







一、分组
在处理数据时,经常会把数据集里拥有相同特征的数据划分到一个群体(group)里进行分析。
#.groupby(分组键)
#分组键:按哪一列分组
groupByDate = data.groupby(data["date"])二、聚合
分组后,就可以在各个分组里进行计算,产生新的值,最终,所有分组会联合为一个结果。
聚合操作是groupby()函数后常见的操作,可以通过聚合函数来计算。聚合函数即统计函数,如:count()--计数;sum()--求和等。
#先分组再聚合
groupByDate = data.groupby(data["date"]).sum()三、数据的重采样
重采样:会把数据中的时间点从一个频率转换为另一个频率。简单来说,就是基于时间段的分组操作。
分三类:①向下采样:从高频率到低频率,比如从每天到每月;
②向上采样:从低频率到高频率,比如从每月到每天;
③同频采样:频率不变,比如从每月的第一个星期天到每月的最后一个星期五。
步骤如下:
第一步:将时间格式的列作为行索引index(因为重采样需要根据时间格式的行索引来进行操作。)
第二步:重采样。resample()函数
第三步:使用聚合函数,把结果聚合起来。
#.resample("所需采样的频率规则")
'''常用频率:在pandas中,频率是由基础频率和一个由整数表示的倍数组成。比如,"H"代表每小时,"5M"代表每五个月,"10T"代表每10分钟'''
resampleData = groupByDate.resample("M").sum()常用频率大总结:
D | 每天 | A | 每年年末 |
W | 每周 | H | 每小时 |
M | 每月月末 | T | 每分钟 |
Q | 每个季度末 | S | 每秒 |
注意:resample()函数需要在groupby()函数之后使用
四、访问多层行索引
多层索引是pandas的重要特性,允许我们在一个轴上拥有2个或2个以上的索引层级。如图:在axis=1的方向上拥有l两层索引,也就是两层行索引。

#访问第一层行索引:通过.loc属性,按照第一层index的值,访问该index所对应的一组数据的值
enter = groupByCategory.loc["娱乐"]补充知识点:

五、重塑多层索引
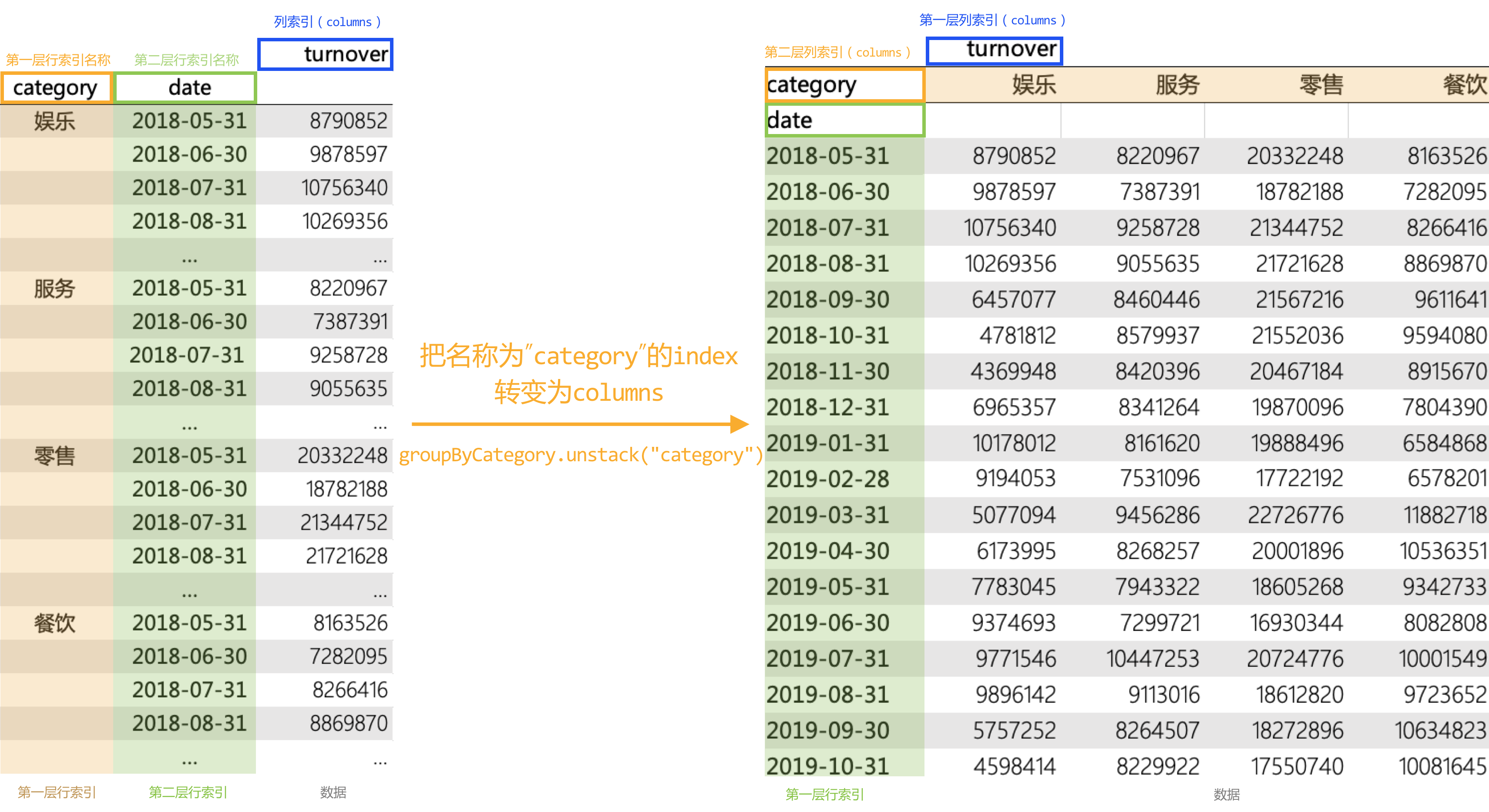
六、apply应用
在pandas中,我们经常会使用apply()函数,将自定义的函数应用到一个DATAFrame上,对其每一行或每一列进行指定的操作,然后根据自定义的函数返回一个新的结果。
#计算占比的函数
def getPercentage(item):
return item/sumTurnover
#使用getPercentage()函数
percentage = groupByCategory.apply(getPercentage)apply应用的整体操作:
①先自定义一个函数
②对一个DataFrame使用apply()函数,并将自定义函数的名称传入apply()函数中。此时,DataFrame的每一列会作为一个Series,传入到自定义的函数中
③对每一个Series执行结果后,apply()函数会将结果整合在一起,并通过自定义函数里的return返回相应的值
七、例题--牛油果指数
百题斩第46题
现代中产阶级的生活已经无法离开牛油果了,牛油果的价格也可以侧面反映一个地区的生活水平。
生活在纽约市的彬彬,获取了2015-2018年间全美国各大城市的牛油果价格数据,存储在 "/Users/binbin/avocado.csv" 路径下:
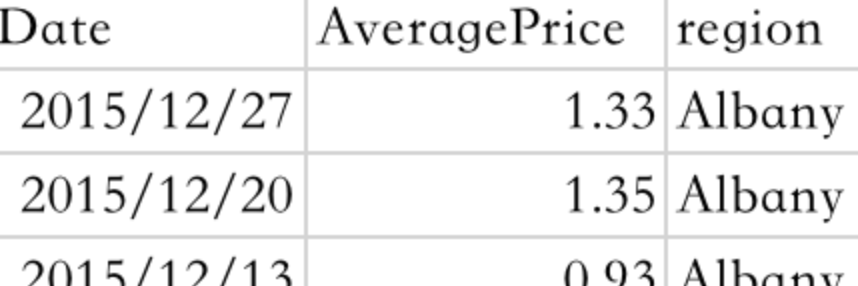
Date表示价格调查的日期,AveragePrice表示当天的平均价格,region表示调查的城市。
彬彬想要获取2015-2018中纽约("NewYork")与芝加哥("Chicago")每月牛油果平均价格,并计算全美国的每月牛油果平均价格,画出3条折线图进行比较。
具体步骤如下:
1. 导入模块、读取文件、并将字体设置为"Arial Unicode MS"
2. 根据城市("region"),将原数据分组、采样聚合,获取纽约和芝加哥两个城市每个月的牛油果平均价格
3. 在这之后,以月份为x轴,绘制展示纽约牛油果每月均价的折线图,并将折线颜色设置为skyblue,标记点的样式设置为"o",图例设置为"纽约价格水平"
4. 同时,以月份为x轴,绘制展示芝加哥牛油果每月均价的折线图,并将折线颜色设置为blue,标记点的样式为"o",图例设置为"芝加哥价格水平"
5. 利用所学知识,计算全美国每个月的牛油果均价,并制作对应的折线图,将折线颜色设置为green,标记点的样式为"o",图例设置为"全美价格水平"
6. 最后,将x轴标题为"时间",y轴标题设置为"价格水平",图例显示在左上角
#1. 导入模块、读取文件、并将字体设置为"Arial Unicode MS"
import pandas as pd
import matplotlib.pyplot as plt
df=pd.read_csv("/Users/binbin/avocado.csv")
plt.rcParams["font.sans-serif"]="Arial Unicode MS"
#2. 根据城市("region"),将原数据分组、采样聚合,获取纽约和芝加哥两个城市每个月的牛油果平均价格
df["Date"] = pd.to_datetime(df["Date"])
df = df.set_index("Date")
ave = df.groupby(df["region"]).resample("M").mean()
NewYork_Ave = ave.loc["NewYork"]
Chicago_Ave = ave.loc["Chicago"]
#3. 在这之后,以月份为x轴,绘制展示纽约牛油果每月均价的折线图,并将折线颜色设置为skyblue,标记点的样式设置为"o",图例设置为"纽约价格水平"
plt.plot(NewYork_Ave.index,NewYork_Ave["AveragePrice"],color="skyblue",marker="o",label="纽约价格水平")
#4. 同时,以月份为x轴,绘制展示芝加哥牛油果每月均价的折线图,并将折线颜色设置为blue,标记点的样式为"o",图例设置为"芝加哥价格水平"
plt.plot(Chicago_Ave.index,Chicago_Ave["AveragePrice"],color="blue",marker="o",label="芝加哥价格水平")
#5. 利用所学知识,计算全美国每个月的牛油果均价,并制作对应的折线图,将折线颜色设置为green,标记点的样式为"o",图例设置为"全美价格水平"
TotalUS_Ave = df.resample("M").mean()
plt.plot(TotalUS_Ave.index,TotalUS_Ave["AveragePrice"],color="green",marker="o",label="全美价格水平")
#6. 最后,将x轴标题为"时间",y轴标题设置为"价格水平",图例显示在左上角
plt.xlabel("时间")
plt.ylabel("价格水平")
plt.legend(loc="upper left")
plt.show()














 1910
1910











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









