







使用docker构建spark运行环境
一、安装docker与docker-compose
查询docker版本号。
在host上执行。
sudo docker -v
根据查询到的版本号,在下列网站找到对应的docker-compose版本。
https://github.com/docker/compose/releases
这里,我们使用最新的1.25.5版本。
执行下列命令,安装docker-compose。
docker-compose为单一可执行文件,将其放到/usr/local/bin中,给予文件执行权限即可使用。
当前使用的是1.25.5版本。
sudo curl -L "https://github.com/docker/compose/releases/download/1.25.5/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-compose
sudo chmod 777 /usr/local/bin/docker-compose
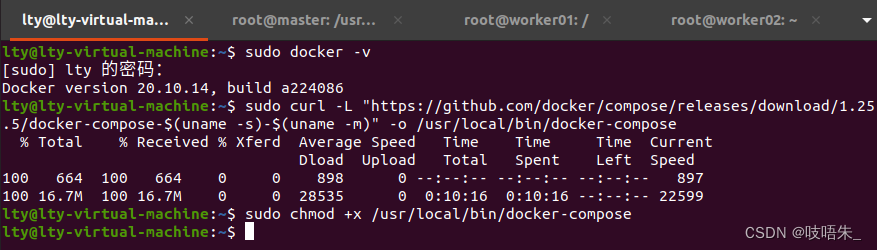
安装docker-compose 最新版本2.4.1 [https://github.com/docker/compose/releases]
二、系统构架图
使用docker hub查找我们需要的镜像。
三、docker compose部署文件
进入文件
vi docker-compose.yml
添加以下内容
version: '3'
services:
spark-master:
image: bde2020/spark-master:3.1.1-hadoop3.2
container_name: spark-master
ports:
- "8080:8080"
- "7077:7077"
volumes:
- <共享目录绝对路径>:/data
environment:
- INIT_DAEMON_STEP=setup_spark
spark-worker-1:
image: bde2020/spark-worker:3.1.1-hadoop3.2
container_name: spark-worker-1
depends_on:
- spark-master
ports:
- "8081:8081"
volumes:
- <共享目录绝对路径>:/data
environment:
- "SPARK_MASTER=spark://spark-master:7077"
spark-worker-2:
image: bde2020/spark-worker:3.1.1-hadoop3.2
container_name: spark-worker-2
depends_on:
- spark-master
ports:
- "8082:8081"
volumes:
- <共享目录绝对路径>:/data
environment:
- "SPARK_MASTER=spark://spark-master:7077"

四、使用yml部署文件部署spark环境
在yml文件所在的目录下,执行命令:
sudo docker-compose up -d
检查docker在命令行的输出确认容器的部署顺利完成。
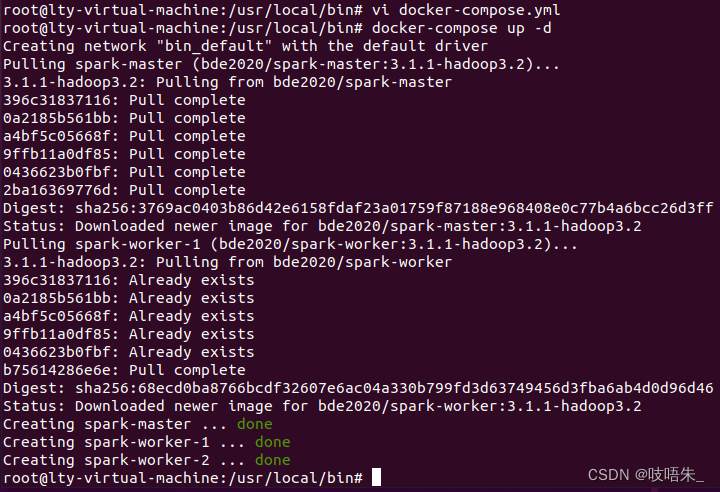
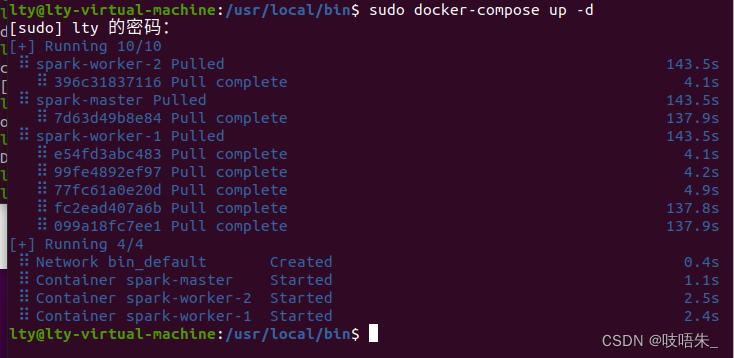
图一为docker compose1.25.5版本下运行截图,图二为2.4.1版本下运行截图
查看容器创建与运行状态
sudo docker ps

对输出进行格式化
sudo docker ps --format '{{.ID}} {{.Names}}'

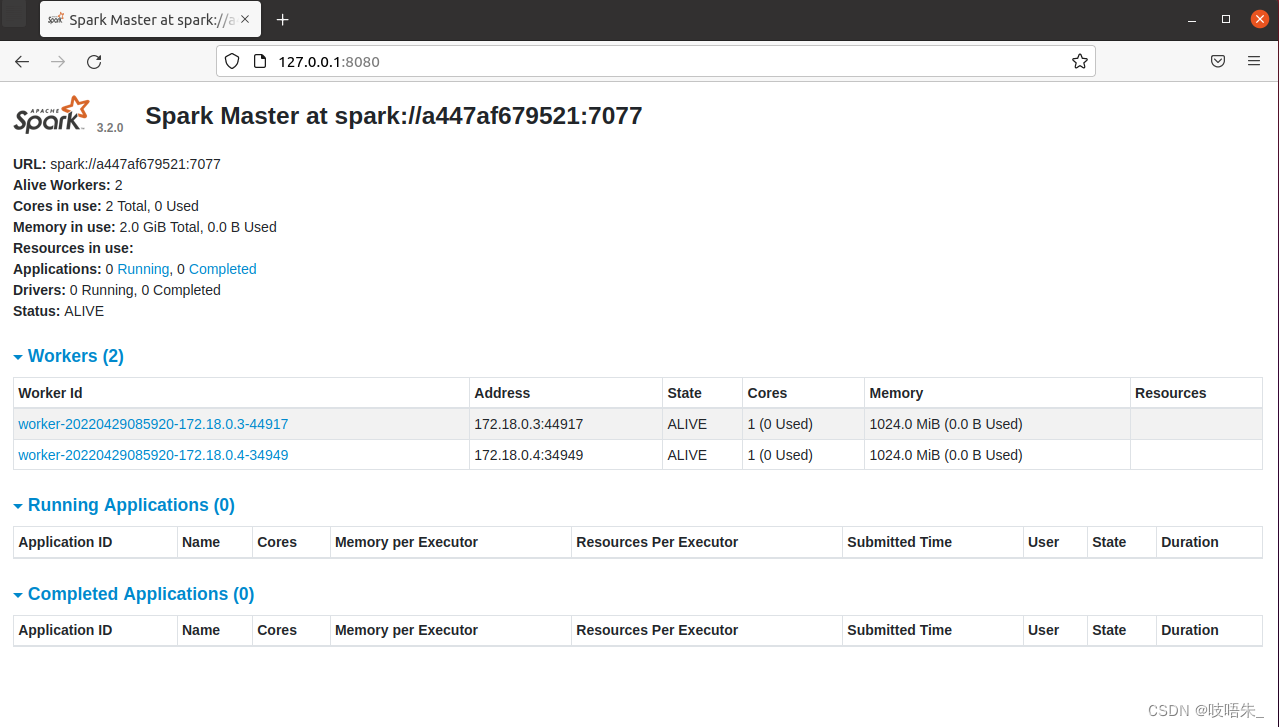
使用浏览器查看master的web ui界面
进入spark-master容器
sudo docker exec -it <master容器的id,仅需输入一部分即刻> /bin/bash
查询spark环境,安装在/spark下面。
ls /spark/bin
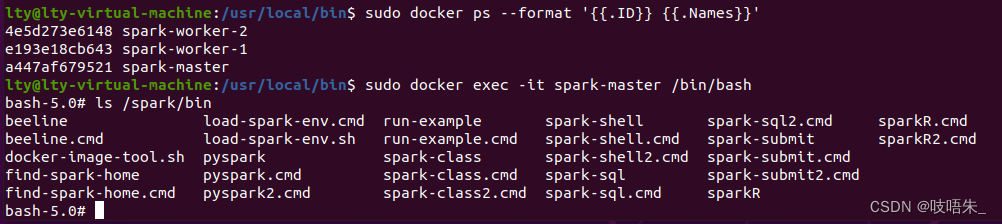
进入spark-shell
/spark/bin/spark-shell --master spark://spark-master:7077 --total-executor-cores 1 --executor-memory 1024m
根据worker内存的具体情况修改cores数量及内存大小

进入浏览器查看spark-shell的状态

五、完成创建RDD与filter处理的实验
创建一个RDD
val rdd=sc.parallelize(Array(1,2,3,4,5,6,7,8))

打印rdd内容
rdd.collect()

查询分区数
rdd.partitions.size

选出大于5的数值
val rddFilter=rdd.filter(_ > 5)

打印rddFilter内容
rddFilter.collect()

退出spark-shell
:quit


















 1428
1428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









