







OpenRLHF 是一个基于 Ray、DeepSpeed 和 HF Transformers 构建的高性能 RLHF 框架:
- 简单易用: OpenRLHF 是目前可用的最简单的高性能 RLHF 库之一,无缝兼容 Huggingface 模型和数据集
- 高性能: RLHF 训练中 80% 的时间用于样本生成阶段。得益于使用 Ray, Packing Samples 以及 vLLM 生成加速的能力,OpenRLHF 的性能是极致优化的 DeepSpeedChat with Hybrid Engine 的3~4倍以上
- 分布式 RLHF: OpenRLHF 使用 Ray 将 Actor、Reward、Reference 和 Critic 模型分布到不同的 GPU 上,同时将 Adam 优化器放在 CPU 上。这使得使用多个 A100 80G GPU 和 vLLM 可以全面微调超过 70B+ 的模型 以及在多个 24GB RTX 4090 GPU 上微调 7B 模型
- 同时OpenRLHF也支持全量SFT、QLoRA参数高效微调、KTO算法、PRM训练等
本实验的基础设备是AutoDL租用的服务器
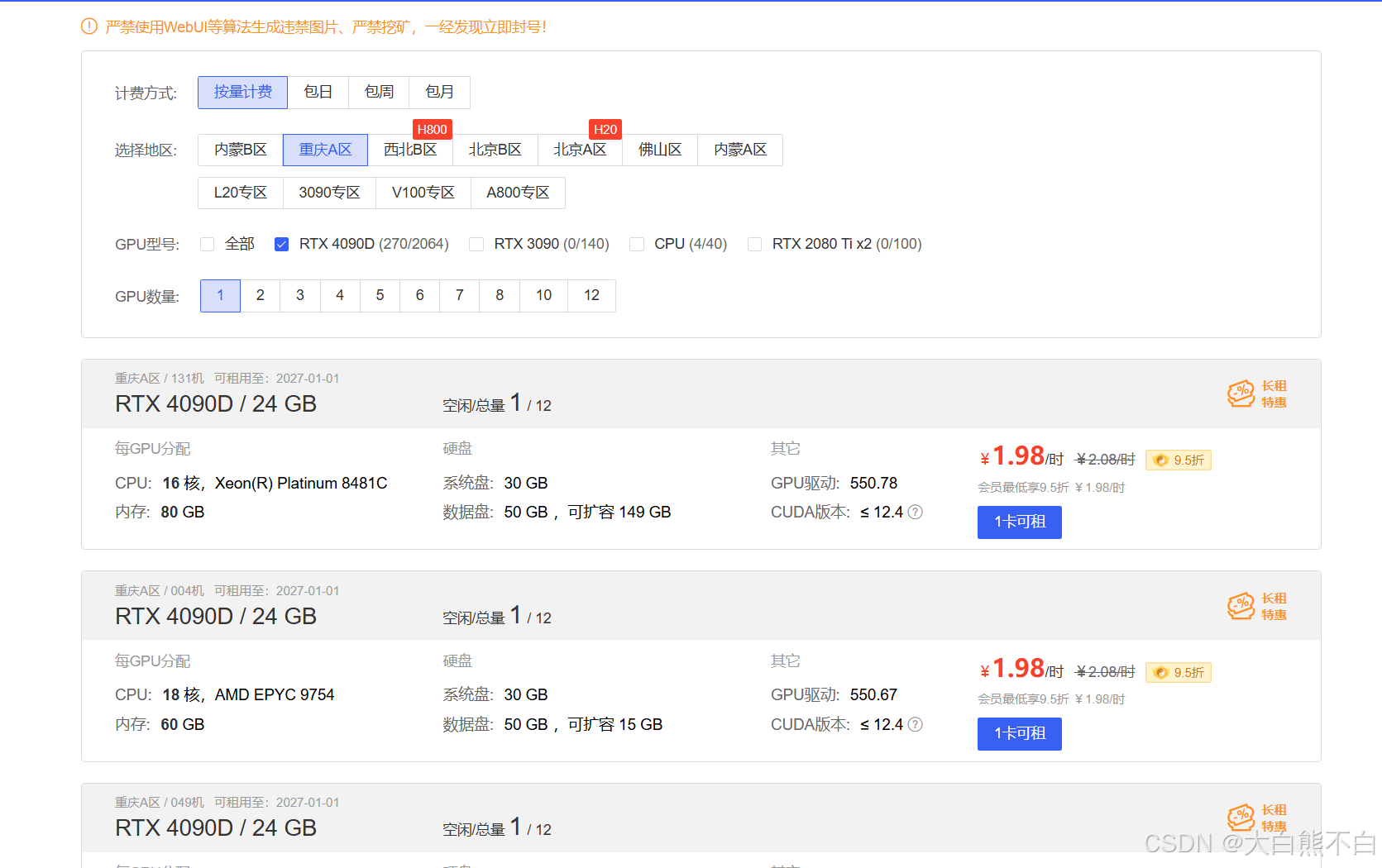
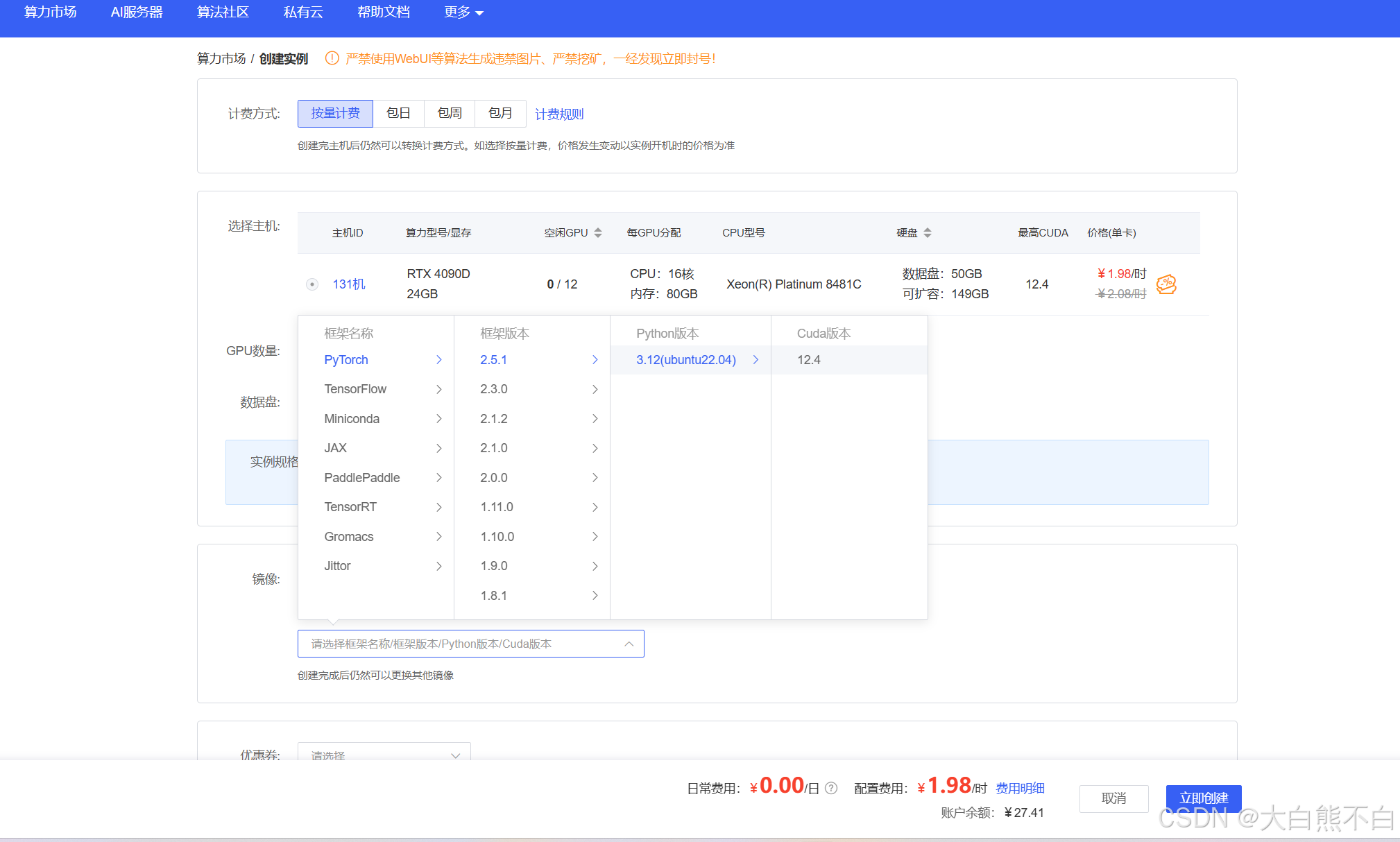
- 这里的建议就是选重庆A区,空闲GPU比较多,即使租用机器GPU不足也可以在同一地区克隆实例--非常快速
- 租用机器的时候先选6卡,点进去后再租一卡,这样你的机器比较不容易GPU不足
- 选择pytorch的环境自带miniconda
AutoDL基础环境miniconda
vim ~/.bashrc
# 将这行添加再最下面
source /root/miniconda3/etc/profile.d/conda.sh
# 按Esc,再输入“:wq”退出
# 然后 重启终端:bash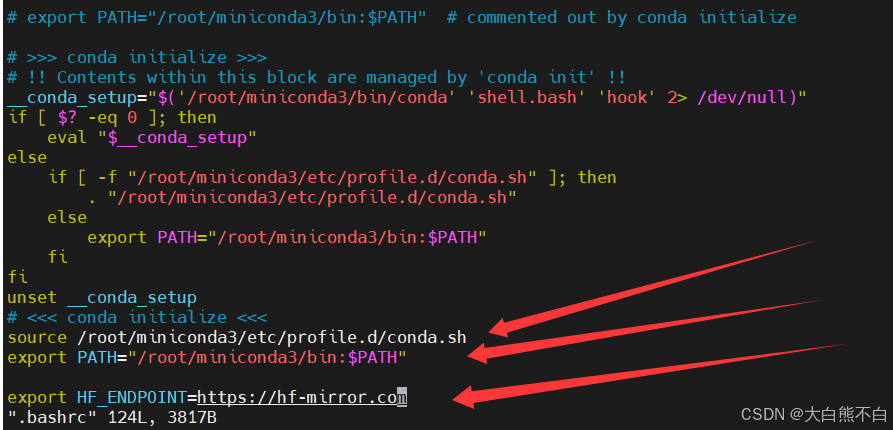
OpenRLHF环境准备
conda create -n openrlhf python=3.11
conda activate openrlhf
pip install openrlhf
pip install torch==2.5.1 torchvision==0.19.0 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu118
pip install openrlhf[vllm]
git clone https://github.com/OpenRLHF/OpenRLHF.git
cd OpenRLHF
pip install -e .
# 如果报ninja相关错
sudo apt update
sudo apt install ninja-build因为是租用的服务器 我就使用miniconda的base环境去下载就ok,ps(系统盘真的不是很多)
下载模型
这里下载的是Qwen2.5-0.5B的模型,这样一张4090显卡足以(省钱)
再Hugging Face上找到模型
这里建议使用huggingface-cli or snapshot_download ,具体就不在这里展开了
huggingface-cli download --resume-download Qwen/Qwen2.5-0.5B --local-dir Qwen
启动训练脚本之前需要确定你的设备能不能直连Huggingface,如果不能的话请在环境变量中加入镜像站
# Linux,最好写到~/.bashrc里面
export HF_ENDPOINT=https://hf-mirror.com
# Windows Power Shell
$env:HF_ENDPOINT = "https://hf-mirror.com"在前面的miniconda哪里已经添加
为了节省训练时间,这里建议你提前运行一个加载模型和数据集的脚本,这样模型和数据集会被下载下来并放到你的 ~/.cache/huddingface里面,后面在此运行训练脚本的时候可以直接读取模型和数据集
from datasets import load_dataset
# 加载数据集的 firefly 文件夹
dataset = load_dataset("QingyiSi/Alpaca-CoT", data_dir="firefly")
# 打印数据集的一些信息
print(dataset)
print(dataset["train"][0])
from transformers import AutoModelForCausalLM, AutoTokenizer
# 加载模型和tokenizer
model_name = "Qwen/Qwen2-1.5B"
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
# 打印模型的一些信息
print(model)STF训练
这里选择了Qwen2-0.5B作为pretrain model,Alpaca-CoT@firefly作为数据集进行SFT训练,下面详细解释一下训练脚本中的各个参数,脚本位置在OpenRLHF/examples/scripts/train_sft_llama.sh
复制一份为train_sft_qwen.sh来编辑
set -x
read -r -d '' training_commands <<EOF
openrlhf.cli.train_sft \ #SFT训练的py文件
--max_len 2048 \ #最长序列长度
--dataset QingyiSi/Alpaca-CoT@firefly \ #数据集name或者path(本地)
--input_key instruction \ #数据集的输入字段
--output_key output \ #数据集输出字段
--train_batch_size 256 \
--micro_train_batch_size 2 \
--max_samples 500000 \ #最大训练样本数
--pretrain /root/Qwen/Qwen2-0.5B \ #pretrain模型name或者path
--save_path ./checkpoint/qwen2-0.5b-firefly-sft \
--save_steps 1000 \ #多少步保存一个checkpoint,-1表示不保存
--logging_steps 1 \
--eval_steps -1 \ #多少步evaluate一下,-1表示最后再evaluate一次
--zero_stage 2 \ #deepspeed Zero阶段,1,2,3,推荐2,优化器状态和梯度都分到每张卡上
--max_epochs 1 \ #训练epoch数量
--bf16 \ #是否用BF16精度训练,默认启用
--flash_attn \ #是否启用flash attention,默认启用
--learning_rate 5e-6 \
--load_checkpoint \ #是否load中间checkpoint
--gradient_checkpointing \ #是否启用梯度检查点技术
--use_wandb=[WANDB_TOKENS] \ #wandb的user token
--wandb_project OpenRLHF \
--wandb_run_name qwen2.5-0.5b-firefly-sft
EOF
# --wandb [WANDB_TOKENS]
# --packing_samples
# 判断命令第一个是不是slurm,如果不是启用deepspeed命令
if [[ ${1} != "slurm" ]]; then
deepspeed --module $training_commands
fi特别的
--use_wandb=[WANDB_TOKENS] \ # 要修改为 wandb的user token
--wandb_project OpenRLHF \
--wandb_run_name qwen2.5-0.5b-firefly-sft我们要去wandb注册一个账号,方便我们来记录和观察训练
训练
nohup bash examples/scripts/train_sft_qwen.sh > output.log 2>&1 &
-
使用
nohup运行脚本train_sft_qwen.sh,即使终端关闭,脚本也会继续执行。 -
将脚本的标准输出和标准错误都重定向到
output.log文件中。 -
将命令放到后台运行,终端可以继续执行其他任务。
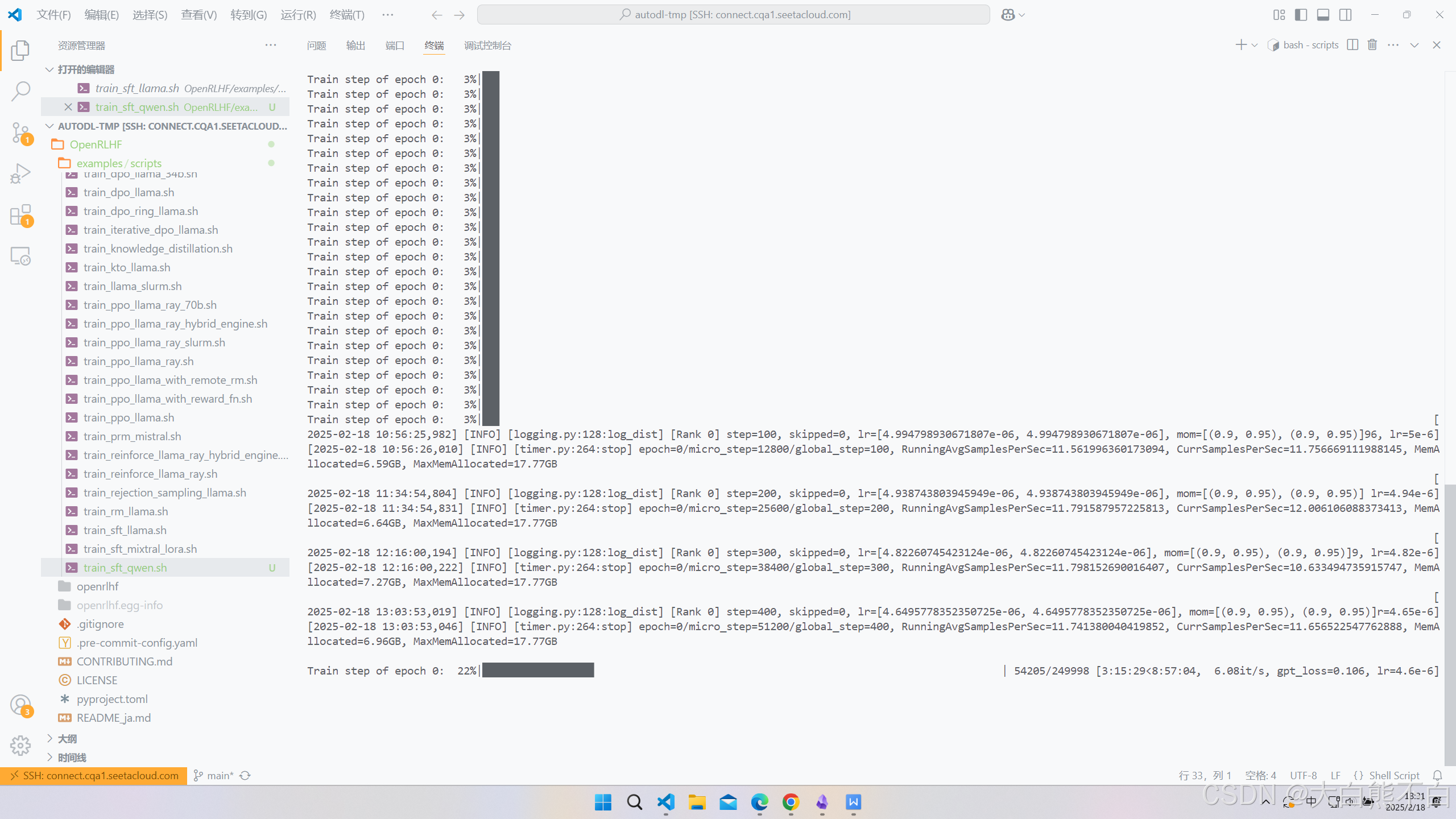
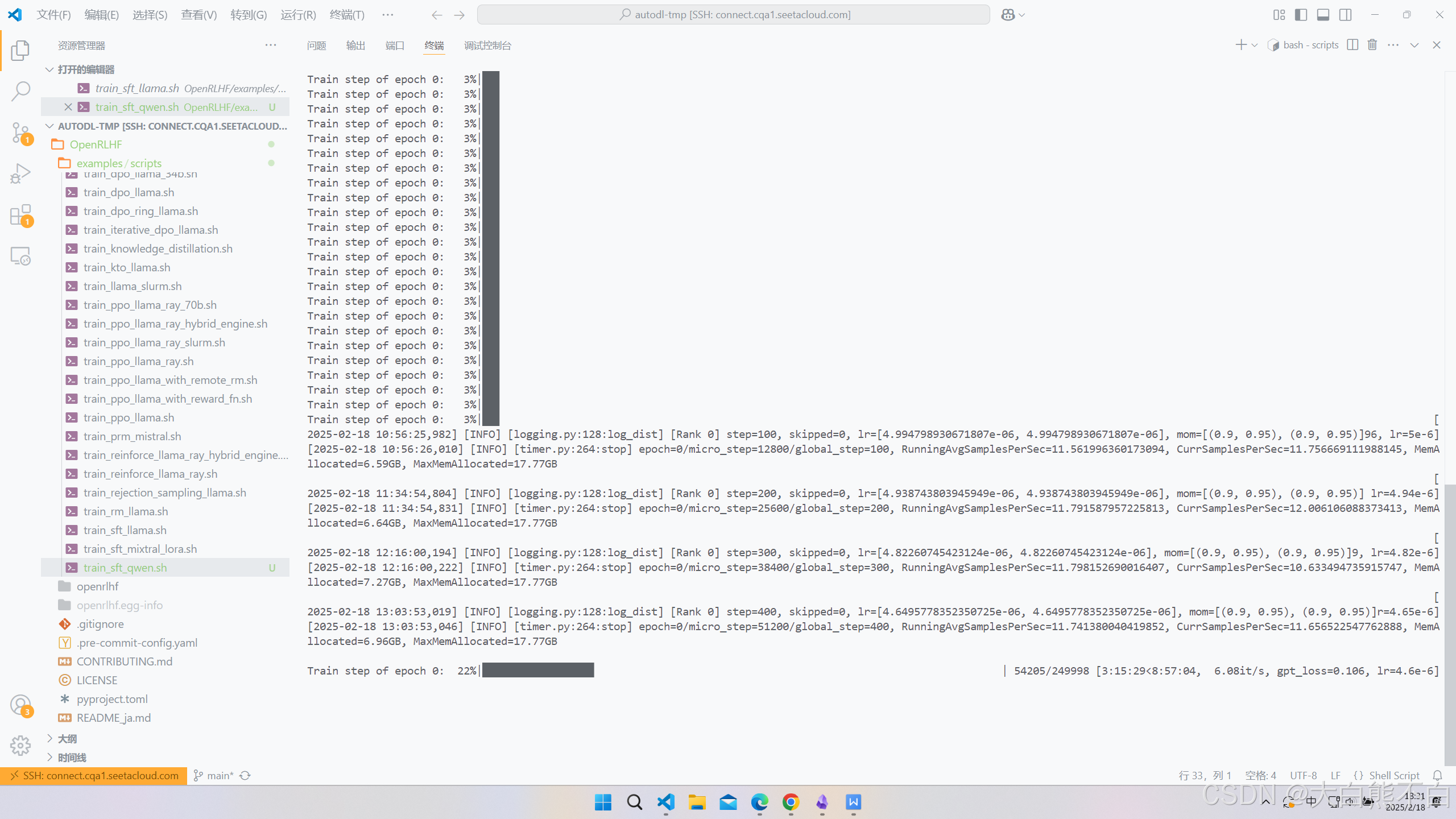
我们可以在wandb里观察实验了
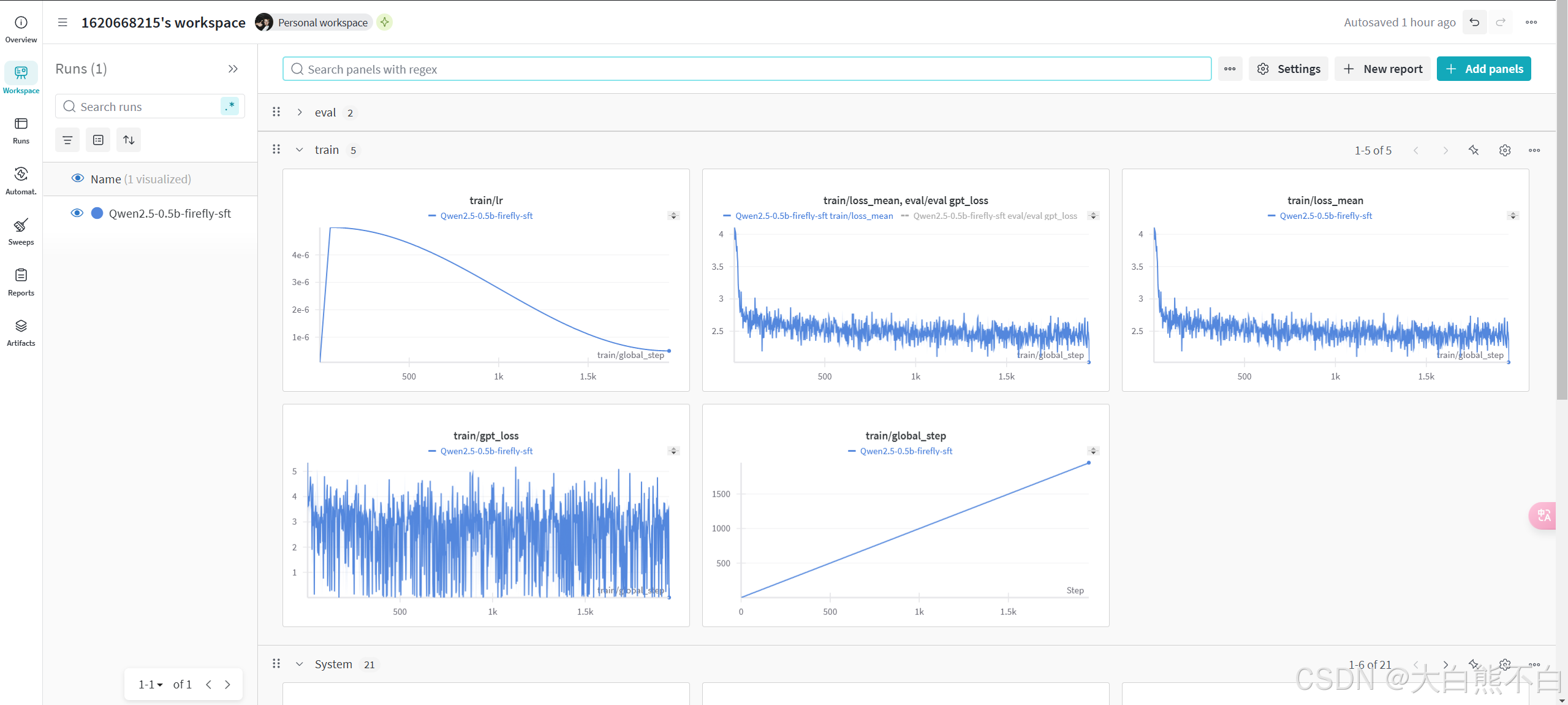
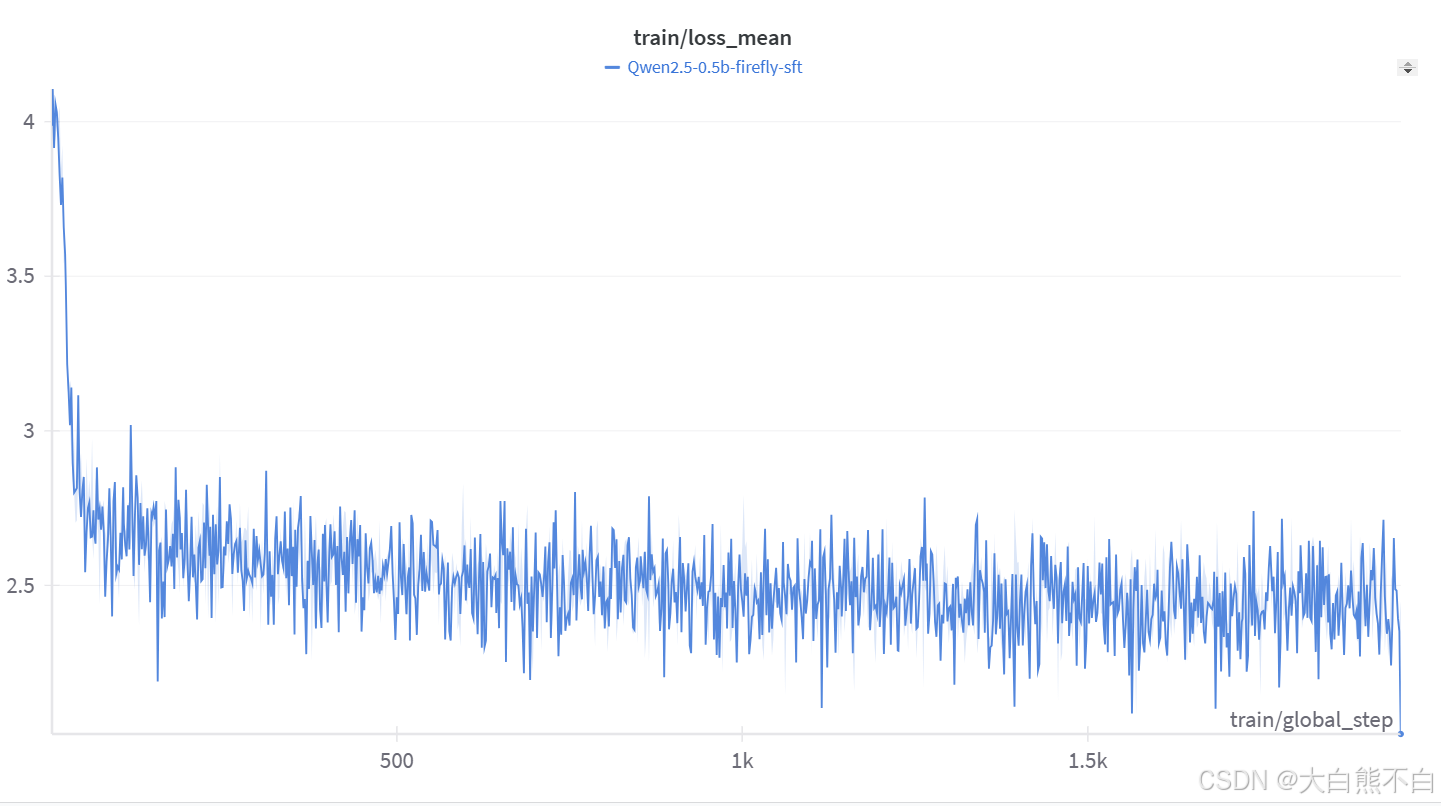
Qwen2.5-0.5B,4090训练一个epoch,500000samples,256batchsize,12小时,loss_mean曲线,最后收敛在2.5左右。
训练期间的显存占用等
SFT训练代码路径:OpenRLHF/openrlhf/cli/train_sft.py,主要是train(args)函数
# train
self.model.train()
for prompt_id_lens, inputs, attention_masks, infos in self.train_dataloader:
if self.packing_samples:
inputs = inputs.to(torch.cuda.current_device())
attention_mask = attention_masks.to(torch.cuda.current_device())
else:
inputs = inputs.to(torch.cuda.current_device()).squeeze(1)
attention_mask = attention_masks.to(torch.cuda.current_device()).squeeze(1)
if self.strategy.ring_attn_group is None:
output = self.model(inputs, attention_mask=attention_mask, return_output=True)
else:
output = self.model(
inputs,
attention_mask=attention_mask,
return_output=True,
ring_attn_group=self.strategy.ring_attn_group,
packed_seq_lens=infos["input_length"],
)
# loss function
labels = torch.where(
attention_mask.bool(),
inputs,
self.loss_fn.IGNORE_INDEX,
)
# mixtral
if self.aux_loss:
aux_loss = output.aux_loss
else:
aux_loss = 0
if not self.pretrain_mode:
if self.packing_samples:
# As response_ranges need to constrain the dataset organization strictly, we handle multiturn feature separately.
if infos["response_ranges"]:
dump_labels = torch.full(labels.size(), self.loss_fn.IGNORE_INDEX).to(labels.device)
for response_ranges in infos["response_ranges"]:
for response_range in response_ranges:
dump_labels[0][response_range[0]: response_range[1]] = labels[0][response_range[0]: response_range[1]]
labels = dump_labels
else:
index = 0
for input_length, source_len in zip(infos["input_length"], prompt_id_lens):
labels[0][index : index + source_len] = self.loss_fn.IGNORE_INDEX
index += input_length
else:
for label, source_len in zip(labels, prompt_id_lens):
label[:source_len] = self.loss_fn.IGNORE_INDEX
gpt_loss = self.loss_fn(output.logits, labels)
loss = gpt_loss + aux_loss * self.args.aux_loss_coef
self.strategy.backward(loss, self.model, self.optimizer)
self.strategy.optimizer_step(self.optimizer, self.model, self.scheduler)
loss_sum += gpt_loss.item()
logs_dict = {
"gpt_loss": gpt_loss.item(),
"lr": self.scheduler.get_last_lr()[0],
}
if self.aux_loss:
logs_dict["aux_loss"] = aux_loss.item()
# step bar
logs_dict = self.strategy.all_reduce(logs_dict)
step_bar.set_postfix(logs_dict)
step_bar.update()
# logs/checkpoints/evaluation
if step % self.strategy.accumulated_gradient == 0:
logs_dict["loss_mean"] = loss_sum / self.strategy.accumulated_gradient
loss_sum = 0
global_step = step // self.strategy.accumulated_gradient
client_states = {"consumed_samples": global_step * args.train_batch_size}
self.save_logs_and_checkpoints(args, global_step, step_bar, logs_dict, client_states)
step += 1
epoch_bar.update()
if self._wandb is not None and self.strategy.is_rank_0():
self._wandb.finish()
if self._tensorboard is not None and self.strategy.is_rank_0():
self._tensorboard.close()


















 4174
4174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









