









目录
导言
诺曼底登陆是一次巧妙的军事欺骗行为,利用一揽子欺骗计划赢得夺岛最佳时机,为战争胜利打下坚实基础。诺曼底登陆因此被称作“最大的军事欺骗”或“十大军事骗局之首”。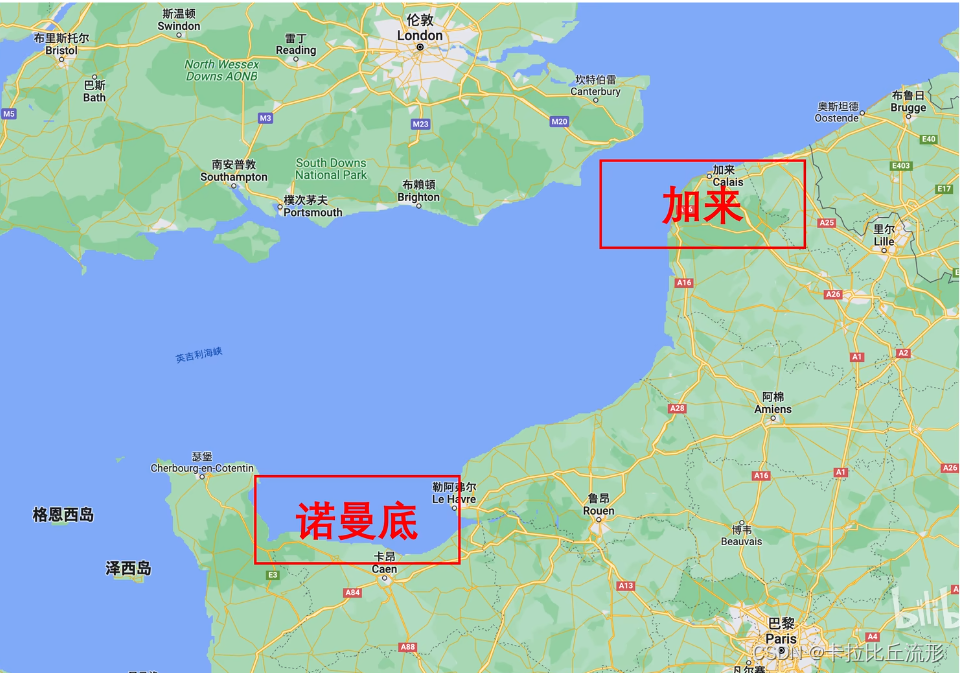
其中一条计划代号是卫士计划——“南方坚韧”之声东击西
牵制住挪威,只是牵制住了德军一部分兵力,更重要的是进攻方向上的欺骗。盟军最终选择加来作为佯攻地点,在对岸多佛建立了第一集团军群的司令部,司令官是巴顿。战争前夕,他们开始大规模的建立营房、医院,弹药库,表面上看似十分逼真。该集团军人员共计3000名,其中2000名是发报人员,通过互传假情报欺骗德国电讯侦察人员。而有1000名是伪装人员,利用橡胶制作了大量的装备模型,坦克、飞机、大炮一应俱全,因此骗过了德军的空军侦察兵。由于巴顿在西西里岛战役中的出色表现,让德军误以为加来是盟军的主攻方向。
到了60年代人工智能出现了,美国军方想利用神经网络来识别照片中的坦克是真坦克,在美国军方的测试集中有99%的准确率,但是在实际应用中的效果很差。造成这个结果的原因大家众说纷纭,神经网络就像一个黑箱子,没有人知道它究竟是怎么工作的,这正是可解释人工智能要解决的问题。
一、什么是可解释人工智能?
人工智能黑箱子灵魂之问
- Al的脑回路是怎样的? Al如何做出决策?是否符合人类的直觉和常识?
- Al会重点关注哪些特征,这些特征是不是真的有用?
- 如何衡量不同特征对Al预测结果的不同贡献?
- Al什么时候work,什么时候不work ?
- AI有没有过拟合?泛化能力如何?
- 会不会被黑客误导,让AI指鹿为马?
- 如果样本的某个特征变大15,会对Al预测结果产生什么影响?
- 如果Al误判,为什么会犯错?如何能不犯错?
- 两个AI预测结果不同,该信哪一-个?
- 能让AI把学到的特征教给人类吗?
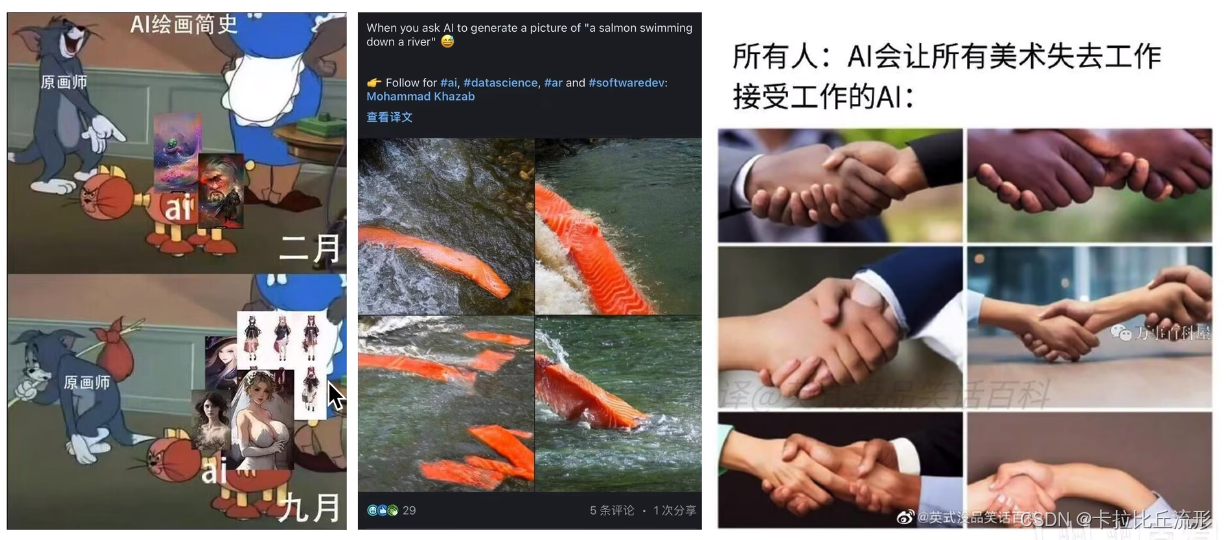
无论是AI绘画还是最近大火的ChatGPT,我们只知道它们的效果很好,但是我们还是无法知道模型能表现这么好的原因。从上图我们可以看出AI绘画有时候生成的图片是看似合理但是经不起推敲的。
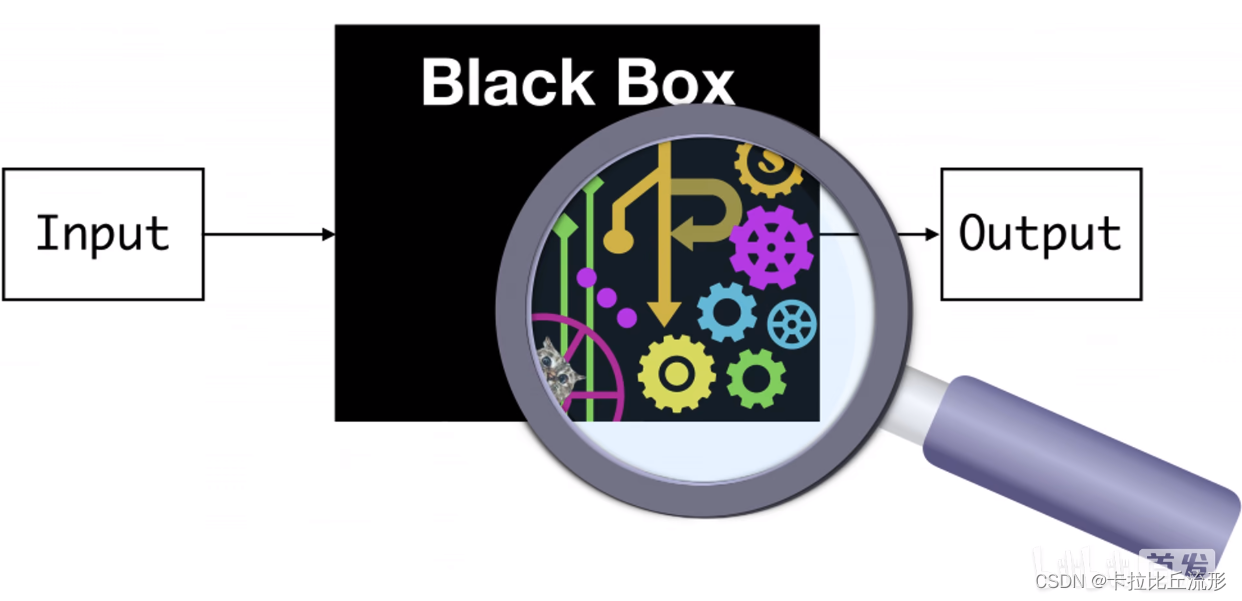
可解释性就是希望寻求对模型工作机理的直接理解,打破人工智能的黑盒子。
二、学可解释机器学习有什么用?
2.1学习可解释机器学习的原因
-
可解释性学习满足选择研究方向时的一下条件:
- 尽可能通用,与其它研究方向交叉
- 顺应主流发展趋势,长期存在且有用
- 有高质量的数据集
- 不过分小众,但也好发paper,没有疯狂内卷
- 能应用到产业界垂直细分行业
- 有商业应用价值,容易“讲故事’
-
研究AI的脑回路,就是研究AI的本质。
-
可解释分析是机器学习和数据挖掘的通用研究方法。
-
和所有Al方向交叉融合:数据挖掘、计算机视觉、自然语言处理、强化学习、知识图谱、联邦学习。
-
包括但不限于:大模型、弱监督、缺陷异常检测、细粒度分类、决策Al和强化学习、图神经网络、Al纠偏、Al for Science、 Machine Teaching、 对抗样本、可信计算、联邦学习。
2.2 Machine Teaching :人工智能教人类学习
- 用AI学习鸟类的分类,让AI教会人类学习

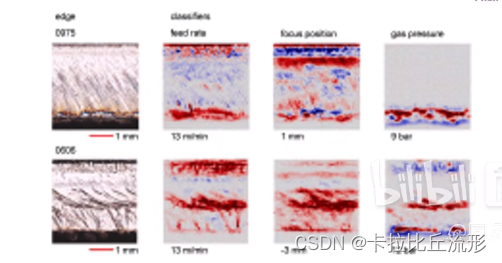
- 用可视化的方法,让神经网络教会人类如何预测工艺参数
- 绝艺围棋AI指导棋:围棋定式、招式
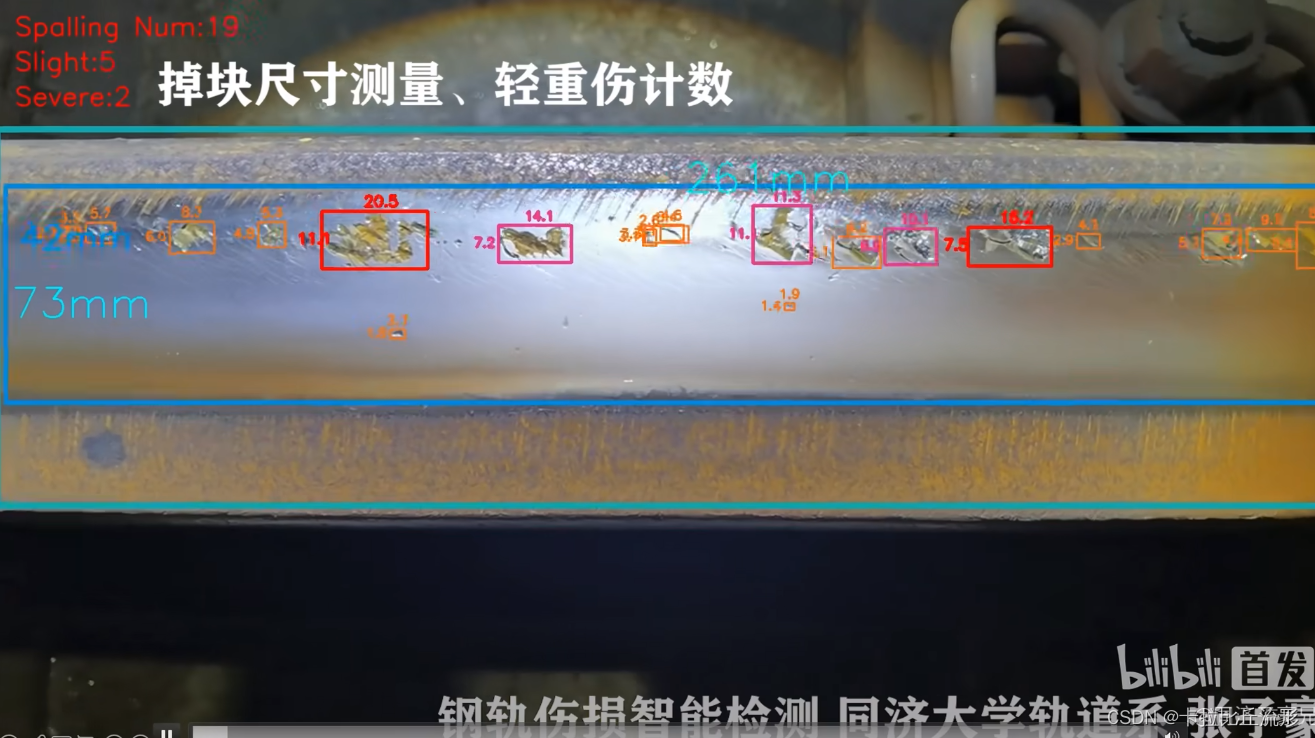
- 铁路轨道伤损识别
- AI作画:指导人类绘画(百度文心)

2.3 细粒度图像分类
-
花和叶子的识别

-
荔枝的类别识别

-
类似的海洋生物的识别

-
韩国女星的识别

-
奥特曼识别

-
X光胸片的肺炎判定

-
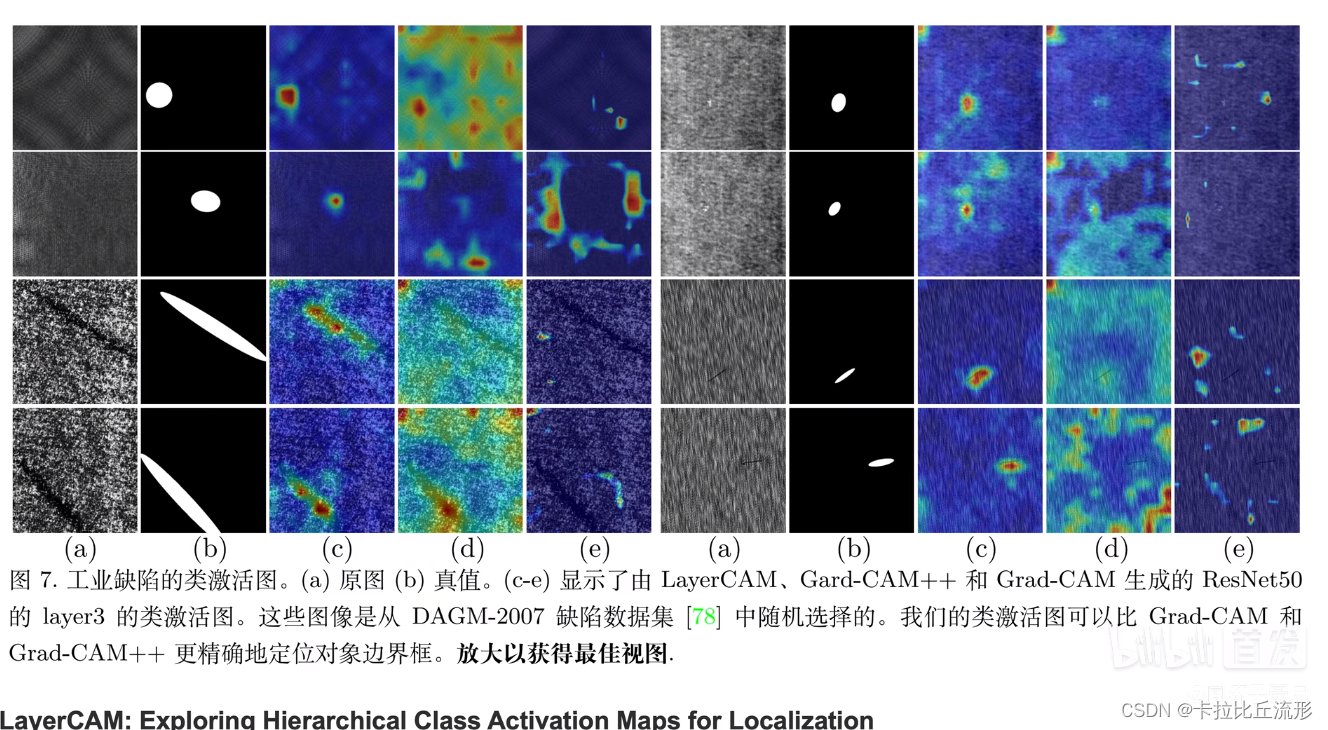
工业缺陷的类激活图:用分类问题解决定位问题
-
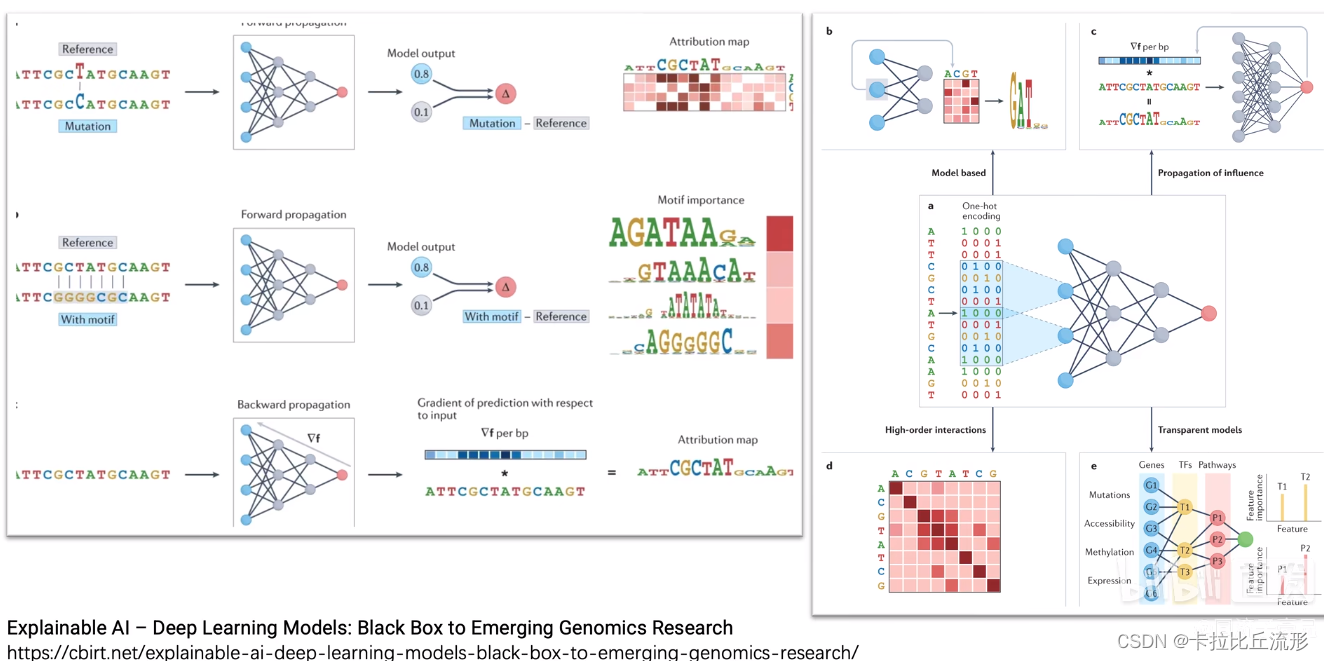
生物医学、生物信息学、基因数据挖掘、蛋白质结构预测领域
2.4前沿AI
-
ChatGPT聊天机器人
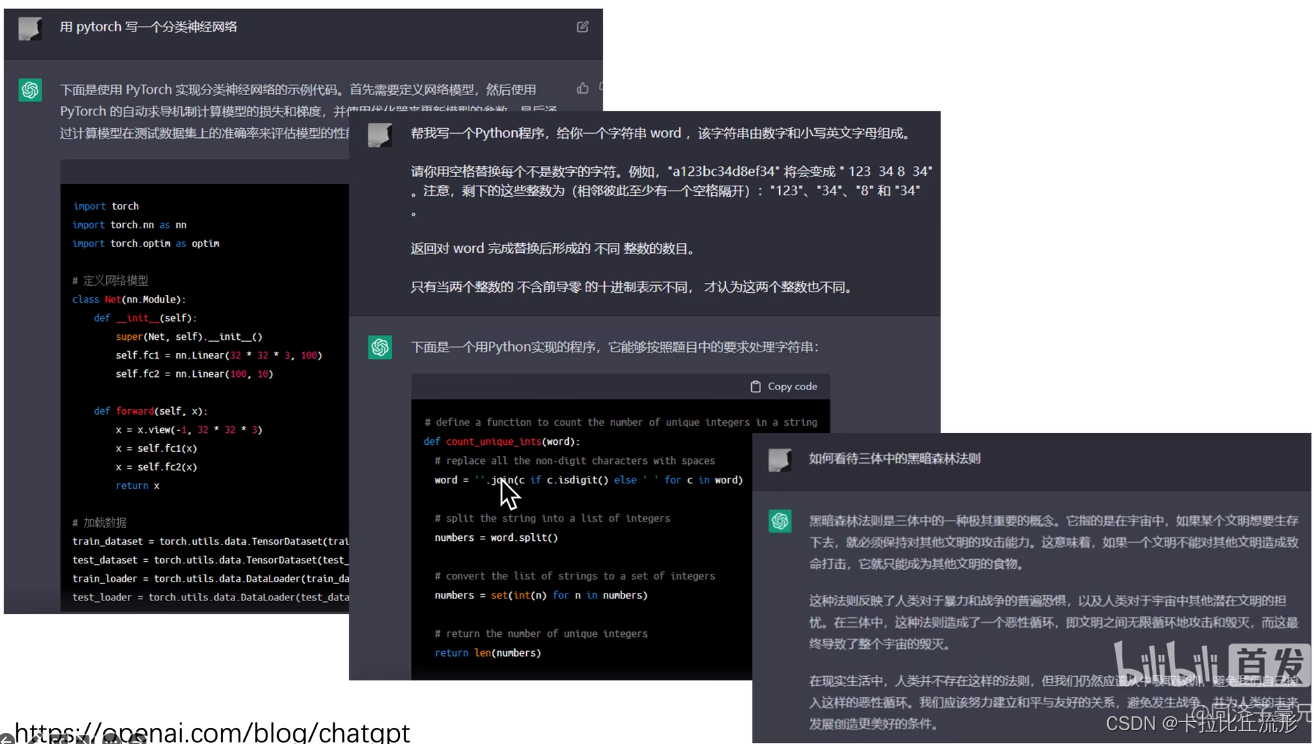
-
AI绘画
-
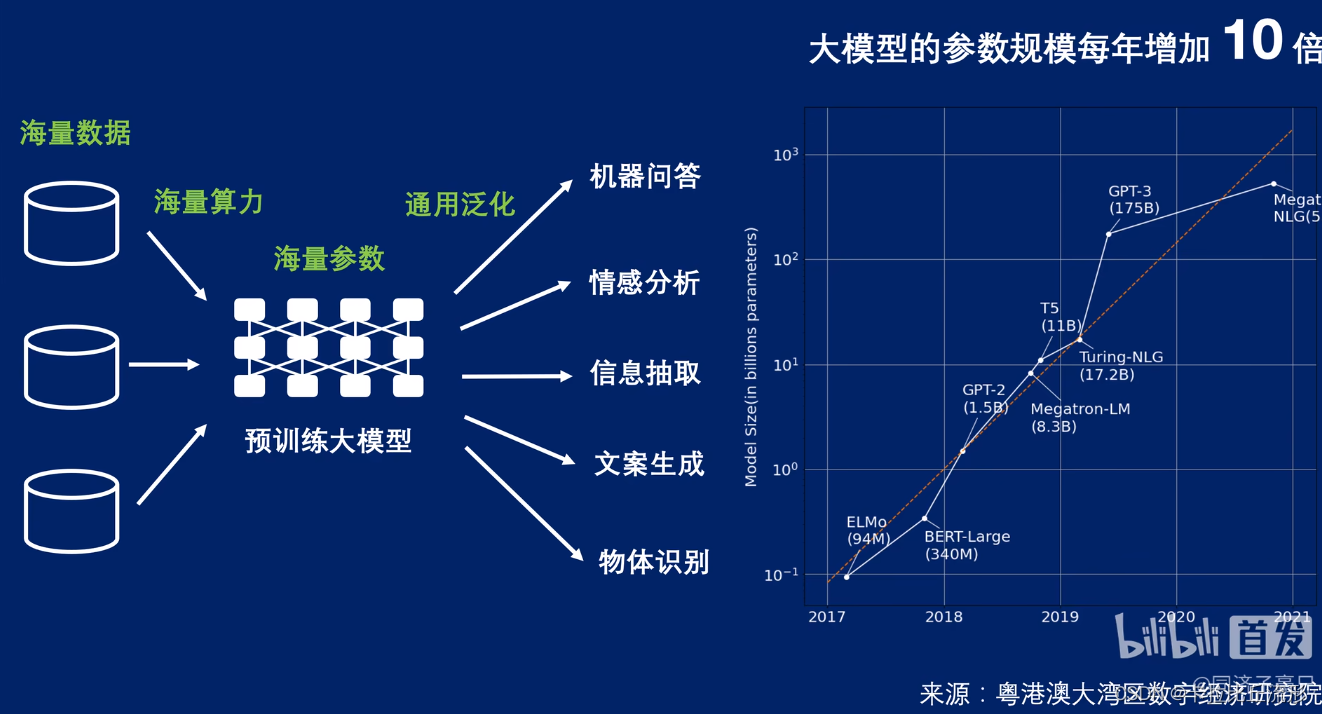
大模型:用海量数据、海量算力、海量参数进行训练
-
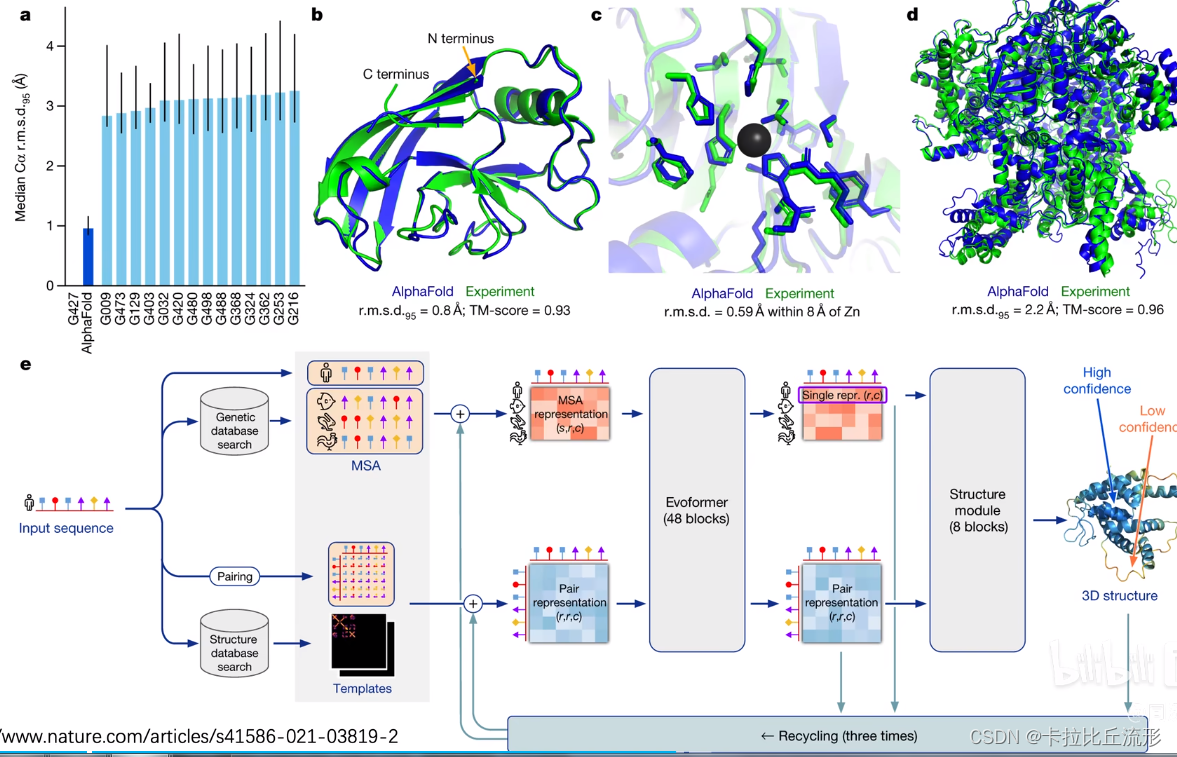
蛋白质的空间预测(要运用大模型)
三、本身可解释性好的机器学习模型
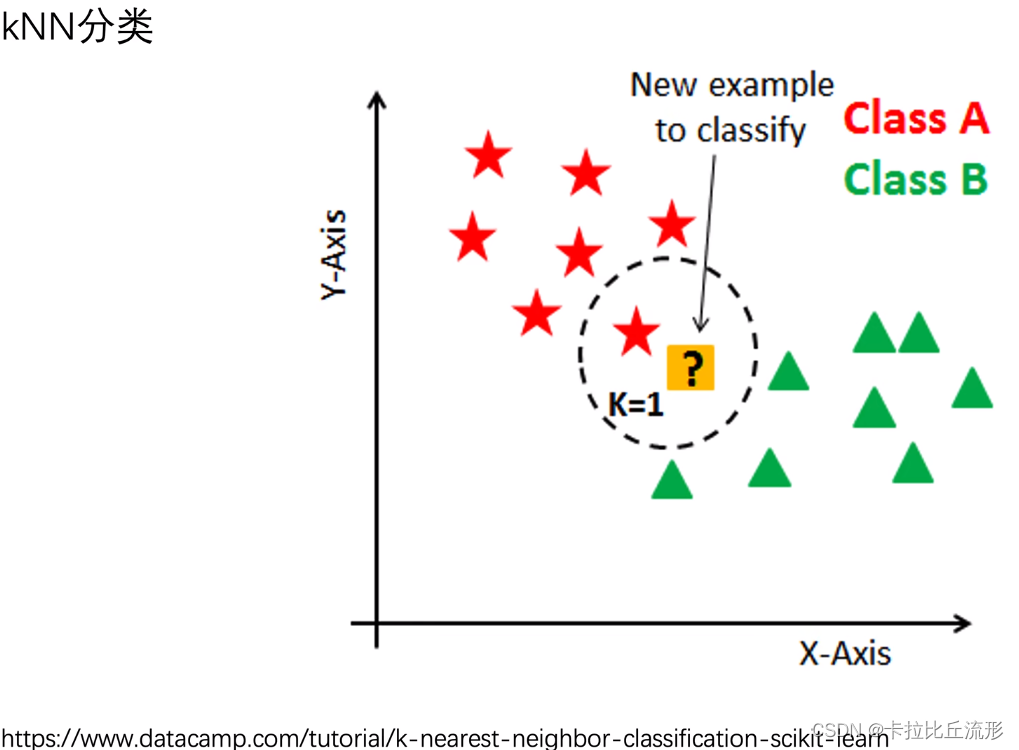
本身可解释性好的机器学习模型:KNN(k-最近邻算法)、Logistic回归算法、线性回归算法、决策树、朴素贝叶斯
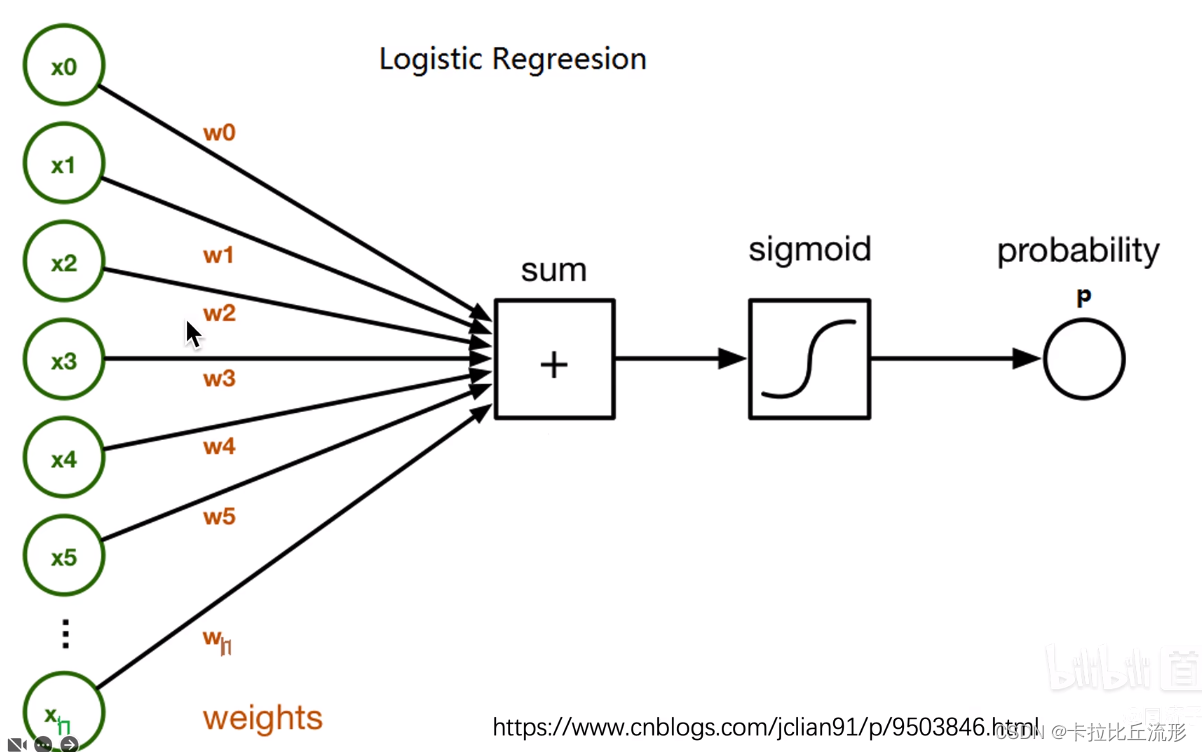
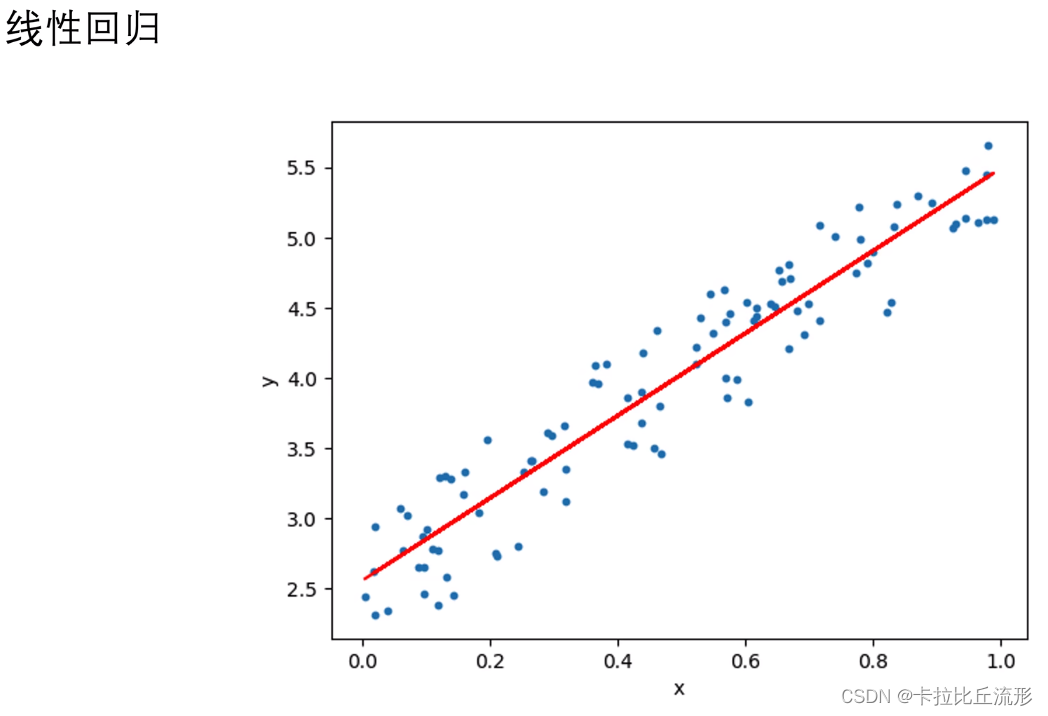
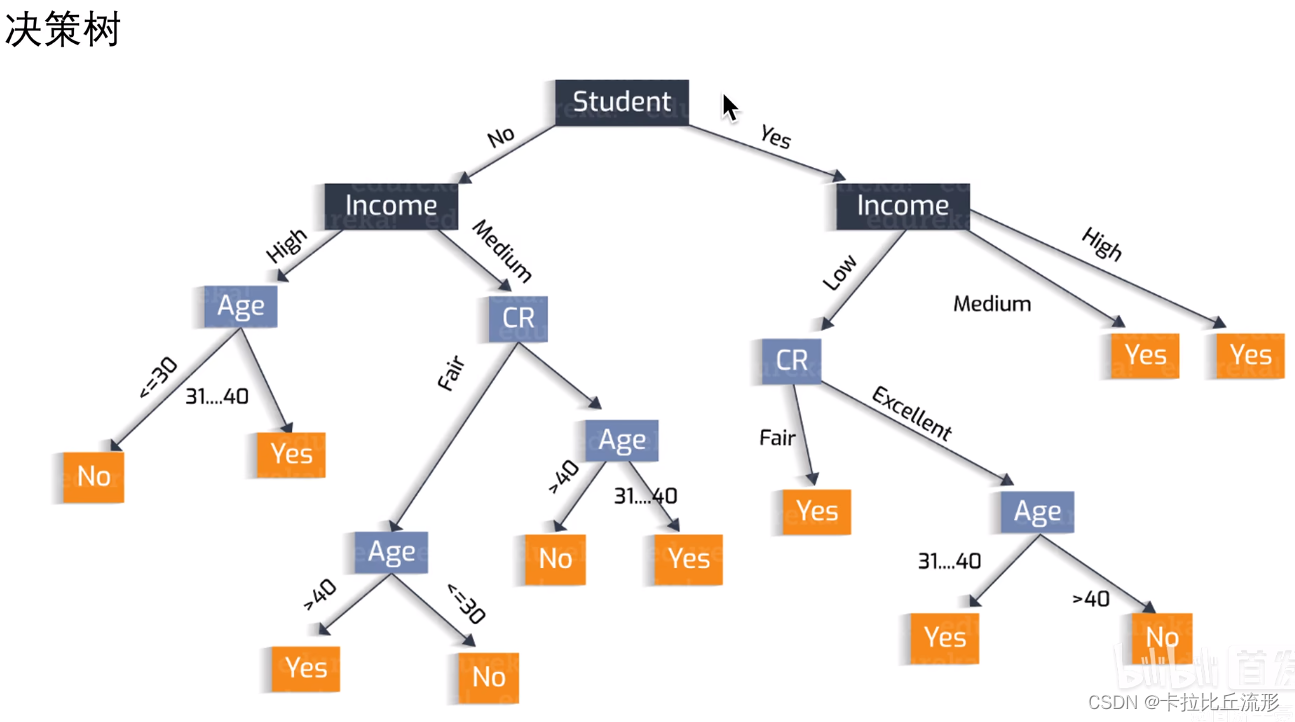
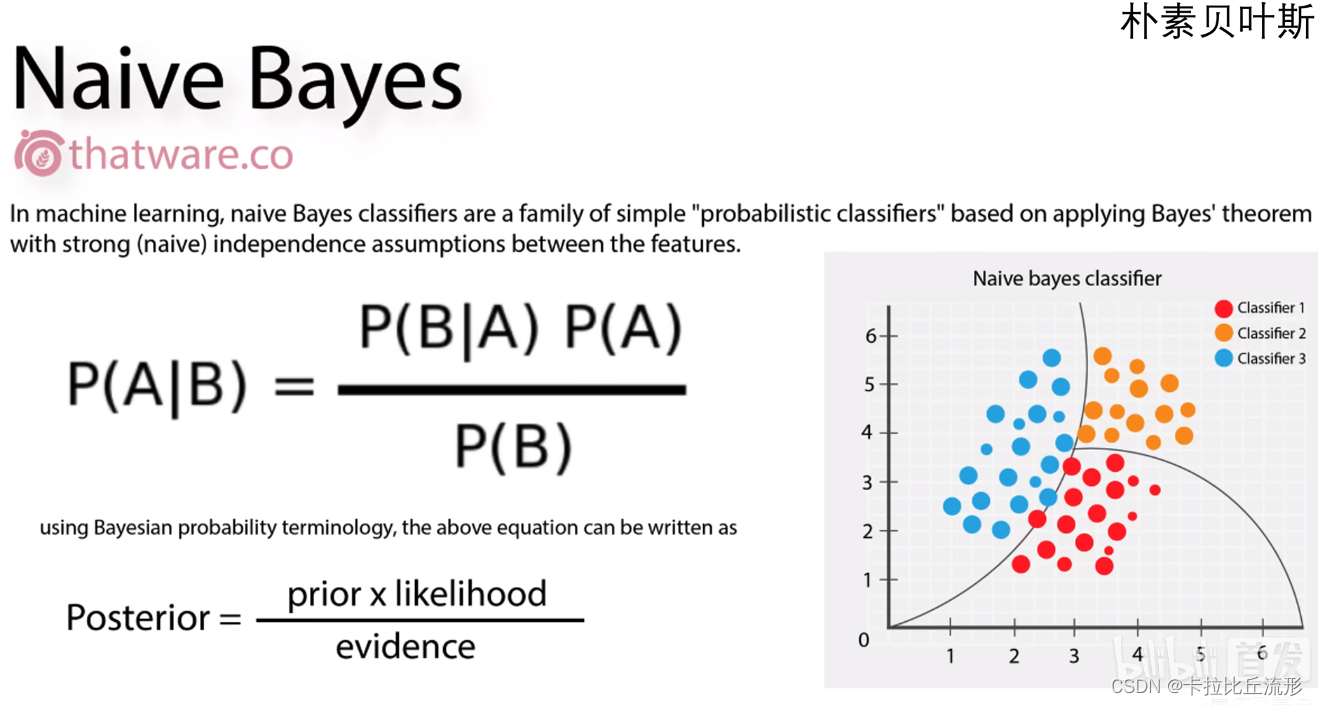
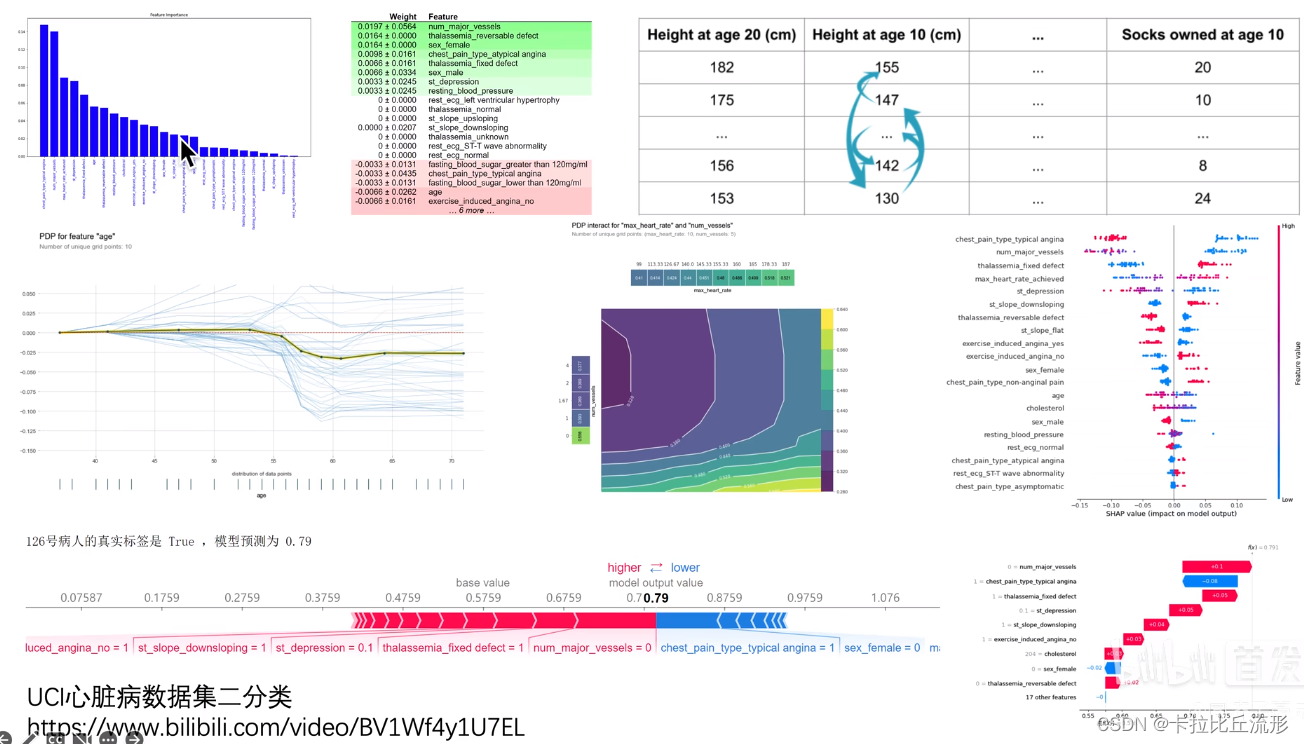
四、传统机器学习算法的可解释性分析
- 算法自带的可视化
- 算法自带的特征权重
- Permutation Importance置换重要度
- PDP图、ICE图
- Shapley值
- Lime
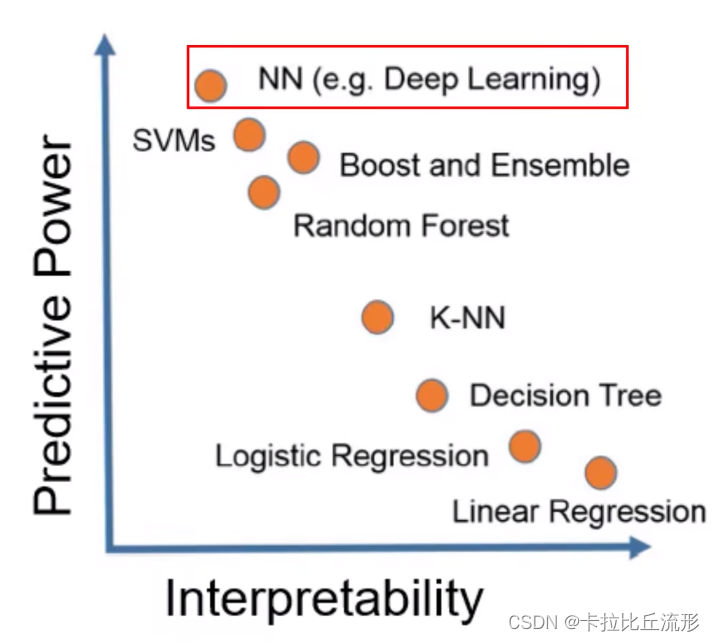
算法性能和可解释能力的关系
五、卷积神经网络的可解释性分析
- 可视化卷积核、特征图
- 遮挡Mask、缩放、平移、旋转
- 找到能使某个神经元激活的原图像素,或者小图
- 基于类激活热力图(CAM) 的可视化
- 语义编码降维可视化
- 由语义编码倒推输入的原图
- 生成满足某些要求的图像 (某类别预测概率最大)
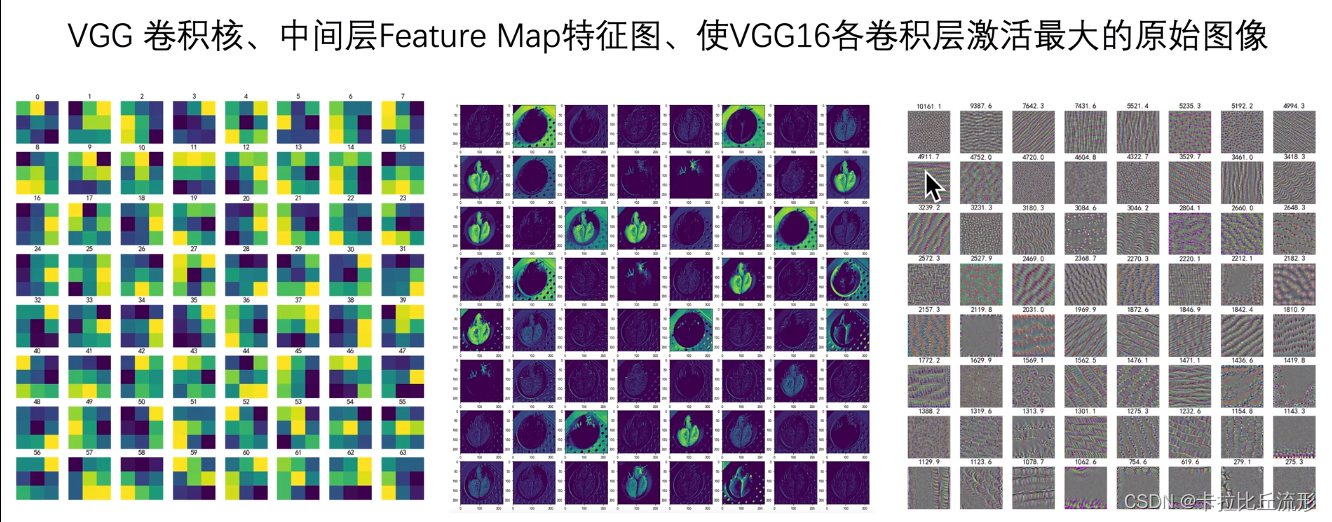
5.1可视化卷积核、特征图
每个卷积核提取不同的特征,每个卷积核对输入进行卷积,生成一个feature map,这个feature map即提现了该卷积核从输入中提取的特征,不同的feature map显示了图像中不同的特征。
- 浅层卷积核提取:边缘、颜色、斑块等底层像素特征
- 中层卷积核提取:条纹、纹路、形状等中层纹理特征
- 高层卷积核提取:眼睛、轮胎、文字等高层语义特征
最后的分类输出层输出最抽象的分类结果

5.2遮挡Mask、缩放、平移、旋转
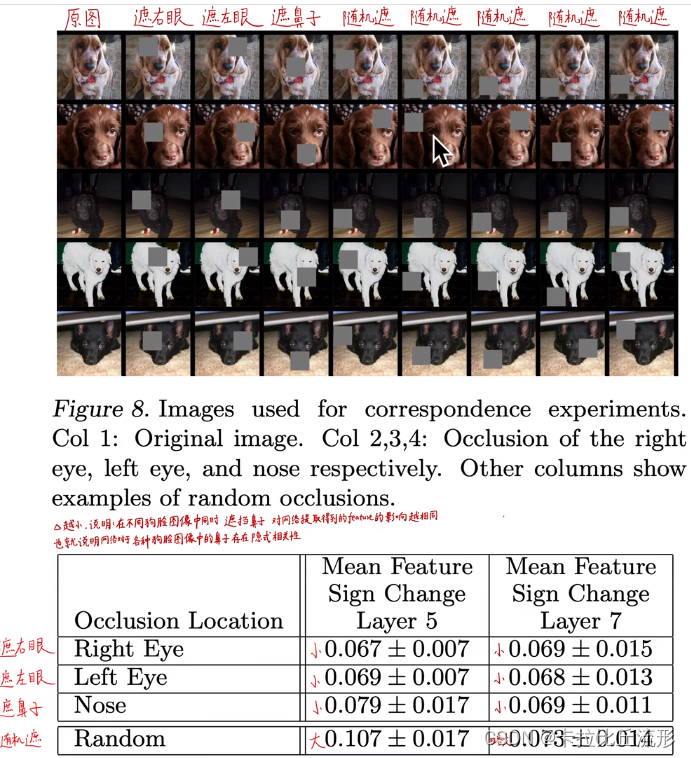
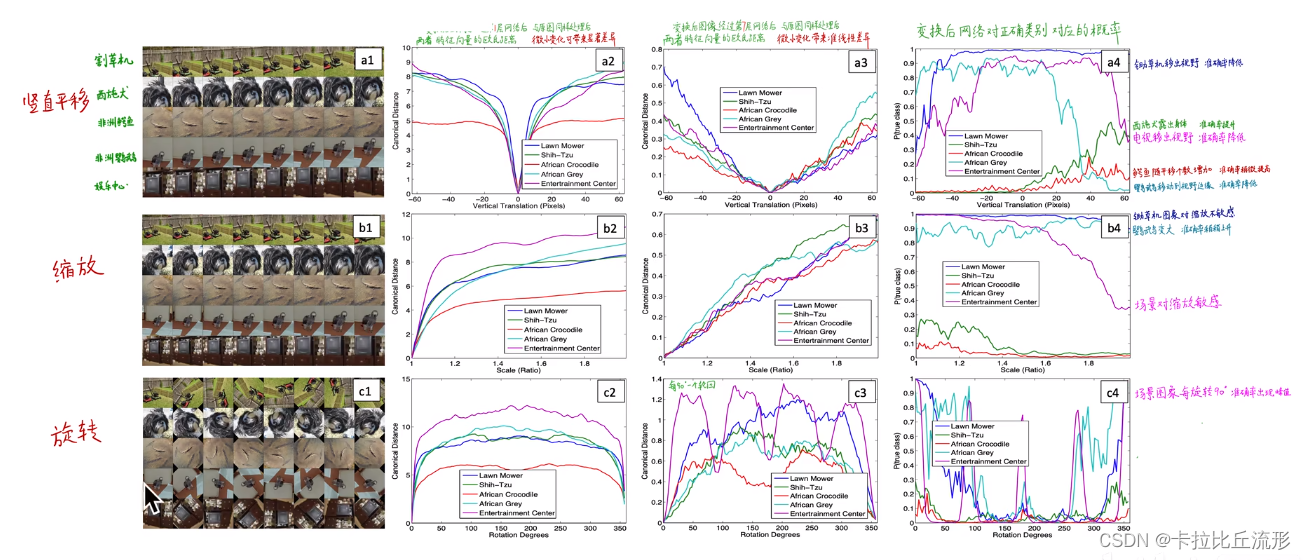
5.3找到能使某个神经元激活的原图像素,或者小图

5.4基于类激活热力图(CAM) 的可视化

5.5语义编码降维可视化
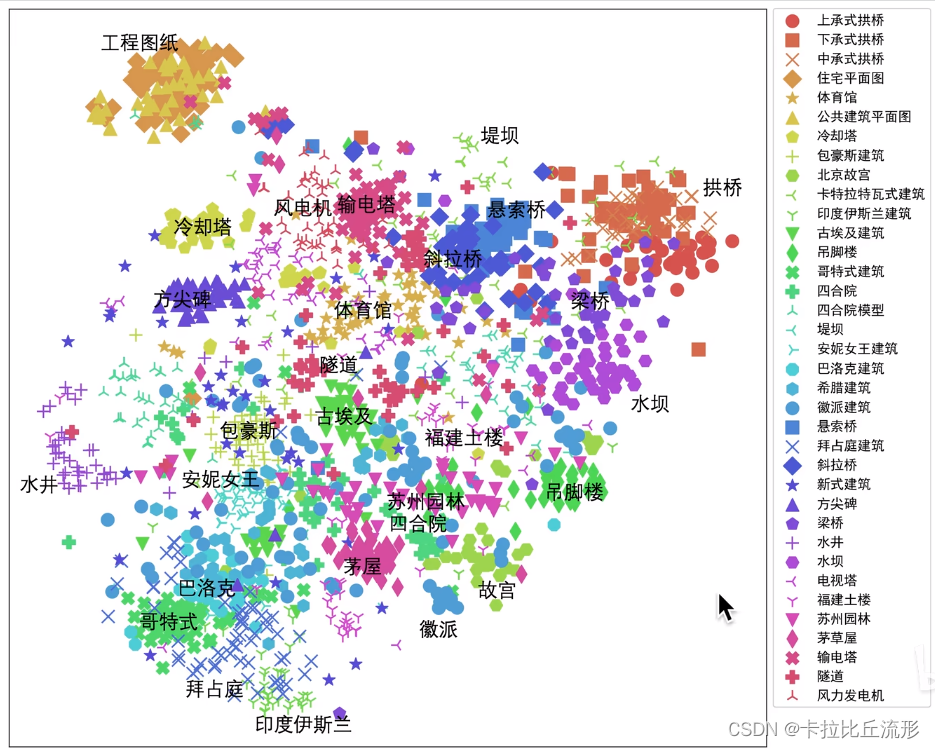
5.6由语义编码倒推输入的原图
5.7生成满足某些要求的图像 (某类别预测概率最大)

逃逸攻击可分为白盒攻击和黑盒攻击。白盒攻击是在已经获取机器学习模型内部的所有信息和参数上进行攻击,令损失函数最大,直接计算得到对抗样本;黑盒攻击则是在神经网络结构为黑箱时,仅通过模型的输入和输出,逆推生成对抗样本。下图左图为白盒攻击(自攻自受),右图为黑盒攻击(用他山之石攻此山之玉)。
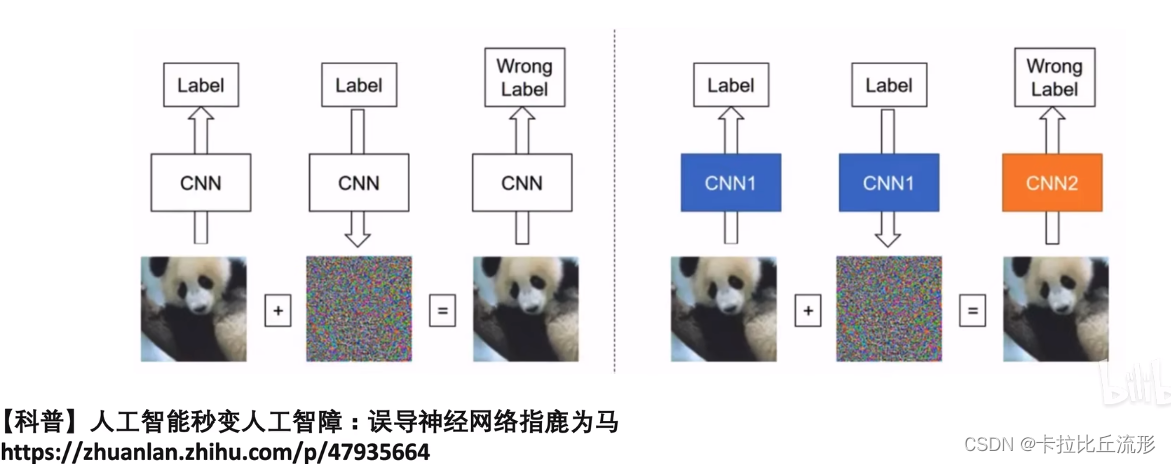
下面的图片就是一种快速梯度符号攻击,加了一部分噪声后,我们会发现,虽然人的判断还是正确的,但是人工智能的判断已经把pandas分类为gibbon长臂猿了。

六、总结

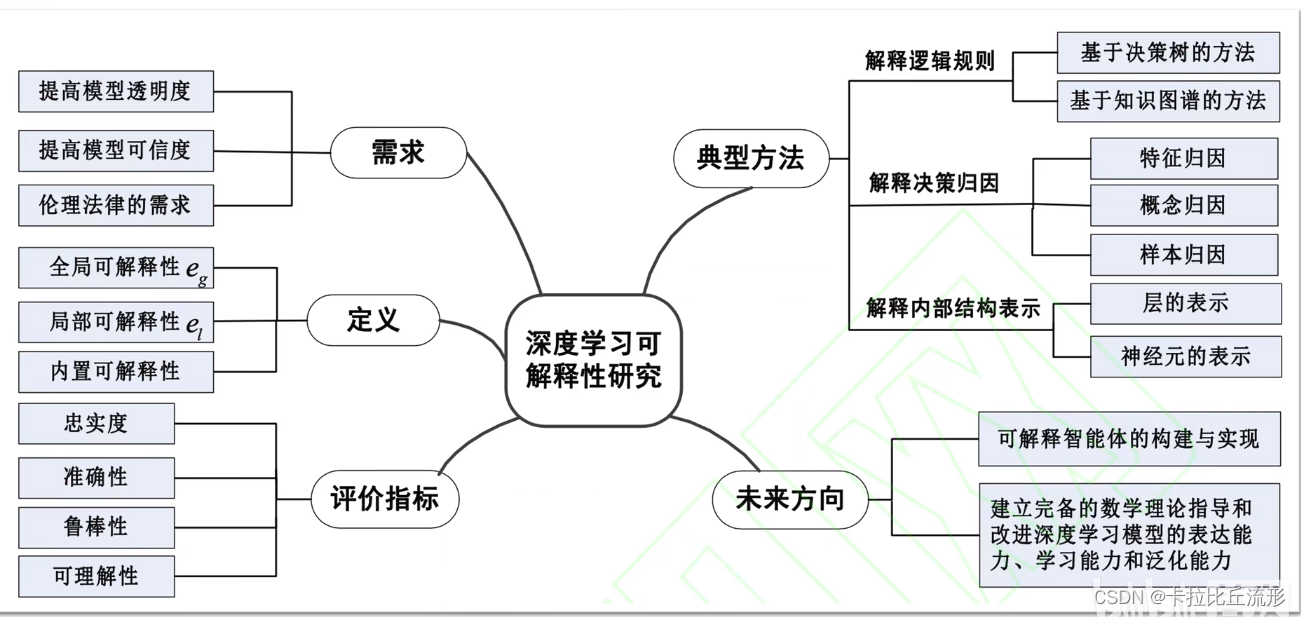
扩展阅读
子豪兄出品的可解释性分析代码:https://github.com/TommyZihao/Train_Custom_Dataset/图像分类
pytorch的可解释性分析库:
https://github.com/utkuozbulak/pytorch-cnn-visualizations
思考题
为什么要对机器学习、深度学习模型做可解释性分析和显著性分析 ?
如何回答“人工智能黑箱子灵魂之问” ?
人工智能的可解释性分析有哪些应用场景?
哪些机器学习算法本身可解释性就好?为什么?
对计算机视觉、自然语言处理、知识图谱、强化学习,分别如何做可解释性分析?
在你自己的研究领域和行业,如何使用可解释性分析?
可以从哪几个角度实现可解释性分析 ?
Machine Teaching有哪些应用场景 ?



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











