







一、摘要
基于LSTM的歌词生成器。首先,从预训练的GloVe词向量中加载词汇表和词向量,然后使用这些词向量构建一个嵌入矩阵。接着定义了一个LSTM模型,该模型包含一个嵌入层、一个LSTM层和一个全连接层。在训练过程中,模型使用交叉熵损失函数和Adam优化器进行参数更新。最后,通过输入一段歌词的开头,模型可以生成指定长度的歌词。
二、实验
2.1、数据准备
此数据集近1000首歌,分成5份json文件,每个文件对应于一位歌手。json数据里面包括了Name歌名、Singer歌手和Lyric歌词。

2.2 数据预处理
定义了一个名为get_batches的函数,用于将输入数组arr划分为大小为batch_size的小批次,每个小批次包含seq_length个连续的元素。函数的输出是一个生成器,每次迭代返回一个小批次的数据。
具体来说,函数首先计算总批次大小batch_size_total,然后根据该值确定可以划分的批次数量n_batches。接着,将输入数组arr截取到合适的长度,并将其重塑为形状为(batch_size, -1)的二维数组。
接下来,函数使用一个循环遍历重塑后的数组,每次取出长度为seq_length的连续元素作为输入x,并创建一个与x形状相同的零矩阵y作为目标输出。在循环中,尝试将x的第二个元素到倒数第二个元素赋值给y的前seq_length-1个元素,将arr中的下一个元素赋值给y的最后一个元素。如果发生索引越界错误(即已经到达数组末尾),则将x的第二个元素到倒数第二个元素赋值给y的前seq_length-1个元素,将arr的第一个元素赋值给y的最后一个元素。
最后,函数通过yield关键字返回当前批次的输入x和目标输出y。

2.3 模型介绍
该模型包括一个嵌入层(Embedding),一个LSTM层和一个全连接层(Linear)
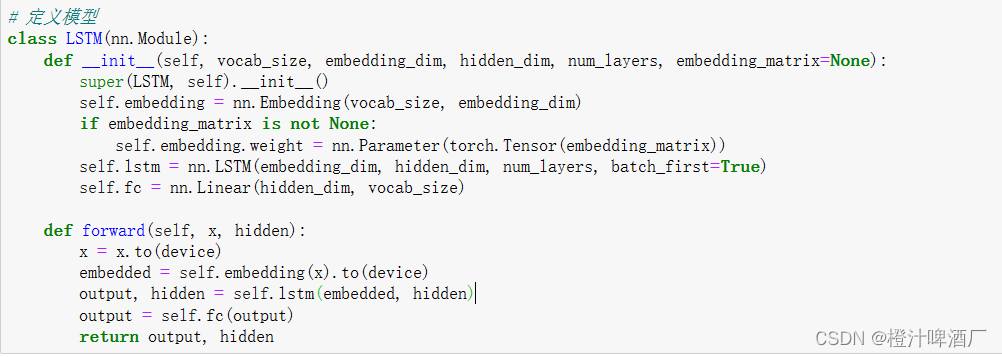
2.4 训练
这里定义的损失函数为交叉熵损失,优化器为Adam。通过循环遍历每个批次的数据,进行前向传播、计算损失、反向传播和参数更新。最后,输出每个epoch的损失值。

训练了80次,可以从图像看出已经趋近收敛,停止训练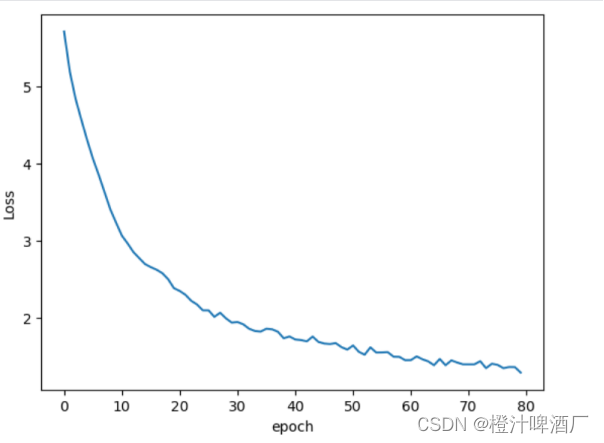
2.5效果
缺点:未能进行分段。


















 1765
1765

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









