






随着人工智能(AI)技术的快速发展,大规模语言模型(如 OpenAI 的 GPT、Anthropic 的 Claude 等)已经能够生成高质量的文本。然而,传统的有监督学习方法存在局限性,难以确保 AI 生成的内容符合人类偏好。因此,RLHF(Reinforcement Learning from Human Feedback,人类反馈强化学习)应运而生。
RLHF 是一种基于强化学习(Reinforcement Learning, RL)的优化方法,它结合人类反馈(Human Feedback)来训练奖励模型(Reward Model, RM),进而优化语言模型的生成策略。它被广泛用于自然语言处理(NLP)任务,尤其是在对话系统、代码生成、文本摘要等场景中,提高模型的输出质量,使其更符合人类期望。
1. RLHF 的理论基础
1.1 强化学习(Reinforcement Learning, RL)概述
RLHF 的核心思想来源于强化学习(Reinforcement Learning, RL),其基本框架如下:
- 智能体(Agent):在 RLHF 中,智能体通常是一个语言模型,如 GPT-4。
- 环境(Environment):智能体与环境交互,生成文本,并接收环境提供的奖励反馈。
- 状态(State, S):表示当前模型的上下文,例如已经生成的文本。
- 动作(Action, A):表示模型可以采取的操作,例如生成下一个单词或句子。
- 状态转移概率(Transition Probability, P(s′∣s,a)):表示执行动作 aaa 之后,环境转移到新状态 s′s's′ 的概率。
- 奖励(Reward, R(s,a)):用于衡量某个动作的质量。RLHF 通过训练奖励模型(Reward Model, RM)来估计这个奖励。
- 策略(Policy, π(a∣s)):表示智能体在特定状态下选择某个动作的概率分布。
整个强化学习的目标是找到最优策略 π*,使得模型在与环境交互的过程中,最大化累积奖励。
1.2 马尔可夫决策过程(MDP)
强化学习通常建模为一个马尔可夫决策过程(Markov Decision Process, MDP),其定义如下:
M=(S,A,P,R,γ)
其中:
- S 是状态空间。
- A是动作空间。
- P(s′∣s,a) 是状态转移概率分布。
- R(s,a) 是奖励函数,表示在状态 s 采取动作 a 时的即时奖励。
- γ∈[0,1] 是折扣因子(Discount Factor),用于衡量未来奖励的重要性。
智能体的目标是找到一个最优策略 π*,使得长期累积奖励最大化:
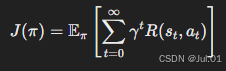
在 RLHF 过程中,模型的策略会不断更新,以生成更符合人类偏好的文本。
2. RLHF 的数学推导
2.1 监督微调(Supervised Fine-Tuning, SFT)
在 RLHF 的第一阶段,我们使用有监督学习(Supervised Learning)对语言模型进行微调。设:
- 语言模型的参数为 θ。
- 训练数据集 D={(xi,yi)},其中 xi 是输入文本,yi 是目标输出。
训练目标是最小化交叉熵损失(Cross-Entropy Loss):
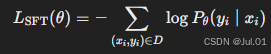
优化方式采用梯度下降:
![]()
其中 η是学习率。
2.2 奖励模型训练(Reward Model, RM)
(1) 人类反馈数据收集
在 RLHF 中,训练数据通常来自人类标注者的偏好排序。具体流程如下:
- AI 生成多个候选回答 y1,y2,yn。
- 人类标注者对这些回答进行排序: yπ(1)≻yπ(2)≻⋯≻yπ(n) 其中 yπ(1) 是最优答案,yπ(n) 是最差答案。
(2) 奖励模型的训练
设奖励模型为 Rϕ(y),我们使用对比学习(Pairwise Comparison)的方法进行训练:
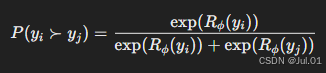
损失函数采用负对数似然(Negative Log-Likelihood, NLL):
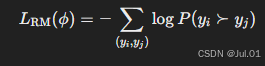
优化方式:
![]()
2.3 强化学习优化(Policy Optimization with RL)
在 RL 过程中,我们使用奖励模型 Rϕ(y)作为强化学习的奖励信号。
(1) 目标函数
强化学习的目标是找到最优策略 πθ 使得期望奖励最大:
![]()
(2) 策略优化(PPO 算法)
在 RLHF 中,常用近端策略优化(Proximal Policy Optimization, PPO)算法进行优化:
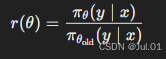
PPO 采用剪裁的目标函数(Clipped Surrogate Objective):
![]()
其中:
- A 是优势函数(Advantage Function)。
- ϵ是超参数。
最终使用梯度上升优化:
![]()
3. 总结
RLHF 是一种结合强化学习(RL)和人类反馈(HF)的 AI 训练方法,能够有效提升 AI 生成文本的质量。其核心步骤包括:
- 监督微调(SFT):训练初始模型。
- 奖励模型训练(RM):基于人类反馈优化奖励函数。
- 强化学习(RL):使用 PPO 等方法优化策略,提高模型表现。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









