







数据结构专升本学习,哈夫曼树
前言
前面我们学习了,树,二叉树,线索二叉树的逻辑,和简单运算,说简单吧不简单,说难吧又还行,对于我们基础较差的同学有些知识知道了解就好了,不必要去深究,好了,讲正事了,今天我们要学的是哈夫曼树,哈夫曼树又被称为最优二叉树,哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近,在计算机中编码中应用广泛,特别是压缩,使用哈夫曼树的逻辑可以使我们的程序运行速度提升,是对项目的一种比较好的优化方式。
每日一遍,防止颓废

1.哈夫曼树的定义
给定N个权值作为N个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。(假设你有10000名学生,成绩是90分以上,采用图一你需要跑40000次,采用图二需要跑20000次,优化了,当然我们并不是所有学生都是90分以上或者60分以下,我们只要得到那个阶段多,我们就作为根,这就是哈夫曼树逻辑)

1、路径和路径长度
在一棵树中,从一个结点往下可以达到的孩子或孙子结点之间的通路,称为路径。通路中分支的数目称为路径长度。若规定根结点的层数为1则从根结点到第L层结点的路径长度为L-1。(讲人话就是:路径:从树中这个结点到另一个结点它们之间的分支构成两个结点的路径,路径长度:就是两个结点路径上的分支数)

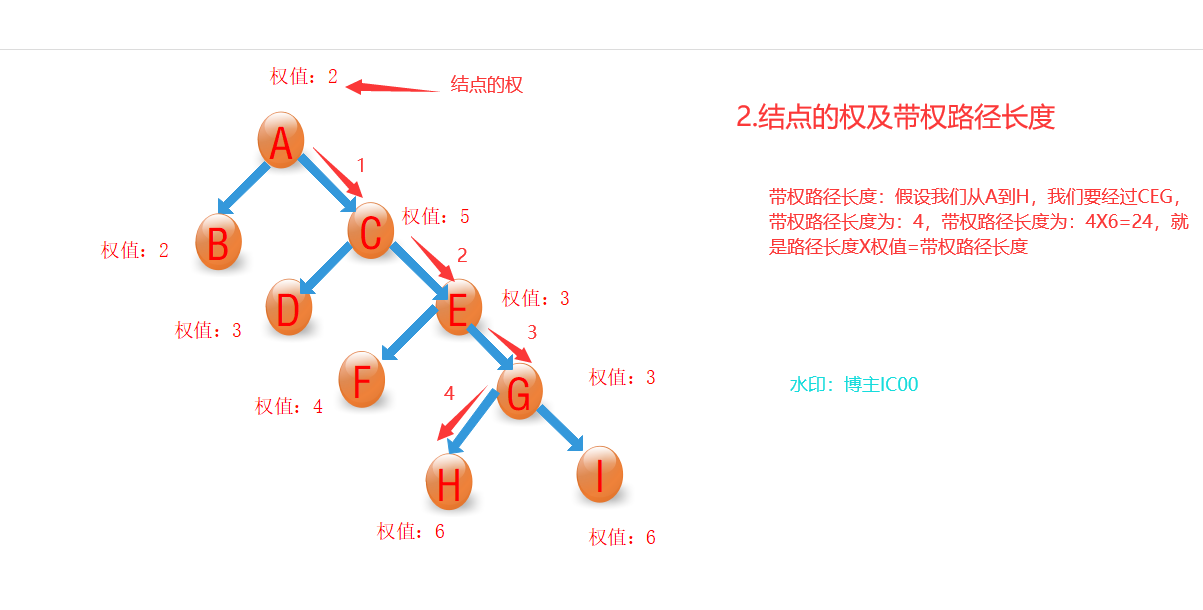
2、结点的权及带权路径长度
若将树中结点赋给一个有着某种含义的数值,则这个数值称为该结点的权。结点的带权路径长度为:从根结点到该结点之间的路径长度与该结点的权的乘积。(讲人话就是:这个结点还有一个值我们称为权值,然后带权路径长度就是路径长度和这个结点相乘)
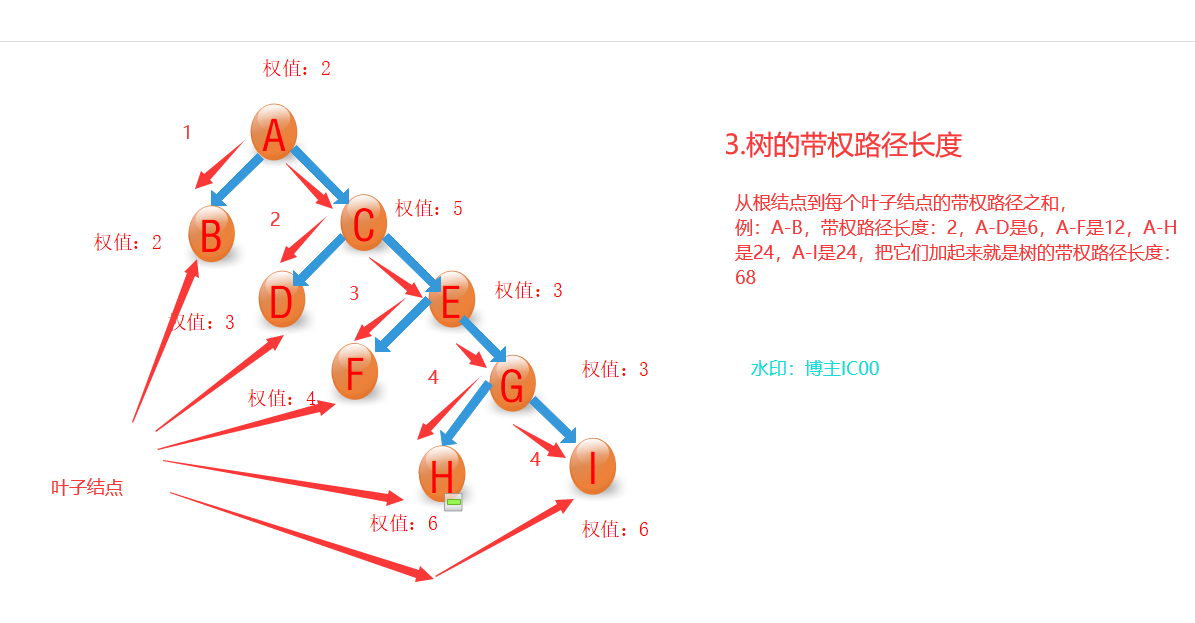
3、树的带权路径长度
树的带权路径长度规定为所有叶子结点的带权路径长度之和,记为WPL。讲人话:(就是这棵树从根结点到每个叶子结点的带权路径之和)(注:哈夫曼树是带权路径最短的树,也称最优树,因为有些题目给我们是叶子节点数需要我们构造最优树,一般都是把权值最大的放在离根近的结点)
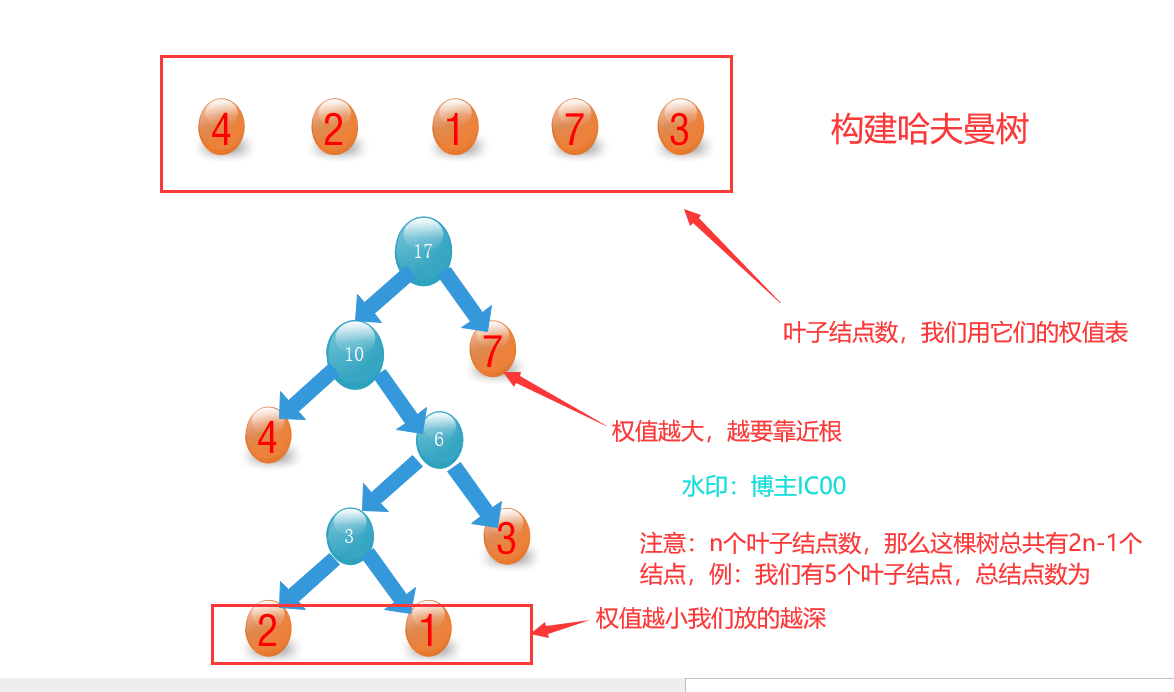
2.构造哈夫曼树
假设有n个权值,则构造出的哈夫曼树有n个叶子结点。 n个权值分别设为 T1、T2、…、Tn,则哈夫曼树的构造规则为:
(1) 将T1、T2、…,Tn看成是有n 棵树的森林(每棵树仅有一个结点);
(2) 在森林中选出两个根结点的权值最小的树合并,作为一棵新树的左、右子树,且新树的根结点权值为其左、右子树根结点权值之和;
(3)从森林中删除选取的两棵树,并将新树加入森林;
(4)重复(2)、(3)步,直到森林中只剩一棵树为止,该树即为所求得的哈夫曼树(讲人话就是:从底部开始建立,每次找一个最小的权值,和前面已经组合好的形成新的二叉树,直到所有叶子结点用完,并且是一棵二叉树)
typedef struct{//使用顺序存储结构
int weight;//权值表示
int parent,lch,rch;//parent表示双亲,lch左孩子,rch右孩子
}HTNode,*HUffmanTree;
由于时间关系具体实现代码就不解释了,如果你是专升本学习,了解一下就可以了,因为这个知识不会深究。
3.哈夫曼编码
哈夫曼编码具有广泛的应用,利用哈夫曼树构造的用于通信的二进制编码称为哈夫曼编码。用给定的若干字符的频度为权值生成哈夫曼树,并在每个叶子上注明对应的字符。树中从根到每个叶子都有一条路径,对路径上的各分支约定指向左子树根的分支表示“0”码,指向右子树的分支表示“1”码,取每条路径上的“0”或“1”的序列作为和各个叶子对应的字符的编码,这就是哈夫曼编码。

注:从哈夫曼编码看出,对于n个字符,构造它们的哈夫曼编码,没有一个字符的哈夫曼编码是另一个字符的哈夫曼编码的前缀
总结
数据结构树方面的知识博主差不多就介绍完了,哈夫曼树其实对于学生学习博主这篇文章就足够了,学校大多数只是简单过一下,让你知道有这么个东西,因为不是很重要,看了博主画的图应该会很好理解,理解就可以了,大多数的资料也只是片面上的东西。好了,创作不易,亲,点赞关注评论收藏哦!!!爱你哟!!!


















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











