







图的深度优先搜索
描述:
图的深度优先搜索类似于树的先根遍历,是树的先根遍历的推广。即从某个结点开始,先访问该结点,然后深度访问该结点的第一棵子树,依次为第二顶子树。如此进行下去,直到所有的结点都访问为止。在该题中,假定所有的结点以“A”至“Z”中的若干字符表示,且要求结点的访问顺序根据“A”至“Z”的字典顺序进行访问。例如有如下图:
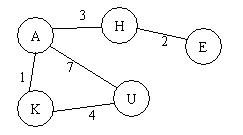
如果要求从H开始进行深度优先搜索,则搜索结果为:H->A->K->U->E.
输入:
输入只包含一个测试用例,第一行为一个自然数n,表示顶点的个数,第二行为n个大写字母构成的字符串,表示顶点,接下来是为一个n*n大小的矩阵,表示图的邻接关系。数字为0表示不邻接,否则为相应的边的长度。
最后一行为一个字符,表示要求进行深度优先搜索的起始顶点。
输出:
用一行输出深度优先搜索结果,起始点为给定的顶点,各顶点之间用一个空格隔开(注意后面的提示)。
样例输入:
5
HUEAK
0 0 2 3 0
0 0 0 7 4
2 0 0 0 0
3 7 0 0 1
0 4 0 1 0
H
样例输出:
H A K U E
参考:
import java.util.*;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int n = sc.nextInt();
String name = sc.next();
int[][] mp = new int[n][n];
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
mp[i][j] = sc.nextInt();
}
}
// 获得起始地点
int sta = name.indexOf(sc.next());
// 用栈模拟来进行深度优先搜索
boolean[] vis = new boolean[n];
Stack<Integer> st = new Stack<>();
// 将起始地点推入栈
st.add(sta);
while (!st.isEmpty()) {
// 取出栈顶,判断该元素是否已经输出过了
int fr = st.pop();
// 如果该元素已经输出过了,就换下一个元素
while (!st.isEmpty() && vis[fr]) {
fr = st.pop();
}
// 如果所有元素都已经输出完了,就可以停止循环了
if (vis[fr]) {
break;
}
// 输出当前元素
System.out.print(name.charAt(fr) + " ");
// 将输出的元素标记
vis[fr] = true;
// 这里将与fr相连接的顶点都放入 al,注意不需要标记
ArrayList<Character> al = new ArrayList<>();
for (int i = n - 1; i >= 0; i--) {
if (mp[fr][i] != 0 && !vis[i]) {
al.add(name.charAt(i));
}
}
// 将所有顶点排序
Collections.sort(al);
// 将所有顶点按从大到小的顺序加入栈
for (int i = al.size() - 1; i >= 0; i--) {
st.push(name.indexOf(al.get(i)));
}
}
}
}
















 316
316











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











