






注意:以下答案含有部分错误,还在纠正中,所有的解法仅供参考!!!
1.已知 DFA M 如图2-6所示。给出它们在处理字符串 1011001 的过程中经过的状态序列。判断该符号串是否能被此 DFA M 所识别。
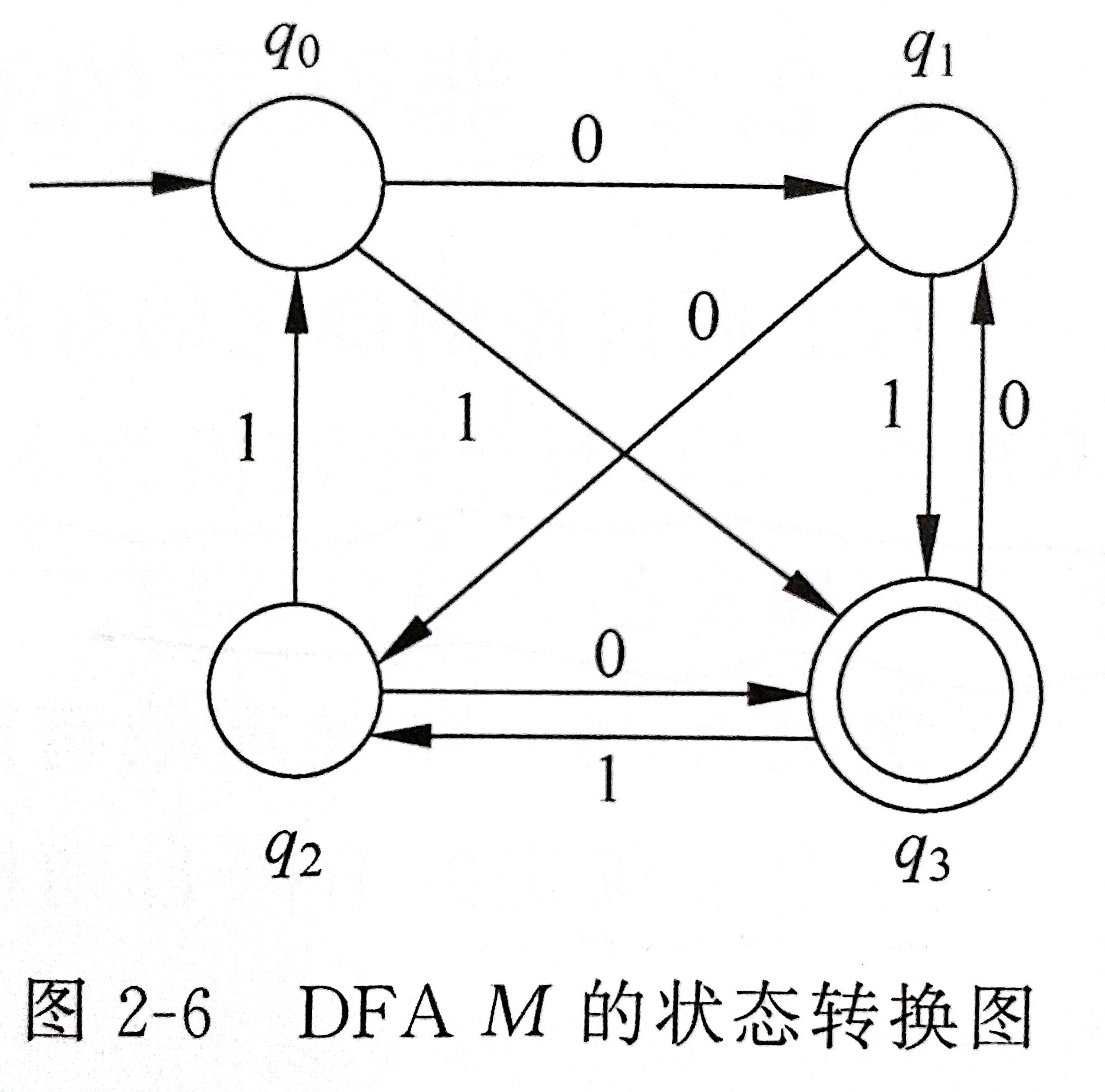
M在处理 1011001 的过程中经过的状态序列为 q 0 q 3 q 1 q 3 q 2 q 3 q 1 q 3 q_0 q_3 q_1 q_3 q_2 q_3 q_1 q_3 q0q3q1q3q2q3q1q3 ;满足 q 0 q_0 q0 为初始状态, q 3 q_3 q3 属于终止状态集合,1011001 是从初态到终态的一条路径,所以符号串 1011001 可以被该 DFA M 所识别。
2.设 Σ = 0 , 1 \Sigma = {0, 1} Σ=0,1 ,请给出 Σ \Sigma Σ 中的下列语言的文法
(1)所有以 0 开头的串。
解1(推荐):
S → 0 ∣ S 0 ∣ S 1 S \rightarrow 0 | S0 | S1 S→0∣S0∣S1
S 先生成任意的 0,1 串,最后在这个 0,1 串之前生成一个 0,从而保证生成的串是以 0 开头的串。
解2:
S → 0 A ∣ 0 S \rightarrow 0A | 0 S→0A∣0
A → 0 ∣ 1 ∣ 0 A ∣ 1 A A \rightarrow 0 | 1 | 0A | 1A A→0∣1∣0A∣1A
S 先生成 0A,然后“将任务交给变量 A",由 A 生成 0 后面的任意 0,1 符号串。
(2)所有以 0 开头,以 1 结尾的串。
解1(推荐):
S → 0 A 1 S \rightarrow 0A1 S→0A1
A → ϵ ∣ 0 A ∣ 1 A A \rightarrow \epsilon | 0A | 1A A→ϵ∣0A∣1A
先由 S 生成以 0 开头以 1 结尾的句型,然后由 0,1 之间的 A 生成中间部分。由于 01 本身也是满足要求的串,所以 A 可以产生 ϵ \epsilon ϵ。
解 2:
S → 0 A S \rightarrow 0A S→0A
A → 1 ∣ 0 A ∣ 1 A A \rightarrow 1 | 0A | 1A A→1∣0A∣1A
用产生式 S → 0 A S \rightarrow 0A S→0A 保证产生的字符串是以 0 开头的,产生式 A → 0 A ∣ 1 A A \rightarrow 0A | 1A A→0A∣1A 被用来生成开头字符 0 之后,结尾字符 1 之前的所有 0,1 子串,产生式 A → 1 A \rightarrow 1 A→1 是使除了 S 之外的所有其他句型中的唯一变量 A 变成终极符号的唯一产生式,该产生式保证了在句型的尾部生成一个 1 → 句子是以1结尾的。
(3)所有以 11 开头,以 11 结尾的串。
解:本题的解法与上一题类似,只不过是用 11 分别代替了字符串的首字符 0 和字符串的尾字符 1,其他位置的字符不变。另外,它还有两个特殊的句子 11 和 111,这是由开头的 11 与结尾的 11 一样所决定的,这里将它们作为特例处理。因此,相应的文法如下。对比本题的解法与上题的解法,读者可以进一步理解文法是经过对语言的结构的描述来定义语言的。所以,要构造一个给定语言的文法,最重要的是找出该语言的结构特征。
解1(推荐):
S -> 11A
A -> 0A | 1A | 11
解2:
S → 11 A 11 ∣ 111 ∣ 11 S \rightarrow 11A11 | 111 | 11 S→11A11∣111∣11
A → ϵ ∣ 0 A ∣ 1 A A \rightarrow \epsilon | 0A | 1A A→ϵ∣0A∣1A
解3:
S → 11 A ∣ 111 ∣ 11 S \rightarrow 11A | 111 | 11 S→11A∣111∣11
A → 11 ∣ 0 A ∣ 1 A A \rightarrow 11 | 0A | 1A A→11∣0A∣1A
(4)所有 0 和 1 构成的但不含 00 的串。
文法规则:
S -> 1S | 0A | ε
A -> 1S | ε
(5)所有 0 和 1 构成的含有形如 10110 的子串。
文法规则:
S -> A10110A
A -> 0A | 1A | ε
(6)含偶数个 0 的二进制数组成的串。
文法规则:
S -> ε | S00S | S1S | 0S0
解释:
S是起始符号。
第一条规则表示空串ε。
第二条规则表示在已生成的字符串前面加上两个0。
第三条规则表示在已生成的字符串前面加上一个1。
第四条规则表示在已生成的字符串两侧加上一个0。
第五条规则表示在已生成的字符串后面加上一个0。
3.指出下列 Lex 正则式所匹配的字符串:
(1)" { " [ ^ { ] * " } "
这个正则表达式匹配的字符串以 “{” 开始,后面跟随任意数量的非 “{” 字符,然后以 “}” 结束。
例如,匹配的字符串可以是:
- “{ }”
- “{ abc }”
- “{ 123 }”
(2)[ ^ 0-9] | [ \r \n ]
该正则表达式匹配任何不是数字(0-9)的字符,或者回车符(\r)或换行符(\n)。
例如,匹配的字符串可以是:
- “a”
- “$”
- “\r”
- “\n”
(3)\’ ( [ ^ ’ \n ] | \’ \’ ) + \’
这个正则表达式匹配的字符串以单引号开始,后面跟随一个或多个非单引号且非换行的字符或者是两个连续的单引号,然后以单引号结束。
例如,匹配的字符串可以是:
- ‘hello’
(4)\" ([ ^ " \n ] | \[ " \n ] ) * \"
这个正则表达式匹配的字符串以双引号开始,后面跟随任意数量的非双引号且非换行的字符或者是字符串"[“\n]”, 其中\n表示换行符,然后以双引号结束。
例如,匹配的字符串可以是:
- “hello”
- “I"m”
- “John’s”
4.已知文法
G
[
E
]
G[E]
G[E]
(1)
E
→
a
A
∣
b
B
E \rightarrow aA | bB
E→aA∣bB
(2)
A
→
c
A
∣
d
A \rightarrow cA | d
A→cA∣d
(3)
B
→
c
B
∣
d
B \rightarrow cB | d
B→cB∣d
构造该文法的
L
R
(
0
)
LR(0)
LR(0) 分析表
首先对文法进行拓广,并对产生式进行编号:
(0) S ′ → E S' \rightarrow E S′→E (1) E → a A E \rightarrow aA E→aA (2) E → b B E \rightarrow bB E→bB (3) A → c A A \rightarrow cA A→cA (4) A → d A \rightarrow d A→d (5) B → c B B \rightarrow cB B→cB (6) B → d B \rightarrow d B→d
根据算法 5-2,从 S ′ → ⋅ E S' \rightarrow · E S′→⋅E 出发,构造识别文法所有可归前缀的 DFA,如图 5-4 所示。
再根据算法 5-3 ,构造文法 G[E] 的 LR(0) 分析表如表 5-7 所示。
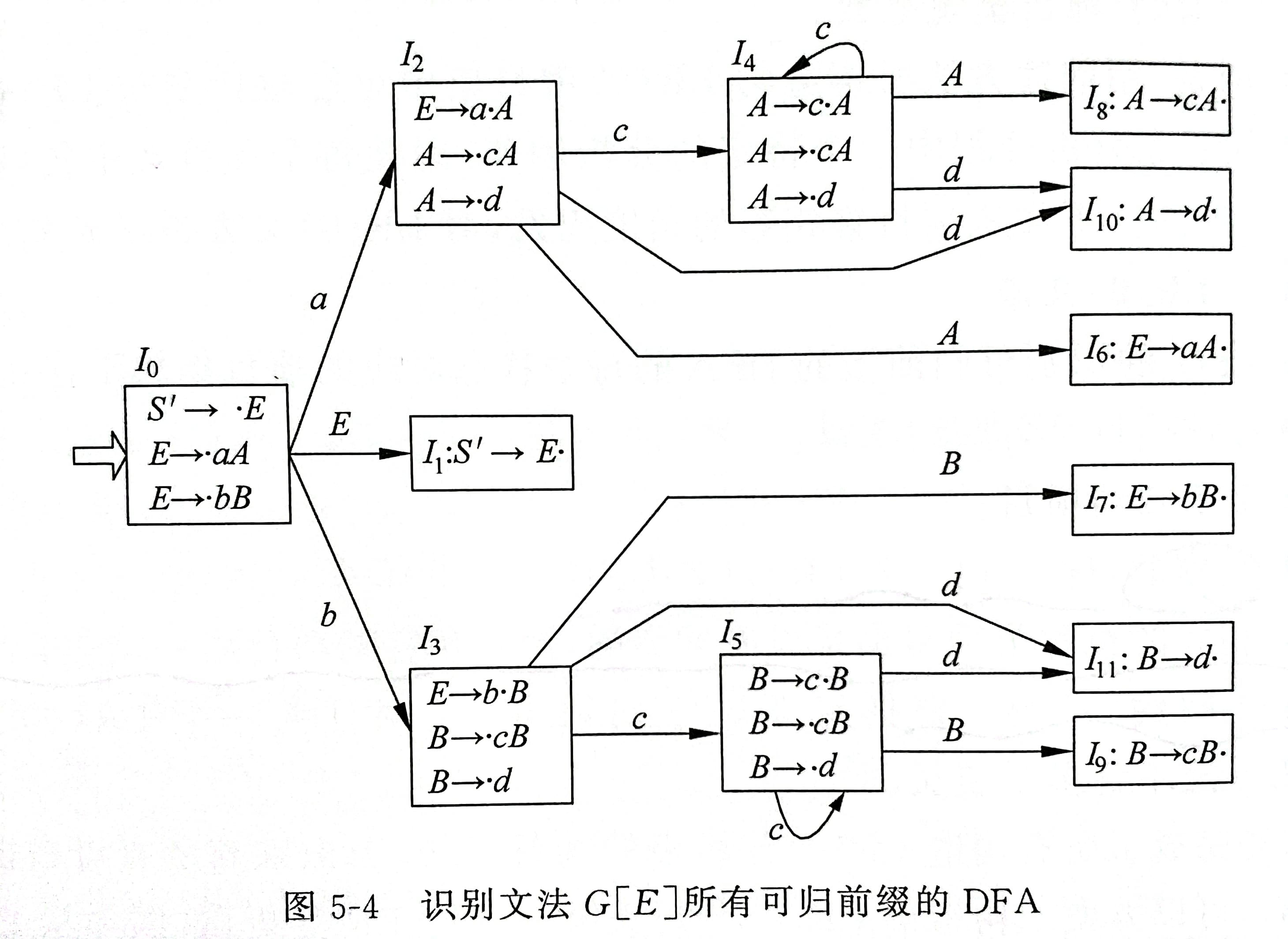
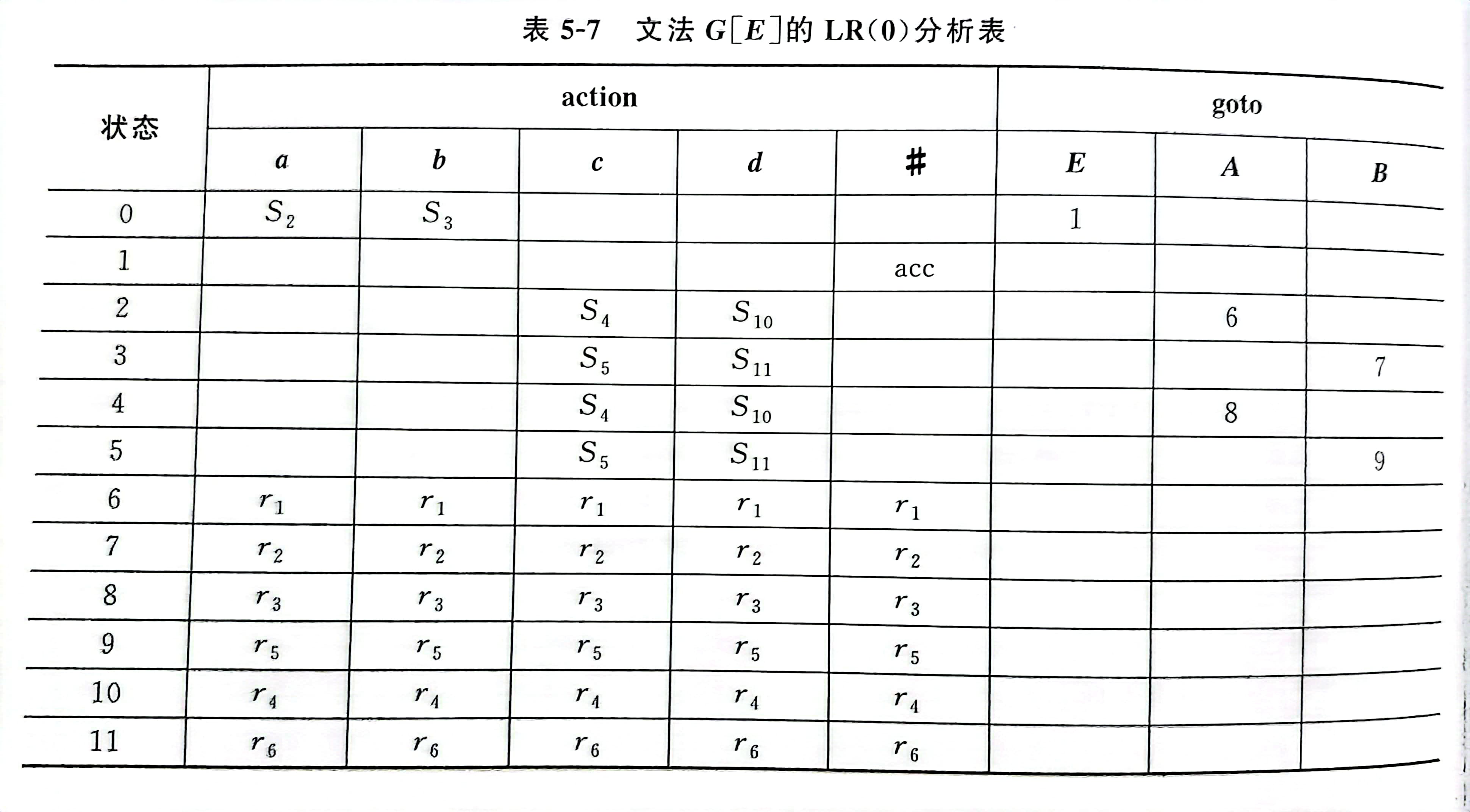
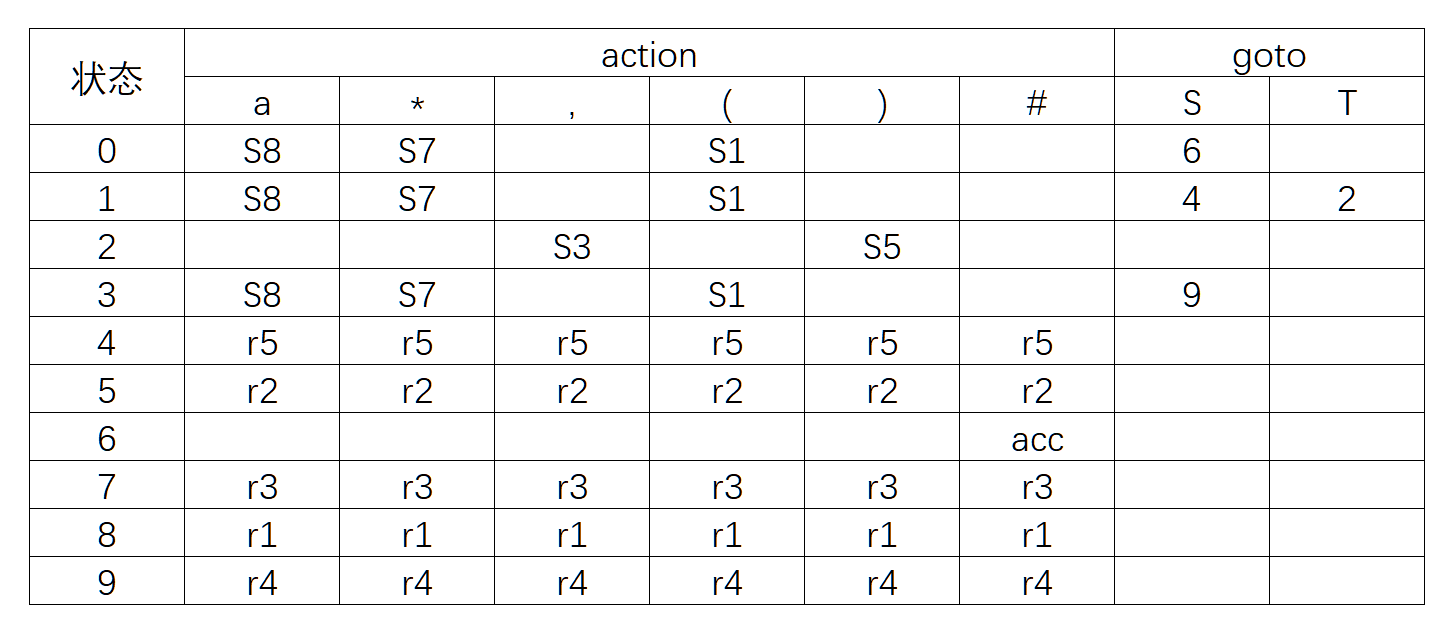
5.设有文法
G
[
S
]
G[S]
G[S]
S
→
a
∣
(
T
)
∣
∗
S \rightarrow a | (T) | *
S→a∣(T)∣∗
T
→
T
,
S
∣
S
T \rightarrow T , S | S
T→T,S∣S
① 构造此文法的
L
R
(
0
)
LR(0)
LR(0) 项目集规范族,并给出识别活前缀的 DFA。
② 构造其
L
R
(
0
)
LR(0)
LR(0) 分析表。
首先对文法进行拓广,并对产生式进行编号:
(0) S ′ → S S' \rightarrow S S′→S (1) S → a S \rightarrow a S→a (2) S → ( T ) S \rightarrow (T) S→(T) (3) S → ∗ S \rightarrow * S→∗ (4) T → T , S T \rightarrow T,S T→T,S (5) T → S T \rightarrow S T→S
根据算法 5-2,从 S ′ → ⋅ S S' \rightarrow · S S′→⋅S 出发,构造识别文法所有可归前缀的 DFA,如下图所示。
再根据算法 5-3 ,构造文法 G[S] 的 LR(0) 分析表如下所示。
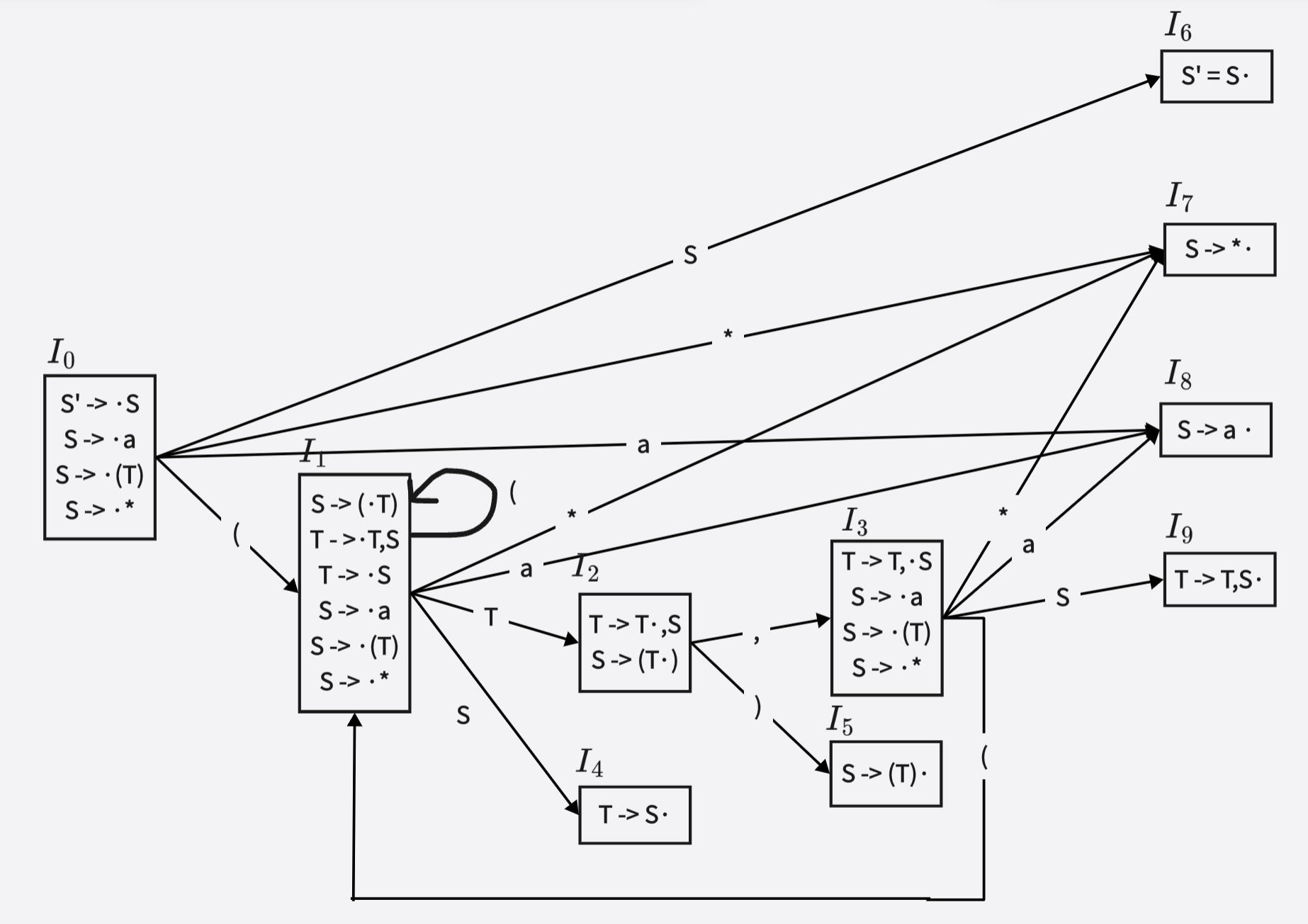
6.请利用代码优化的思想(代码外提和强度削弱等),改写下面程序中的循环,得到优化后的 C 语言程序。
Main( )
{
int i, j;
int S[20][50];
for( i = 0; i < 20; i++)
{
for(j = 0; j < 50; j++)
S[i][j] = 10 * i * j;
}
}
【解答】 本题用到的代码优化技术主要有代码外提和强度消弱。 10 ∗ i 10 * i 10∗i 在内循环是不变计算,可以外提,于是在外循环有 k = 10 ∗ i k = 10 * i k=10∗i,在内循环有 r [ i ] [ j ] = k ∗ j r[i][j] = k * j r[i][j]=k∗j;然后把这两个乘法进行轻度消弱,在循环中使用加法,在外循环每次加 10 10 10, r [ i ] [ j ] r[i][j] r[i][j] 在内循环每次加 k k k。
C语言中允许使用指针访问数组的首地址,二维数组在存储区域是按行排列。这样,通过指针的加法运算就可以访问数组元素,避免在循环内部寻址的重复运算。优化后的C语言程序如下:Main() { int i, j, m, n, k; int* p; int r[20][50]; p = &r[0][0]; n = 0; for(i = 0; i < 20; i++) { k = n; n + = 10; m = 0; for(j = 0; j < 50; j++) { * p = m; p++; m + = k; } } }
补充:
7.设有文法 G[S]:
S
→
a
A
c
B
e
S \rightarrow aAcBe
S→aAcBe
A
→
b
∣
A
b
A \rightarrow b | Ab
A→b∣Ab
B
→
d
B \rightarrow d
B→d
对输入符号串 abbcde 进行“移进-归约”分析,即判定它是否为该文法的句子。
用“移进-归约”分析方法对输入符号串 abbcde 的分析过程如表5-1所示。符号#作为输入符号串 abbcde 的左右界符,即输入符号串的开始和结束标志。初始化时,将左界符 # 首先放入符号栈底,然后从第一个符号开始分析。

8.设有文法 G[S]:
(1)
S
→
L
,
S
S \rightarrow L , S
S→L,S
(2)
S
→
L
S \rightarrow L
S→L
(3)
L
→
x
L \rightarrow x
L→x
(4)
L
→
y
L \rightarrow y
L→y
已知文法 G[S] 的 LR 分析表如表 5-4 所示。以输入串 “x , y , x” 为例,给出 LR 分析器的分析过程。

输入串 “x , y , x” 的 LR 分析过程如表 5-5 所示。

















 3180
3180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











