







 文章介绍了如何在一个区间集合中找到需要移除的最小区间数量以使得剩余区间互不重叠,以及合并所有重叠区间的方法。使用了排序和边界比较的技巧,时间复杂度为O(nlogn),空间复杂度为O(n)。
文章介绍了如何在一个区间集合中找到需要移除的最小区间数量以使得剩余区间互不重叠,以及合并所有重叠区间的方法。使用了排序和边界比较的技巧,时间复杂度为O(nlogn),空间复杂度为O(n)。
无重叠区间
给定一个区间的集合,找到需要移除区间的最小数量,使剩余区间互不重叠。
注意: 可以认为区间的终点总是大于它的起点。 区间 [1,2] 和 [2,3] 的边界相互“接触”,但没有相互重叠。
示例 1:
- 输入: [ [1,2], [2,3], [3,4], [1,3] ]
- 输出: 1
- 解释: 移除 [1,3] 后,剩下的区间没有重叠。
示例 2:
- 输入: [ [1,2], [1,2], [1,2] ]
- 输出: 2
- 解释: 你需要移除两个 [1,2] 来使剩下的区间没有重叠。
示例 3:
- 输入: [ [1,2], [2,3] ]
- 输出: 0
- 解释: 你不需要移除任何区间,因为它们已经是无重叠的了。
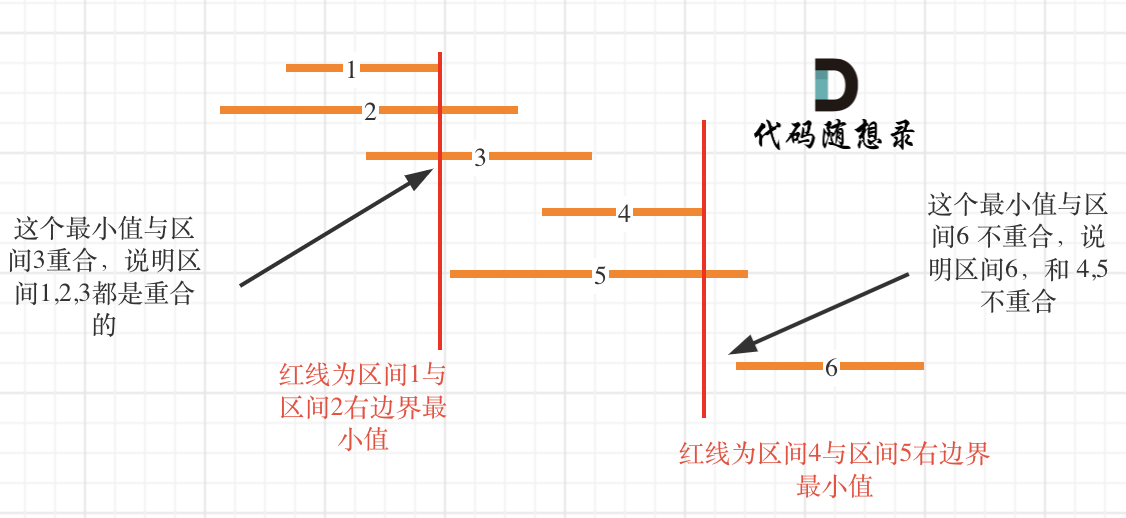
思路和上一道题是一样的,排序,边界大小判断,但是会多出来一个移除元素的操作使剩余区间互不重叠;
和之前题目思路一样,因为只需要返回移除数组的数量,而不需要返回具体是哪个,所以直接定义计数器即可,无须真正删除元素;
要得到删除的元素数量,排序是必然的,这样方便统一比较;此处按照区间左右边界点排序都可以,若按照右边界排序,则从左往右比较,记录不重叠的区间数;此处采取比较符合习惯的有边界排序:
代码如下:
static bool cmp(vector<int>& a, vector<int>& b){
return a[1] < b[1];
}
int minRemovedIntervals(vector<vector<int>>& intervals){
if(intervals.size() == 0) return 0;
sort(intervals.begin(), intervals.end(), cmp);//右边界排序
int count = 1;//最小非重叠区间数,至少为1
int index = intervals[0][1];//右边界排序,无法直接使用intevals[i][j]的语句实现更新
for(int i = 1; i < intervals.size(); i++){
if(index <= intervals[i][0]){
index = intervals[i][1];//更新有边界,如果不用index,更新语句就是intervals[i][1] = intervals[i][1];
count++;
}
}
return intervals.size() - count;
}
左边排序也可以,这时返回的count直接就是最大重叠区间数:
static bool cmp(vector<int>& a, vector<int>& b){
return a[0] < b[0];
}
int minRemovedIntervals(vector<vector<int>>& intervals){
if(intervals.size() == 0) return 0;
sort(intervals.begin(), intervals.end(), cmp);//左边界排序
int count = 0;//最大重叠区间数,最小为0
//int index = intervals[0][1];//左边界排序,无须index更新
for(int i = 1; i < intervals.size(); i++){
if(intervals[i][0] < intervals[i - 1][1]){//重叠
intervals[i][1] = min(intervals[i - 1][1], intervals[i][1]);
count++;
}
}
return count;
}
- 时间复杂度:O(nlog n) ,有一个快排;
- 空间复杂度:O(n),有一个快排,最差情况(倒序)时,需要n次递归调用。因此确实需要O(n)的栈空间。
划分字母区间
字符串 S 由小写字母组成。我们要把这个字符串划分为尽可能多的片段,同一字母最多出现在一个片段中。返回一个表示每个字符串片段的长度的列表。
示例:
- 输入:S = “ababcbacadefegdehijhklij”
- 输出:[9,7,8] 解释: 划分结果为 “ababcbaca”, “defegde”, “hijhklij”。 每个字母最多出现在一个片段中。 像 “ababcbacadefegde”, “hijhklij” 的划分是错误的,因为划分的片段数较少。
提示:
- S的长度在[1, 500]之间。
- S只包含小写字母 ‘a’ 到 ‘z’ 。
初识,真没思路,甚至想到了回溯嗯找,不得不说标记最大下标这个思路是真的巧妙,确保了每个被分割的片段必然是满足题目要求的;
找每⼀个字⺟的边界,如果找到之前遍历过的所有字⺟的最远边界,说明这个边界就是分割点。此时前⾯出现过所有字⺟,最远也就到这个边界
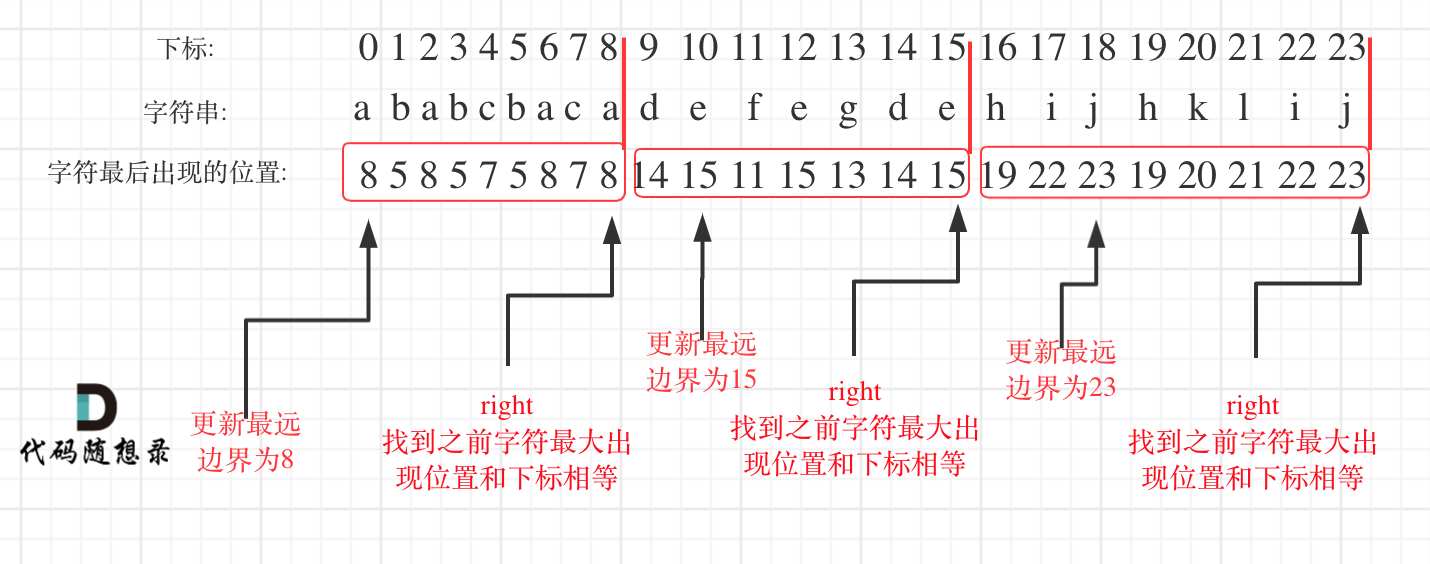
vector<int> partitionLabels(string s){
int hash[27] = {0};
for(int i = 0; i < s.size(); i++){
hash[s[i] - 'a'] = i;//记录元素出现的最远边界
}
vector<int> result;
int left = 0;
int right = 0;
for(int i = 0; i < s.size(); i++){
right = max(right, hash[s[i] - 'a']);//更新最大值
if(i == right){//达到最大值即分割边界
res.push_back(right - left + 1);
left = i + 1;
}
}
return res;
}
合并区间
给出一个区间的集合,请合并所有重叠的区间。
示例 1:
- 输入: intervals = [[1,3],[2,6],[8,10],[15,18]]
- 输出: [[1,6],[8,10],[15,18]]
- 解释: 区间 [1,3] 和 [2,6] 重叠, 将它们合并为 [1,6].
示例 2:
- 输入: intervals = [[1,4],[4,5]]
- 输出: [[1,5]]
- 解释: 区间 [1,4] 和 [4,5] 可被视为重叠区间。
- 注意:输入类型已于2019年4月15日更改。 请重置默认代码定义以获取新方法签名。
和无重叠区间操作方法一致,但是合并区间:
static bool cmp(vector<int>& a, vector<int>& b){
return a[0] < b[0];
}
vector<vector<int>> MergeIntervals(vector<vector<int>>& intervals){
vector<vector<int>> res;//直接操作原数组会很复杂
if(intervals.size() == 0) return res;
sort(intervals.begin(), intervals.end(), cmp);//左边界排序
res.push_back(intervals[0]);
for(int i = 1; i < intervals.size(); i++){
if(intervals[i][0] <= res.back()[1]){//重叠,i的左边界<=上个区间的有边界
//res.back()[0];左边界不需要处理
res.back()[1] = max(intervals[i][1], res.back()[1]);
}
else{
res.push_back(intervals[i]);
}
}
return res;
}















 313
313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









