







1.Hadoop 分布式文件系统(HDFS)
HDFS 是一个高度容错性的系统,适合部署在廉价的机器上。 HDFS 能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。其解决了海量数据存储问题,突破了单体服务器的存储能力。
2.HDFS架构
HDFS是分布式主从系统架构,通常包含一个NameNode 节点和多个 DataNode 节点。存储文件时,一个文件被分成了一个或者多个数据块,并存储在多个 DataNode 上,不同DataNode 会对其他DataNode 的数据块进行备份,称为副本(默认共3个)
2.1 NameNode
NameNode可以当做一个管理者。
- 基于内存存储管理文件的元数据信息。
元数据:描述数据属性的信息。如文件名、大小、存储位置、类型、权限等。
- HDFS集群的管理者master:管理集群中所有的datanode。
- 掌握datanode健康状况,了解磁盘容量,数据分布的负载均衡。
- 均衡使用datanode的磁盘空间。
- 集合多个datanode服务器的网络带宽,提高数据传输速度。
- 接收客户端文件操作的请求(文件元数据操作请求)。
如打开,关闭和重命名文件和目录。
- 存储了文件拆分后的block分布信息。
如:block0–所在datanode的ip–起始位置–大小–checksum校验和
2.2 DataNode
HDFS的从机slave,数据节点。(干活的)
- DataNode 是文件系统的工作节点,供客户端和NameNode 调用并执行数据块datablock的上传下载创建删除请求。
- 管理存储数据文件切分后的block块(默认128MB),存放硬盘上。
- 定期向namenode发送心跳(3s),告知datanode(ip 磁盘容量)。
2.3 block
文件切分后的数据块。
默认大小:128MB
原因:现有服务器机房局域网网络带宽千兆带宽==125MB/s
注意:
block过大:导致单个block网络传输速度过慢,无法利用多个datanode网络传输的带宽。
block过小:block个数过多,导致namenode内存过度占用,导致不足。
2.4 replication:副本
每个block在hdfs的datanode会存储多份。
默认replication=3,每个block有3份。
原因:防止datanode因为单点故障,导致数据丢失。
2.5 checksum:校验和
hdfs文件的数字指纹。
作用:datanode定期向namenode汇报文件的checksum,由namenode判断文件是否完整。
注意: 如果文件不完整,namenode会协调从损坏数据块的副本所在DataNode拷贝损坏的数据块。
3. HDFS相关原理
3.1NameNode持久化
问题:NameNode宕机,导致内存中的文件元数据丢失怎么办?
解决:NameNode会将内存中的元数据持久化到磁盘中。
3.1.1 SecondaryNameNode
NameNode会将客户端的操作指令信息存储到Editslog文件中,然后再按照指令操作元数据。
- SecondaryNameNode向NameNode发起合并请求。
- NameNode将当前的Editslog文件保存改名edits,并新建EditsLog继续持久化工作。
- 将改名后的edits文件和本地的FSImage(旧)发送给sencondaryNameNode。
- SecondaryNameNode负责将FSImage(旧)+edits文件合并成FSImage(新)。
- 将新的FSImage(新)发送给NameNode保存。
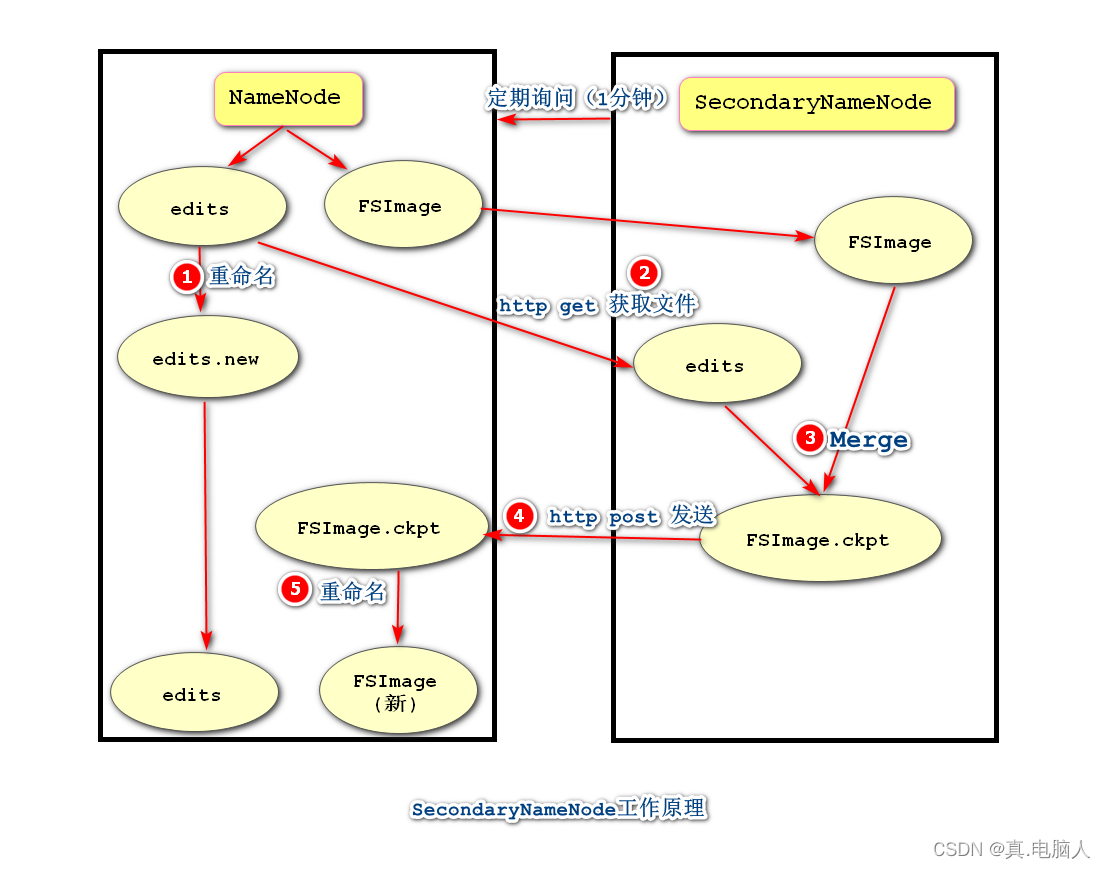
非实时merge,一旦NameNode挂了,可能会导致元数据丢失;
持久化触发条件: 1.超过3600s
2.edits.log的大小超过64M时
3.默认累计操作次数满100w次操作就会触发保存检查点操作
| 属性名 | 默认值 | 含义 |
|---|---|---|
| dfs.namenode.checkpoint.check.period | 60 | 每1分钟检查一次触发条件 |
| dfs.namenode.checkpoint.period | 3600 | 3600秒触发一次,数据合并。checkpoint |
| dfs.namenode.checkpoint.txns | 1000000 | 100w次操作触发一次 |
3.1.2 Standby NameNode
- HDFS 第一次格式化后, NameNode 就会生成 fsimage 和 editslog 两个文件。
- Standby NameNode从主用 NameNode 上下载FSimage,并从共享存储中读取 EditLog;
- Standby NameNode将日志和旧的元数据合并,生成新的元数据 FSImage.ckpt;
- Standby NameNode将元数据上传到主用NameNode;
- NameNode 将上传的元数据进行回滚。
实时merge,一旦前者挂了,后者能够马上顶上,不会出现元数据丢失。
非HA高可用时,有Secondary NameNode;HA时,有Standby NameNode。

















 2751
2751

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









