




 Pandas中的.loc和.iloc是两种常用的索引方式。.loc主要基于标签进行操作,适合处理行名列名,同时能接受布尔数组。.iloc则基于整数位置进行索引,适用于行和列的零索引选择。两者都可以处理切片和布尔数组,但在使用切片时,.loc包含起始和结束标签,而.iloc包含起始和结束的位置。
Pandas中的.loc和.iloc是两种常用的索引方式。.loc主要基于标签进行操作,适合处理行名列名,同时能接受布尔数组。.iloc则基于整数位置进行索引,适用于行和列的零索引选择。两者都可以处理切片和布尔数组,但在使用切片时,.loc包含起始和结束标签,而.iloc包含起始和结束的位置。
.loc[]主要基于标签(就是行名列名),但也可以与布尔数组一起使用
.iloc[]主要基于整数位置(行列索引都是从零开始,内在顺序),但也可以与布尔数组一起使用。
.loc[]用法
以下都是在jupyter中代码块
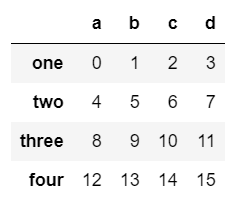
先定义一个DataFrame
import numpy as np
import pandas as pd
data=pd.DataFrame(np.arange(16).reshape(4,4),index=['one','two','three','four'],columns=['a','b','c','d'])
data
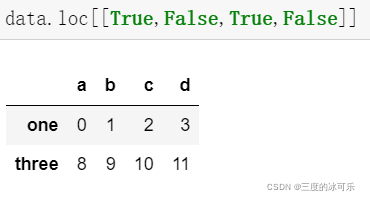
[ ]里可以输入什么
单个标签

标签列表

带有标签的切片对象(与通常的 python 切片相反,包括开始和停止)


与要切片的轴的长度相同的布尔数组
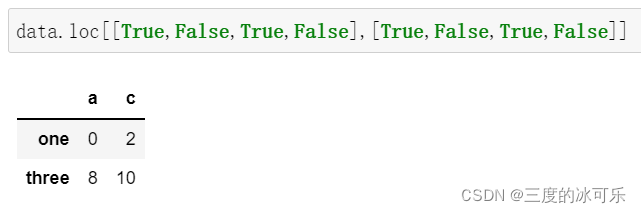
.iloc[]用法
[ ]里可以输入什么
单个整数
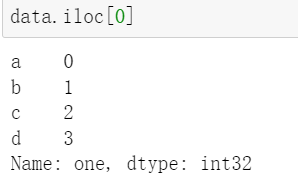
取第一行
整数的列表或数组

取一二行
具有整数的切片对象

前两行两列的交集
布尔数组

取前两行
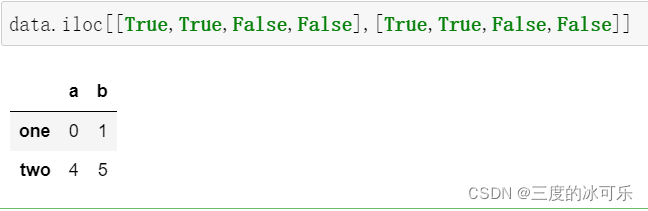
前两行两列的交集
总结
.loc[[start:end],[start:end]]和.iloc[[start:end],[start:end]]
区别在于.loc使用的是行列标签(定义的具体行名和列名),而.iloc使用的是行列整数位置(从零开始)

















 1915
1915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









