







 CKAN模型通过异构传播策略结合用户交互和知识图谱信息,采用知识感知注意力机制区分不同知识邻接的贡献。模型包括协作传播和知识图谱传播两部分,以及知识感知注意力嵌入,旨在提高推荐系统的性能,特别是处理新用户和高阶交互的噪声问题。
CKAN模型通过异构传播策略结合用户交互和知识图谱信息,采用知识感知注意力机制区分不同知识邻接的贡献。模型包括协作传播和知识图谱传播两部分,以及知识感知注意力嵌入,旨在提高推荐系统的性能,特别是处理新用户和高阶交互的噪声问题。
CKAN: Collaborative Knowledge-aware Attentive Network for Recommender Systems
0、Abstract
Collaborattive Knowledge-aware Attentive Network(CKAN 协作知识感知注意网络),通过协作传播传播对协作编号显示编码,并提出了一种将协作信号与知识关联结合的自然方式。具体而言,CKAN采用异构传播策略对这两种信息进行显式编码,并采用知识感知的注意机制对不同知识邻居的贡献进行区分。
1、Introduction
推荐系统大致可以分为3类:
-
embedding-based:
使用知识图嵌入(KGE)预先训练实体嵌入作为推荐中的物品表示。
CKE(TransR)、DKN(TransD)、KTUP(TransH)。这些模型中采用的KGE方法比推荐系统方法更适用于图内应用。
-
path-based:
提出了KG中实体间的多种连接模式,为推荐提供额外的指导。
一种是利用选择算法选择突出路径、另一种方法是定义元路径模式来约束路径。
基于路径的方法的主要问题是在实践中难以优化路径选择。
-
propagation-based:
在整个KG上迭代的进行传播,以寻找辅助信息进行推荐。
RippleNet,通过KG中的链接挖掘用户的潜在兴趣。
KGCN、KGNN-LS采用图卷积网络(GCN),通过它们在KG中的邻居来获取项的嵌入,表明邻居的信息能够导致推荐任务的很大提升。
- KGAT提出协作知识图(CKG)将user-item图(UIG)和知识图(KG)结合在一起,并通过GCN递归地在CKG上进行传播,以补充实体嵌入。
- 唯一的不足是将user也视为CKG中的实体节点,使得难以处理新用户。
- KGAT假设UIG中相互作用的item和KG中相关联的实体应被视为同构节点,但实际上它们处于不同的潜在空间中。
- 由于用户所交互的物品类型通常非常广泛,UIG中的高阶交互可能与原始物品的潜在语义表示具有完全不同的意义,这将给嵌入带来噪声。下图中Forrest Gump是喜剧而12 Monkeys是恐怖片,两者完全不相关。
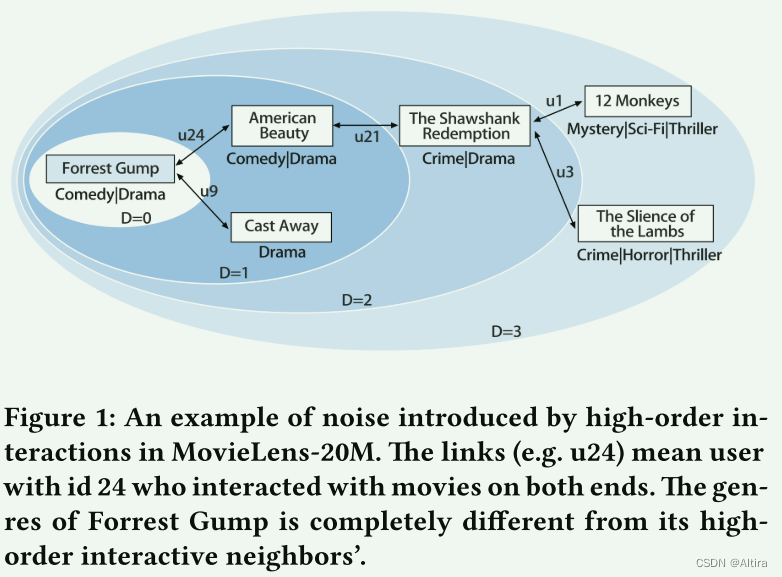
- 为了解决现有基于KG推荐方法的局限性,本文提出了一种端到端(end-to-end)协作知识感知注意网络模型。本文提出了一种端到端协作知识感知注意网络模型,该模型将用户-物品交互中明确编码的协作信号与KG中辅助知识关联进行了无缝结合。
- 有两种设计:
- 异构传播(Heterogeneous propagation),它由协作传播和知识图传播两部分组成,将交互和知识视为两个不同空间中的信息,并将其自然地组合在一起,使它们共享不同的权重,从而对嵌入做出贡献。
- 知识意思注意力嵌入(Knowledge-aware attentive embedding),这是一种全新的知识意识神经注意机制,用于在不同条件下学习KG中相邻节点的不同权重。 ( K G A T 中不就已经有了吗?) \color{#FF7D00}{(KGAT中不就已经有了吗?)} (KGAT中不就已经有了吗?)
2、问题描述
- m个user集合 U = { u 1 , u 2 , … , u M } \mathcal{U}=\{u_1,u_2,\ldots,u_M\} U={u1,u2,…,uM}
- n个item集合 V = { v 1 , v 2 , … , v N } \mathcal{V}=\{v_1,v_2,\ldots,v_N\} V={v1,v2,…,vN}
- user-item interation matrix Y ∈ R M × N \mathbf{Y}\in\mathbb{R}^{M\times N} Y∈RM×N , y u v = 1 y_{uv}=1 yuv=1表示user u和item v 进行了交互。
- 知识图 G = { ( h , r , t ) ∣ h , t ∈ E , r ∈ R } \mathcal{G}=\{(h,r,t)|h,t\in\mathcal{E},r\in\mathcal{R}\} G={(h,r,t)∣h,t∈E,r∈R} , R R R 中包含了正向关系(Actorof)和反向关系(ActedBy)。
- 集合 A = { ( v , e ) ∣ v ∈ V , e ∈ E } \mathcal{A}=\{(v,\mathrm{e})|v\in\mathcal{V},\mathrm{e}\in\mathcal{E}\} A={(v,e)∣v∈V,e∈E} ,其中(v, e)表示在知识图中项目v可以与实体e对齐,相同的物品在item和entity中都有,借此可以对齐。
- 得到了交互矩阵和知识图,下面需要应该预测函数 y ^ u v = F ( u , v ∣ Θ , G ) \hat{y}_{u v}={\cal F}(u,v|\Theta,{\cal G}) y^uv=F(u,v∣Θ,G) , Θ \Theta Θ表示函数F的模型参数
3、方法
模型架构: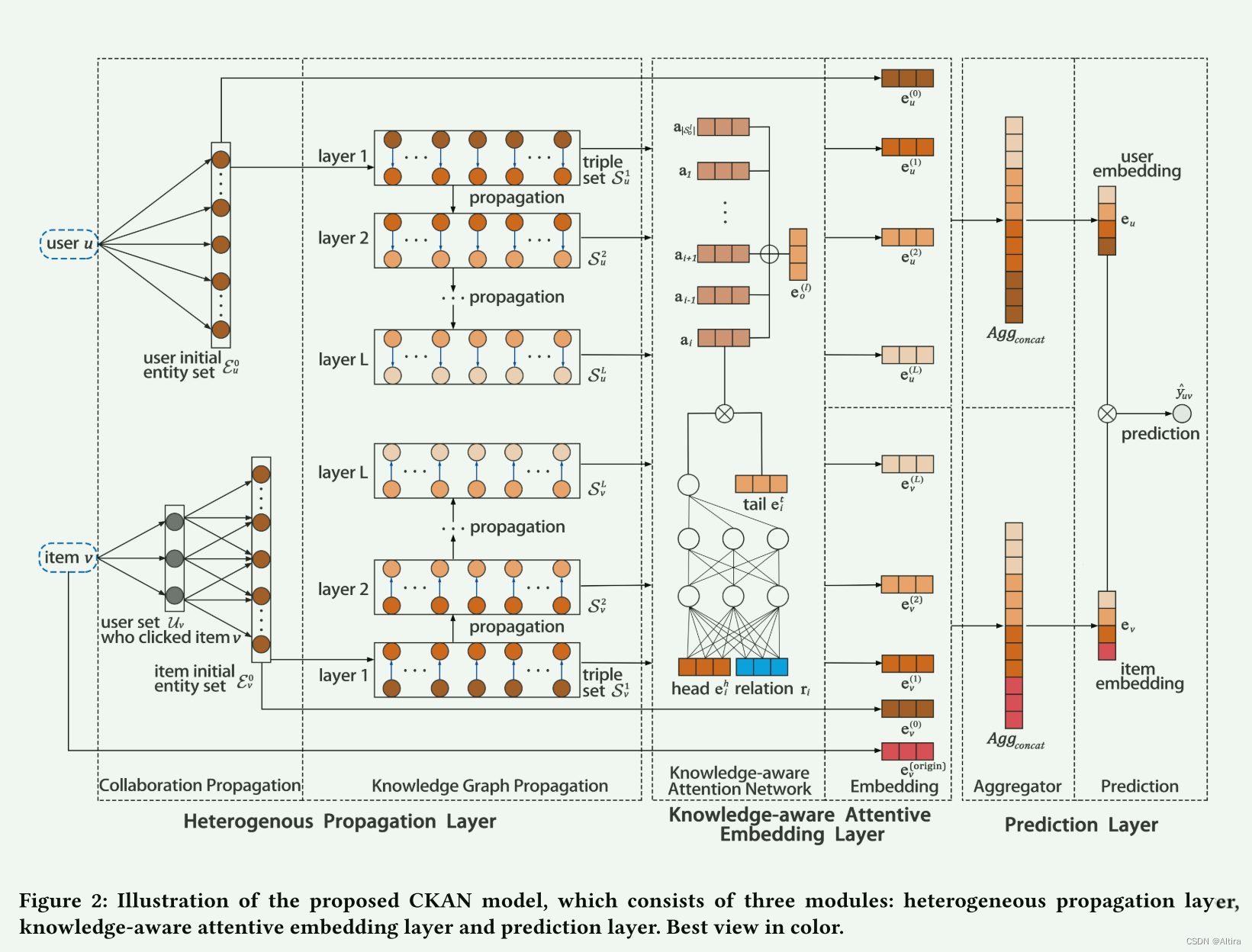
- 异构传播层(异构是指两种不同的传播结构),通过用户-物品交互和知识图中的知识关联来传播协作信号
- 知识感知注意嵌入层,提出一种新的神经网络知识感知注意机制,学习同一实体集中实体的基于知识的权重,生成实体的加权表示
- 预测层,聚合不同传播层的用户和商品的表示,并输出预测的点击概率。
3.1、异构传播层
3.1.1 协同传播
与传统的使用独立的潜在向量不同,本文使用相关item表示user u,通过用户u 的相关物品集得到历史交互,可以通过items和entites的对齐可以得到KG的初始集合。用户u的初始实体集:
E
u
0
=
{
e
∣
(
v
,
e
)
∈
A
a
n
d
v
∈
{
v
∣
y
u
v
=
1
}
}
\mathcal{E}_u^0=\{\mathrm{e}|(v,\mathrm{e})\in\mathcal{A}\ and \ v\in\{v|y_{uv}=1\}\}
Eu0={e∣(v,e)∈A and v∈{v∣yuv=1}}
相似的,与同一物品进行过交互的用户也可以由于他们相似的行为偏好而为该物品的特征表示做出贡献。将同一个用户交互过的物品定义为协作邻居,并将物品v的协作item集定义为:
V
v
=
{
v
u
∣
u
∈
{
u
∣
y
u
v
=
1
}
a
n
d
y
u
v
u
=
1
}
\mathcal{V}_v=\{v_u|u\in\{u|y_{uv}=1\} \ and \ y_{uv_u}=1\}
Vv={vu∣u∈{u∣yuv=1} and yuvu=1}
公式的意思应该就是v和vu是邻居,他们都和u有过交互,选出这样的物品
综合协作item集和对齐集A=(v,e),item v的初始实体集定义如下:
E
v
0
=
{
e
∣
(
v
u
,
e
)
∈
A
a
n
d
v
u
∈
V
v
}
\mathcal{E}_v^0=\{\mathcal{e}|(v_u,\mathrm{e})\in\mathcal{A}\ and\ v_u\in\mathcal{V}_v\}
Ev0={e∣(vu,e)∈A and vu∈Vv}
3.1.2 知识图谱传播
用户u与物品v的实体集定义递归表示为:
E
o
l
=
{
t
∣
(
h
,
r
,
t
)
∈
G
a
n
d
h
∈
E
o
l
−
1
}
,
l
=
1
,
2
,
…
,
L
\mathcal{E}_o^l=\{t|(h,r,t)\in\mathcal{G}\ and\ h\in\mathcal{E}_o^{l-1}\},\quad l=1,2,\ldots,L
Eol={t∣(h,r,t)∈G and h∈Eol−1},l=1,2,…,L
L是到初始实体集的距离,下表o是u或v的统一占位符。
根据实体集的定义,为用户u和物品v定义第l个三元集的公式定义如下:
S
o
l
=
{
(
h
,
r
,
t
)
∣
(
h
,
r
,
t
)
∈
G
and
h
∈
E
o
l
−
1
}
,
l
=
1
,
2
,
…
,
L
\mathcal{S}_o^l=\{(h,r,t)|(h,r,t)\in\mathcal{G}\textit{\ and\ }h\in\mathcal{E}_o^{l-1}\},\quad l=1,2,\ldots,L
Sol={(h,r,t)∣(h,r,t)∈G and h∈Eol−1},l=1,2,…,L
通过协同传播获得的初始实体集类似于声源,在kg介质中逐层传播,由近到远。通过基于知识的深度传播,成功捕获了用户与物品的基于知识的高阶交互信息,有效地提高了模型用潜在向量表示用户与物品的能力。
3.2 知识意识的注意力嵌入
通过对尾部实体的不同注意权重来揭示其在得到不同头部实体和不同关系时的不同含义。
假设(h,r,t)是第l层的第i个三元组,构建一个尾部实体的注意力嵌入的
a
i
a_i
ai如下:
a
i
=
π
(
e
i
h
,
r
i
)
e
i
t
\mathrm{a}_i=\pi(\mathrm{e}_i^h,\mathrm{r}_i)\mathrm{e}_i^t
ai=π(eih,ri)eit
e i h e_i^h eih是头实体的嵌入, r i r_i ri是关系嵌入, e i t e_i^t eit是第i个三元组的尾实体嵌入
π
(
e
i
h
,
r
i
)
\pi(e_i^h,r_i)
π(eih,ri)控制着由头部实体产生的注意力权重以及头部和尾部之间的关系。我们通过一个类似于注意力机制[18]的神经网络来实现π(·)函数,其表达式如下:
Z
0
=
R
e
L
U
(
W
0
(
e
i
h
∣
∣
r
i
)
+
b
0
)
π
(
e
i
h
,
r
i
)
=
σ
(
W
2
ReLU
(
W
1
z
0
+
b
1
)
+
b
2
)
\begin{gathered} Z_0 =\mathrm{ReLU}{\Big(}W_{0}{\big(}e_{i}^{h}||\mathrm{r}_{i}{\big)}+\mathrm{b}_{0}{\Big)} \\ \pi(\mathrm{e}_{i}^{h},\mathrm{r}_{i}) =\sigma\Big(\text{W}_2\text{Re}\text{LU}\big(\text{W}_1\text{z}_0+\text{b}_1\big)+\text{b}_2\Big) \end{gathered}
Z0=ReLU(W0(eih∣∣ri)+b0)π(eih,ri)=σ(W2ReLU(W1z0+b1)+b2)
接下来,我们采用softmax函数对整个三元组的系数进行归一化处理:
π
(
e
i
h
,
r
i
)
=
exp
(
π
(
e
i
h
,
r
i
)
)
∑
(
h
′
,
r
′
,
t
′
)
∈
S
o
l
exp
(
π
(
e
i
h
′
,
r
i
′
)
)
\pi(\mathrm e_i^h,\mathrm r_i)=\frac{\exp(\pi(\mathrm e_i^h,\mathrm r_i))}{\sum_{(h',r',t')\in S_o^l}\exp(\pi(\mathrm e_i^{h'},\mathrm r_i'))}
π(eih,ri)=∑(h′,r′,t′)∈Solexp(π(eih′,ri′))exp(π(eih,ri))
最后,我们得到用户u或项目v的第l层三元组的表示:
e
o
(
l
)
=
∑
i
=
1
∣
S
o
l
∣
a
i
(
o
)
,
l
=
1
,
2
,
…
,
L
\mathrm{e}_o^{(l)}=\sum_{i=1}^{|S_o^l|}\mathrm{a}_i^{(o)},l=1,2,\ldots,L
eo(l)=i=1∑∣Sol∣ai(o),l=1,2,…,L
注意,由于初始实体集中的实体就像知识传播的种子一样,最接近于原始表示,因此初始实体集与原始用户和项目有很强的联系。相应地,我们为user和item添加了初始实体集的表示:
e
o
(
0
)
=
∑
e
∈
E
o
0
e
∣
E
o
0
∣
\mathrm e_o^{(0)}=\frac{\sum_{\mathrm e\in\mathcal E_o^0}\mathrm e}{|\mathcal E_o^0|}
eo(0)=∣Eo0∣∑e∈Eo0e
特别地,itemv有其原始表示的相关实体,而用户u没有。原始相关实体是潜在语义空间中与项目v最接近的节点。因此,我们将它添加到item v的表示集中,并按如下方式定义它:
e
v
(
o
r
i
g
i
n
)
=
∑
e
∈
{
e
∣
(
e
,
v
)
∈
A
}
e
∣
{
e
∣
(
e
,
v
)
∈
A
}
∣
\begin{aligned} & \\ \mathrm{e}_{v}^{(orig in)}& =\frac{\sum_{\mathrm{e}\in\{\mathrm{e}|(\mathrm{e},v)\in\mathcal{A}\}}\mathrm{e}}{|\{\mathrm{e}|(\mathrm{e},v)\in\mathcal{A}\}|} \end{aligned}
ev(origin)=∣{e∣(e,v)∈A}∣∑e∈{e∣(e,v)∈A}e
在进行知识感知的注意嵌入后,我们将包含用户u和物品v的基于知识的注意加权表示和附加表示的表示集表示为:
T
u
=
{
e
u
(
0
)
,
e
u
(
1
)
,
…
,
e
u
(
L
)
}
T
v
=
{
e
v
(
o
r
i
g
i
n
)
,
e
v
(
0
)
,
e
v
(
1
)
,
…
,
e
v
(
L
)
}
\begin{aligned} &T_u =\{\mathrm{e}_{u}^{(0)},\mathrm{e}_{u}^{(1)},\dots,\mathrm{e}_{u}^{(L)}\} \\ &T_v =\{\mathrm{e}_{v}^{(origin)},\mathrm{e}_{v}^{(0)},\mathrm{e}_{v}^{(1)},\dots,\mathrm{e}_{v}^{(L)}\} \end{aligned}
Tu={eu(0),eu(1),…,eu(L)}Tv={ev(origin),ev(0),ev(1),…,ev(L)}
3.3 模型预测
实现了三种聚合器,将上 T u T_u Tu、 T v T_v Tv多个表示聚合为用户和物品的单个表示
-
和聚合器
a g g s u m ( o ) = σ ( W a ⋅ ∑ e o ∈ T o e o + b a ) agg_{sum}^{(o)}=\sigma\Big(\text{W}_a\cdot\sum_{\mathrm e_o\in\mathcal T_o}\mathrm e_o+\text b_a\Big) aggsum(o)=σ(Wa⋅eo∈To∑eo+ba) -
池化聚合器:取多个向量的最大值作为同一纬度,然后进行非线性变换:
a g g p o o l ( o ) = σ ( W a ⋅ p o o l m a x ( T o ) + b a ) agg_{pool}^{(o)}=\sigma\Big(\text{W}_a\cdot pool_{max}\big(\mathcal{T}_o\big)+\text{b}_a\Big) aggpool(o)=σ(Wa⋅poolmax(To)+ba) -
连接聚合器
a g g c o n c a t ( o ) = σ ( W a ⋅ ( e o ( i 1 ) ∣ ∣ e o ( i 2 ) ∣ ∣ … ∣ ∣ e o ( i n ) ) + b a ) agg_{concat}^{(o)}=\sigma\Big(\text{W}_a\cdot(\mathrm{e}_o^{(i_1)}||\mathrm{e}_o^{(i_2)}||\dots||\mathrm{e}_o^{(i_n)})+\mathrm{b}_a\Big) aggconcat(o)=σ(Wa⋅(eo(i1)∣∣eo(i2)∣∣…∣∣eo(in))+ba)
其中 e 0 i k ∈ T o e_0^{ik}\in \mathcal T_o e0ik∈To 。
使用
e
u
e_u
eu表示用户的聚合向量,
e
v
e_v
ev表示物品的聚合向量,预测得分:
y
^
u
v
=
e
u
⊤
e
v
\hat{y}_{uv}=\mathrm{e}_{u}^{\top}\mathrm{e}_{v}
y^uv=eu⊤ev
3.4 损失函数
为了平衡正样本和负样本的数量,保证模型训练的效果,我们为每个用户提取与正样本相同数量的负样本。损失函数如下:
L
=
∑
u
∈
U
(
∑
v
∈
{
v
∣
(
u
,
v
)
∈
P
+
}
J
(
y
u
v
,
y
^
u
v
)
−
∑
v
∈
{
v
∣
(
u
,
v
)
∈
P
−
}
J
(
y
u
v
,
y
^
u
v
)
)
+
λ
∣
∣
Θ
∣
∣
2
2
\begin{aligned} L& =\sum\limits_{u\in\mathcal{U}}\Big(\sum\limits_{v\in\{v|(u,v)\in\mathcal{P}^{+}\}}\mathcal{J}(y_{u v},\hat{y}_{u v})- \\ &\sum_{v\in\{v|(u,v)\in\mathcal{P}^{-}\}}\mathcal{J}(y_{uv},\hat{y}_{uv})\Big)+\lambda||\Theta||_2^2 \end{aligned}
L=u∈U∑(v∈{v∣(u,v)∈P+}∑J(yuv,y^uv)−v∈{v∣(u,v)∈P−}∑J(yuv,y^uv))+λ∣∣Θ∣∣22
其中
J
\mathcal J
J是交叉熵损失,P+表示正user-item集合,P-表示负,
Θ
=
{
E
,
R
,
W
i
,
b
i
,
∀
i
∈
{
0
,
1
,
2
,
a
}
}
\Theta=\{\mathrm{E},\mathrm{R},\mathrm{W}_{i},\mathrm{b}_{i},\forall i\in\{0,1,2,a\}\}
Θ={E,R,Wi,bi,∀i∈{0,1,2,a}} 是模型参数集,
∣
∣
Θ
∣
∣
2
2
||\Theta||_2^2
∣∣Θ∣∣22 由
λ
\lambda
λ 参数化的L2正则化。

















 1578
1578

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









