






一、注意
对应版本:
Yolov5-v5.0 deepsort-v3.0
Yolov5-v6.1 deepsort-v4.0
二、源码
1、yolov5源码:https://github.com/ultralytics/yolov5
2、yolov5s.pt权重文件下载:yolov5的权重文件yolov5s.pt是分版本的,要在github上下对应的v5.0版本
3、deepsort源码:https://github.com/mikel-brostrom/boxmot
注意下载对应版本的源码
下载完后将yolov5放入deepsort
4、数据集格式txt转xml代码:txt2xml.py
from xml.dom.minidom import Document
import os
import cv2
from tqdm import tqdm
# def makexml(txtPath, xmlPath, picPath): # txt所在文件夹路径,xml文件保存路径,图片所在文件夹路径
def makexml(picPath, txtPath, xmlPath, datasetName): # txt所在文件夹路径,xml文件保存路径,图片所在文件夹路径
"""此函数用于将yolo格式txt标注文件转换为voc格式xml标注文件
在自己的标注图片文件夹下建三个子文件夹,分别命名为picture、txt、xml
"""
dic = {'0': "cow", # 创建字典用来对类型进行转换
}
files = os.listdir(txtPath)
for i, name in enumerate(tqdm(files)):
if name == 'classes.txt':
continue
xmlBuilder = Document()
annotation = xmlBuilder.createElement("annotation") # 创建annotation标签
xmlBuilder.appendChild(annotation)
txtFile = open(os.path.join(txtPath, name))
txtList = txtFile.readlines()
img = cv2.imread(os.path.join(picPath, name.replace('txt', 'jpg')))
Pheight, Pwidth, Pdepth = img.shape
folder = xmlBuilder.createElement("folder") # folder标签
foldercontent = xmlBuilder.createTextNode(datasetName)
folder.appendChild(foldercontent)
annotation.appendChild(folder) # folder标签结束
filename = xmlBuilder.createElement("filename") # filename标签
filenamecontent = xmlBuilder.createTextNode(name[0:-4] + ".jpg")
filename.appendChild(filenamecontent)
annotation.appendChild(filename) # filename标签结束
size = xmlBuilder.createElement("size") # size标签
width = xmlBuilder.createElement("width") # size子标签width
widthcontent = xmlBuilder.createTextNode(str(Pwidth))
width.appendChild(widthcontent)
size.appendChild(width) # size子标签width结束
height = xmlBuilder.createElement("height") # size子标签height
heightcontent = xmlBuilder.createTextNode(str(Pheight))
height.appendChild(heightcontent)
size.appendChild(height) # size子标签height结束
depth = xmlBuilder.createElement("depth") # size子标签depth
depthcontent = xmlBuilder.createTextNode(str(Pdepth))
depth.appendChild(depthcontent)
size.appendChild(depth) # size子标签depth结束
annotation.appendChild(size) # size标签结束
for j in txtList:
oneline = j.strip().split(" ")
object = xmlBuilder.createElement("object") # object 标签
picname = xmlBuilder.createElement("name") # name标签
namecontent = xmlBuilder.createTextNode(dic[oneline[0]])
picname.appendChild(namecontent)
object.appendChild(picname) # name标签结束
pose = xmlBuilder.createElement("pose") # pose标签
posecontent = xmlBuilder.createTextNode("Unspecified")
pose.appendChild(posecontent)
object.appendChild(pose) # pose标签结束
truncated = xmlBuilder.createElement("truncated") # truncated标签
truncatedContent = xmlBuilder.createTextNode("0")
truncated.appendChild(truncatedContent)
object.appendChild(truncated) # truncated标签结束
difficult = xmlBuilder.createElement("difficult") # difficult标签
difficultcontent = xmlBuilder.createTextNode("0")
difficult.appendChild(difficultcontent)
object.appendChild(difficult) # difficult标签结束
bndbox = xmlBuilder.createElement("bndbox") # bndbox标签
xmin = xmlBuilder.createElement("xmin") # xmin标签
mathData = int(((float(oneline[1])) * Pwidth + 1) - (float(oneline[3])) * 0.5 * Pwidth)
xminContent = xmlBuilder.createTextNode(str(mathData))
xmin.appendChild(xminContent)
bndbox.appendChild(xmin) # xmin标签结束
ymin = xmlBuilder.createElement("ymin") # ymin标签
mathData = int(((float(oneline[2])) * Pheight + 1) - (float(oneline[4])) * 0.5 * Pheight)
yminContent = xmlBuilder.createTextNode(str(mathData))
ymin.appendChild(yminContent)
bndbox.appendChild(ymin) # ymin标签结束
xmax = xmlBuilder.createElement("xmax") # xmax标签
mathData = int(((float(oneline[1])) * Pwidth + 1) + (float(oneline[3])) * 0.5 * Pwidth)
xmaxContent = xmlBuilder.createTextNode(str(mathData))
xmax.appendChild(xmaxContent)
bndbox.appendChild(xmax) # xmax标签结束
ymax = xmlBuilder.createElement("ymax") # ymax标签
mathData = int(((float(oneline[2])) * Pheight + 1) + (float(oneline[4])) * 0.5 * Pheight)
ymaxContent = xmlBuilder.createTextNode(str(mathData))
ymax.appendChild(ymaxContent)
bndbox.appendChild(ymax) # ymax标签结束
object.appendChild(bndbox) # bndbox标签结束
annotation.appendChild(object) # object标签结束
f = open(os.path.join(xmlPath, name.replace('txt', 'xml')), 'w')
xmlBuilder.writexml(f, indent='\t', newl='\n', addindent='\t', encoding='utf-8')
f.close()
if __name__ == "__main__":
picPath = r"D:\Github_download\Yolov5_DeepSort\yolov5\cows\images\val" # 原图文件夹路径
txtPath = r"D:\Github_download\Yolov5_DeepSort\yolov5\cows\labels\val" # 原txt标签文件夹路径
xmlPath = r"D:\Github_download\Yolov5_DeepSort\yolov5\cows\labels\val" # 保存xml文件夹路径
datasetName = r'cows' # 数据集名称
os.makedirs(xmlPath) if not os.path.exists(xmlPath) else None
makexml(picPath, txtPath, xmlPath, datasetName)
# tasks = ['train', 'test', 'val'] # 当前任务
# for task in tasks:
# picPath = r"...\images\{}".format(task) # 原图文件夹路径
# txtPath = r"...\labels\{}".format(task) # 原txt标签文件夹路径
# xmlPath = r"...\labels\{}_xml".format(task) # 保存xml文件夹路径
# datasetName = r'MyDataset'
# os.makedirs(xmlPath) if not os.path.exists(xmlPath) else None
# makexml(picPath, txtPath, xmlPath, datasetName)
5、deepsort数据集需要抠图,koutu.py:
import cv2
import xml.etree.ElementTree as ET
import numpy as np
import xml.dom.minidom
import os
import argparse
def main():
# JPG文件的地址
img_path = "F:/cow_deepsort/train/images/"
# XML文件的地址
anno_path = "F:/cow_deepsort/train/labels_xml/"
# 存结果的文件夹
cut_path = "F:/cow_deepsort/train/crops/"
if not os.path.exists(cut_path):
os.makedirs(cut_path)
# 获取文件夹中的文件
imagelist = os.listdir(img_path)
# print(imagelist
for image in imagelist:
image_pre, ext = os.path.splitext(image)
img_file = img_path + image
img = cv2.imread(img_file)
xml_file = anno_path + image_pre + '.xml'
# DOMTree = xml.dom.minidom.parse(xml_file)
# collection = DOMTree.documentElement
# objects = collection.getElementsByTagName("object")
tree = ET.parse(xml_file)
root = tree.getroot()
# if root.find('object') == None:
# return
obj_i = 0
for obj in root.iter('object'):
obj_i += 1
print(obj_i)
cls = obj.find('name').text
xmlbox = obj.find('bndbox')
b = [int(float(xmlbox.find('xmin').text)), int(float(xmlbox.find('ymin').text)),
int(float(xmlbox.find('xmax').text)),
int(float(xmlbox.find('ymax').text))]
img_cut = img[b[1]:b[3], b[0]:b[2], :]
path = os.path.join(cut_path, cls)
# 目录是否存在,不存在则创建
mkdirlambda = lambda x: os.makedirs(x) if not os.path.exists(x) else True
mkdirlambda(path)
try:
cv2.imwrite(os.path.join(cut_path, cls, '{}_{:0>2d}.jpg'.format(image_pre, obj_i)), img_cut)
except:
continue
print("&&&&")
if __name__ == '__main__':
main()抠完图再将数据集划分为训练集和验证集:
import os
from PIL import Image
from shutil import copyfile, copytree, rmtree, move
PATH_DATASET = r'F:\cow_deepsort\cow' # 需要处理的文件夹
PATH_NEW_DATASET = 'F:\cow_dp' # 处理后的文件夹
PATH_ALL_IMAGES = PATH_NEW_DATASET + '/all_images'
PATH_TRAIN = PATH_NEW_DATASET + '/train'
PATH_TEST = PATH_NEW_DATASET + '/test'
# 定义创建目录函数
def mymkdir(path):
path = path.strip() # 去除首位空格
path = path.rstrip("\\") # 去除尾部 \ 符号
isExists = os.path.exists(path) # 判断路径是否存在
if not isExists:
os.makedirs(path) # 如果不存在则创建目录
print(path + ' 创建成功')
return True
else:
# 如果目录存在则不创建,并提示目录已存在
print(path + ' 目录已存在')
return False
class BatchRename():
'''
批量重命名文件夹中的图片文件
'''
def __init__(self):
self.path = PATH_DATASET # 表示需要命名处理的文件夹
# 修改图像尺寸
def resize(self):
for aroot, dirs, files in os.walk(self.path):
# aroot是self.path目录下的所有子目录(含self.path),dir是self.path下所有的文件夹的列表.
filelist = files # 注意此处仅是该路径下的其中一个列表
# print('list', list)
# filelist = os.listdir(self.path) #获取文件路径
total_num = len(filelist) # 获取文件长度(个数)
for item in filelist:
if item.endswith('.jpg'): # 初始的图片的格式为jpg格式的(或者源文件是png格式及其他格式,后面的转换格式就可以调整为自己需要的格式即可)
src = os.path.join(os.path.abspath(aroot), item)
# 修改图片尺寸到128宽*256高
im = Image.open(src)
out = im.resize((128, 256), Image.ANTIALIAS) # resize image with high-quality
out.save(src) # 原路径保存
def rename(self):
for aroot, dirs, files in os.walk(self.path):
# aroot是self.path目录下的所有子目录(含self.path),dir是self.path下所有的文件夹的列表.
filelist = files # 注意此处仅是该路径下的其中一个列表
# print('list', list)
# filelist = os.listdir(self.path) #获取文件路径
total_num = len(filelist) # 获取文件长度(个数)
i = 1 # 表示文件的命名是从1开始的
for item in filelist:
if item.endswith('.jpg'): # 初始的图片的格式为jpg格式的(或者源文件是png格式及其他格式,后面的转换格式就可以调整为自己需要的格式即可)
src = os.path.join(os.path.abspath(aroot), item)
# 根据图片名创建图片目录
dirname = str(item.split('_')[0])
# 为相同车辆创建目录
# new_dir = os.path.join(self.path, '..', 'bbox_all', dirname)
new_dir = os.path.join(PATH_ALL_IMAGES, dirname)
if not os.path.isdir(new_dir):
mymkdir(new_dir)
# 获得new_dir中的图片数
num_pic = len(os.listdir(new_dir))
dst = os.path.join(os.path.abspath(new_dir),
dirname + 'C1T0001F' + str(num_pic + 1) + '.jpg')
# 处理后的格式也为jpg格式的,当然这里可以改成png格式 C1T0001F见mars.py filenames 相机ID,跟踪指数
# dst = os.path.join(os.path.abspath(self.path), '0000' + format(str(i), '0>3s') + '.jpg') 这种情况下的命名格式为0000000.jpg形式,可以自主定义想要的格式
try:
copyfile(src, dst) # os.rename(src, dst)
print('converting %s to %s ...' % (src, dst))
i = i + 1
except:
continue
print('total %d to rename & converted %d jpgs' % (total_num, i))
def split(self):
# ---------------------------------------
# train_test
images_path = PATH_ALL_IMAGES
train_save_path = PATH_TRAIN
test_save_path = PATH_TEST
if not os.path.isdir(train_save_path):
os.mkdir(train_save_path)
os.mkdir(test_save_path)
for _, dirs, _ in os.walk(images_path, topdown=True):
for i, dir in enumerate(dirs):
for root, _, files in os.walk(images_path + '/' + dir, topdown=True):
for j, file in enumerate(files):
if (j == 0): # test dataset;每个车辆的第一幅图片
print("序号:%s 文件夹: %s 图片:%s 归为测试集" % (i + 1, root, file))
src_path = root + '/' + file
dst_dir = test_save_path + '/' + dir
if not os.path.isdir(dst_dir):
os.mkdir(dst_dir)
dst_path = dst_dir + '/' + file
move(src_path, dst_path)
else:
src_path = root + '/' + file
dst_dir = train_save_path + '/' + dir
if not os.path.isdir(dst_dir):
os.mkdir(dst_dir)
dst_path = dst_dir + '/' + file
move(src_path, dst_path)
rmtree(PATH_ALL_IMAGES)
if __name__ == '__main__':
demo = BatchRename()
demo.resize()
demo.rename()
demo.split()三、yolov5训练
略
四、deepsort训练
1、数据集构建
deep_sort的数据集和yolov5不一样,这是一个分类的数据集
将用于yolo训练的数据集(txt格式)用txt2xml.py转换为xml格式
再用koutu.py进行抠图得到数据集,再划分数据集为训练集和验证集
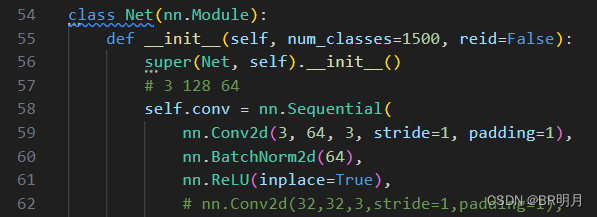
2、修改model.py
将num_classes=数据集子文件夹数目
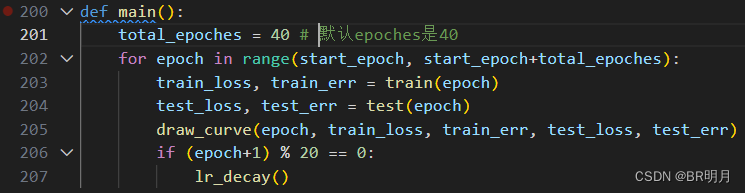
3、修改train.py

epoch次数:
权重文件保存路径:(以免权重保存覆盖原始权重)
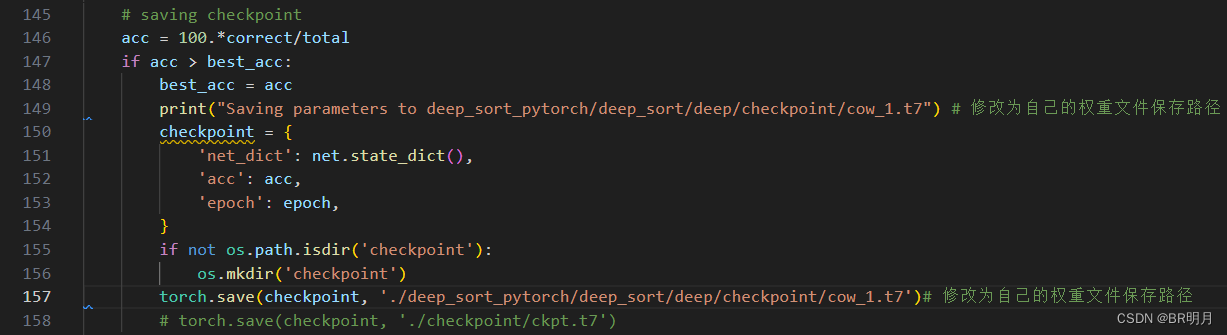
修改dataset的预处理:
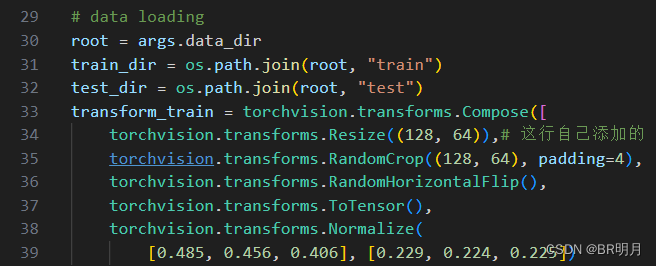
4、训练
运行train.py开始训练,得到的权重结果保存在deep/checkpoint中
五、运行deepsort
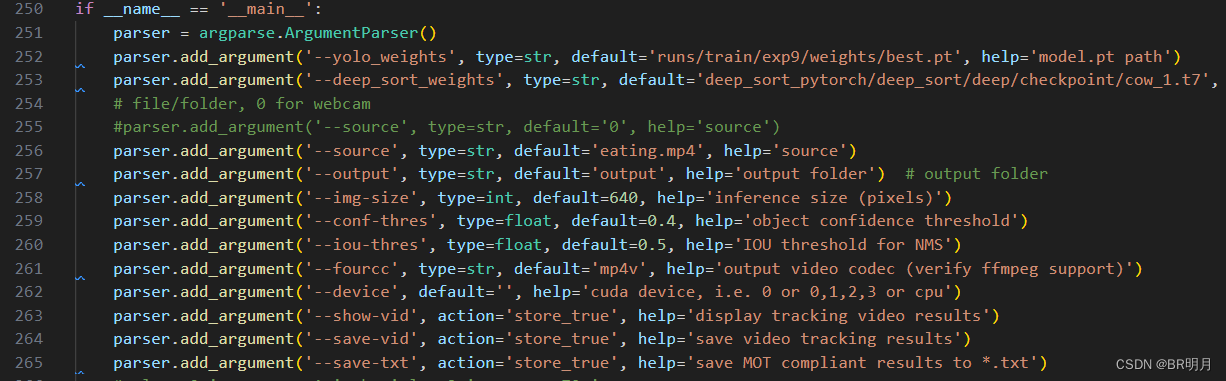
修改权重文件路径参数后运行track.py:
六、报错
1、
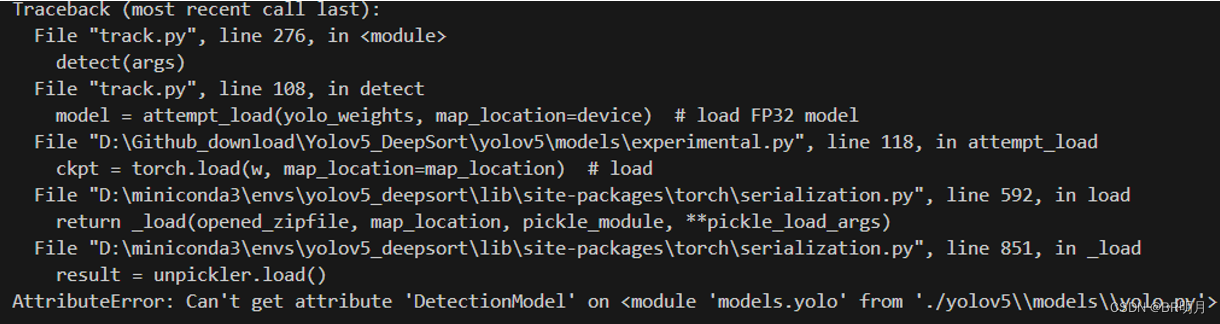
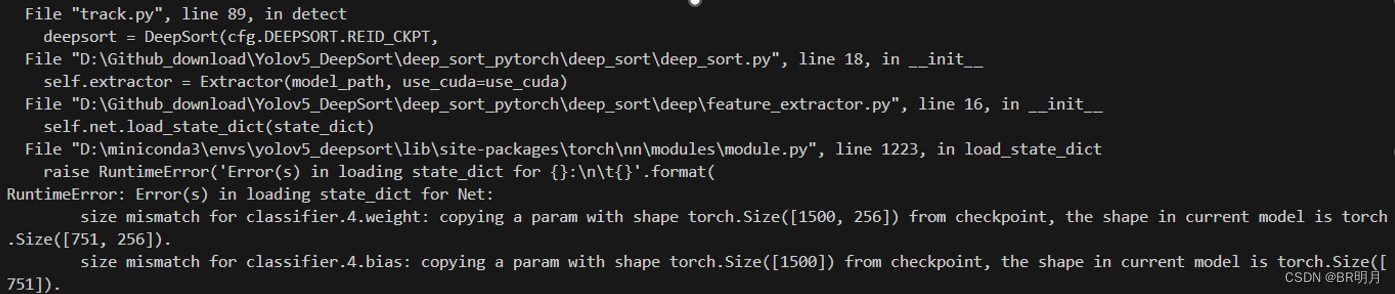
权重文件pt版本不对应于deepsort,检查该权重是用yolov5的哪个版本训练的。Yolov5-5.0对应deepsort-v3.0,应该用5.0版本的yolov5训练得到pt文件
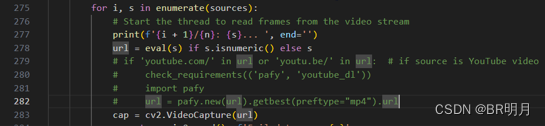
2、运行—source 0 报错url为整数:解决方法:注释掉了if ‘youtube.com/’代码部分
3、
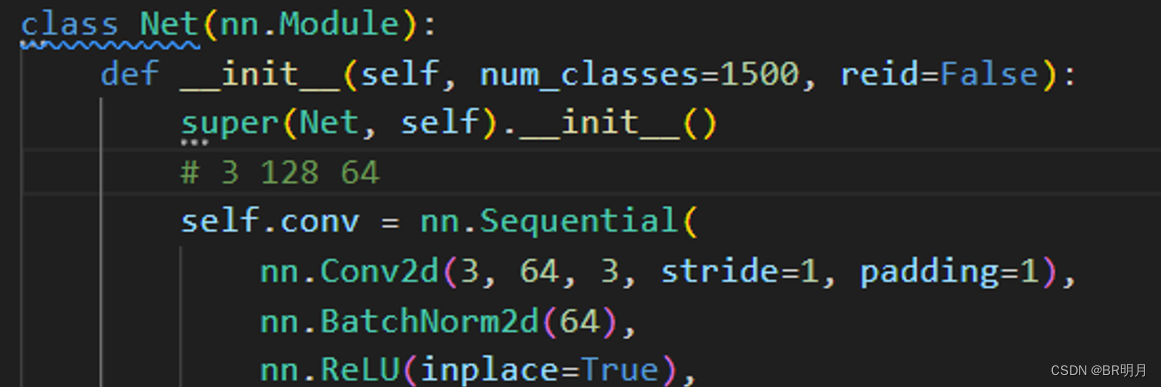
更改model.py中的num_classes即可
4、

未使用对应版本的预训练权重文件yolov5s.pt,去下载对应版本的pt文件
https://github.com/ultralytics/yolov5/releases
未完待续
参考:
Yolov5 + Deepsort 重新训练自己的数据(保姆级超详细)_yolov5+deepsort训练自己的数据-CSDN博客文章浏览阅读4.2w次,点赞78次,收藏689次。从下面github库中拿代码:https://github.com/mikel-brostrom/Yolov5_DeepSort_Pytorchhttps://github.com/mikel-brostrom/Yolov5_DeepSort_PytorchGitHub - Sharpiless/Yolov5-Deepsort: 最新版本yolov5+deepsort目标检测和追踪,能够显示目标类别,支持5.0版本可训练自己数据集最新版本yolov5+deepsort目标检测和追踪,能够显示目标类别,支_yolov5+deepsort训练自己的数据https://blog.csdn.net/weixin_53711236/article/details/123762215?spm=1001.2014.3001.5506【Yolov5+Deepsort】训练自己的数据集(3)| 目标检测&追踪 | 轨迹绘制 | 报错分析&解决_deepsort训练自己数据-CSDN博客文章浏览阅读6.8k次,点赞52次,收藏154次。【Yolov5+Deepsort】训练自己的数据集(3)| 目标检测&追踪 | 轨迹绘制_deepsort训练自己数据
https://blog.csdn.net/m0_66307842/article/details/132124942?spm=1001.2014.3001.5506















 7976
7976

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









