






本文是在centos 7 虚拟机中安装Superset和clickhouse
安装python3环境
Centos7.6默认有python2,要先安装python3,下边这个python3安装教程很详细。
参考连接:CentOS7下安装Python3,超详细完整教程_centos7安装python3_清香可口柑的博客-CSDN博客
在安装过程中会遇到 环境变量配置的相关内容,对~/.bash_profile 配置文件的修改方法,可以参考这个连接:
修改vim .bash_profile_vim ~/.bash_profile_SmallMartin的博客-CSDN博客
安装 ClickHouse
1. 添加 ClickHouse 的 YUM 源:
sudo yum install -y yum-utils
sudo rpm --import https://repo.clickhouse.tech/CLICKHOUSE-KEY.GPG
sudo yum-config-manager --add-repo https://repo.clickhouse.tech/rpm/stable/x86_64
2. 安装 ClickHouse:
sudo yum install -y clickhouse-server clickhouse-client
3. 启动 ClickHouse 服务:
sudo systemctl enable clickhouse-server
sudo systemctl start clickhouse-server
安装 Superset
1. 安装依赖包:
sudo yum install -y gcc gcc-c++ libffi-devel python-devel python-pip python-wheel openssl-devel libsasl2-devel openldap-devel
2. 安装 Superset:
sudo pip3 install superset
然后需要将superset 配置环境变量,与配置python3、pip3的方法类似。
a. 找到Superset执行文件的位置,使用find命令:
sudo find / -name superset
这里可能会返回很多,选择一个就可以,我的路径是
/home/Python-3.6.10/bin/superset
b. 手动将 Superset 的执行文件添加到 PATH 路径中,方法与配置python3 和 pip3 的类似,可以编辑 ~/.bashrc 或 ~/.bash_profile 文件
i 输入命令:
vi ~/.bash_profile
ii 键入I,进入 Insert模式,编辑该文件,在文件末尾添加:
export PATH=/path/to/superset/bin:$PATH
注意:其中 /path/to/superset /bin 是
superset命令所在的目录,例如我的这行代码就是export PATH=/home/Python-3.6.10/bin:$PATH,不需要加superset那一层
iii编辑完时候按 Esc退出编辑,输入: 不编辑文本即为推出成功,输入wq 保存
iiii 更新环境变量
source ~/.bash_profile
3. 安装环境
如果忽略这步,直接第4步也是可以的,可能会提醒No module named 'xxx',可以缺什么就补什么pip3 install xxx,但是需要考虑flask、werkzeug等的版本问题,推荐使用以下方法下载指定的版本:
i 新建一个superset_requirements.txt文本文档,
vi superset_requirements.txt
ii 在这个文件中添加以下内容:
#
# This file is autogenerated by pip-compile
# To update, run:
#
# pip-compile --output-file=requirements.txt setup.py
#
alembic==1.3.2 # via flask-migrate
amqp==2.5.2 # via kombu
apispec[yaml]==1.3.3 # via flask-appbuilder
attrs==19.3.0 # via jsonschema
babel==2.8.0 # via flask-babel
backoff==1.10.0 # via apache-superset (setup.py)
billiard==3.6.3.0 # via celery
bleach==3.1.0 # via apache-superset (setup.py)
celery==4.4.1 # via apache-superset (setup.py)
cffi==1.13.2 # via cryptography
click==7.1.1 # via apache-superset (setup.py), flask, flask-appbuilder
colorama==0.4.3 # via apache-superset (setup.py), flask-appbuilder
contextlib2==0.6.0.post1 # via apache-superset (setup.py)
croniter==0.3.31 # via apache-superset (setup.py)
cryptography==2.8 # via apache-superset (setup.py)
decorator==4.4.1 # via retry
defusedxml==0.6.0 # via python3-openid
flask-appbuilder==2.2.4 # via apache-superset (setup.py)
flask-babel==1.0.0 # via flask-appbuilder
flask-caching==1.8.0 # via apache-superset (setup.py)
flask-compress==1.4.0 # via apache-superset (setup.py)
flask-jwt-extended==3.24.1 # via flask-appbuilder
flask-login==0.4.1 # via flask-appbuilder
flask-migrate==2.5.2 # via apache-superset (setup.py)
flask-openid==1.2.5 # via flask-appbuilder
flask-sqlalchemy==2.4.1 # via flask-appbuilder, flask-migrate
flask-talisman==0.7.0 # via apache-superset (setup.py)
flask-wtf==0.14.2 # via apache-superset (setup.py), flask-appbuilder
flask==1.1.1 # via apache-superset (setup.py), flask-appbuilder, flask-babel, flask-caching, flask-compress, flask-jwt-extended, flask-login, flask-migrate, flask-openid, flask-sqlalchemy, flask-wtf
geographiclib==1.50 # via geopy
geopy==1.20.0 # via apache-superset (setup.py)
gunicorn==20.0.4 # via apache-superset (setup.py)
humanize==0.5.1 # via apache-superset (setup.py)
importlib-metadata==1.4.0 # via jsonschema, kombu
isodate==0.6.0 # via apache-superset (setup.py)
itsdangerous==1.1.0 # via flask
jinja2==2.10.3 # via flask, flask-babel
jsonschema==3.2.0 # via flask-appbuilder
kombu==4.6.8 # via celery
mako==1.1.1 # via alembic
markdown==3.1.1 # via apache-superset (setup.py)
markupsafe==1.1.1 # via jinja2, mako
marshmallow-enum==1.5.1 # via flask-appbuilder
marshmallow-sqlalchemy==0.21.0 # via flask-appbuilder
marshmallow==2.19.5 # via flask-appbuilder, marshmallow-enum, marshmallow-sqlalchemy
more-itertools==8.1.0 # via zipp
msgpack==0.6.2 # via apache-superset (setup.py)
numpy==1.18.1 # via pandas, pyarrow
pandas==0.25.3 # via apache-superset (setup.py)
parsedatetime==2.5 # via apache-superset (setup.py)
pathlib2==2.3.5 # via apache-superset (setup.py)
polyline==1.4.0 # via apache-superset (setup.py)
prison==0.1.2 # via flask-appbuilder
py==1.8.1 # via retry
pyarrow==0.16.0 # via apache-superset (setup.py)
pycparser==2.19 # via cffi
pyjwt==1.7.1 # via flask-appbuilder, flask-jwt-extended
pyrsistent==0.15.7 # via jsonschema
python-dateutil==2.8.1 # via alembic, apache-superset (setup.py), croniter, flask-appbuilder, pandas
python-dotenv==0.10.5 # via apache-superset (setup.py)
python-editor==1.0.4 # via alembic
python-geohash==0.8.5 # via apache-superset (setup.py)
python3-openid==3.1.0 # via flask-openid
pytz==2019.3 # via babel, celery, flask-babel, pandas
pyyaml==5.3 # via apache-superset (setup.py), apispec
retry==0.9.2 # via apache-superset (setup.py)
selenium==3.141.0 # via apache-superset (setup.py)
simplejson==3.17.0 # via apache-superset (setup.py)
six==1.14.0 # via bleach, cryptography, flask-jwt-extended, flask-talisman, isodate, jsonschema, pathlib2, polyline, prison, pyarrow, pyrsistent, python-dateutil, sqlalchemy-utils, wtforms-json
sqlalchemy-utils==0.36.1 # via apache-superset (setup.py), flask-appbuilder
sqlalchemy==1.3.12 # via alembic, apache-superset (setup.py), flask-sqlalchemy, marshmallow-sqlalchemy, sqlalchemy-utils
sqlparse==0.3.0 # via apache-superset (setup.py)
urllib3==1.25.8 # via selenium
vine==1.3.0 # via amqp, celery
webencodings==0.5.1 # via bleach
werkzeug==0.16.0 # via flask, flask-jwt-extended
wtforms-json==0.3.3 # via apache-superset (setup.py)
wtforms==2.2.1 # via flask-wtf, wtforms-json
zipp==2.0.0 # via importlib-metadata
# The following packages are considered to be unsafe in a requirements file:
# setuptools
参考:superset所需环境的博客
iii 在该文件目录下,安装依赖包
pip3 install -r superset_requirements.txt
4. 初始化数据库:
如果不是第一次启动,直接这两个命令就可以初始化数据库,
# 创建一个空数据库
superset db upgrade
# superset初始化
superset init
在你第一次启动 Superset 时,需要创建一个管理员帐户,步骤如下
i 创建一个空数据库
superset db upgrade
ii 创建一个管理员账户
export FLASK_APP=superset
export FLASK_ENV=development
superset fab create-admin
我的版本是0.999.0,会遇到 no such command "create-admin" 的错误,可能是因为superset版本比较旧,可以使用以下这个命令
FLASK_APP=superset FLASK_ENV=production superset fab create-admin
之后会提醒设置用户名和密码,创建完成后,就可以使用这个帐户登录Superset 了。
iii 加载数据
iiii 初始化superset环境
superset init
5. 启动 Superset:
i在虚拟机中,可以使用以下命令来查看虚拟机的 IP 地址:
ifconfig
在命令输出中,找到网络接口的 IP 地址,通常以 eth0 或 enp0s3 等命名,例如:
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.1.100 netmask 255.255.255.0 broadcast 192.168.1.255
...
在这个例子中,虚拟机的 IP 地址为 192.168.1.100。然后,在启动 Superset 时,将 superset run 命令中的 -h 参数设置为这个 IP 地址,例如:
superset run -h 192.168.1.100 -p 8088 --with-threads --reload --debugger
这将使 Superset 只监听虚拟机的 IP 地址 192.168.1.100,并使用端口号为 8088。此时,你可以使用主机上的浏览器来访问 Superset,只需在浏览器中输入虚拟机的 IP 地址和端口号即可。
6. 访问 Superset 网页界面:
在浏览器中访问 http://IP地址:端口号,即可打开 Superset 的网页界面,开始使用。例如:http://192.168.1.100:8088
Superset 连接 Clickhouse
1. 安装 ClickHouse 数据库驱动:
如果需要连接 ClickHouse 数据库,还需要安装 ClickHouse 数据库驱动。安装的时候需要注意版本号是否匹配。
i 安装 greenlet
sudo pip3 install greenlet==0.4.17 -i https://pypi.tuna.tsinghua.edu.cn/simple```
ii 安装clickhouse-sqlalchemy
sudo pip3 install clickhouse-sqlalchemy==0.1.5 -i https://pypi.tuna.tsinghua.edu.cn/simple
2. Superset 连接 clickhouse数据库
完成上一章的第6步,进入到superset系统后,点击source中的databases
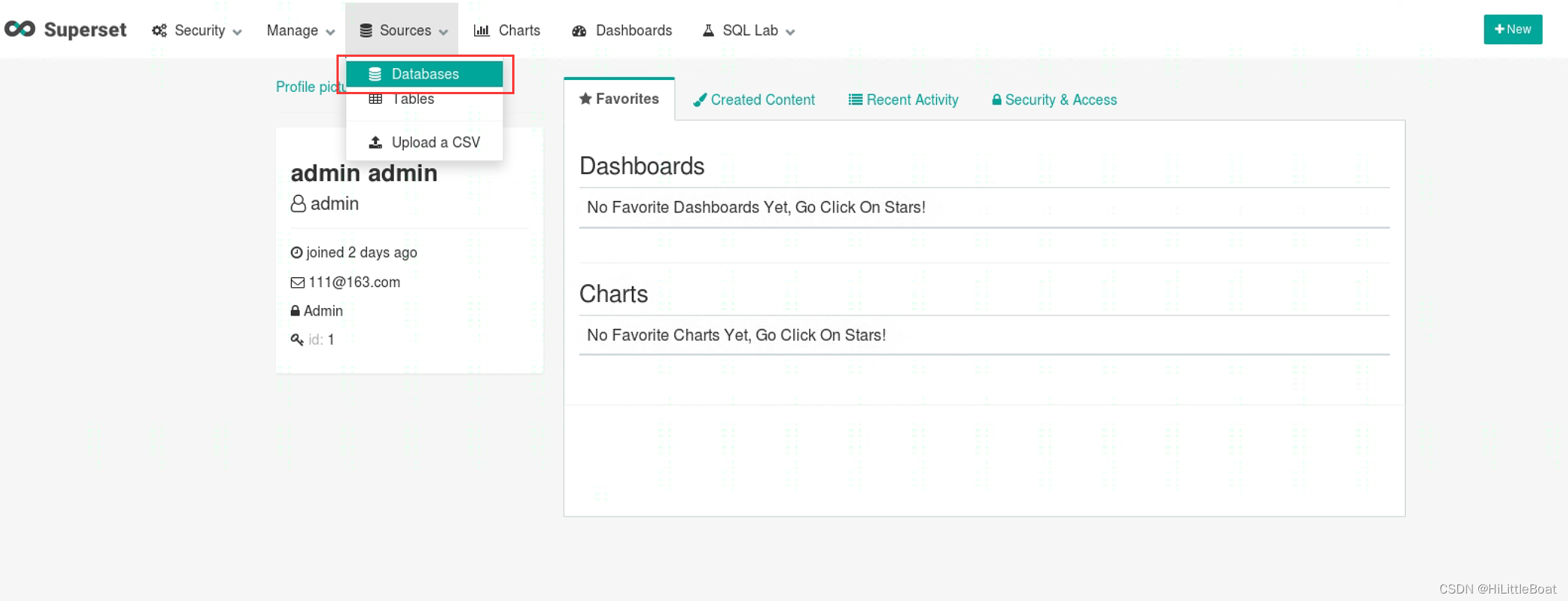
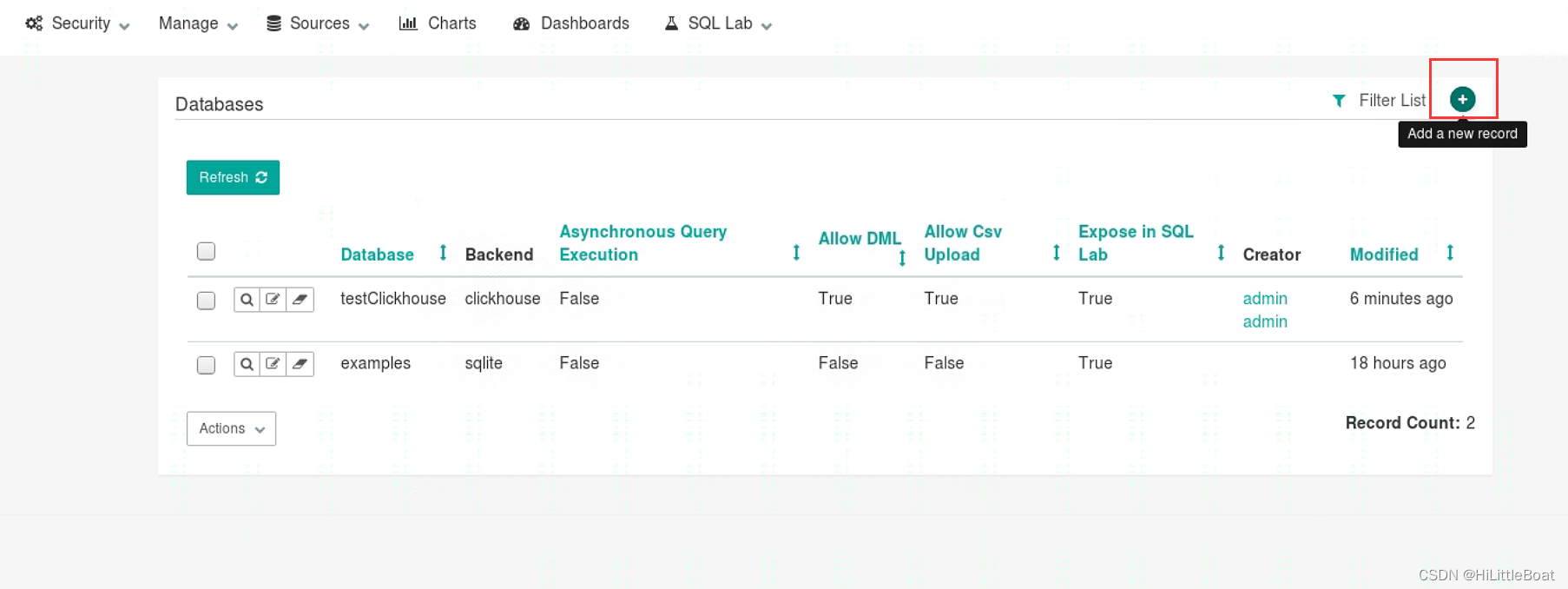
点击右上角的➕
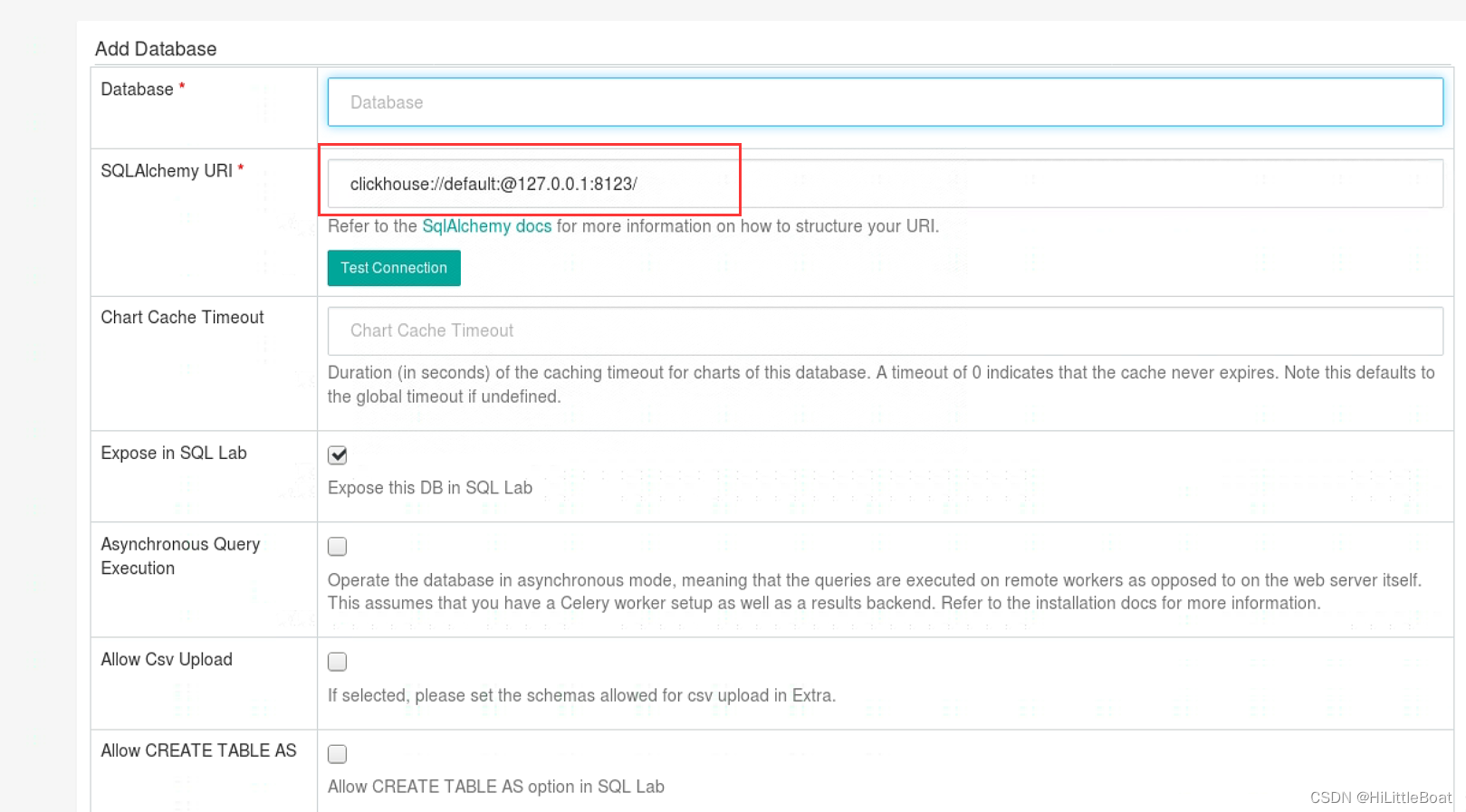
Database中填写在superset中的新名称,SQLAlchemyURL的格式为:
clickhouse://<username>:<password>@<host>:<port>/<database>
其中:
<username>:ClickHouse 数据库的用户名(如果没有设置用户名,默认default)<password>:ClickHouse 数据库的密码(如果没有设置密码,则留空)<host>:ClickHouse 数据库的主机名或 IP 地址,如果和superset是一台主机,可以用localhost,或者127.0.0.1<port>:ClickHouse 数据库的端口号,默认是 8123,检测端口是否已经打开且可以访问http://localhost:8123,返回ok既是没有问题<database>:需要连接的 ClickHouse 数据库名
例如,假设 ClickHouse 数据库的 IP 地址、端口号是默认的 ,也没有设置用户名和密码,需要连接的数据库名是 mydatabase,那么对应的 SQLAlchemy URL 是:
clickhouse://default:@localhost:8123/mydatabase
勾选Allow Csv Upload ,Allow CREATE TABLE AS, Allow DML
点击Test Connection,返回Seems OK!即连接上了,点击Save保存。
参考博客:CLICKHOUSE+SUPERSET搭建数据平台(三)-SUPERSET安装并连接CLICKHOUSE–灰信网
容易报错的点
-
使用superset 命令行的时候,提醒 “superset: 未找到命令…”
首先检查已经完成了pip install superset 的步骤,如果完成了,找一下是否已经有superset,使用
find命令:sudo find / -name superset如果存在,检查是否加入环境变量,参考《安装superset》章节中的第2步;
如果已经加入环境变量,就用source命令激活一下环境变量就可以了。source ~/.bash_profile -
安装
click-sqlalchemy出现的各种错误:
指定要安装的greenlet和click-sqlalchemy版本,参考《Superset 连接 Clickhouse》章节的 第一步 -
superset所需要的依赖,按照版本装,不然容易冲突,参考《安装Superset》的第三步。














 1018
1018











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









