







1. LLaMA 的 Transformer 架构改进
LLaMA 基于经典的 Transformer 架构,但与原始的 Transformer 相比有几点重要改进:
- 前置层归一化(Pre-Normalization):LLaMA 采用的是前置层归一化,意味着层归一化操作在多头自注意力层(self-attention layer)和全连接层之前进行。这种方法有助于稳定梯度,使得模型在深层次网络中能够更好地传播梯度,避免训练中的梯度消失或爆炸问题。
- RMSNorm 替代了 LayerNorm:在 LLaMA 中,RMSNorm 被用作归一化函数,区别于 GPT-2 中的 LayerNorm。RMSNorm 的优势在于其通过对输入向量的均方根(Root Mean Square, RMS)进行归一化,进一步增强了训练过程中的稳定性。其计算公式:
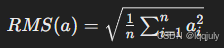
- 该公式计算出输入向量的均方根,再进行归一化,并可引入可学习的缩放因子和偏移参数来增强模型表达能力。
RMSNorm
在
HuggingFace Transformer
库中代码实现:
class LlamaRMSNorm(nn.Module):
def __init__(self, hidden_size, eps=1e-6):
"""
初始化 LlamaRMSNorm 模块。
参数:
- hidden_size: 输入隐藏状态的维度,即需要归一化的特征数。
- eps: 用于数值稳定的非常小的数,防止计算过程中分母为0(通常为1e-6)。
"""
super().__init__()
self.weight = nn.Parameter(torch.ones(hidden_size)) # 权重参数初始化为1
self.variance_epsilon = eps # 数值稳定项
def forward(self, hidden_states):
"""
前向传播函数,执行归一化操作。
参数:
- hidden_states: 输入的张量,表示网络层的隐藏状态。
返回值:
- 返回归一化并且经过缩放的隐藏状态。
"""
# 保存输入的原始数据类型,以便最后转换回同样的类型
input_dtype = hidden_states.dtype
# 计算方差(或更准确地说是每个样本的特征值的均值平方)
variance = hidden_states.to(torch.float32).pow(2).mean(-1, keepdim=True)
# 对 variance 加上 epsilon,防止分母为0,然后取平方根的倒数,进行归一化
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
# weight 是可训练参数,用于缩放归一化后的输出
return (self.weight * hidden_states).to(input_dtype)
2. 激活函数 SwiGLU
LLaMA 还在全连接层中使用了 SwiGLU 激活函数。SwiGLU 是一种改进的激活函数,相比经典的 ReLU 或 Swish,它在大规模模型如 PaLM 和 LLaMA 中表现更好,能提供更高的非线性表达能力。其计算公式为:
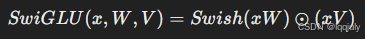
- Swish 函数本身定义为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









