






一、ReLU函数
函数公式为:
函数图像为:
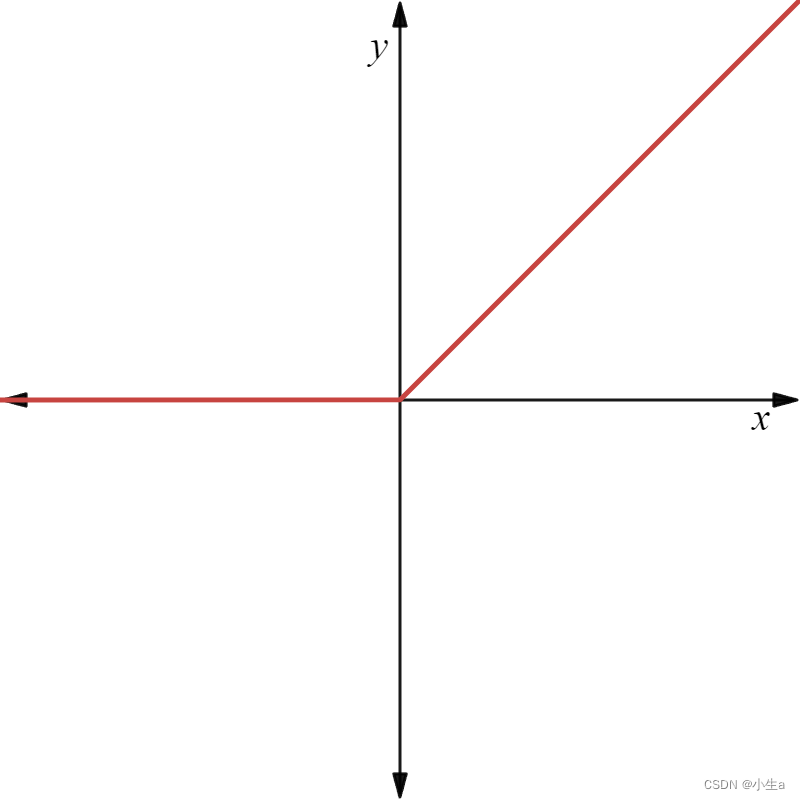
优点:
- 稀疏激活性:当输入值为0时,ReLU的输出为0,因此激活神经元的条件是输入值大于0,这导致了网络的稀疏激活性。这种稀疏性可以帮助减少梯度消失问题,从而促进了网络的训练速度和稳定性。
-
计算简单:ReLU函数的计算非常简单,只需比较输入值与0的大小,然后选择较大的值作为输出。这种简单性使得ReLU在实际应用中具有较高的计算效率,特别是在大规模深度学习模型中。
-
线性增长区域:ReLU在输入大于0时呈线性关系,这意味着在这个区域内,梯度保持不变。这有助于缓解梯度消失问题,同时使得网络更容易优化。
-
抑制梯度爆炸:ReLU函数在输入值为负时输出为0,这意味着它有助于抑制梯度爆炸的问题,因为它将大于某个阈值的梯度截断为0。
缺点:
-
神经元死亡问题:当输入值为负时,ReLU的梯度为0,这意味着对应的权重将不会得到更新,导致了神经元的“死亡”。在训练过程中,如果某个神经元的权重更新到一个非常负的值,那么该神经元将永远不会被激活,这样它将不会再学习到任何信息。
-
输出不是zero-centered:ReLU函数的输出在负半轴上始终为0,这导致了输出不是zero-centered的问题,可能会影响网络的收敛性和学习效果。
-
不适用于负值输入:对于负值输入,ReLU的输出始终为0,这可能会导致部分信息的丢失,尤其是在一些任务中,负值的信息也是有意义的。
-
不可导性问题:虽然ReLU在大部分输入范围内是可导的,但在0点处并不可导,这可能会导致在使用基于梯度的优化算法时出现一些数值问题。
二、Sigmoid函数
函数公式为:
函数图像为:
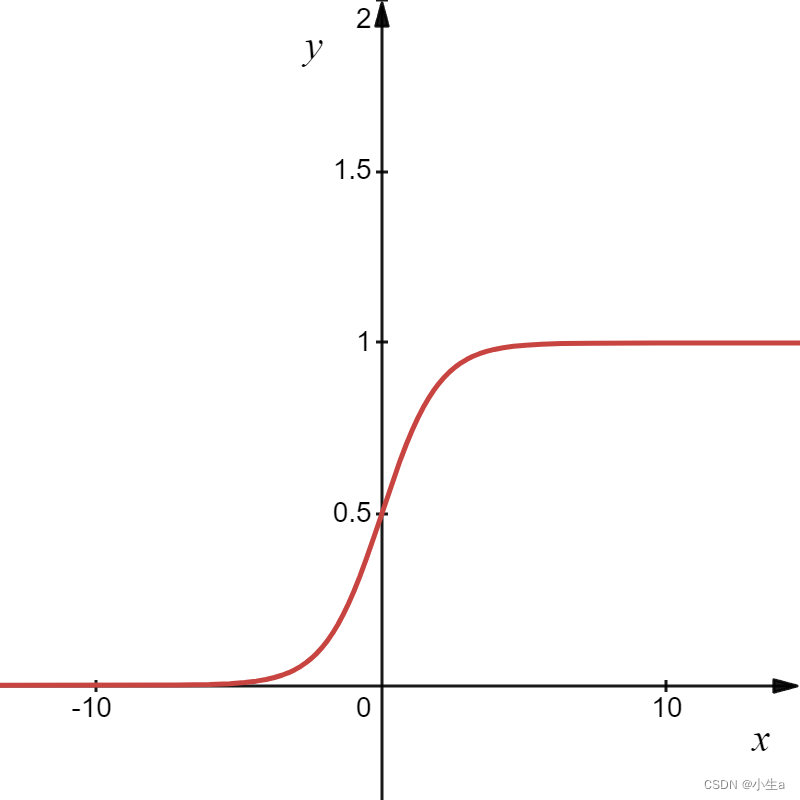
优点:
-
连续性和可微性: Sigmod函数是连续且可微的函数,这使得它在优化过程中更易于处理。神经网络的训练通常涉及到梯度下降等基于梯度的优化方法,而Sigmod函数的可微性使得这些方法可以直接应用于网络的训练过程中。
-
输出范围有界: Sigmod函数的输出范围在(0, 1)之间,这对于某些任务来说是有用的,特别是当输出的是概率值时,可以将输出限制在0到1之间。
-
对输入的响应平滑: Sigmod函数对输入的响应相对平滑,这在一定程度上有助于防止梯度消失问题(vanishing gradient problem)的发生。
缺点:
-
梯度消失: 当输入很大或很小时,Sigmod函数的梯度会趋于零,这会导致梯度消失问题。在反向传播过程中,这可能会导致模型学习变得非常缓慢,甚至停止学习。
-
非零均值: Sigmod函数的输出均值不为零,这可能导致神经网络中的某些神经元在训练过程中出现偏移,从而影响整个网络的学习过程。
-
计算成本高: Sigmod函数的计算相对复杂,涉及到指数运算,因此在大规模的神经网络中,使用Sigmod函数可能会增加计算成本。
-
不以零为中心: Sigmod函数不是以零为中心的,这可能会导致梯度更新时出现不稳定的情况,使得收敛速度变慢。
三、tanh函数
函数公式为:
函数图像为:
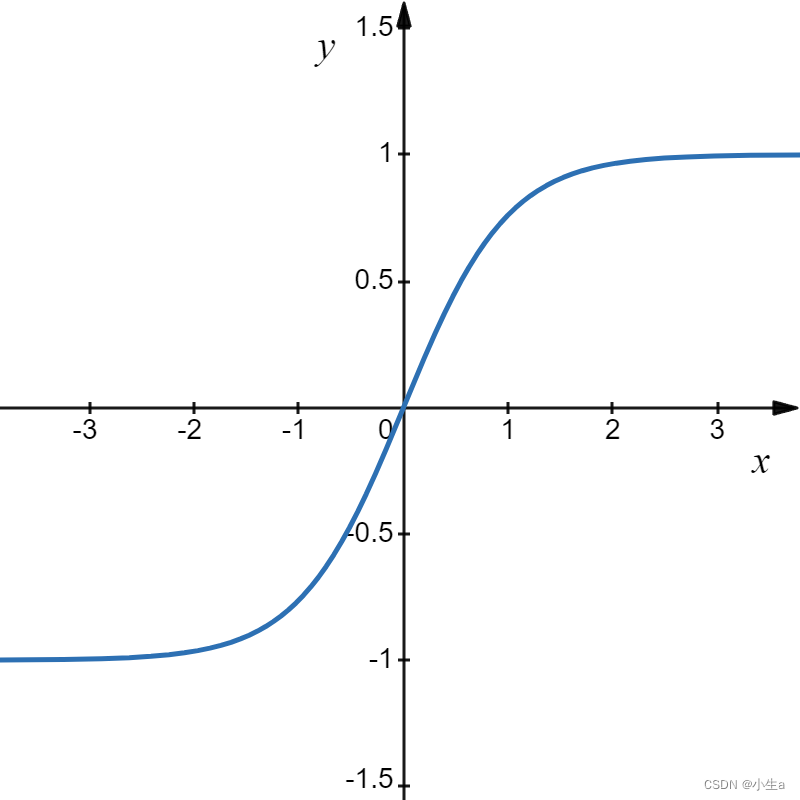
优点:
-
零中心化输出:tanh函数的输出范围是(-1, 1),相比于ReLU函数的输出范围(0, 1),tanh函数的输出是零中心化的,即均值接近于0。这有助于减少梯度消失问题,提高模型的训练效率。
-
非线性特性:与线性激活函数相比,tanh函数是非线性的,能够更好地捕获数据的复杂特征,从而提高模型的表达能力。
-
导数可微性:tanh函数在整个定义域内都是可导的,这使得它适用于基于梯度的优化算法,如反向传播算法。
-
抑制梯度爆炸:与Sigmoid函数相似,tanh函数在输入值较大或较小时会饱和,从而抑制梯度爆炸的问题。
缺点:
-
梯度消失问题:虽然tanh函数的输出范围是(-1, 1),相对于Sigmoid函数来说更接近于零中心化,但在网络较深时,仍然存在梯度消失的问题,尤其是在反向传播时,梯度可能会逐渐变小,导致学习速度变慢或训练过程中出现停滞。
-
计算复杂度:tanh函数的计算相对复杂,需要进行指数运算和除法运算,相比于ReLU函数的简单比较操作,计算成本较高。
-
激活输出范围有限:tanh函数的输出范围是(-1, 1),这意味着当输入值非常大或非常小时,梯度会接近于零,导致饱和现象,这可能会影响模型的收敛速度和稳定性。
四、swish函数
函数公式为:
函数图像为:
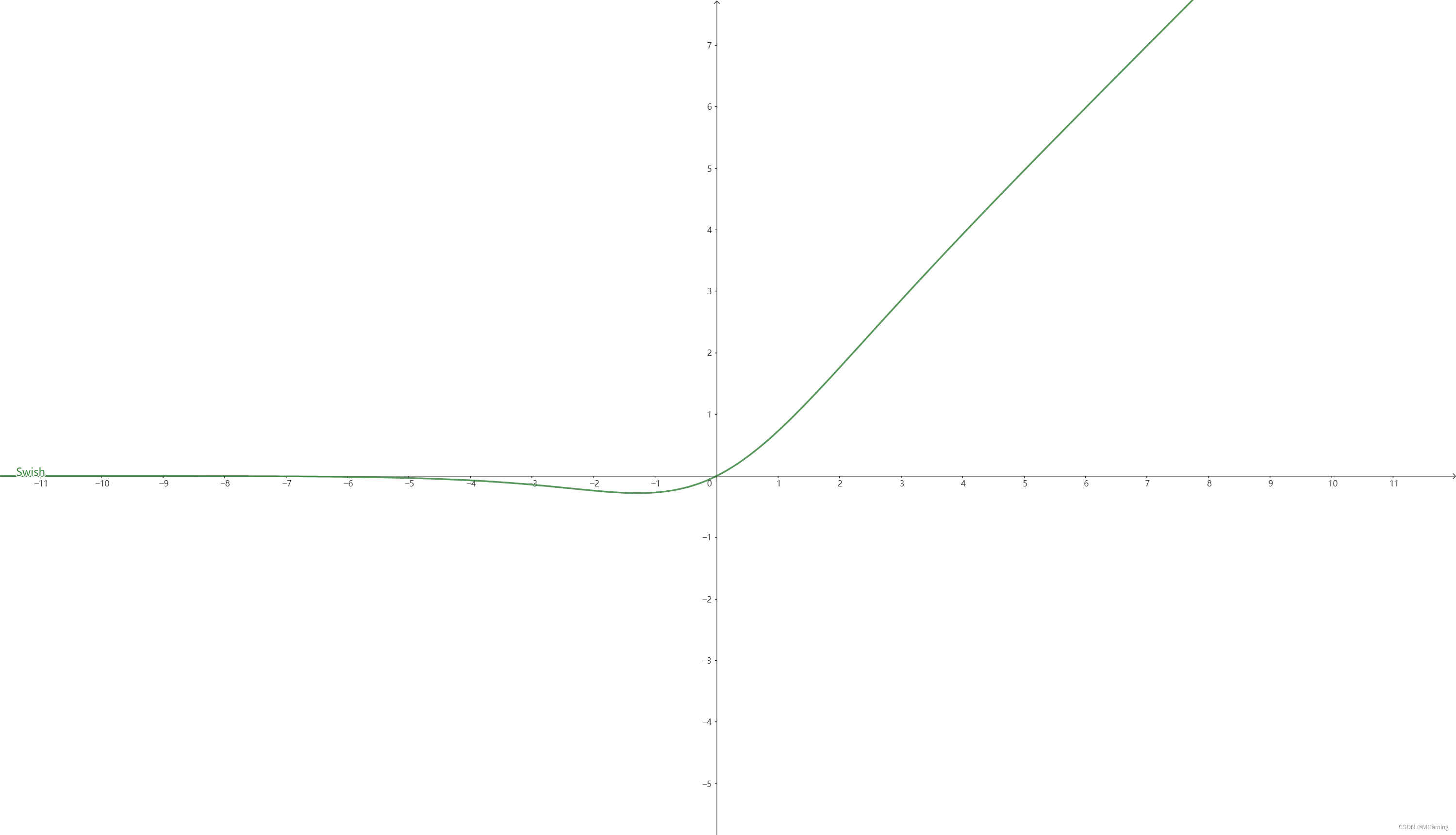
优点:
-
平滑性:Swish函数在整个实数域上都是可导的,并且在接近零的时候变化较为平滑,这有助于减轻梯度消失问题。相比于ReLU等阶跃函数,Swish函数的平滑性使得模型训练更加稳定。
-
非线性度自适应:Swish函数的非线性度取决于输入值,因为它是通过Sigmoid函数进行缩放的。这意味着在不同的输入范围内,其非线性度可能会有所不同,这种自适应性有助于更好地适应不同类型的数据分布。
-
梯度传播良好:由于Swish函数在整个实数域上都是可导的,并且其导数在大部分区域都不会接近零,因此梯度可以更好地传播,减轻了梯度消失的问题。这有助于训练更深的神经网络模型。
-
表现良好:在一些实验中,Swish函数表现出了与ReLU相媲美甚至更好的性能,尤其是在一些较深的神经网络架构中。它能够提供更好的性能和更快的收敛速度。
缺点:
-
计算开销:Swish函数的计算相对复杂,需要计算Sigmoid函数,而Sigmoid函数的计算开销较大。这可能会导致在大规模模型或训练过程中出现较高的计算成本。
-
非线性度不固定:由于Swish函数的非线性度是根据输入值动态调整的,因此可能导致模型的学习行为不稳定,尤其是在训练初始阶段。
-
过拟合风险:由于Swish函数的非线性度在不同的输入范围内可能会有所不同,因此可能导致模型更容易过拟合训练数据,特别是在数据量较小的情况下。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









