






transformer与beter
入门1:从编解码和词嵌入开始,一步一步理解Transformer,注意力机制(Attention)的本质是卷积神经网络(CNN) - YouTube
中英文翻译大概原理就是:把中文的token和英文的token,分别投射到对应的潜空间中(embeding),之后将两个潜空间进行统一
潜空间里面每个位置代表不同的语义,如果单看位置上面的值,不能获得详细的语义。需要将所有特征(也就是不同位置的语义)合起来看,才能代表详细的语义,同理图片的特征也是一样,需要将不同通道(也就是不同特征)上面的点合起来。才能知道图片该店的具体含义

解码和编码器含义
主要是解的码:是语义也就是上下文关系

如图,相当于存在一种上下文语义密切的话,在高维空间具有更近的模长之类的关系
tokizer标记器和one-hot独热编码
实现对token(也就是单位词)做数字化
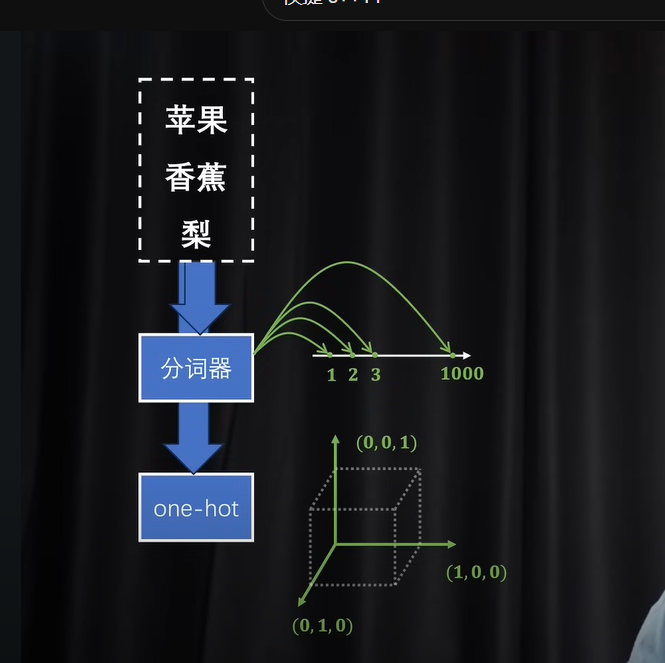
大概关系就是前者给id,后者给种类标记
但不过这种简单的表示方法不能产生语义关系,也就是
假设手机是(1)苹果是2.这样虽然很近,但其实没有具体的语义关系
前者信息过于密集无法区分语义,后者信息过于稀疏,每个token基本都占据了一个维度
编码解码–语义较好的维度空间
这样既能利用好高维度空间也能利用空间的长度
因此想法有两个:
想法一:使用分词器(tokzier)获得,密集信息,在进行升高维度
想法二:使用独热编码(one-hot)获得稀疏信息,在进行降低维度(压缩数据)
主要是运用想法二的思想
矩阵相乘–空间变换

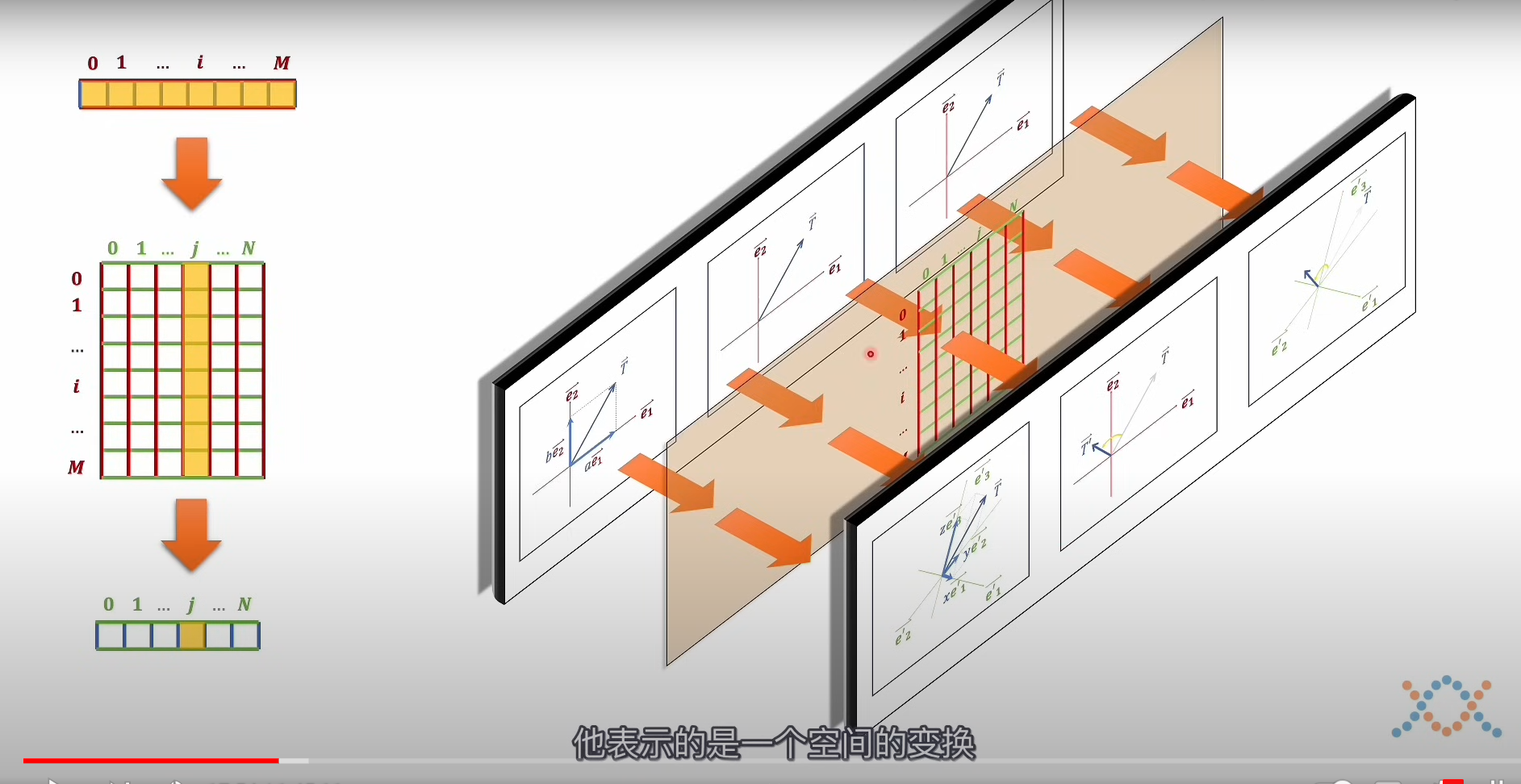
如果只是向量和矩阵的乘法,那么只会出现向量在新的坐标系下面的旋转和伸缩,也就是空间的变换,但不过值任然是一一对应的
如果采用矩阵相乘这个二次型的方式,就会像函数一样,向量出现形状的变化
下图演示
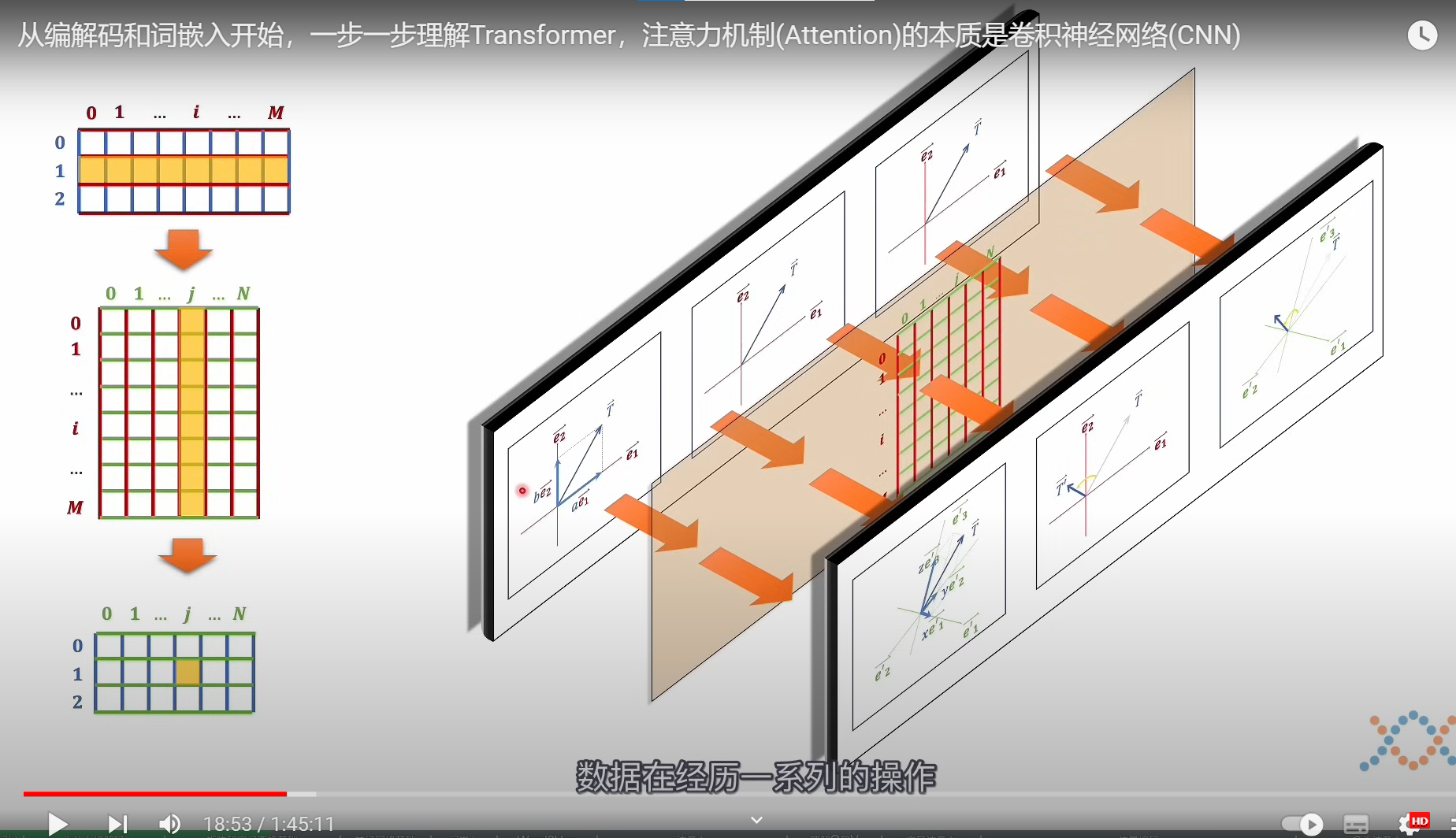
代表三个向量,也就是三个数据经过空间变换(矩阵),得到新空间的数据,所以规则(矩阵)和数据不能够进行颠倒
编码理解
先把一个文本里面的token(词元)变成独热码(获取稀疏信息),之后在进行降维(获取词元之间的语义关系(这里可以采用之前理解的距离))
总结:这个相当于把输入的一句话根据语义映射到到高维(独热编码),在把它投射到低维空间,这个也就是嵌入过程(embeding)(这个嵌入维度也就是潜空间)
相当于一个token被映射到潜空间之后,向量上面的位置,代表了不同的语义
例如

潜空间里面向量的不同值代表是该语义的程度,我们无法人为可知
如何构造降维的嵌入矩阵–实现到达潜空间
word2vec下面的:
第一个CBOW(邻字模型)

相当于用上下文的token(词元)(可能需要先升维度——独热编码),通过嵌入矩阵,获得嵌入向量,之后进行相加,将结果作为中间词元的嵌入向量,这样就可以于真实的词元向量进行比较了,进行修正
第一个跳字模型同理

最终的目的就是为了获得嵌入矩阵
转化为神经网络如下

只需要训练一个w即可,因为解码过程是一个逆过程,但实际过程好像是都要训练
不需要激活函数,因为只是对向量进行见简单的相加和分解
上面是基础,下面是transformer正文

核心是如何将得到的潜空间(embeding),去理解它的语义–注意力机制
自注意力机制
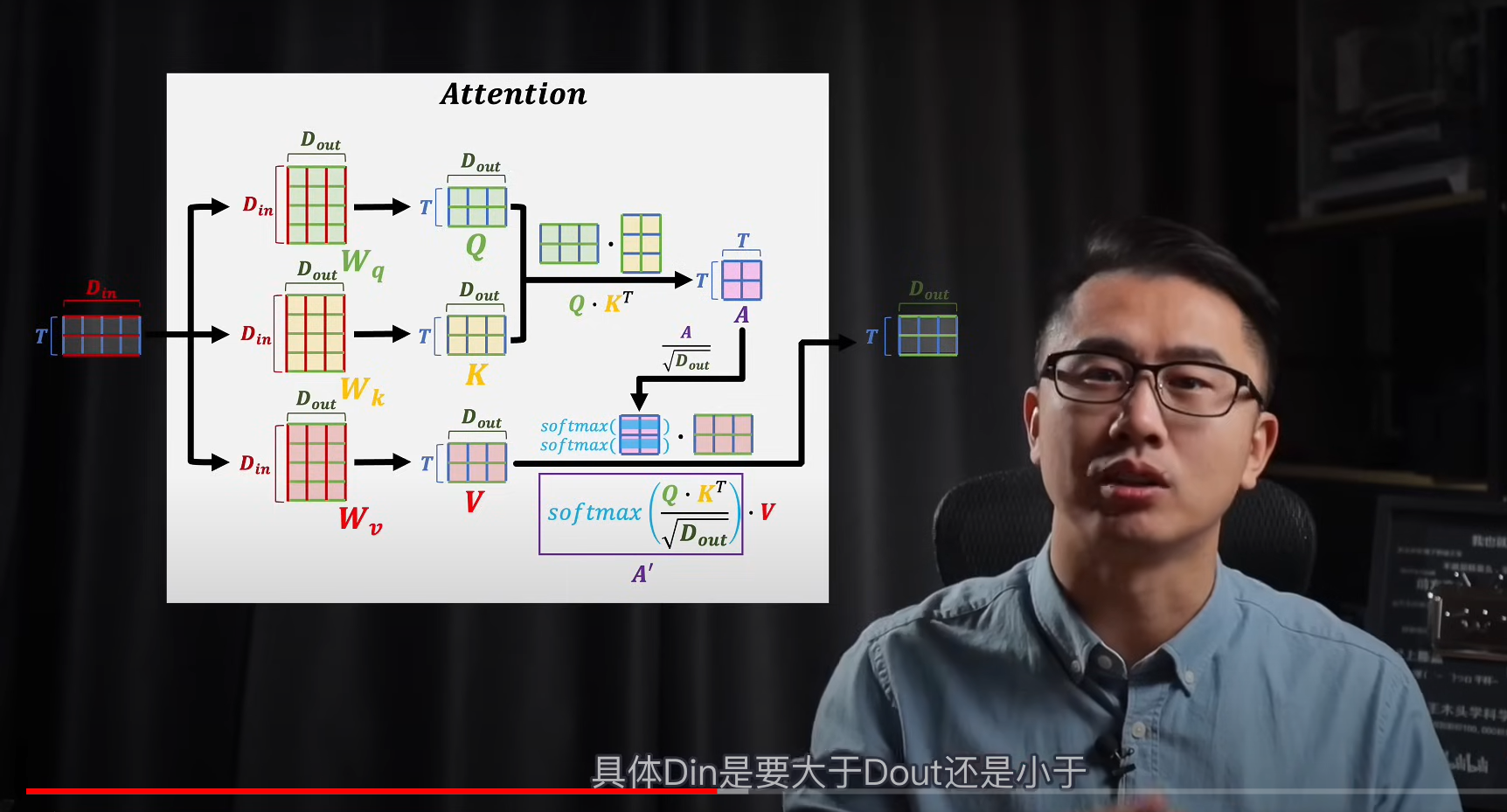
由于我们需要上下文语义的关系,输入到注意力那块的时候,不能是单个词的词嵌入向量,需要输入多个(T个,嵌入向量维度是Din)
- 按照原理,输入的词向量组,需要和三个矩阵进行空间变化得到KQV,三个状态矩阵
- 之后将K,Q其中一个转置相乘,得到T X T的矩阵,之后对改矩阵进行缩放,其实就是缩放它的方差到1上面
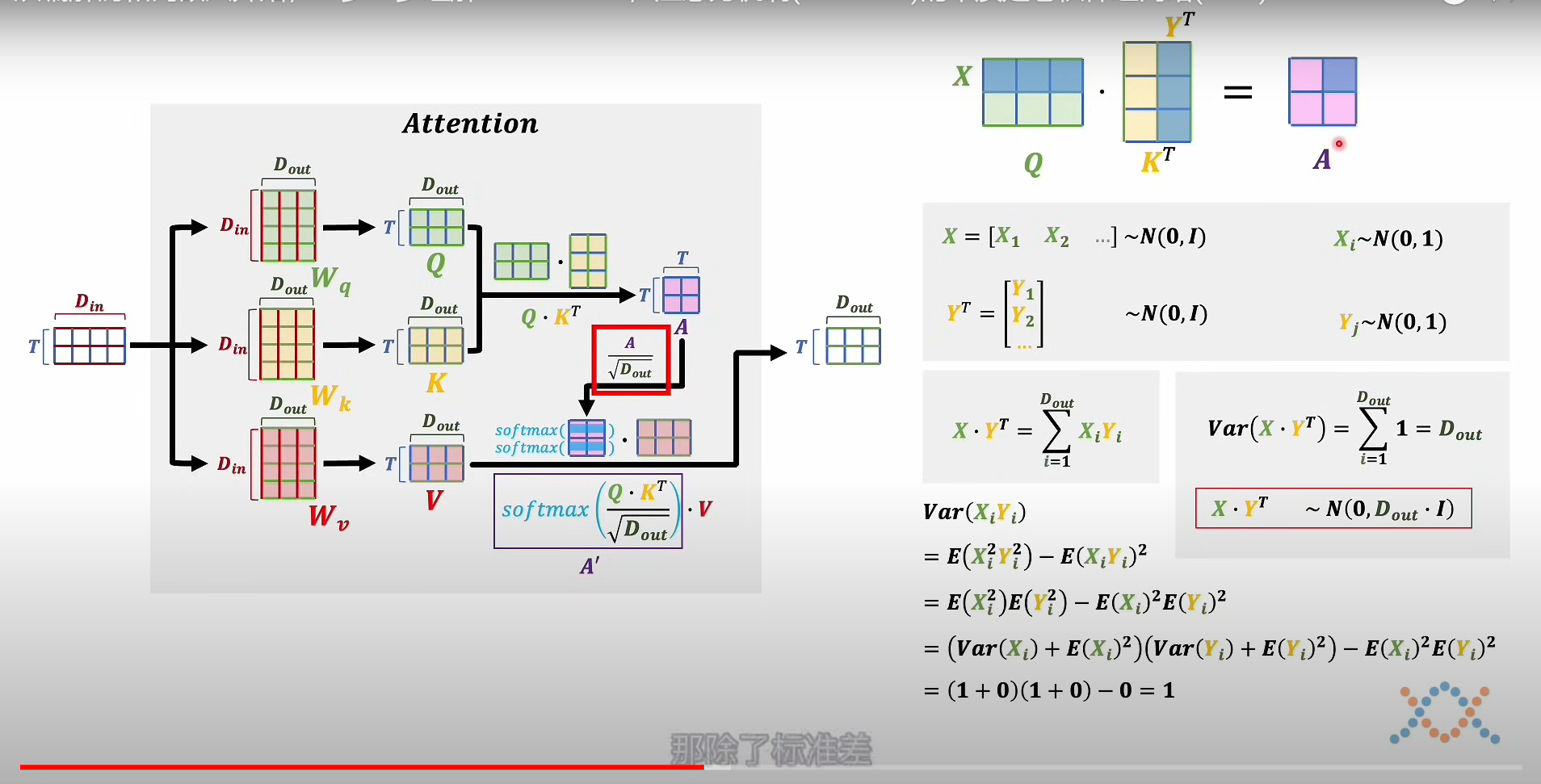
- 之后缩放的矩阵进行softmax,这里是按照行进行概率归一(这样获得了注意力分数),最后将其和V相乘,得到输出注意力结果T X Dout
总结:这个注意力分数相当于是该词在上下文关联的修改系数,而V就是该词在嵌入空间的客观语义。
注意力分数–上下文修正系数
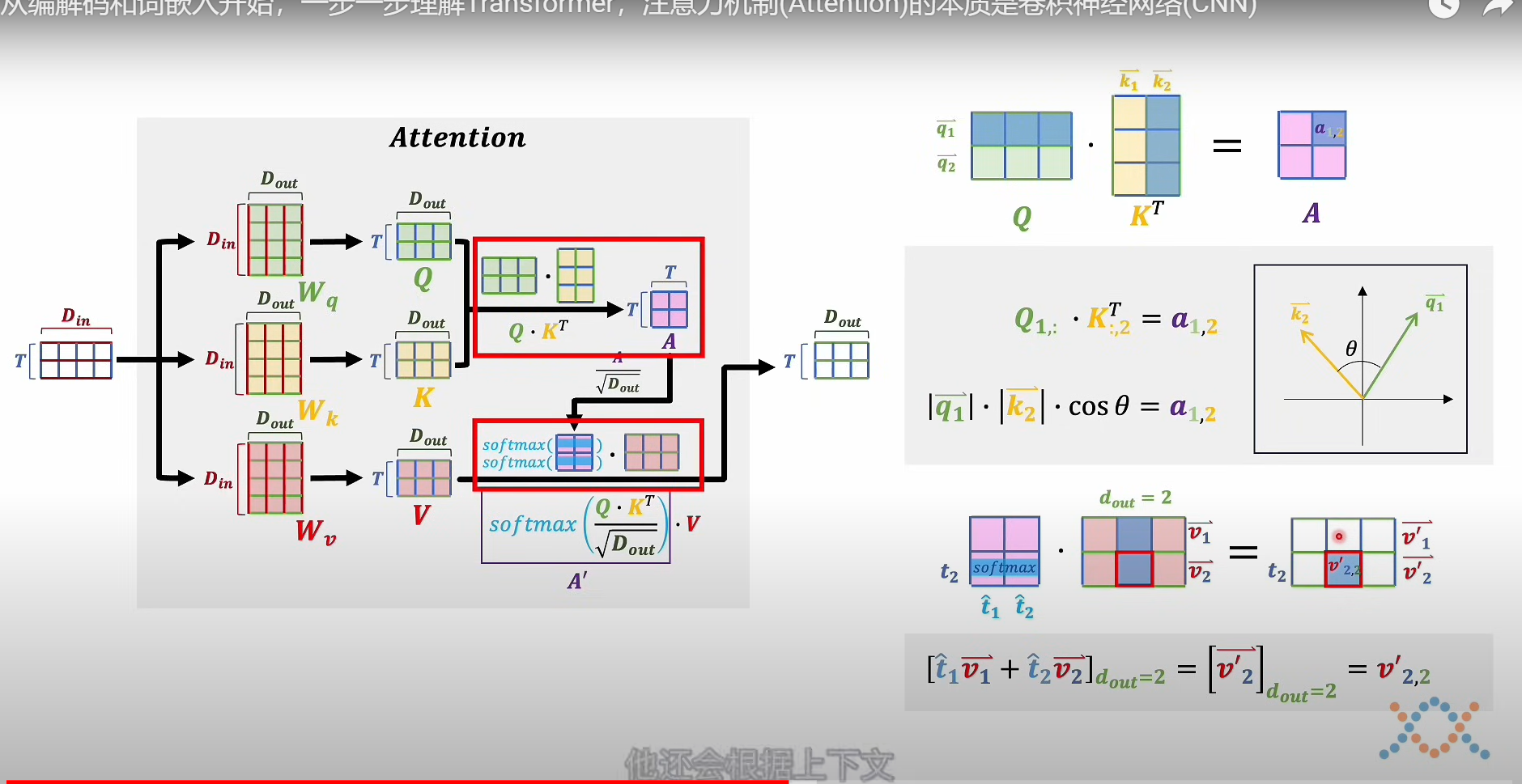
转置相乘得到的矩阵是:所有词向量之间的关联性,之后被转化为概率权重(上下文关系),最后用来修正次元的客观语义
为什么需要KQ两个矩阵,并且还是转置,进行相乘?

因为这样就构造了,二次型,能够更好的表达模型的复杂情况,更好的理解语义
需要K和Q,也是因为在上下文语义中,我们需要区分该词的设定语义和表达语义,也就是前后关系,所以猜测需要两个矩阵,KQ
交叉注意力机制

相当于拿到解码器的主观语义里面的设定语义,与解码器的KV,进行操作
其实是相当于有了一份主观语义里面设定语义的参考资料,相当于不需要理解主观语义,学起来很被动,但在机器翻译上面就没有问题
绝对位置编码–对输入的数据进行修饰
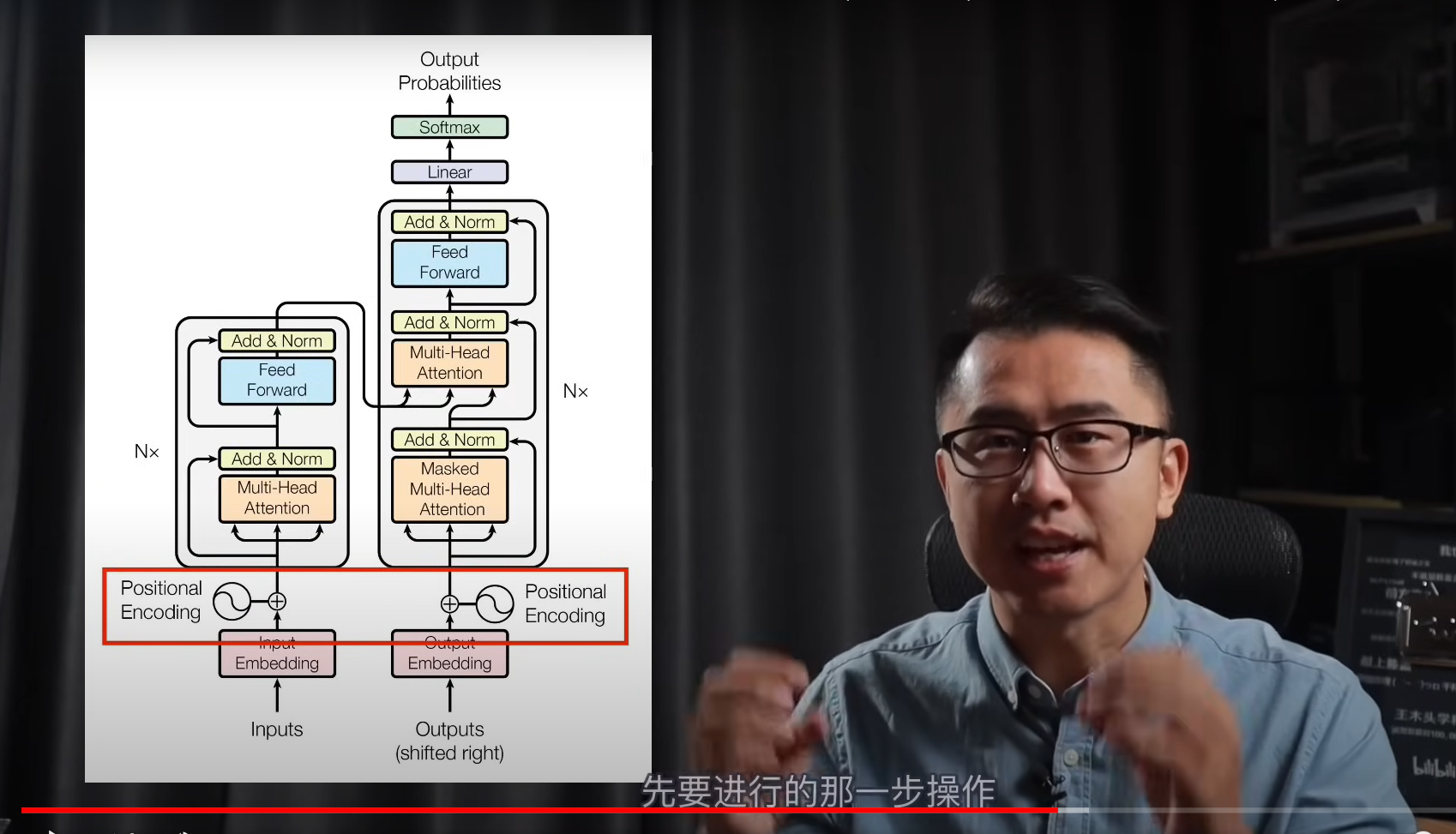
将0-n这些数字,通过傅里叶变换到相同嵌入向量的维度

不同语义(特征)之间相互正交,且不同token之间的编码也不相同
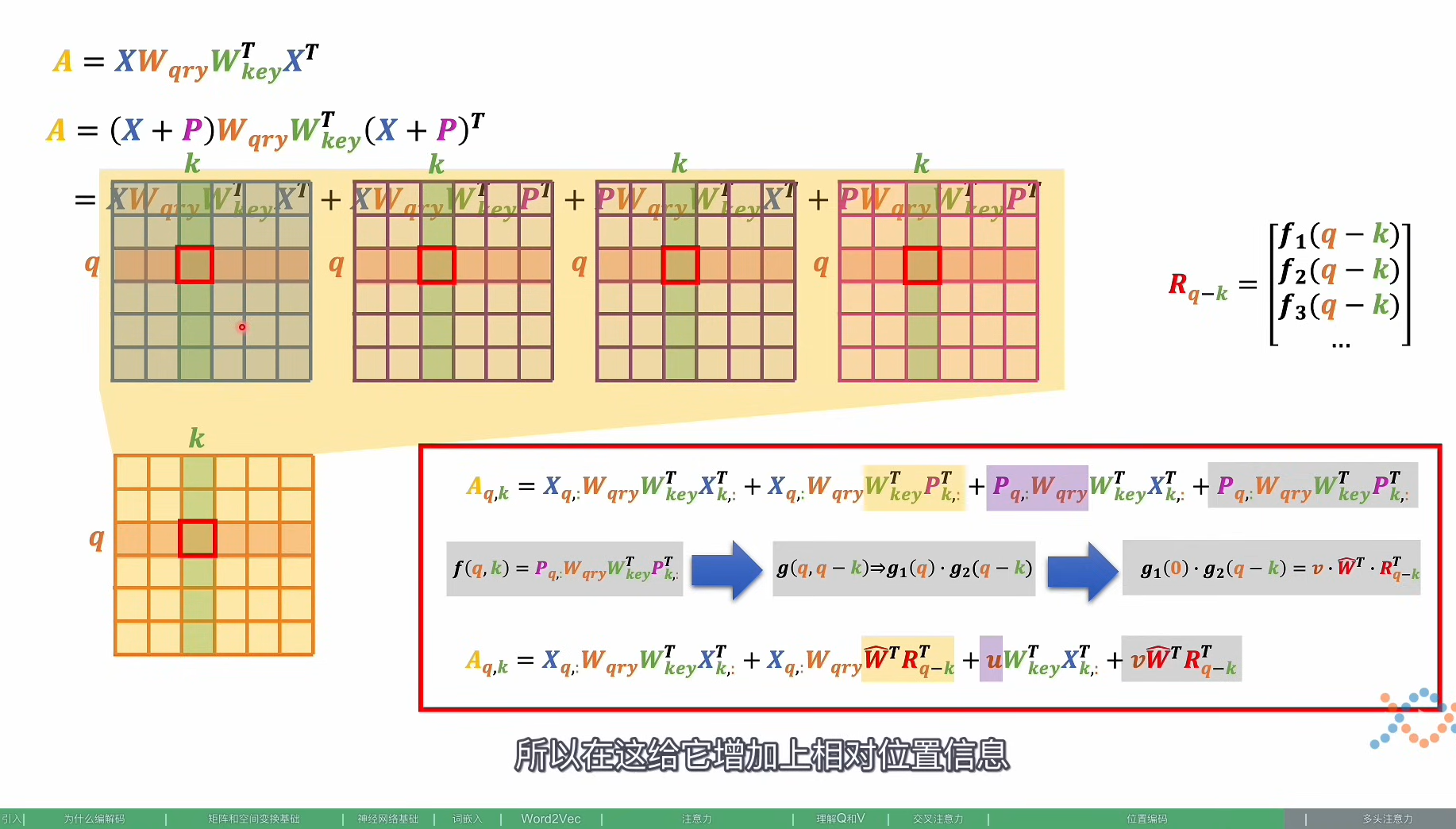
相对位置编码–修饰在注意力分数上面
多头注意力机制

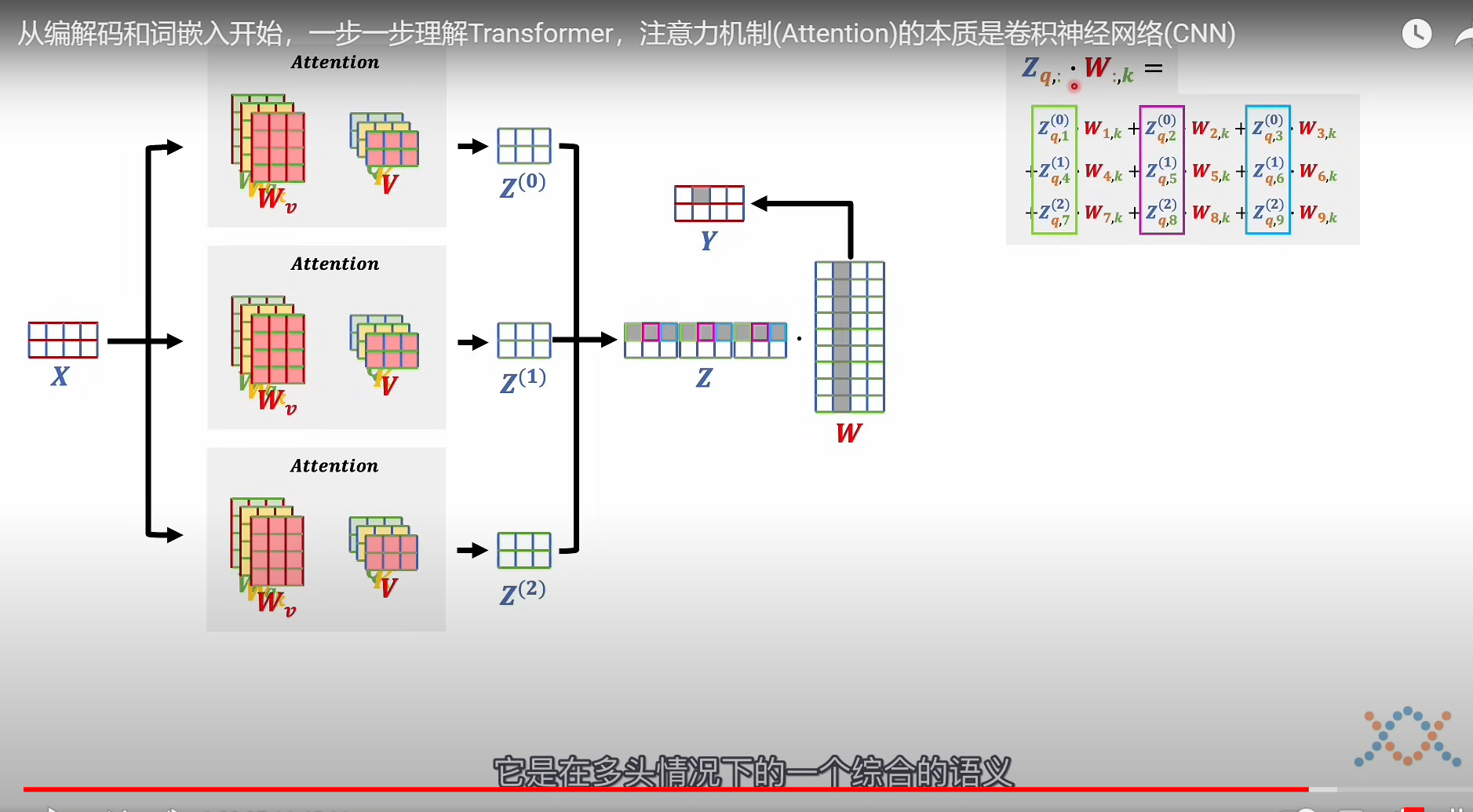
大概就是一个token(嵌入向量)进去,经过多头,一个小语义会被学习到更多相似的语义或者更大的跨度,最后通过多头相加综合起来,相当于学习到相似语义的综合语义
解码器掩码—正则残差
在推理过程需要屏蔽掉之后词语的影响

屏蔽掉一个词之后的注意力分数
正测残差
把数据加起来在正则化
残差能够学习到变化的程度
模型框架

每一个解码器的输出,都要拿着解码器的参考去更新差异
推理部分
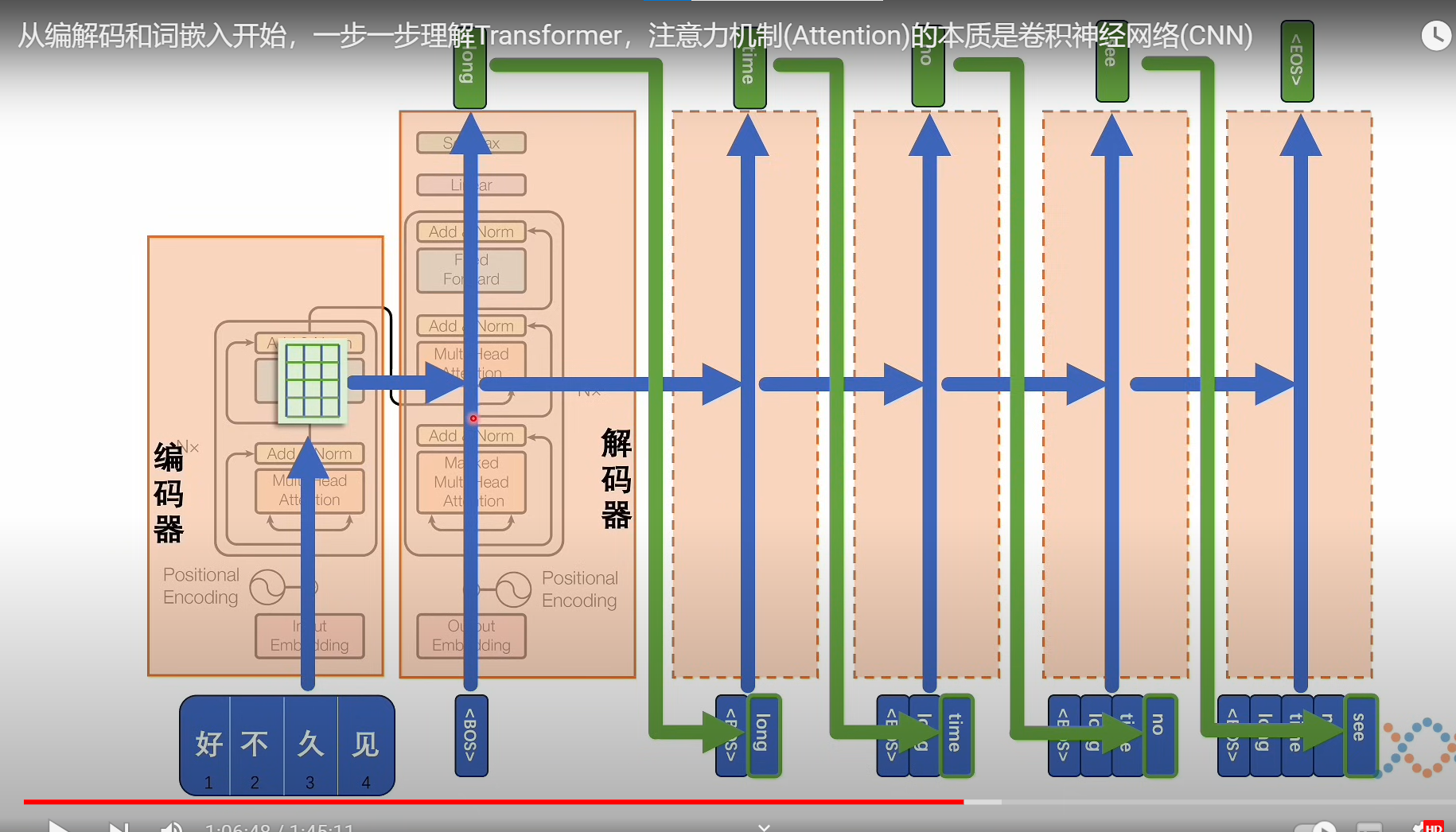
可能最后的softmax部分的输出是一个,形状确实不变都是,T X Dout,解码器部分提供的是K















 3982
3982











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









