







文章目录
一、基于hadoop与MapReduce的分布式编程
在上一章中,我们使用docker构建了Hadoop的分布式环境镜像,并使用docker run命令从该镜像中部署了一主两从的三个分布式节点:master、worker01、worker02。
执行sudo docker rm命令删除容器
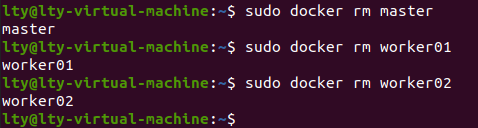
重新部署命令如下:
sudo docker run -p 8088:8088 -p 9000:9000 -v /home/ryu/Documents/hadoop/master/share:/root/share -it -h master --name master <IMAGE NAME>
sudo docker run -v /home/ryu/Documents/hadoop/worker01/share:/root/share -it -h worker01 --name worker01 <IMAGE NAME>
sudo docker run -v /home/ryu/Documents/hadoop/worker02/share:/root/share -it -h worker02 --name worker02 <IMAGE NAME>
并按照实验一进行网络配置



在端口映射上,需要打开9000端口,方便客户端访问分布式文件系统HDFS。
另外,8088端口为Hadoop的应用程序web界面,打开后可以通过web查看应用程序与节点的状态。
通过docker run命令部署仍然稍显麻烦,下一节将介绍使用docker-compose部署容器的方法。
1.通过docker-compose部署容器
1.1安装docker-compose
查询docker版本号。
在host上执行。
sudo docker -v
根据查询到的版本号,在下列网站找到对应的docker-compose版本。
https://github.com/docker/compose/releases
这里,我们使用最新的1.25.5版本。
执行下列命令,安装docker-compose。
docker-compose为单一可执行文件,将其放到/usr/local/bin中,给予文件执行权限即可使用。
当前使用的是1.25.5版本。
sudo curl -L "https://github.com/docker/compose/releases/download/1.25.5/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-compose
或者通过下列网址下载:
https://github.com/docker/compose/releases
1.2编写docker-compose.yml文件
docker-compose.yml将通过配置的方式代替docker run冗长的参数。
具体请参考目录下的docker-compose.yml。
根据docker-compose.yml文件部署镜像
1.3进入docker-compose.yml的目录
sudo docker-compose up -d
通过docker exec命令可以进入启动容器的交互界面。
sudo docker exec -it master bash
sudo docker exec -it worker01 bash
sudo docker exec -it worker02 bash
再次部署容器时,必须删除上一次部署的容器(container)与网络(network)。
在删除容器之前,需要先停止容器。
sudo docker stop <contain id>
Q: 执行部署容器后,产生错误信息:
Pool overlaps with other one on this address space
A: 相同名称的network以及定义,通过以下命令,查询并删除同名network
sudo docker network ls
sudo docker network rm <network id>
Q: 如何删除所有已经退出的容器。
A: sudo docker container prune
2.基于JAVA的MapReduce分布式编程(完成)
检查java环境。
java -version

当前Hadoop的版本号为3.2.1,支持的JDK版本号为8(1.8)。
JAVA编程环境所用的JDK/JRE版本号必须与Hadoop环境的JDK/JRE版本号一致。



参考代码:https://github.com/hbut-edu/BigDataProcessing
2.1 Maven安装与配置(eclipse)
参考文章:
eclipse Maven安装与配置
https://blog.csdn.net/qq_43663493/article/details/104663638
2.2 将Git项目转为Maven项目(eclipse)
以下内容参考文章:
Eclipse使用之将Git项目转为Maven项目
https://blog.csdn.net/yxys01/article/details/77082431
1、打开Eclipse,File->Import
2、Git->Projects from Git

3、Clone URl


5、选择Git分支master(默认勾选即可,点击下一步)
6、选择存放地址

7、选择Import as general project

8、填写项目名

9、删掉刚刚新建的项目(只从Eclipse里面删除,不要删掉本地文件)

10、重新导入项目File->Import->Maven->Existing Maven projects

11、选择刚才从Git下载下来的项目的本地地址

成功将Git项目转化为Maven项目

对上述代码进行修改(ip改成自己master容器ip)

2.3 将maven工程打包成jar包(eclipse)
(以下内容参考文章:将maven工程打成jar包
https://blog.csdn.net/u011723409/article/details/116671296)
1、eclipse中使用命令:
选中项目:右键-> Run As -> Run Configurations,在base directory(workspace)中选中要打包的工程
Goals输入命令:clean package
点击run


在项目文件夹target中可以找到生成的jar包

2.4将jar包从本机传到虚拟机中
参考文章:
将本机文件复制到安装的虚拟机系统中的两种方法
https://blog.csdn.net/qq_41486333/article/details/115259771
虚拟机如何使用共享文件夹传文件
https://blog.csdn.net/weixin_45205599/article/details/121214310?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-1.pc_relevant_default&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-1.pc_relevant_default&utm_relevant_index=1建议安装vmware tools将JAR包传到虚拟机
安装VMware Tools按钮为灰色的解决方法
https://blog.csdn.net/qq_43203949/article/details/121728559
https://blog.csdn.net/tanbitlong/article/details/116205873


或直接拖拽主机文件至虚拟机文件夹
在非RPC模式下,代码和数据的传递方式有所不同。
假设开发环境位于host,那么:
代码:在host环境下编译生成JAR包,需要通过共享文件夹将JAR包传到master容器内部。
数据:在host环境下的数据文件可以直接通过HDFS的API上传至HDFS内部。
数据集地址
链接:https://pan.baidu.com/s/1tkQjDlmhzEu7try6gNJgLw
密码:66pr
输入命令将jar包和数据集文件移动到共享文件夹下:
sudo mv BigDataProcessing-1.0-SNAPSHOT.jar /home/ryu/Documents/hadoop/master/share
sudo mv training_data.csv /home/ryu/Documents/hadoop/master/share

在master查看这两个文件
ls /root/share

按照实验一的步骤启动hadoop
./bin/hdfs namenode -format
./sbin/start-all.sh

在两个worker上用jps查看,有Datanode则代表成功
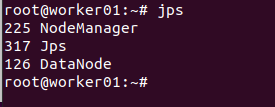
在hdfs新建一个 /input目录
./bin/hdfs dfs -mkdir /input
查看是否创建成功
./bin/hdfs dfs -ls /

将数据集csv文件放到hdfs上刚创建好的文件夹上并查看
./bin/hdfs dfs -put /root/share/training_data.csv /input
./bin/hdfs dfs -ls /input

2.5 运行
./bin/hadoop jar /root/share/BigDataProcessing-1.0-SNAPSHOT.jar cn.edu.hbut.bigdataprocessing.BigDataProcessing

结果可以在output中查看:
./bin/hdfs dfs -ls /output
./bin/hdfs dfs -cat /output/part-r-00000


3.基于Hadoop Streaming与Python的MapReduce分布式编程
Hadoop MapReduce不仅可以使用JAVA进行编程。借助于标准输入输出机制(STDIN/STDOUT)与Hadoop Streaming库可以与几乎所有语言进行连接。
Python是大数据处理领域流行的编程语言,本节将介绍如何使用Python编写MapReduce算法,以及如何提交给Hadoop处理。
3.1 检查运行环境
ls ./share/hadoop/tools/hadoop-streaming-3.2.1.jar
3.2 使用Python编写MapReduce代码
参考目录:BigDataProcessingStreaming
https://github.com/hbut-edu/big-data-processing/tree/master/BigDataProcessingStreaming
在基于Hadoop Streaming的MapReduce编程中,输入为标准输入STDIN,输出为标准输出STDOUT。
3.3 执行MapReduce
./bin/hadoop jar ./share/hadoop/tools/lib/hadoop-streaming-3.2.1.jar \
-files /root/share/BigDataProcessingStreaming/mapper.py,/root/share/BigDataProcessingStreaming/reducer.py \
-input "/input/training_data.csv" \
-output "/output" \
-mapper "python3 mapper.py" \
-reducer "python3 reducer.py"
说明:
和JAVA一样,在使用Hadoop Streaming的时候请注意python代码同样需要事先通过共享文件夹上传到master内部。
示例中,通过-files参数指定上传的文件路径。
和JAVA不同的是,Hadoop Streaming不能对HDFS直接通讯,所以需要事先通过hdfs dfs -put命令将数据文件上传到HDFS内部。
-mapper和-reducer参数用于指定执行任务时候的bash命令。
在执行前,可以先检查一下python解释器命令。这里为python3。
二、Q&A
Q:如何查看输出结果(或HDFS上的文本文件)。
A:使用cat命令。
./bin/hdfs dfs -cat /output/part-00000
Q:如何删除HDFS上的目录。
A:使用-rm -r命令。
./bin/hdfs dfs -rm -r /output*
三、实验任务:
使用Hadoop平台处理数据集,输出数据集中的异常值。
数据集地址
链接:https://pan.baidu.com/s/1tkQjDlmhzEu7try6gNJgLw
密码:66pr
数据集说明(输入)
数据集来源于某地市网络的流量数据,收集了16000+个网元167天的流量数据。
数据集格式:
横坐标为网元数,无header。
纵坐标为天数,无header。
数据中因为采集设备故障等因素有异常值发生。请使用Hadoop与MapReduce以及相关算法计算出每个网元中异常值的数量。
输出格式(以网元为单位)
网元1 10
网元2 15
网元3 9
…
见2.5运行模块
















 332
332











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









