







目录
以下为论文《Deep Residual Learning for Image Recognition》的一些摘抄。
1.研究背景
深度卷积神经网络在图像分类领域取得一系列突破。深度网络自然地将一个端到端多层模型中的低/中/高级特征以及分类器整合起来,而特征的“等级”可以通过堆叠层的数量(深度)来丰富。模型的深度发挥着至关重要的作用,许多视觉识别任务也都受益于非常深的模型。
2.目前研究存在的问题
在一个合理的网络模型中,随着网络深度的增加,准确率会趋于饱和并迅速衰落,这种退化问题不是由过拟合造成的。退化问题使得网络达不到一定的深度,无法得到更高的准确率。
3.本文贡献
本文针对随网络深度增加时发生的退化问题,提出了一个新的网络结构——深度残差网络。本文给出了多种深度残差网络,在原本的网络中引入恒等映射Shortcuts产生x分量,使得非线性层拟合的函数变为F(x)=H(x)-x,则原来的映射变为F(x)+x,这使得网络可以更快地收敛,网络模型也更易于优化。本文构建的残差网络在ImageNet2012数据集和CIFAR-10数据集上进行了测试,并和其他网络模型进行了对比,整体上准确率均高于其他模型。
4.文本模型
本文中网络模型是在Plain网络模型的基础上添加shortcuts连接形成残差网络的。当输入与输出维度相同时,残差网络构建块的输入输出关系为:;当输入和输出维度不同时,残差网络构建块的输入输出关系为:,即通过的卷积来使输入输出维度相同。shortcuts连接有无参数恒等shortcuts和映射shortcuts两种。其中映射shortcuts有三种具体方法:①对增加的维度使用0填充,所有的shortcuts是无参数的②对增加的维度使用映射shortcuts,其它使用恒等shortcuts③所有的都是映射shortcuts。
4.1构建块
本文给出了残差网络的两种构建块。
第一种是两层卷积的构建块(如图4-1所示),输入为64维度的数据,第一层为卷积核为33的卷积层,经过激活函数后进入第二层卷积层,卷积核大小也为33。第二层的输出与第一层输入的shortcuts连接进行相加,将相加结果经过激活后得到输出结果,输出也为64维度的数据,其中shortcuts连接可采用不同的方法。
第二种是三层卷积的构建块(如图4-2所示),输入为256维度的数据,第一层卷积核为11的卷积层,经过激活函数后进入第二层卷积层,卷积核大小为33,然后再经过11的卷积层,得到的结果与shortcuts连接进行相加,经激活后输出。因为卷积层的卷积核大小,这种构造块也称为深度瓶颈结构。第一个11卷积层可以减少维度,中间的33卷积层可以减少输入和输出的维度,第二个11卷积层可以恢复维度。正是因为这种瓶颈结构,当采用映射shortcuts时,时间复杂度和模型尺寸会大大增加,所以其一般采用恒等shortcuts进行连接。
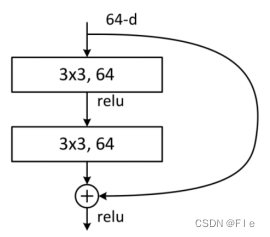
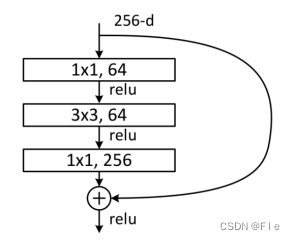
4.2残差网络
本文通过上面的两种构建块的堆叠搭建了如图4-3所示的5种网络,分别为Resnet-18、Resnet-34、Resnet-50、Resnet-101和Resnet-152。以Resnet-18为例,首先是经过1个77的卷积,然后经过一个33的池化,接下来就是构建块,总共8个两层卷积构造块,即16层卷积,最后进行池化输出。
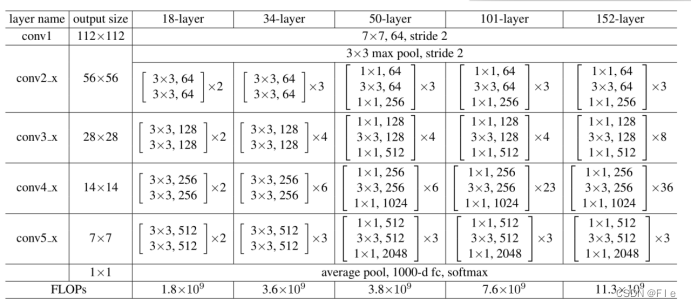
5.模型训练
本文搭建的不同残差网络分别在ImageNet2012数据集和CIFAR-10数据集上做了测试。损失函数使用训练结果与标签的交叉熵,评价指标是训练错误率和测试错误率。
5.1 ImageNet2012
(1)plain与ResNet的对比
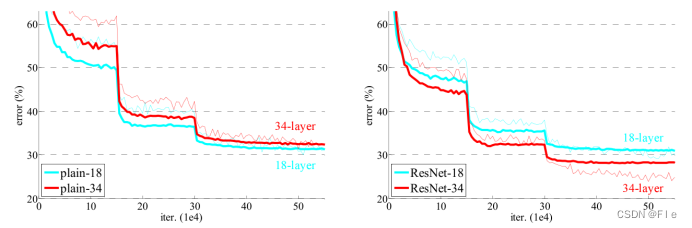
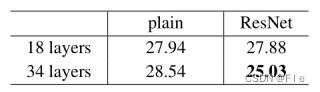
从训练结果可以得出3点结论:
①与plain网络相反,34层的ResNet比18层ResNet的结果更优,这表明了残差网络可以很好的解决退化问题。
②与对应的plain网络相比,34层的ResNet在top-1 错误率上降低了3.5%,这验证了在极深的网络中残差学习的有效性。
③18层的plain网络和残差网络的准确率很接近,但是ResNet的收敛速度要快得多。这说明ResNet能够使优化得到更快的收敛。
(2)不同映射shortcuts对比和ResNet不同深度对比
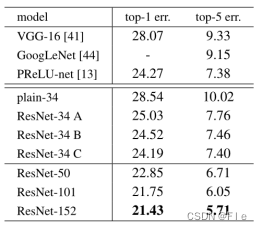
A、B、C表示三种不同的映射shortcuts连接,从结果看7.76、7.74、7.4差别并不大,说明映射shortcuts对于解决退化问题并不是必需的;可以看出50层、101层、152层的残差网络误差越来越小,这说明可以通过增加层数来达到提高准确率的效果。
5.2 CIFAR-10
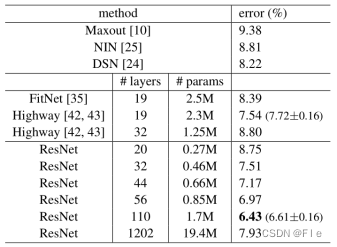
在CIFAR-10数据集上出现了与ImageNet2012同样的效果,误差随着层数的增加而减小,这说明了残差网络具有良好的泛化能力。
6.复现
受限于计算机算力,代码复现选择复现ResNet-18和RestNet-50,采用的数据集是CIFAR-10,最后基于RestNet-50设计一个简单界面,展示模型的预测效果。
6.1代码大致结构
①构建块
创建一个类ResidualBlock表示图4-1或者图4-2所示的结构
②残差网络搭建
创建一个类ResNet,在类里面使用ResidualBlock类堆叠搭建。
③准备数据集并训练
定义损失函数、batch_size、学习率和优化方法;加载CIFAR-10数据集,并分为训练集和测试集;每训练一个batch打印一次损失值和准确率,并记录在log.txt文件中;每训练完一个epoch测试一次准确率,并保存这一次对应的模型参数(.pth文件),同时记录高于85%的epoch及其对应的准确率。

6.2复现过程
①RestNet-18
import torch.nn.functional as F
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import argparse
#残差构建块
class ResidualBlock(nn.Module):
def __init__(self, inchannel, outchannel, stride=1):
super(ResidualBlock, self).__init__()
self.left = nn.Sequential(
nn.Conv2d(inchannel, outchannel, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(outchannel),
nn.ReLU(inplace=True),
nn.Conv2d(outchannel, outchannel, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(outchannel)
)
self.shortcut = nn.Sequential()
#如果输入与输出维度不相同,使用1*1卷积使其相同
if stride != 1 or inchannel != outchannel:
self.shortcut = nn.Sequential(
nn.Conv2d(inchannel, outchannel, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(outchannel)
)
#前向传播
def forward(self, x):
out = self.left(x)
out += self.shortcut(x)
out = F.relu(out)
return out
# ResNet-18搭建
class ResNet(nn.Module):
def __init__(self, ResidualBlock, num_classes=10):
super(ResNet, self).__init__()
self.inchannel = 64
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(),
)
#对应论文中的结构
self.layer1 = self.make_layer(ResidualBlock, 64, 2, stride=1)
self.layer2 = self.make_layer(ResidualBlock, 128, 2, stride=2)
self.layer3 = self.make_layer(ResidualBlock, 256, 2, stride=2)
self.layer4 = self.make_layer(ResidualBlock, 512, 2, stride=2)
self.fc = nn.Linear(512, num_classes)
def make_layer(self, block, channels, num_blocks, stride):
strides = [stride] + [1] * (num_blocks - 1) # strides=[1,1]
layers = []
for stride in strides:
layers.append(block(self.inchannel, channels, stride))
self.inchannel = channels
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv1(x)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
def ResNet18():
return ResNet(ResidualBlock)
# 定义是否使用GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 参数设置
parser = argparse.ArgumentParser(description='PyTorch CIFAR10 Training')
parser.add_argument('--outf', default='./model/', help='folder to output images and model checkpoints') # 输出结果保存路径
parser.add_argument('--net', default='./model/Resnet18.pth', help="path to net (to continue training)") # 恢复训练时的模型路径
args = parser.parse_args()
# 超参数设置
EPOCH = 135 # 遍历数据集次数,这个数据足够大,但是在22次时准确率已经基本不变了,所以就手动退出了
pre_epoch = 0 # 定义已经遍历数据集的次数
BATCH_SIZE = 128 # 批处理尺寸
LR = 0.1 # 学习率
# 准备数据集并预处理
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4), # 先四周填充0,在吧图像随机裁剪成32*32,这里的32决定了输入的图片大小
transforms.RandomHorizontalFlip(), # 图像一半的概率翻转,一半的概率不翻转
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)), # R,G,B每层的归一化用到的均值和方差
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
# 加载数据集
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train) # 训练数据集
trainloader = torch.utils.data.DataLoader(trainset, batch_size=BATCH_SIZE, shuffle=True,
num_workers=2) # 生成一个个batch进行批训练,组成batch的时候顺序打乱取
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=False, num_workers=2)
# Cifar-10的标签
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# 模型定义-ResNet
net = ResNet18().to(device)
# 定义损失函数和优化方式
criterion = nn.CrossEntropyLoss() # 损失函数为交叉熵,多用于多分类问题
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9,
weight_decay=5e-4) # 优化方式为mini-batch momentum-SGD,并采用L2正则化(权重衰减)
# 训练
if __name__ == "__main__":
best_acc = 85 # 2 初始化best test accuracy
print("Start Training, Resnet-18!") # 定义遍历数据集的次数
with open("acc.txt", "w") as f:
with open("log.txt", "w")as f2:
for epoch in range(pre_epoch, EPOCH):
print('\nEpoch: %d' % (epoch + 1))
net.train()
sum_loss = 0.0
correct = 0.0
total = 0.0
for i, data in enumerate(trainloader, 0):
# 准备数据
length = len(trainloader)
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
# forward + backward
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 每训练1个batch打印一次loss和准确率
sum_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += predicted.eq(labels.data).cpu().sum()
print('[epoch:%d, iter:%d] Loss: %.03f | Acc: %.3f%% '
% (epoch + 1, (i + 1 + epoch * length), sum_loss / (i + 1), 100. * correct / total))
f2.write('%03d %05d |Loss: %.03f | Acc: %.3f%% '
% (epoch + 1, (i + 1 + epoch * length), sum_loss / (i + 1), 100. * correct / total))
f2.write('\n')
f2.flush()
# 每训练完一个epoch测试一下准确率
print("Waiting Test!")
with torch.no_grad():
correct = 0
total = 0
for data in testloader:
net.eval()
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
# 取得分最高的那个类 (outputs.data的索引号)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
print('测试分类准确率为:%.3f%%' % (100 * correct / total))
acc = 100. * correct / total
# 将每次测试结果实时写入acc.txt文件中
print('Saving model......')
torch.save(net.state_dict(), '%s/net_%03d.pth' % (args.outf, epoch + 1))
f.write("EPOCH=%03d,Accuracy= %.3f%%" % (epoch + 1, acc))
f.write('\n')
f.flush()
# 记录最佳测试分类准确率并写入best_acc.txt文件中
if acc > best_acc:
f3 = open("best_acc.txt", "w")
f3.write("EPOCH=%d,best_acc= %.3f%%" % (epoch + 1, acc))
f3.close()
best_acc = acc
print("Training Finished, TotalEPOCH=%d" % EPOCH)
输入图片大小为32*32。总共迭代训练了22次。
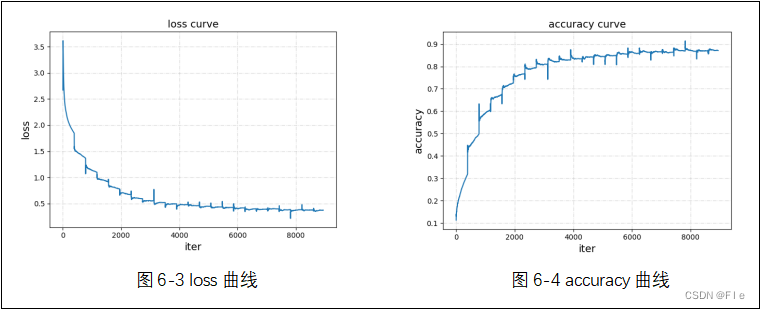
②RestNet-50
import torch
from torch.utils.tensorboard.summary import image
import torchvision
import torch.nn as nn
import torchvision.transforms as transforms
import torch.optim as optim
import argparse
# 参数设置
parser = argparse.ArgumentParser(description='PyTorch CIFAR10 Training')
parser.add_argument('--outf', default='./model/', help='folder to output images and model checkpoints') # 输出结果保存路径
parser.add_argument('--net', default='./model/Resnet18.pth', help="path to net (to continue training)") # 恢复训练时的模型路径
args = parser.parse_args()
#图片转换格式
myTransforms = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))])
#加载数据集
train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True,
transform=myTransforms)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True, num_workers=0)
test_dataset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True,
transform=myTransforms)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=4, shuffle=True, num_workers=0)
# 定义模型
myModel = torchvision.models.resnet50(pretrained=True)
# 将原来的ResNet-50的最后两层全连接层拿掉,替换成一个输出单元为10的全连接层
inchannel = myModel.fc.in_features
myModel.fc = nn.Linear(inchannel, 10)
# GPU加速
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
myModel = myModel.to(device)
# 学习率
learning_rate = 0.001
# 优化器
optimizer = optim.SGD(myModel.parameters(), lr=learning_rate, momentum=0.9)
# 损失函数
myLoss = torch.nn.CrossEntropyLoss()
if __name__ == "__main__":
best_acc = 85 # 初始化best test accuracy
print("Start Training, Resnet-50!")
with open("acc.txt", "w") as f:
with open("log.txt", "w")as f2:
# 这里先定义迭代20次,但是加载了预训练模型,在第三次已近达到97%,就手动退出了
for epoch in range(0, 20):
print('\nEpoch: %d' % (epoch + 1))
sum_loss = 0.0
correct = 0.0
total = 0.0
for i, data in enumerate(train_loader, 0):
# 准备数据
length = len(train_loader)
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
outputs = myModel.forward(inputs)
loss = myLoss(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 每训练1个batch打印一次loss和准确率
sum_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += predicted.eq(labels.data).cpu().sum()
print('[epoch:%d, iter:%d] Loss: %.03f | Acc: %.3f%% '
% (epoch + 1, (i + 1 + epoch * length), sum_loss / (i + 1), 100. * correct / total))
f2.write('%03d %05d |Loss: %.03f | Acc: %.3f%% '
% (epoch + 1, (i + 1 + epoch * length), sum_loss / (i + 1), 100. * correct / total))
f2.write('\n')
f2.flush()
# 每训练完一个epoch测试一下准确率
print("Waiting Test!")
with torch.no_grad():
correct = 0
total = 0
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = myModel(images)
# 取得分最高的那个类 (outputs.data的索引号)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
print('测试分类准确率为:%.3f%%' % (100 * correct / total))
acc = 100. * correct / total
# 将每次测试结果实时写入acc.txt文件中
print('Saving model......')
torch.save(myModel.state_dict(), '%s/net_%03d.pth' % (args.outf, epoch + 1))
f.write("EPOCH=%03d,Accuracy= %.3f%%" % (epoch + 1, acc))
f.write('\n')
f.flush()
# 记录最佳测试分类准确率并写入best_acc.txt文件中
if acc > best_acc:
f3 = open("best_acc.txt", "w")
f3.write("EPOCH=%d,best_acc= %.3f%%" % (epoch + 1, acc))
f3.close()
best_acc = acc
print("Training Finished, TotalEPOCH=%d" % 100)
为了提高预测准确率,输入图片大小为224*224。总共迭代训练了3次。
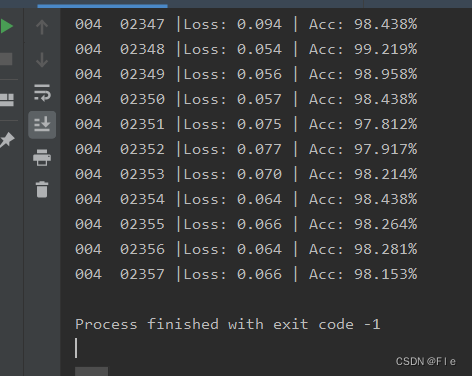
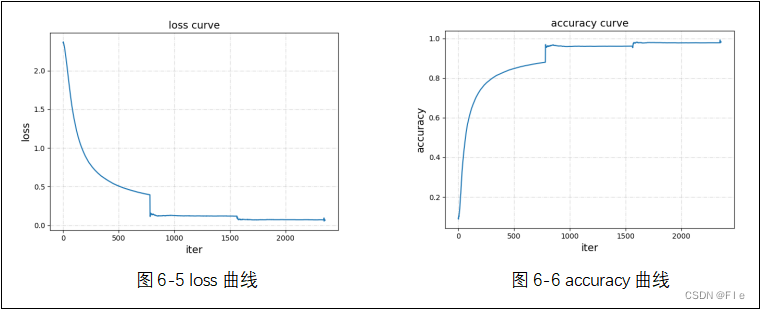
③界面展示
界面.py:
# -*- coding: utf-8 -*-
# Form implementation generated from reading ui file 'pyqt'
#
# Created by: PyQt5 UI code generator 5.15.4
#
# WARNING: Any manual changes made to this file will be lost when pyuic5 is
# run again. Do not edit this file unless you know what you are doing.
from PyQt5 import QtCore, QtGui, QtWidgets
class Ui_Dialog(object):
def setupUi(self, Dialog):
Dialog.setObjectName("Dialog")
Dialog.resize(1046, 621)
self.gridLayout = QtWidgets.QGridLayout(Dialog)
self.gridLayout.setObjectName("gridLayout")
spacerItem = QtWidgets.QSpacerItem(40, 20, QtWidgets.QSizePolicy.Fixed, QtWidgets.QSizePolicy.Minimum)
self.gridLayout.addItem(spacerItem, 2, 0, 1, 1)
spacerItem1 = QtWidgets.QSpacerItem(40, 20, QtWidgets.QSizePolicy.Fixed, QtWidgets.QSizePolicy.Minimum)
self.gridLayout.addItem(spacerItem1, 2, 2, 1, 1)
spacerItem2 = QtWidgets.QSpacerItem(20, 40, QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Fixed)
self.gridLayout.addItem(spacerItem2, 4, 1, 1, 1)
self.label_title = QtWidgets.QLabel(Dialog)
font = QtGui.QFont()
font.setFamily("Adobe 黑体 Std R")
font.setPointSize(24)
self.label_title.setFont(font)
self.label_title.setContextMenuPolicy(QtCore.Qt.DefaultContextMenu)
self.label_title.setFrameShape(QtWidgets.QFrame.Box)
self.label_title.setFrameShadow(QtWidgets.QFrame.Plain)
self.label_title.setObjectName("label_title")
self.gridLayout.addWidget(self.label_title, 2, 1, 1, 1)
self.horizontalLayout_3 = QtWidgets.QHBoxLayout()
self.horizontalLayout_3.setObjectName("horizontalLayout_3")
self.label_img = QtWidgets.QLabel(Dialog)
self.label_img.setFrameShape(QtWidgets.QFrame.Box)
self.label_img.setObjectName("label_img")
self.horizontalLayout_3.addWidget(self.label_img)
self.verticalLayout = QtWidgets.QVBoxLayout()
self.verticalLayout.setObjectName("verticalLayout")
self.horizontalLayout = QtWidgets.QHBoxLayout()
self.horizontalLayout.setObjectName("horizontalLayout")
self.label_label = QtWidgets.QLabel(Dialog)
font = QtGui.QFont()
font.setFamily("方正舒体")
font.setPointSize(20)
self.label_label.setFont(font)
self.label_label.setObjectName("label_label")
self.horizontalLayout.addWidget(self.label_label)
self.label_label_name = QtWidgets.QLabel(Dialog)
font = QtGui.QFont()
font.setFamily("方正舒体")
font.setPointSize(20)
self.label_label_name.setFont(font)
self.label_label_name.setObjectName("label_label_name")
self.horizontalLayout.addWidget(self.label_label_name)
self.verticalLayout.addLayout(self.horizontalLayout)
spacerItem3 = QtWidgets.QSpacerItem(20, 40, QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Fixed)
self.verticalLayout.addItem(spacerItem3)
self.horizontalLayout_2 = QtWidgets.QHBoxLayout()
self.horizontalLayout_2.setObjectName("horizontalLayout_2")
self.label_acc = QtWidgets.QLabel(Dialog)
font = QtGui.QFont()
font.setFamily("方正舒体")
font.setPointSize(20)
self.label_acc.setFont(font)
self.label_acc.setObjectName("label_acc")
self.horizontalLayout_2.addWidget(self.label_acc)
self.label_acc_value = QtWidgets.QLabel(Dialog)
font = QtGui.QFont()
font.setFamily("方正舒体")
font.setPointSize(20)
self.label_acc_value.setFont(font)
self.label_acc_value.setObjectName("label_acc_value")
self.horizontalLayout_2.addWidget(self.label_acc_value)
self.verticalLayout.addLayout(self.horizontalLayout_2)
spacerItem4 = QtWidgets.QSpacerItem(20, 40, QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Fixed)
self.verticalLayout.addItem(spacerItem4)
self.pushButton = QtWidgets.QPushButton(Dialog)
font = QtGui.QFont()
font.setFamily("方正舒体")
font.setPointSize(20)
self.pushButton.setFont(font)
self.pushButton.setObjectName("pushButton")
self.verticalLayout.addWidget(self.pushButton)
self.horizontalLayout_3.addLayout(self.verticalLayout)
self.gridLayout.addLayout(self.horizontalLayout_3, 3, 1, 1, 1)
spacerItem5 = QtWidgets.QSpacerItem(20, 40, QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Fixed)
self.gridLayout.addItem(spacerItem5, 1, 1, 1, 1)
self.retranslateUi(Dialog)
QtCore.QMetaObject.connectSlotsByName(Dialog)
def retranslateUi(self, Dialog):
_translate = QtCore.QCoreApplication.translate
Dialog.setWindowTitle(_translate("Dialog", "Dialog"))
self.label_title.setText(_translate("Dialog", "TextLabel"))
self.label_img.setText(_translate("Dialog", "TextLabel"))
self.label_label.setText(_translate("Dialog", "TextLabel"))
self.label_label_name.setText(_translate("Dialog", "TextLabel"))
self.label_acc.setText(_translate("Dialog", "TextLabel"))
self.label_acc_value.setText(_translate("Dialog", "TextLabel"))
self.pushButton.setText(_translate("Dialog", "PushButton"))
main.py:
import sys
import torchvision
from PyQt5 import QtCore, QtGui
from PyQt5.QtWidgets import *
from PyQt5.QtCore import Qt
from PyQt5.QtGui import QIcon
import cv2
import torch.nn.functional as F
import torch
import torch.nn as nn
import torchvision.transforms as transforms
from pyqt import Ui_Dialog
class ShowWindow(QDialog,Ui_Dialog):
def __init__(self):
super(ShowWindow,self).__init__()
self.setupUi(self)
#初始化界面
self.label_label.setText(" 类别:")
self.label_label_name.setText("")
self.label_acc.setText("置信度:")
self.label_acc_value.setText("")
self.label_title.setAlignment(Qt.AlignCenter)
self.label_title.setText("机器学习大作业")
self.pushButton.setText("预测")
self.setWindowTitle("ResNet-50")
self.setWindowIcon(QIcon("logo.ico"))
# 创建定时器,定时器用来定时拍照
self.timer_camera = QtCore.QTimer()
self.user = []
#读取模型
self.model_path = r"net.pth"
self.classes = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']#Fifar-10的10个种类名
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")#有则用GPU
# 将原来的ResNet50的最后两层全连接层拿掉,替换成一个输出单元为10的全连接层
self.net = torchvision.models.resnet50(pretrained=True)
inchannel = self.net.fc.in_features
self.net.fc = nn.Linear(inchannel, 10)
#加载模型参数
self.net.load_state_dict(torch.load(self.model_path))
self.net.eval()
self.camera_init()#摄像头初始化
self.timer_camera.timeout.connect(self.show_camera)#计时结束显示图片
self.timer_camera.start(30)#30ms拍一次照片
# 点击按键进行预测
self.pushButton.clicked.connect(self.slot_btn_recognize)
def camera_init(self):
self.cap = cv2.VideoCapture(0)
def show_camera(self):
flag, self.image = self.cap.read()#读一张图片
show = cv2.resize(self.image, (640, 480))
show = cv2.cvtColor(show, cv2.COLOR_BGR2RGB)
# 将图片显示在了label上
showImage = QtGui.QImage(show.data, show.shape[1], show.shape[0], QtGui.QImage.Format_RGB888)
self.label_img.setPixmap(QtGui.QPixmap.fromImage(showImage))
# 按钮预测事件
def slot_btn_recognize(self):
class_name,acc=self.preict_one_img(self.image, self.model_path)
self.label_label_name.setText(class_name)#预测的类别名
self.label_acc_value.setText(str(acc))#预测正确的概率
def preict_one_img(self,img, model_path):
img = cv2.resize(img, (224, 224))#训练时设置输入为224*224
# 将numpy数据变成tensor
tran = transforms.ToTensor()
img = tran(img)
img = img.to(self.device)
# 将数据变成网络需要的shape
img = img.view(1, 3, 224, 224)
out1 = self.net(img)
out1 = F.softmax(out1, dim=1)
proba, class_ind = torch.max(out1, 1)
proba = float(proba)
class_ind = int(class_ind)
return self.classes[class_ind], round(proba, 3)
if __name__ == "__main__":
app = QApplication(sys.argv)
w = ShowWindow()
w.show()
sys.exit(app.exec_())
6.3参考代码链接
https://blog.csdn.net/TTTSEP9TH2244/article/details/123122902
https://blog.csdn.net/e01528/article/details/83339241
https://blog.csdn.net/TTTSEP9TH2244/article/details/123123067
















 1512
1512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











