







 深度残差学习框架解决了深度网络的退化问题,使得增加网络深度能有效提高图像识别的准确率。通过引入残差学习和捷径连接,尤其是恒等映射,网络能够更容易优化并逼近目标映射。实验表明,残差网络在ImageNet、CIFAR-10等数据集上表现出优越的性能,并在物体检测任务中也取得良好效果。
深度残差学习框架解决了深度网络的退化问题,使得增加网络深度能有效提高图像识别的准确率。通过引入残差学习和捷径连接,尤其是恒等映射,网络能够更容易优化并逼近目标映射。实验表明,残差网络在ImageNet、CIFAR-10等数据集上表现出优越的性能,并在物体检测任务中也取得良好效果。
深度残差学习(Deep Residual Learning for Image Recognition)
He K, Zhang X, Ren S, et al. Deep Residual Learning for Image Recognition[C], CVPR, 2016.
摘要
残差学习框架(residual learning framework):以输入(inputs)为参考,将层(layers)定义为残差学习函数(learning residual functions)
残差网络(residual networks)易于优化,能够通过增加网络深度(depth)提高准确率(gain accuary)。
表示的深度(depth of representations)对许多视觉识别任务(visual recognition tasks)至关重要。
1 引言
深度网络(deep networks)能够提取底层、中层和高层特征(low/mid/high-level features),特征的“层次”可以通过堆叠网络层(stacked layers)的数量(深度)来丰富。
梯度消失、爆炸(vanishing/exploding gradients)问题能够通过初始值标准化(normalized initialization)和层间标准化解决。
退化问题(degradation problem):随着网络深度的增加,网络预测准确率趋于饱和,然后迅速退化。但这种退化并非由过拟合引起,对恰到好处的深度模型(suitable deep model)添加更多的层会导致其训练误差增加。
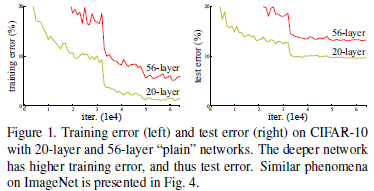
为解决退化问题,本文提出一种深度残差学习框架(residual learning framework)。假设目标映射(desired underlying mapping)为 H ( x ) \mathcal{H}(\mathbf{x}) H(x),则堆叠非线性网络层(stacked nonlinear layers)需拟合(fit)的映射为 F ( x ) : = H ( x ) − x \mathcal{F}(\mathbf{x}) := \mathcal{H}(\mathbf{x}) - \mathbf{x} F(x):=H(x)−x。
本文工作的基础是假设优化残差映射比优化原始目标映射容易。极端情况下,如果恒等映射为最优,则相比于拟合恒等映射,堆叠网络层将残差映射拟合为零更加容易。
捷径连接(shortcut connections):跳过一层或多层的连接。本文中,捷径连接简化为恒等映射(identity mapping),其输出与堆叠网络层的输出相加(Fig.2)。
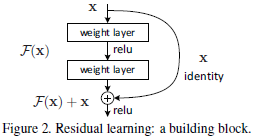
F = W 2 σ ( W 1 x ) \mathcal{F} = \mathbf{W}_2 \sigma(\mathbf{W}_1 \mathbf{x}) F=W2σ(W1x)
σ ( F +
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5107
5107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









