






实验题目:Cassandra集群的搭建与JavaAPI的应用
实验目的与要求:搭建三节点的Cassandra集群,用Java接口实现数据的增删改查,之后写Java程序,统计Cassandra中某个表的总行数,把统计结果写入HDFS。
实验步骤:
一、前期准备
1.Hadoop集群已配置完毕
2.linux系统安装jdk
3.在linux系统中安装并破解IntelliJ IDEA
4.实现IDEA连接hdfs并在hdfs上进行增删改查操作
二、搭建三节点的Cassandra集群
1.创建cassandra用户及数据存放目录
useradd cassandra #创建用户名
mkdir /opt/module/data1 #创建数据存放目录
mkdir /opt/module/data2
cd /opt/module
chmod 777 data1 #开放权限
chmod 777 data2

2.安装cassandra
(1)解压cassandra
tar -zxvf apache-cassandra-3.11.11-bin.tar.gz
(2)将/opt/cassandra的拥有者设为新创建的用户cassandra
chown -R cassandra.cassandra /opt/module/apache-cassandra-3.11.11
3.在cassandra用户下创建数据目录、日志目录、缓存目录
mkdir /opt/data1/commitlog #创建日志目录
mkdir /opt/data1/data1file #创建数据目录
mkdir /opt/data2/data2file
mkdir /opt/data2/saved_caches #创建缓存目录

4.在cassandra用户下配置JAVA环境
(1)vi /home/cassandra/.bashrc
(2)配置JDK环境变量
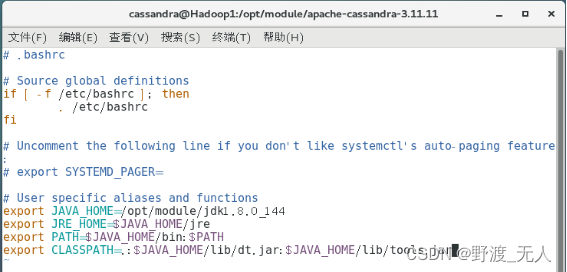
(3)刷新环境变量
source .bashrc
(4)验证是否配置成功

5.修改配置文件(三个节点依次执行此操作)
(1)打开cassandra.yaml配置文件
vim /opt/module/apache-cassandra-3.11.11/conf/cassandra.yaml
(2)修改集群名称

(3)修改数据目录地址

(4)修改日志目录地址

(5)修改缓存目录地址

(6)修改种子节点(本实验选择192.168.71.128服务器作为种子节点)

(7)修改需要监听的地址为本机IP

(8)修改用于监听客户端连接的地址为本机IP


(9)下发文件到其他两个节点
xsync cassandra.yaml

(10)对Hadoop2中的配置文件进行修改


(11)对Hadoop3中的配置文件进行修改


6.启动集群
(1)在三个节点上启动cassandra服务
cd bin
./cassandra
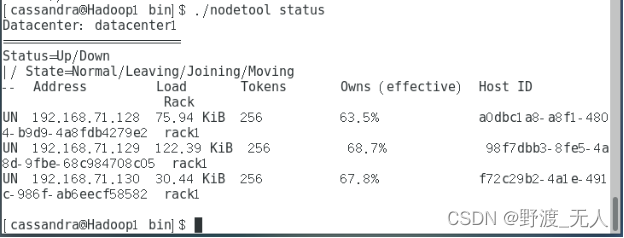
(2)查看各节点状态
7.使用CQL操纵cassandra数据库
(1)启动CQL

(2)创建Keyspace

(3)选择Keyspace,创建表student

(4)向表中添加数据,并查询

三、IntelliJ IDEA通过JavaAPI操作cassandra数据库
1.新建项目
(1)新建maven项目cassandra1
File->New->Project->Maven
(2)在项目中导入cassandra的lib下的jar包
(3)在src->main->java下创建com.min.cassandra包,并在下面建立demo1.java、demo2.java文件,目录结构即导入包如下

2.在demo2.java中实现通过JavaAPI对cassandra数据库的增删改查
(1)demo2.java在cassandra数据库中创建Keyspace demo2并在其中创建student表进行增删改查操作的代码如下
package com.min.cassandra;
import java.util.List;
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.ResultSet;
import com.datastax.driver.core.Row;
import com.datastax.driver.core.Session;
public class demo2 {
public static void main(String[] args) {
Cluster cluster = null;
Session session = null;
try {
// 定义一个cluster类
cluster = Cluster.builder().addContactPoint("192.168.71.128").build();
// 获取session对象
session = cluster.connect();
// 创建键空间
String createKeySpaceCQL = "create keyspace if not exists demo2 with replication={'class':'SimpleStrategy','replication_factor':1}";
session.execute(createKeySpaceCQL);
// 创建列族
String createTableCQL = "create table if not exists demo2.student(name varchar primary key,age int)";
session.execute(createTableCQL);
// 插入数据
String insertCQL = "insert into demo2.student(name,age) values('bhn',25)";
String insertCQL1 = "insert into demo2.student(name,age) values('lyf',31)";
session.execute(insertCQL);
session.execute(insertCQL1);
// 查询数据
query01(session);
// 修改数据
String updateCQL="update demo2.student set age=21 where name='bhn'";
session.execute(updateCQL);
query01(session);
// 删除数据
String deleteCQL="delete from demo2.student where name='lyf'";
session.execute(deleteCQL);
query01(session);
} catch (Exception e) {
e.printStackTrace();
} finally {
// 关闭资源
session.close();
cluster.close();
}
}
private static void query01(Session session) {
System.out.println("开始查询--------------------------");
String queryCQL = "select * from demo2.student";
ResultSet rs = session.execute(queryCQL);
List<Row> dataList = rs.all();
System.out.println("name"+"\t"+"age");
for (Row row : dataList) {
System.out.println(row.getString("name")+"\t"+"\t"+row.getInt("age"));
}
System.out.println("结束查询--------------------------");
}
}(2)运行结果

(3)cassandra数据库查看

四、JavaAPI实现hdfs和cassandra的联合操作
统计Cassandra中某个表的总行数,把统计结果写入HDFS
1.demo1.java实现统计Keyspace demo1下的student表的行数,并将student表中的数据和表的行数写入bhn.txt文件下上传到hdfs,其代码如下
package com.min.cassandra;
import java.io.BufferedWriter;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.List;
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.ResultSet;
import com.datastax.driver.core.Row;
import com.datastax.driver.core.Session;
import com.min.hadoop.HdfsUtil;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class demo1{
public static void main(String[] args) {
Cluster cluster = null;
Session session = null;
FileSystem fs = null;
Configuration cfg = new Configuration();
URI uri = null;
try {
uri = new URI("hdfs://Hadoop1:9000");
} catch (URISyntaxException e) {
e.printStackTrace();
}
try {
// 根据配置文件,实例化成DistributedFileSystem
fs = FileSystem.get(uri, cfg, "user1"); // 得到fs句柄
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
BufferedWriter out = null;
try {
out = new BufferedWriter(new OutputStreamWriter(new FileOutputStream("/home/planet/桌面/bhn.txt", true)));
try {
// 定义一个cluster类
cluster = Cluster.builder().addContactPoint("192.168.71.128").build();
// 获取session对象
session = cluster.connect();
//查询
query01(session,out,fs);
} catch (Exception e) {
e.printStackTrace();
} finally {
// 关闭资源
session.close();
cluster.close();
}
} catch (Exception e) {
} finally {
// Log4jBean.logger.info("开始关闭输出流");
try {
out.close();
} catch (IOException e) {
// Log4jBean.logger.info("关闭输出流异常,异常信息为:["+e.getMessage()+"]");
}
}
try {
// 上传
fs.copyFromLocalFile(new Path("/home/planet/桌面/bhn.txt"), new Path("/bhn.txt"));
System.out.println("上传成功!");
} catch (IOException e) {
e.printStackTrace();
}
}
private static void query01(Session session,BufferedWriter out,FileSystem fs) throws IOException {
System.out.println("开始查询--------------------------");
String queryCQL = "select * from demo1.student";
ResultSet rs = session.execute(queryCQL);
List<Row> dataList = rs.all();
out.write("id"+"\t"+"s_name"+"\n");
int i = 0;
for (Row row : dataList) {
i++;
out.write(row.getInt("id")+"\t"+row.getString("s_name")+"\n");
}
String C="一共有"+i+"行数据\n";
out.write(C);
System.out.println("结束查询--------------------------");
}
}2.运行结果如下

3.hdfs Web端查看结果

4.hdfs节点CentOS下查看结果















 822
822











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









