






1.准备工作
【loc[]】和【iloc[]】都是【pandas】的【DataFrame对象】的方法,而且都是用来选择一个确定的【组】,区别在于:loc是用【行标签】来选择行,而iloc是用行的【整数索引】(从0开始)来选择行。我个人觉得这么说可能有点抽象,不如咱们来探索一下,具体iloc和loc是怎样运作的
正式开始前,我们来明确一下,本教程代码均在【jupyter notebook】上运行,然后每一小节,我都会把源数据粘贴一遍,便于那么对比,最后我们要明确一下等会使用的数据,如下代码:
import pandas as pd
import numpy as np
data=pd.DataFrame(
[
['苏打','含','冷',10.5,150],
['咖啡','不含','热',3.0,31],
['冰沙','不含','冷',6.0,85],
['冰水','不含','冷',0.0,0],
['凉茶','不含','热',2.0,43]
],
columns=['饮料','含碳?','温度','含糖量','卡路里']
)
data.set_index('饮料')
通过上面的第三条语句,我们创建了一个DataFrame矩阵,如下图输出
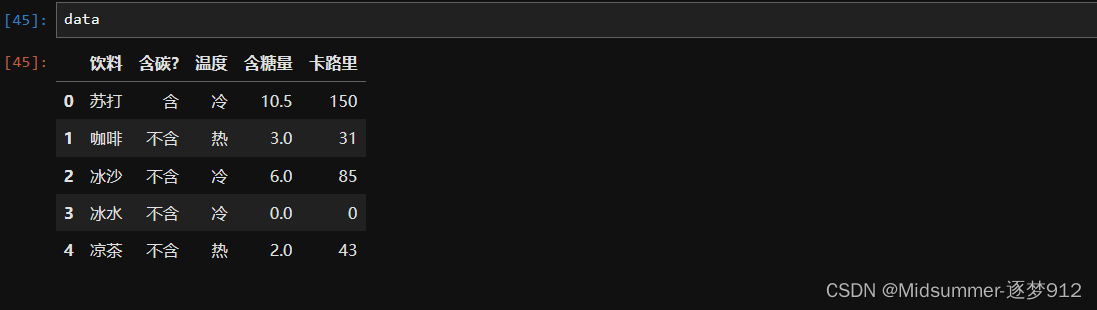
然后通过最后一条语句,将【饮料】这一列设置为了【行索引】,下面是data的输出:

下面要正式开始了!
2.选择单行数据
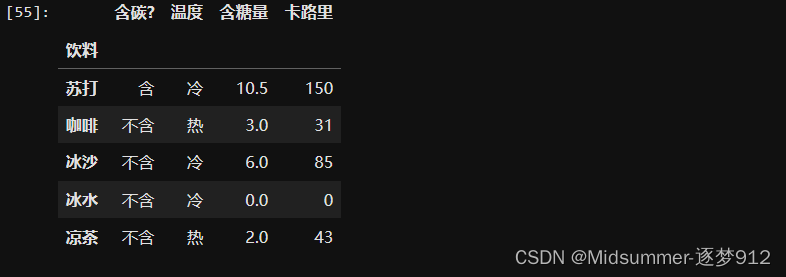
①用【loc】选择单行数据
使用具体的【行标签】来进行索引,如果行索引没有这个标签,则会报错。

②用【iloc】选择单行数据
使用具体的【行号】来进行索引,行号从【0】开始,这与python的列表,c语言的数组等都是一致,所以我相信,你看一眼上面的数据,在看一眼输出就很容易明白这里为什么取0会输出下面的数据了。

现在我们有一个问题,就是源数据是一个【矩阵】,排列得还算整齐好看吧,但是你看上面的输出,只选择一行的话,它就会把这一行的数据进行【转置输出】(就是倒过来嘛),我觉得这很难看呀,作为处女座的娃,下面就来处理一下这个问题!
③选择单行数据,但仍使用DataFrame格式输出
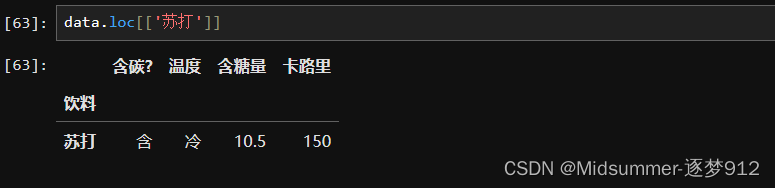
这个操作不难,只要将索引框嵌套一层就好啦,如【data.loc[['苏打']]】这一条语句就不会转置了,为什么会这样,光说不解释可不行,我们来尝试理解一下。
因为本身loc和iloc是用来在DataFrame结构中选择多行的,这个框框里就是要输入的多行索引,比如【data.loc[['苏打','冰沙','凉茶']]】这样,他就会按照DataFrame的格式输出这三行:
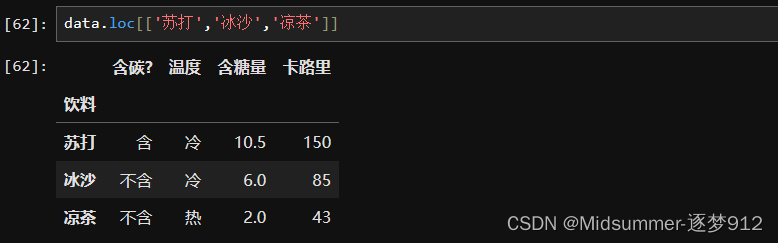
如果套上框就表示你【有意向】要选择多行,但是你可以在这个里面只写一行嘛,又不犯法是不是?这样,它就会按DataFrame的格式处理输出,所以这就是为什么套个框会有如此神奇的效果,看一看测试数据吧!没戳你不?
3.选择多行数据

①用【列表】作为输入选择多行
这里衔接上一节第三小点嘛,就是套个框框,不解释咯,直接上图
【loc】实现

【iloc】实现
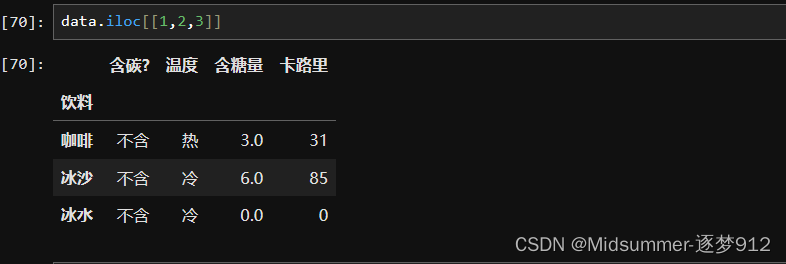
②用【切片】作为输入,选择多行
可以用切片机制作为输入来选择是个很棒的特性吧,但是特别需要注意的一点是,【loc】的切片会包含最后一个索引行,而【iloc】的切片会丢弃最后一个索引,感觉说起来就是挺抽象的,上代码吧!
【loc】实现

【iloc】实现

是吧,索引【3】应该是【冰水】,但是输出并没有包含,嗯,是个细节。
4.选择行和列
定位到具体的矩形,要求给出具体的索引。
①选择一个单元值
选择一个单元值就类似excel中选择一个单元格,选择一个单元格要咋整,是不是在excel中要给出明确的【行号】和【列标】,同样,DataFrame的选择要给出明确的【行索引】和【列索引】,其实都是一个东西,就是换了个叫法而已,格式是【data.loc[行索引,列索引]】或【data.iloc[行索引,列索引]】,看示例吧!
【loc】实现

是吧,【苏打】的温度就是【冷】,其实苏打冷不冷我不知道哈哈,没喝过
【iloc】实现

②用【列表】作为输出,选择一个矩形区域
其实跟上面都没什么区别的,只是把具体的单个索引,变成了用列表来表示的多个索引,格式是【data.loc[[行索引序列],[列索引序列]]】或【data.iloc[[行索引序列],[列索引序列]]】
【loc】实现

【iloc】实现

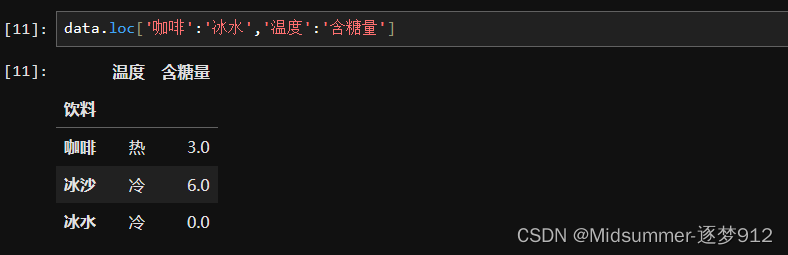
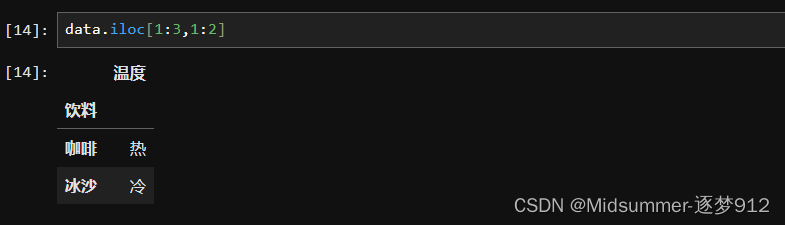
③用【切片】作为输入,选择一个矩形区域
切片也很简单,就是把行索引和列索引的位置分别替换成行索引切片和列索引切片就好啦,格式为【data.loc[行索引切片,列索引切片]】或【data.iloc[行索引切片,列索引切片]】
【loc】实现
【iloc】实现
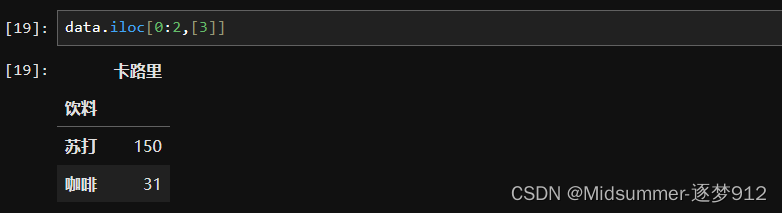
④用各种方法的组合,选择一个矩形区域
这里其实就是前面介绍的方法的combination,比如说行可以用列表作为输入,列可以用切片作为输入,总之,可以多种组合,但是值得注意的是,行或者列,只能有一种表示,而不能说,行输入外层用列表,列表里面再嵌套个切片,这种是不允许的,而且语法也是错误的。看看下面的实际例子吧。
【loc】实现

【iloc】实现
5.使用布尔型列表作为输入
使用布尔列表作为输入时,只有值为【True】对应的项会被选中,【False】项不会被包含。

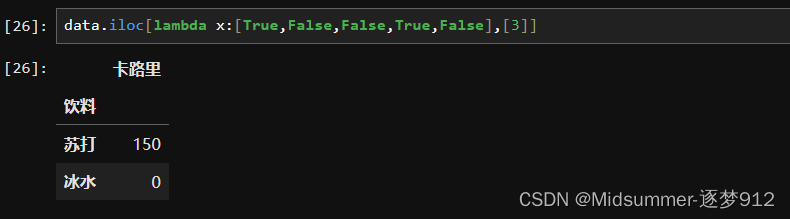
6.使用lambda函数表达式作为输入
使用lambda函数作为输入也可以试一试,有时候能帮助我们更加方便快捷地批量处理输入,而不是靠我们手动去添加索引。
结束语
大功告成,希望对各位有帮助,此外由于文章匆匆写成,若有不妥之处直接提刀就行了,现在是北京时间2023年9月11日18:38分,刚刚下课,我该去吃饭了。
希望时间见证你我,青春不负光阴不负卿

参考文献
[1]DataFrame Indexing: .loc[] vs .iloc[] - Data Science Discovery (illinois.edu)
[2]pandas.DataFrame.loc — pandas 2.1.0 documentation
[3]pandas.DataFrame.iloc — pandas 2.1.0 documentation















 6292
6292











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









