









文章目录
絮絮叨叨
本来考完试那阵发来着,发了几个忘了,最近有人问我才想起来原来没发完呀,就把后面的发出来了,有点想法想把所有的笔记汇总做个网站,但是又懒得动hhh,就在csdn将就一下吧
编译原理可以说就是明牌考试,我就考那些大题,你搞会了就能拿分,搞不会就补考,就这样简单粗暴hhhh,涉及到的大题每一章基本都有,步骤我笔记里面也都有了,老师最后一节课也会说他考试考什么,而且有往年题!!!
考试题型我记得是10选择+几个大题,应该是这样,可以参考往年卷,老师也会说,选择题感觉难度挺大,不是很好得分,大题呃,直接明牌(参考最后一部分题目总结),你会的话就能得分,所以就必须要把那些题目全部搞会,最起码把往年题能做出来吧,然后那些概念什么的最好自己把定义搞明白,这个集那个集的,到后面多了基本都是靠定义去分的(反正我是这样hhh),有时候不知道写的是哪个性质,但是这类题看着就应该这么写,所以步骤一定一定得会,下面应该都有。
复习建议的话,建议多留几天复习,这玩意复习起来挺难的,先把那些每一章笔记都先看一遍(全部!!!),然后看的时候根据最后的考试题类型把这一章的大题步骤搞明白,然后再把那个往年题一做,就这样一章一章复习完,然后再看看这个博客里面汇总的一些东西(我现在已经忘了里面是啥了,但是我本地markdown名字叫复习汇总,所以应该内容不会太离谱),全部复习完了之后再把所有题从前到后挨着做一遍,最好是随机抽那种(因为你可能记得它是第几章的然后去套哪一章的方法),直到自己能全部做出来基本拿90+就很稳了
要是实在不会的话,呃,那就只能选择性放弃了,这门确实挺难,你步骤看不懂,有哪个概念不懂,你就是做不出来,然后每个题的分都基本固定,自己看着搞吧,最好留点容错,别给自己搞挂了
写在最后,这门基本是最后一门考试了,大家考完可能就去成都实习或者是准备考研、保研、找工作了,希望大家一切顺利,拿到自己理想的offer,三者不论哪个都需要心态放平,不断努力,加油!!
各章笔记汇总
- 编译原理第一章笔记 – 绪论
- 编译原理第二章笔记 – 上下文无关文法
- 编译原理第三章笔记 – 词法分析
- 编译原理第四章笔记 – 自上而下的语法分析
- 编译原理第五章笔记 – 自下而上的语法分析
- 编译原理第六章笔记 – 属性文法和语法制导翻译
- 编译原理第七章笔记 – 中间代码生成
第二章
-
文法是描述语言的语法结构的形式规则(即语法规则)
-
文法主要分成四类:0,1,2,3四类文法,与程序语言有关的是上下文无关文法
-
一个上下文无关文法G是一个四元式 ( V T , V N , S , P ) (V_T,V_N,S,P) (VT,VN,S,P),其中:
-
V T V_T VT:是非空有限集,它的每个元素是终结符号;
-
V N V_N VN:是非空有限集,它的每个元素是非终结符号;
V T ∩ V N = Φ V T ∪ V N = V V_T\cap V_N=\Phi \qquad V_T\cup V_N = V VT∩VN=ΦVT∪VN=V -
S: S ∈ V N S\in V_N S∈VN,称为开始符号
-
P P P:产生式集合(有限),每个产生式的形式是 { P → α ∣ P ∈ V N , α ∈ ( V T ∪ V N ) ∗ , S 至少一次为 P } \{P\rightarrow\alpha|P\in V_N,\alpha\in(V_T\cup V_N)^*,S至少一次为P\} {P→α∣P∈VN,α∈(VT∪VN)∗,S至少一次为P}
-
-
直接推出:如: ( α A β ) R ( α γ β ) (\alpha\ A\ \beta)\ R \ (\alpha \ \gamma\ \beta) (α A β) R (α γ β),表示:若 A → γ ∈ P , α 、 β ∈ V ∗ A\rightarrow \gamma\in P,\alpha、\beta\in V^* A→γ∈P,α、β∈V∗,则 R R R就是直接推出, R R R记为 ⇒ \Rightarrow ⇒。即: α A β ⇒ α γ β \alpha\ A \ \beta \Rightarrow \alpha \ \gamma\ \beta α A β⇒α γ β
-
推导:推导的最后是由终结符组成的终结符串
- u o ⇒ + u n u_o\stackrel{+}{\Rightarrow}u_n uo⇒+un:表示从 u o u_o uo出发,经一步或若干步,可以推导出 u n u_n un
- u o ⇒ ∗ u n u_o\stackrel{*}{\Rightarrow}u_n uo⇒∗un:表示从 u o u_o uo出发,经零步或若干步,可以推导出 u n u_n un
-
从开始符号开始推导得到的串称为文法的句型, S ⇒ ∗ α , α ∈ V ∗ S\stackrel{*}{\Rightarrow}\alpha,\alpha\in V^* S⇒∗α,α∈V∗,则称 α \alpha α为G的句型,如果要求这个串全部由终结符组成,则这个串是文法的句子,文法G产生的句子的全体是一个语言,记为 L ( G ) L(G) L(G)
-
句子一定是终结符串,但是终结符串不全是句子,生成的串要与开始符号存在 ⇒ + \stackrel{+}{\Rightarrow} ⇒+关系才可以
-
句型是终结符和非终结符的混合串,但是他们的混合串不一定全是句型,生成的串需要与开始符号存在 ⇒ ∗ \stackrel{*}{\Rightarrow} ⇒∗关系才可以(S是不是句型?)
-
语言是由句子构成的, V T ∗ V_T^* VT∗不代表语言(表示的意思是所有终结字符串), V ∗ V^* V∗不代表句型集(代表所有字符和非终结字符的串)
-
一个文法可以通过最左推导和最右推导得到
-
如果文法G的某一句子有两个不同的树,则G为二义的
-
语言的二义性问题与文法的二义性问题:
- 如语言找到一个文法是无二义的,则语言是无二义的
- 如未找到一个文法是无二义的,则也不能断定它二义,但先天二义也存在
- 文法的二义性是不可判定的(因为文法的二义性由句子的语法树判定,不可能对无穷句子来判别)
第三章
- 词法分析器输出的单词符号有五种:关键字,标识符,常数,界符,运算符
- 单词类别可以有一类一种和一符一种
- 单词符号表示为二元式:(单词种别,单词自身的值)
- 词法分析器的设计前提是把Scanner作为一个独立的子程序(除此之外可以把Scanner作为语法分析的子程序)
- 预处理是为了去掉语句中的空白符,回车符等
- 预处理子程序从输入缓冲区中读取字符,将处理结果放入扫描缓冲区中交由扫描器使用
- 扫描缓冲区包含起点指示器和搜索指示器,是由两个互补的扫描缓冲区组成的,每个的大小是120个字符
- 状态转换图的功能:识别符合一定要求的字符串,节点代表状态,状态之间使用箭弧链接,箭弧上的标记(字符)代表在射出节点状态下可能出现的输入字符或字符类
- 可以使用超前搜索来识别单词符号,具体表现为终态结点上的*
- 字母表是一个非空有穷集合,通常用 Σ \Sigma Σ表示,其中的元素称为字母,或者符号,或者字符(一般都是称为字符)
- 字母表的两个特性:非空性和有穷性(字母表中的字符特性:整体性和可辨认性)
- Σ \Sigma Σ的正闭包( Σ + \Sigma^+ Σ+), Σ \Sigma Σ的克林闭包( Σ ∗ \Sigma^* Σ∗,默认是这个,与正闭包的区别只在于增加了空串,即 Σ ∗ = { ε } ∪ Σ + \Sigma^*=\{\varepsilon\}\cup\Sigma^+ Σ∗={ε}∪Σ+)
- 对于任何 x ∈ Σ ∗ x\in\Sigma^* x∈Σ∗,x即 Σ \Sigma Σ上的一个句子(sentence),也叫做符号串
- 证明两个正规集相等可以从正规集出发,证明集合相等
- 确定有限自动机,DFA M是一个五元式
M
=
(
S
,
Σ
,
δ
,
s
0
,
F
)
M=(S,\Sigma,\delta,s_0,F)
M=(S,Σ,δ,s0,F),其中
- S是一个有限集,它的每个元素称为一个状态
- Σ \Sigma Σ是一个有穷字母表,它的每个元素称为一个输入字符
- δ \delta δ是一个从 S × Σ S\times\Sigma S×Σ至 S S S的单值部分映射, δ ( s , a ) = s ′ \delta(s,a)=s' δ(s,a)=s′意味着:当现行状态为s、输入字符为a时,将转换到下一状态 s ′ s' s′。我们称 s ′ s' s′为s的一个后继状态
- s 0 ∈ S s_0\in S s0∈S是唯一的初态(不可空)
- F ⊆ S F\subseteq S F⊆S是一个终态集(可空)
- 一个DFA可以用一个矩阵表示,该矩阵的行表示状态,列表示字符,矩阵元素表示 δ ( s , a ) \delta(s,a) δ(s,a)的值,这个矩阵称为状态转换矩阵
- 约定进入的有向箭头表示初态节点,终态结点需要用双圈表示
- 非确定有限自动机,NFA M也是一个五元式
M
=
{
S
,
Σ
,
δ
,
S
0
,
F
}
M =\{S,\Sigma,\delta,S_0,F\}
M={S,Σ,δ,S0,F},其中
- S是一个有限集,它的每一个元素称为一个状态
- Σ \Sigma Σ是一个有穷字母表,它的每个元素称为一个输入字符
- δ \delta δ是一个从 S × Σ ∗ S\times \Sigma^* S×Σ∗至S的子集的映射,即 δ : S × Σ ∗ → 2 s \delta:S\times \Sigma^*\rightarrow2^s δ:S×Σ∗→2s
- S 0 ⊆ S S_0\subseteq S S0⊆S是一个非空初态集(可以有多个,但至少有一个)
- F ⊆ S F\subseteq S F⊆S是一个终态集(可空)
- DFA与NFA的区别
- NFA可以有多个初态
- 弧上的标记可以是 Σ ∗ \Sigma^* Σ∗中的一个字(甚至可以是一个正规式),而不一定是单个字符
- 同一个字可能出现在同状态射出的多条弧上
第四章
- 语法分析的任务:分析一个文法的句子的结构
- 自上而下推导是从文法的开始符号出发,反复使用各种产生吃,寻找匹配的推导,即根据文法的产生式的规则,把串中出现的产生式的左部符号替换成右部,主要方法有递归下降分析法,预测分析程序,LL分析法
- 自下而上推导是从输入串开始,逐步进行规约,直到文法的开始符号,规约就是根据文法的产生式规则,把串中出现的产生式的右部替换成左部符号,主要方法有:算符优先分析法,LR分析法
- 在进行自上而下分析时候,有两个问题非常重要:左递归问题与回溯问题
- 三种形式的左递归:直接左递归,间接左递归,潜在左递归
- 直接左递归改造前不能含有空字产生式,即右侧不能含有
ε
\varepsilon
ε
- 消除方法:如果 A → A α ∣ β A\to A\alpha|\beta A→Aα∣β,其中 β \beta β不以A开头,则修改规则为 A → β A ′ A ′ → α A ′ ∣ ε A\to \beta A'\quad A'\to \alpha A'|\varepsilon A→βA′A′→αA′∣ε
- 可以通过代入将间接和潜在左递归转换为直接左递归,一般是按照字母表的升序进行排序代入的
- 消除回溯原因的时候需要引入首符集, F I R S T ( α ) = { a ∣ α ⇒ ∗ a ⋅ ⋅ ⋅ , a ∈ V T } ,若 α ⇒ ∗ ε ,规定 ε ∈ F I R S T ( α ) FIRST(\alpha)=\{a|\alpha\stackrel{*}{\Rightarrow}a \cdot\cdot\cdot,a\in V_T\},若\alpha\stackrel{*}{\Rightarrow}\varepsilon,规定\varepsilon\in FIRST(\alpha) FIRST(α)={a∣α⇒∗a⋅⋅⋅,a∈VT},若α⇒∗ε,规定ε∈FIRST(α), F I R S T ( α ) FIRST(\alpha) FIRST(α)不可以称为首终结符集,因为有 ε ∈ F I R S T ( α ) \varepsilon\in{FIRST(\alpha)} ε∈FIRST(α)
- 清楚回溯的方法是使非终结符A的所有候选式的首符集两两不相交
- 方法为提取公因式,然后把规则改写为: A → δ A ′ ∣ γ 1 ∣ γ 2 ∣ ⋅ ⋅ ⋅ ∣ γ m A ′ → β 1 ∣ β 2 ∣ ⋅ ⋅ ⋅ ∣ β n A\to \delta A'|\gamma_1|\gamma_2|\cdot\cdot\cdot|\gamma_m\quad A'\to \beta_1|\beta_2|\cdot\cdot\cdot|\beta_n A→δA′∣γ1∣γ2∣⋅⋅⋅∣γmA′→β1∣β2∣⋅⋅⋅∣βn
- 在消除了左递归和回溯的情况下,构造一个自上而下的分析程序,该分析程序由一组递归过程组成,每个过程对应文法的一个非终结符,这样的一个分析程序称为递归下降分析器
- 也就是在一个过程中,递归调用其他过程进行处理
- 缺点是无成功和失败消息返回,并且出错位置不确切
- 使用一张表和一个栈实现递归下降的语法分析程序叫做预测分析程序
- 需要包含四个部分:一个输入的终结符串(右端为#),一个栈(栈底为#),分析表(需要实现建好),输出
- 栈顶符号X和当前输入符号a,由(X,a)决定程序动作,三种可能:
- 若 X = a = # X=a=\# X=a=#,分析停止,宣告成功地完成分析
- 若 X = a ≠ # X=a\neq \# X=a=# ,则X弹出栈,前移输入指针
- 若 X ∈ V N X\in V_N X∈VN,则去查分析表M的元素M[X,a],该元素或为X的产生式,或者为一个出错元素
- 在构造预测分析表的过程中需要用到首符集和后继符集
- F I R S T ( α ) = { a ∣ α ⇒ ∗ a ⋅ ⋅ ⋅ , a ∈ V T } , 若 α ⇒ ∗ ε ,规定 ε ∈ F I R S T ( α ) FIRST(\alpha)=\{a|\alpha\stackrel{*}{\Rightarrow}a\cdot\cdot\cdot,a\in V_T\},若\alpha\stackrel{*}{\Rightarrow}\varepsilon,规定\varepsilon\in FIRST(\alpha) FIRST(α)={a∣α⇒∗a⋅⋅⋅,a∈VT},若α⇒∗ε,规定ε∈FIRST(α)
- F O L L O W ( A ) = { a ∣ S ⇒ ∗ α A a β , a ∈ V T , α , β ∈ V ∗ } FOLLOW(A)=\{a|S\stackrel{*}{\Rightarrow}\alpha Aa\beta,a\in V_T,\alpha,\beta \in V^*\} FOLLOW(A)={a∣S⇒∗αAaβ,a∈VT,α,β∈V∗},即句型当中的跟在非终结符后面的终结符
- LL(1)分析法:第一个L表示从左到右扫描输入串,第二个L表示最左推导,(1)表示分析时每一步只需向前查看一个符号
- 如果一个的分析表M不含多重定义入口,则称他是一个LL(1)文法
- LL(1)文法的条件:对于文法的每一个非终结符A的任何两个不同的产生式,有:
- F I R S T ( α ) ∩ F I R S T ( β ) = ϕ FIRST(\alpha)\cap FIRST(\beta) = \phi FIRST(α)∩FIRST(β)=ϕ
- 若 β ⇒ ∗ ε \beta \stackrel{*}{\Rightarrow} \varepsilon β⇒∗ε,则 F I R S T ( α ) ∩ F O L L O W ( A ) = ϕ FIRST(\alpha) \cap FOLLOW(A) = \phi FIRST(α)∩FOLLOW(A)=ϕ
第五章
-
自下而上分析:从输入串开始,逐步进行规约,知道规约到文法的开始符号S,即“移进 - 规约”法
-
规约:利用栈,输入符号移进栈,当栈顶形成P的候选式时,就规约为它的左部P符号
-
短语:令G是一个文法,S是文法的开始符号,若 α β δ \alpha \beta \delta αβδ是文法G的一个句型,如果有 S ⇒ ∗ α A δ 且 A ⇒ + β S\stackrel{*}{\Rightarrow}\alpha A \delta且 A\stackrel{+}{\Rightarrow}\beta S⇒∗αAδ且A⇒+β,则称 β \beta β是句型 α β δ \alpha\beta\delta αβδ相对于非终结符A的短语
-
直接短语:如果有 A → β A\to \beta A→β,则称 β \beta β是句型 α β δ \alpha\beta\delta αβδ相对于规则 A → β A\to \beta A→β的直接短语
-
句柄:一个句型的最左直接短语称为该句型的句柄
-
规范推导:即最右推导
-
规范句型:由规范推导所得到的句型称为规范句型
-
规范归约:是关于句型 α \alpha α的一个最右推导的逆过程,也称最左规约
-
所谓素短语是指这样一个短语,它至少含有一个终结符,并且除自身之外不再含任何更小的素短语
-
句型最左边的那个素短语叫最左素短语
-
在按“移进-规约”方式进行自上而下语法分析时候,可规约串是句柄
-
分析程序的动作:移进,规约,接受,出错
-
直观算符优先分析算法:通过构造运算符栈和操作数栈来实现,在读入数字时候直接入栈,读入符号时候与栈顶符号进行比较,如果当前读入符号优先级高则符号入栈,如果当前符号优先级低,则处理栈顶的符号了,如果相等且两个都为#,则分析成功
-
需要注意的是终结符之间的优先关系的传递以及逆都不成立
-
算符文法:如果一个文法的任何产生式右部都不含两个并列的非终结符,即不含有如下形式的产生式右部 ⋯ Q R ⋯ \cdots QR \cdots ⋯QR⋯,则我们称该文法为算符文法
-
算符优先分析算法:如果一个算符文法中的任何终结符对至多只满足 a ≖ b , a ⋖ b , a ⋗ b a\eqcirc b,a\lessdot b, a\gtrdot b a≖b,a⋖b,a⋗b关系之一,则称该文法为算符优先文法,算符优先分析法不是一种规范归约法
-
优先函数:
-
我们把每个终结符 θ \theta θ与两个自然数 f ( θ ) f(\theta) f(θ)和 g ( θ ) g(\theta) g(θ)相对应,使得:
- 若 θ 1 ⋖ θ 2 \theta_1\lessdot \theta_2 θ1⋖θ2,则 f ( θ 1 ) < g ( θ 2 ) f(\theta_1)< g(\theta_2) f(θ1)<g(θ2)
- 若 θ 1 ≖ θ 2 \theta_1\eqcirc \theta_2 θ1≖θ2,则 f ( θ 1 ) = g ( θ 2 ) f(\theta_1)= g(\theta_2) f(θ1)=g(θ2)
- 若 θ 1 ⋗ θ 2 \theta_1\gtrdot \theta_2 θ1⋗θ2,则 f ( θ 1 ) > g ( θ 2 ) f(\theta_1)> g(\theta_2) f(θ1)>g(θ2)
函数 f f f称为入栈优先函数, g g g称为比较优先函数,构造的方法可以再去看一下笔记的对应地方
-
LR分析程序:自左向右扫描,识别句柄,自下而上规约的语法分析程序
-
LR分析表的核心是分析表,由两部分组成:ACTION和GOTO
-
共有四种方法:LR(0),SLR,LR(1),LALR
-
LR文法:对于一个文法,如果能够构造一张分析表,使得它的每个入口均是唯一确定的,则我们把这个文法称为LR文法
-
文法G的每一个产生式的右部添加一个圆点,称为G的一个LR(0)项目,其意义是指明在分析过程中的某时刻我们能看到多大一部分
-
字的前缀:指该字的任意首部
-
活前缀:规范句型的一个前缀,该前缀不含句柄之后的任何符号,活前缀包含的经并不完整,完整了就会直接规约了
-
LR(0)文法:不存在移进规约冲突与规约规约冲突的文法
-
SLR其实就是SLR(1),S是Simple,也就是简单的LR(1)算法
-
如果除去搜索符之后,这两个集合是相同的,我们称两个LR(1)项目集具有相同的心
第六章
-
语义分析的任务是对语法分析所识别出的各类语法范畴,分析其含义,并进行初步翻译
-
包括两个方面的工作:静态语义检查和中间代码翻译
-
S属性文法和L属性文法的并集不是全体的属性文法,L属性文法是一个更大的属性文法,其中包含了S属性文法,但是L文法也不是全体的属性文法, { 属性文法 } ⊃ { L − 属性文法 } ⊃ { S − 属性文法 } \{属性文法\}\supset \{L-属性文法\} \supset \{S-属性文法\} {属性文法}⊃{L−属性文法}⊃{S−属性文法}
-
属性文法(也称为属性翻译文法)是在上下文无关文法的基础上,为每个文法符号(终结符或非终结符)配备若干相关的值(或者称为属性),属性加工的过程就是语义处理的过程
-
属性通常分为两类
- 综合属性:自下而上传递信息,根据子节点的属性和父节点自身的属性计算父节点的综合属性
- 继承属性:自上而下传递信息,根据父节点和兄弟节点的属性计算子节点的继承属性
-
语义规则:为文法的每个产生式都配备的一组属性的计算规则
-
终结符只有综合属性,他们由词法分析器提供
-
非终结符既可以有综合属性也可以有继承属性,文法的开始符号的所有继承属性作为属性计算前的初始值
-
为出现在产生式右边的继承属性和出现在产生式左边的综合属性都必须提供一个计算规则,左边的继承属性和右边的综合属性由其他产生式的属性计算规则或者属性计算器的参数提供
-
语义规则所描述的工作可以包括:属性计算,静态语义检查,符号表操作,代码生成
-
仅仅使用综合属性的属性文法称为S-属性文法
-
基于属性文法的处理过程:输入串 → \to →语法树 → \to →依赖图 → \to →语义规则计算次序
-
在一颗语法树中的结点的继承属性和综合属性之间的相互依赖关系可以由称作依赖图的一个有向图来描述,如果在一颗语法树中一个结点的属性b依赖于属性c,那么这个节点处计算b的语义规则必须在确定c的语义规则之后使用(在图中为c指向b)。
-
良定义属性文法:如果一个文法不存在属性之间的循环依赖关系,那么该属性文法为良定义的(我们只处理良定义的属性文法)
-
属性计算方法:
- 依赖图:建立属性之间相互关系的有向图,可能需要多遍的扫描才能完成
- 树遍历:按照某种顺序遍历语法树,在遍历的过程中计算属性,可能需要多次遍历才能计算完所有的属性
- 一遍扫描的属性计算方法:在语法分析的同时计算计算属性值,只需要一遍扫描即可,常用的方法有:S-属性文法和L-属性文法
-
一遍扫描的处理方法与所采用的语法分析方法和属性的计算次序密切相关
-
抽象语法树:在语法树中去掉对那些对翻译不必要的信息,从而获得更有效的源程序的中间表示,这种经变换过后的语法树称为抽象语法树,在抽象语法树中,操作符和关键字都不作为叶结点出现,而是把他们作为内部节点,即这些叶结点的父结点。
-
S-属性文法的翻译通常可以借助LR分析器来实现,在S-属性文法的基础上,LR分析器可以改造为一个翻译器,在对输入串进行语法分析的同时对属性进行计算
- 使用翻译栈进行来存放已经分析过的子树的信息,存储两项信息:state和val
- 用代码段来代替语义规则
-
词法分析:扫描器,语法分析:分析器,语义分析:翻译器
-
L-属性文法:如果对于每个产生式 A → X 1 X 2 ⋯ X n A\to X_1X_2\cdots X_n A→X1X2⋯Xn,其每个语义规则中的每个属性或者是综合属性,或者是 X j ( 1 ≤ j ≤ n ) X_j(1\le j \le n) Xj(1≤j≤n)的一个继承属性且这个继承属性仅依赖于:
- X j X_j Xj的左边符号 X 1 , X 2 , ⋯ , X j − 1 X_1,X_2,\cdots,X_{j-1} X1,X2,⋯,Xj−1的属性
- A的继承属性
-
属性文法可以看做是语言翻译的高级规范说明,其中隐去实现细节,是用户从明确说明翻译顺序的工作中解脱出来
-
翻译模式给出了使用语义规则进行计算的次序,在翻译模式中,和文法符号相关的属性和语义规则(也称为语义动作),用花括号{}括起来,插入到产生式右部的合适位置
-
在翻译模式中如果要使用自上而下的语法分析则必须需要消除文法中的左递归,这时候会引入一些其他的继承属性
-
自下而上计算继承属性的分析过程中实现了L-属性文法,这种方法可以实现任何基于LL(1)文法的L-属性文法,它还可以实现许多(不是所有)基于LR(1)文法的L-属性文法
-
通过引入标记非终结符可以从翻译模式中去掉嵌入在产生式中间的动作
-
通过改变基础文法来使用综合属性替代继承属性
题目总结
选择题





伪属性是在构造语法树时候用来站位的,本质还是一个综合属性

第一题(NFA确定化及DFA化简)
将NFA确定化为DFA,然后进行DFA的化简
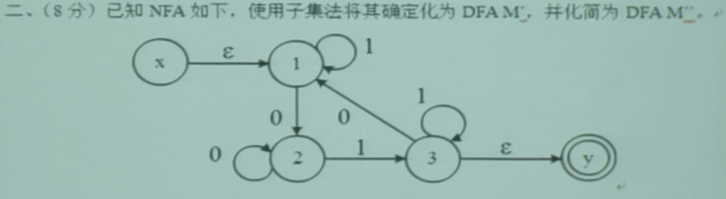
通过子集算法来将NFA确定化
确定化处理步骤:
-
找初始节点的空字闭包( ε _ C L O S U R E ( I ) \varepsilon\_CLOSURE(I) ε_CLOSURE(I)),写到第一行的第一列
-
再找一步转移闭包,再找空字闭包,写第一行的后面所有各列
-
然后看该集合是不是在第一列出现了
- 如果没出现把他写到第一列继续处理
-
直到全部处理结束
化简步骤:
- 先按终态和非终态结点进行分组
- 在两个组分别做一步转移(注意这里不用再找空字闭包了,因为已经是DFA了,DFA中不包含空串)
- 观察两个组的后继结点是不是前继结点的子集,如果不是则要进一步分割,如果是就不用了
- 根据后继结点是否相同进行分割
- 将分割后的结点写在左侧进行进一步的划分
第二题(LL(1)文法)





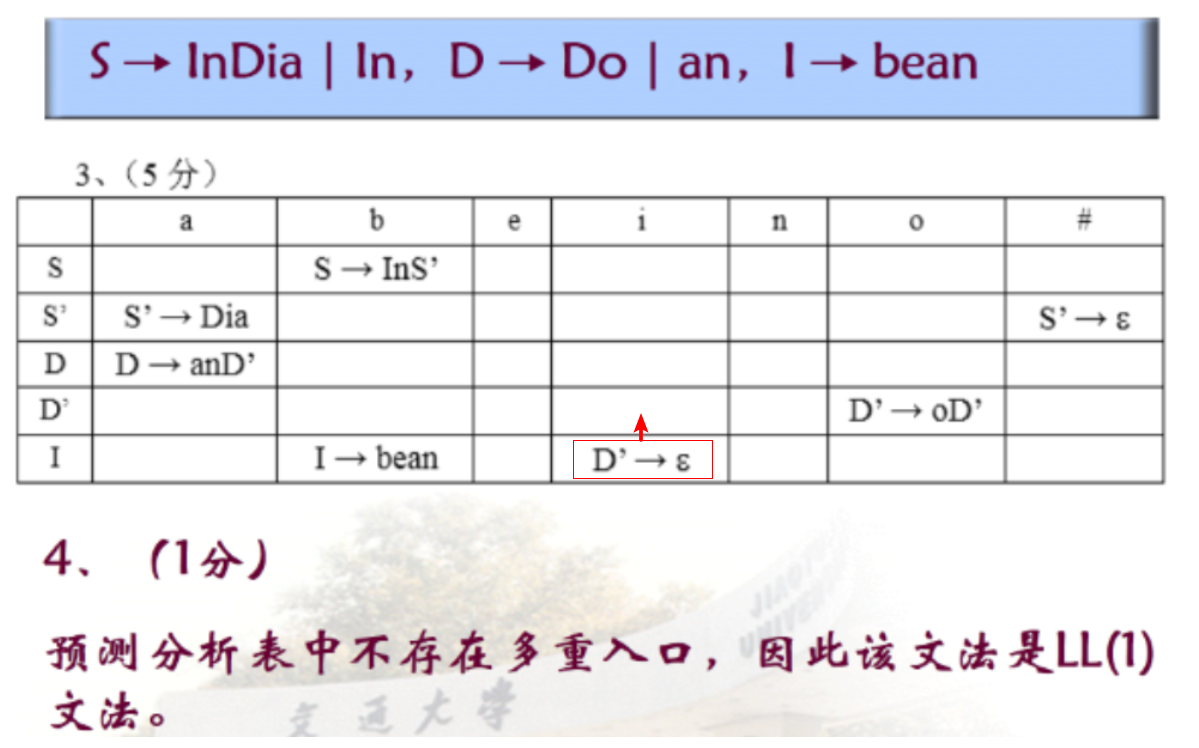
首符集中可以包含空串,但是后继符集中只能包含终结符
构造首符集
F I R S T ( α ) = { a ∣ α ⇒ ∗ a ⋅ ⋅ ⋅ , a ∈ V T } , 若 α ⇒ ∗ ε ,规定 ε ∈ F I R S T ( α ) FIRST(\alpha)=\{a|\alpha\stackrel{*}{\Rightarrow}a\cdot\cdot\cdot,a\in V_T\},若\alpha\stackrel{*}{\Rightarrow}\varepsilon,规定\varepsilon\in FIRST(\alpha) FIRST(α)={a∣α⇒∗a⋅⋅⋅,a∈VT},若α⇒∗ε,规定ε∈FIRST(α)
- 如果是终结符,则首符集就是自己,即 F I R S T ( X ) FIRST(X) FIRST(X)是 { X } \{X\} {X}
- 如果是非终结符(
X
∈
V
N
X\in V_N
X∈VN),
- 情况一:右侧第一个是终结符( X → a α X\to a\alpha X→aα),则 { a } ∪ F I R S T ( X ) \{a\}\cup FIRST(X) {a}∪FIRST(X)
- 情况二:右侧是空串( X → ε X\to \varepsilon X→ε),则 { ε } ∪ F I R S T ( X ) \{\varepsilon\}\cup FIRST(X) {ε}∪FIRST(X)
- 如果是非终结符,并且右侧的第一个元素是另一个非终结符(这里有个前提是,文法中已经不包括左递归了,所以这里只能是其他非终结符而不能是自己),Y中的首符集的非空串全部纳入X的首符集中
- 形式化语言描述是,若 X ∈ V N , X → Y ⋅ ⋅ ⋅ , Y ∈ V N X\in V_N,X\to Y\cdot\cdot\cdot,Y\in V_N X∈VN,X→Y⋅⋅⋅,Y∈VN,则 F I R S T ( Y ) ∖ { ε } ∪ F I R S T ( X ) FIRST(Y) \setminus \{\varepsilon\} \cup FIRST(X) FIRST(Y)∖{ε}∪FIRST(X)
- 如果Y的首符集包含空串 ε \varepsilon ε,则继续看Y后面的元素,按照这三个规则继续扩充X的首符集
- 如果右侧所有字符的首符集都包含空串,则把空串也加入X的首符集中
构造后继符集
F O L L O W ( A ) = { a ∣ S ⇒ ∗ α A a β , a ∈ V T , α , β ∈ V ∗ } FOLLOW(A)=\{a|S\stackrel{*}{\Rightarrow}\alpha Aa\beta,a\in V_T,\alpha,\beta \in V^*\} FOLLOW(A)={a∣S⇒∗αAaβ,a∈VT,α,β∈V∗},即句型当中的跟在非终结符后面的终结符
#属于FOLLOW(S),一定不能忘了
应用下列规则,直到再没有什么加进任一 F O L L O W FOLLOW FOLLOW为止
- #属于 F O L L O W ( S ) FOLLOW(S) FOLLOW(S)
- 若存在 A → a B β A\to a B \beta A→aBβ,则 F I R S T ( β ) ⊂ F O L L O W ( B ) , ε FIRST(\beta) \subset FOLLOW(B),\varepsilon FIRST(β)⊂FOLLOW(B),ε除外
- 若有 A → a B , 或 A → a B β 且 ε ∈ F I R S T ( β ) , 则 F O L L O W ( B ) ⊃ F O L L O W ( A ) A\to aB,或A\to a B \beta 且 \varepsilon\in FIRST(\beta),则FOLLOW(B) \supset FOLLOW(A) A→aB,或A→aBβ且ε∈FIRST(β),则FOLLOW(B)⊃FOLLOW(A),把A的位置用 α B \alpha B αB替换之后,原来跟在A后面的现在就跟在B的后面了
构造分析表
就是说对于一个产生式,先把其加入 [ A , a ] [A,a] [A,a], a a a是它的首符集的一个元素,然后如果首符集中有空串,就把其也加入 [ A , b ] [A,b] [A,b],b是后继符集中的元素
- 对于文法的每一个 A → α A\to \alpha A→α,做下面两步
- 对于任何 a ∈ F I R S T ( α ) a \in FIRST(\alpha) a∈FIRST(α),把 A → α A\to \alpha A→α加进 M [ A , a ] M[A,a] M[A,a]
- 若 ε ∈ F I R S T ( α ) \varepsilon \in FIRST(\alpha) ε∈FIRST(α),则把 A → α A\to \alpha A→α加进 M [ A , b ] , b ∈ F O L L O W ( A ) M[A,b],b\in FOLLOW(A) M[A,b],b∈FOLLOW(A)
判断是否是LL(1)文法
方法一
LL(1)文法的条件:对于文法的每一个非终结符A的任何两个不同的产生式,有:
- F I R S T ( α ) ∩ F I R S T ( β ) = ϕ FIRST(\alpha)\cap FIRST(\beta) = \phi FIRST(α)∩FIRST(β)=ϕ
- 若 β ⇒ ∗ ε \beta \stackrel{*}{\Rightarrow} \varepsilon β⇒∗ε,则 F I R S T ( α ) ∩ F O L L O W ( A ) = ϕ FIRST(\alpha) \cap FOLLOW(A) = \phi FIRST(α)∩FOLLOW(A)=ϕ
方法二
看生成的分析表是否有多重入口,如果没有多重入口则说明是LL(1)文法
第三题(算符优先文法)


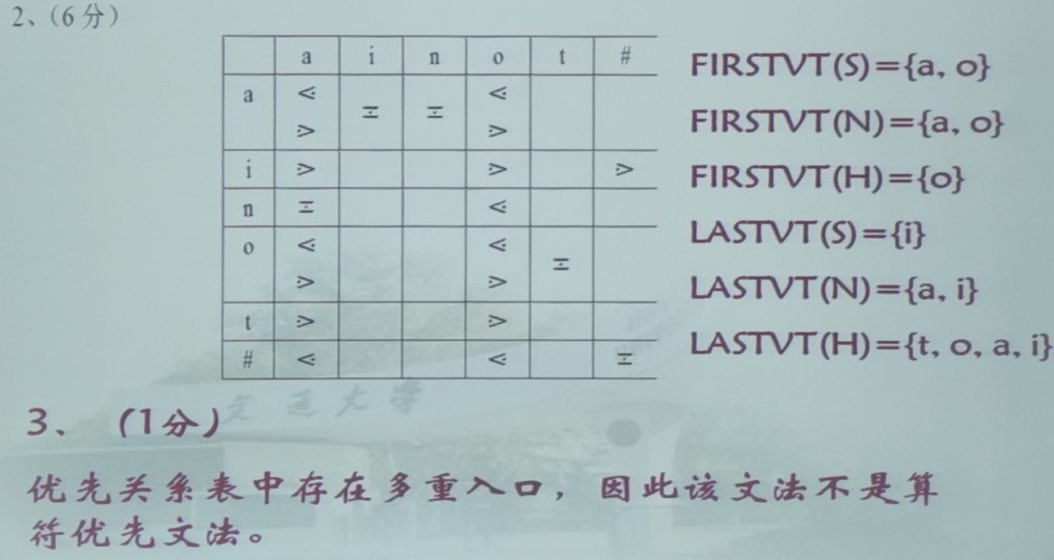

这例的LASTVT(w)错了,没有c
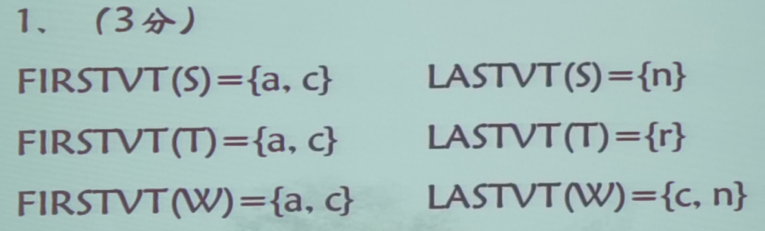
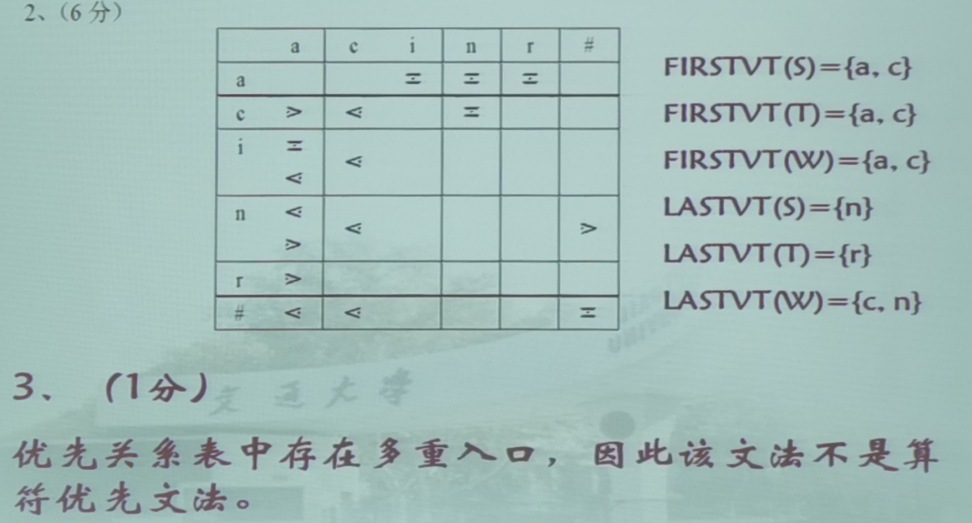
FIRSTVT集合
F I R S T V T ( P ) = { a ∣ P ⇒ + a ⋯ 或 P ⇒ + Q a ⋯ , a ∈ V T 而 Q ∈ V N } FIRSTVT(P)=\{a|P\stackrel{+}{\Rightarrow}a\cdots或P\stackrel{+}{\Rightarrow}Qa\cdots,a\in V_T 而 Q\in V_N\} FIRSTVT(P)={a∣P⇒+a⋯或P⇒+Qa⋯,a∈VT而Q∈VN}$
- $P\to a\cdots 或 或 或P\to Qa\cdots ,则 ,则 ,则a\in FIRSTVT§$
- 若 a ∈ F I R S T V T ( Q ) a\in FIRSTVT(Q) a∈FIRSTVT(Q),且有产生式 P → Q ⋯ P\to Q\cdots P→Q⋯,则 a ∈ F I R S T V T ( P ) a\in FIRSTVT(P) a∈FIRSTVT(P) ,Q的首终结符也是P的首终结符
LASTVT集合
L A S T V T ( P ) = { a ∣ P ⇒ + ⋯ a 或 P ⇒ + ⋯ a Q , a ∈ V T 而 Q ∈ V N } LASTVT(P)=\{a|P\stackrel{+}{\Rightarrow}\cdots a或P\stackrel{+}{\Rightarrow}\cdots aQ,a\in V_T 而 Q\in V_N\} LASTVT(P)={a∣P⇒+⋯a或P⇒+⋯aQ,a∈VT而Q∈VN}
- $P\to \cdots a 或 或 或P\to \cdots aQ ,则 ,则 ,则a\in LASTVT§$
- 若 a ∈ L A S T V T ( Q ) a\in LASTVT(Q) a∈LASTVT(Q),且有产生式 P → ⋯ Q P\to \cdots Q P→⋯Q,则 a ∈ L A S T V T ( P ) a\in LASTVT(P) a∈LASTVT(P)
构造优先关系矩阵
- 对于形如 P → ⋯ a b ⋯ P\to \cdots ab \cdots P→⋯ab⋯和形如 P → ⋯ a Q b ⋯ P\to \cdots aQb \cdots P→⋯aQb⋯,有 a ≖ b a\eqcirc b a≖b
- 对于形如 P → ⋯ a R ⋯ P\to \cdots aR \cdots P→⋯aR⋯,而 b ∈ F I R S T V T ( R ) b\in FIRSTVT(R) b∈FIRSTVT(R),有 a ⋖ b a\lessdot b a⋖b
- 对于形如 P → ⋯ R b ⋯ P\to \cdots Rb \cdots P→⋯Rb⋯,而 a ∈ L A S T V T ( R ) a\in LASTVT(R) a∈LASTVT(R),有 a ⋗ b a\gtrdot b a⋗b
- 对于S和终结符#,有 # ⋖ F I R S T V T ( S ) , L A S T V T ( S ) ⋗ # \# \lessdot FIRSTVT(S),LASTVT(S)\gtrdot \# #⋖FIRSTVT(S),LASTVT(S)⋗#,且对 # S # \#S\# #S#,有 # ≖ # \#\eqcirc \# #≖#
判断是否为算符优先文法
如果优先关系矩阵中无多重入口,则该文法为算符优先文法
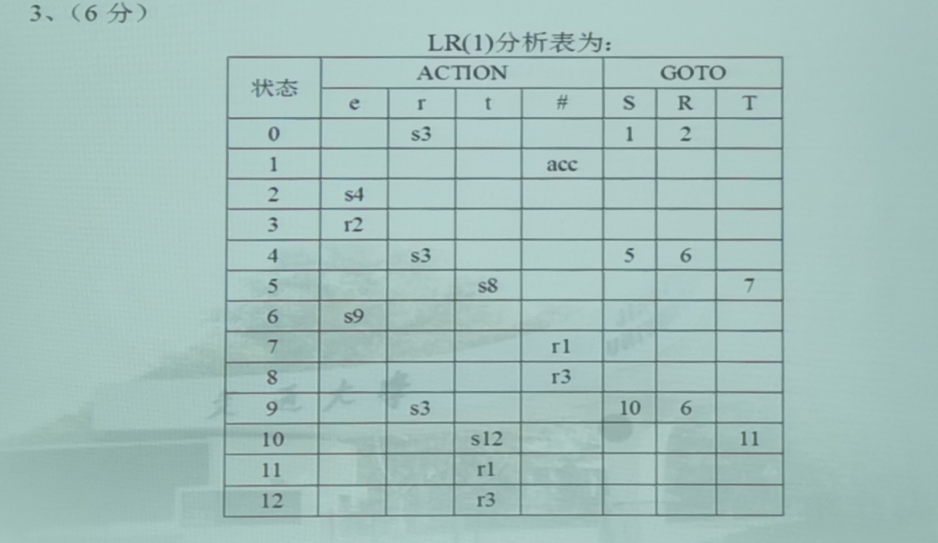
第四题(LR(1)文法)


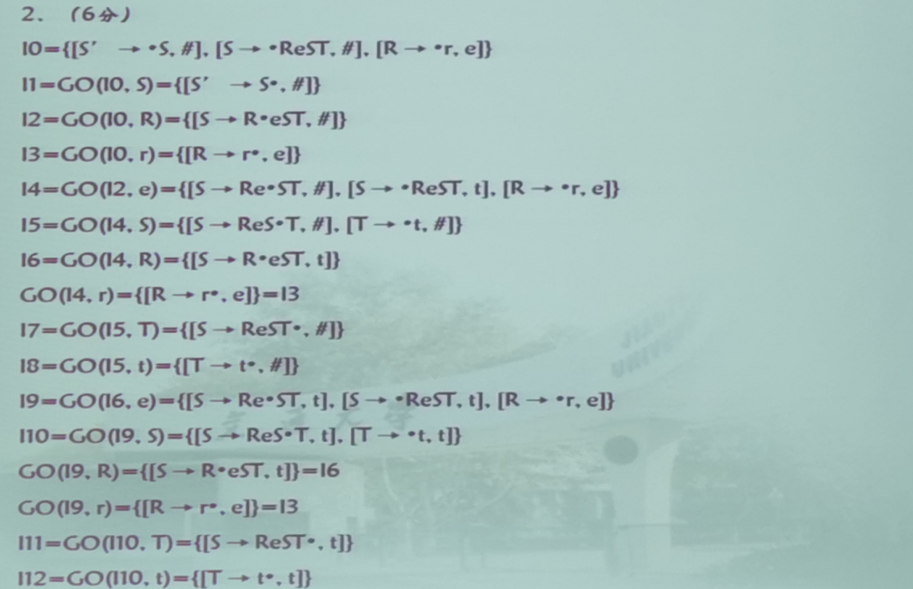


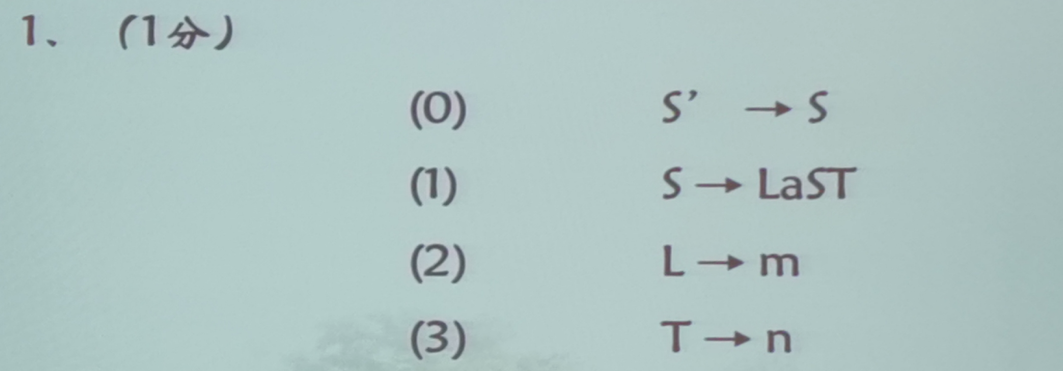

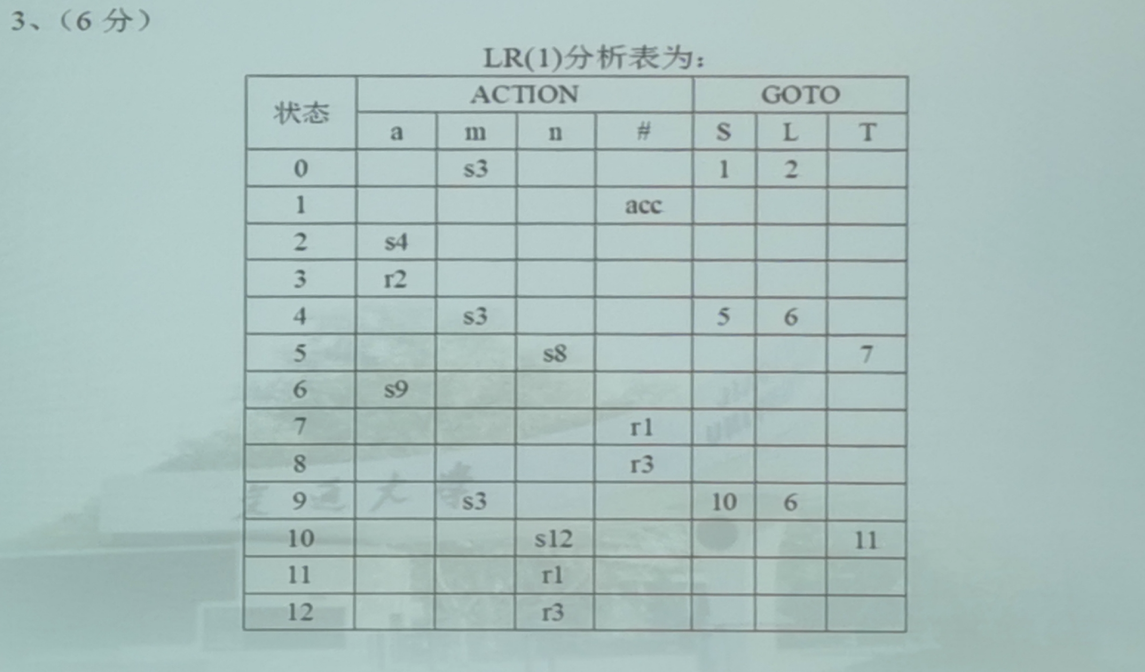

文法拓广
文法拓广的时候直接加入一条额外的产生式: S ′ → S S'\to S S′→S,其余的不变即可,然后 S ′ S' S′为新的开始符号,同时需要对所有的式子按顺序进行编号,这里需要把右部有多个候选式的式子拆开为多个产生式
拓广的原因是为了保证开始符号只有一个产生式
构造项目集规范族
这里四种方法都可能会考到,所以最好还是都看会
LR(0)文法
- 令NFA的初态为 I I I,求其 C L O S U R E ( I ) CLOSURE(I) CLOSURE(I),得到初态项目集。即:求 C L O S U R E ( { S ′ → ⋅ S } ) CLOSURE(\{S'\to \cdot S\}) CLOSURE({S′→⋅S})
- 对所得项目集 I I I和文法 G G G的每个文法符号 X X X(包括 V T 和 V N V_T和V_N VT和VN)计算 G O ( I , X ) = C L O S U R E ( J ) GO(I, X)=CLOSURE(J) GO(I,X)=CLOSURE(J),得到新的项目集,其中: J = { 任何形如 A → α X ⋅ β 的项目 ∣ A → α ⋅ X β 属于 I } J=\{任何形如A\to \alpha X\cdot \beta的项目|A\to \alpha \cdot X \beta属于I\} J={任何形如A→αX⋅β的项目∣A→α⋅Xβ属于I}
- 重复步骤二,直至没有新的项目集出现
SLR文法
与LR(0)一样
LR(1)文法
规范LR就是LR(1),二者是一个意思
重新定义项目,使得每个项目都附带有k个终结符,即每个项目的形式为: [ A → α ⋅ β , a 1 a 2 ⋯ a k ] [A\to \alpha\cdot\beta,a_1a_2\cdots a_k] [A→α⋅β,a1a2⋯ak]
归约项目 [ A → α ⋅ , a 1 a 2 ⋯ a k ] [A\to \alpha\cdot,a_1a_2\cdots a_k] [A→α⋅,a1a2⋯ak]意味着:当它所属的状态呈现在栈顶且后续的k个输入符号位 a 1 a 2 ⋯ a k a_1a_2\cdots a_k a1a2⋯ak时,才可以把栈顶上的 α \alpha α规约为A
假定 I I I是 G ′ G' G′的任一项目集,定义和构造 I I I的闭包 C L O S U R E ( I ) CLOSURE(I) CLOSURE(I)如下:
-
I的任何项目都属于 C L O S U R E ( I ) CLOSURE(I) CLOSURE(I)
-
若项目 [ A → α ⋅ B β , a ] [A\to \alpha\cdot B\beta,a] [A→α⋅Bβ,a]属于 C L O S U R E ( I ) CLOSURE(I) CLOSURE(I), B → ξ B\to \xi B→ξ是一个产生式,那么,对于 F I R S T ( β a ) FIRST(\beta a) FIRST(βa)中的每个终结符 b b b,如果 [ B → ⋅ ξ , b ] [B\to \cdot \xi,b] [B→⋅ξ,b]原来不在 C L O S U R E ( I ) CLOSURE(I) CLOSURE(I)中,则把他加进去
-
重复执行步骤2,直至 C L O S U R E ( I ) CLOSURE(I) CLOSURE(I)不再增大为止
LALR文法
构造项目规范集的方法与LR(1)的方法一样
然后在LR(1)的方法构造的项目规范集上合并同心集
如果除去搜索符之后,这两个集合是相同的,我们称两个LR(1)项目集具有相同的心
合并项目集时不用修改转换函数,即 G O ( I , X ) GO(I,X) GO(I,X);动作 A C T I O N ACTION ACTION应进行修改,使得能够反映各被合并的集合的既定动作
合并同心集不会产生新的移进-归约冲突,但有可能产生新的“归约-归约”冲突
对于同一个文法,LALR分析表和SLR分析表永远具有相同数目的状态,却能处理一些SLR所不能对付的事情
构造分析表
四种方法除了第二条之外其余的都一样,所以需要重点区分不同方法的第二条有什么区别
- 具体做的时候先看
GO(Ii, x) = Ij,如果x是终结符,则在表中 [ i , x ] [i,x] [i,x]填写 s j sj sj,如果是终结符,则在表中 [ i , x ] [i,x] [i,x]填写 j j j即可- 然后看哪一个项目规范族中有类似于 A → B ⋅ A\to B \cdot A→B⋅的形式的项目,如果有的话根据对应的规则在表中填写 r j rj rj即可(四种方法主要是这里不一样)
LR(0)文法
- 若项目 A → α ⋅ a β A\to \alpha \cdot a\beta A→α⋅aβ属于 I k I_k Ik且 G O ( I k , a ) = I j GO(I_k,a)=I_j GO(Ik,a)=Ij, a a a为终结符,则置 A C T I O N [ k , a ] ACTION[k, a] ACTION[k,a]为“把 ( j , a ) 移进栈 (j,a)移进栈 (j,a)移进栈”,简记为“ s j sj sj”
- 若项目 A → α ⋅ A\to \alpha \cdot A→α⋅属于 I k I_k Ik,那么,对任何输入符号 a a a(或者终结符#)置 A C T I O N [ k , a ] ACTION[k,a] ACTION[k,a]为"用产生式 A → α A\to \alpha A→α进行归约",简记为" r j rj rj":其中,假定 A → α A\to \alpha A→α为文法 G ’ G’ G’的第 j j j个产生式
- 若项目 S ′ → S ⋅ S'\to S\cdot S′→S⋅属于 I k I_k Ik,则置 A C T I O N [ k . # ] ACTION[k.\#] ACTION[k.#]为”接受“,简记为" a c c acc acc"
- 若 G O ( I k , A ) = I j , A GO(I_k,A)=I_j,A GO(Ik,A)=Ij,A为非终结符,则置 G O T O [ k , A ] = j GOTO[k,A]=j GOTO[k,A]=j
- 分析表中凡不能使用规则1至4填入信息的空白格均置上“出错标志”
SLR文法
-
若项目 A → α ⋅ a β A\to \alpha\cdot a\beta A→α⋅aβ属于 I k I_k Ik且 G O ( I k , a ) = I , a GO(I_k,a)=I,a GO(Ik,a)=I,a为终结符,则置 A C T I O N k , a ACTION{k,a} ACTIONk,a为“把状态j和顾浩a移进栈”,简记为“ s j sj sj”
-
若项目 A → α ⋅ A\to \alpha \cdot A→α⋅属于 I k I_k Ik,那么,对任何输入符号 a , a ∈ F O L L O W ( A ) a,a\in FOLLOW(A) a,a∈FOLLOW(A),则置 A C T I O N [ k , a ] ACTION[k,a] ACTION[k,a]为“用产生式 A → α A\to \alpha A→α进行规约”,简记为“ r j rj rj”;其中,假定 A → α A\to \alpha A→α为文法 G ′ G' G′的第j个产生式
只在规约时才向前展望,即 ⋅ \cdot ⋅已到产生式末尾,则去判断 F O L L O W ( A ) FOLLOW(A) FOLLOW(A)
-
若项目 S ′ → S ⋅ S'\to S\cdot S′→S⋅属于 I k I_k Ik,则置 A C T I O N [ k , # ] ACTION[k,\#] ACTION[k,#]为“接受”,简记为“acc”
-
若 G O ( I k , A ) = I j GO(I_k,A)=I_j GO(Ik,A)=Ij,A为非终结符,则置 G O T O [ k , A ] = j GOTO[k,A]=j GOTO[k,A]=j
-
分析表中凡不能使用规则1至4填入信息的空白格置上“出错标志”
LR(1)文法
- 若项目 [ A → α ⋅ a β , b ] [A\to \alpha \cdot a\beta,b] [A→α⋅aβ,b]属于 I k I_k Ik且 G O ( I k , a ) = I j GO(I_k,a)=I_j GO(Ik,a)=Ij, a a a为终结符,则置 A C T I O N [ k , a ] ACTION[k,a] ACTION[k,a]为“把 ( j , a ) (j,a) (j,a)移进栈”,简记为“ s j sj sj”
- 若项目 [ A → α ⋅ , a ] [A\to \alpha\cdot,a] [A→α⋅,a]属于 I k I_k Ik,则置 A C T I O N [ k , a ] ACTION[k,a] ACTION[k,a]为“用产生式 A → α A\to \alpha A→α归约”,简记为“ r j rj rj”,其中,假定 A → α A\to \alpha A→α为文法 G ′ G' G′的第 j j j个产生式
- 若项目 [ S ′ → S ⋅ , # ] [S'\to S\cdot ,\#] [S′→S⋅,#]属于 I k I_k Ik,则置 A C T I O N [ k . # ] ACTION[k.\#] ACTION[k.#]为“接受”,简记为“ a c c acc acc”
- 若 G O ( I k , A ) = I j GO(I_k,A)=I_j GO(Ik,A)=Ij,A为非终结符,则置 G O T O [ k , A ] = j GOTO[k,A]=j GOTO[k,A]=j
- 分析表中凡不能使用规则1至4填入信息的空白格均置上“出错标志”
LALR文法
在LR(1)的基础上合并了同心集,其他都一样
- 构造文法G的LR(1)项目集族 C = { I 0 , I 1 , ⋯ , I n } C=\{I_0,I_1,\cdots,I_n\} C={I0,I1,⋯,In}
- 把所有的同心集合并在一起,记 C ′ = { J 0 , J 1 , ⋯ , J m } C'=\{J_0,J_1,\cdots,J_m\} C′={J0,J1,⋯,Jm}为合并后的新族。那个含有项目 [ S ′ → ⋅ S , # ] [S'\to \cdot S,\#] [S′→⋅S,#]的 J k J_k Jk为分析表的初态
- 从
C
′
C'
C′构造
A
C
T
I
O
N
ACTION
ACTION表
- 若项目 [ A → α ⋅ a β , b ] [A\to \alpha \cdot a \beta ,b] [A→α⋅aβ,b]属于 J k J_k Jk且 G O ( J k , a ) = J i GO(J_k,a)=J_i GO(Jk,a)=Ji, a a a为终结符,则置 A C T I O N [ k , a ] ACTION[k,a] ACTION[k,a]为“ s j sj sj”
- 若项目 [ A → α ⋅ , a ] [A\to \alpha \cdot ,a] [A→α⋅,a]属于 J k J_k Jk,则置 A C T I O N [ k , a ] ACTION[k,a] ACTION[k,a]为“用产生式 A → α A\to \alpha A→α归约”,简记为" r j rj rj";其中,假定 A → α A\to \alpha A→α为文法 G ′ G' G′的第 j j j个产生式
- 若项目 [ S ′ → S ⋅ , # ] [S'\to S\cdot ,\#] [S′→S⋅,#]属于 J k J_k Jk,则置 A C T I O N [ k , # ] ACTION[k,\#] ACTION[k,#]为"接受",简记为“ a c c acc acc”
- 构造 G O T O GOTO GOTO表
- 分析表中凡不能用步骤3、4填入信息的空白格均填上“出错标志”
判断是否为LR(1)文法
如果分析表没有多重入口,则说明是一个LR(1)文法
第五题(数组元素引用)


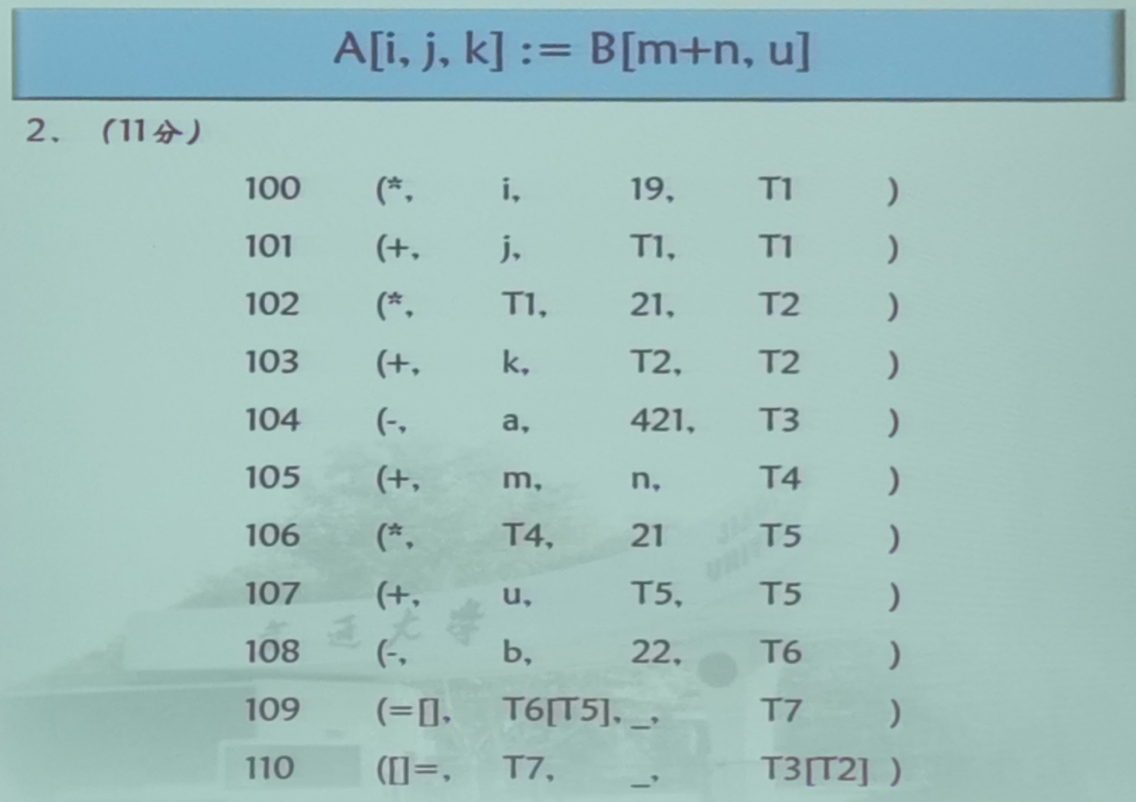

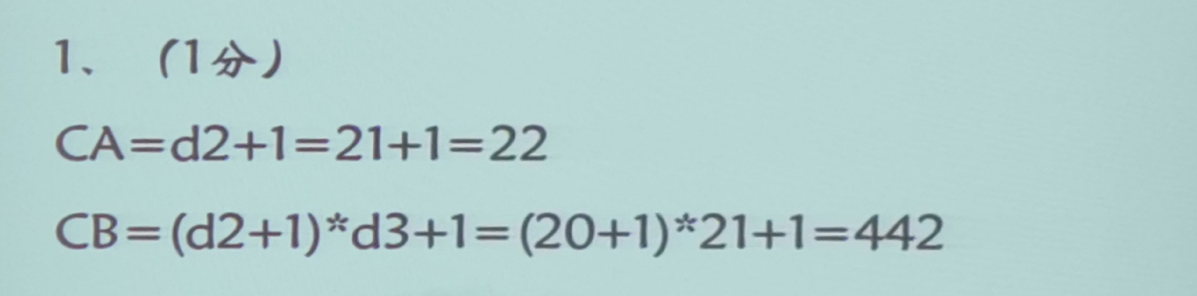

第二题有几分就有几条四元式,顺序和个数都需要正确才给分
计算相对地址子项
计算相对地址子项也就是计算内情向量中的常数C,其计算方法如下:
对于三维数组: C = ( l 1 d 2 + i 2 ) d 3 + i 3 C = (l_1d_2+i_2)d_3+i_3 C=(l1d2+i2)d3+i3
对于二维数组: C = l 1 d 2 + i 2 C = l_1d_2+i_2 C=l1d2+i2
对于一维数组: C = l 1 C=l_1 C=l1
四元式序列
这个如果有时间的话去看一下修改之后的语义动作,如果全都能看懂的话写这个就会很简单
在做的时候先数一下有多少四元式,看能不能找到给定的所有四元式,然后再按顺序写出来
从数组的第二维开始,每扫过一维之后就需要进行一个*,+计算VARPART,也就是会产生两个四元式,当扫到],需要计算数组的CONSTPART,会再产生一个四元式
所以对于一个二维数组来说,类似于 A [ i , k ] A[i,k] A[i,k]来说,其会有三个产生式,如果下标有计算的话需要再把计算的四元式也加上,例如对于 A [ i + j , k ∗ m ] A[i+j,k*m] A[i+j,k∗m]来说有五个四元式
对于一个三维数组来说,例如
A
[
i
,
j
,
k
]
A[i,j,k]
A[i,j,k],会有五个产生式(两个*,+,一个计算CONSPART)
另外在需要使用数组元素值的时候需要变址取值,四元式写法为:(=[],T3[T2],_,T4),需要将取出的结果放到一个临时变量中待后续使用
然后在对数组赋值的时候需要进行变址取值,四元式写法为:([]=,T4,_,T3[T2])
T3[T2]这种写法是偏移取指,即是对T3+T2位置的元素进行操作,其中T3为数组的CONSPART,T2位数组的VARPART
第六题(控制流语句的翻译)

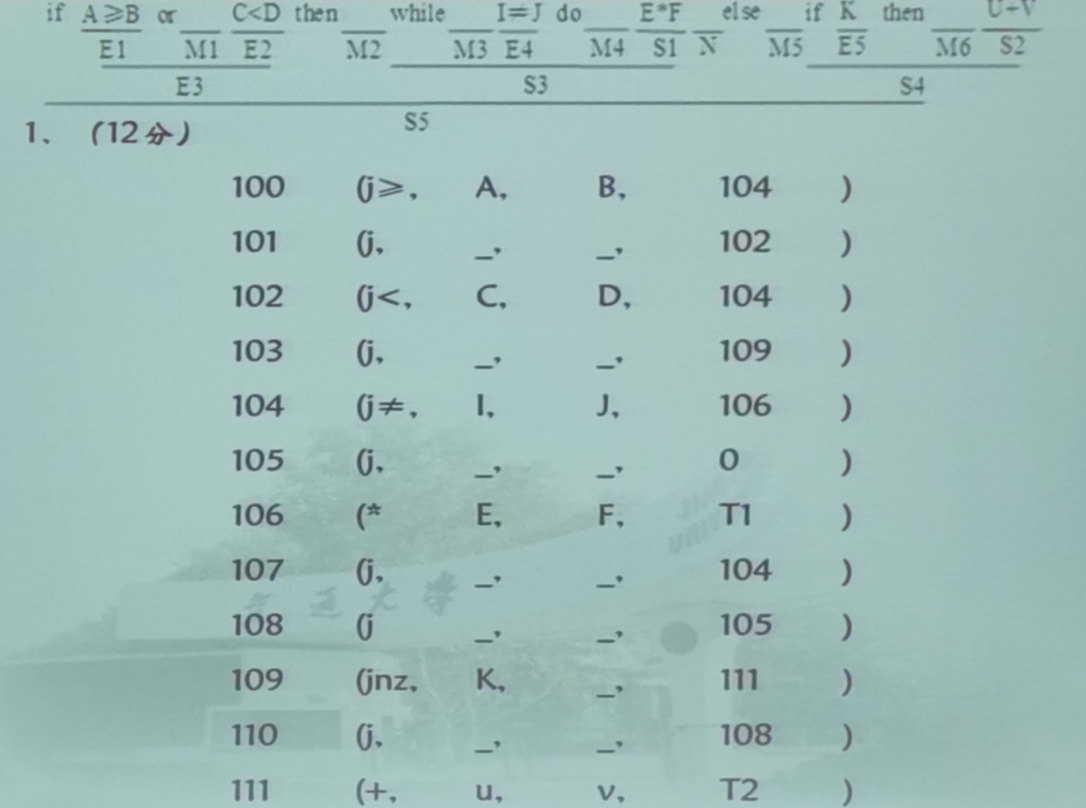


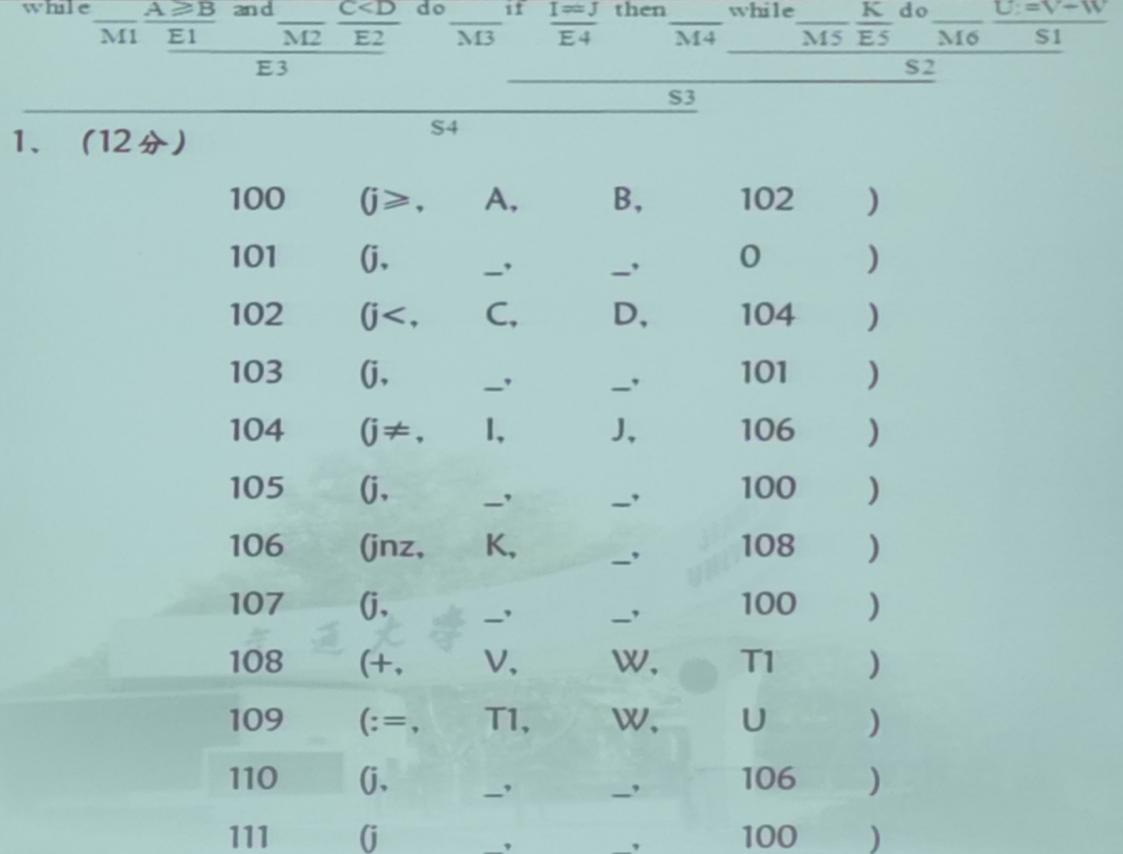

首先还是一样的,前面给出的分表示四元式的个数,第二问的分表示BP和MERGE的总数,在做题时候先看能不能把所有的四元式和BP,MERGE数量找全
这个题的三问没有明显的先后顺序,在做的时候根据老师在题中画出的线进行规约,规约完成之后执行相应的语义动作,然后写出BP和merge
- 一个关系算式(A<B)会产生两个四元式
- while的结尾会产生一个四元式,总共有两个BP
- if then else的then最后会产生一个四元式,总共有两个BP,一个MERGE
- if then有一个BP,一个MERGE,不会产生额外的四元式
- KaTeX parse error: Undefined control sequence: \and at position 1: \̲a̲n̲d̲,\or会有一个BP,一个MERGE
另外,需要把这几种翻译模式都熟记


















 4111
4111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











