







 本文分析了lexicase选择方法在符号回归任务中的性能,并提出了epsilon-lexicase选择,这是一种改进的版本,适应连续误差空间。通过理论分析和实证研究,epsilon-lexicase选择在保持多样性的同时提高了模型预测精度,尤其是在处理连续误差时。实验表明,epsilon-lexicase选择在多个回归问题上优于传统选择策略。
本文分析了lexicase选择方法在符号回归任务中的性能,并提出了epsilon-lexicase选择,这是一种改进的版本,适应连续误差空间。通过理论分析和实证研究,epsilon-lexicase选择在保持多样性的同时提高了模型预测精度,尤其是在处理连续误差时。实验表明,epsilon-lexicase选择在多个回归问题上优于传统选择策略。

Abstract
Lexicase 选择是一种父代选择方法,在进行父代选择时,单独考虑训练案例,而不是综合考虑。虽然先前的工作已经证明了 Lexicase 选择能够解决程序合成和符号回归中的难题,但本文的中心目标是发展解释其性能的理论基础。为此,我们推导出一个解析公式,在给定种群及其行为的情况下,给出在 lexicase 选择下选择的期望概率。此外,我们将 lexicase selection 的关系拓展到高维多目标优化方法,以描述 lexicase selection 的行为,即在高维空间的 Pareto 前沿边界上选择个体。我们解析地展示了为什么对于一定规模的种群和训练 case,lexicase selection 表现得更差,并展示了为什么它在连续误差空间中表现得更差。为了解决最后一个问题,我们提出了 ϵ \epsilon ϵ-lexicase 选择的新变种,该方法修改了 lexicase 选择中的通过条件,允许近精英个体通过case,从而在连续错误的情况下提高选择性能。我们证明了 ϵ \epsilon ϵ- lexicase 在一些现实世界和合成回归问题上优于几种多样性维护策略。
1 Introduction
进化计算 (EC) 传统上通过给候选解分配标量适应度值 fitness 来决定如何指导搜索。在遗传规划 (GP) 的情况下,该适应度值概括了候选方案的行为与期望行为的平均匹配程度。以符号回归任务为例,在该任务中,我们尝试使用一组训练样本来寻找模型,即案例。一个典型的适应度度量是均方误差 (MSE),它平均了模型输出 (y) 和目标输出 (y) 之间的平方差。这种平均的效果是减少了为单个标量值比较模型输出和期望输出的一组丰富信息。正如 Krawiec(2016) 所指出的,( y ^ \hat{y} y^ 对 y y y 的关系只能用这个适应度值来粗略表示。因此,相对于输出到目标的原始比较中对候选程序行为的描述,适应度分数限制了传递给搜索过程的关于候选程序的信息,这些信息有助于指导搜索(Krawiec and O’Reilly, 2014; Krawiec and Liskowski, 2015)。这一发现引起了人们对开发能够直接利用程序输出来更有效地驱动搜索 (Vanneschi et al., 2014) 的方法的兴趣。
除了减少信息外,平均测试性能假设所有的测试都具有相同的信息,这导致即使在大多数种群难以解决的训练 case 中表现最好,但平均测试性能较差的个体也受到潜在的损失。这对于需要不同行为模式才能产生问题 (Spector, 2012). 的充分解决方案的问题尤其相关。传统选择方法的基本假设是,选择压力应针对训练 case 均匀施加。在实践中,构成该问题的 cases 不太可能是统一困难的。在GP中,训练 case 的难度可以认为是任意程序求解该案例的概率。在任意程序不统一求解训练 case 的假设下,对于一个GP程序种群,训练 case 不太可能是统一困难的。因此,如果能够通过识别在问题较难的部分表现良好的个体来考虑特定案例的难度,搜索很可能会受益。这最后一点的基础是假设GP通过识别、传播和重组手头任务 (Poli and Langdon, 1998) 的部分解(即积木)来解决问题。因此,在问题的唯一子集上表现良好的程序可能包含我们任务的部分解决方案。
已经提出了几种方法来奖励具有独特良好训练表现的个体,例如隐式适应度共享 (IFS) (McKay, 2001)、historically assessed hardness (Klein and Spector, 2008) 和 co-solvability (Krawiec and Lichocki, 2010),所有这些方法都为根据种群表现被判断为更困难的适应度 case 分配了更大的权重。也许最有效的考虑 case hardness 的父代选择方法是案例选择 lexicase selection (Spector, 2012)。特别地,“全局池、均匀随机序列、elitist lexicase selection” (Spector, 2012),我们简称为 lexicase selection,在最近的研究 (Helmuth et al., 2014; Helmuth and Spector, 2015; Liskowski et al., 2015) 中超过了其他类似动机的方法。尽管有这些收获,但由于其基于训练 case 精英选择个体的方法,在应用于连续型符号回归问题时未能产生这样的好处。为此,我们最近提出了(La Cava et al., 2016),通过自动定义的阈值来调节 lexicase selection 中的案例通过条件,从而使 lexicase selection 的好处在连续域中实现。
迄今为止,对 lexicase selection 和 ϵ \epsilon ϵ- lexicase selection 的分析大多是通过实证研究,而非算法分析。特别地,之前的工作并没有明确地描述与其他选择方法相比,lexicase selection 下的选择概率,也没有 lexicase selection 如何与多目标文献联系起来。因此,与其他方法相比,本文的首要目的是解析地描述在给定的群体中,lexicase selection 和 ϵ \epsilon ϵ- lexicase selection 是如何运作的。考虑到这一点,在 §3.1 中我们推导了一个方程,它描述了给定种群中的个体期望选择概率基于他们的 training cases 的行为。 对于这里描述的 lexicase selection 的所有变体。然后在 §3.2 中,我们从多目标的角度分析 lexicase 和 ϵ \epsilon ϵ-lexicase selection ,其中我们认为每个 training case 都是一个目标。我们证明了在由程序错误向量定义的 Pareto 前沿的边界上,通过局部选择选出的个体是存在的。我们通过 §SM 1 中的一个示例种群展示了 tournament 、lexicase 和 ϵ \epsilon ϵ-lexicase selection 下选择概率的差异。
本文的第二个目的是实证评估 ϵ \epsilon ϵ-lexicase selection 在符号回归任务中的使用。在 §2.3 中,我们定义了 ϵ \epsilon ϵ-lexicase selection 的两个新的变体:semi-dynamic and dynamic,与原来的静态实现相比,这两个变体被证明可以改进方法。一组实验在一组真实世界的基准问题上将 ϵ \epsilon ϵ-lexicase selection 的变体与现有的几种选择技术进行了比较。结果表明 ϵ \epsilon ϵ-lexicase selection 能够提高模型对这些问题的预测精度。我们详细研究了这些运行期间程序的多样性,以及选择事件中使用的 case 数量,以验证我们的假设,即与 lexicase selection 相比, ϵ \epsilon ϵ-lexicase selection 选择允许在选择个体时使用更多的 case。最后,实验分析了 lexicase selection 的时间复杂度是种群规模的函数。
2 Methods
2.1 Preliminaries
在符号回归中,我们试图通过一组 T 个训练样本
T
=
{
t
i
=
(
y
i
,
x
i
)
}
i
=
1
T
T = \{t_i = ( y_i , x_i)\}^T_{i = 1}
T={ti=(yi,xi)}i=1T 找到一个将变量映射到目标输出的模型
(
y
^
(
x
)
:
R
d
→
R
)
(\hat{y}(x):\Bbb{R}^d→\Bbb{R})
(y^(x):Rd→R),其中 x 是变量的 d 维向量,即特征,y 是期望输出。我们把 T 的元素称为 “case”。GP 提出了这个问题
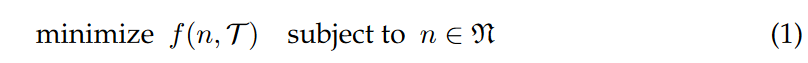
其中
N
\mathfrak{N}
N 是可能方案
n
n
n 的空间,
f
f
f 是极小化的适应度函数. GP 试图通过优化 N 个程序
N
=
n
i
i
=
1
N
N = { n_i }^N_{i = 1}
N=nii=1N 的种群来解决符号回归任务,每个程序编码过程的一个模型,并在 case t 评估时产生一个估计
(
y
^
t
(
n
,
x
t
)
:
R
d
→
R
)
(\hat{y}_t( n , x_t):\Bbb{R}^d→\Bbb{R})
(y^t(n,xt):Rd→R)。我们称
y
^
(
n
)
\hat{y}(n)
y^(n) 为程序
n
n
n 的语义,为了简洁省略 x。记
(
y
^
(\hat{y}
(y^ 与
y
y
y 的平方差(即,错误)为
e
t
(
n
)
=
(
y
t
−
(
y
^
t
(
n
)
)
)
2
e_t(n) = (y_t - (\hat{y}_t(n)))^2
et(n)=(yt−(y^t(n)))2。我们用
e
t
∈
R
N
e_t∈\Bbb{R}^N
et∈RN 表示种群中所有程序在训练样本 t 上的错误。
e
t
e_t
et 中的最低误差称为
e
t
∗
e_t^*
et∗。
一个典型的适应度度量 (f) 是均方误差 M S E ( n , T ) = 1 N ∑ t ∈ T e t ( n ) MSE(n, T) = \frac{1}{N}∑_{t∈T} e_t ( n ) MSE(n,T)=N1∑t∈Tet(n),我们用它来比较 §4.1.1 的结果。在我们的讨论中,MSE 或平均绝对误差,即是不相关的。使用 M A E ( n , T ) = 1 N ∑ t ∈ T ∣ y t − ( y ^ t ( n ) ∣ MAE( n , T) = \frac{1}{N}∑_{t∈T} |y_t - (\hat{y}_t ( n ) | MAE(n,T)=N1∑t∈T∣yt−(y^t(n)∣,因此我们使用 MAE 来简化整个文章中的几个例子。在 lexicase selection 及其变体中, e ( n ) e(n) e(n) 在选择过程中直接使用,而不是在个案中平均。然而,与方程 1 中的问题表述一致。我们实验返回的最终程序是使 MSE 最小的程序
2.2 Lexicase Selection
Lexicase Selection 是一种基于 training cases (i.e. fitness) 字典排序的父代选择技术。单个选择事件的 lexicase selection 算法如算法 1 所示。

算法 1 只包含几个步骤:
- 选择一个 case,
- 基于该 case 过滤选择池,
- 重复直到 case 耗尽或者选择池减少为一个个体。如果选择池不随每个 case 被考虑的时间而减少,则从剩余池中随机选择一个个体 S S S。
在 lexicase 选择下, τ \tau τ 中的 cases 可以被认为是过滤器,将选择池缩小为该 case 中最好的个体。每个 parent selection event 通过这些过滤器构建新的路径。如果在考虑 case 时某个体仍然被留在选择池中。,我们将个体称为 “passing” case,a case 的滤波强度主要受两个因素的影响:其难度由 case 从选择池中筛选出的个体数量定义。并且它在 selection event 中的顺序,因选择而异。在 lexicase selection 中这两个因素交织在一起,共同决定了一个案例的选择,因为 a case 对它之前的一个随机序列产生的一个子集种群进行过滤。换言之,a case 的难易程度不仅取决于问题定义,还取决于 the case 在 selection event 中的排序,每次选择都是随机的。
随机的 case 顺序和过滤机制允许选择性压力不断转移到在 N N N 中很少解决的 case 上的精英个体。由于 case 在选择过程中以不同的顺序出现,个体在解决 case 的独特子集时存在选择性压力。因此,Lexicase selection 解释了单个 case 的困难以及解决任意大小的 case 子集的困难。这种选择压力导致进化过程中保持了较高的行为多样性. ∣ τ ∣ = T | \tau | = T ∣τ∣=T 个测试用例每代选择 N N N 个父代的最坏情况复杂度为 O ( T N 2 ) O(TN^2) O(TN2)。这种运行时间源于这样一个事实,即为了选择单个个体,在选择测试用例时可能需要考虑每个个体在每个测试用例上的误差值。相比之下,锦标赛选择只需要考虑一个恒定规模的个体数的预计算的 fitness。因此选择单个父代可以在恒定的时间内完成。由于每个个体上的每个测试用例都需要计算误差并求和,因此锦标赛选择需要 O ( T N ) O(TN) O(TN) 时间来选择 N N N 个父代。通常情况下,由于群体间的性能差异,以及 lexicase selection 倾向于促进多样性,一个 lexicase selection event 将使用比 T T T 更少的测试用例;选择池通常小于 N N N,这意味着实际运行时间往往优于最坏情况下的复杂度.
我们使用一个最初出现在(斯佩克特, 2012)中的示例种群来说明下面几节中 standard lexicase selection 的一些方面。种群由 5 个个体和 4 个具有离散误差的训练 case 组成,如表 1 所示。针对这个例子,在图 1 中给出了选择过滤机制的一个图形例子。每个 lexicase selection event 可以可视化为一个随机深度优先遍历的训练案例。图 1 展示了三个导致不同个体被选择的示例 selection event 。种群在每个情况下被绞向精英,直到单个个体被选择,用菱形节点表示。

图 1 中案例解释:对于 5 个个体,4 个 训练 case,每个个体程序可以通过 4 个 case 计算出 4 个估计值,利用真实值与估计值计算误差 e t e_t et,即表 1 所示,通过不同的路径选择最低的 e t e_t et。选择个体的过程:选择不同的个体程序,选择不同的列误差,都不同。
如图 1 中的(1),首先观察 e 1 e_1 e1 列对应 t 1 t_1 t1,选出 5 个个体对应最低的误差值。即 n 4 , n 5 n_4, n_5 n4,n5,再观察 e 3 e_3 e3 列, n 4 , n 5 n_4, n_5 n4,n5 相同,均被选择,再观察 e 2 e_2 e2,选出误差值最少的 n 4 n_4 n4.
图 1 中的(2),首先看 e 3 e_3 e3 列对应 t 3 t_3 t3, n 3 n_3 n3 误差最小,直接选出
图 1 中的(3),首先看 e 4 e_4 e4 列对应 t 4 t_4 t4, 选出 n 1 , n 5 n_1, n_5 n1,n5,再看 e 3 e_3 e3 列对应 t 3 t_3 t3,选出 n 1 n_1 n1
2.3 ϵ \epsilon ϵ-Lexicase Selection
在离散误差空间中,Lexicase selection 已被证明是有效的,这两种方法都适用于多模态问题,而对于每一个 case 都必须解决的问题恰好被认为是一个解决方案,然而,在连续误差空间中,要求个体恰好等于选择池中的 elite error 才能通过一个 case 的要求被证明是过于严格的,在连续的误差空间中,特别是对于含噪数据的符号回归,除非是(或减少为)等价模型,否则两个个体在任何训练情况下都不可能有完全相同的误差。因此,lexicase selection 倾向于基于 single cases 进行选择,对于所选择的个体满足 e t ≡ e t ∗ e_t \equiv e_t^* et≡et∗, 即 N N N 中关于 t t t 的最小误差。single cases 选择限制了 lexicase 有效利用测试用例子集上的 case 信息的能力,并且可能导致比传统选择方法更差的性能
这些观察导致了 ϵ \epsilon ϵ-Lexicase Selection 的发展,它通过对每个训练样本计算 ϵ \epsilon ϵ 阈值标准来调节 case 过滤。提出并测试了 ϵ \epsilon ϵ 的手动调谐和自动变体,最佳性能是由 “parameter-less” 版本实现的,该版本使用中位数绝对偏差统计量,根据每个训练 case 中总体误差的离散度定义 ϵ \epsilon ϵ :
ϵ t = λ ( e t ) = median ( ∣ e t − median ( e t ) ∣ ) (2) \epsilon_t = \lambda(e_t) = \text{median}(|e_t - \text{median}(e_t)|) \tag{2} ϵt=λ(et)=median(∣et−median(et)∣)(2)
根据 Eqn. 2 定义 ϵ \epsilon ϵ,可以使阈值符合每个训练情况下总体的表现。随着每个训练 case 在总体上的表现提高, ϵ \epsilon ϵ 会缩小,从而根据 case 的难度来调节它的选择性。我们选择绝对偏差中位数来代替标准差统计量来计算 ϵ \epsilon ϵ ,因为它对离群值更稳健 (Pham-Gia andHung, 2001)。
在本文中,我们研究了 ϵ \epsilon ϵ-Lexicase Selection 的三种实现:
- static,这是最初提出的版本(La Cava et al., 2016);
- semi-dynamic,其中 elite error 是相对于当前选择池定义的;
- dynamic,其中 elite error 和 ϵ \epsilon ϵ 都是相对于当前选择池定义的。
Static
ϵ
\epsilon
ϵ-lexicase selection 可以被视为添加到 lexicase selection 的预处理步骤,其中个体程序的 error 根据
ϵ
\epsilon
ϵ 阈值转换为 pass/fail。这个阈值是相对于
e
t
∗
e_t^*
et∗ 定义的,
e
t
∗
e_t^*
et∗ 是测试用例 case
t
t
t 在整个总体上的最低误差。我们称之为 static
ϵ
\epsilon
ϵ-lexicase selection,因为 elite error
e
t
∗
e_t^*
et∗ 和
ϵ
\epsilon
ϵ 每代只计算一次,而不是相对于当前的选择池,如算法 2 所述。


Semi-dynamic
ϵ
\epsilon
ϵ-lexicase selection 与 static
ϵ
\epsilon
ϵ-lexicase selection 的不同之处在于,pass 条件是相对于池中的最佳误差来定义的,而不是全局种群中的所有个体
N
N
N,这样它的表现更类似于标准的 lexicase-selection (Algorithim 1 ),除非个体的误差大于
e
t
∗
+
ϵ
t
e_t^* + \epsilon_t
et∗+ϵt 才会被过滤掉。它在 Algorithm 3 中定义。


ϵ
\epsilon
ϵ-lexicase selection 的最终变体是 dynamic
ϵ
\epsilon
ϵ-lexicase selection ,其中 error 和
ϵ
\epsilon
ϵ 都定义在当前选择池中。在这种情况下,
ϵ
\epsilon
ϵ 定义为:
ϵ
t
(
S
)
=
median
(
∣
e
t
(
S
)
−
median
(
e
t
(
S
)
)
∣
)
=
λ
(
e
t
(
S
)
)
(3)
\epsilon_t(S) = \text{median}(|e_t(S) - \text{median}(e_t(S))|) = \lambda(e_t(S)) \tag{3}
ϵt(S)=median(∣et(S)−median(et(S))∣)=λ(et(S))(3)
其中, e t ( S ) e_t(S) et(S) 是当前选择池 S S S 中关于 case t t t 的 error 向量。Algorithm 4 给出了 dynamic ϵ \epsilon ϵ-lexicase selection。

对于单个测试 case,根据 式 2 计算
ϵ
\epsilon
ϵ 的时间复杂度为
O
(
N
)
O( N )
O(N),3 种
ϵ
\epsilon
ϵ-lexicase selection 算法选择
N
N
N 个父代的最坏情况复杂度均为
O
(
T
N
2
)
O( TN^2)
O(TN2),。正如
§
§
§ 2.2 所讨论的,这些最坏情况下的时间复杂度基本不会出现。并且实证结果证实了
ϵ
\epsilon
ϵ-lexicase 运行在与锦标赛选择( La Cava等, 2016)相同的时间框架内。我们评估了
§
§
§ SM 2 中种群大小对 wall-clock times 的影响。
2.4 Related Work
lexicase selection 属于一类搜索驱动,它将程序的全部语义直接纳入搜索过程,因此与语义GP方法具有共同的动机。几何语义 GP (Moraglio et al , 2012)通过定义在语义空间中执行步骤的变异和交叉算子,在变异步骤中使用程序的语义。中间程序语义也可以被利用,如 Behavioral GP (Krawiec and O’Reilly, 2014) 所示,它使用程序执行轨迹来构建程序构建块的存档并学习中间概念。与 lexicase选 择不同,Behavioral GP 一般利用中间程序语义,而不是中间 fitness cases 来指导搜索。这些相关的语义GP方法在搜索过程的其他步骤利用程序语义的同时,倾向于使用既定的选择方法。
而不是融入完整的语义,另一种选择是通过基于种群性能 (McKay, 2001) 的加权训练样本来改变适应度度量。例如,在非二进制隐式适应度共享(IFS)(Krawiec and Nawrocki, 2013) 中,一个 case 的适应度比例由其他个体在该案例上的表现来衡量。类似地,历史上通过种群 (Klein and Spector, 2008) 的成功率评估每个 training case 的 hardness scales error。这些方法能够捕捉到 fitness case difficulty 的单变量概念,但与 lexicase selection 不同,在估算难度时没有考虑 cases 之间的相互作用。
通过聚类发现目标 (DOC) (Krawiec and Liskowski, 2015) 通过种群性能对 training cases 进行聚类,从而将 training cases 缩减为一组用于多目标优化的目标。在先前的研究 (Helmuth and Spector, 2015; Liskowski et al., 2015). 中,IFS 和 DOC 在程序综合和布尔问题上的表现均优于 lexicase selection。最近,Liskowski and Krawiec (2017) 提出了将 DOC 和相关客观推导方法与 ϵ \epsilon ϵ-lexicase selection 相结合的混合技术,并且发现这种组合在符号回归问题上展现很好。
其他方法尝试对 T 的子集进行采样以减少计算时间或提高性能,如动态子集选择 (Gathercole and Ross, 1994) 、交错采样 (Gon ̧ calves and Silva, 2013) 、协同进化适应度预测器 (Schmidt and Lipson, 2008) 等。与这些方法不同的是,lexicase selection 从每一个选择开始都有全套的 training cases,并允许选择适应它们上的程序性能。另一种根据群体表现调整选择压力的方法是自动调整锦标赛选择,Xie and Zhang (2013) 对此进行了研究。在这项工作中,锦标赛选择压力被调整为对应于 population 中 fitness ranks 的分布。
尽管多目标优化的思想在一定程度上适用于多个 training cases,但它们在质上是不同的,通常在不同的尺度下运行。符号回归往往涉及一个或两个目标(例如准确性和模型简洁性)和成百上千的 training cases 。在 Langdon (1995) 中出现了一个明确使用 training cases 作为目标的例子,其中少量的 training cases (在这种情况下 6)被用作帕累托选择方案中的多个目标。其他的多目标方法如 NSGA-II (Deb et al., 2002),,SPEA2(Zitzler et al., 2001) 和 ParetoGP(Smits and Kotanchek, 2005) 在符号回归中通常使用较小的目标集。 “curse of dimensionality” 使得在典型训练案例规模下的目标使用存在问题,因为大多数个体成为非支配个体。Ishibuchi et al. (2008) 回顾了高维多目标优化中的尺度问题,Li et al. (2015) 对其进行了综述。为了处理大量的目标,已经提出了一些方法,包括基于超体积的方法如 HypE,参考点方法如NSGA-III,问题分解方法如 MOEA 和 MOEA/D (Chand and Wagner, 2015). Li et al. (2017) 在多达100个目标的问题上对多个参考点方法进行了基准测试,进一步缩小了可扩展性差距。在 §3.2 中,深入探索了 lexicase selection 与多目标方法的联系。
基于阈值将模型的实值适应度值转换为离散值的方法在其他研究中已有探索;例如,Novelty Search GP (Martínez et al , 2013) 使用减少的误差向量来定义种群中个体的行为表示。La Cava et al (2016) 首次将其作为一种解决方法,将 lexicase selection 有效地应用到回归中,采用 static ϵ \epsilon ϵ-lexicase selection(算法2 )。
最近的工作对 lexicase selection 进行了实证研究和扩展。 Helmuth et al. (2016b) 发现,lexicase selection 中的极端选择事件对其性能提升并不重要, lexicase selection 可以使多样性较低的种群重新多样化,而不是锦标赛选择 (Helmuth et al., 2016a) 。为了在集成学习环境中保持不相关的种群,还提出了一种基于生存的 ϵ \epsilon ϵ-lexicase selection 版本 (La Cava and Moore, 2017a,b)
4 Experimental Analysis
在这一部分,我们在一组回归基准上测试了几种父代选择策略。在补充材料中,我们提供了一个示例,详细说明了给定种群的选择及其语义( §SM 1 )。我们也提供了量化不同选择策略下种群规模对 wall-clock 运行时间影响的缩放实验 (§SM 2)。这些实验的代码可在线获得:https://github.com/lacava/epsilon_lexicase
4.1 Regression Experiments
我们对 §2.3 中介绍的
ϵ
\epsilon
ϵ-lexicase selection 的每个变体进行实证检验。本部分研究的问题列于表 2。我们使用 8 个不同的数据集对 9 种方法进行了测试。其中 6 个问题可从 UCI 知识库(Lichman , 2013)获得。UBall5D 问题是一个具有形式的模拟方程2
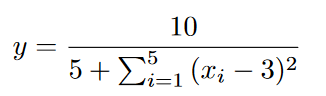
- 2UBall5D is also known as Vladislavleva-4.
Tower 问题和 UBall5D 选自 White 等 (2012)提出的基准测试集。
我们比较了 8 种不同的选择方法:random selection、tournament selection、lexicase selection、age-fitness pareto optimization (Schmidt and Lipson, 2011)、deterministic crowding (Mahfoud, 1995),以及 §2.3 中的 3 种 ϵ \epsilon ϵ-lexicase selection 方法。除了基准的选择方法之外,我们还包括使用 Lasso (Tibshirani, 1996) 进行正则化线性回归的比较。下面简要介绍这些方法,以及它们在结果中使用的缩写。
- 随机选择(rand):父母的选择是均匀随机的。
- 锦标赛选择(Tourn):大小两个锦标赛进行选择父母。
- Lexicase Selection (lex): see Algorithm 1.
- Age-fitness Pareto optimization (afp):该方法每一代引入一个年龄为 0 的新个体。每一代,个体被分配一个年龄等于他们最古老的祖先进入种群的世代数。随机选择父母,产生 N 个子女。然后,孩子和父母在规模为 2 的生存锦标赛中竞争,在这个锦标赛中,如果一个人在年龄和健康方面被其竞争者所控制,那么他就被从种群中剔除。
- Deterministic crowding (dc): 采用这种小生境方法的一种世代形式,随机选择父母进行变异,孩子竞争替换与其最相似的父母。相似性是根据父方程形式的 Levenshtein 距离来确定的,使用一个通用符号表示系数。只有当一个孩子的体质较好时,该孩子才会在种群中替代父代。
- Static ϵ \epsilon ϵ-lexicase selection (ep-lex-s): See Algorithm 2.
- Semi-dynamic ϵ \epsilon ϵ-lexicase selection (ep-lex-sd): See Algorithm 3.
- Dynamic ϵ \epsilon ϵ-lexicase selection (ep-lex-d): See Algorithm 4.
- Lasso (lasso): 该方法使用模型系数的 ℓ 1 \ell_1 ℓ1 测度将正则化惩罚融入到最小二乘回归中,并使用调节参数λ指定该正则化的权重。我们使用 Lasso 的最小角度回归 (Efron等, 2004) 实现,通过交叉验证自动选择 λ
GP system 3 的设置如表 3 所示。我们通过在随机划分的 70% 的数据集上进行训练,并在另外 30% 的数据集上比较每种方法的最佳模型的预测误差,对每种方法进行 50 次试验。除了测试误差之外,我们还比较了基于 GP 方法的训练收敛性、运行过程中种群的语义多样性以及用于选择 lexicase 方法的案例数。我们将种群多样性计算为种群中唯一语义的分数。为了比较 lexicase 法选择事件所用的案例数,我们保存了选择事件所用案例数的中位数,即每代案例深度。
- 3 available from https://github.com/cavalab/ellyn

4.1.1 Regression Results
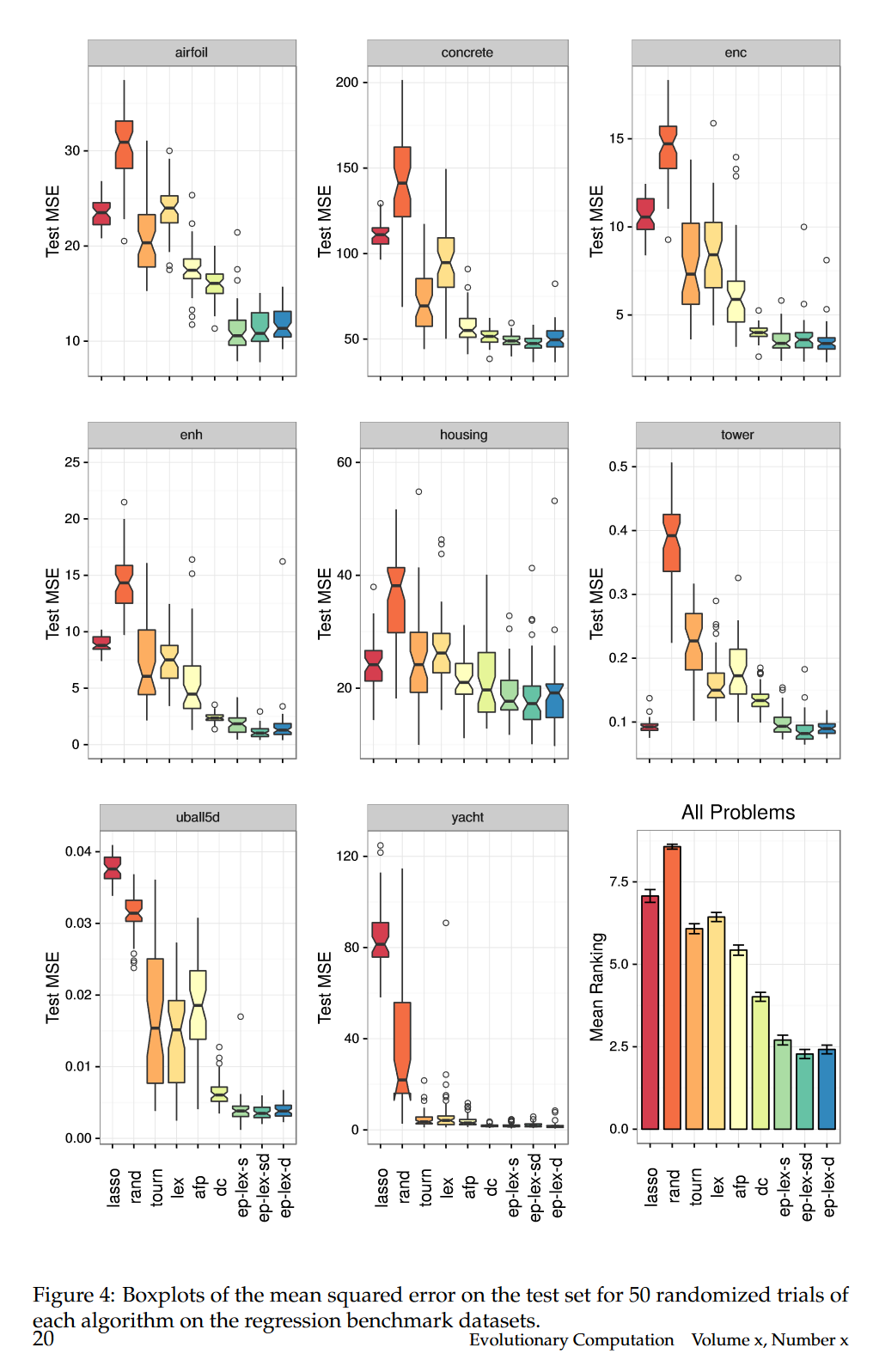
图 4 中的箱线图显示了每种方法在每个问题上的测试集 MSE。在最后的子图中,我们总结了方法在每个问题的每个试次上的平均排名,以给出性能的一般比较。为每个试验计算排名,然后对所有试验和问题进行平均,以给出总体排名比较。总的来说,我们发现
ϵ
\epsilon
ϵ-lexicase selection 方法在测试问题中产生了具有最佳泛化性能的模型。Random selection 和 Lasso 在这些问题上往往表现最差。值得注意的是 Lasso 在 Tower 问题上的表现优于其他数据集上的表现;ep-lex-sd 和 ep-lex-d 是唯一显著优于它的 GP 变体。对于每一个问题,
ϵ
\epsilon
ϵ-lexicase selection 的一个变体表现最好,它的三个变体表现趋于一致。与之前的结果 (La Cava et al., 2016) 一致,对于这些连续值问题,lexicase selection 的表现要差于锦标赛选择。与之前的研究结果 (Schmidt and Lipson, 2011) 相比,虽然两种方法的表现都优于锦标赛选择,但是 dc 的表现优于 afp。
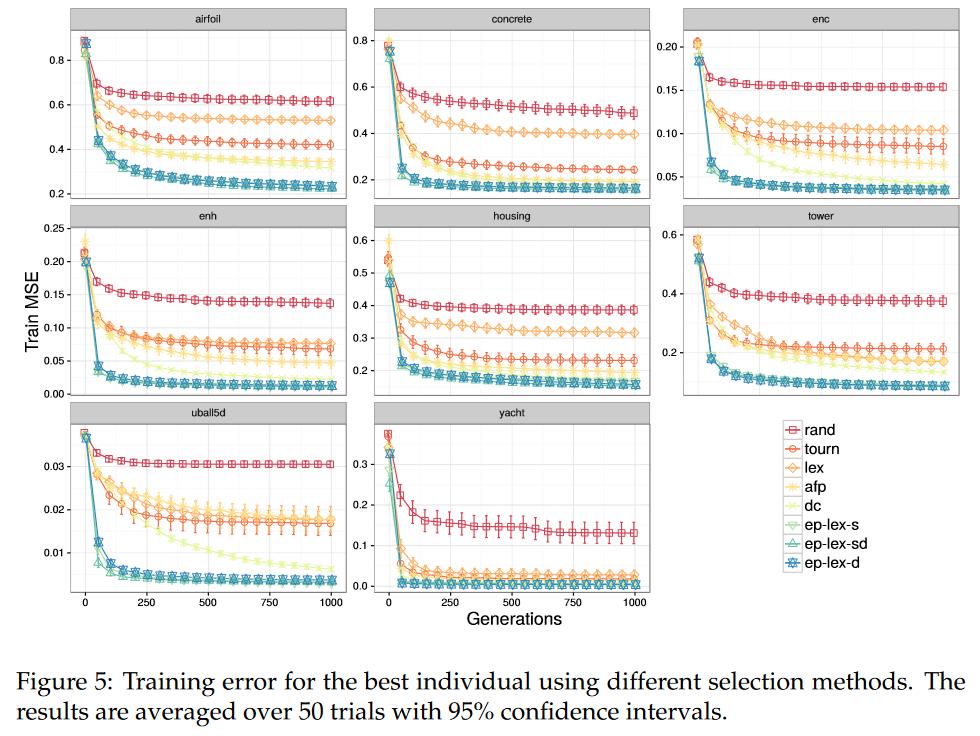
如图 5 所示,与所有其他方法相比, ϵ \epsilon ϵ-lexicase 方法在更少的代数内收敛到一个较低的训练误差上表现出明显的优势。
Note Figure 5 报告了每一代种群中最佳个体在训练集上的归一化 MSE 值。我们再次观察到
ϵ
\epsilon
ϵ-lexicase selection 变体之间的差异很小。
我们分析了 Tables 4 and 5 中检验 MSE 结果的统计显著性。Tables 4 给出了各方法相对于 ep-lex-sd 的两两 Wilcoxon 秩和检验。ep-lex-sd 和所有 non-
ϵ
\epsilon
ϵ-lexicase方法在所有问题上的性能都有显著差异,除了在 housing 和 tower 数据集上与 dc 的比较。所有问题的方法排名的方差分析表明(p < 2e-16) 存在显著差异。Table 5 所示的事后统计分析表明,这种差异是由于 ep-lex-sd 和 ep-lex-d 在所有问题上的排名在两两比较中与所有其他非排序方法存在显著差异。根据本试验,
ϵ
\epsilon
ϵ-lexicase的三个变体之间没有显著差异。
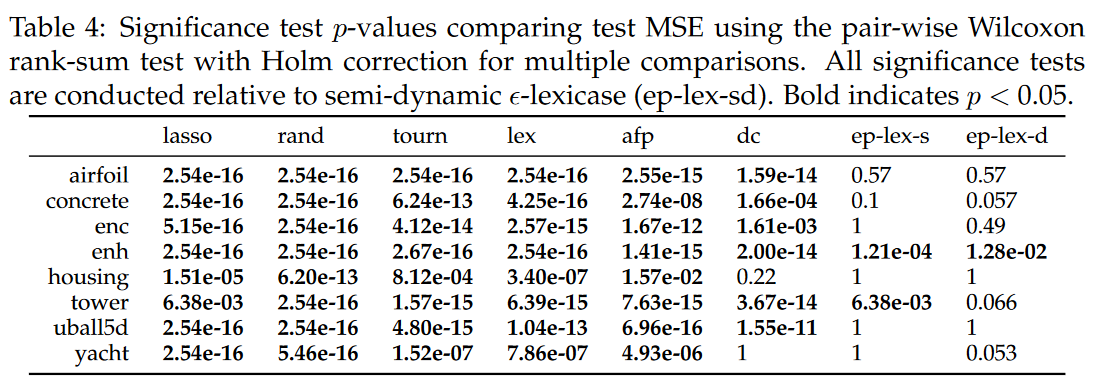
- Table 4:显著性检验p值比较采用配对Wilcoxon秩和检验,多重比较采用Holm校正。所有的显著性检验都是相对于半动态词典( ep-lex-sd )进行的。Bold表示p < 0.05。
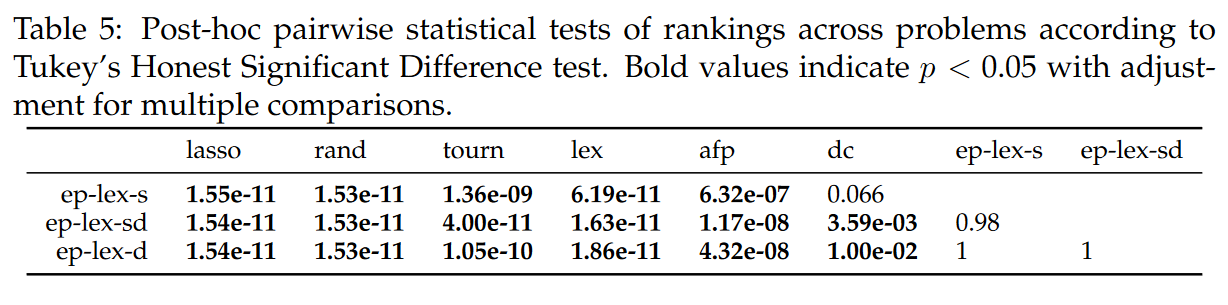
- Table 5: 根据Tukey ’ s Honest显著性差异检验对问题间的排名进行事后两两统计检验。Bold值表示p < 0.05,多重比较校正
图 6 显示了使用不同选择方法的各代群体的语义多样性,
ϵ
\epsilon
ϵ-lexicase 变体、dc 和 lexicase 选择都产生了最高的群体多样性,这是由于它们的多样性维持设计。有趣的是,它们都产生了比随机选择更多样的语义,这表明保留有用的多样性是观察到的性能改进的一个重要特征。令人惊讶的是,afp 被发现产生低语义多样性,尽管它结合了年龄和随机重启每一代。鉴于afp没有明确的语义多样性机制,在这些问题上,年龄可能不是行为多样性的充分替代。
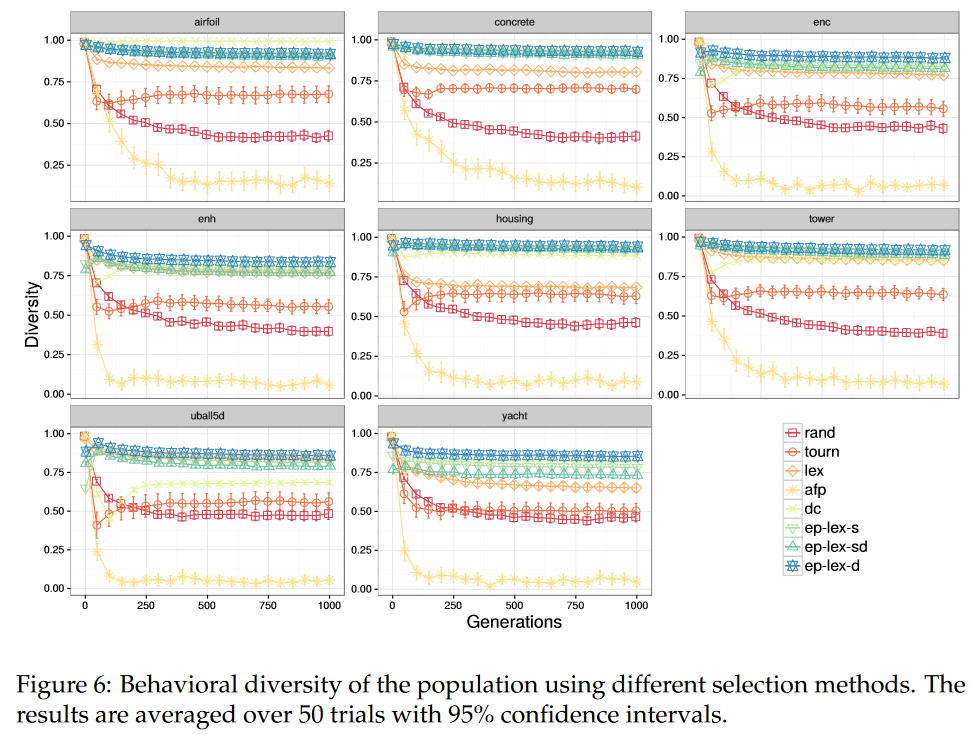
- 图 6:采用不同选择方式的种群行为多样性。结果以 95% 的置信区间平均超过 50 个试验。
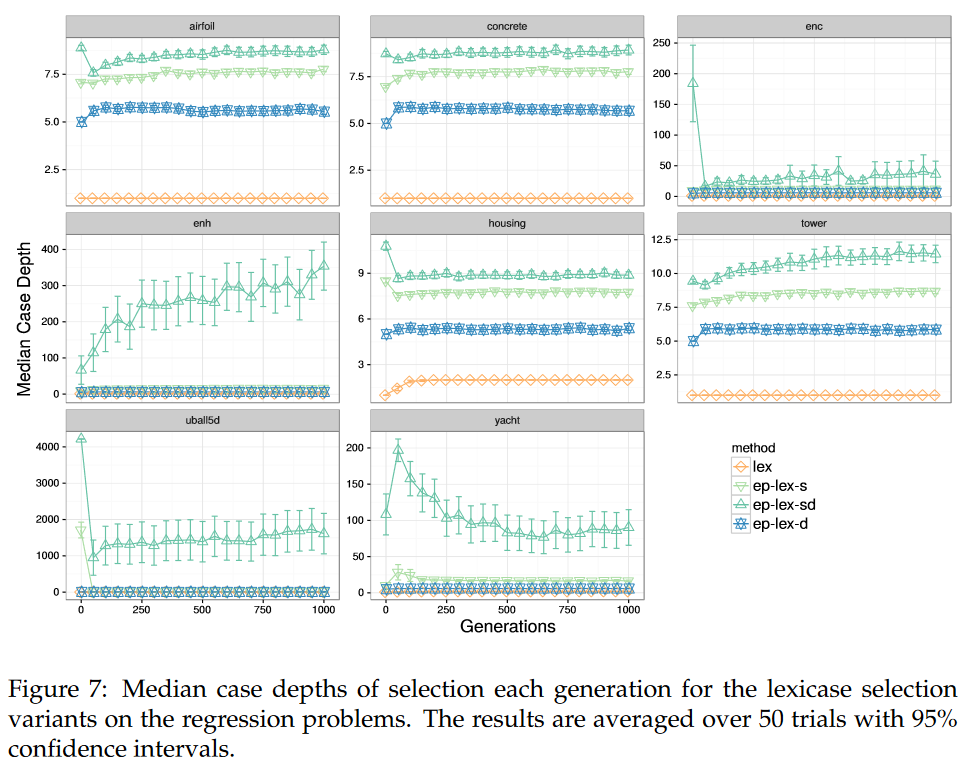
在这些问题上寻求行为多样性。将
ϵ
\epsilon
ϵ 阈值引入 lexicase selection 的动机之一是允许选择在选择父代时利用连续域中更多的 cases。图 7 表明
ϵ
\epsilon
ϵ-lexicase 方法实现了这一目标。正如我们在 §2.3 开头所指出的,在连续域中,每个选择事件可能只使用一个 case,导致性能不佳。我们在中位深度测量中观察到了这一现象。在
ϵ
\epsilon
ϵ-lexicase 变体中,ep-lex-sd 使用的情况最多,其次是 ep-lex-s 和 ep-lex-d。从直觉上讲,这个结果是有意义的:在整个种群中计算时很可能是最大的,并且由于 ep-lex-sd 使用了全局
ϵ
\epsilon
ϵ (式( 2)) 和一个局部误差阈值,所以很可能在每个情况下都保留了最多的个体。这些结果也表明,在 ep-lex-d 中每一个事例(式(3)) 之后的池子之间计算时,都会出现大幅度的收缩。
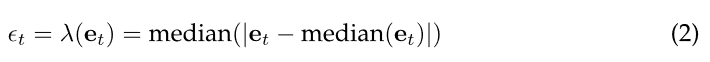
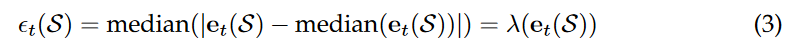
5 Discussion
实验结果表明,与其他GP方法和Lasso相比, ϵ \epsilon ϵ-lexicase selection 在符号回归问题上表现良好。与其他 GP 方法相比, ϵ \epsilon ϵ-lexicase 在训练集上学习更快 (图 5),在测试集上表现更好(图 4 )。与传统选择方法相比,性能的提高似乎与 ϵ \epsilon ϵ-lexicase selection 在整个训练过程中保持较高的语义多样性有关 (图 6 ),它保留了在训练案例中独特部分表现良好的个体。 ϵ \epsilon ϵ-lexicase selection 比 lexicase selection 对这些连续值问题有分类的改进。虽然 lexicase selection 也保持了多样化的语义,但其较差的性能可以解释为其对用于选择的训练样本的利用不足(图 7 )以及其仅在严格精英个体中选择的特性(见§ SM 1的例子),通过在 ϵ \epsilon ϵ-lexicase selection 中引入阈值而放松的特性
在我们的实验中,两种新的
ϵ
\epsilon
ϵ-lexicase selection 变体,semi-dynamic and dynamic 在整体上表现最好。然而,
ϵ
\epsilon
ϵ-lexicase 的变体在所有测试问题中并没有显著差异,这表明该方法的基础对不同的定义是稳健的,只要它们导致在选择过程中使用的案例信息高于普通的 lexicase selection,这在回归问题上表现不佳。鉴于结果,我们建议 semi-dynamic -lexicase (eplex-sd, Algorithm 3) 作为
ϵ
\epsilon
ϵ-lexicase selection 的默认实现,因为它具有最低的平均测试排名,并且根据图 7 显示它使用了最多的案例信息。
ϵ
\epsilon
ϵ-lexicase selection 是一个全局池、均匀随机序列、非精英版本的lexicase selection (Spector, 2012)。与传统的 “精英主义” lexicase selection 相比,
ϵ
\epsilon
ϵ-lexicase selection 代表了一种宽松的 lexicase selection;其他潜在的放松可以显示出类似的好处。“全局池” 是指每个选择事件从整个种群开始;然而,较小的池,也许是在地理上定义的 (Spector and Klein, 2006),可以在某些问题上提高性能,这些问题可以很好地响应宽松的选择压力。未来的工作还可以考虑测试用例的替代性排序,这些排序可能比迄今为止工作的重点 “均匀随机序列” 排序表现更好。Liskowski et al. (2015) 尝试使用派生目标群作为 lexicase selection 的 cases,但发现这实际上降低了性能,可能是由于产生的目标数量较少。Burks and Punch (2016) 发现在绩效方面有偏的 case 排序产生了混合结果。尽管如此,仍可能存在一种排序或案例缩减的形式提高了 lexicase selection 在随机洗牌中的表现。
产生给定父实例的训练实例的排序也包含了GP中的搜索算子可以使用的关于父实例的潜在有用信息。Helmuth and Spector (2015) 观察到,在种群(图 6 支持的观察)中,lexicase selection 产生了大量不同的行为集群。在这方面,它可能是有利的,例如,对通过不同案例顺序选择的个体进行交叉,使其后代更有可能继承给定任务的具有唯一部分解的子程序。最近的工作强调了语义多样化的父代在几何语义GP (Chen et al., 2017). 中进行几何语义交叉时的有用性。
基于 §3.1 中的观察,当训练集远大于种群规模时,某些情况下很可能会闲置。在这些场景中,当方案出现在选择事件中时,对方案进行惰性评价,可能有利于减少方案评价。事实上,Eqn.5 可以作为判断惰性评价策略何时会导致显著计算节省的指导。
需要指出的是,目前实验分析的局限性。首先,我们没有考虑GP系统的超参数调节,这也是我们在以后的工作中打算追求的。此外,非GP回归比较仅限于 Lasso。在未来的工作中,我们打算与更广泛的一类学习算法进行比较。最后,我们仅在 GP 应用于符号回归的情形下考虑了 lexicase 和 ϵ \epsilon ϵ-lexicase 选择问题。未来的工作应该考虑将这些选择方法应用到 EC 的其他领域,以及将这些算法用于其他学习任务。
6 Conclusions
在本文中,我们给出了一个关于 lexicase 选择和 ϵ \epsilon ϵ-lexicase 选择的概率和多目标分析。我们给出了 lexicase 选择变体下的期望选择概率,并展示了种群规模和训练集规模对选择概率的影响。首次分析了 lexicase 选择与多目标优化的联系,表明在种群误差所张成的高维空间中,通过 lexicase 选择选出的个体占据了Pareto前沿的边界或近边界。
此外,我们在一组真实世界和合成符号回归问题上实验验证了 ϵ \epsilon ϵ-lexicase 选择,包括新的半动态和动态变体。结果表明, ϵ \epsilon ϵ-lexicase 选择显著提高了 GP 寻找精确模型的能力。对这些游程的进一步分析表明,在进化过程中,同义词变体保持了异常高的多样性,同义词变体比标准同义词选择考虑了更多的每个选择事件。研究结果验证了我们为连续域创建这种lexicase 变体的动机,并建议在相似域中采用 lexicase 选择及其变体。
Reference
La Cava W, Helmuth T, Spector L, et al. A probabilistic and multi-objective analysis of lexicase selection and ε-lexicase selection[J]. Evolutionary Computation, 2019.
总结: 2019,EC, A probabilistic and multi-objective analysis of lexicase selection and ε-lexicase selection
原文地址: 点击跳转
Lexicase Selection
Lexicase Selection 是一种基于 training cases (i.e. fitness) 字典排序的父代选择技术。单个选择事件的 lexicase selection 算法如算法 1 所示。
图示案例
图 1 中案例解释:对于 5 个个体,4 个 训练 case,每个个体程序可以通过 4 个 case 计算出 4 个估计值,利用真实值与估计值计算误差 e t e_t et,即表 1 所示,通过不同的路径选择最低的 e t e_t et。选择个体的过程:选择不同的个体程序,选择不同的列误差,都不同。
如图 1 中的(1),首先观察 e 1 e_1 e1 列对应 t 1 t_1 t1,选出 5 个个体对应最低的误差值。即 n 4 , n 5 n_4, n_5 n4,n5,再观察 e 3 e_3 e3 列, n 4 , n 5 n_4, n_5 n4,n5 相同,均被选择,再观察 e 2 e_2 e2,选出误差值最少的 n 4 n_4 n4.
图 1 中的(2),首先看 e 3 e_3 e3 列对应 t 3 t_3 t3, n 3 n_3 n3 误差最小,直接选出
图 1 中的(3),首先看 e 4 e_4 e4 列对应 t 4 t_4 t4, 选出 n 1 , n 5 n_1, n_5 n1,n5,再看 e 3 e_3 e3 列对应 t 3 t_3 t3,选出 n 1 n_1 n1
ϵ \epsilon ϵ-lexicase selection
如算法 2 所述。
Semi-dynamic ϵ \epsilon ϵ-lexicase selection
dynamic ϵ \epsilon ϵ-lexicase selection。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









