








目录
1、用Socket实现一个简单的web服务器
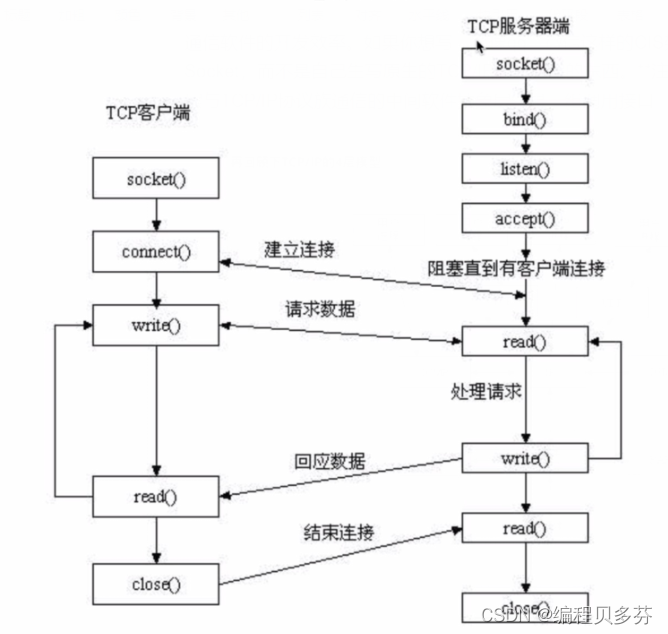
首先大概讲述一下,Socket创建服务器端和客户端的一个大致流程:
客户端调用 socket() 函数创建套接字后,因为没有建立连接,所以套接字处于CLOSED状态;服务器端调用 listen() 函数后,套接字进入LISTEN状态,开始监听客户端请求
这时客户端发起请求:
1) 当客户端调用 connect() 函数后,TCP协议会组建一个数据包,并设置 SYN 标志位,表示该数据包是用来建立同步连接的。同时生成一个随机数字 1000,填充“序号(Seq)”字段,表示该数据包的序号。完成这些工作,开始向服务器端发送数据包,客户端就进入了SYN-SEND状态。
2) 服务器端收到数据包,检测到已经设置了 SYN 标志位,就知道这是客户端发来的建立连接的“请求包”。服务器端也会组建一个数据包,并设置 SYN 和 ACK 标志位,SYN 表示该数据包用来建立连接,ACK 用来确认收到了刚才客户端发送的数据包
服务器生成一个随机数 2000,填充“序号(Seq)”字段。2000 和客户端数据包没有关系。
服务器将客户端数据包序号(1000)加1,得到1001,并用这个数字填充“确认号(Ack)”字段。
服务器将数据包发出,进入SYN-RECV状态
3) 客户端收到数据包,检测到已经设置了 SYN 和 ACK 标志位,就知道这是服务器发来的“确认包”。客户端会检测“确认号(Ack)”字段,看它的值是否为 1000+1,如果是就说明连接建立成功。
接下来,客户端会继续组建数据包,并设置 ACK 标志位,表示客户端正确接收了服务器发来的“确认包”。同时,将刚才服务器发来的数据包序号(2000)加1,得到 2001,并用这个数字来填充“确认号(Ack)”字段。
客户端将数据包发出,进入ESTABLISED状态,表示连接已经成功建立。
4) 服务器端收到数据包,检测到已经设置了 ACK 标志位,就知道这是客户端发来的“确认包”。服务器会检测“确认号(Ack)”字段,看它的值是否为 2000+1,如果是就说明连接建立成功,服务器进入ESTABLISED状态。
至此,客户端和服务器都进入了ESTABLISED状态,连接建立成功,接下来就可以收发数据了。
我们可以简单的利用该流程去实现应该简单的socket web服务器:
代码也很简洁:
import socket
def main():
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
s.bind(('localhost',8000))
s.listen(5)
while True:
#等待浏览器连接服务器
conn,conn_adr=s.accept()
#接收浏览器发送的内容
data=conn.recv(1024)
print(data)
#给浏览器返回一个内容,在发送内容之前,首先告诉我们的浏览器发生的是文本内容,超链接,还是图片
conn.send(b"HTTP/1.1 200 OK\r\nContent-Type:text/html; charset=utf-8\r\n\r\n")
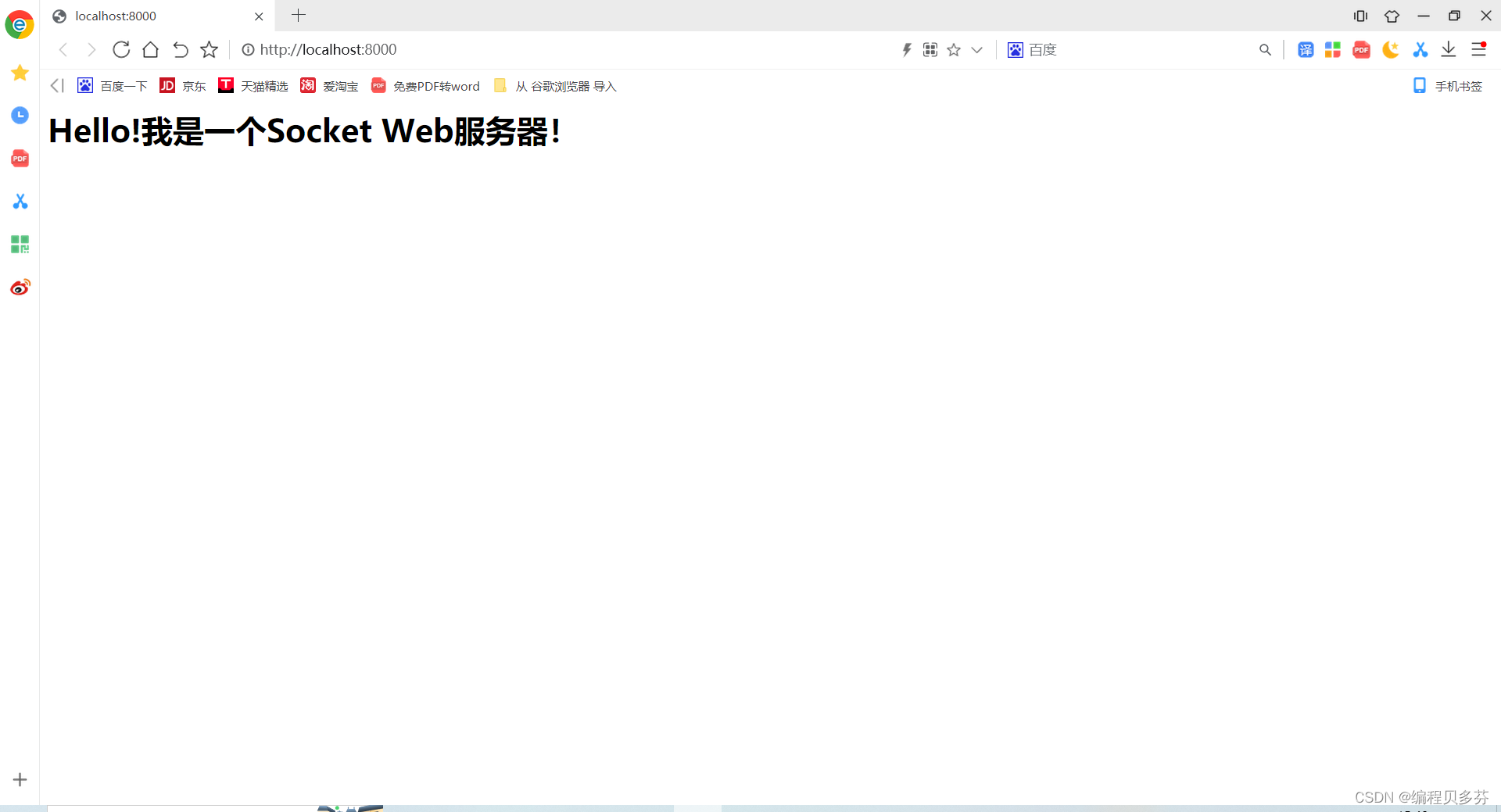
conn.send('<h1>Hello!我是一个Socket Web服务器!</h1>'.encode('utf-8'))
conn.close()
if __name__=='__main__':
main()注意:不要用edge去打开8000端口,我试了很多次,用谷歌的话是可以正常使用的!不要把问题遗留在一些没有意义的事情上面!!!
2、用Wsgi实现一个简单的web服务器
wSGI (Web Server Gateway Interface)是一种规范﹐它定义了使用python编写的web app(应用程序)与web server (socket服务端)之间接口格式﹐实现web app与web server间的解耦
通俗的说︰当规范建立后﹐程序就不再重复编写web server (socket服务端)﹐
而是直接使用现成的实现WSGI的模块(例如︰wsgiref · uwsgi· werkzeug)﹐从而让程序员更加专注与业务代码
与其重复造轮子﹐不如直接用现成的·
这里的代码也是比较简单的:
"""
wSGI (Web Server Gateway Interface)是一种规范﹐它定义了使用python编写的web app(应用程序)
与web server (socket服务端)之间接口格式﹐实现web app与web server间的解耦
通俗的说︰当规范建立后﹐程序就不再重复编写web server (socket服务端)﹐
而是直接使用现成的实现WSGI的模块(例如︰wsgiref · uwsgi· werkzeug)﹐从而让程序员更加专注与业务代码
与其重复造轮子﹐不如直接用现成的·
"""
#首先导入模块接口,接入一个创建简单服务器的模块功能
from wsgiref.simple_server import make_server
def run_server(environ,start_response):
#print('Hello',environ)
#start_response 应该是一个函数用于给客户端传输数据使用
start_response("200 OK",[('Content-Type','text/html;charset=utf-8')])#这里的是语法,是死的!!
'''
先写好状态码,在写要传输的数据类型(超文本,超链接,还是图片)
'''
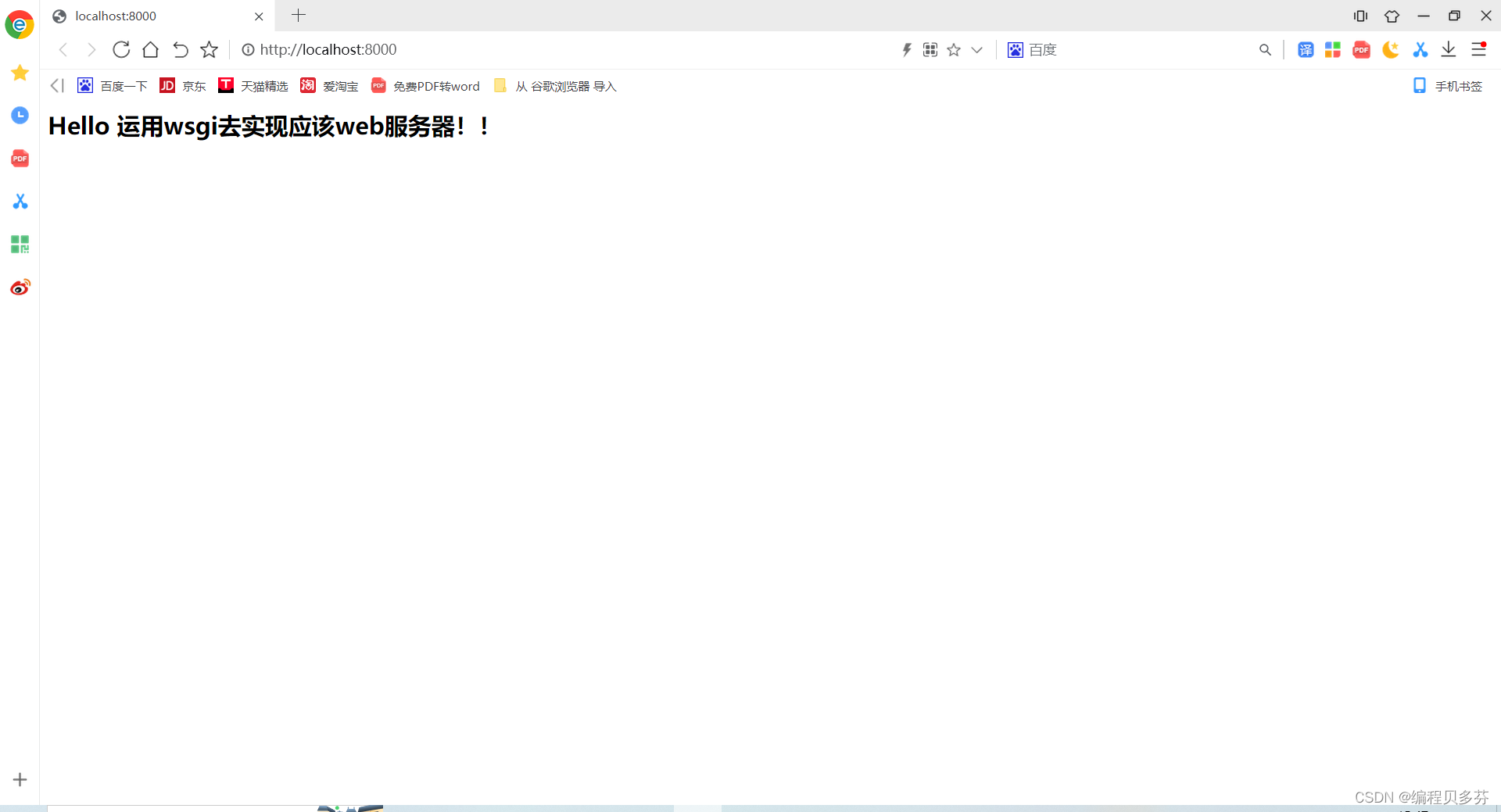
return [bytes("<h2>Hello 运用wsgi去实现应该web服务器!!</h2>",encoding='utf-8')]
#在make_server功能中调用run_server接口,我们需要知道的是运用该模块构件一个服务器端,需要传入两个参数
#一个是environ 有关浏览器内容的一个参数
#一个是 给客户端返回数据
s=make_server('localhost',8000,run_server)
s.serve_forever() #代表一个死循环,一直运行该服务器代码运行结果如下:
在上述的程序中,我们只是实现应该url,那么我们如何实现支持多url的web服务器?
3、用Wsgi实现支持多url的web服务器
1、路由的分发器,负责把url 匹配到对应的函数中去
2、开发好对应的 业务函数
3、当一个请求来了之后,先走路由分发器,如果找到对应的function,就执行,如果没有找到,就返回404
代码也是比较简单的:
'''
1、路由的分发器,负责把url 匹配到对应的函数中去
2、开发好对应的 业务函数
3、当一个请求来了之后,先走路由分发器,如果找到对应的function,就执行,如果没有找到,就返回404
'''
from wsgiref.simple_server import make_server
def Pig(environ,start_response):
print('你是头猪!')
start_response("200 OK", [('Content-Type', 'text/html;charset=utf-8')])
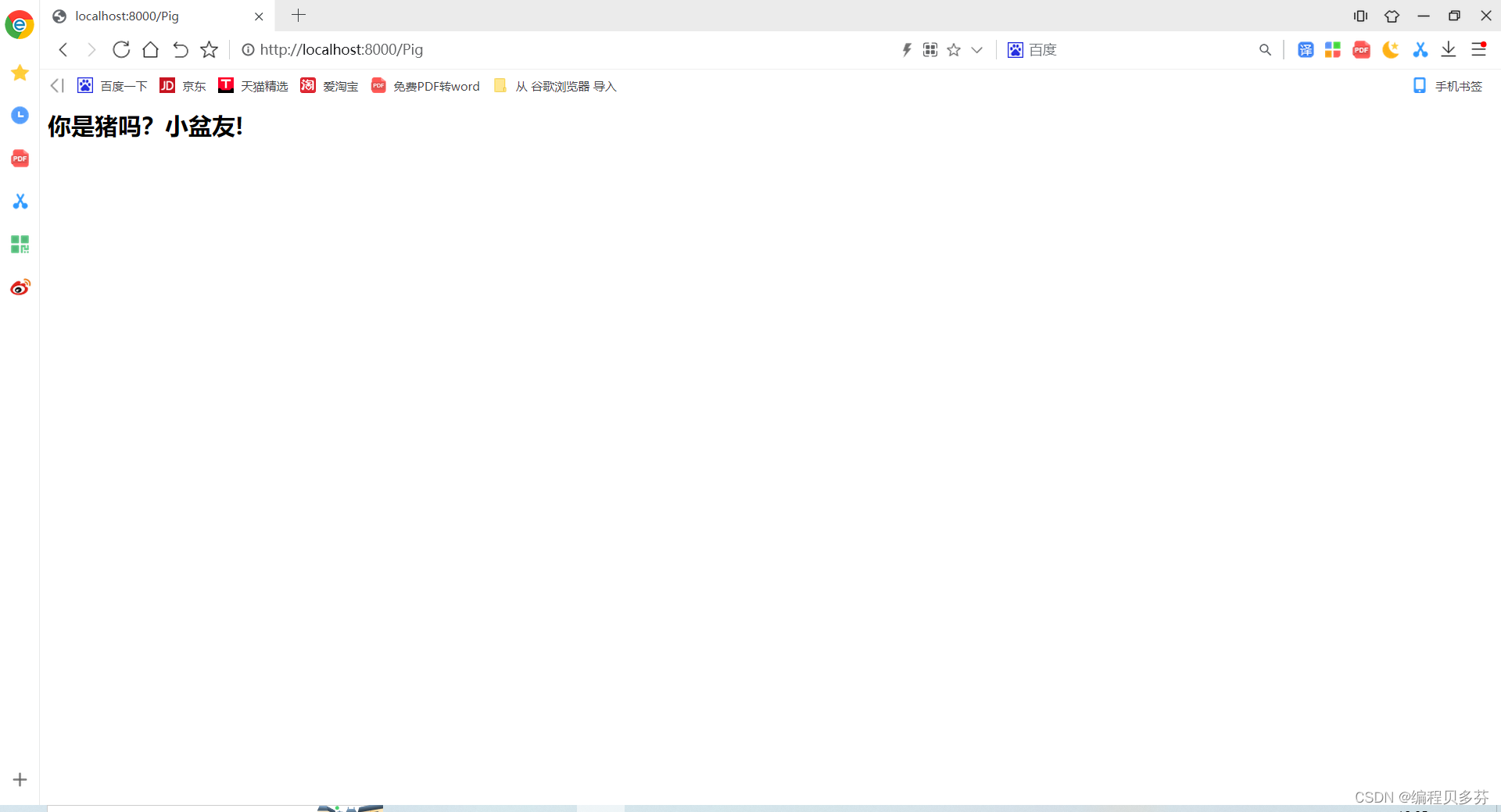
return [bytes("<h2>你是猪吗?小盆友! </h2>", encoding='utf-8')]
def Book(environ,start_response):
print('你喜欢看书吗?')
start_response("200 OK", [('Content-Type', 'text/html;charset=utf-8')])
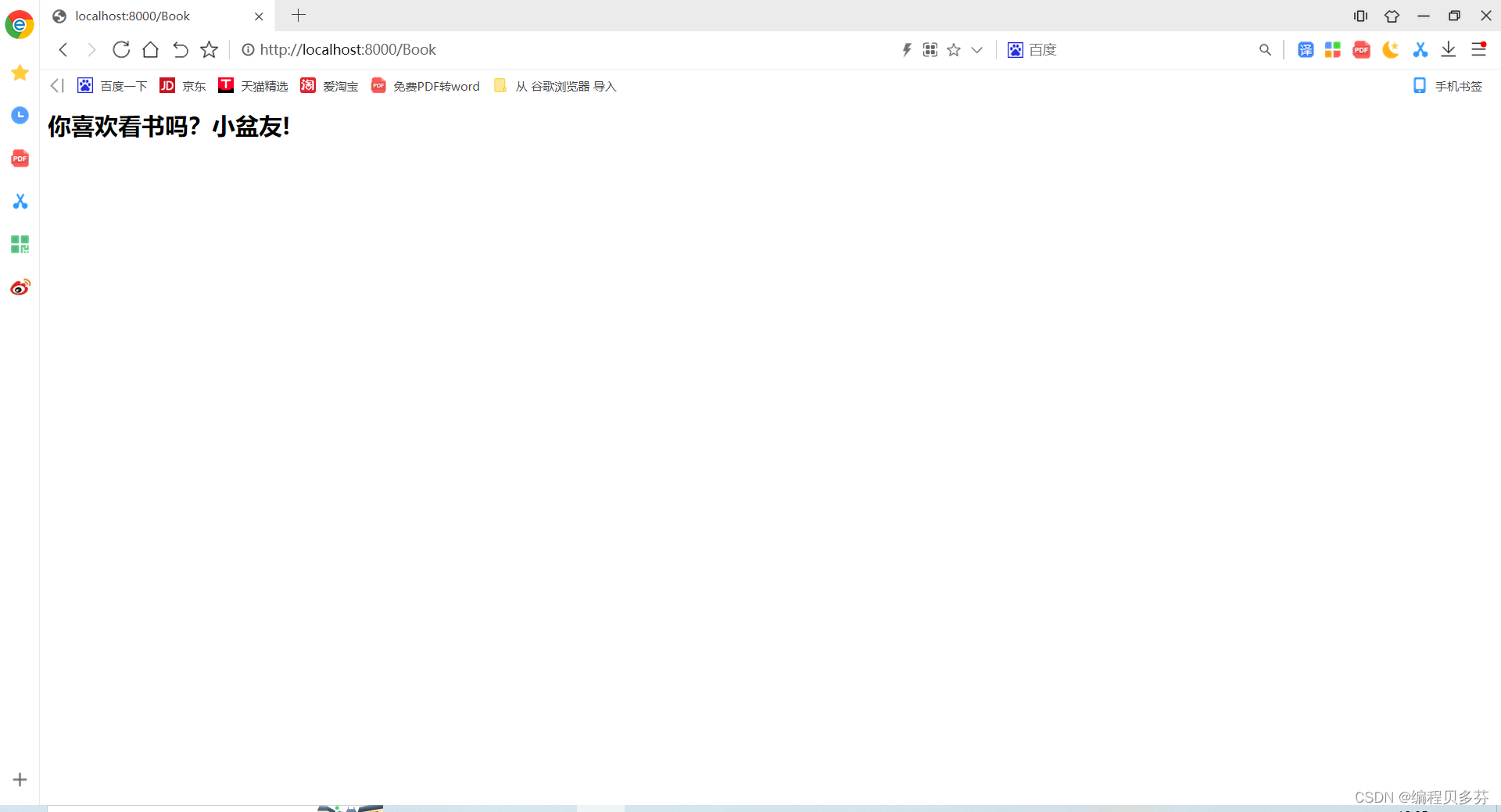
return [bytes("<h2>你喜欢看书吗?小盆友! </h2>", encoding='utf-8')]
#用户访问的url在environ中
#写一个路由分发器,用于获取路由地址
def url_dispach():
urls={
'/Pig':Pig,
'/Book':Book
}
return urls
def run_server(environ,start_response):
print('我又来了!',environ)
#该语句是需要输出的内容!
#首先我们要拿到所有的url
url_list=url_dispach()
#获取用户指定的url接口,是从众多environ中获取PATH_INFO变量下的url接口
request_url=environ.get('PATH_INFO')
print('request url',request_url)
if request_url in url_list:
#这样子写是因为方法在我们上面所设置的列表当中,通过列表调用键值对的形式来调用函数
fun_data=url_list[request_url](environ,start_response)
#上面这种形式因为return的是一种
return fun_data
else:
start_response("404 OK", [('Content-Type', 'text/html;charset=utf-8')])
return [bytes("<h1>404!! 找不到该网页!! </h1>", encoding='utf-8')]
# start_response("200 OK", [('Content-Type', 'text/html;charset=utf-8')])
# return [bytes("<h2>Hello </h2>",encoding='utf-8')]
s=make_server('localhost',8000,run_server)
s.serve_forever()
运行结果图如下: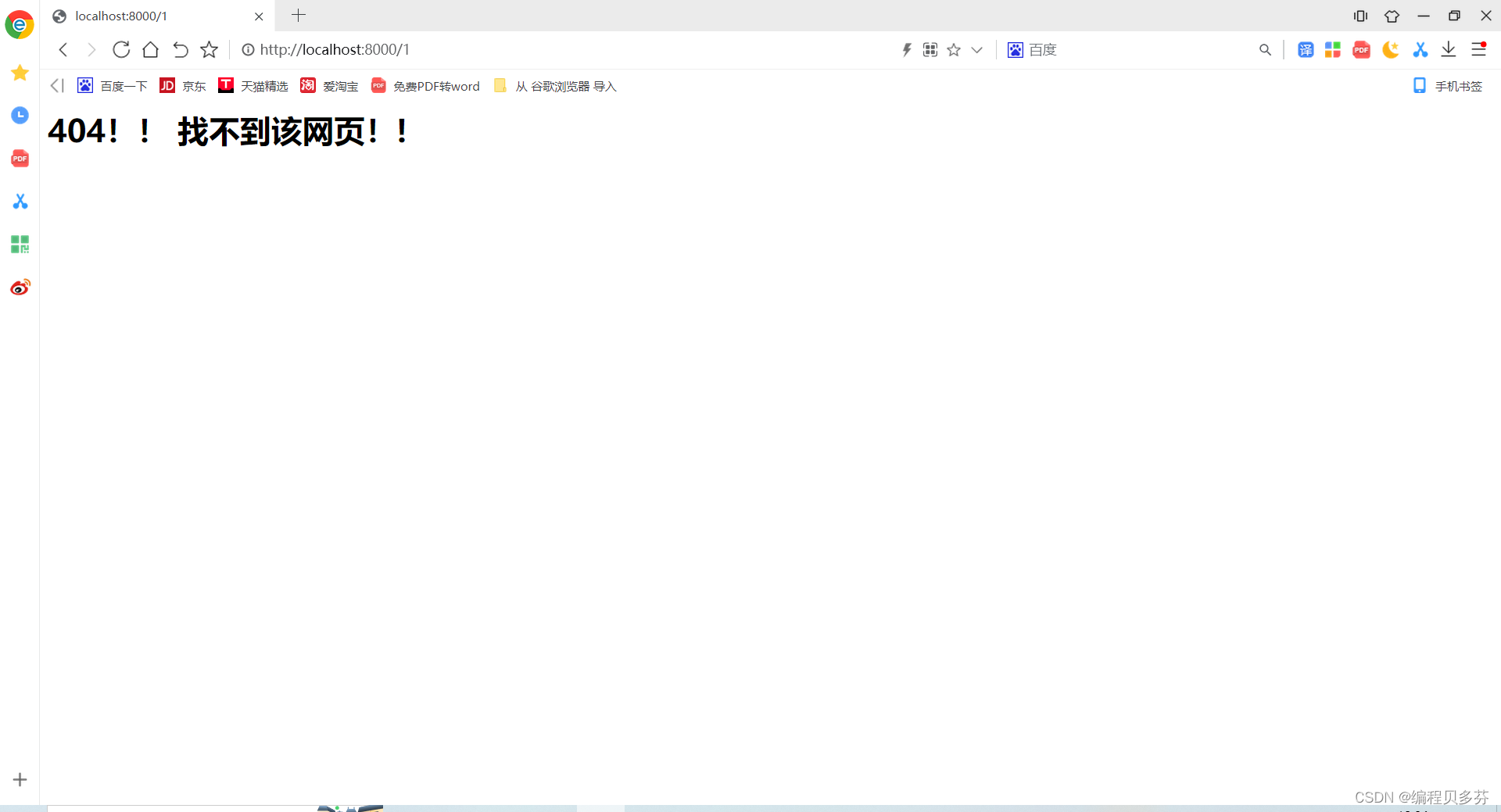
三、用Wsgi实现支持多url和图片的web服务器
难点主要在于,文件的读写操作!!和图片路径的获取!
主要代码也是比较简单的!
import re
import os
from wsgiref.simple_server import make_server
#获取文件的绝对路径
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
def Pig(envirson,response):
print('hello pig')
response("200 OK",[('Content-Type','text/html;charset=utf-8')])
data="""
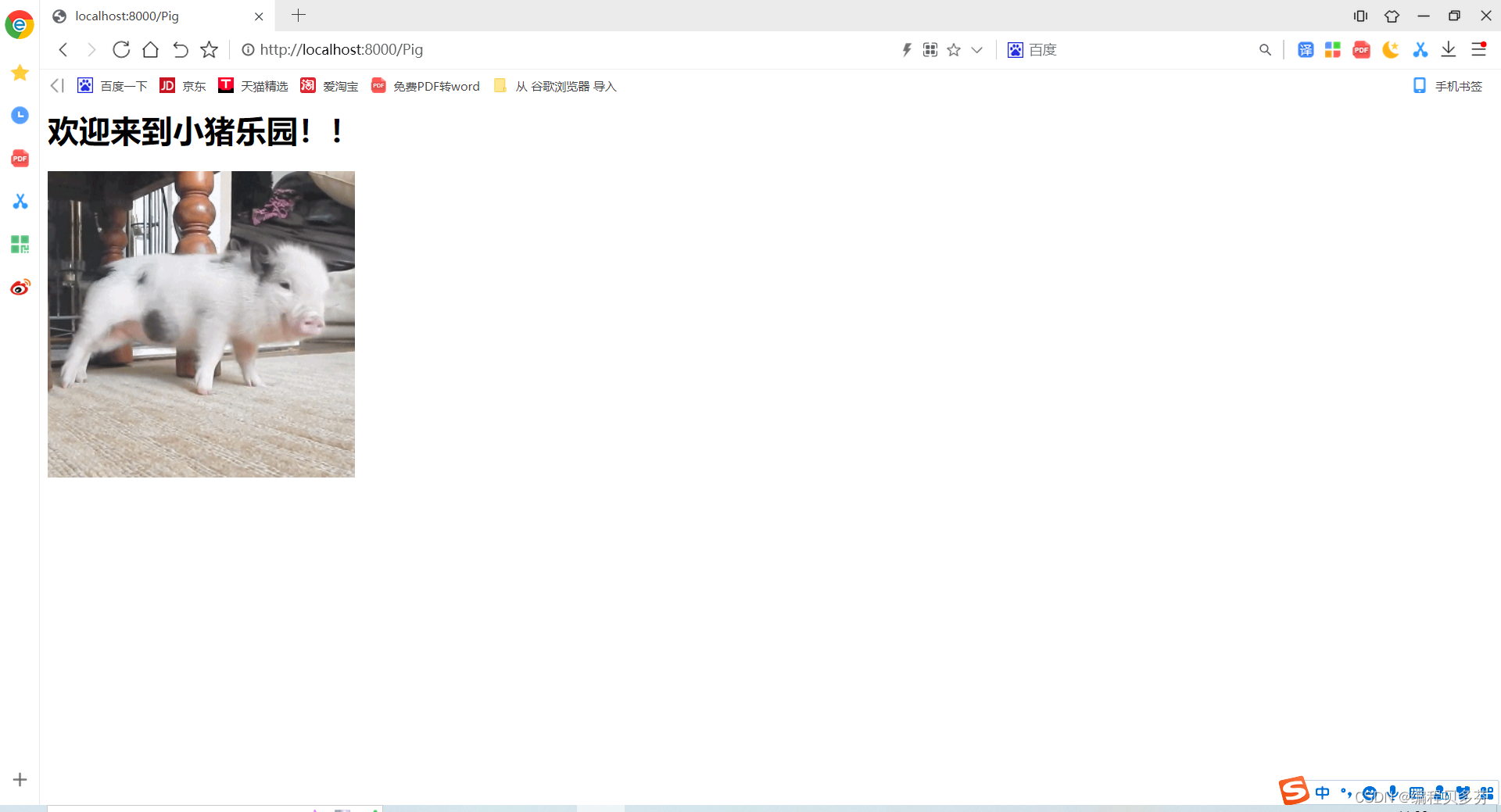
<h1>欢迎来到小猪乐园!!</h1>
<img src="/static/imgs/pig.gif" />
"""
return [bytes(data, encoding='utf-8'),]
def Book(envirson,response):
print('hello book')
response('200 OK',[('Content-Type', 'text/html;charset=utf-8')])
return [bytes("<h2>Hello 多读书呀小盆友!!</h2>", encoding='utf-8')]
def url_dispatch():
urls={
'/Pig':Pig,
'/Book':Book
}
return urls
#找到文件并且打开文件
def img_handler(request_url):
#获取文件路径
img_path=re.sub('/static','/static_data', request_url)
img_abs_path="%s%s" %(BASE_DIR,img_path)
print('BASE',BASE_DIR)
print(img_abs_path)
#导入os模块,并且调用os模块打开和获取相应文件
if os.path.isfile(img_abs_path):
print('---有内容')
f=open(img_abs_path,'rb')#以rb形式来打开文件
data=f.read()#读取和展示文件
#返回给浏览器
return [data,0]#创建一个列表,如果文件存在,则返回0
return [None,1]#如果不存在则返回1
def run_server(environ,start_response):
print('hahhahah',environ)
url_list = url_dispatch() #拿到所有的url
request_url = environ.get("PATH_INFO")
print('request url',request_url)
if request_url in url_list:
func_data = url_list[request_url](environ,start_response)
return func_data #真正返回数据给用户
elif request_url.startswith("/static/"):# 代表 是图片
img_data,img_status = img_handler(request_url)
if img_status == 0 : #图片有内容
start_response("200 OK ", [('Content-Type', 'text/jpeg;charset=utf-8')])
return [img_data,]
else:
start_response("404 ",[('Content-Type','text/html;charset=utf-8')])
return [bytes('<h1 style="font-size:50px">404, Page not found!</h1>',encoding="utf-8"),]
#书写返回浏览器的文本格式(文本,超链接,图片)
# response('200 OK',[('Content-Type','text/html;charset=utf-8')])
# return [bytes("<h2>Hello 运用wsgi去实现应该web服务器!!</h2>",encoding='utf-8')]
s=make_server('localhost',8000,run_server)
s.serve_forever()
展示图如下:
















 1337
1337











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











