







 本文介绍了OpenCL,一个跨平台的并行计算框架,用于在CPU、GPU等设备上编程。文章详细讲解了OpenCL的模型、内存管理、执行流程,以及如何利用GPU进行高效计算,包括内核、工作项、工作组的使用和同步机制。并与CUDA进行了对比。
本文介绍了OpenCL,一个跨平台的并行计算框架,用于在CPU、GPU等设备上编程。文章详细讲解了OpenCL的模型、内存管理、执行流程,以及如何利用GPU进行高效计算,包括内核、工作项、工作组的使用和同步机制。并与CUDA进行了对比。
Introduction to OpenCL
Open Computing Language 是用于编写跨异构平台执行的程序的框架。
例如,它们由 CPU、GPU、DSP 和 FPGA 组成。
OpenCL 指定了一种用于对这些设备进行编程的编程语言(基于 C99)和应用程序编程接口 (API),以控制平台并在计算设备上执行程序。
OpenCL 为使用基于任务和基于数据的并行性的并行计算提供了标准接口。
First thing to notice
虽然 OpenCL 本身可以与多种设备通信,但这并不意味着您的代码无需您付出任何努力就能在所有设备上以最佳方式运行。事实上,鉴于不同的 CL 设备具有非常不同的功能集,因此根本无法保证它能够运行。如果您坚持 OpenCL 规范并避免特定于供应商的扩展,那么您的代码即使没有针对速度进行调整,也应该是可移植的。
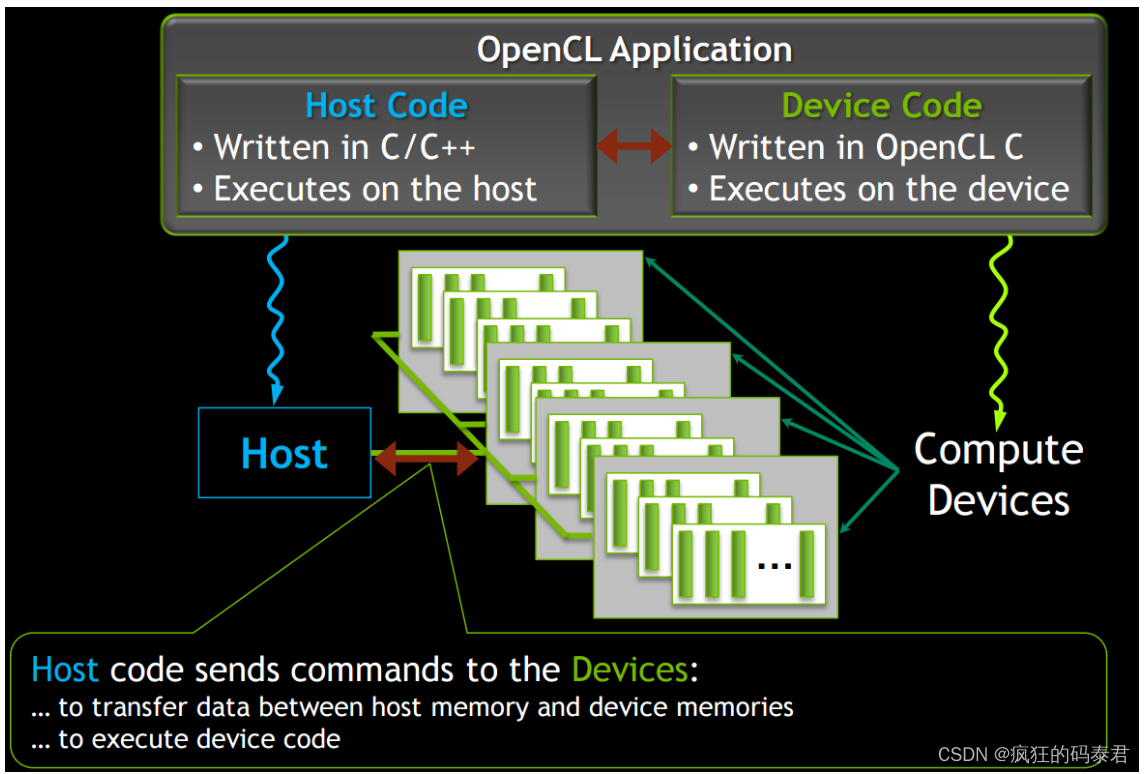
Actors on OpenCL system
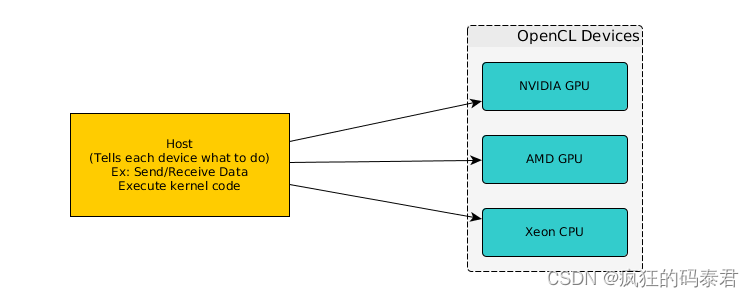
Use cases
这是您应该使用 GPU 进行计算的正常情况。
- 快速排列:设备比主机更快地移动内存
- 数据转换:从一种格式更改为另一种格式
- 数值加速:设备计算大数据块的速度比 主机快
Heterogeneous systems
它是一个由多个计算系统组成的系统。例如,具有多核 CPU 和 GPU 的桌面系统。
以下是该系统的主要组件:
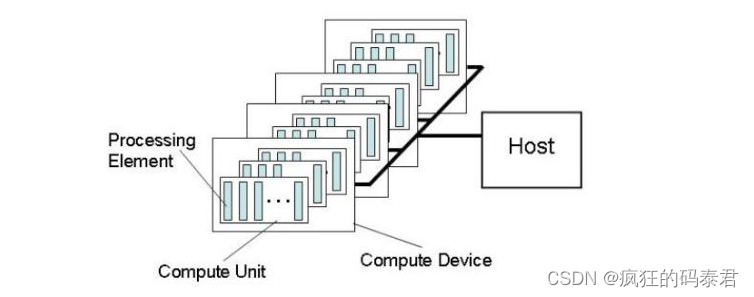
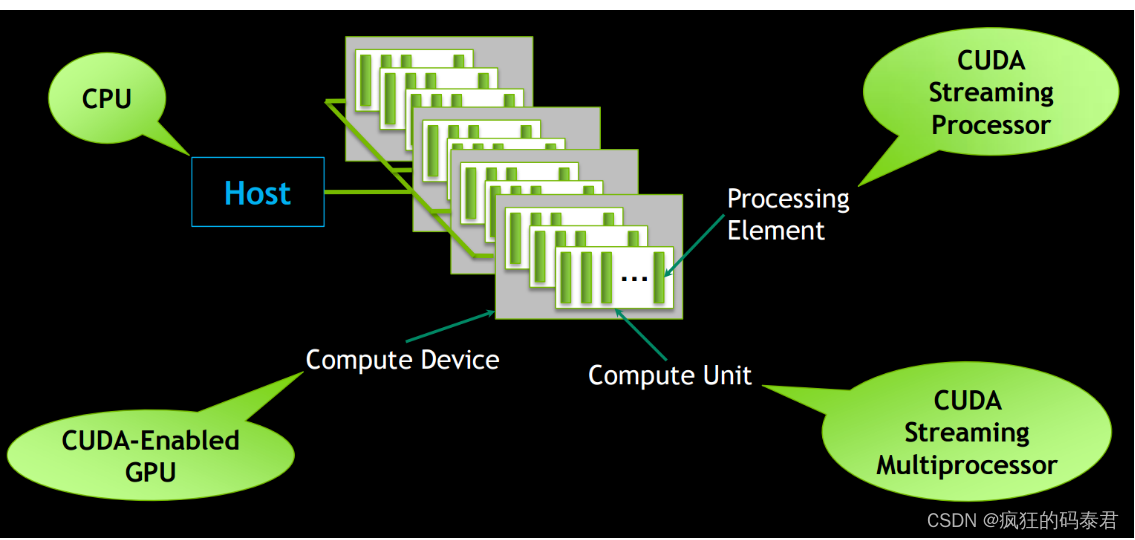
Host: Your desktop system Compute
Device: CPU, GPU, FPGA, DSP.
Compute Unit: Number of cores
Processing Elements: ALUs on each core.
您不需要过多考虑 OpenCL 设备模型如何适合特定硬件,这是硬件供应商的责任。不要认为处理元件是“处理器”或CPU 核心。
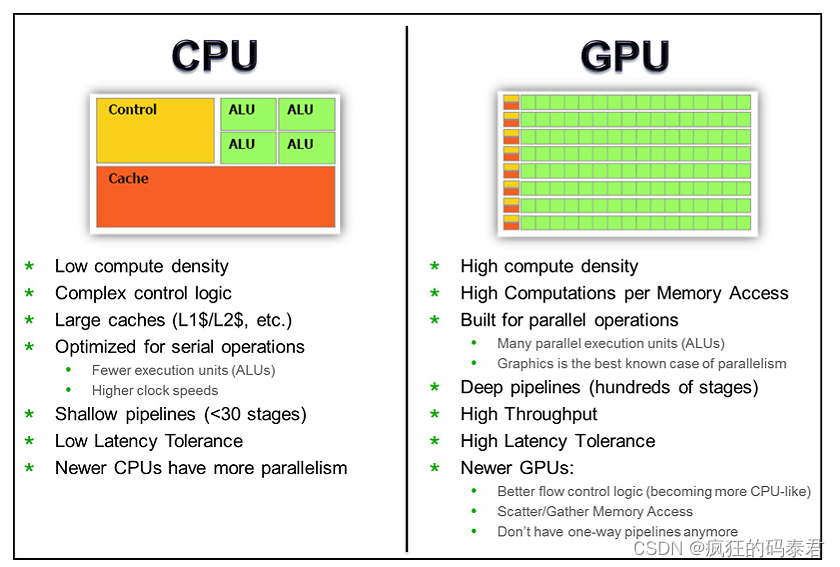
OpenCL Models
首先要了解 OpenCL,我们需要了解以下模型。
- 设备型号:设备内部的外观。
- 执行模型:如何在设备上完成工作。
- 内存模型:设备和主机如何查看数据。
- 主机
API:主机如何控制设备。
OpenCL components
C Host API:用于控制设备的 C API。 (例如:内存传输、内核编译)
OpenCL C:在设备上使用(内核语言)
Device Model
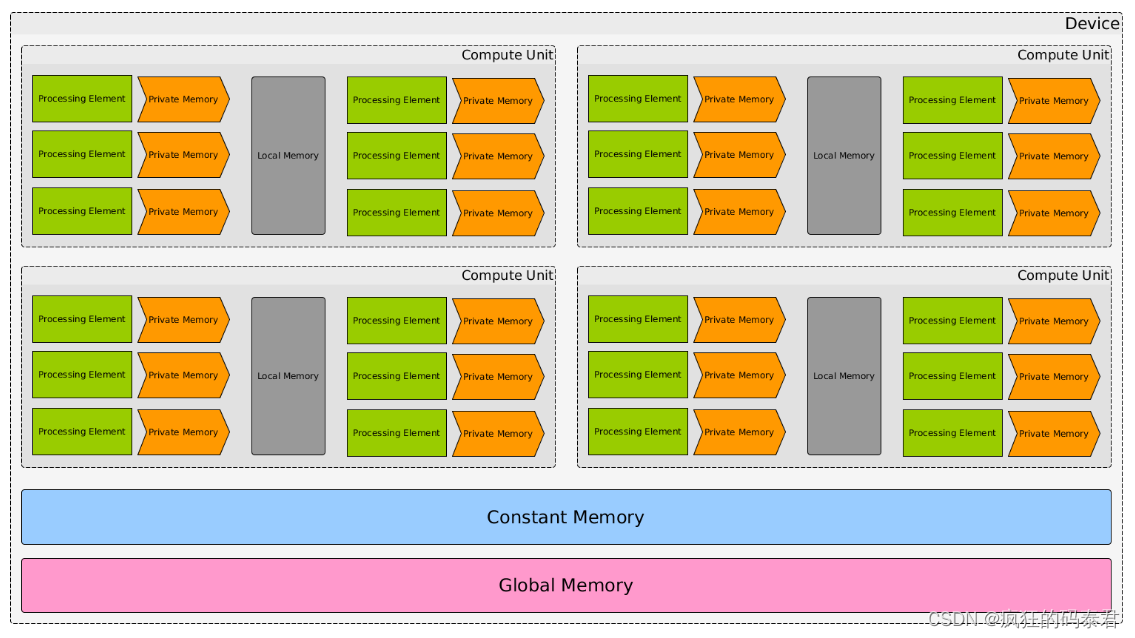
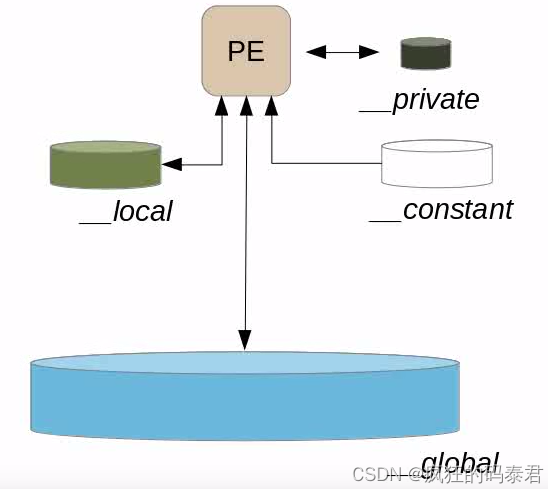
关于memory的一些话:
- 全局内存:与所有设备共享,但速度慢。并且在内核调用之间是持久的。
- Constant Memory:比全局内存更快,将其用于过滤器参数
- 本地内存:每个计算单元私有,并由所有处理元素共享。
- 私有内存:速度更快,但对于每个处理元素来说都是本地的。
常量内存、本地内存和私有内存都是暂存空间,因此您无法在其中保存数据以供其他内核使用。
如果您熟悉 CUDA 一词,这就是 OpenCl 模型如何适合 Cuda 计算架构。
Execution Model
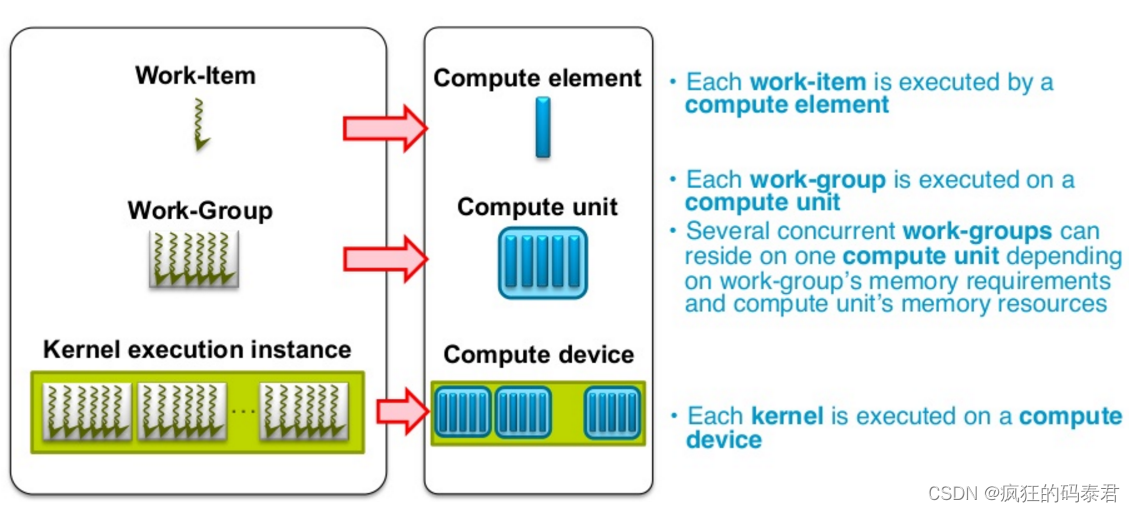
OpenCl 应用程序在主机上运行,主机将工作提交到计算设备。
- 工作项:计算设备上的基本工作单元
- 内核:在工作项上运行的代码(基本上是 C 函数)
- 程序:内核和其他函数的集合
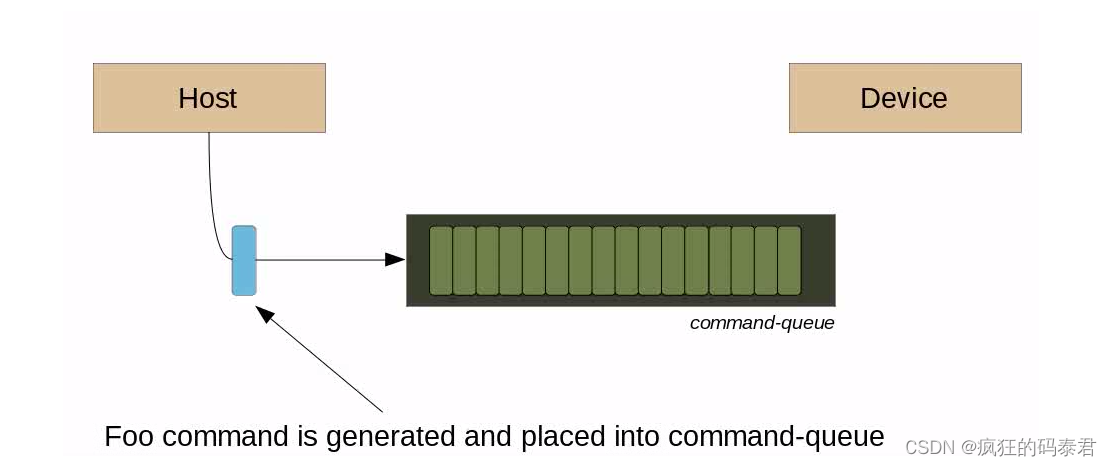
- 上下文:工作项执行的环境(设备、其内存和命令队列)
- 命令队列:主机用来向设备提交工作(内核、内存副本)的队列。
它是一个定义内核如何在问题(N 维向量)的每个点上执行的框架。或者可以看作是任务在工作项中的分解。
需要定义什么:
- 全局工作大小:输入向量上的元素数量。
- 全局抵消
- 工作组大小:计算分区的大小。
Work-Groups
在理想情况下,您将拥有无限的处理元件 (PE),因此每个 PE 都会处理您的一项数据,并且它们永远不需要进行通信。这种情况几乎不会发生,因此您需要对工作进行分区。
- 将全局工作划分为更小的部分
- 每个分区称为工作组
- 工作组计划在计算单元上执行
- 每个工作组都有一个共享内存(与计算单元上的本地内存相同)
- 工作组上的工作项直接映射到计算单元上的处理元素。
恢复工作组被调度到计算单元,并且工作项在处理元素内执行。
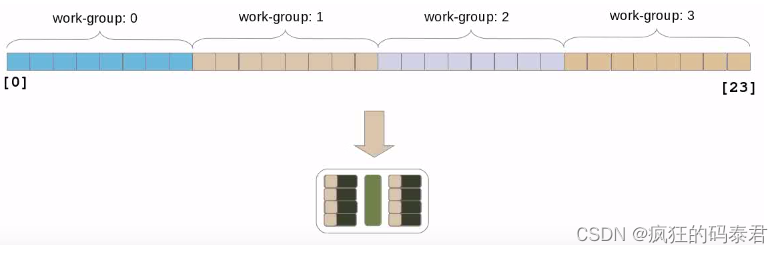
考虑以下情况,您有一个包含 24 个元素的向量,并且工作组大小为 8。Open CL 将像这样自动对数据进行分区。
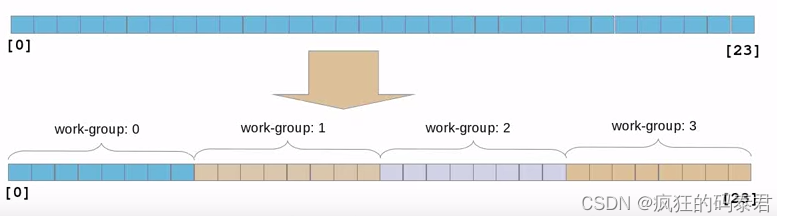
如果您有足够的计算单元,每个工作组将映射到一个计算单元。
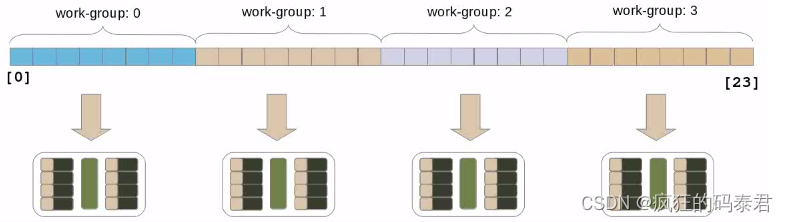
这个过程由 opencl 自动完成,您只需给出全局工作大小 (24) 和工作组大小 (8)。然后,在理想情况下,每个 PE 都会获得您工作组的一项。
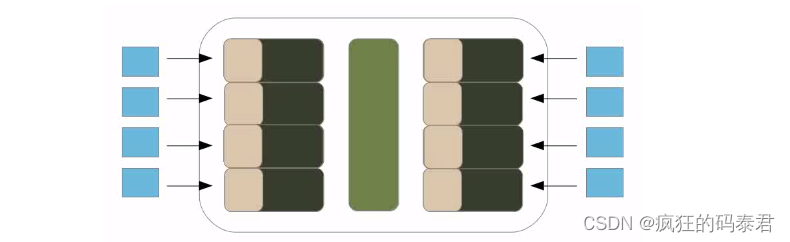
现在,如果您没有足够的计算能力(也是正常情况),会发生什么。如果发生这种情况,OpenCL 将以串行方式将每个工作组一一分配给该计算单元。这样做的好处在于,如果您只是插入更好的硬件(更多计算单元),性能就会受到影响。
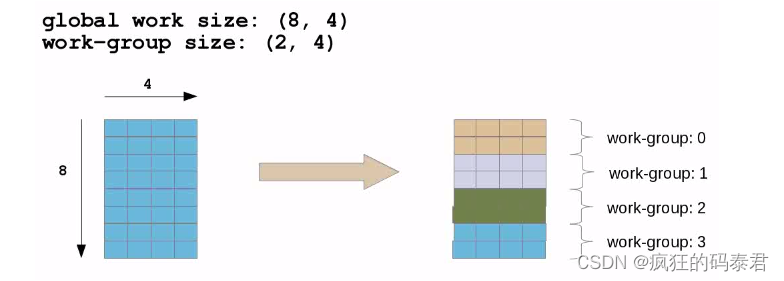
除了处理一维向量之外,您还可以在二维上工作/思考。
And 3d
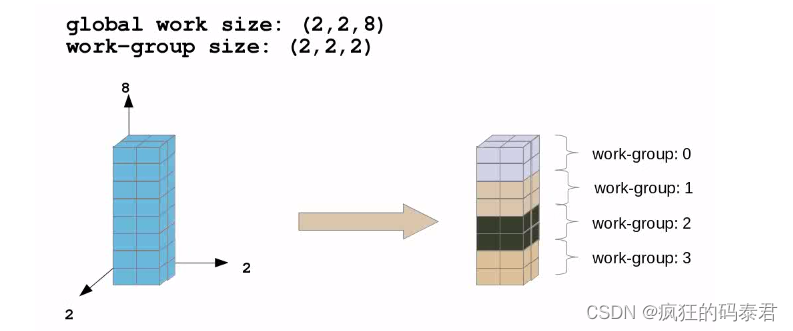
另一件需要指出的是,工作项只能与同一工作组中的它们进行通信。不同的工作组无法通信。唯一的选择是在 2 个内核上解决问题并使用全局内存,但这会很慢。
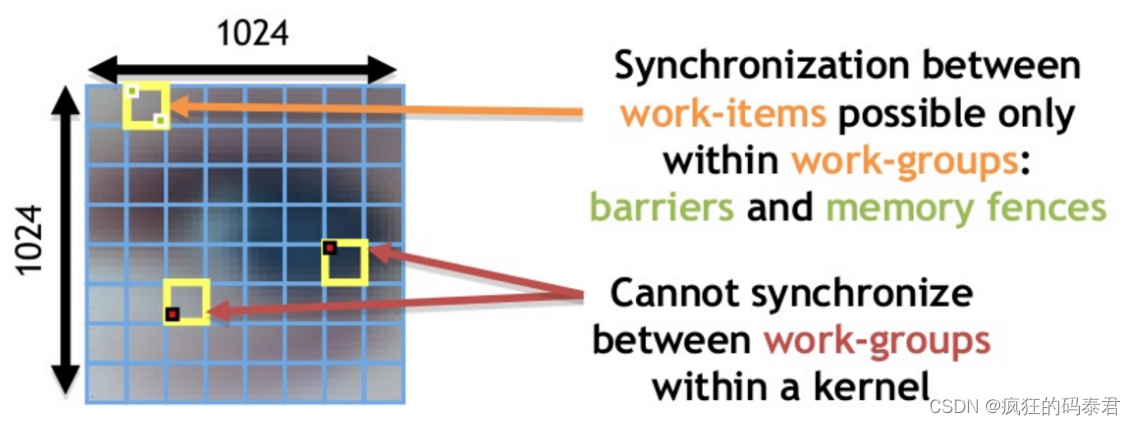
最大的工作组大小是特定于设备的。
Launching the kernel
要启动内核,您将使用该函数clEnqueueNDRangeKernel,在此函数上,您将使用参数 global_work_size 和 local_work_size。
global_work_size 参数定义将启动的(工作项/线程)总数,每个工作项单独执行并获取一大块输入数据。
local_work_size 参数定义工作组(工作项/线程)数量的大小。工作组可以共享局部变量。
工作组的数量是通过将 global_work_size 除以 __local_work_size 来定义的。
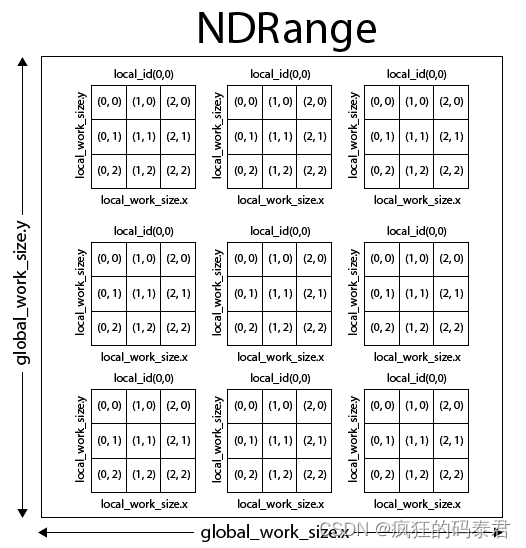
每个工作组都在一个计算单元上执行,该计算单元能够处理各种工作项,而不仅仅是一个。因此,拥有多个小型工作组并不是一个好主意。另一方面,如果您的工作组包含太多工作项,您将失去并行性,最好的配给是通过反复试验找到的。
在同一计算单元上工作的线程可以共享变量,因为它们将在同一工作组上执行。
如果传递参数 NULL 而不是 local_work_size,则可以自动计算工作组大小(并不总是最好的)。
Some notes:
- 每个工作项都会调用一次内核。每个工作项都有私有内存。
- 工作项被分组为工作组。每个工作组共享本地内存
- 所有工作项的总数由全局工作大小指定。
- 全局和常量内存在所有工作组的所有工作工作项之间共享。
Host-API
OpenCl提供了一组函数来控制系统上的设备。设备不知道要做什么,主机 API 控制整个系统。
下面我们有 Host-API 的主要组件
- Platform
- Context
- Programs
- Asynchronous Device calls
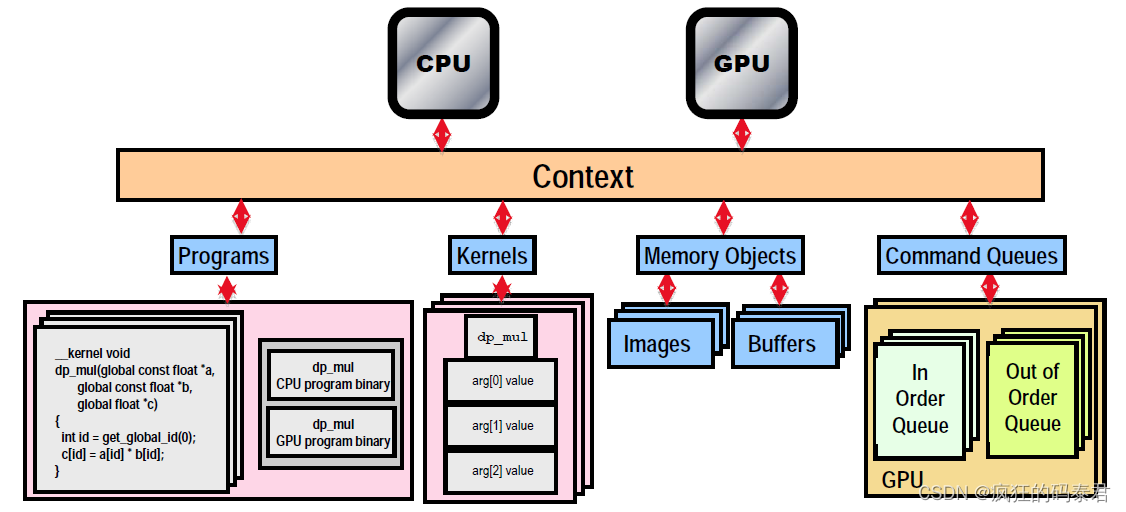
Platform
平台是 OpenCl 实现。想象一下,作为一个设备驱动程序,它公开了异构上可用的设备。例如一台具有 2 个 GPU、1 个 FPGA 卡和一个 32 核大 CPU 的台式计算机。平台 API 发现您可用的设备。
Context
上下文允许您在某个特定平台上对多个设备进行分组。想象一下,您希望使所有设备的所有计算单元都可用。上下文有设备和内存。
Programs
只是需要编译和/或加载的内核集合。
Asynchronous Device calls
主机 API 提供向设备发出命令的功能 (clEnque*)。这些功能是异步的,因此当设备执行命令时主机不会冻结。
Host program Structure
大多数 OpenCl Host 程序具有以下结构
从源代码来看:
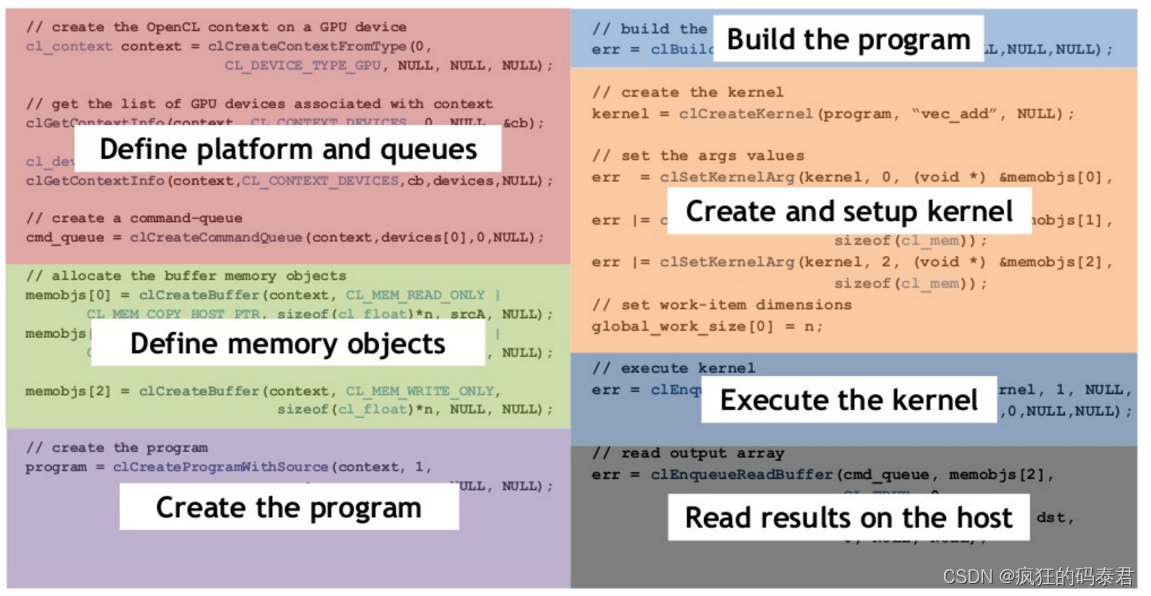
实际上这段大代码总是遵循相同的结构
-
定义(查询)平台并创建命令队列
-
定义内存对象(
clCreateBuffer) -
创建程序(内核库)
-
构建程序
-
设置内核(
clCreateKernel、clSetKernelArg) -
将结果返回给 Host
OpenCl Kernels
在 OpenCl 上,设备将执行内核,这些内核是用 OpenCl C 编写的小函数,OpenCl` C 是 `C (C99) 子集。
内核是设备执行的入口点(如主函数)。内核由主机加载和准备。
以下是 C 和 OpenCl C 之间的主要区别:
-
没有函数指针
-
无递归
-
具有矢量类型
-
有图像类型
-
允许结构但会降低性能,并且与主机的通信可能会很复杂。
-
没有不同内核之间协作的机制
内核参数将是指向全局内存的指针或给定的一些值。
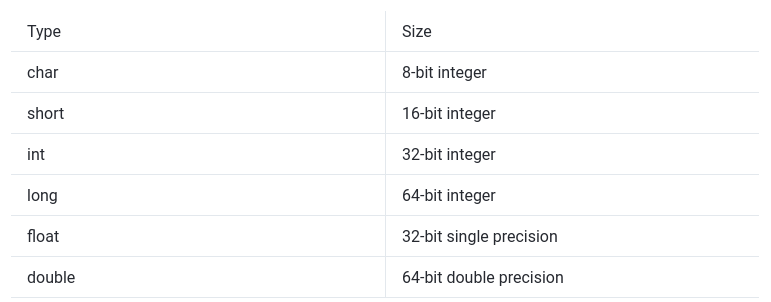
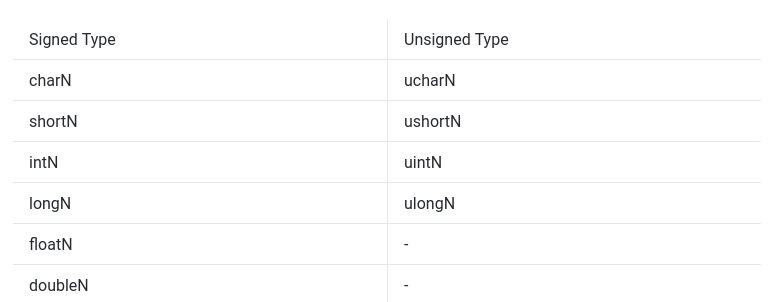
Types
唯一需要注意的一点是整数类型表示为二进制补码,并且其在主机上可能有所不同。
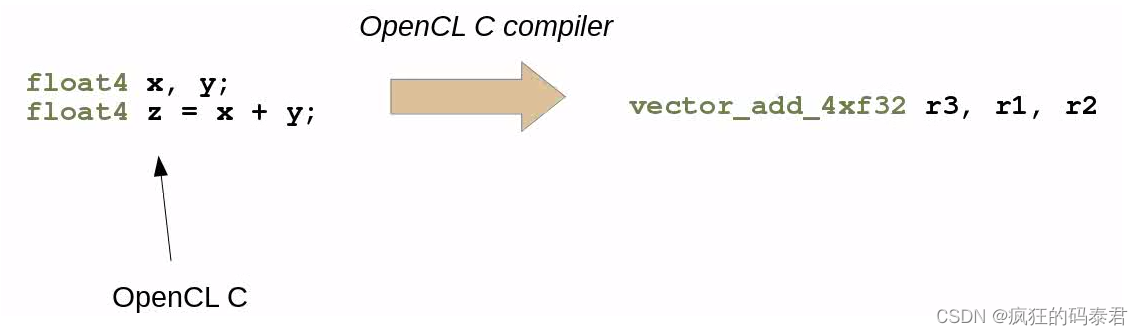
Vector Types
OpenCl 支持大小为 N={2,3,4,8,16}N={2,3,4,8,16} 的向量类型。这将允许 OpenCl 使用设备技术的矢量化指令,例如 Neon 指令。
混合标量和向量

Memory Regions
下图显示了如何定义内存区域(本地、私有、常量、全局)
// Pointers for an integer on the global memory
__global int *x;
__global int *y;
// This is ok
x = y;
// Now check this
__global int *a;
__private int *b;
// THIS IS AN ERROR YOU CANNOT POINT TO DIFFERENT MEMORY REGIONS
a = b;
// NOW THIS IS POSSIBLE BUT COSTLY... (Copy from private to global memory)
*a = *b;
Relevant functions
请记住,工作组分区是由 OpenCl 自动创建的。我们只选择工作组的大小。
get_global_id(n):获取工作组维度 (n) 上的工作项 id。
get_global_offset(n):获取维度(n)上的全局offser
get_local_id(n):我在维度 (n) 的工作组内是哪个工作项

1d Vector addition.
例如,想象一个函数需要计算 2 个大小为 10.000000(1000 万个元素)的 1d 向量的相加。
在正常编程中,这将类似于:
void vectorAdd( float *a, float *b, float *c, int numElements)
{
int nIndex = 0;
for (nIndex = 0; nIndex < numElements; nIndex++)
{
// This will execute 10.000000 times one after the other.
c[nIndex] = a[nIndex] + b[nIndex];
}
}
在 OpenCl 内核上,我们可以选择在多个处理元素上执行此函数。理想情况下,每个向量元素都可以有一个处理元素。在这种情况下,整个操作将需要 1 个周期。
事实是,处理元素常常少于要使用的元素。
请注意,我们希望通过并行执行前一个循环的多次迭代来替换 for 循环。
__kernel void
vectorAdd(__global const float * a,
__global const float * b,
__global float * c)
{
// Vector index
int nIndex = get_global_id(0);
c[nIndex] = a[nIndex] + b[nIndex];
}
Using Local Memory
#define SCRATCH_SIZE 1024
__kernel void foo(__global float *in, __global float *out, uint32_t len) {
// All kernels on this work-group will be able to see "scratch"
__local float scratch[SCRATCH_SIZE];
// Get global id of work item on dimension 0
size_t global_idx = get_global_id(0);
// Get our local id inside the work-group
size_t local_idx = get_local_id(0);
// Avoid run out of the input boundary
if (global_idx >= len) {
return;
}
// Do a copy from global memory to local memory
scratch[local_idx] = in[global_idx];
// Do something....
out[global_idx] = scratch[local_idx];
}
Synchronization on OpenCl
如前所述,无法同步不同工作组上的工作项(线程)(不同工作组将在不同计算单元上执行)。但在同一个工作组中 OpenCl 提供了选项:
- 内存栅栏
- 障碍
- 这两个命令都有
CLK_LOCAL_MEM_FENCE和/或CLK_GLOBAL_MEM_FENCE作为参数。这些命令的使用也会对性能产生一些影响,但有时您确实需要它们。
Mem-fences
等待直到 mem_fence() 之前调用工作项对本地或全局内存进行的所有读/写对工作组中的所有工作项(线程)可见。基本上强制当前工作项所做的某些更改可供所有工作组使用。
Barriers
等待工作组中的所有工作项都到达此点并调用 mem_fence 以确保所有工作项(线程)看到相同的数据。
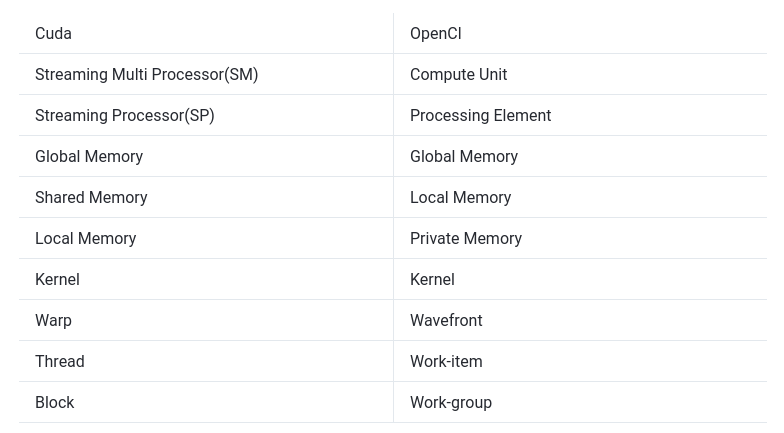
Some cross terminology between Cuda and OpenCl
















 3735
3735











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











