验我应该这么做,能不能比他做得更好、我怎么做没有往前走的部分。
--脑补出它整个流程是什么样子的,似乎是自己在做实验,写论文一样。
第三遍之后,关上文章也能会回忆出很多细节的部分和整体流程,之后在基于它做研究时(可以详详细细的复述一遍)。
2.3.1 存在什么问题
与深度学习模型相比,基于树的模型有一些局限性
(a)它们不适合于从流数据进行连续训练,并且在存在多模态沿着表格数据的情况下不允许图像/文本编码器的有效端到端学习。
(b)它们的基本形式不适合最先进的半监督学习方法这是由于基本的决策树学习器不能对其预测产生可靠的概率估计(Tanha,索梅伦和Afsarmanesh 2017)。
(c)处理缺失和噪声数据特征的最先进的深度学习方法(Devlin et al. 2019)不适用于它们。此外,基于树的模型的鲁棒性还没有在文献中研究很多.
MLP通常学习参数嵌入来编码分类数据特征。但由于它们的浅架构和上下文无关的嵌入,它们具有以下局限性:
(a)模型和学习的嵌入都不可解释;
(b)它对缺失和噪声数据不鲁棒(第3.2节);
(c)对于半监督学习,它们没有达到竞争性性能(第3.4节)。
许多现有的表格数据深度学习模型都是针对监督学习场景设计的,但很少有针对半监督学习(SSL)的。
不幸的是,在计算机视觉(Alfredlodimos et al. 2018; Kendall and Gal 2017)和NLP(Vaswani et al. 2017; Devlin et al. 2019)中开发的最先进的SSL模型无法轻松扩展到表格域。
2.3.2 有什么方法解决问题
// A code block
var foo = 'bar';
2.1puss1
2.1.1标题title
TabTransformer:使用上下文嵌入的表格数据建模-2020
2.1.2摘要abs
我们提出了TabTransformer,这是一种用于监督和半监督学习的新型深度表格数据建模架构。TabTransformer是建立在基于自我注意力的Transformers之上的。Transformer层将分类特征的嵌入转换为强大的上下文嵌入,以实现更高的预测准确性。通过对15个公开数据集的广泛实验,我们表明TabTransformer在平均AUC上比最先进的表格数据深度学习方法至少高出1.0%,并且与基于树的集成模型的性能相匹配。此外,我们证明了从TabTransformer学习的上下文嵌入对缺失和噪声数据特征都具有很强的鲁棒性,并提供了更好的可解释性。最后,对于半监督设置,我们开发了一个无监督的预训练过程来学习数据驱动的上下文嵌入,与最先进的方法相比,平均AUC提升了2.1%。
2.1.3结论conclusion
我们提出了TabTransformer,这是一种用于监督和半监督学习的新型深度表格数据建模架构。我们提供了大量的经验证据,表明TabTransformer在表格数据方面的性能显著优于MLP和最近的深度网络,同时与基于树的集成模型(GBDT)的性能相匹配。我们提供并广泛研究了一个两阶段的预训练,然后对表格数据进行微调,击败了半监督学习方法的最新性能。TabTransformer显示了对噪声和丢失数据的鲁棒性以及上下文嵌入的可解释性的有希望的结果。在今后的工作中,详细调查这些问题将是有益的。
2.1.4研究背景intro
表格数据是许多现实应用中最常见的数据类型,例如推荐系统(Cheng et al. 2016),在线广告(Song et al. 2019)和投资组合优化(Ban,El Karoui和Lim 2018)。许多机器学习竞赛,如Kaggle和KDD Cup,主要是为了解决表格领域的问题。表格数据建模的最新技术是基于树的集成方法,例如梯度提升决策树(GBDT)(Chen和Guestrin 2016; Prokhorenkova等人2018)。这与对图像和文本数据建模形成鲜明对比,所有现有的竞争模型都基于深度学习(Sandler et al. 2018; Devlin et al. 2019)。基于树的集成模型可以达到有竞争力的预测精度,训练速度快,易于解释。这些好处使它们在机器学习从业者中非常受欢迎。然而,与深度学习模型相比,基于树的模型有一些局限性。
(a)它们不适合于从流数据进行连续训练,并且在存在多模态沿着表格数据的情况下不允许图像/文本编码器的有效端到端学习。
(b)它们的基本形式不适合最先进的半监督学习方法这是由于基本的决策树学习器不能对其预测产生可靠的概率估计(Tanha,索梅伦和Afsarmanesh 2017)。
( c)处理缺失和噪声数据特征的最先进的深度学习方法(Devlin et al. 2019)不适用于它们。此外,基于树的模型的鲁棒性还没有在文献中研究很多
使用梯度下降训练并因此允许图像/文本编码器的端到端学习的经典和流行的模型是多层感知器(MLP)。
MLP通常学习参数嵌入来编码分类数据特征。但由于它们的浅架构和上下文无关的嵌入,它们具有以下局限性:
(a)模型和学习的嵌入都不可解释;
(b)它对缺失和噪声数据不鲁棒(第3.2节);
(c)对于半监督学习,它们没有达到竞争性性能(第3.4节)。
最重要的是,MLP在大多数数据集上与基于树的模型(如GBDT)的性能不匹配(Arik和Pfister 2019)。为了弥合MLP和GBDT之间的性能差距,研究人员提出了各种深度学习模型(Song et al. 2019; Cheng et al. 2016; Arik and Pfister 2019; Guo et al. 2018)。尽管这些深度学习模型达到了相当的预测精度,但它们并没有解决GBDT和MLP的所有局限性。此外,它们的比较是在少数数据集的有限设置中进行的。特别是,在第3.3节中,我们展示了在大量数据集上与标准GBDT相比,GBDT的表现明显优于这些最新模型。在本文中,我们提出TabTransformer来解决MLP和现有深度学习模型的局限性,同时弥合MLP和GBDT之间的性能差距。我们通过对15个公开数据集的广泛实验,建立了TabTransformer的性能增益。
TabTransformer基于Transformers(Vaswani et al. 2017)构建,用于学习分类特征的有效上下文嵌入。与表域不同,嵌入在自然语言处理中的应用已经得到了广泛的研究。在自然语言处理中,使用嵌入在密集的低维空间中对单词进行编码是普遍的。从Word2Vec(Rong 2014)开始,将上下文无关的单词嵌入到BERT(Devlin et al. 2019),随着上下文词符嵌入的出现,嵌入在自然语言处理中得到了广泛的研究和应用。与上下文无关的嵌入相比,基于上下文的嵌入模型(Mikolov et al. 2011; Huang,Xu,and Yu 2015; Devlin et al. 2019)取得了巨大的成功。特别是,基于自我注意力的变形金刚(Vaswani et al. 2017)已经成为NLP模型的标准组件,以实现最先进的性能。变形金刚生成的上下文嵌入的有效性和可解释性也得到了很好的研究(Coenen et al. 2019; Brunner et al. 2019)。受Transformer在自然语言处理中的成功应用的启发,我们将其应用于表格领域。特别是,TabTransformer在参数嵌入上应用了一系列基于多头注意力的Transformer层,将它们转换为上下文嵌入,弥合了基线MLP和GBDT模型之间的性能差距。我们调查的有效性和可解释性所产生的上下文嵌入的变形金刚。我们发现,高度相关的特征(包括同一列和交叉列中的特征对)会导致嵌入向量在欧几里得距离上非常接近,而在基线MLP模型中学习的上下文无关嵌入中不存在这种模式。我们还研究了TabTransformer对随机缺失和噪声数据的鲁棒性。与MLP相比,上下文嵌入使它们非常强大。
此外,许多现有的表格数据深度学习模型都是针对监督学习场景设计的,但很少有针对半监督学习(SSL)的。不幸的是,在计算机视觉(Alfredlodimos et al. 2018; Kendall and Gal 2017)和NLP(Vaswani et al. 2017; Devlin et al. 2019)中开发的最先进的SSL模型无法轻松扩展到表格域。受这些挑战的激励,我们利用语言模型的预训练方法,并提出了一种半监督学习方法,用于使用未标记数据预训练TabTransformer模型的Transformer。我们提出的半监督学习方法的主要优点之一是两个独立的训练阶段:对未标记数据进行昂贵的预训练阶段 和 对标记数据进行轻量级微调阶段.这与许多最先进的半监督方法(Chapelle,Scholkopf和Zien 2009;奥利弗等人2018; Stretcu等人2019)不同,后者需要一个单一的训练任务,包括标记和未标记的数据。分离的训练过程有利于模型需要预训练一次但针对多个目标变量进行多次微调的场景。事实上,这种情况在工业环境中非常常见,因为公司往往拥有一个大型数据集(例如描述客户/产品),并且有兴趣对这些数据进行多项分析。
总而言之,我们提供了以下贡献:
1.我们提出TabTransformer,一个架构,提供和利用上下文嵌入的分类功能。我们提供了大量的经验证据,表明TabTransformer上级基线MLP和最近的深度网络,同时匹配基于树的集成模型(GBDT)的性能。
2.我们调查所产生的上下文嵌入,并突出其可解释性,对比现有技术实现的参数上下文无关嵌入。
3.我们证明了TabTransformer对噪声和丢失数据的鲁棒性。
4.我们提供并广泛研究了一个两阶段的预训练,然后对表格数据进行微调,击败了半监督学习方法的最先进性能。
2.2puss2
(**关注的地方**:第二遍阅读的时候,最重要是搞明白那些重要的图和表,
都要知道他每一个字在干什么事情作者提出的方法和别人提出的方法是怎么进行对比的?之间差距有多大?
比如:方法里面的流程图、算法图长什么样子,实验里的每张xy轴代表什么、每个点的意思,
作者提出的方法和别人的方法怎么对比、之间差距有多大。)
(**达到的效果**:第二遍阅读完之后,你就对整个论文的各个部分,都有一个大概的了解,
中间可以把作者引用的别人的相关文献圈出来,比如作者是在某某某的方法上进行了改进,做了哪些改进之类的。
这里需要注意的是,如果你发现作者引用的这些重要文献是你没有读过的,
那么你需要把它圈出来,作为你的稍后阅读清单(圈出相关的文献,那些方法是xxx提出的,再xxx的方法上改进的))
(**对后续的影响**:这一遍阅读之后,你需要再继续思考一下这篇论文的质量以及和自己研究方向的契合程度,
决定一下自己要不要进行第三遍的完完全全彻底的精读(解决了什么问题,结果怎么样,用了什么方法。决定要不要继续往下精读puss3。))
2.2.1方法method
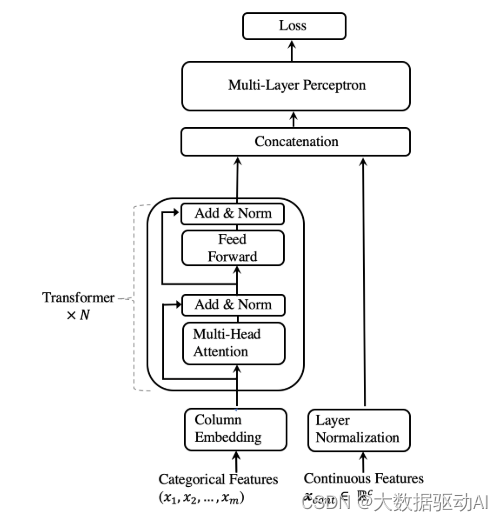
图1:TabTransformer的架构。
TabTransformer架构包括列嵌入层、 N个Transformer层的堆栈 和 多层感知器。每个Transformer层(Vaswani et al. 2017)由一个多头自注意层和一个位置前馈层组成。TabTransformer的架构如图1所示。
令(x,y)表示特征-目标对,其中x表示{xcat,xcont}。
xcat表示所有的分类特征,
xcont ∈ Rc表示所有的c个连续特征。
设xcat ∈ {x1,x2,· · ·,xm},其中每个Xi是分类特征,其中i ∈ {1,· · ·,m}.
我们使用列嵌入将每个Xi分类特征嵌入到维度d的参数嵌入中,这在下面详细解释。
设eφi(Xi)∈ Rd(i ∈ {1,· · ·,m})是Xi特征的嵌入,
Eφ(xcat)= {eφ1(x1),· · ·,eφm(xm)}是所有分类特征的嵌入集.
接下来,这些参数嵌入Eφ(xcat)被输入到第一Transformer层。第一Transformer层被输入到第二层Transformer,依此类推。当从顶层Transformer输出时,通过连续聚合来自其他嵌入的上下文,每个参数嵌入被转换为上下文嵌入。
我们将Transformer层的序列表示为函数 fθ 。函数 fθ 对参数嵌入{eφ1(x1),· · ·,eφm(xm)}进行运算,并返回相应的上下文嵌入{h1,· · ·,hm},其中hi ∈ Rd,i ∈ {1,· · ·,m}。
上下文嵌入{h1,· · ·,hm}与连续特征xm沿着连接以形成维度为(d ×m+ c)的向量。该向量被输入到MLP(由g表示)以预测目标y。
假设H是分类任务的交叉熵,回归任务的均方误差。我们最小化以下损失函数L(x,y),以通过一阶梯度方法在端到端学习中学习所有TabTransformer参数。
TabTransformer参数包括用于列嵌入的φ、用于Transformer层的θ和用于顶部MLP层的θ。
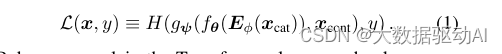
下面,我们将解释Transformer层和列嵌入。
Transformer。一个Transformer(Vaswani et al. 2017)由一个多头自注意层和一个位置前馈层组成,在每一层之后进行元素加法和层归一化。自注意层包括三个参数矩阵Key、Query和Value。每个输入嵌入都被投影到这些矩阵上,以生成它们的键、查询和值向量。形式上,设K ∈ Rm×k、Q ∈ Rm×k和V ∈ Rm×v分别是包括所有嵌入的键、查询和值向量的矩阵,m是输入到Transformer的嵌入的数量,k和v分别是键和值向量的维数。每个输入嵌入都通过Attention头来关注所有其他嵌入,Attention头的计算如下:
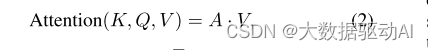
其中,A = softmax((QKT)/softmax)。对于每个嵌入,注意矩阵A ∈ Rm×m计算它对其他嵌入的关注程度,从而将嵌入转换为上下文嵌入。维度v的注意力头的输出通过全连接层被投射回维度d的嵌入,该全连接层又通过两个位置前馈层。第一层将嵌入扩展到其大小的四倍,第二层将其投影回原始大小。
列嵌入
对于每个分类特征(列)i,我们有一个嵌入查找表eφi(.),i ∈ {1,2,…,m}。
对于具有di类的第i个特征,嵌入表eφi(.)具有(di + 1)个嵌入,其中附加嵌入对应于缺失值。
编码值Xi = j ∈ [0,1,2,…,di]是eφi(j)= [cφi,wφij ],其中cφi ∈ R,wφij ∈ Rd−。cφi的维数l是超参数。
唯一标识符cφi ∈ R将列i中的类与其他列中的类区分开来。
唯一标识符的使用是新的,并且是专门为表格数据设计的。相反,在语言建模中,嵌入是按元素添加的,并对句子中的单词进行位置编码。由于在表格数据中,特征没有顺序,因此我们不使用位置编码。不同包埋策略的消融研究见附录A。这些策略包括不同的选择,d和元素方式添加唯一标识符和特征值特定的嵌入,而不是连接它们。
预训练嵌入
上面解释的上下文嵌入是在使用标记示例的端到端监督训练中学习的。对于一个场景,当有几个标记的例子和大量的未标记的例子,我们引入了一个预训练过程,使用未标记的数据来训练Transformer层。接下来是使用标记数据对预训练的Transformer层沿着顶部MLP层进行微调。对于微调,我们使用等式(1)中定义的监督损失。
我们探索了两种不同类型的预训练过程,即掩蔽语言建模(MLM)(Devlin et al. 2019)和替换标记检测(RTD)(Clark et al. 2020)。
给定输入xcat = {x1,x2,…,xm}时,MLM随机选择索引1到m中的k%特征,并将其掩蔽为缺失。通过最小化多类分类器的交叉熵损失来训练Transformer层沿着列嵌入,该多类分类器试图根据从顶层Transformer输出的上下文嵌入来预测被掩蔽特征的原始特征。
RTD不是屏蔽特征,而是用该特征的随机值替换原始特征。在这里,对于试图预测特征是否已被替换的二元分类器,损失被最小化。(Clark等人,2020)中提出的RTD程序使用辅助发生器对应替换的特征子集进行采样。他们使用辅助编码器网络作为生成器的原因是,语言数据中有数万个标记,并且均匀随机的标记太容易检测。相反,
(a)每个分类特征中的类的数量通常是有限的;
(b)为每列定义不同的二元分类器,而不是共享的二元分类器,因为每列都有自己的嵌入查找表。
我们将这两种预训练方法命名为TabTransformer-MLM和TabTransformer-RTD。在我们的实验中,替换值k被设置为30。关于k的消融研究见附录A。
2.2.2实验exp
数据
我们评估了来自UCI存储库(Dua和Graff 2017),AutoML挑战(Guyon等人2019)和Kaggle(Kaggle,Inc.)的15个公开可用的二进制分类数据集的TabTransformer和基线模型。2017年)用于监督和半监督学习。每个数据集分为五个交叉验证部分。每个数据的训练/验证/测试比例,比例为65/15/20%。跨数据集的分类特征的数量范围从2到136。在半监督实验中,对于每个数据集和分割,训练数据中的前p个观测值被标记为标记数据,其余训练数据被标记为未标记集。p的值被选择为50、200和500,对应于3种不同的场景。在监督实验中,每个训练数据集都被完全标记。所有数据集的汇总统计量见附录C中的表8和表9。
Setup.
对于TabTransformer,隐藏(嵌入)维度,层数和注意力头的数量分别固定为32,6和8。MLP层大小被设置为{4 × l,2 × l},其中l是其输入的大小。对于超参数优化(HPO),每个模型对于每个交叉验证分割都有20个HPO轮。对于评估指标,我们使用曲线下面积(AUC)(布拉德利1997)。注意,预训练仅适用于半监督场景。当整个数据都被标记时,我们没有发现使用它有多大好处。它的好处是显而易见的,当有大量的未标记的例子和一些标记的例子。因为在这种情况下,预训练提供了一种数据的表示,而这种表示不能仅仅基于标记的示例来学习。
实验部分的组织如下。在第3.1节中,我们首先通过比较我们的模型与没有变压器的模型(相当于MLP模型)来证明基于注意力的Transformer的有效性。在第3.2节中,我们展示了TabTransformer对噪声和缺失数据的鲁棒性。最后,在第3.3节中对监督学习的各种方法进行了广泛的评估,在第3.4节中对半监督学习进行了评估。
3.1变压器层的有效性
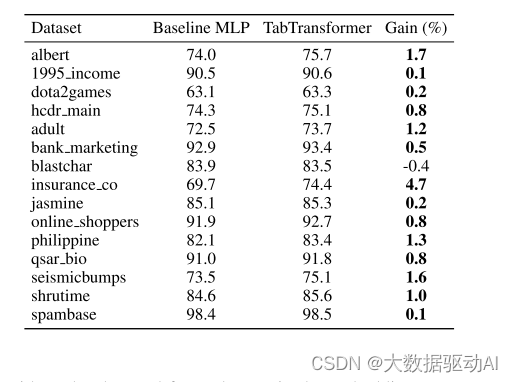
表1:TabTransfomers与基线MLP之间的比较。评价指标是AUC(百分比)。
首先,TabTransformers和基线MLP之间的比较进行监督学习的情况下。我们从架构中删除了Transformer层fθ,修复了其余的组件,并将其与原始的Tab Transformer进行比较。没有基于注意力的Transformer层的模型相当于一个MLP。对于两个模型,分类特征的嵌入d的维度被设置为32。15个数据集的比较结果见表1。具有Transformer层的TabTransformer在15个数据集中的14个数据集上优于基线MLP,AUC平均增加1.0%。
接下来,我们从Transformer的不同层获取上下文嵌入,并计算t-SNE图(Maaten和欣顿,2008),以可视化它们在函数空间中的相似性。更准确地说,对于每个数据集,我们获取其测试数据,将其分类特征传递到经过训练的TabTransformer中,并从Transformer的某个层提取所有上下文嵌入(跨所有列)。然后使用t-SNE算法将每个嵌入减少到t-SNE图中的2D点。图2(左)显示了用于数据集库营销的Transformer最后一层的嵌入的2D可视化。图中的每个标记表示某个类的测试数据点上的2D点的平均值。我们可以看到语义相似的类很接近,在嵌入空间中形成簇。每个聚类由一组标签注释。例如,我们发现所有基于客户端的功能职业、教育程度、婚姻状况等(颜色标记)保持在中心位置,而非基于客户的特征(灰色标记),如月份(最后一次联系月份),日(一周最后联系日)位于中心区域之外;在底部集群中,拥有住房贷款的嵌入与违约的嵌入保持接近;在左边的集群中,作为学生的嵌入,婚姻状况为单身,没有住房贷款,教育水平为大专;在右边的集群中,教育水平与职业类型密切相关(Torpey和Watson 2014)。在图2中,中间和右边的图分别是通过Transformer之前的嵌入和来自MLP的上下文无关嵌入的t-SNE图。对于传递到Transformer之前的嵌入,它开始区分非基于客户端的特征(灰色标记)和基于客户端的特征(颜色标记)。对于来自MLP的嵌入,我们没有观察到这种模式,并且许多语义不相似的分类特征被分组在一起,如图中的注释所示。
除了证明Transformer层的有效性外,我们还在测试数据上从训练的TabTransformer的每个Transformer层中获取所有上下文嵌入,使用每个层的嵌入沿着连续变量作为特征,并分别拟合具有目标y的线性模型。由于所有的实验数据集都是二进制分类,线性模型是逻辑回归。这种评估的动机是将简单线性模型的成功定义为学习嵌入的质量度量。对于每个数据集和每个层,计算测试数据上AUC中CV分数的平均值。评价是在整个测试数据上进行的,数据点数量超过9000。
图3显示了数据集BankMarketing、Adult和QSAR Bio的结果。对于每一行,每个预测得分都由对应数据集的端到端训练TabTransformer的“最佳得分”进行归一化。我们也探索平均和最大池化策略(霍华德and Ruder 2018),而不是将嵌入的串联作为线性模型的特征。向上的模式清楚地表明,随着Transformer层的发展,嵌入变得更加有效。相比之下,来自MLP的嵌入(单个黑色标记)在线性模型中表现更差。此外,每行中的最后一个值接近1.0,表明以最后一层嵌入为特征的线性模型可以达到可靠的准确性,这证实了我们的假设。
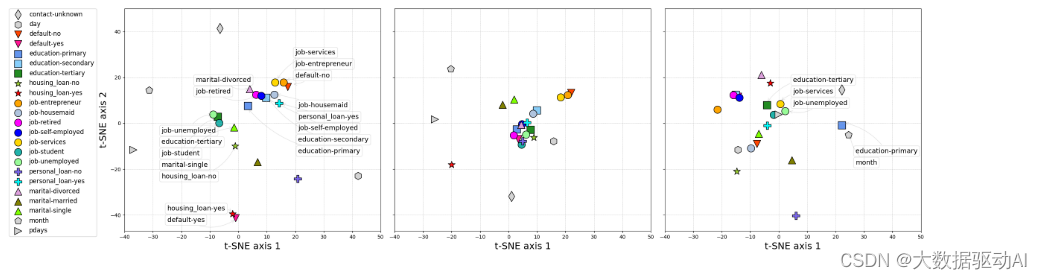
图2:数据集BankMarketing上分类特征的学习嵌入的t-SNE图。左图:TabTransformer-基于注意力的Transformer最后一层生成的嵌入。中心:TabTransformer-在传递到基于注意力的Transformer之前的嵌入。右图:从MLP学习的嵌入。
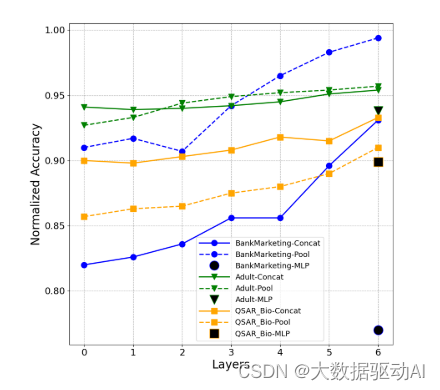
图3:使用从TabTransformer中不同的Transformer层提取的特征作为嵌入的线性模型的预测。第0层对应于传入Transformer层之前的嵌入。对于每个数据集,每个预测得分都由来自端到端训练的TabTransformer的“最佳得分”标准化。
3.2 TabTransformer的鲁棒性
我们进一步证明了TabTransformer对噪声数据和缺失值数据的鲁棒性,与基线MLP相比。我们只在分类特征上考虑这两种情况,以具体证明来自Transformer层的上下文嵌入的鲁棒性。
噪声数据。
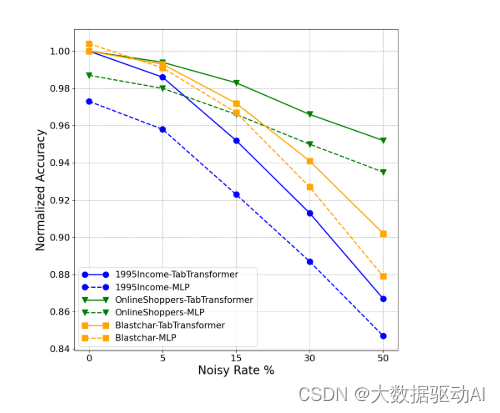
在测试示例中,我们首先通过用相应列(特征)中随机生成的值替换一定数量的值来污染数据。接下来,将噪声数据传递到经过训练的TabTransformer中以计算预测AUC得分。3个不同数据集的结果见图4。随着噪声率的增加,TabTransformer在预测精度方面表现得更好,因此比MLP更鲁棒。特别注意Blastchar数据集,其中性能几乎与无噪声相同,但随着噪声的增加,TabTransformer的性能与基线相比明显提高。我们推测,鲁棒性来自嵌入的上下文属性。尽管一个特征是有噪声的,但它从正确的特征中提取信息,允许一定量的校正。
有缺失值的数据。
类似地,在测试数据上,我们人为地选择了一些缺失的值,并将缺失值的数据发送给经过训练的TabTransformer来计算预测得分。有两种方法可以处理缺失值的嵌入:(1)使用相应列中所有类的平均学习嵌入;(2)缺失值类的嵌入,第2节中提到的每列的额外嵌入。由于基准数据集不包含足够的缺失值来有效地训练选项(2)中的嵌入,因此我们使用(1)中的平均嵌入进行插补。相同3个数据集的结果见图5。我们可以看到噪声数据情况下的相同模式,即TabTransformer在处理缺失值时表现出比MLP更好的稳定性。
3.3监督学习在这里
我们将TabTransformer的性能与以下四类方法进行比较:(a)逻辑回归和GBDT(b)MLP和稀疏MLP(Morcos等人,2019)(c)Arik和Pfister的TabNet模型(2019)(d)和Alemi等人的变分信息瓶颈模型(VIB)(2017)。结果总结见表2。TabTransformer、MLP和GBDT是表现最好的3个。TabTransformer的性能优于基准MLP,平均增益为1.0%,与GBDT相当。此外,TabTransformer明显优于TabNet和VIB,后者是最近的表格数据深度网络。有关实验和模型详情,请参见附录B。模型在每个单独数据集上的性能如下:
回归和GBDT(b)MLP和稀疏MLP(Morcos等人,2019)(c)Arik和Pfister的TabNet模型(2019)(d)和Alemi等人的变分信息瓶颈模型(VIB)(2017)。结果总结见表2。TabTransformer、MLP和GBDT是表现最好的3个。TabTransformer的性能优于基准MLP,平均增益为1.0%,与GBDT相当。此外,TabTransformer明显优于TabNet和VIB,后者是最近的表格数据深度网络。有关实验和模型详情,请参见附录B。模型在每个单独数据集上的性能如下:
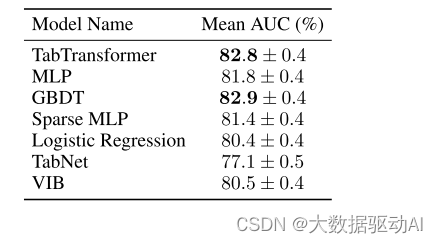
表2:监督学习中的模型性能。评价指标为每个模型15个数据集的AUC评分的平均值±标准差。数字越大,结果越好。前两个数字是粗体。
3.4半监督学习
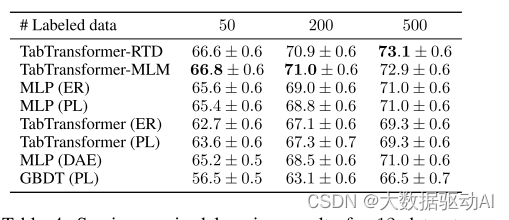
表3:8个数据集的半监督学习结果,每个数据集具有超过30K个数据点,对于不同数量的标记数据点。评价指标为平均AUC(百分比)。数字越大,结果越好。
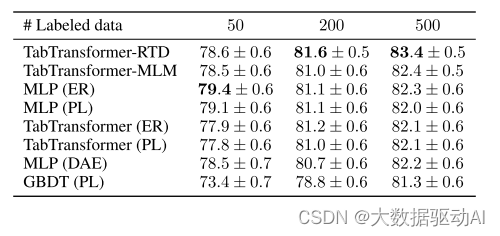
表4:12个数据集的半监督学习结果,每个数据集的数据点少于30K,不同数量的标记数据点。评价指标为平均AUC(百分比)。数字越大,结果越好。
最后,我们在半监督学习场景下评估TabTransformer,其中很少有标记的训练示例可用,未标记的样品。具体来说,我们将预训练和微调的TabTransformer-RTD/MLM与以下半监督模型进行比较:
(a)熵正则化(ER)(Grandvalet和Bengio 2006)结合MLP和TabTransformer
(b)伪标记(PL)(Lee 2013)结合MLP、TabTransformer和GBDT(Jain 2017)
(c)MLP(DAE):为表格数据的深度模型设计的无监督预训练方法:交换噪声去噪自动编码器(Jahrer 2018)。
预训练模型TabTransformer-MLM、TabTransformer-RTD和MLP(DAE)首先在整个未标记的训练数据上进行预训练,然后在标记数据上进行微调。半监督学习方法,伪标记和熵正则化,在标记和未标记的训练数据的混合上训练。为了更好地呈现结果,我们将15个数据集分成两个子集。第一组包括具有超过30 K数据点的6个数据集,第二组包括剩余的9个数据集。
结果见表3和表4。当未标记数据的数量很大时,表3显示我们的TabTransformer-RTD和TabTransformer-MLM显著优于所有其他竞争对手。特别是,TabTransformer-RTD/MLM在50、200和500个标记数据点的情况下,平均AUC分别比所有其他竞争产品提高至少1.2%、2.0%和2.1%。基于transformer的半监督学习方法TabTransformer(ER)和TabTransformer(PL)以及基于树的半监督学习方法GBDT(PL)的性能比所有模型的平均值差。当未标记数据的数量变少时,如表4所示,abTransformer-RTD仍然优于其大多数竞争对手,但略有改善。
此外,我们观察到,当未标记数据的数量很小时,如表4所示,TabTransformerRTD比TabTransformer-MLM表现更好,这要归功于其比MLM(多类分类)更容易的预训练任务(二进制分类)。这与ELECTRA论文的发现一致(Clark等人,2020)。在表4中,只有50个标记的数据点,MLP(ER)和MLP(PL)击败了我们的TabTransformer-RTD/MLM。这可能是因为我们的微调程序有改善的空间。特别是,我们的方法允许获得信息嵌入,但不允许分类器本身的权重使用未标记的数据进行训练。由于ER和PL不会出现这个问题,因此它们在极小的标记集上具有优势。然而,我们指出,这仅仅意味着这些方法是互补的,并提到可能的后续行动可以将所有方法中最好的方法联合收割机结合起来。
表3和表4的评估结果都表明,我们的TabTransformer-RTD和Transformers-MLM模型在从未标记数据中提取有用信息以帮助监督训练方面很有前途,并且在未标记数据的大小很大时特别有用。关于每个单个数据集的模型性能,请参见附录C中的表10、11、12、13、14、15。
相关工作
监督学习。
多年来,标准MLP一直应用于表格数据(De Br 'ebisson等人,2015年)。对于专门为表格数据设计的深度模型,有深度版本的因子分解机(Guo et al. 2018; Xiao et al. 2017),
基于transformers的方法(Song et al. 2019; Li et al. 2020; Sun et al. 2019)和
基于决策树的算法的深度版本(Ke et al. 2019; Yang,Morillo和Hospedales 2018)。
特别是,(Song et al. 2019)在嵌入上应用一层多头注意力来学习高阶特征。高阶特征被连接并输入到全连接层以进行最终预测。(Li等人2020)使用自我注意力层并跟踪注意力分数以获得特征重要性分数。(Sun 2019)将因子分解机模型与Transformer机制相结合。
这三篇论文都集中在推荐系统上,很难与本文进行清晰的比较。其他模型已经围绕表格数据的所谓属性(如低阶和稀疏特征交互)设计。其中包括Deep & Cross Networks(Wang et al. 2017),Wide & Deep Networks(Cheng et al. 2016),TabNets(Arik and Pfister 2019)和AdaNet(科尔特斯et al. 2016)。
半监督学习
(Izmailov et al. 2019)给予了一种基于密度估计的半监督方法,并在表格数据上评估了他们的方法。
**伪标记(Lee 2013)是一种简单、有效和流行的基线方法。**伪标签使用当前网络通过选择最有信心的类来推断未标记示例的伪标签。这些伪标签在交叉熵损失中被视为人类提供的标签。
标签传播(Zhu and Ghahramani 2002),(Iscen et al. 2019)是一种类似的方法,其中节点的标签根据它们的接近度传播到所有节点,并被训练模型使用,就好像它们是真正的标签一样。
半监督学习的另一个标准方法是熵正则化(Grandvalet and Bengio 2005; Sajjadi,Javanmarti,and Tasdizen 2016)。它将未标记示例的平均每样本熵添加到标记示例的原始损失函数。
半监督学习的另一种经典方法是协同训练(Nigam and Ghani 2000)。
然而,最近的方法-熵正则化和伪标记-通常更好,更受欢迎。一般来说,半监督学习方法的简要回顾可以在(奥利弗等人2019; Chappelle,Schöolkopf和Zien 2010)中找到。

















 2157
2157

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









