







一、不平衡数据学习的评价指标度量
少数类的类标签定义为正(positive),多数类的类标签定义为负(negative)
Tp:被正确分类的正例的数量
Tn:被正确分类的反例的数量
Fn:表示错误分类的正例的数量
Fp:表示错误分类的反例的数量
-
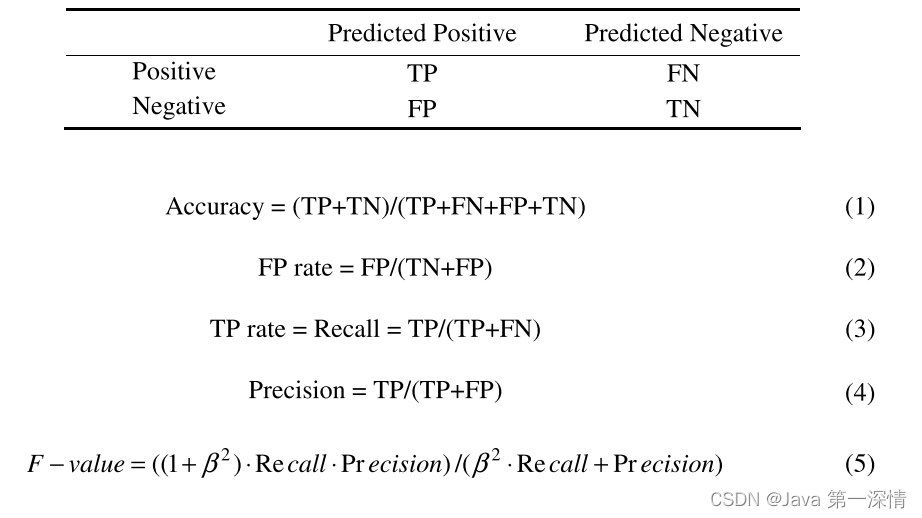
混淆矩阵:作为评估基础,混淆矩阵展示了分类结果与实际标签之间的对应关系,其中TP(真正例)、TN(真负例)、FP(假正例)、FN(假负例)是核心组成部分。
-
准确率(Accuracy):公式(1)定义了准确率,但在高度不平衡的数据集中,准确率可能因多数类的表现而偏高,无法真实反映少数类的分类效果。
-
假正率(False Positive Rate, FPR)与真正例率(True Positive Rate, TPR):分别由公式(2)和(3)给出,它们是ROC曲线的两个关键组成,其中TPR也称为召回率,用来衡量分类器识别出所有正例的能力。
-
精确率(Precision):公式(4)定义,它关注被预测为正例中实际为正例的比例,适用于信息检索等重视精确性的领域。
-
F值(F-score或F-measure):公式(5)结合了召回率和精确率,通过调整β值可以平衡两者的重要性,β=1时得到F1分数,尤其适合评估不平衡数据集中的分类性能。
-
ROC曲线与AUC:ROC曲线通过TPR与FPR的二维图展示分类器的性能,y轴代表TP rate,x轴代表FP rate。AUC(曲线下面积)是其量化指标,能有效评估模型在不同阈值下的表现,尤其适用于不平衡数据。
二、Borderline-SMOTE方法描述
大多数分类算法的核心目标是在训练过程中尽可能精确地学习每个类别的边界。位于边界附近或边界上的样本相比远离边界的样本更容易被错误分类,因此对于提升分类性能尤为关键。
作者提出由于远离边界的样本对分类贡献相对较小,故而引入了两种新的少数类过采样方法:borderline-SMOTE1和borderline-SMOTE2。
这两种方法的创新之处在于它们只对少数类中的边缘线样本进行过采样
这与以往的过采样技术有所不同。以往的方法要么对所有少数类样本进行过采样,要么随机选择少数类样本子集进行过采样。
0、算法步骤
①首先找出位于边界线上的少数类样本
②少数类记为p,多数类记为N
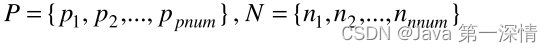
③基于p生成样本,并将其添加到原始训练集中
1、Borderline-SMOTE1的详细步骤
①
对于p中的每一个样本Pi,计算出最近的m个近邻样本。m中如若存在多数类样本,则m当中的多数类样本个数记为m'
②
如果 m' = m,即Pi的m个近邻样本都为多数类样本,则Pi视为Noise噪声样本,不进行下一步
如果,即Pi的m个近邻样本中,多数类样本大于少数类样本,这时候Pi被视为Danger样本,这类样本很容易被错误分类。将Pi加入Danger样本集中
如果,即Pi的m个近邻样本中,少数类样本大于多数类样本,这时候Pi被视为Safe样本,无需进行下一步
③
Danger中的样本即为少数类中的边界样本
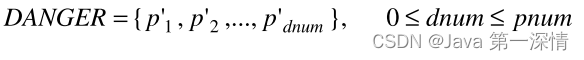
对Danger中的每个样本计算其k个最近邻样本
④
这一步就要生成s个少数类样本了
对danger中的每一个P'j,从其k个最近邻样本中随机挑选s个(s是介于1到k的整数),参与下面公式的生成
rj是一个介于0,1的随机数,difj是P'j与上面挑选的s个样本的距离,当前是j,那就是与第j个样本的距离
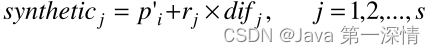
总结:我们可以看到,新的合成数据是沿着少数类边界样本与其同类最近邻域之间的直线产生的,从而加强了边界样本。
三、Borderline-SMOTE2
这是对borderline-SMOTE方法的一种扩展,通过更精细的操作来优化少数类样本的生成
- 识别DANGER区域样本:首先,该方法识别出少数类中的“边缘线”样本,这些样本被认为是最容易被错误分类的,因为它们靠近类别边界。这些样本集合称为DANGER。
-
选取邻居样本:对于DANGER区域中的每一个少数类样本,borderline-SMOTE2不仅考虑其在多数类P中的最近邻正样本(即属于少数类的样本),还会考虑它在多数类N中的最近邻负样本(即属于多数类的样本)。
-
生成合成样本:不同于仅从正样本生成合成样本,该方法还利用与最近邻负样本的差异来生成新的合成样本。这个差异会被乘以一个介于0和0.5之间的随机数,这样做的目的是确保新生成的样本更接近少数类,而不是简单地落在两类之间的某个中间位置。通过这种方式,可以更有效地扩展少数类样本的分布范围,同时尝试“推动”分类边界向多数类一侧移动,从而减小误分类的风险。
四、未来研究点
Different strategies to define the DANGER examples
automated adaptive determination of the number of examples in DANGER
Borderline与欠采样结合
Borderline与数据挖掘算法集成

















 2572
2572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









