






 菜鸡学习噜~~~
菜鸡学习噜~~~
波士顿房价案例——数据处理、模型训练、优化、预测和结果可视化
Key Point:
1. **导入必要的库和模块**:
- `matplotlib.pyplot`: 用于数据可视化,如绘制2D图形和图表。
- `numpy`: 提供数组支持,以及基础的科学计算功能。
- `sklearn.datasets`: 包含各种标准数据集,这里使用的是波士顿房价数据集。
- `sklearn.metrics`: 包含性能度量的函数,如计算模型的 R^2 分数。
- `sklearn.model_selection.train_test_split`: 该函数用于将数据集随机分割为训练集和测试集。
- `sklearn.linear_model.Ridge`: 岭回归模型实现,用于处理具有多重共线性的数据。
- `sklearn.linear_model.RidgeCV`: 岭回归的交叉验证版本,用于寻找最优的正则化参数。
2. **数据加载和预处理**:
- 使用 `datasets.load_boston()` 加载波士顿房价数据集。
- 使用 `train_test_split()` 将数据分割为训练集和测试集。
-
参数:
- 第一个和第二个参数通常是特征集(X)和目标集(y),分别表示输入的数据和目标变量。
test_size是一个介于0和1之间的浮点数,表示测试集占整个数据集的比例。例如,0.2 表示测试集应占20%。random_state参数是一个整数或 RandomState 实例,它决定了数据分割时随机性的种子。指定一个整数可以确保每次运行代码时数据分割都是相同的。train_size是一个可选参数,类似于test_size,它允许你指定训练集的大小。shuffle是一个布尔值,表示在分割之前是否应该打乱数据。默认情况下是 True,即数据通常会被打乱以提高随机性。
3. **模型训练和参数优化**:
- `RidgeCV` 对一系列正则化参数进行交叉验证,从而找到最佳的正则化强度 `alpha`。(RidgeCV通过交叉验证从Lambdas候选列表中选择了一个最优的alpha值,用于减少过拟合并提高模型的泛化能力。)
- `Ridge` 使用最佳 `alpha` 值来拟合训练数据。
4. **模型评估**:
- 使用 `metrics.r2_score` 计算 R^2 分数,了解模型对于测试数据的预测性能。
5. **可视化结果**:
- 设置 matplotlib 参数以支持中文显示。
- 使用 `plt.plot()` 画出预测值和实际值的图形对比。
- 使用 `plt.show()` 展示图形。
6. **结果输出**:
- 打印出岭回归模型的系数,这些系数反映了每个特征对目标变量(房价)的影响。
7. **代码实用性**:
- 这段代码展示了从数据预处理到模型训练、参数优化、预测、评估以及结果展示的整个流程,是典型的机器学习应用实例。
8. **代码扩展性**:
- 训练的岭回归模型可以替换为其他任何回归模型。
- 通过更改数据集和调整模型参数,代码可以轻松地适用于其他类型的预测问题。
总的来说,这段代码集合了数据处理、模型选择、模型评估和数据可视化等多个机器学习领域的关键要素,是一个很好的实践机器学习项目的起点。
回归(Regression)是统计学中的一个术语,指的是分析和建模一个或多个自变量(解释变量)与因变量(目标变量)之间关系的过程。这种分析的目标是了解变量之间是否存在某种趋势或模式,并使用这种模式来预测或估计数据。
import matplotlib.pyplot as plt #导入 mnatplolib库中的pyplot 模块,并给它起了一个别名plt。
import numpy as np #导入numpy数组(科学计算库,主要用于数组计算)
#(导入sklearn库中的datasets,metrics模块(数据集,评估)
from sklearn import datasets, metrics
# 从sklearn的model_selection模块导入训练集、测试集的分割函数
# train_test_split用于将数据集分割成两部分:训练集和测试集
from sklearn.model_selection import train_test_split
# 从sklearn库的linear_model模块导入Ridge,RidgeCV类
# Ridge类实现了岭回归,而RidgeCV是一个交叉验证的版本,它可以找到最优的正则化参数。
from sklearn.linear_model import Ridge, RidgeCV
d_sets = datasets.load_boston() # 获取数据集
# 使用train_test_split函数将数据集分成训练集和测试集,其中测试集占总数据量的20%
# random_state用于设定随机数生成器的种子,确保结果的可复现性
x_train, x_test, y_train, y_test = train_teat_split(d_sets.data, d_sets.target, test_size = 0.2, random_state = 8)
# 生成一个由200个数构成的在对数尺度上均匀分布的数组,从10^-5到10^2
Lambdas = np.logspace(-5, 2, 200)
"""
创建RidgeCV对象,用于确定最优的正则化参数
参数alphas是候选的正则化系数
normalize=True会对回归变量进行标准化处理
scoring参数用于模型评估的方法
这里使用负均方误差(因为越高越好的评分策略,所以是负值)
cv表示交叉验证的折数。
"""
ridge_cv = RidgeCV(alphas = Lambdas, normalize = True, scoring = 'neg_mean_squared
_error', cv=10)
# 在训练数据上拟合岭回归模型,RidgeCV会自动进行交叉验证来选择最佳的正则化参数
ridge_cv.fit(x_train, y_train)
# 使用通过RidgeCV找到的最佳正则化参数alpha_创建了一个新的Ridge模型实例。
ridge = Ridge(alpha=ridge_cv.alpha_, normalize = True)
ridge.fit(x_train, y_train) # 用训练集拟合Ridge模型
y_fit = ridge.predict(x_test) #用拟合好的模型在测试集上进行预测。
R2 = metrics.r2_score(y_test, y_fit) # 计算预测值和真实值之间的R^2分数
# R^2分数是回归模型拟合优度的一种度量,其值通常位于0到1之间。
plt.reParams['font.sans-serif'] = 'SimHei' # 设置matplotlib的全局字体,以支持中文显示。
plt.figure(figsize=(8,5)) # 创建一个新的图形窗口,指定大小为8*5英寸。
# 画出测试集的真实值和预测值,真实值为红色,预测值为蓝色并使用了点线。
plt.plot(np.arange(len(y_fit)), y_test, color = 'r') # np.arange()生成等差数列,0-(len-1)
plt.plot(np.arange(len(y_fit)), y_fit, color = 'b', linestyle= ':')
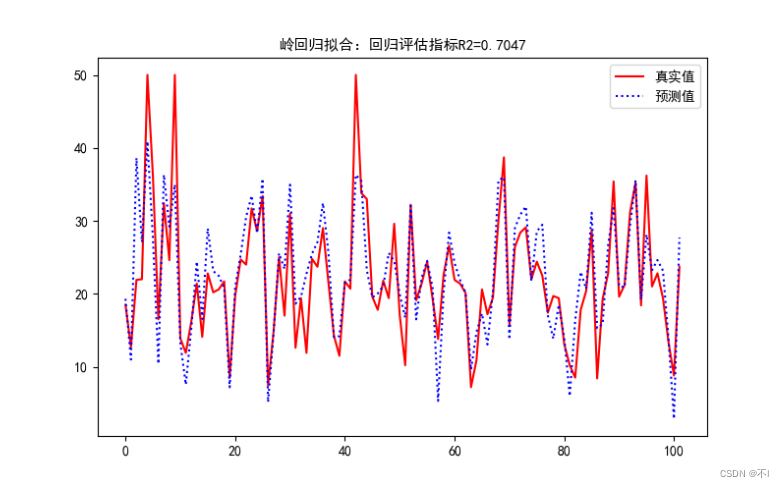
plt.title("岭回归拟合:回归评估指标R2=" + str(round(R2,4)), fontsize=11)
'''
str(round(R2, 4)) 是一个将决定系数(R^2)分数转换为字符串的操作。
round(R2, 4) 表示将决定系数 R2 四舍五入到小数点后四位。
然后,str() 函数将这个数转换为字符串形式,以便将其用作图像标题的一部分。
'''
plt.legend(['真实值', '预测值']) #plt.legend() 用于在图表中添加图例
plt.show() # 展示图片
'''
ridge.coef_ 返回一个一维数组,其中包含了每个特征对应的系数值,即权重。
round(ridge.coef_[i],2)即对ridge.coef_[i]进行四舍五入到小数点后两位
参数sep=''表示打印多个值时不使用分隔符,默认是使用空格分隔。end=','表示打印完每个系数后不换行,而是使用逗号分隔继续打印下一个系数。
'''
for i in np.arange(len(ridge.coef_)):
print(round(ridge.coef_[i],2), sep='', end=',')浅了解一下~咯
Python 的切片(slice)语法
[start:stop:step]
start:切片的起始位置(包含)。stop:切片的结束位置(不包含)。step:切片的步长(可选,默认为 1)
`raw_df.values` 表示将 pandas DataFrame 对象 `raw_df` 转换为 NumPy 数组,这样可以更方便地进行数组操作。该属性返回一个包含 DataFrame 中所有数据的二维数组。
现在,让我们逐步解释 `raw_df.values[::2, :]` 和 `raw_df.values[1::2, :2]`:
1. `raw_df.values[::2, :]`:
- `::2` 表示使用步长为 2 进行切片,这意味着选择数组的偶数行。
- `:` 表示选择所有的列。(从0开始到最后,步长为1)
- 因此,这个表达式选择了 `raw_df` 中的偶数行以及所有的列,即特征数据部分。
2. `raw_df.values[1::2, :2]`:
- `1::2` 表示使用步长为 2 进行切片,这意味着选择数组的奇数行。
- `:2` 表示选择数组中的前两列。从0开始到2结束(不包括2),步长为默认1。
- 因此,这个表达式选择了 `raw_df` 中的奇数行的前两列,即目标数据部分。
综合起来,这两个表达式一起使用时,可以从原始的 DataFrame 数据中分别获取特征数据和目标数据。`raw_df.values[::2, :]` 用于提取偶数行(特征数据),而 `raw_df.values[1::2, :2]` 用于提取奇数行的前两列(目标数据)。
交叉验证(Cross-Validation)
是一种用于评估模型性能、选择合适参数和防止过拟合的技术。它通过将数据集划分为多个子集,在每个子集上训练模型并在剩余子集上进行验证,从而综合多次训练和验证的结果来评估模型的泛化能力。
**原理:**
1. **简单交叉验证(Holdout Cross-Validation):** 将数据集随机划分为训练集和测试集两部分,其中训练集用于模型训练,测试集用于模型评估。这是最基本的交叉验证方法,但可能会因为划分不均匀而导致评估结果的方差较大。
2. **k折交叉验证(k-Fold Cross-Validation):** 将数据集划分为k个大小相等的子集(称为折叠),每次使用其中一个子集作为测试集,其余k-1个子集作为训练集,然后重复k次,每次选择不同的测试集。最终,将k次的评估结果取平均作为模型的性能指标。
3. **留一交叉验证(Leave-One-Out Cross-Validation,LOOCV):** 是k折交叉验证的一种特例,其中k等于数据集的样本数量。对于每个样本,都将其单独作为测试集,其余样本作为训练集,重复n次(n为样本数量),然后将n次的评估结果取平均。
**常用的交叉验证方法:**
- **k折交叉验证(k-Fold Cross-Validation)**:是最常用的交叉验证方法,通常选择k=5或k=10。
- **留一交叉验证(Leave-One-Out Cross-Validation,LOOCV)**:当数据集较小且计算资源充足时使用,因为需要对每个样本进行训练。
- **分组交叉验证(Group Cross-Validation)**:适用于具有分组结构的数据集,如时间序列数据或者具有不同来源的数据。
**在模型选择和调优中的应用:**
- **模型选择(Model Selection)**:通过交叉验证比较不同模型在相同数据集上的性能,选择表现最好的模型。
- **超参数调优(Hyperparameter Tuning)**:通过交叉验证来调整模型的超参数,如正则化参数、学习率等,选择使得模型性能最优的参数值。
- **评估模型性能(Model Evaluation)**:交叉验证提供了对模型泛化能力的更准确评估,比单次划分训练集和测试集更可靠。
交叉验证的主要目的是评估模型在未见过的数据上的性能,通过更好地利用数据并减少因数据划分而引入的偶然性,提高模型评估的稳定性和可靠性。
多重共线性(Multicollinearity)
指的是在回归分析中,自变量之间存在高度相关性或线性相关性的情况。具体来说,多重共线性通常会导致以下情况:
1. **相关性高:** 多重共线性意味着自变量之间存在高度相关性,即一个或多个自变量可以通过其他自变量进行线性组合来近似表示。
2. **系数不稳定:** 多重共线性会导致回归系数的估计不稳定,即使微小的数据变动也可能导致回归系数的显著变化。
3. **解释困难:** 当自变量之间存在高度相关性时,很难对单个自变量的影响进行解释,因为这些自变量的效果很难区分。
4. **降低模型的准确性:** 多重共线性会降低模型的准确性和解释能力,导致模型对数据的拟合程度不佳。
多重共线性通常会对回归分析的结果产生负面影响,包括增加回归系数的方差、降低回归系数的可信度、降低模型的预测准确性等。因此,在进行回归分析时,需要注意检测和处理多重共线性,以确保模型的准确性和稳定性。常见的处理多重共线性的方法包括岭回归、套索回归、主成分分析等。
CSV(Comma-Separated Values)
是一种常用的文本文件格式,用于存储表格数据,如电子表格或数据库信息。CSV文件的特点如下:
1. **简单结构**:CSV文件由纯文本组成,具有非常简单的结构,易于读写和处理。
2. **数据分隔**:在CSV文件中,各个值(或字段)通常由逗号分隔(在某些地区,分号或其他字符可能用作分隔符)。
3. **表格对应**:每一行CSV文件通常对应表格中的一行数据,而每个分隔的值对应一个单元格。
4. **可选标题行**:CSV文件的第一行可以是标题行,包含了每列的名称,但这不是强制的。
### CSV文件示例
假设有一个记录学生信息的CSV文件,内容可能如下所示:
Name,Age,Grade
John Doe,16,A
Jane Smith,15,B+
在这个例子中,CSV文件有一个标题行,指明了每列的含义(分别是姓名、年龄和成绩),接下来的每一行则代表一个学生的信息,各个值由逗号分隔。
### CSV与其他格式的对比
与其他数据存储格式(如JSON、XML或YAML)相比,CSV格式的主要优势在于其简单性和广泛的支持。大多数电子表格软件(如Microsoft Excel、Google Sheets)都能够导入和导出CSV文件,许多编程语言和库也提供了读写CSV文件的功能。
然而,CSV格式也有其局限性,例如不支持多层嵌套的数据结构,以及有限的数据类型表示能力(CSV文件中的所有数据都是字符串形式存储,需要在使用时转换成相应的数据类型)。尽管如此,对于简单的表格数据交换,CSV仍然是一个非常实用的选择。
字符串 " " 、列表 [ ]、字典 { key : vlue}、集合{ }
# 字符串中的字符数
string_length = len("Hello")
print(string_length) # 输出:5
# 列表中的项目数
list_length = len([1, 2, 3, 4, 5])
print(list_length) # 输出:5
# 字典中的键值对数
dict_length = len({'name': 'Alice', 'age': 30})
print(dict_length) # 输出:2
# 集合中的元素数
set_length = len({1, 2, 3, 4, 5})
print(set_length) # 输出:5
字典可以通过花括号 {} 来定义,键和值之间使用冒号 : 分隔,键值对之间使用逗号 , 分隔。
输出:
print(my_dict['name']) # 输出:John
修改、添加键值对 :
my_dict['gender'] = 'Male' # 添加新的键值对
my_dict['age'] = 31 # 修改已有的键值对
删除字典:
del my_dict['city'] # 删除键值对
age = my_dict.pop('age') # 删除并返回值
遍历字典:
for key in my_dict:
print(key, my_dict[key]) # 遍历键和对应的值
for key, value in my_dict.items():
print(key, value) # 遍历键值对
Debug
# @Author : 发疯的谢必安
# @Time : 2024/3/6 11:07
# @Description:波士顿房价——线性回归案例
import matplotlib.pyplot as plt # 导入matplotlib库中的pyplot模块
# as plt 就是为 matplotlib.pyplot 定义了一个简短的别名 plt,(alias别名)
# matplotlib.pyplot 是 Python 中一个用于绘制图表的模块,它是 matplotlib 库中用于绘图的子模块。
import numpy as np
# 导入numpy库,这是Python的一个科学计算包
from sklearn import datasets,metrics
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Ridge,RidgeCV
import pandas as pd
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
# d_sets = datasets.load_boston()#获取不到数据集,在最新版本的 scikit-learn 中,load_boston 函数已经被移除
#将指标数据集、因变量数据集划分为训练集、测试集,测试集占20%,随机数种子8
x_train,x_test,y_train,y_test = train_test_split(data,target,test_size=0.2,random_state=8)
Lambdas = np.logspace(-5,2,200)
#先用交叉验证函数RidgeCV()确定参数Lambdas,再用Ridge()求最小二乘法解,使用均方误差
ridge_cv=RidgeCV(alphas=Lambdas, scoring='neg_mean_squared_error', cv=10)
ridge_cv.fit(x_train,y_train)
ridge = Ridge(alpha=ridge_cv.alpha_)#岭回归:基于最佳lambda建模
ridge.fit(x_train, y_train)
# 模型评估:数据预测
y_fit = ridge.predict(x_test)
#R2(决定系数分数)
R2 = metrics.r2_score(y_test,y_fit)
#设置中文显示
plt.rcParams['font.sans-serif'] = 'SimHei'
#结果可视化
plt.figure(figsize=(8,5))
plt.plot(np.arange(len(y_fit)),y_test,color='r')
plt.plot(np.arange(len(y_fit)),y_fit,color='b',linestyle=':')
plt.title("岭回归拟合:回归评估指标R2="+str (round(R2,4)),fontsize=11)
plt.legend(['真实值','预测值'])
#显示图像
plt.show()
for i in np.arange(len(ridge.coef_)):
print(round(ridge.coef_[i],2),sep='',end=',')

PS:如果希望最末尾没有“ , " 将末尾两行寻黄遍历输出修改为:
result = []
for i in np.arange(len(ridge.coef_)):
result.append(round(ridge.coef_[i], 2))
print(','.join(map(str, result)))或者是:
for i in np.arange(len(ridge.coef_)):
if i < len(ridge.coef_) - 1:
print(round(ridge.coef_[i], 2), end=',')
else:
print(round(ridge.coef_[i], 2))

join() 方法是字符串对象的一个方法,用于将序列中的元素连接成一个字符串。而 map() 函数则用于对序列中的每个元素应用一个函数,然后返回一个包含结果的迭代器。
在这个特定的用例中,map(str, result) 会将 result 列表中的每个元素都转换为字符串类型,然后 join() 方法将这些字符串连接起来,并以逗号作为分隔符。
具体来说,map(str, result) 会将 result 中的每个数字转换为字符串,然后 join() 方法将这些字符串连接起来,形成一个以逗号分隔的字符串。这样做可以确保输出的最末尾没有逗号。
my_list = ['ab', 'ba', 'abc']
result = ' , '.join(my_list) #字符串的join方法
print (result)
迭代器(Iterator)是一种计算机编程中的设计模式,用于遍历集合中的元素,而无需暴露集合内部的结构。迭代器提供了一种统一的方式来访问集合中的元素,而不需要关心集合的具体实现方式。
完结,撒花*★,°*:.☆( ̄▽ ̄)/$:*.°★* 。

















 3116
3116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









