







Openmv学习笔记----基础知识
图像处理背景知识
什么是摄像头
那么什么是摄像头,说到底,就是一个将光学信号转变成电信号的一个装置。在计算机视觉中,最简单的相机模型是小孔成像模型:
小孔模型是一种理想相机模型,没有考虑实际相机中存在的场曲、畸变等问题。但是在实际使用时,这些问题可以通过在标定的过程中引入畸变参数解决,所以小孔模型仍然是目前最广泛使用的相机模型。
图像透过镜头,照在一个感光芯片上,感光芯片可以把光照的波长和强度等信息转成计算机(数字电路)可以识别的数字信号,感光元件是长这样的:

(中间的方形元件就是感光元件)
什么是像素和分辨率
感光元件是有很多个感光点构成的,比如有640480个点,每个点就是一个像素,把每个点的像素收集整理起来,就是一副图片,那么这张图片的分辨率就是640480:
什么是帧率
帧率(FPS)就是每秒钟处理的图片数量,如果超过20帧,人眼就基本分辨不出卡顿。当然,如果用在机器上,帧率是越高越好的,OpenMV的最大帧率对比:
注:没有标注均为不传输图像给IDE,因为这个过程很耗费时间。
什么是颜色
物理上,颜色就是不同波长的电磁波。

但是,根据人眼的视觉效果,可以通过RGB,CMYK,HSB,LAB色域,来将可见光的颜色描述出来。
RGB三原色
三原色的原理不是物理原因,而是由于人的生理原因造成的。人的眼睛内有几种辨别颜色的锥形感光细胞,分别对黄绿色、绿色和蓝紫色(或称紫罗兰色)的光最敏感(波长分别为564、534和420纳米)。
所以RGB经常用于显示器上,用来显示图片。
LAB亮度-对比度
Lab颜色空间中,L亮度;a的正数代表红色,负端代表绿色;b的正数代表黄色,负端代表兰色。不像RGB和CMYK色彩空间,Lab颜色被设计来接近人类视觉。
因此L分量可以调整亮度对,修改a和b分量的输出色阶来做精确的颜色平衡。
注意:在OpneMV的查找色块的算法中,运用的就是这个LAB模式
光源的选择
如果你的机器是在工业上,或者24小时长时间运行的设备,保持一个稳定的光源是至关重要的,尤其在颜色算法中。亮度一变,整个颜色的值会变化的很大!
镜头的焦距
因为图像是通过镜头的光学折射,照到感光元件上的。那么镜头就决定了,整个画面的大小和远近。一个最重要的参数就是焦距。
镜头焦距:是指镜头光学后主点到焦点的距离,是镜头的重要性能指标。镜头焦距的长短决定着拍摄的成像大小,视场角大小,景深大小和画面的透视强弱。当对同一距离远的同一个被摄目标拍摄时,镜头焦距长的所成的象大,镜头焦距短的所成的象小。注意焦距越长,视角越小。
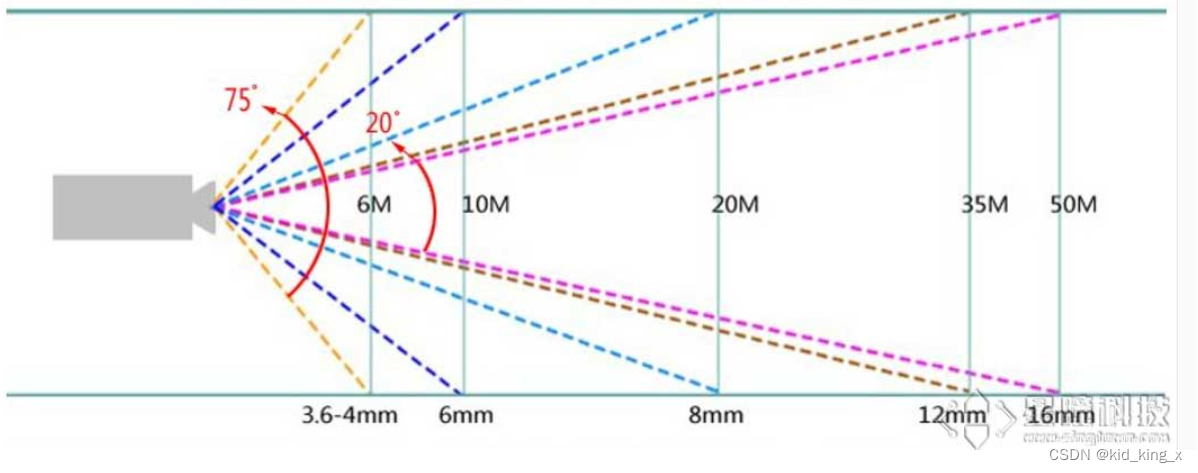
还有一点是镜头的畸变,因为光学原理,在感光芯片上不同的位置,与镜头的距离不同的,简单说就是近大远小,所以在边缘会出现鱼眼效果(桶型畸变)。为了解决这个问题,可以在代码中使用算法来矫正畸变,
注:OpenMV中使用image.lens_corr(1.8)
来矫正2.8mm焦距的镜头。也可以直接使用无畸变镜头。无畸变镜头加入了额外的矫正透镜部分,价格自然会高不少。
下面是,当OpenMV距离桌面20cm左右时,不同焦距镜头的对比图

镜头的滤片
在镜头上,通常会有一个滤片。

这个滤片是做什么的呢?
我们知道,不同颜色的光,是波长不一样。在正常环境中,除了可见光,还有很多红外光,在夜视中,用的就是红外光。
但是,在正常颜色应用中,是不需要红外光的,因为红外光也会使感光元件受到反应,就使得整个画面泛白。所以我们在镜头上放一个只能通过波长650nm以内的滤光片,就把红外光截止了。
Python的语法
宏定义
个人认为宏定义还是非常重要的,代码移植还是非常方便的
PI = 3.14
WINDOW_WIDTH = 800
WINDOW_HEIGHT = 600
一般用大写表示变量。
输出
print('hello,world')
print()函数也可以接收多个字符串,用逗号“,”隔开,就可以连成一串输出,print()会依次打印每个字符串,遇到逗号“,”会输出一个空格。
print('The quick brown fox', 'jumps over', 'the lazy dog')
print()也可以打印整数,或者计算结果:
print(300)
print(100 + 200)
变量
在Python中,等号=是赋值语句,可以把任意数据类型赋值给变量,同一个变量可以反复赋值,而且可以是不同类型的变量,例如:
a = 123 # a是整数
print(a)
a = 'ABC' # a变为字符串
print(a)
这种变量本身类型不固定的语言称之为动态语言,与之对应的是静态语言。静态语言在定义变量时必须指定变量类型,如果赋值的时候类型不匹配,就会报错。
list列表
Python内置的一种数据类型是列表:list。list是一种有序的集合,可以随时添加和删除其中的元素。
比如,列出班里所有同学的名字,就可以用一个list表示:
classmates = ['Michael', 'Bob', 'Tracy']
变量classmates就是一个list。用len()函数可以获得list元素的个数:
len(classmates)
用索引来访问list中每一个位置的元素,记得索引是从0开始的:
classmates[0]
当索引超出了范围时,Python会报一个IndexError错误,所以,要确保索引不要越界,记得最后一个元素的索引是len(classmates) - 1。
如果要取最后一个元素,除了计算索引位置外,还可以用-1做索引,直接获取最后一个元素:
classmates[-1]
以此类推,可以获取倒数第2个、倒数第3个:
classmates[-2]
classmates[-3]
list是一个可变的有序表,所以,可以往list中追加元素到末尾:
classmates.append('Adam')
也可以把元素插入到指定的位置,比如索引号为1的位置:
classmates.insert(1, 'Jack')
要删除list末尾的元素,用pop()方法:
classmates.pop()
要把某个元素替换成别的元素,可以直接赋值给对应的索引位置:
classmates[1] = 'Sarah'
list里面的元素的数据类型也可以不同,比如:
L = ['Apple', 123, True]
如果一个list中一个元素也没有,就是一个空的list,它的长度为0:
L = []
len(L)
0
tuple元组
另一种有序列表叫元组:tuple。tuple和list非常类似,但是tuple一旦初始化就不能修改,比如同样是列出同学的名字:
classmates = ('Michael', 'Bob', 'Tracy')
现在,classmates这个tuple不能变了,它也没有append(),insert()这样的方法。其他获取元素的方法和list是一样的,你可以正常地使用classmates[0],classmates[-1],但不能赋值成另外的元素。
不可变的tuple有什么意义?因为tuple不可变,所以代码更安全。如果可能,能用tuple代替list就尽量用tuple。
tuple的陷阱:当你定义一个tuple时,在定义的时候,tuple的元素就必须被确定下来,比如:
t = (1, 2)
但是,要定义一个只有1个元素的tuple,如果你这么定义:
t = (1)
定义的不是tuple,t是整型变量,变量t的值为1!这是因为括号()既可以表示tuple,又可以表示数学公式中的小括号,这就产生了歧义,因此,Python规定,这种情况下,按小括号进行计算,计算结果自然是1。
所以,只有1个元素的tuple定义时必须加一个逗号,,来消除歧义:
t = (1,)
Python在显示只有1个元素的tuple时,也会加一个逗号,,以免你误解成数学计算意义上的括号。
条件判断
if语句的完整形式是:
if <条件判断1>:
<执行1>
elif <条件判断2>:
<执行2>
elif <条件判断3>:
<执行3>
else:
<执行4>
比如:
age = 20
if age >= 6:
print('teenager')
elif age >= 18:
print('adult')
else:
print('kid')
循环
Python的循环有两种,一种是for…in循环,依次把list或tuple中的每个元素迭代出来,看例子:
names = ['Michael', 'Bob', 'Tracy']
for name in names:
print(name)
执行这段代码,会依次打印names的每一个元素:
Michael
Bob
Tracy
所以for x in …循环就是把每个元素代入变量x,然后执行缩进块的语句。
如果要计算1-100的整数之和,从1写到100有点困难,幸好Python提供一个range()函数,可以生成一个整数序列,再通过list()函数可以转换为list。比如range(5)生成的序列是从0开始小于5的整数:
list(range(5))
[0, 1, 2, 3, 4]
range(101)就可以生成0-100的整数序列,计算如下:
sum = 0
for x in range(101):
sum = sum + x
print(sum)
第二种循环是while循环,比如我们要计算100以内所有奇数之和,可以用while循环实现:
sum = 0
n = 99
while n > 0:
sum = sum + n
n = n - 2
print(sum)
数据类型转换
Python内置的常用函数还包括数据类型转换函数,比如int()函数可以把其他数据类型转换为整数:
>>> int('123')
123
>>> int(12.34)
12
>>> float('12.34')
12.34
>>> str(1.23)
'1.23'
>>> str(100)
'100'
>>> bool(1)
True
>>> bool('')
False
函数
在Python中,定义一个函数要使用def语句,依次写出函数名、括号、括号中的参数和冒号:,然后,在缩进块中编写函数体,函数的返回值用return语句返回。
我们先写一个计算x2的函数:
def power(x):
return x * x
对于power(x)函数,参数x就是一个位置参数。
当我们调用power函数时,必须传入有且仅有的一个参数x。
现在,如果我们要计算x3怎么办?可以再定义一个power3函数,但是如果要计算x4、x5……怎么办?我们不可能定义无限多个函数。
你也许想到了,可以把power(x)修改为power(x, n),用来计算xn,说干就干:
def power(x, n):
s = 1
while n > 0:
n = n - 1
s = s * x
return s
对于这个修改后的power(x, n)函数,可以计算任意n次方。
修改后的power(x, n)函数有两个参数:x和n,这两个参数都是位置参数,调用函数时,传入的两个值按照位置顺序依次赋给参数x和n。
切片
取一个list或tuple的部分元素是非常常见的操作。比如,一个list如下:

取前3个元素,用一行代码就可以完成切片:

L[0:3]表示,从索引0开始取,直到索引3为止,但不包括索引3。即索引0,1,2,正好是3个元素。
如果第一个索引是0,还可以省略:

也可以从索引1开始,取出2个元素出来:

tuple也是一种list,唯一区别是tuple不可变。因此,tuple也可以用切片操作,只是操作的结果仍是tuple:

字符串’xxx’也可以看成是一种list,每个元素就是一个字符。因此,字符串也可以用切片操作,只是操作结果仍是字符串:

对象
Python是面向对象编程的,比如一个LED灯
from pyb import LED
red_led = LED(1)
red_led.on()
LED是一个类,red_led就是一个对象,可以对这个对象进行操作,比如点亮on,关掉off,查看value。
模块
什么是模块
随着代码的增多,在一个文件里的代码会越来越长,越来越难看懂。
为了编写可维护的代码,我们把很多函数分组,放到不同的文件里。在Python中,一个.py文件就称之为一个模块(Module)。
模块有什么好处?复用代码方便!如果我写了一个模块,你也写了一个模块,我们就有了两个模块。我们把这些模块都组织起来,大家就可以少写很多代码了!
如何使用模块?
import pyb
red_led = pyb.LED(1)
red_led.on()
import pyb就是引入pyb这个模块。通过import语句,就可以引入模块。
还有from xxx import ooo 的语句,意思是通过xxx模块引入ooo类,或者通过xxx模块引入ooo函数。比如上面的程序可以写成:
from pyb import LED
red_led = LED(1)
red_led.on()
这就是通过pyb的模块来引入LED类了。
如何添加自定义模块?
之前我们提到了,OpenMV是有文件系统的。
文件系统的根目录存在一个main.py,代码执行的当前目录就是根目录。
所以我们把模块的文件复制到OpenMV的“U盘”里就可以。如图:
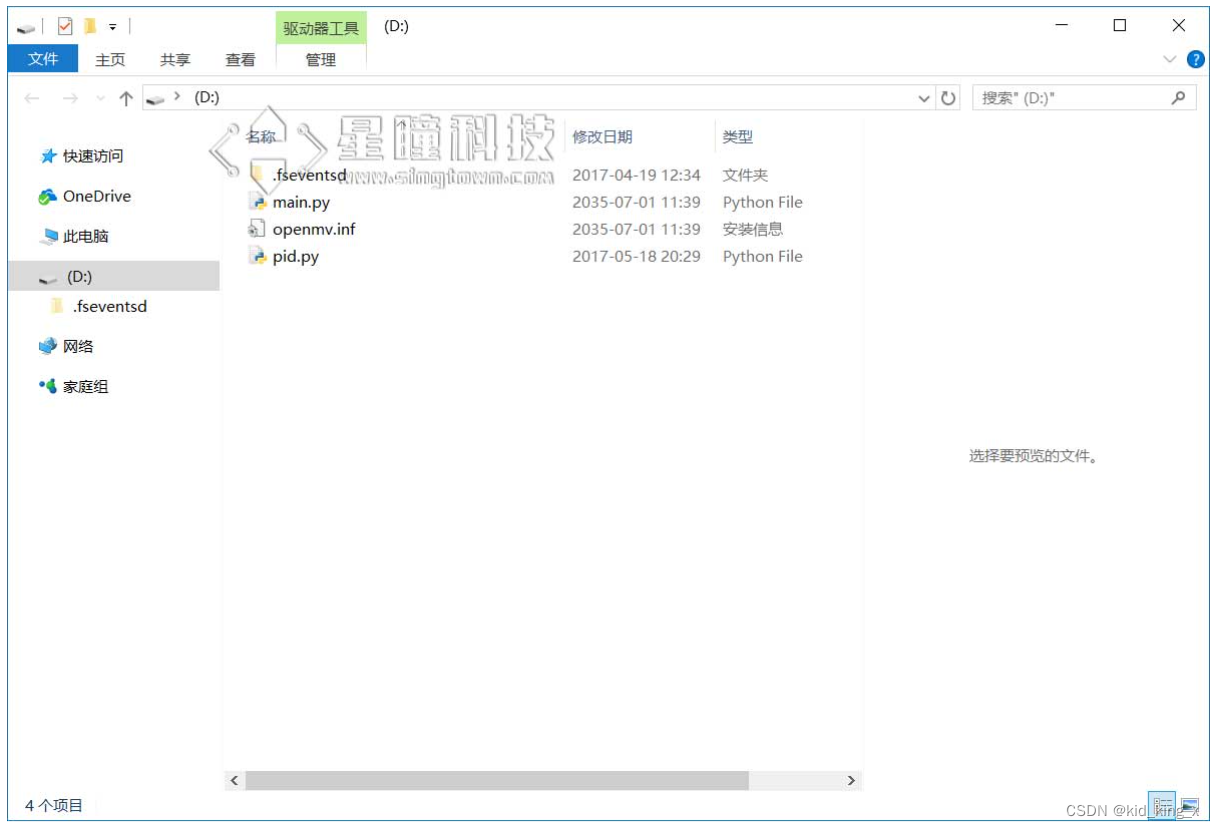
这里的pid.py只是举一个举例。
我把pid.py复制到了U盘的根目录下。那么在程序中:
import pid
就可以引入pid模块了了。或者通过:
from pid import PID
这就是引入了PID类。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









