







使用mllib完成mnist手写识别任务
小提示:通过restart命令重启已经退出了的容器:
sudo docker restart <contain id>
一、准备数据集
1.下载数据集并解压
http://yann.lecun.com/exdb/mnist/

2.执行程序生成.libsvm文件
将解压得到的数据集文件与csv_to_libsvm.py和mnist_to_csv.py文件(见下方代码)放置在同一目录下
先执行mnist_to_csv.py
def convert(imgf, labelf, outf, n):
f = open(imgf, "rb")
o = open(outf, "w")
l = open(labelf, "rb")
f.read(16)
l.read(8)
images = []
for i in range(n):
image = [ord(l.read(1))]
for j in range(28 * 28):
image.append(ord(f.read(1)))
images.append(image)
for image in images:
o.write(",".join(str(pix) for pix in image) + "\n")
f.close()
o.close()
l.close()
# 数据集在 http://yann.lecun.com/exdb/mnist/ 下载
convert("train-images.idx3-ubyte", "train-labels.idx1-ubyte",
"mnist_train.csv", 60000)
convert("t10k-images.idx3-ubyte", "t10k-labels.idx1-ubyte",
"mnist_test.csv", 10000)

执行完成后在根目录下产生以下两个.csv文件:
mnist_train.csv
mnist_test.csv
再执行csv_to_libsvm.py
import csv
def execute(data, savepath):
csv_reader = csv.reader(open(data))
f = open(savepath, 'wb')
for line in csv_reader:
label = line[0]
features = line[1:]
libsvm_line = label + ' '
for index, feature in enumerate(features):
libsvm_line += str(index + 1) + ':' + feature + ' '
f.write(bytes(libsvm_line.strip() + '\n', 'UTF-8'))
f.close()
execute('mnist_train.csv', 'mnist_train.libsvm')
execute('mnist_test.csv', 'mnist_test.libsvm')
执行完成后在根目录下产生以下两个.libsvm文件:
mnist_test.libsvm
mnist_train.libsvm
3.通过共享目录传递数据集到spark-master容器内
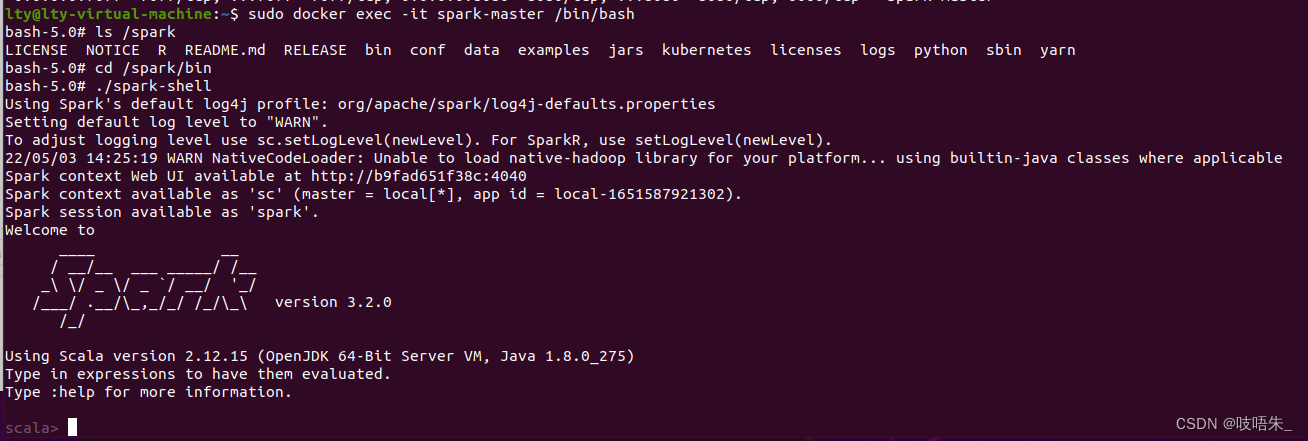
进入spark-master
sudo docker exec -it spark-master /bin/bash
输入命令将数据集文件移动到共享文件夹下(即实验四yml文件里配置的路径)
sudo mv mnist_test.libsvm /home/ryu/spark
sudo mv mnist_train.libsvm /home/ryu/spark
spark-shell位于/spark/bin目录下,使用./spark-shell命令进入spark-shell。
二、读取数据集
读取训练集
val train = spark.read.format("libsvm").load("/data/mnist_train.libsvm")

读取测试集
val test = spark.read.format("libsvm").load("/data/mnist_test.libsvm")

定义网络结构。如果计算机性能不好可以降低隐藏层的参数。
val layers = Array[Int](784, 784, 784, 10)

导入多层感知机与多分类评价器。
import org.apache.spark.ml.classification.MultilayerPerceptronClassifier
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator

使用多层感知机初始化训练器。
val trainer = new MultilayerPerceptronClassifier().setLayers(layers).setBlockSize(128).setSeed(1234L).setMaxIter(100)

三、训练模型
var model = trainer.fit(train)

输入测试集进行识别
val result = model.transform(test)

获取测试结果中的预测结果与实际结果
val predictionAndLabels = result.select("prediction", "label")

初始化评价器
val evaluator = new MulticlassClassificationEvaluator().setMetricName("accuracy")

计算识别精度
println(s"Test set accuracy = ${evaluator.evaluate(predictionAndLabels)}")

在result上创建临时视图
result.toDF.createOrReplaceTempView("deep_learning")
使用Spark SQL的方式计算识别精度
spark.sql("select (select count(*) from deep_learning where label=prediction)/count(*) as accuracy from deep_learning").show()

















 192
192











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









