说起来 , Python就是包裹在一堆语法糖中的字典 .
--Lalo Martins
早期数学游民 , Python专家
没有Python程序不使用字典 , 即使不直接出现在我们自己编写的代码中 , 我们也间接用到了 ,
因为dict类型是实现Python的基石 .
一些Python核心结构在内存中以字典的形式存在 , 比如说类和实例属性 , 模块命名空间 , 以及函数的关键字参数 .
另外 , __builtins__ . __dict__存储这所有内置类型 , 对象和函数 ,
由于字典的关键作用 , Python对字典做了高度优化 , 而且已知在改进 .
Python字典能如此高效 , 要归功于 '哈希表' .
处理字典之外 , 内置类型中set和frozenset也基于哈希表 .
这两种类型的API和运算符比其他流行语言中的集合更丰富 .
具体而言 , Python集合实现了集合论中的所有基本运算 , 包括并集 , 交集 , 子集测试等 .
有了这些运算 , 就能以更具描述性的方式表达算法 , 避免了一层层嵌套循环和测试条件 .
本章涵盖了一下内容 :
• 构建及处理dict和映射的现代句法 , 包括增加的拆包和模式匹配 ;
• 映射类型的常用方法 ;
• 特别处理缺失键的情况 ;
• 标准库中的dict变体 ;
• set和frozenset类型 ;
• 哈希表对几何和字典行为的影响 .
第 2 版的改动大多是对映射类型新功能的介绍 .
• 3.2 节介绍增强的拆包句法和合并映射的不同方式 , 包括自Python3 . 9 开始受dict支持的 | 和 | = 运算符 .
• 3.3 节说明如何使用Python3 . 10 引入的match / case句法处理映射 .
• 3.6 .1 节现在关注的是dict和OrderedDict之间微小却不可忽略的差异 ,
毕竟自Python3 . 6 起 , dict也能保留键的插入顺序 .
• 新增 3.8 节和 3.12 节 , 讲解dict . keys , dict . items , dict . values返回的视图对象 .
dict和set的底层实现任然依赖于哈希表 , 不过dict的代码有两项重要的优化 , 节省了内存 , 还保留了插入的顺序 .
3.9 节和 3.11 节综述如何合理利用这两种类型 .
接下来几节介绍用于构建 , 拆包和处理映射的高级语法功能 .
其中一些功能在Python中早以出现 , 不过你可能还不知道 .
还有一些功能相对较新 , 例如Python3 . 9 引入的 | 运算符和Python3 . 10 引入的match / case句法 .
先从我们熟悉的功能讲起 .
自Python2 . 7 开始 , 列表推导式和生成器表达式经过改造 , 以适用于字典推导式 ( 以及后文要讲的集合推导式 ) .
'字典推导式' 从任何可迭代对象中获取键值对 , 构建dict实例 .
示例 3 - 1 使用字典推导式根据同一个元组列表构建两个字典 .
>> > dial_codes = [
. . . ( 880 , 'Bangladesh' ) ,
. . . ( 55 , 'Brazil' ) ,
. . . ( 86 , 'China' ) ,
. . . ( 91 , 'India' ) ,
. . . ( 62 , 'Indonesia' ) ,
. . . ( 81 , 'Japan' ) ,
. . . ( 234 , 'Nigeria' ) ,
. . . ( 7 , 'Russia' ) ,
. . . ( 1 , 'United States' ) ,
. . . ]
>> > country_dial = { country: code for code, country in dial_codes}
>> > country_dial
{ 'Bangladesh' : 880 , 'Brazil' : 55 , 'China' : 86 , 'India' : 91 , 'Indonesia' : 62 ,
'Japan' : 81 , 'Nigeria' : 234 , 'Russia' : 7 , 'United States' : 1 }
>> > { code: country. upper( )
. . . for country, code in sorted ( country_dial. items( ) )
. . . if code < 70 }
{ 55 : 'BRAZIL' , 62 : 'INDONESIA' , 7 : 'RUSSIA' , 1 : 'UNITED STATES' }
习惯列表推导式之后 , 自然能理解字典推导式 .
即使现在不理解也没关系 , 推导式句法以及被人们广泛使用 , 熟练掌握是迟早的事 .
从Python3 . 5 开始 , 'PEP 448--Additinal Unpacking Generalizations' 在两方面增强了隐射拆包功能 .
首先 , 调用函数时 , 不止一个参数可以使用 * * .
但是 , 所有键都要是字符串 ( 关键字参数 ) , 而且在所有参数中是唯一的 ( 因为关键字参数不可重复 ) .
>> > def dump ( ** kwargs) :
. . . return kwargs
. . .
>> > dump( ** { 'x' : 1 } , y= 2 , ** { 'z' : 3 } )
{ 'x' : 1 , 'y' : 2 , 'z' : 3 }
其次 , * * 可以在dict字面量中使用 , 同样可以多次使用 .
>> > { 'a' : 0 , ** { 'x' : 1 } , 'y' : 2 , ** { 'z' : 3 , 'x' : 4 } }
{ 'a' : 0 , 'x' : 4 , 'y' : 2 , 'z' : 3 }
这种情况下允许键重复 , 后面的键覆盖前面的键 , 比如本例中x映射的值 .
这种句法也可以用于合并映射 , 但是合并映射还有其他方式 . 请继续往下读 .
Python3 . 9 支持使用 | 和 | = 合并映射 .
这不难理解 , 因为二者也是并集运算符 .
| 运算符创建一个新映射 .
>> > d1 = { 'a' : 1 , 'b' : 3 }
>> > d2 = { 'a' : 2 , 'b' : 4 , 'c' : 6 }
>> > d1 | d2
{ 'a' : 2 , 'b' : 4 , 'c' : 6 }
通常 , 新映射的类型与左操作数 ( 本例中的d1 ) 的类型相同 .
不过 , 涉及用户定义的类型是 , 也可能与第二个操作数的类型相同 .
这背后涉及运算符重载规则 , 详见第 16 章 .
如果想就地更新现有映射 , 则使用 | = .
续前例 , 当时d1没有变化 , 但是现在变了 .
>> > d1
{ 'a' : 1 , 'b' : 3 }
>> > d1 | = d2
>> > d1
{ 'a' : 2 , 'b' : 4 , 'c' : 6 }
* -------------------------------------------------------------------------------------------- *
如果你想要维护使用Python3 . 8 或更早版本编写的代码 ,
请看 'PEP 584-Add Union Operators To dict' 中的 'Motivation' 一节 , 那里简单总结了合并映射的其他方式 .
* -------------------------------------------------------------------------------------------- *
下面来看如何使用模式匹配处理映射 .
match / case语法的匹配对象可以是映射 .
映射的模式看似dict字面量 , 其实能够匹配collections . abs . Mapping的任何具体子类或虚拟子类 . ①
( 注 1 : 虚拟子类是调用抽象类的 . register ( ) 方法注册的类 , 详见 13.5 .6 节 .
通过Python或C语言API实现的类型 , 如果设定了Py_TPFLAGS_MAPPING标记位 , 那么也能匹配 . )
第二章只重点讲了序列模式 , 其实不同类型的模式可以组成嵌套 .
模式匹配是一种强大的工具 , 借助析构可以处理嵌套的映射和序列等结构化记录 .
我们经常需要从JSON API和具有半结构化模式的数据库 ( 例如MongoDB , EdgeDB或PostgresSQL )
中读取这类记录 , 示例 3 - 2 就是一例 .
get_creators函数有一些简单的类型注解 , 作用是明确表明参数为一个dict , 返回值是一个list .
def get_creators ( record: dict ) - > list :
match record:
case { 'type' : 'book' , 'api' : 2 , 'authors' : [ * names] } :
return names
case { 'type' : 'book' , 'api' : 1 , 'author' : name} :
return [ name]
case { 'type' : 'book' } :
raise ValueError( f"Invalid 'book' record: { record!r } " )
case { 'type' : 'movie' , 'director' : name} :
return [ name]
case _ :
raise ValueError( f'Invalid record: { record!r } ' )
通过示例 3 - 2 可以看出处理半结构化数据 ( 例如JSON记录 ) 的几点注意事项 :
• 包含一个描述记录种类的字段 ( 例如 'type' : 'movie' ) ;
• 包含一个标识模式版本的字段 ( 例如 'api' : 2 ) , 方便公开API版本更迭 ;
• 包含处理特定无效记录 ( 例如 'book' ) 的case子句 , 以及兜底case子句 .
下面在doctest中测试一下get_creators函数 .
>> > b1 = dict ( api= 1 , author= 'Douglas Hofstadter' ,
. . . type = 'book' , title= 'Godel, Escher, Bach' )
>> > get_creators( b1)
[ 'Douglas Hofstadter' ]
>> > from collections import OrderedDict
>> > b2 = OrderedDict( api= 2 , type = 'book' ,
. . . title= 'Python in a Nutshell' ,
. . . authors= 'Martell Ravenscroft Holden' . split( ) )
. . .
>> > get_creators( b2)
[ 'Martell' , 'Ravenscroft' , 'Holden' ]
>> > get_creators( { 'type' : 'book' , 'pages' : 770 } )
Traceback ( most recent call last) :
. . .
ValueError: Invalid 'book' record: { 'type' : 'book' , 'pages' : 770 }
>> > get_creators( 'Spam, spam, spam' )
Traceback ( most recent call last) :
. . .
ValueError: Invalid record: 'Spam, spam, spam'
注意 , 模式中键的顺序无关紧要 .
即使b2是一个OrderedDict , 也能作为匹配对象 .
与序列模式不同 , 就算只有部分匹配 , 映射模式也算成功匹配 .
在上述doctest中 , b1和b2两个匹配对象中都有 'title' 键 , 尽管任何 'book' 模式中都没有这个键 , 但依然可以匹配 .
没有必要使用 * * extra匹配多出来的键值对 , 倘若你想把多出的键值对捕获到一个dict中 ,
可以在一个变量前面加上 * * , 不过必须放在模式最后 . * * _是无效的 , 纯属于画蛇添足 .
( 会直接报错 : SyntaxError : invalid syntax , 语法错误 : 无效的语法 . )
下面是一个简答的例子 .
>> > food = dict ( category= 'ice cream' , flavor= 'vanilla' , cost= 199 )
>> > match food:
. . . case { 'category' : 'ice cream' , ** details} :
. . . print ( f'Ice cream details: { details} ' )
. . .
Ice cream details: { 'flavor' : 'vanilla' , 'cost' : 199 }
3.5 节讲解的defaultdict等映射 , 通过__getitem__查找键 ( 即d [ key ] ) 始终成功 .
这是因为倘若缺少一项 , 则自动创建 .
对模式匹配而言 , 仅当匹配对象在运行match语句之前以及含有所需要的键才能成功匹配 .
* -------------------------------------------------------------------------------------------- *
模式匹配不会自动处理缺失的键 , 因为模式匹配始终使用d . get ( key , sentinel ) 方法 .
其中 , sentinel是特殊的标记值 , 不会出现在用户数据中 .
* -------------------------------------------------------------------------------------------- *
讲完句法和结构之后 , 接下来研究映射API .
collections . abc模块中的抽象基类和Mapping和MutableMapping描述dict和类似类型的接口 , 见图 3 - 1.
这两个抽象基类的主要作用是确立映射对象的标准接口 , 并在需要广义上的映射对象时为isinstance提供测试标准 .
>> > from collections import abc
>> > my_dict = { }
>> > isinstance ( my_dict, abc. Mapping)
True
>> > isinstance ( my_dict, abc. MutableMapping)
True
* ---------------------------------------------提示------------------------------------------- *
使用isinstance测试是否满足抽象基类的接口要求 , 往往比检查一个函数的参数是不是具体的dict类型要好 ,
因为除了dict之外还有其他映射类型可用 .
这个问题将在第 13 章详谈 .
* -------------------------------------------------------------------------------------------- *
图 3 - 1 : MutableMapping及其collections . abc中的超类的简化UML类图 .
如果想自定义映射类型 , 拓展collections . UserDict或通过组合模式包装dict更简单 ,
那就不要定义这些抽象基类的子类 .
collections . UserDict类和标准库中的所有具体映射类都在实现中封装了基本的dict ,
而dict又建立在哈希表之上 .
因此 , 这些类有一个共同的限制 , 即键必须 '可哈希' ( 值不要求可哈希 , 只有键需要 ) .
3.4 .1 节会讲一讲相关概念 , 帮你回顾一下 .
"可哈希" 在Python术语表中有定义 , 摘录 ( 有部分改动 ) 如下 :
如果一个对象的哈希码在整个生命周期内永不改变 ( 依托__hash__ ( ) 方法 ) ,
而且可与其他对象比较 ( 依托__eq__ ( ) 方法 ) , 那么这个对象就是可哈希的 .
两个可哈希对象仅当哈希码相同时相等 . ②
( 注 2 : Python术语表中的 '和哈希' 词条使用的是 '哈希值' , 而不是 '哈希码' .
我倾向于使用 '哈希码' , 因为这个概念出现在映射上下文中 , 而映射对象中的项由键和值构成 ,
使用 '哈希值' 容易与键对应的 '值' 混淆 . 本书始终使用 '哈希码' 一说 . )
数值类型以及不可变的扁平类型str和bytes均是可哈希的 .
如果容器类型是不可变的 , 而且所含的对象是可哈希的 , 那么容器类型自身也是可哈希的 .
frozenset对象全部是可哈希的 , 因为按照定义 , 每一个元素都必须是可哈希的 .
仅当所有项均可哈希 , tuple对象才是可哈希的 .
请考察一下示例中的tt , tl和tf .
>> > tt = ( 1 , 2 , ( 30 , 40 ) )
>> > hash ( tt)
80271212646858338501
>> > tl = ( 1 , 2 , [ 30 , 40 ] )
>> > hash ( tl)
Traceback ( most recent call last) :
File "<stdin>" , line 1 , in < module>
TypeError: unhashable type : 'list'
>> > tf = ( 1 , 2 , frozenset ( [ 30 , 40 ] ) )
>> > hash ( tf)
- 4118419923444501110
一个对象的哈希码根据所用的Python版本和设备架构有所不同 .
如果出于安全考量而在哈希计算过程中 '加盐' , 那么哈希码也会发生变化 .
③ 正确实现的对象 , 其哈希码在一个Python进程内保持不变 .
( 注 3 : 一些安全隐患和应对方案参见 'PEP 456 --Seccure and interchangeable hash algorithm' . )
默认情况下 , 用户定义的类型是可哈希的 , 因为自定义类型的哈希码取自id ( ) ,
而且继承自object类的__eq__ ( ) 方法只不过比较对象ID .
如果自己实现了__eq__ ( ) 方法 , 根据对象的内部状态进行比较 ,
那么仅当__hash__ ( ) 方法始终返回同一个哈希码时 , 对象才是可哈希的 .
实践中 , 这要求__eq__ ( ) 和__hash__ ( ) 只考虑在对象的生命周期内始终不变的实例属性 .
解释 :
在Python中 , 如果一个对象是可哈希的 , 则它可以用作字典的键或集合的成员 .
可哈希的对象必须满足以下两个条件 :
1. 对象的哈希码必须始终保持不变 .
2. 对象可以使用__eq__ ( ) 方法进行比较 , 即如果a = = b为真 , 则hash ( a ) = = hash ( b ) 也为真 .
对于自定义类型 , 默认情况下Python使用该对象的id ( ) 来生成哈希码 .
这意味着如果对象的内部状态发生变化 , 则哈希码也会发生变化 , 因此对象将不再可哈希 .
但是 , 如果你定义了自己的__hash__ ( ) 方法 , 那么你可以在该方法中根据对象的不变属性生成哈希码 .
如果你确保__hash__ ( ) 方法始终返回相同的哈希码 , 则对象将保持可哈希 .
请注意 , 这意味着你必须确保在对象的生命周期中不变的属性 , 否则哈希码会发生变化 , 导致对象不再可哈希 .
另外 , 请注意 , 如果你自定义了__eq__ ( ) 方法 , 则也需要确保它与__hash__ ( ) 方法一致 .
也就是说 , 如果a = = b为真 , 则hash ( a ) = = hash ( b ) 也应该为真 .
否则 , 如果你使用自定义类型作为字典的键或集合的成员 , 则可能会出现奇怪的行为 .
接下来概览Python中最常用的几种映射类型的API , 包括dict , defaultdict和OrderDict .
映射的基本API非常丰富 .
表 3 - 1 列出了dict , 以及collections模块中两个常用变体defaultdict和OrderDict实现的方法 .
表 3 - 1 : 映射类型dict , collections . defaultdict和collections . OrderDict实现的方法
( 简单起见 , 省略了object实现的方法 , [ ... ] 表示可选参数 )
方法 dict defaultdicr orderdDict 含义
d . clear ( ) • • • 删除所有项
d . __contains__ ( k ) • • • k in d
d . copy ( ) • • • 浅拷贝
d . __copy__ ( ) • 为copy . copy ( d ) 提供支持
d . default_factory • 由__missing__调用的可调用对象 , 用于设置缺失的值 ( a ) d . __delitem__ ( k ) • • • del d [ k ] : 删除键k对应的项
d . fromkeys ( it , [ initial ] ) • • • 根据可迭代对象中的键构建一个映射 ,
可选参数initial指定初始化值 ( 默认为None ) d . get ( k , [ default ] ) • • • 获取键k对应的项 , 不存在时则返回default或None
d . __getitem__ ( k ) • • • d [ k ] : 获取键k对应的项
d . items ( ) • • • 获取项视图 , 即 ( key , value ) 对
d . __iter__ ( ) • • • 获取遍历见的迭代器
d . keys ( ) • • • 获取键视图
d . __len__ ( ) • • • len ( d ) : 项数
d . __missing__ ( k ) • • • 当__getitem__找不到键是调用
d . move_to_end ( k , [ last ] ) • 把k移到开头或结尾 ( last默认为True )
d . __or__ ( other ) • • • d1 | d2 : 合并d1和d2 , 新建一个dict对象
( Python3 . 9 及以上版本 )
d . __ior__ ( other ) • • • d1 | = d2 : 使用d2中的项更新d1
( Python3 . 9 及以上版本 )
d . pop ( k , [ default ] ) • • • 删除并返回k对应的项 ,
如果没有键k , 则返回default或None
d . popitem ( ) • • • 删除并返回 ( ( key , value ) 形式 ) 最后插入的项 ( b )
d . __reversed__ ( ) • • • reverse ( d ) : 按插入顺序从后向前返回遍历键的迭代器
d . __ror__ ( other ) • • • other | dd : 反向合并运算符 ( Python3 . 9 及以上版本c )
d . setdefault ( k , [ default ] ) • • • 如果d中有键k , 则返回d [ k ] ;
否则 , 把d [ k ] 设置为的fault , 并返回default
d . __setitem__ ( k , v ) • • • d [ k ] = v : 把键k对应的值设为v
d . update ( m , [ **kwargs ] ) • • • 使用映射或可迭代对象中的键值更新d
d . value ( ) • • • 获取值视图
a default_factory不是方法 , 而是可调用的属性 , 有终端用户在实例化defaultdict对象时设置 .
b OrderedDict . popitem ( last = False ) 删除最想插入的项 ( 即先进先出 ) . 截止Python3 . 10 b3 ,
dict和default不支持关键字参数last .
c 反向运算符详见第 16 章 .
d . update ( m ) 处理第一个参数m的方式是 '鸭子类型' 的经典应用 :
先检查m有没有keys方法 , 如果有 , 则假定m是映射 ;
否则 , 退而求其次 , 迭代m , 假定项是键值对形式 ( ( key , value ) ) .
多数Python映射的结构函数 , 内部编辑逻辑与update ( ) 方法一样 ,
也就是说 , 可以从其他映射或生成键值对的可迭代对象初始化 ( 初始化映射 ) .
setdefault ( ) 方法不容忽视 .
如果想就地更新一个项的值 , 使用该方法就不用再去查找键 .
3.4 .3 节会说明具体用法 .
根据Python的 '快速失败' 原则 , 当键k不存在时 , d [ k ] 抛出错误 .
深谙Python的人知道 , 如果觉得默认值不抛出KetError更好 , 那么可以把d [ k ] 换成d . get ( k , default ) .
然而 , 如果你想要更新得到的可变值 , 那么还有更好的方法 .
举个例子 .
鸡舍你想编写一个脚本分析文本 , 编制索引 , 生成一个映射 , 以词为键 , 值为一个列表 , 表示词出现的位置 .
如示例 3 - 3 所示 .
# zen . txt
The Zen of Python , by Tim Peters
Beautiful is better than ugly .
Explicit is better than implicit .
Simple is better than complex .
Complex is better than complicated .
Flat is better than nested .
Sparse is better than dense .
Readability counts .
Special cases aren ' t special enough to break the rules .
Although practicality beats purity .
Errors should never pass silently .
Unless explicitly silenced .
In the face of ambiguity , refuse the temptation to guess .
There should be one-- and preferably only one --obvious way to do it .
Although that way may not be obvious at first unless you ' re Dutch .
Now is better than never .
Although never is often better than * right * now .
If the implementation is hard to explain , it ' s a bad idea .
If the implementation is easy to explain , it may be a good idea .
Namespaces are one honking great idea -- let ' s do more of those !
$ python index0. py zen. txt
a [ ( 19 , 48 ) , ( 20 , 53 ) ]
Although [ ( 11 , 1 ) , ( 16 , 1 ) , ( 18 , 1 ) ]
ambiguity [ ( 14 , 16 ) ]
and [ ( 15 , 23 ) ]
are [ ( 21 , 12 ) ]
aren [ ( 10 , 15 ) ]
at [ ( 16 , 38 ) ]
bad [ ( 19 , 50 ) ]
be [ ( 15 , 14 ) , ( 16 , 27 ) , ( 20 , 50 ) ]
beats [ ( 11 , 23 ) ]
Beautiful [ ( 3 , 1 ) ]
better [ ( 3 , 14 ) , ( 4 , 13 ) , ( 5 , 11 ) , ( 6 , 12 ) , ( 7 , 9 ) , ( 8 , 11 ) , ( 17 , 8 ) , ( 18 , 25 ) ]
. . .
示例 3 - 4 种的脚本不太完美 , 目的告诉你dict . get不是处理缺失键的最近佳方式 .
这个脚本根据Alex Maartelli的一个示例修改而来 . ④
( 注 4 : 原脚本出自Martelli的演讲 'Re-leaming Python' , 第 41 张幻灯片 .
它的脚本其实是演示dict . setdefault , 如示例 3 - 5 所示 . )
"""构建一个索引映射, 列出词出现的位置"""
import re
import sys
WORD_RE = re. compile ( r'\w+' )
index = { }
with open ( sys. argv[ 1 ] , encoding= 'utf-8' ) as fp:
for line_no, line in enumerate ( fp, 1 ) :
for match in WORD_RE. finditer( line) :
word = match . group( )
column_no = match . start( ) + 1
location = ( line_no, column_no)
occurrences = index. get( word, [ ] )
occurrences. append( location)
index[ word] = occurrences
for word in sorted ( index, key= str . upper) :
print ( word, index[ word] )
示例 3 - 4 处理occurrences用了 3 行代码 , 换成dict . setdefault则只需要一行代码 .
示例 3 - 5 与Alex Martelli最初写的代码类似 .
import re
import sys
WORD_RE = re. compile ( r'\w+' )
index = { }
with open ( sys. argv[ 1 ] , encoding= 'utf-8' ) as fp:
for line_no, line in enumerate ( fp, 1 ) :
for match in WORD_RE. finditer( line) :
word = match . group( )
column_no = match . start( ) + 1
location = ( line_no, column_no)
index. setdefault( word, [ ] ) . append( location)
for word in sorted ( index, key= str . upper) :
print ( word, index[ word] )
也就是说 , 下面这一行 :
my_dict. setdefault( key, [ ] ) . append( new_value)
作用与下面 3 行一样 :
if key not in my_dict:
my_dict[ key] = [ ]
my_dict[ key] . append( new_value)
不过 , 后一种写法至少要搜索key两次 , 如未找到则搜索 3 次 , 而setdefault只搜索一次 .
3.5 节将探讨一个相关话题 : 处理任何操作 ( 而不仅限于插入 ) 缺失键的情况 .
有时搜索的键不一定存在 , 为了以防万一 , 可以人为设置一个值 , 以方便某些情况的处理 .
人为设置的值主要有两种方法 :
第一种是把普通的dict换成defaultdict ;
第二种是定义dict或其他映射类型的子类 , 现实__missing__方法 .
下面分别介绍这两种情况 .
对于collections . defaultdict , d [ k ] 句法找不到搜索的键时 , 使用指定的默认值创建对应的项 .
示例 3 - 6 使用defaultdict重新实现示例 3 - 5 , 以另一种优雅的方式编制索引 .
这词实现的原理是 , 实例化defaultdict对象时提供一个可调用对象 , 当__getitem__遇到键不存在的键时 ,
调用那个可调用对象生成一个默认值 .
举个例子 .
假设使用dd = defaultdict ( list ) 创建一个defaultdict对象 ,
而dd中没有 'new-key' 键 , 那么dd [ 'new-key' ] 表达式按一下几步处理 .
1. 调用list ( ) 创建一个新列表 .
2. 把该列表插入dd , 对应到 'new-key' 键上 .
3. 返回该列表的应用 .
生成默认值的可调用对象存放在实例属性default_factory中 .
"""构建一个索引映射, 列出词出现的位置"""
import collections
import re
import sys
WORD_RE = re. compile ( r'\w+' )
index = collections. defaultdict( list )
with open ( sys. argv[ 1 ] , encoding= 'utf-8' ) as fp:
for line_no, line in enumerate ( fp, 1 ) :
for match in WORD_RE. finditer( line) :
word = match . group( )
column_no = match . start( ) + 1
location = ( line_no, column_no)
index[ word] . append( location)
for word in sorted ( index, key= str . upper) :
print ( word, index[ word] )
如果未提供default_factory , 遇到缺失的键时 , 则像往常一样抛出异常KeyError .
* * * ---------------------------------------------------------------------------------------- * * *
defaultdict的default_factory仅为__getitem__提供默认值 , 其他方法用不到 .
例如 , dd是一个defaultdict对象 , 如果没有键k , 那么dd [ k ] 将调用的default_factory创建默认值 ,
但是dd . get ( k ) 依然返回Nont , 而且k in dd 也返回False .
* * * ---------------------------------------------------------------------------------------- * * *
defaultdict之所以调用default_factory , 背后的机制是接下来要讨论的特殊方法__missing__ .
__missing__方法映射处理缺失键的底层逻辑在__missing__方法中 .
dict基类本身没有定义这个方法 , 但是如果dict的子类定义了这个方法 ,
那么dict . __getitem__找不到键是将调用__missing__方法 , 不抛出KeyError .
假设你希望查找映射的键时把键转换成str类型 . IoT设备的代码库就需要这么做 . ⑥
( 注 6 : 例如开发已经停滞的Pingo . io库 )
可编程板 ( 例如 , Raspberry Pi或Arduino ) 上有一些通用I / O引脚 ,
在代码库中通过Board类的my_board . pins属性表示 .
这个属性把物理引脚标识符映射到引脚对象上 .
物理引脚标识符可以使纯数值 , 也可以是 'A0' 或 'P9_12' 之类的字符串 .
为了保持一致 , 我们希望pins中所有的键都是字符串 , 可是有些时候也想通过数值来查找引脚 ,
例如 , my_arduino . pin [ 13 ] , 这是为了避免初学者不知道如何点亮arduino板 13 号引脚上的LED .
这种映射要求如示例 3 - 7 所示 .
>> > d = StrKeyDict0( [ ( '2' , 'two' ) , ( '4' , 'four' ) ] )
>> > d[ '2' ]
'two'
>> > d[ 4 ]
'four'
>> > d[ 1 ]
Traceback ( most recent call last) :
. . .
KeyError: '1'
>> > d. get( '2' )
'two'
>> > d. get( 4 )
'four'
>> > d. get( 1 , 'N/A' )
'N/A'
>> > 2 in d
True
>> > 1 in d
False
示例 3 - 8 实现了可通过以上的doctest的StrKeyDict0类 .
* -------------------------------------------------------------------------------------------- *
用户自定义映射类型最好像示例 3 - 9 那样继承collections . UserDict类 , 而不要继承dict类 .
这里继承dict类时为了说明内置的dict . __getitem__方法支持__missing__ .
* -------------------------------------------------------------------------------------------- *
class StrKerDict0 ( dict ) :
def __missing__ ( self, key) :
if isinstance ( key, str ) :
raise KeyError( key)
return self[ str ( key) ]
def get ( self, key, default= None ) :
try :
return self[ key]
except KeyError:
return default
def __contatins__ ( self, key) :
return key in self. keys( ) or str ( key) in self. keys( )
请想一想 , 为什么实现__missing__方法时要做isinstance ( key , str ) 测试 .
如果不做这个测试 , 则__missing__方法可以处理任何类型的键 , 是不是字符串都无所谓 ,
但前提是str ( k ) 得到的是现有的键 .
然而 , 倘如str ( k ) 得到的键不存在 , 那就进入了无限递归 :
__missing__方法的最后一行self [ str(key) ] 将调用__getitem__方法 , 转而又调用__missing__方法 .
本例中 , 出于对行为一致性的考虑 , 也需要__contains__方法 ,
应为k in d操作调用它 , 而从dict继承的__contains__方法不回落到__missing__方法 .
__contains__方法的实现方式有一个微妙的细节 , 我们没有按照常规的Python风格检查键 ( k in my_dict ) ,
因为str ( key ) in self将递归调用__contains__方法 .
为了避免这个问题 , 我们显示地在self . keys ( ) 中查找键 .
行为的一致性 : 是指在不同情况下 , 一个对象或方法的行为应该保持相同 ,
不会因为上下文的不同而导致行为不一致或意外的结果 .
在这个示例中 , 如果没有实现__contains__方法 ,
那么使用in操作符检查一个非字符串键是否存在于StrKeyDict0实例中时 ,
会根据dict类的默认行为 , 直接返回False , 而不会调用__missing__方法 .
因此 , 为了保持StrKeyDict0实例的行为一致性 , 需要实现__contains__方法 ,
让它先检查经过修改的键 ( 让它先检查经过修改的键 ) ,
然后再检查键的字符串形式 ( 直接存储在字典中的的字符串键 ) .
这样就可以保证无论传入什么类型的键 , 都可以得到一致的结果 .
"回落" : 指的是在一个对象或方法的某个操作没有得到正确结果时 ,
继续尝试其他操作或方法 , 以获得正确结果的过程
在Python3中 , 即使是特别大型的映射 , k in my_dict . keys ( ) 这样的搜索效率也不低 ( 意思说还是很高的 ) ,
应为dict . keys ( ) 返回的是类似集合的视图 , 详见 3.12 节 .
尽管如此 , k in my_dict的作用是相同的 , 而且速度更快 , 因为无须通过属性查找 . keys方法 .
示例 3 - 8 中 , __contains__方法使用self . keys ( ) 还有一个特定的原因 .
为了保证结果正确 , 必须使用key in self . keys ( ) 检查未经过修改的键 ,
因为StrKeyDict0不强制要求字典中所有键都是str类型 .
这个简单的示例只有一个目的 , 即提高搜索的 '友好度' , 而不是限定键的类型 .
* * * ---------------------------------------------------------------------------------------- * * *
用户自己定义的类 , 如果继承标准库中的映射 ,
在实现__getitem__ , get或__contains__方法时不一定回落到_missing__方法 , 具体原因见 3.5 .3 节 .
* * * ---------------------------------------------------------------------------------------- * * *
__missing__方法的使用不一致下面分几种情况演示查找缺失键的不同行为 .
dict子类
定义一个dict子类 , 只实现__missing__方法 , 其他方法均不实现 .
这种情况下 , 可能只有d [ k ] ( 使用继承自dict的__getitem__方法 ) 会调用__missing__方法 .
cillections . UserDict子类
定义一个UserDict子类 , 同样只实现__missing__方法 , 其他方法均不实现 .
继承自UserDict的get方法调用__getitem__ .
这意味着 , d [ k ] 和d . get ( k ) 在查找键时可能会调用__missing__方法 .
abc . Mapping子类 , 以最简单的方式实现__getitem__方法
定义一个精简的abc . Mapping子类 , 实现__missing__方法和必要的抽象方法 ,
其中__getitem__方法不调用__missing__ .
这个类永不触发__missing__方法 .
abc . Mapping子类 , 让__getitem__调用__missing__
定义一个精简的abc . Mapping子类 , 实现__missing__方法和必要的抽象方法 ,
其中__getitem__方法调用__missing__ .
d . get ( k ) 和k in d遇到缺失的键将触发__missing__方法 .
这种情况的代码件示例代码中的missing . py文件 .
def _upper ( x) :
try :
return x. upper( )
except AttributeError:
return x
class DictSub ( dict ) :
def __missing__ ( self, key) :
return self[ _upper( key) ]
d = DictSub( A = 'letter A' )
d[ 'a' ]
d. get( 'a' , '' )
'a' in d
from collections import UserDict
class UserDictSub ( UserDict) :
def __missing__ ( self, key) :
return self[ _upper( key) ]
ud = UserDictSub( A = 'letter A' )
ud[ 'a' ]
ud. get( 'a' , '' )
'a' in ud
from collections import abc
class SimpleMappingSub ( abc. Mapping) :
def __init__ ( self, * args, ** kwargs) :
self. _data = dict ( * args, ** kwargs)
def __getitem__ ( self, key) :
return self. _data[ key]
def __len__ ( self) :
return len ( self. _data)
def __iter__ ( self) :
return iter ( self. _data)
sms = SimpleMappingSub( A = 'letter A' )
sms[ 'a' ]
sms. get( 'a' , '' )
'a' in sms
class MappingMissingSub ( SimpleMappingSub) :
def __getitem__ ( self, key) :
try :
return self. _data[ key]
except KeyError:
return self[ _upper( key) ]
mms = MappingMissingSub( A = 'letter A' )
mms[ 'a' ]
mms. get( 'a' , '' )
'a' in mms
class DictLikeMappingSub ( SimpleMappingSub) :
def __getitem__ ( self, key) :
try :
return self. _data[ key]
except KeyError:
return self[ _upper( key) ]
def get ( self, key, default= None ) :
return self. _data. get( key, default)
def __contains__ ( self, key) :
return key in self. _data
dms = DictLikeMappingSub( A = 'letter A' )
dms[ 'a' ]
dms. get( 'a' , '' )
'a' in dms
以上 4 种情况的具体实现做了简化处理 .
你在自定义的子类中实现__getitem__ , get和__contains__方法时 ,
可以根据实际需求决定是否使用__missing__方法 .
本节的目的是指出 , 继承标准库中的映射时要小心谨慎 , 不同的基类对__missing__的使用方式不一样 .
不要忘了 , setdeault和update的行为也受键查找的影响 .
最后 , __missing__的逻辑容易出错 , 有时候还要以特殊的逻辑实现__setitem__ , 以免行为不一致或出乎意料 .
3.6 .5 节有一个示例 .
目前我们讨论了dict和defaultdict两种映射类型 , 除此之外 , 标准库中海油其他映射类型 , 下面将逐一讨论 .
本节概述标准库中除defaultdict ( 3.5 .1 节已经介绍 ) 之外的映射类型 .
自Python3 . 6 起 , 内置的dict也保留键的顺序 .
使用OrderedDict最主要的原因是编写与早期Python版本兼容的代码 .
不过 , dict和OrderedDict之间还有一些差异 , Python文档中有说明 ,
摘录如下 ( 根据日常使用频率 , 顺序有调整 ) .
• OrderedDict 的等值检查考虑顺序 .
• OrderedDict 的popitem ( ) 方法签名不同 , 可通过一个可选参数指定移除哪一项 .
• OrderedDict 多了一个move_to_end ( ) 方法 , 便于把元素的位置移到某一端 .
• 常规的dict主要用于执行映射操作 , 插入顺序是次要的 .
• OrderedDict 的目的是方便执行重新排序操作 , 空间利用率 , 迭代速度和更新操作的性能是次要的 .
• 从算法上看 , OrderedDict处理频繁重新排序操作的效果比dict好 ,
因此适合用于跟踪近期存取情况 ( 例如在LRU缓存中 ) .
ChainMap实例存放一组映射 , 可作为一个整体来搜索 .
查找操作按照输入映射在构造函数调用中出现的顺序执行 , 一旦在某个映射中找到指定的键 , 旋即结束 .
例如 :
>> > d1 = dict ( a= 1 , b= 3 )
>> > d2 = dict ( a= 2 , b= 4 , c= 6 )
>> > from collections import ChainMap
>> > chain = ChainMap( d1, d2)
>> > chain[ 'a' ]
1
>> > chain[ 'c' ]
6
ChainMap实例不复制输入的映射 , 而是存放映射的引用 .
ChainMap的更新或插入操作只影响第一个输入映射 .
续前例 :
>> > chain[ 'c' ] = - 1
>> > d1
{ 'a' : 1 , 'b' : 3 , 'c' : - 1 }
>> > d2
{ 'a' : 2 , 'b' : 4 , 'c' : 6 }
ChainMap可用于实现支持嵌套作用域的语言解释器 , 按嵌套层级从内到外 , 一个映射表示一个作用域上下文 .
collections文档中的 'ChainMap objects' 一节举了几个ChainMap用法示例 .
其中一个就是模仿Python查找变量的基本规则 , 如下所示 .
import builltins
pylookup = ChinaMap( locals ( ) , global ( ) , vars ( builtins) )
第 18 章中的示例 18 - 14 使用一个ChainMap子类为Scheme编程语言的子集实现解释器 .
这是一种对键计数的映 . 更新现有的键 , 计数随之增加 .
可用于统计可哈希对象的实例数量 , 或者作为多重集 ( multiset , 本节后文讨论 ) 使用 .
Counter 实现了组合计数的 + 和-运算符 , 以及其他一些有用的方法 , 例如 , most_common ( [ n ] ) .
该方法返回一个有序元组列表 , 对应前n个计算值最大的项及其数量 .
下面使用Counter统计词中的字母数量 .
>> > import collections
>> > ct = collections. Counter( 'abracadabra' )
>> > ct
Counter( { 'a' : 5 , 'b' : 2 , 'r' : 2 , 'c' : 1 , 'd' : 1 } )
>> > ct. update( 'aaaaazzz' )
>> > ct
Counter( { 'a' : 10 , 'z' : 3 , 'b' : 2 , 'r' : 2 , 'c' : 1 , 'd' : 1 } )
>> > ct. most_common( 3 )
[ ( 'a' , 10 ) , ( 'z' , 3 ) , ( 'b' , 2 ) ]
注意 , 'b' 和 'r' 两个键并列第三 , 但是ct . most_common ( 3 ) 只显示 3 项 .
若想把collections . Counter当作多重集使用 , 假设各个键是集合中的元素 , 计算值则是元素在集合中出现的次数 .
标准库中的shrlve模式持久存储字符串键与 ( 以plckle二进制格式序列化的 ) Python对象之间的映射 .
你可能觉得shrlve这个名字有点奇怪 , 不过想到泡菜坛 ( pickle jar ) 是放在货架 ( shelve ) 上的 , 还是有一定道理的 .
模块级函数shelv . open返回一个shelve . Shelf实例 , 这个一个简单的键值DBM数据库 , 背后dbm模块 .
shelve . Shelf具有以下特征 .
• shelve . Shelf是abc . MutableMapping的子类 , 提供了我们预期的映射类型基本方法 .
• 此外 , shelve . Shelf还提供了一些其他I / O管理方法 , 例如sync和close .
• Shelf实例是上下文件管理器 , 因此可以使用with块确保在使用后关闭 .
• 为键分配新值后即保存键和值 .
• 键必须是字符串 .
• 值必须是pickle模块可以序列化的对象 .
详细说明和一些注意事项见shelve模块 , dbm模块和pickle模块的文档 .
* * * ---------------------------------------------------------------------------------------- * * *
在极为简单的情况下 , Python的pickle模块用着比较顺手 , 但也是隐藏的陷阱也不少 .
使用pickle解决问题之前 , 请务必阅读Ned Batchelder写的 "Pickle's nine flaws" 一文 .
Ned在这篇文章中给出了可供选择的其他序列化格式 .
* * * ---------------------------------------------------------------------------------------- * * *
OrderedDict , ChainMap , Counter和shelf本身就是可用的 , 此外也可以通过子类定制 .
相反 , UserDict只应作为基类 , 在此基础上拓展 .
创建新的映射类型 , 最好拓展collections . UserDict , 而不是dict .
为了确保以str类型存储添加到映射中的键 , 我们在示例 3 - 8 中定义了StrKeyDict0类 .
那时我们就意识到了这一点 .
子类最好继承UserDict的主要原因是 , 内置的dict在实现上走了一些捷径 ,
如果继承dict , 那就不得不覆盖一些方法 , 而继承UserDict则没有这些问题 . ⑦
( 注 7 : 子类继承dict和其他内置类型的具体问题将在 14.3 节讨论 . )
注意 , UserDict没有继承dict , 使用的是组合模式 : 内部有一个dict实例 , 名为data , 存放具体的项 .
与示例 3 - 8 相比 , 这样做可以避免__setitem__等特殊方法意外递归 , 还能简化__contains__的实现 .
示例 3 - 9 的StrKeyDict继承UserDict , 实现过程比StrKeyDict0 ( 示例 3 - 8 ) 更简洁 ,
而且功能更丰富 : 所有见都以str类型存储 , 使用包含非字符串键的数据结构或更新说不会发生意外情况 .
import collect
class StrKeyDict ( collections. UserDict) :
def __missing__ ( self, key) :
if isinstance ( key, str ) :
raise KeyError( key)
return self[ str ( key) ]
def __contains__ ( self, key) :
return str ( key) in self. date
def __setitem__ ( self, key, item) :
self. data[ str ( key) ] = item
由于UserDict拓展abc . MutableMapping , 因此使StrKetDict成为一种功能完整的映射的方法 ,
是从UserDict , MutableMapping或Mapping继承的方法 .
后两个类虽然是抽象基类 , 但是也有一些有用的具体方法 .
这句话主要在讲述StrKeyDict类如何成为一个功能完整的映射 ( 即支持映射的基本操作 ,
如__getitem__ , __setitem__ , __delitem__ , __len__ , __iter__ ` 等 ) .
首先 , StrKeyDict继承了UserDict类 ,
这个类是一个类字典的实现 , 它提供了一些方便的方法来操作字典 , 例如get和pop等方法 .
其次 , UserDict类继承了MutableMapping抽象基类 ,
这个抽象基类定义了一些必须实现的方法 , 以便能够支持字典的基本操作 .
具体来说 , 它要求实现__getitem__ , __setitem__ , __delitem__ , __iter__ , 和__len__这五个方法 .
最后 , MutableMapping继承了Mapping抽象基类 ,
Mapping抽象基类是一个只读映射的基类 , 它定义了只读映射必须实现的方法 ,
包括__getitem__ , __iter__ , __len__ , 和keys , values , items等方法 .
因此 , 通过继承UserDict类 , 它实现了MutableMapping抽象基类定义的方法 ,
同时通过MutableMapping的继承关系 , 它也实现了Mapping抽象基类定义的方法 ,
这使得StrKeyDict类成为了一个功能完整的映射 .
下面两个方法值得关注 .
MutableMapping . update
这个强大的方法可以直接调用 , __init__也使用它从其他映射 , 键值对可迭代对象和关键字参数中加载实例 .
该方法使用self [ key ] = value句法添加项 , 最终会调用子类实现的__setitem__ .
Mapping . get
在StrKeyDict0中 ( 参见示例 3 - 8 ) , 我们必须自己实现get方法 , 返回与__getitem__一样的结果 .
而在示例 3 - 9 中 , 我们继承了Mapping . get , 它的实现与StrKeyDict0 . get完全相同 .
( Mapping . get的实现就是从collections . abc . Mapping类中继承下来的默认实现 ) .
* --------------------------------------------------------------------------------------------- *
Antoine Pitron编写 'PEP 455--Adding a key-transforming dictionary to collections'
提议为collectionss模块增加TransformDict , 这比StrKeyDict更通用 , 在转换之前保留键的原本类型 .
PEP 455 在 2015 年 5 月被否决 , 拒绝原因见Raymond Hettinger的回应 .
为了试验TransformDict , 我把Pitrou的补丁从 18986 号工单中提取出来了 ,
制成了独立的模块 ( 03 -dict / set / transformdict . py ) .
* --------------------------------------------------------------------------------------------- *
我们知道Python有不可变序列类型 , 那有没有不可变映射呢?
其实 , 标准库中没有 , 不过有变通方案 . 详见 3.7 节 .
标准库提供的映射类型都是可变的 , 不过有时也需要防止用户意外更改映射 .
3.5 .2 节提到的硬件编程库Pingo就有一例 : board . pings映射表示设备上的GPIO物理引脚 ,
因此需要防止被人无意中更新 , 毕竟软件不能更改硬件 , 不然就与设备的实际物理结构不一致了 .
types模块提供的MappingProxyType是一个包装类 , 把传入的映射包装成一个mappingproxy实例 ,
这是原映射的动态代理 , 只可读取 .
这意味着 , 是原映射的更新将体现在mappingproxy实例身上 , 但是不能通过mappingproxy实例更改映射 .
示例 3 - 10 简单演示MappingProxyType的用途 .
>> > from types import MappingProxyType
>> > d = { 1 : 'A' }
>> > d_proxy = MappingProxyType( d)
>> > d_proxy
mappingproxy( { 1 : 'A' } )
>> > d_proxy[ 1 ]
'A'
>> > d_proxy[ 2 ] = 'x'
Traceback ( most recent call last) :
File "<stdin>" , line 1 , in < module>
TypeError: 'mappingproxy' object does not support item assignment
>> > d[ 2 ] = 'B'
>> > d_proxy
mappingproxy( { 1 : 'A' , 2 : 'B' } )
>> > d_proxy[ 2 ]
'B'
在硬件编程场景中可以这样使用 : 定义Board的具体子类 , 在构造方法中声明一个私有映射 , 存放引脚对象 ,
再使用mappingproxy实现一个公开的 . pin属性 , 通过API开放给客户端使用 .
这样 , 客户端就不会意外地添加 , 删除或更改引脚 .
接下来探讨视图 .
通过视图可以对字典执行一些高性能操作 , 免去了复制数据的麻烦 .
dict的实例方法 . keys ( ) , . values ( ) , . items ( ) 分别放返回dict_keys , dict_values和dict_items类的实例 .
这些字典视图是dict内部实现使用的数据结构的只读投影 .
Python2中对应的方法返回列表 , 重复dict中已有的数据 , 有一定的内存开销 .
另外 , 视图还取代了返回迭代器的旧方法 .
示例 3 - 11 展示所有字典视图均支持的一些基本操作 .
>> > d = dict ( a= 10 , b= 20 , c= 30 )
>> > values = d. values( )
>> > values
dict_values( [ 10 , 20 , 30 ] )
>> > len ( values)
3
>> > list ( values)
[ 10 , 20 , 30 ]
>> > reversed ( values)
< dict_reversevalueiterator object at 0x10e9e7310 >
>> > values[ 0 ]
Traceback ( most recent call last) :
File "<stdin>" , line 1 , in < module>
TypeError: 'dict_values' object is not subscriptable
视图对象是动态代理 .
更新原dict对象后 , 现有的视图立刻就能看到变化 . 续示例 3 - 11 :
>> > d[ 'z' ] = 99
>> > d
{ 'a' : 10 , 'b' : 20 , 'c' : 30 , 'z' : 99 }
>> > values
dict_values( [ 10 , 20 , 30 , 99 ] )
dict_keys , dict_values和dict_items是内部类 ,
不能通过__builtins__或标准库中的任何模块获取 , 尽管可以得到实例 , 但是在Python代码中不能自己动手创建 .
>> > values_class = type ( { } . values( ) )
>> > v = values_class( )
Traceback ( most recent call last) :
File "<stdin>" , line 1 , in < module>
TypeError: cannot create 'dict_values' instances
dict_values类是最简单的字典视图 , 只实现了__len__ , __iter__和__reversed__这三个特殊方法 .
除此以外 , dict_keys和dict_items还实现了多个集合的方法 , 基本与frozenset类相当 .
讲解集合之后再深入探讨dict_key和dict_items , 详见 3.13 节 .
接下来讲一讲dict的内部实现产生的一些制约 , 并给出一些实践小窍门 .
Python使用哈希表实现dict , 因此字典的效率非常高 , 不过这种设计对实践也有一些影响 , 不容忽视 .
• 键必须是可哈希的对象 .
就像 3.4 .1 节所说的那样 , 必须正确实现__hash__和__eq__方法 .
• 通过见访问项速度非常快 .
对于一个包含数百万个键的dict对象 , Python通过计算键的哈希码就能直接定位键 ,
然后找出索引在哈希表中的偏移量 , 稍微尝试几次就能找打匹配的条目 , 因此开销不大 .
• 在CPython3 . 6 中 , dict的内存布局更为紧凑 , 顺带一个副作用是键的顺序得以保留 .
Python3 . 7 正式支持保留顺序 .
• 尽管采用了新的紧凑布局 , 但是字典任然占用大量内存 , 这是不可避免的 .
对容器来说 , 最紧凑的内部数据结构是指向项的指针的数组 .
⑧ 与之相比 , 哈希表中的条目存储的数据更多 ,
而且为了保证效率 , Python至少需要把哈希表中三分之一的行留空 .
( 注 8 : 元组就是这样存储的 . )
• 为了节省内存 , 不要在__init__方法之外创建实例属性 .
最后一点背后的原因是 , Python默认在特殊的__dict__属性中存储实例的属性 ,
而这个属性的值是一个字典 , 依附在各个实例上 .
⑨自从Python3 . 3 实现 'PEP 412--Key-Sharing Dictionary' 之后 , 类的实例可以共用一个哈希表 , 随类一起存储 .
( 注 9 : 除非类有__slots__属性 , 详见 11.11 节 . )
如果新实例与__init__返回的第一个实例拥有相同的属性名称 ,
那么新实例的__dict__属性就共享这个哈希表 , 仅以指针数组的形式存储新实例的属性值 .
__init__方法执行完毕后再添加实例属性 ,
Python就不得不为这个实例的__dict__属性创建一个新哈希表 ( 在Python3 . 3 之前 , 这是所有实例的默认行为 ) .
根据PEP 412 , 这种优化可将面向对象程序的内存使用量减少 10 % ~ 20 % .
上诉解释 :
在Python中 , 实例对象的属性通常是存储在一个名为__dict__的字典中 .
每个实例对象都有一个独立的__dict__字典 , 用于存储该实例的属性和对应的值 .
当创建一个新的实例对象时 , Python会为该实例分配一个独立的__dict__字典 .
然而 , 如果新创建的实例对象与__init__方法返回的第一个实例对象具有相同的属性名称 ,
Python会优化内存使用 , 将新实例的__dict__属性与第一个实例共享同一个哈希表 .
这意味着新实例的__dict__属性实际上是一个指针数组 , 指向第一个实例的属性值 .
然而 , 一旦__init__方法执行完毕并为新实例添加了额外的属性 ,
Python就不得不为新实例的__dict__属性创建一个新的哈希表 , 以容纳这些额外的属性 .
这是因为新实例的属性与第一个实例的属性不再完全相同 , 因此需要一个新的字典来存储新实例的属性和值 .
这种优化可以帮助减少内存消耗 , 特别是对于那些具有大量相同属性的实例对象 .
通过共享哈希表 , 可以节省内存空间 .
然而 , 需要注意的是 , 一旦新实例添加了与第一个实例不同的属性 ,
就会引发哈希表的重新创建 , 从而可能导致内存占用的增加 .
下面开始研究集合 .
集合对Python来说并不是新事物 , 但目前尚未得到充分利用 .
set类型及其不可变形式frozenset首先作为模块出现在Python2 . 3 标准库中 ,
随后在Python2 . 6 中被提升为内置函数 .
* * ------------------------------------------------------------------------------------------- * *
本书使用 '集合' 一词指代set和frozenset .
如果讨论内容仅涉及set类 , 则使用等宽字体 , 写作set .
* * ------------------------------------------------------------------------------------------- * *
集合是一组唯一的对象 .
集合的基本作用是去除重复项 .
>> > l = [ 'spam' , 'spam' , 'eggs' , 'spam' , 'bacon' , 'eggs' ]
>> > set ( l)
{ 'eggs' , 'spam' , 'bacon' }
>> > list ( set ( l)
[ 'eggs' , 'spam' , 'bacon' ]
* ------------------------------------------------------------------------------------------- *
如果想去除重复项 , 同时保留每一项首次出现位置的顺序 , 那么现在使用普通的dict即可 , 如下所示 .
* ------------------------------------------------------------------------------------------- *
>> > dict . fromkeys( l) . keys( )
dict_keys( [ 'spam' , 'eggs' , 'bacon' ] )
>> > list ( dict . fromkeys( l) . keys( ) )
[ 'spam' , 'eggs' , 'bacon' ]
集合元素必须是可哈希的对象 .
set类型不可哈希对象 , 因此不能构建嵌套set实例的set对象 .
但是frozenset可以哈希 , 所以set对象可以包含frozenste元素 .
除了强制唯一性之外 , 集合类型通过中缀运算法实现了许多集合运算 .
给定两个集合a和b , a | b计算并集 , a & b计算交集 , a - b计算差集 , a ^ b计算对称集 .
巧妙使用集合即可以减少代码行 , 也能缩减Python程序的运行时间 , 同时还能少编写一些循环和添加逻辑 ,
从而让代码更易于阅读和理解 .
举个例子 , 假设有一个集合存储大量电子邮件地址 ( haystack ) , 还有一个集合存储少量电子邮件地址 ( needled ) ,
你想统计needled中有多少邮件地址出现在haystack中 .
捷足集合交集运算 ( & 运算符 ) , 用一行代码即可实现 ( 见例 3 - 12 ) .
found = len ( needles & haystack)
如果不使用交集运算符 , 则要像示例 3 - 13 那样编写代码 , 才能实现与示例 3 - 12 一样的效果 .
found = 0
for n in needles:
if n in haystack:
fount += 1
示例 3 - 12 的运行速度比示例 3 - 13 稍快 .
不过 , 示例 3 - 13 处理的needles和haystack可以是任意可迭代对象 , 而示例 3 - 12 要求二者均为集合 .
然而 , 就算一开始不是集合 , 也可以快速构建 , 如示例 3 - 14 所示 .
found = len ( set ( needles) & set ( haystack) )
found = len ( set ( needles) . intetsection( haystack) )
当然 , 像示例 3 - 14 那样构建集合有一个额外的开销 .
但是 , 如果needles和haystack中有一个本身就是集合 , 那么示例 3 - 14 中的第二种方式比示例 3 - 13 开销更小 .
假如needles中有 1000 个元素 , haystack中有 10 000 000 项 , 那么前面几例的运行时间都在 0.3 毫秒左右 ,
平摊到每一个元素上约为 0.3 微秒 .
成了成员测试速度极快 ( 归功于底层哈希表 ) 之外 , 内置类型set和drozenset还提供了丰富的API ,
有的用于创建新集合 , 有的用于更改set对象 .
在讨论这些操作之前 , 先讲一讲句法 .
set字面量的句法与集合的数字表示法几乎一样 , 例如 { 1 } , { 1 , 2 } 等 .
唯有一点例外 : 空set没有字面量表示法 , 必须写作set ( ) .
* * * --------------------------------------句法陷阱-------------------------------------------- * * *
创建空set , 务必使用不带参数的构造函数 , 即set ( ) .
倘如写成 { } , 则创建的是空dict--这一点在Python中没有变化 .
* * * ----------------------------------------------------------------------------------------- * * *
在Python3中, 几何的标准字符串表形式始终使用{ . . . } 表示, 唯有空集例外.
>> > s = { 1 }
>> > type ( s)
< class 'set' >
>> > s
{ 1 }
>> > s. pop( )
1
>> > s
set ( )
与调用构造函数 ( 例如 set ( [ 1 , 2 , 3 ] ) ) 相比 ,
使用set的字面量句法 ( 例如 { 1 , 2 , 3 } ) 不仅速度快 , 而且更具可读性 .
调用构造函数速度慢的原因是 , Python要查找set名称 , 找出构造函数 ,
然后构建一个列表 , 最后再把列表传给构造函数 .
相比之下 , Python处理字面量只需要运行一个专门的BUILD_SET字节码 . ⑩
( 注 10 : 这可能很有趣 , 但不是特别重要 .
只有求解一个集合字面是才有加速效果 , 而且每个Python进程最多发生一次 , 即首次编译模块时 .
如果你好奇 , 可以从dis模块导入dis函数 ,
反汇编set字面量 ( 例如dis ( '{1}' ) ) 和set调用 ( 例如dis ( 'set([1])' ) ) 的字节码 . )
frozenset没有字面量句法 , 必须调用构造函数创建 .
在Python3中 , frozenset的字符串表示形式类似于构造函数调用 ( 字符串表示形式和调用方式长的一样 ) .
下面是控制台会话的输出 .
>> > frozenset ( range ( 10 ) )
frozenset ( { 0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 } )
说到句法 , 列表推导式的思想也可以用于构建集合 .
结合推导式早在Python2 . 7 就已出现 , 与 3.2 .1 节讲到的字典推导式同时引入 .
示例 3 - 15 演示集合推导式的用法 .
>> > from unicodedata import name
>> > { chr ( i) for i in range ( 32 , 256 ) if 'SIGN' in name( chr ( i) , '' ) }
{ '#' , '<' , '§' , '£' , '¤' , '÷' , '¶' , 'µ' , '©' , '°' , '=' ,
'¥' , '%' , '$' , '¬' , '±' , '>' , '¢' , '+' , '®' , '×' }
不同的Python进程得到的输出顺序不一样 , 原因与 3.4 .1 节提到的加盐哈希有关 ,
句法讲完了 , 接下来讨论集合的行为 .
set和frozenset类型都使用哈希表实现 . 这种设计带来了以下影响 .
• 集合元素必须是哈希对象 , 必须像 3.4 .1 节所说那样正确实现__hash__和__eq__方法 .
• 成员测试效率非常高 .
对于一个包含数百万个元素的集合 , 计算元素的哈希码就可以直接定位元素 , 找出元素的索引偏移量 .
稍微搜索几次就能找打匹配的元素 , 即使穷经搜索开销也不大 .
• 与存放原始指针的低层数组相比 , 集合占用大量内存 .
尽管集合的结构更紧凑 , 但是一旦要搜索元素数量变多 , 搜索速度将显著下降 .
• 元素的顺序取决于插入顺序 , 但是顺序对集合没有什么意义 , 也得不到保障 .
如果两个元素具有相同的哈希码 , 则顺序取决于哪个元素先被添加到集合里 .
• 向集合中添加元素后 , 现有元素的顺序可能发生变化 .
这是应为哈希表使用率超过三分之二后 , 算法效率会有所下降 , Python可能需要移动和调整哈希表大小 ,
然后重新插入元素 , 导致元素的相关顺序发生变化 .
接下来讲解丰富的集合运算 .
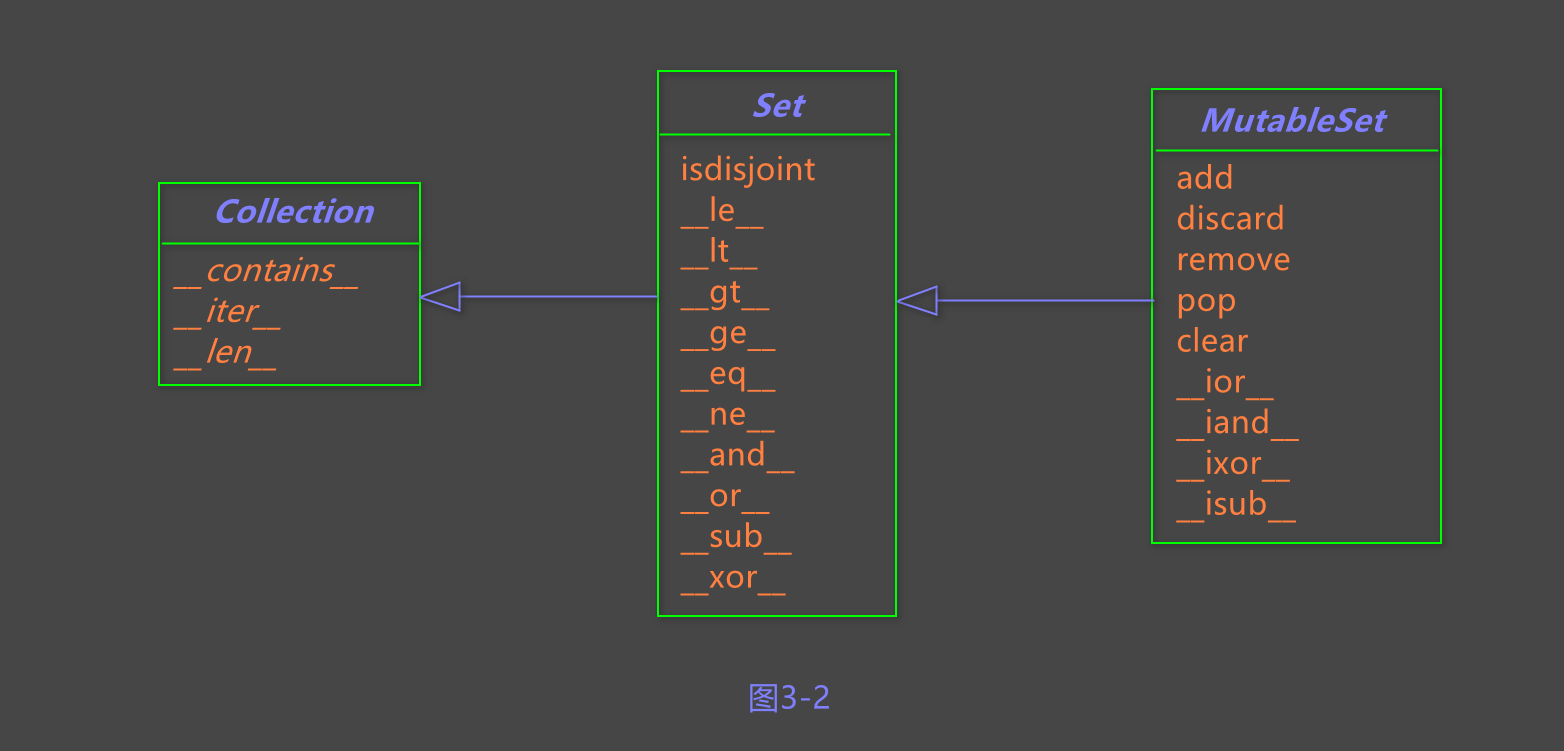
图 3 - 2 概括了可变和不可变集合使用的方法 .
其中很多方法是重载运算符 ( 例如 & 和 > = ) 的特殊方法 .
表 3 - 2 列出数学上的集合运算符和对应的Python运算符或方法 .
注意 , 一些运算符和方法就地更改目标集合 , 例如 & = , difference_update等 .
这样的运算对理想世界中的数学集合没有意义 , 而且frozenset没有实现 .
* ------------------------------------------------------------------------------------------- *
表 3 - 2 列出的中缀运算符要求两个操作数均为集合 , 其他方法则接受一个或多个可迭代对象参数 .
比如说 , 为了计算 4 个容器a , b , c和d的并集 , 可以调用a . union ( b , c , d ) , 其中a必须是集合 ,
而b , c和d可以使任何类型的可迭代对象 , 只要项是可哈希的对象即可 .
Python3 . 5 实现 'PEP 448--Additional Unpacking Generalizations' 之后 ,
如果你想要使用 4 个可迭代对象合并后的结果创建一个集合 ,
那么无须在现有的集合上更新 , 加可以使 { * a , * b , * c , * d } 句法 .
* ------------------------------------------------------------------------------------------- *
图 3 - 2 : MutableSet及其子类collentions . abc中的超类的简化UML类图
( 以斜体显示的名称是抽象类和抽象方法 : 简单起见 , 省略了反向运算符方法 )
∩ 交集
⊂ A⊂B , A属于B
⊃ A⊃B , A包括B
∈ a∈A , a是A的元素
⊆ A⊆B , A不大于B
⊇ A⊇B , A不小于B
Ø 空集
表 3 - 2 : 集合数学运算符 * 要么生成一个新集合 , 要么就地更新可变集合 )
数学符号 Python运算符 方法 说明
S ∩ Z s & z s . __add__ ( z ) s和z的交集
z & s s . __radd__ ( z ) 反向 & 运算符
s . intersection ( it , . . . ) s和根据可迭代对象it等构建的集合的交集
s & = z s . __iadd__ ( z ) 使用s和z的交集更新s
s . intersection_update ( it , . . . ) 使用s和根据可迭代对象it等
构建的集合的交集更新s
S ∪ Z s | z s . __or__ ( z ) s和z的并集
z | s s . __ror__ ( z ) 反向 | 运算符
s . union ( it , . . . ) s和根据可迭代对象it等构造的集合的并集
s | = z s . __ior__ ( z ) 使用s和z的并集更新s
s . update ( it , . . . ) 使用s和根据可迭代对象it等
构建的集合的并集更新s
S \ Z s - z s . __sub_ ( z ) s和z的相对补集 ( 或差集 )
z - s s . __rsub__ ( z ) 反向-运算符
s . difference ( it , . . . ) s和根据可迭代对象it等构建的集合的差集
s - = z s . __isub__ ( z ) 使用s和z的差集更新s
s . differrnce_update ( it , . . . ) 使用s和根据可迭代对象id等
构建的集合差集更新s
S△Z s ^ z s . __xor__ ( z ) 对称差集 ( s & z的补集 )
z ^ s s . __rxor__ ( z ) 反向 ^ 运算符
s . symmetric_difference ( it ) s & set ( it ) 的补集
s ^ = z s . __ixor__ ( z ) 使用s和z的对称差集跟新s
s . symmetric_difference_update ( it , . . . ) 使用s和根据可迭代对象it等
构建的集合的对称差集更新s
表 3 - 3 列出了集合谓词 , 即返回True或False的运算符和方法 .
表 3 - 3 : 返回布尔值的集合比较运算符和方法
数学符号 Python运算符 方法 说明
S ∩ Z = Ø s . isdisjoint ( z ) s和z不相交 ( 没有共同元素 )
e ∈ S e in s s . __contains__ ( e ) 元素e是s的成员
S ⊆ Z s < = z s . __le__ ( z ) s是z的子集
s . issubset ( it ) s是由可可迭代对象it构建的集合的子集
A ⊂ Z s < z s . __lt__ ( z ) s是z的真子集
S ⊇ s > = z s . __ge__ ( z ) s是z的超集
s . issuperset ( it ) s是由可迭代对象it构建的集合的超级
S ⊃ Z s > z s . __gt__ ( z ) s是z的真超集
除了源自数学集合论的运算符和方法之外 , 集合类型还实现了一些其他实用方法 , 如表 3 - 4 所示 .
表 3 - : 集合的其他方法
方法 set frozenset 说明
s . add ( e ) • 把元素e添加到s中
s . clear ( ) • 删除s中的全部元素
s . copy ( ) • • 浅拷贝s
s . discard ( e ) • 从s中删除元素e ( 如果存在e )
s . __iter__ ( ) • • 获取遍历s的迭代器
s . __len__ ( ) • • len ( s )
s . pop ( ) • 从s中删除并返回一个元素 , 如果s为空 , 则抛出KeyError
s . remove ( ) • 从s中删除元素e , 如果e不在s中 , 则抛出KeyError
对集合功能的概述到此结束 .
3.12 节将兑现 3.8 节的承诺 , 探讨与frozenset行为非常相似的两种字典视图 .
. keys ( ) 和 . items ( ) 这两个dict方法返回的视图对象与frozenset极为相似 , 如表 3 - 5 所示 .
表 3 - 5 : frozenset , dict_keys和dict_items实现的方法
方法 frozenset dict_keys dict_values 说明
s . __add__ ( z ) • • • s $ z ( s和z的交集 )
s . __rand__ ( z ) • • • 反向 & 运算符
s . __contains__ ( ) • • • e in s
s . copy ( ) • 浅拷贝s
s . difference ( it , . . . ) • s和可迭代对象it的差集
d . intersection ( it , . . ) • s和可迭代对象it的交集
s . isdisjoint ( z ) • • • s和z不相交 ( 没有共同的元素 )
s . issubset ( it ) • s是可迭代对象it的子集
s . issuperset ( it ) • s是可迭代对象的超集
s . __iter__ ( ) • • • 获取遍历s的迭代器
s . __len__ ( ) • • • len ( s )
s . __or__ ( z ) • • • s | z ( s和z的并集 )
s . __ror__ ( ) • • • 反向 | 运算符
s . __reversed__ ( ) • • 获取逆序遍历s的迭代器
s . __sub__ ( z ) • • • s - z ( s和z的差集 )
s . __rsub__ ( z ) • • • 反向-运算符
s . symmetric_difference ( it ) • s & set ( it ) 的补集
s . union ( it , . . . ) • s和可迭代对象it等的并集
s . __xor__ ( ) • • • s ^ z ( s和z的对称差集 )
s . __rxor__ ( ) • • • 反向 ^ 运算符
需要特别注意的是 , dict_keys和dict_items实现了一些特殊方法 , 支持强大的集合运算符 ,
包括 & ( 交集 ) , | ( 并集 ) , - ( 差集 ) 和 ^ ( 对称集 ) .
例如 , 使用 & 运算法可以轻易获取两个字典都有的键 .
>> > d1 = dict ( a= 1 , b= 2 , c= 3 , d= 4 )
>> > d2 = dict ( b= 20 , d= 40 , e= 50 )
>> > d1. keys( ) & d2. keys( )
{ 'b' , 'd' }
注意 , & 运算符返回一个set .
更方便的是 , 字典视图的集合运算符均兼容set示例 , 如下所示 .
>> > s = { 'a' , 'e' , 'i' }
>> > d1. keys( ) & s
{ 'a' }
>> > d1. keys( ) | s
{ 'a' , 'c' , 'b' , 'd' , 'i' , 'e' }
* * * ----------------------------------------------------------------------------------------- * * *
仅当dict中所有值均可哈希时 , dict_items视图才可当作集合使用 .
倘若dict中有不可哈希的值 , 对dict_items视图做集合运算将抛出TypeError :
unhashable type 'T' , 其中T是不可哈希的类型 .
相反 , dict_keys视图实始终可当作集合使用 , 因此按照其设计 , 因为按照其设计 , 所有键均可哈希 .
* * * ----------------------------------------------------------------------------------------- * * *
使用集合运算符处理视图可以省去大量循环和条件判断 .
繁重工作都可以交给C语言实现的Python高效完成 .
字典是Python的基石 .
近些年 , 我们熟悉的字面量句法 { k1 : v1 , k1 : v2 } 有所增强 , 现在支持使用 * * 拆包 , 模式匹配和字典推导式 .
除了基本的dict之外 , 标准库中的collections模块还提供了随取随存的专门映射 ,
例如 , defaultdict , ChainMap , Counter .
重新实现dict之后 , OrderedDict不像以前那样有用了 , 但仍然应该留在标准库中 , 一方面是为了向后兼容 ,
另一方面OrseredDict还有一些特殊是dict不具备的 , 例如比较运算符 = = 把键的顺序纳入考虑范围 .
collections模块中的UserDict是一个基类 , 供用户自定义映射 .
多数映射具有两个强大的方法 , setdefault和update .
setdefault方法可以更新可变值的项 ( 例如list值 ) , 从而避免再次搜索相同的键 .
update方法可以批量插入或覆盖项 , 项可以来自提供键值对的可迭代对象 , 也可以来自关键字参数 .
映射构造函数在内部也使用update , 以便你根据映射 , 可迭代对象或关键字参数初始化实例 .
从Python3 . 9 开始 , hiahia可以使用 | = 运算符更新映射 , 以及使用 | 运算符根据两个映射的合集创建新映射 .
映射API中的__missing__方法是一个巧妙的钩子 ,
利用它可以自定义d [ k ] 句法 ( 调用__getitem__ ) 找不到键时的行为 .
( 抽象基类是Python中用于定义接口的类 , 它们不能直接实例化 , 而是用作其他类的基类 .
抽象基类定义了一组方法 , 子类需要实现这些方法以符合接口规范 . )
collections . abc模块中的抽象基类Mapping和MutableMapping定义标准接口 , 可以运行时检查类型 .
types模块中的MappingProxyType为映射包装了一层不可变外壳 , 防止意外更改映射 .
Set和MutableSet也有抽象基类 .
Python3引入的字典视图实一个很好的特性 ,
消除了Python2中 . keys ( ) , . values ( ) 和 . items ( ) 方法开销的内存 , 不用再构建列表 , 重复目标dict实例中的数据 .
此外dict_keys和dict_items类还支持frozenset的一些最有用的运算符 ,
Python标准库文档中的 'collections--Container datatypes' 有一些示例个实践技巧 , 涵盖多种映射类型 .
如果你想创建新映射类型 , 或者了解现有映射的逻辑 ,
collections模块的Python源码 ( Lib / collections / __init__ . py ) 是不可错过的参考 .
< < Python Cookbook 中文版 ( 第 3 版 ) > > 第 1 章有 20 个实用的经典示例 ,
深入挖掘数据结果的用法 , 尤其是dict的使用技巧 .
Greg Gandenberger在 'Python Dictionaries Are Now Ordered. Keep Keep Using OrderedDict'
一文中提倡继续使用collections . OrderedDict , 理由有三 :
一是 '明确胜于模糊' , 二是向后模式 , 三是一些工具和库假定dict键的顺序无关紧要 .
( 第三点的意思 : 这些工具和库可能会将字典视为无序的数据结构 , 并假设字典的键的顺序对其功能没有影响 .
因此 , 如果你在使用这些工具或库时使用了普通的字典 ( dict ) 它们可能会忽略或更改键的顺序 . )
Guido van Rossum在 'PEP 3106--Revamping dict.keys(), .values() and .items()'
中提出为Python3增加字典视图功能 .
摘要指出 , 这个想法源自Java Collections Framework .
在几个Python解释器中 , PyPy第一个实现了Raymond Hettinger提议的紧凑字典 ,
详见博客文章 'Faster, more memory efficient and more ordered dictionaries on PyPy' .
文中承认 , PHP7也采用了类似地布局 , 详见 "PHP's new hashtable implementation" 一文 .
指明出处值得肯定 .
在PyCon2017 , Brandon Rhodes做了题为 'The Dictionary Even Mightier' 的演讲 ,
这是经典动画演讲 'The Mighty Dictonary' 的续集 , 用动画演示了哈希碰撞 .
Paymond Hettinger的演讲 'Modern Dictionary' 对dict的内部机制剖析更为深入 .
在演讲中他提到 , 最初他先向CPython核心开发团队建议实现更紧凑字典 , 但无果而终 , 后来成功游说PyPy团队 ,
引起CPython团队的关注 , 而后由INADA Naoki在CPython3 . 6 中实现 .
详细信息参阅CPython源码Objects / dictobject . c中的大量注释和设计文档Objects / dictnotes . txt .
为Python添加集合的根本原因见 'PEP 218--Addding a Built-In Set Object Type' .
PEP218被批准时 , 尚未为集合提供专门的子面量句法 .
set字面量 , 连同字典和拖导式 , 在Python3中才实现 , 并向后移植到Python2 . 7.
在PyCon2019 , 我做了题为 "Set Practice: learning from Python's set types" 的演讲 ,
通过具体的程序说明了集合的用途 , 介绍了集合API的设计思路和uintset的实现方式 .
uintset是一个存放整数元素的集合类 , 使用的是位向量 , 而不是哈希表 ,
灵感来自 < < Go 程序设计语言 > > 第 6 章的一个示例 .
IEEE出版的杂志Spectrum有一篇关于Hans Peter Luhn的报道 ,
他是一位多产的发明家 , 增获得一种穿孔片组的专利 , 根据可用的成分选择鸡尾酒配方 .
在他众多的发明中就包括哈希表 . 详见 : 'Hans Peter Luhn and the Birth of the Hashong Algorithm' 一文 .
* --------------------------------------------杂谈--------------------------------------------- *
语法糖
我的朋友Geraldo Cohen 说过 , Python '简单又正确' .
编程语言纯粹主义者认为句法并不重要 .
语法糖诱发分号癌 .
---- Alan Perlis
句法是编程语言的用户界面 , 在实践中很重要 .
发现Python之前 , 我使用Perl和PHP做过一些web编程 .
这些语言的映射句法非常好用 , 在不得不使用Java或C语言的日子里 , 总是令我怀念 .
好的映射字面量句法用着十分便利 , 方便配置 , 方便实现表驱动设计 , 还方便存放原型设计和测试数据 .
Go语言的设计人员就从动态语言中学到了这一点 .
由于缺乏在代码中表达结构化数据的好方法 , Java社区不得不采用烦琐的XML作为数据格式 .
JSON是XML的一种替代方案 , 取繁从件 , 取得了巨大成功 , 在很多情况下可以取代XML .
列表格字典的句法简单明了 , 使JSON成为一种出色的数据交换格式 .
PHP和Ruby模仿Perl的哈希句法 , 使用 = > 链接键和值 .
JavaScript与Python一眼 , 使用 : 一个字符串就能表明意图 , 为什么要用两个呢? ⑪
( 注 11 : 从Ruby1 . 9 开始 , 如果哈希的键时Symbol类型 , 也可以使用 : 字符 . --译者注 )
JSON源自于JavaScript , 无巧不成书 , 它几乎就是Python句法的子集 .
除了 true , false 和null等值的拼写不一样之外 , JSON与Python几乎完全兼容 .
Armin Ronacher在一篇推文中说 ,
他喜欢在Python的全局命名空间中为Python的True , False和None添加兼容JSON的别名 ,
这样就可以直接把JSON粘贴到Python控制台中了 , 就像下面这样 .
> > > true , false , null = True , False , None
> > > fruit = {
. . . "type" : "banana" ,
. . . "avg_weight" : 123.2 ,
. . . "edible_peel" : false ,
. . . "species" : [ "acuminata" , "balbisiana" , "paradisiace" ] ,
. . . "issues" : null ,
. . . }
> > > fruit
{ 'type' : 'banana' , 'avg_weight' : 123.2 , 'edible_peel' : False ,
'species' : [ 'acuminata' , 'balbisiana' , 'paradisiace' ] , 'issues' : None }
现在 , 人人都使用Python的dict和list句法交换数据 .
如今 , 句法越来越便利 , 还能保留插入顺序 .
真是简单又正确 .
* --------------------------------------------------------------------------------------------- *



























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









