







逻辑回归应用之Kaggle泰坦尼克之灾
背景
训练和测试数据是一些乘客的个人信息以及存活状况,要尝试根据它生成合适的模型并预测其他人的存活状况。
1. 数据总览
train.csv和test.csv分别为训练集和测试集,ground_truth.csv为对应答案
得到这些后,对这些数据读入和简单分析一下
df = pd.read_csv("train.csv")
print(df.head())
df.info()
print(df.describe())
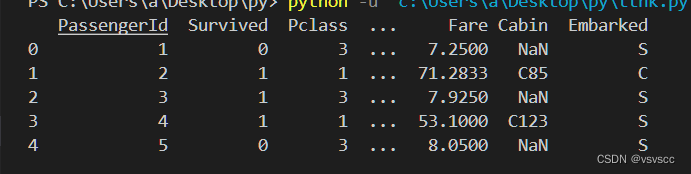
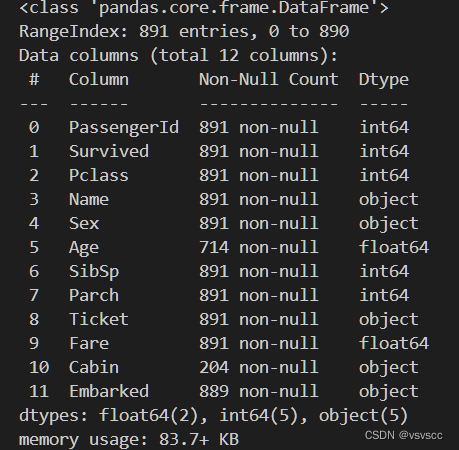
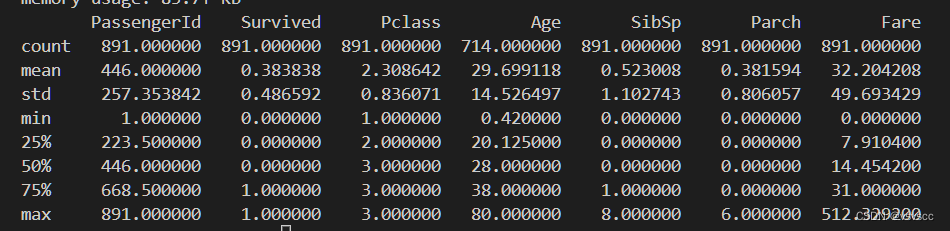
简单分析可以得出Age、Cabin、Embarked、Fare几个特征存在缺失值,大概0.383838的人最后获救了,2/3等舱的人数比1等舱要多,平均乘客年龄大概是29.7岁
数据初步分析
先看下每个属性与Survived的关系
```python
fig = plt.figure()
fig.set(alpha=0.2) # 设定图标透明度
plt.subplot2grid((2,3),(0,1))#把几个小图放在一个大图里面
df.Pclass.value_counts().plot(kind="bar") # 柱状图
plt.ylabel(u"人数")
plt.title(u"乘客等级分布")
plt.subplot2grid((2,3),(0,0))
df.Survived.value_counts().plot(kind='bar')
plt.title(u'获救情况(1为获救)')
plt.ylabel(u'人数')
plt.subplot2grid((2,3),(0,2))
plt.scatter(df.Survived, df.Age)
plt.ylabel(u"年龄")
plt.grid(b=True, which='major', axis='y') # 绘制网格线
plt.title(u"按年龄看获救分布 (1为获救)")
plt.subplot2grid((2,3),(1,0), colspan=2)
df.Age[ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 385
385











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









