







描述性分析是社会调查统计分析的第一个步骤,对调查所得的大量数据资料进行初步的整理和归纳,以找出这些资料的内在规律。
描述性分析的核心:集中趋势、离散趋势
一、集中趋势
集中趋势,又被称为“数据的中心位置”。
它能够代表性的描述总体数据的某一特征。通常用平均数来反映数据的集中趋势。
注:这里的平均数,是一种描述集中趋势的指标。可以分为“数值平均数”和“位置平均数”
①数值平均数,即以往说的平均数,即“均值”;
#均值:.mean()函数,反应的是一组数据,在数量上的中心点
area_mean = df["建筑面积(平方)"].mean()②位置平均数:指的是“中位数”。
#中位数:.median()函数,反应的是一组数据,在位置上的中心点
area_median = df["建筑面积(平方)"].median()1、绘制直方图
直方图:用来展示数值数据数据分布的图表
#plt.hist(列数据,bins=区间数量),bins参数可选
plt.hist(df["房源面积(平)"],bins=100)注:与柱状图的区别:
直方图体现的是数据在各个区间的分布情况,而柱状图体现的是各个数据的变化趋势。
2、正态与偏态
正态:直方图左右对称,数据的均值、中位数都相等。
偏态:直接反映在中位数和均值的大小上。
右偏态:中位数<均值,均值被极端大的数据影响
左偏态:均值<中位数,均值被极端小的数据影响
二、离散趋势
能够代表性的描述每个数据,偏离中心值得特征。
通常用方差、标准差、四分位数来反映数据得离散趋势。方差、标准差越小,说明每一个数据距离均值得距离越近,即数据越集中
#.var():求方差
area_var = df["建筑面积(平方)"].var()
#.std():求标准差
area_std = df["建筑面积(平方)"].std()1、四分位数
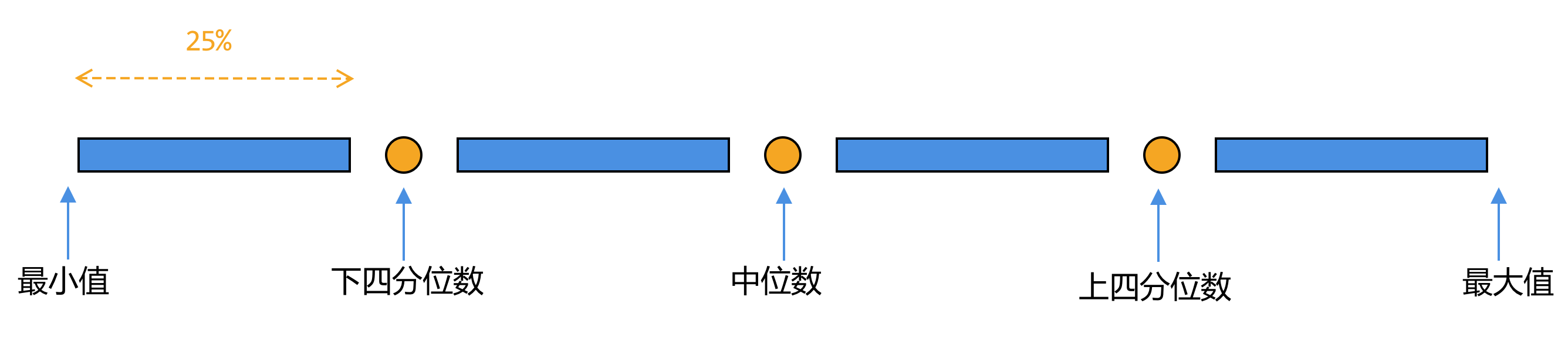
2、描述函数
describe()的输出结果,包含了均值、中位数、标准差、最大值最小值、四分位数等。
df.describe()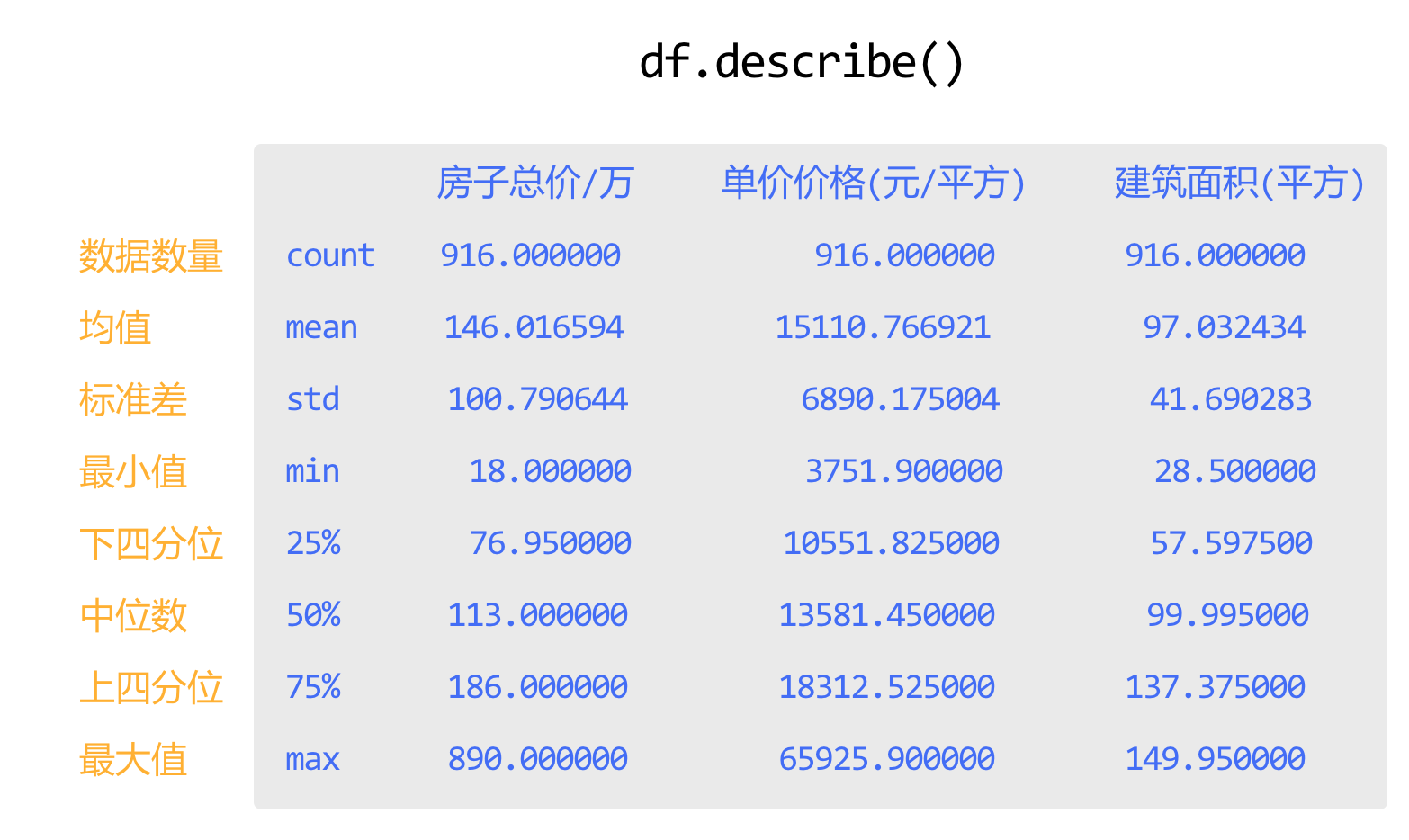
补充:函数类型:①float(浮点型) ②int(整型) ③bool(布尔型) ④datetime64[ns](日期时间) ⑤timedelta[ns](时间差) ⑥category(有限长度的文本值列表) ⑦object(文本)
#.astype():强制转换数据类型函数
#使用astype()函数将"所在区域"列的数据类型强制转化为分类型
df["所在区域"] = df["所在区域"].astype('category')describe()函数:可对category类型的数据进行描述性统计,输出结果分别为:
①列非空元素的数目--count ②类别的数目--unique ③数目最多的类别--top ④数目最多的数目--freq
3、计数排序
value_counts():对Series里面的每个值进行计数且排序。
#对每个区域进行计数并且默认按照从高到低排序。
df["所在区域"].value_counts()














 1858
1858











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









