







LeNet

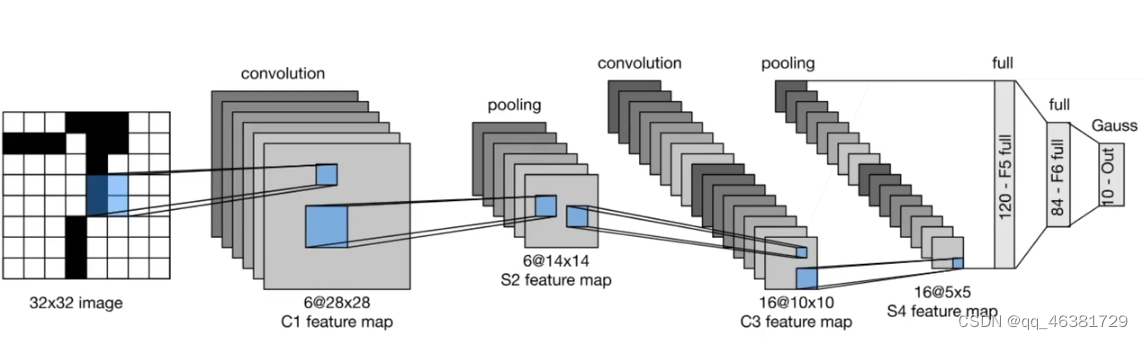
LeNet网络结构如上,两个卷积层,两个池化层,再加连个全连接层构成了LeNet。

QA:
- 时序性数据同样可以用卷积网络。
- 在数据压缩高宽减半的同时,可以把通道数翻倍,通道数增加可以使得能匹配的模式变多,所以同样一个像素表示的信息变大,通道变多相当于把信息分散到通道中。
- 输出通道可以很大程度上认为是匹配的某一个局部特征。
卷积神经网络(LeNet)
LeNet-由两部分组成,卷积编码器和全连接层密集块
import torch
from torch import nn
from d2l import torch as d2l
class Reshape(torch.nn.Module):
def forward(self,x):
return x.view(-1,1,28,28)
net = torch.nn.Sequential(
Reshape(),
#卷积
nn.Conv2d(1, 6, kernel_size=5,padding=2), nn.Sigmoid(),
#均值池化层2*2窗口
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),
nn.MaxPool2d(kernel_size=2, stride=2),
#卷积层出来是4D的东西,要把高宽拉成一个向量,Flatten()就是保留一维,后面拉伸
nn.Flatten(),
# 16*5*5是该层输入,120是输出
nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(),
nn.Linear(84, 10))
检查模型
X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)
for layer in net:
X = layer(X)
#layer.__class__指的是每一层, .__name__得到每一次的名字
print(layer.__class__.__name__,'output shape: \t',X.shape)

LeNet在FashionMNIST数据集的表现
from d2l import torch as d2l
batch_size = 256
train_iter,test_iter = d2l.load_data_fashion_mnist(batch_size)
def evaluate_accuracy_gpu(net, data_iter, device=None):
"""使⽤GPU计算模型在数据集上的精度"""
if isinstance(net, nn.Module):
net.eval() # 设置为评估模式
if not device:
# 如果没有传入device的话,就看网络存的地方
device = next(iter(net.parameters())).device
# 正确预测的数量,总预测的数量
metric = d2l.Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
if isinstance(X, list):
# BERT微调所需的(之后将介绍)
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
metric.add(d2l.accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
为使用GPU,训练函数需要改动
def train_ch6(net,train_iter,test_iter,num_epochs,lr,device):
"trian a model with a gpu(defined in chapter 6)"
# 权重初始化,使得输入和输出的方差不太大
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
# 每一层都调用函数,初始化网络权值
net.apply(init_weights)
print('training on',device)
net.to(device)
# 随机梯度下降
optimizer = torch.optim.SGD(net.parameters(),lr=lr)
# 交叉熵
loss = nn.CrossEntropyLoss()
# 动画效果
animator = d2l.Animator(xlabel='epoch',xlim=[1,num_epochs],
legend = ['train_loss','train_acc','test_acc'])
timer,num_batches = d2l.Timer(),len(train_iter)
for epoch in range(num_epochs):
metric = d2l.Accumulator(3)
net.train()
for i,(x,y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
x,y = x.to(device),y.to(device)
y_hat = net(x)
# 计算损失
l = loss(y_hat,y)
# 计算梯度
l.backward()
# 迭代优化
optimizer.step()
metric.add(l*x.shape[0],d2l.accuracy(y_hat,y),x.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(train_l, train_acc, None))
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
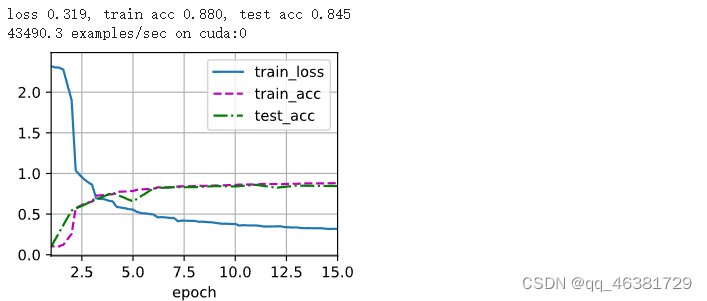
print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, '
f'test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec '
f'on {str(device)}')
lr, num_epochs = 1.5, 15
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())















 726
726











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









