







 文章介绍了如何通过动态子集选择(DSS)减少遗传编程(GP)在大型训练集上的函数树评估次数,实验证明DSS可以显著提高GP在甲状腺问题上的性能,有时甚至接近神经网络的结果。
文章介绍了如何通过动态子集选择(DSS)减少遗传编程(GP)在大型训练集上的函数树评估次数,实验证明DSS可以显著提高GP在甲状腺问题上的性能,有时甚至接近神经网络的结果。

Abstract
当使用遗传规划(GP)算法来解决具有大量训练案例的难题时,需要大量的群体规模,并且必须进行大量的函数树评估。本文描述了如何通过选择训练数据集的一个小子集来实际执行 GP 算法来减少此类评估的数量。本文中描述的三种子集选择方法是:动态子集选择(DSS),使用当前的 GP 运行来选择“困难”和/或废弃的案例,历史子集选择(HSS),使用以前的 GP 运行,随机子集选择( RSS)。各种运行表明,GP+DSS 可以在不到 GP 所用时间 20% 的情况下产生更好的结果。 GP+HSS 几乎可以与 GP 的结果相匹配,并且令人惊讶的是,GP+RSS 偶尔可以接近 GP 的结果。当用于解决甲状腺问题这一实质性问题时,GP+DSS 还产生了比各种神经网络论文中报告的更好、更普遍的结果。
1 Introduction
目前,遗传编程(GP)和遗传算法(GA)的潜力已在许多不同的问题领域得到证明。一般来说,这些实验涉及解决相对简单的小问题。然而,未来将面临巨大且极其混乱的问题,GP 方法必须扩大规模。
通过监督学习,涉及一组案例的训练,目的是学习如何对这些已知案例进行分类,并希望能够概括为能够正确地对所有可能的案例进行分类。大问题需要大量训练集。在标准 GP 算法中,GP 函数树的整个种群是根据整个训练数据集进行评估的,因此每代执行的函数树评估数量与种群大小和训练集大小成正比。
本文描述了动态子集选择(DSS)的简单方法。 DSS 减少了在得出令人满意的答案之前需要执行的此类评估的数量,并且实际上可以产生更通用的答案。为了进行比较,描述了另外两种选择方法:(甚至)更简单的随机子集选择(RSS)方法和历史子集选择(HSS),它使用以前的 GP 运行来选择单个训练子集。涉及甲状腺数据集(如下所述)的分类问题被用作标记“大而混乱”的问题。
2 GP, Code and Parameters
GP [3] 涉及一组类似 Lisp 的函数树表达式,每个表达式都由一组允许的函数和终端组成,并且全部具有相同的数据类型。从随机生成的功能树群体开始,选择在所讨论的问题上表现最好的树(例如,正确分类大多数训练案例)作为“种畜”。这些父树被组合(通过交换子树)和变异(通过生成新的子树),为下一代群体产生新树,这些新树继承了父母的一些特征。然后针对该问题评估下一代树。选择最好的树来产生下一代,依此类推。与遗传算法 [2, 1] 一样,GP 群体经过进化(希望)能够产生能够在所讨论的问题上表现良好的功能树。
本文允许使用的函数和端子集为:{ IFLTE、+、-、*、%、TANH、LOG、MINIMUM_OF_3、NEGATE、SQRT }和{ B1 至 B15、F1 至 F6、0、-1 },其中“B”和“F”指的是甲状腺病例的二进制和浮点字段。
用于这些实验的代码改编自 SGPC 代码 [8],用 C 语言编写。无论如何,此处选择的参数设置都不是最佳的,因为主要目的是演示训练子集选择而不是参数调整的效果。
3 The ‘Large and Messy’ Thyroid Problem
甲状腺数据集 [6] 代表了一个硬分类问题。神经网络 [4, 5] 报告的结果提供了与 GP 性能的有趣比较,然而,本文的主要目的是提高 GP 在难题上的性能。
该数据基于对医院患者甲状腺的测量。每个测量向量由 15 个二进制值(0.0 或 1.0)和 6 个浮点值(即总共 21 个值)组成,并且属于三类之一。第 3 类表示“正常”甲状腺,是迄今为止训练和测试数据集中最常见的类别,而第 1 类和第 2 类表示该腺体后来出现问题。在实践中有助于识别潜在的甲状腺,分类方案必须正确分类显着超过 92% 的所有病例,因为超过 92% 的所有患者具有正常(3 级)甲状腺。训练集和测试集中可能有 50 到 100 个真正困难的案例。因此,当尝试生成正确率在97%-100% 范围内的良好分类方案时,小的改进很重要,但很难获得。
训练集中有 3772 个案例,测试集中有 3428 个案例。以图形形式检查数据,例如使用 XGobi [7],揭示了点类之间的界限确实非常模糊。来自不同类别的点似乎可以自由地相互混合。
在所有运行中,GP 仅使用训练集来尝试进化其群体,以将甲状腺病例分类到正确的类别中。测试集仅用作对每一代最佳(或最适合)分类器(相对于训练集)的检查,以了解其推广到另一组同类数据的效果如何。运行的最佳分类器被认为是在训练集上表现最好的分类器。这不一定是在测试集上表现最好的。
生成相对于训练集最适合的分类器的设置,然后以这种方式在测试集上表现最好的设置被认为是最成功的设置。
3.1 Modification to Thyroid Problem for this Paper
为了使 GP 的工作变得更容易(在几次初始的不成功运行之后),甲状腺问题被重新表述为将病例分类为第 3 类或非第 3 类。这种重新表述允许 GP 函数树的输出被视为布尔值(输出 > 0 ~ 3 类,输出 < 0 ~ 非 3 类)。
事实证明,在单独的运行中,DSS 生成的函数树表达式相对简单,可以在训练集和测试集上以 100% 的准确度区分类别 1 和类别 2。如果要在实践中使用它们,则必须分两个阶段使用两个 GP 表达式树:首先(也是最困难的)区分 3 类案例和其他案例,然后,如果不是 3 类案例,则区分1 类和 2 类案例。
使用三种子集选择方法进行了实验,并与在每一代中使用整个训练集的标准 GP 的基线性能进行了比较。
4 Subset Selection Methods
4.1 Dynamic Subset Selection
这个简单的想法是基于一些前提和少量的后见之明。首先,将全科医生的注意力集中在疑难病例上,即那些经常被错误分类的病例上,是有好处的。其次,涉及几代人没有研究过的案件也是有好处的。这引出了最后一点:最终应该查看训练集中的所有案例。
DSS 算法涉及在每一代中从整个训练集中随机选择目标数量的案例,并带有偏差,因此如果案例“困难”或几代都没有被选择,则该案例更有可能被选择。
在每一代中,子集是通过以下两次完整训练集来选择的。
在整个训练集(大小为 T)的一次传递中,在一代 g g g 中,每个训练案例 i i i 被分配一个权重 W W W,它是其当前“难度”D 的一定幂的总和, d d d,以及自上次选择以来的代数(或年龄)A,也取一定幂a的幂:
∀ i : 1 ≤ i ≤ T , W i ( g ) = D i ( g ) d + A i ( g ) a ( 1 ) ∀ i : 1 ≤ i ≤ T , D i ( g = 0 ) = A i ( g = 0 ) = 0 ( 2 ) \begin{aligned}\forall i:1\leq i\leq T,\quad&W_i(g)=D_i(g)^d+A_i(g)^a\quad&(1)\\\\\forall i:1\leq i\leq T,\quad&D_i(g=0)=A_i(g=0)=0\quad&(2)\end{aligned} ∀i:1≤i≤T,∀i:1≤i≤T,Wi(g)=Di(g)d+Ai(g)aDi(g=0)=Ai(g=0)=0(1)(2)
所有案例的权重总和也在第一遍期间计算。
然后,在整个训练集的第二遍中,依次给每个案例一个被选入子集中的概率 P。案例的概率由其权重除以所有案例权重之和并乘以目标子集大小 S 给出:
∀ i : 1 ≤ i ≤ T , P i ( g ) = W i ( g ) ∗ S ∑ j = 1 T W j ( g ) ( 3 ) \forall i:1\leq i\leq T,\quad P_i(g)=\frac{W_i(g)*S}{\sum_{j=1}^TW_j(g)}\quad\quad\quad(3) ∀i:1≤i≤T,Pi(g)=∑j=1TWj(g)Wi(g)∗S(3)
如果一个案例 i i i 被选择在子集中,则其难度 D i D_i Di 和年龄 A i A_i Ai 被设置为 0,否则其难度保持不变,并且其年龄 A i A_i Ai 递增。在针对当前训练案例子集中的每个案例测试 GP 群体的每个成员时,每当案例被其中一棵 GP 树错误分类时,难度 D i D_i Di(从 0 开始)就会增加。
依次给出每个案例被选择的缩放概率,确保平均而言,子集的大小为 S。然而,每次选择新的子集时,子集大小都会围绕目标大小波动。其他选择方法可以很容易地产生恰好为 S 的子集大小,但人们认为不同的子集大小可能对 GP 算法的效率有更大的贡献。
然后根据这部分病例而不是整个训练集来评估当前一代的全科医生群体。
要使用这种形式的 DSS,必须设置三个参数:
- 目标案例数 - 子集大小
- 难度指数 - 对困难案例的重视程度
- 年龄指数 - 未选择案例的重要性
目前(而且似乎一如既往),选择有用的参数设置组合有点像魔术。出于甲状腺数据集的目的,目标大小 400(共 3772 个)很快被选为有效值。这相当于略多于 HSS 方法选择的中等“困难”案例的数量,为包括一些简单的案例留下了空间。
将目标大小设置为 400 后,可以更轻松地为两个指数选择合理的值。人口规模为 10000 的案例的平均难度等级可能约为 2000 左右。最困难的案例的评级为 10000 左右。如果目标规模为 400,则至少需要 10 代才能覆盖所有 3772 个训练案例。由于非常“困难”的案例和“老”的案例之间存在这种差异,我们任意决定将难度指数保持为 1.0 并将年龄指数设置为 3.5 。有了这些指数,最困难的案例和 15 代左右的案例将具有大致相同的权重。
4.2 Historical Subset Selection
在这里,以前的标准 GP 运行用于确定每个训练案例的难度程度。在几次运行(例如五次左右)的过程中,记录每次运行中每一代中最好的群体成员错误分类的案例。然后,这些情况组成了在进一步的 GP+HSS 运行中使用的子集,并且该子集在其初始选择后保持静态。由于选择的方法比较粗糙,因此该子集包含许多“困难”点和许多实际上非常“容易”分类的点。即使是最优秀的一代人口成员,在其发展的早期也会做出一些简单的错误分类。
在这里,以前的标准 GP 运行用于确定每个训练案例的难度程度。在几次运行(例如五次左右)的过程中,记录每次运行中每一代中最好的群体成员错误分类的案例。然后,这些情况组成了在进一步的 GP+HSS 运行中使用的子集,并且该子集在其初始选择后保持静态。由于选择的方法比较粗糙,因此该子集包含许多“困难”点和许多实际上非常“容易”分类的点。即使是最优秀的一代人口成员,在其发展的早期也会做出一些简单的错误分类。
4.3 Random Subset Selection
在这种选择形式中,在每一代,每个案例依次被以相等的概率选择为当前训练案例子集。该概率被缩放以确保所选择的子集平均而言具有目标大小。
∀ i : 1 ≤ i ≤ T , P i ( g ) = S T ( 4 ) \forall i:1\leq i\leq T,\quad P_i(g)=\frac ST\quad\quad\quad\quad(4) ∀i:1≤i≤T,Pi(g)=TS(4)
与 DSS 方法一样,子集大小随着每一代在目标大小周围波动。
5 Results
本文给出的结果来自两组运行:
- Population Size ---- 10000
这个群体规模给出了 DSS 取得的最佳结果,但是,不可能以如此巨大的群体规模对标准 GP 进行合理的长度运行,因为它花费的时间太长了。对于 DSS、HSS 和 RSS 运行,峰值如下表 1 所示。 - Population Size = 5000
GP、DSS、RSS 和 HSS 运行的这些结果都包含在内,以便可以直接比较所有四种方法。这里,难度指数增加到 1.5,以允许更小的难度值。对于这四次运行,峰值也显示在下面的表 1 中,以及以下三个图表:- 图 1 显示 DSS 的运行性能轻松优于 RSS。
- 图 2 显示标准 GP 运行优于 HSS,尽管这只是由于第 48 代左右的激增。这两种方法通常会产生相似的分数,但 HSS 通过更少的函数树评估来实现这些分数。
- 图 3 显示了仅使用 20% 数量的函数树评估的 DSS 匹配 GP 结果。
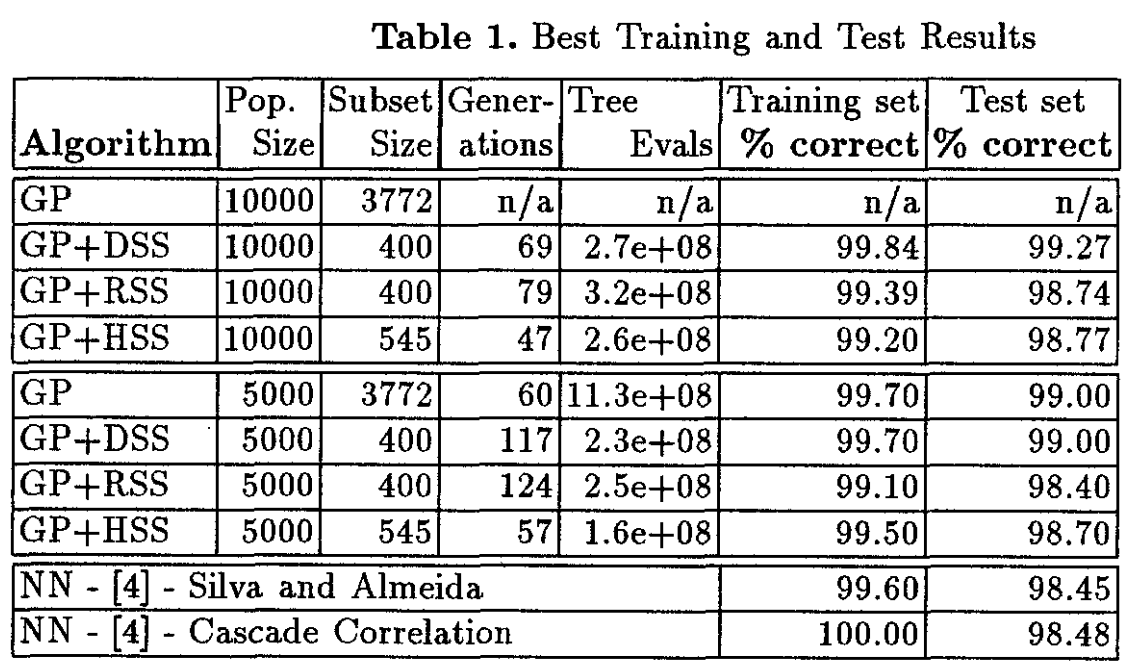
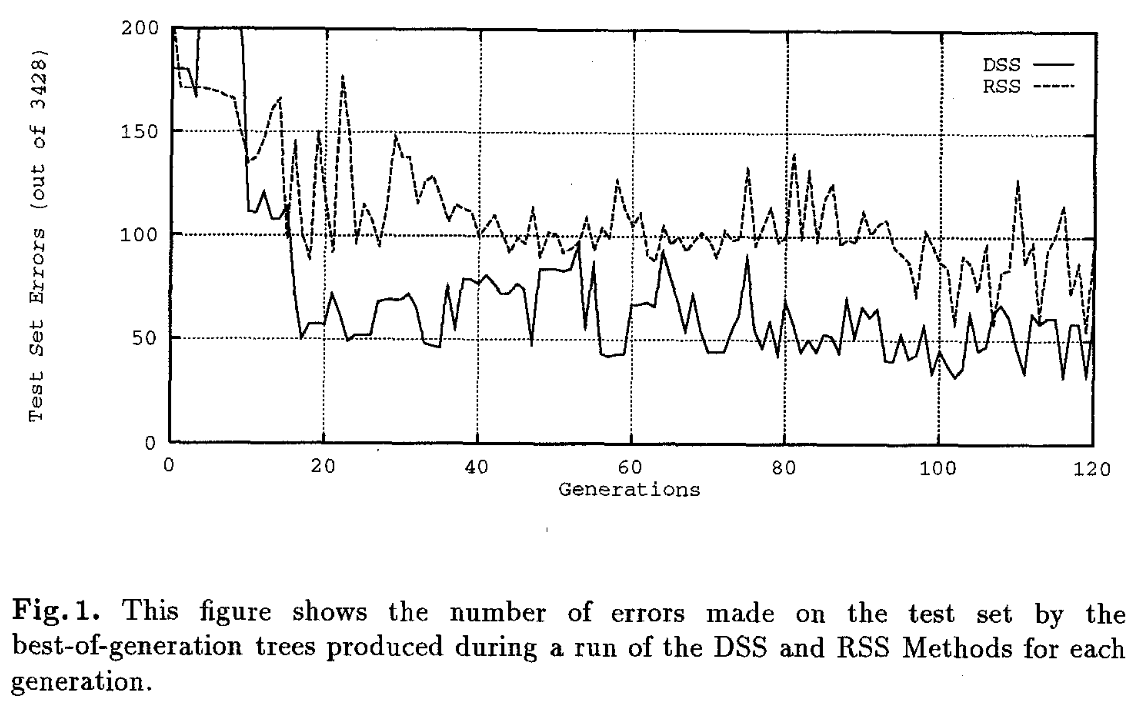
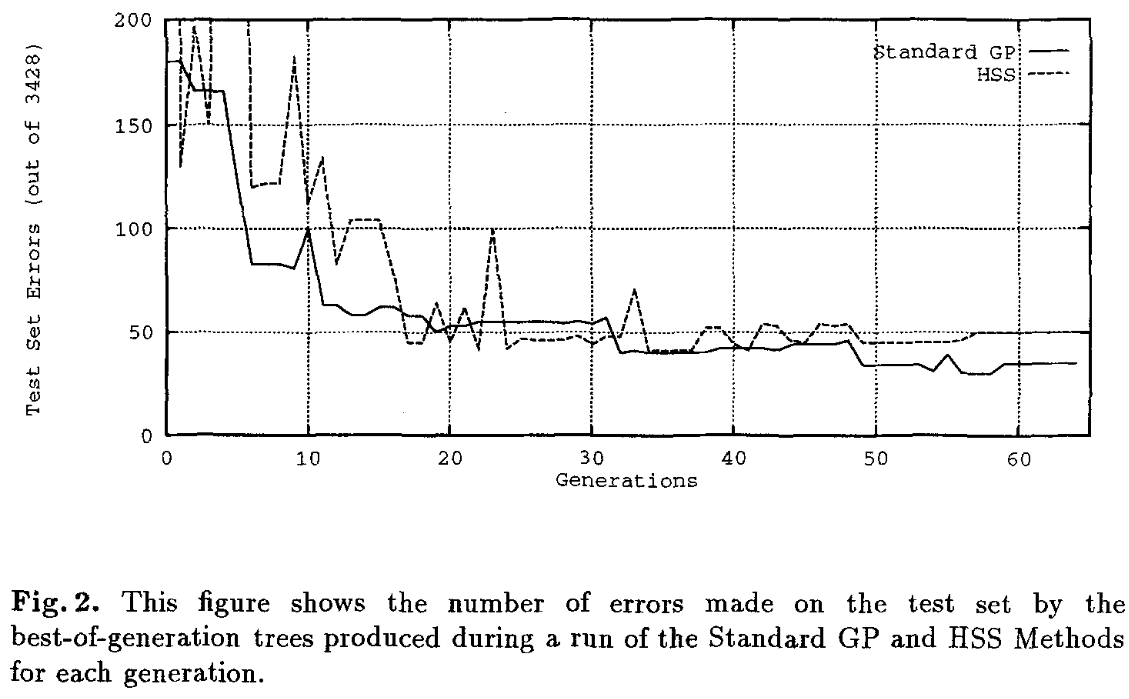

在第 69 代中发现了 DSS 运行(群体大小 = 10000)生成的用于区分类别 3 和非类别 3 的最佳树,在测试集上仅给出 25 个错误。它仅使用了可用于对甲状腺病例进行分类的 21 个变量中的 13 个。
5.1 A Quick Summary of Results from Other Runs
尝试了不同的子集大小,范围从 50 到完整训练集大小 3772。当子集大小接近 200 或更低时,性能显着下降甚至无法与标准 GP 相媲美。与大小为 400 左右的子集相比,更大的子集大小似乎并没有提高性能。
添加简约因子(即惩罚大型和“浓密”的树)可以加快 GP 程序的运行速度,因为它使用更少的运行时内存来存储整个(较小的)树种群,并且树速度更快评估。标准 GP 在有此限制的情况下的表现不如没有此限制的情况。然而,DSS 的表现似乎比以前稍好一些。
6 Discussion
GP + DSS 方法产生的结果与标准 GP 的结果一样好,而且时间短得多,至少在甲状腺问题上是这样。 DSS 实际上可以产生更好的答案,并且与标准 GP 或 HSS 相比,人们似乎在后代中产生了更多种类的解决方案。 DSS 的随机性质似乎有助于基本的 GP 算法。
在调查的早期阶段,有强烈的迹象表明该方法更广泛地适用于涉及大型训练集的 GP 和 GA 解决一般问题(为了节省时间),以及困难问题(为了更好和更普遍的答案)。而且,DSS 很容易添加到基本 GP 算法中。
HSS 在处理时间方面优于标准 GP,在结果质量方面几乎与之匹配。在实施 DSS 之前,I-ISS 是本周改进的主要竞争者。HSS 的一大优势是以前的标准 GP 运行可以轻松地利用信息来选择困难案例的子集。
RSS 的性能出奇的好,在某些情况下可以在更短的时间内达到标准 GP 的性能。
最佳函数树产生的错误分布或多或少均匀地分布在有问题的情况(第 1 类和第 2 类)和无问题情况(第 3 类)之间。这可以通过使 GP 算法偏向于在问题案例方面犯错来改变,即更多的假阳性错误和更少的假阴性错误,这在医疗环境中会更有用。
看看生成的函数树,有趣的是,最好的树仅使用 21 个可用变量中的 13 个来正确分类大多数情况。这可能会节省一些有用的数据收集成本,或者有助于将注意力集中在一些关键测量上。也许可以进行一些进一步的测量,并将每个关键测量分为几个不同的、更精细的测量。与神经网络相比,GP 的优势之一是很难从训练有素的神经网络中获得此类见解。
与 [4] 中的神经网络结果(其中最好的结果如上表 1 所示)相比,GP+DSS 生成了一个函数树,它从训练集中概括得更好。公平地说,在将问题分为两个阶段(第 3 类或非第 3 类,然后是第 1 类或第 2 类)时,向 GP 提出的问题比向神经网络提出的问题更简单。这可以用不同的方式来理解:将问题分解是轻微的作弊,或者展示 GP 方法的灵活性。
到目前为止,DSS 更有用的方面之一可能是它能够快速产生结果,对于 GP 来说,意味着可以尝试不同的功能集和参数设置。
有无数的调查线索需要跟进。例如,DSS 对于其他问题的适用范围有多大? DSS 的随机性如何影响 GP 的行为?如果 DSS 仅基于单个树的难度度量(例如一代最佳树的性能,还是需要整个种群的综合测量? DSS 是否可以应用于其他监督训练算法,例如神经网络,不断重新评估训练案例直到正确分类? DSS对其参数设置的敏感度如何?
7 Conclusions
添加到遗传编程中的动态子集选择在大型、混乱的甲状腺问题上表现得非常好。当人口规模为 5000 时,它产生的等效答案大约是标准 GP 所需功能树评估数量的 20%。当种群规模为 10000 时,DSS 产生的答案比此处显示的任何其他方法都更好,包括[4, 5]中报告的各种神经网络。
有强烈的迹象表明 DSS 更广泛地适用于 GP 和 GA 的其他监督训练问题。好处包括:需要更少的 CPU 时间、更好地概括答案、轻松添加到标准 GA 或 GP 中的非常简单的算法,从而允许 GP 应用于更大的监督学习问题。
References
Gathercole C, Ross P. Dynamic training subset selection for supervised learning in genetic programming[C]//Parallel Problem Solving from Nature—PPSN III: International Conference on Evolutionary Computation The Third Conference on Parallel Problem Solving from Nature Jerusalem, Israel, October 9–14, 1994 Proceedings 3. Springer Berlin Heidelberg, 1994: 312-321.
@inproceedings{gathercole1994dynamic,
title={Dynamic training subset selection for supervised learning in genetic programming},
author={Gathercole, Chris and Ross, Peter},
booktitle={Parallel Problem Solving from Nature—PPSN III: International Conference on Evolutionary Computation The Third Conference on Parallel Problem Solving from Nature Jerusalem, Israel, October 9--14, 1994 Proceedings 3},
pages={312--321},
year={1994},
organization={Springer}
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









