






Pandas是一个开源的Python库,是基于NumPy的一种工具,提供了数据结构和数据分析工具,使得Python可以更轻松地处理数据。Pandas的主要数据结构是Series和DataFrame,它们可以用来处理不同类型的数据,如数值型、字符串型、时间序列等。Pandas包含了许多功能,如数据清洗、数据转换、数据合并、数据过滤等,使得数据处理变得更加简单和高效。该库常用于数据分析、数据可视化、机器学习等领域。
Windows下安装(运行管理员模式的终端):pip install pandas
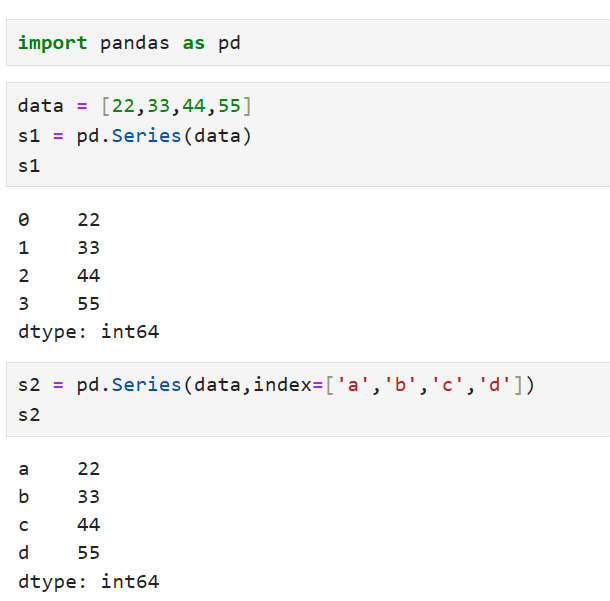
导入pandas模块:import pandas as pd

Pandas有两大主要数据结构:
① Series(一维数据)
② DataFrame(二维数据)
pandas之Series系列:
Series是 Pandas中的一种一维标记型数据结构,类似于一维数组。
Series具有以下一些主要特点:
1. 包含数据:可以是各种数据类型,如整数、浮点数、字符串等。
2. 索引:每个元素都有与之对应的索引。
3. 操作灵活:支持多种数据操作和运算。
函数:pd.Series(data,index,dtype,name,copy=False)
参数:
- data:一组数据(ndarray、list、tuple、dict)
- index:数据索引标签,如果不指定,默认RangeIndex(0,1,2,...,n)
- dtype:数据类型,默认会自己判断
- name:设置名称
- copy:拷贝数据,默认为False

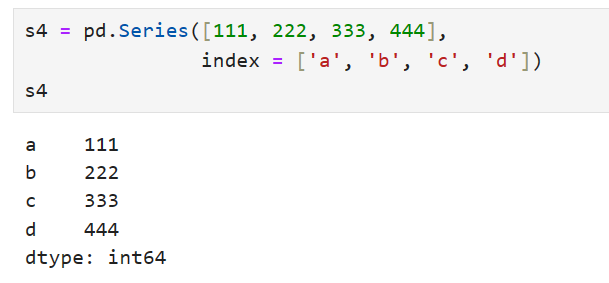
Series的属性:
- .shape 形状属性
- .ndim 维度属性
- .size 元素个数
- .dtype 数据类型
- .empty 数据是否为空
- .index 索引标签,可以通过此属性修改数组的索引
- .values 返回numpy的ndarray数组

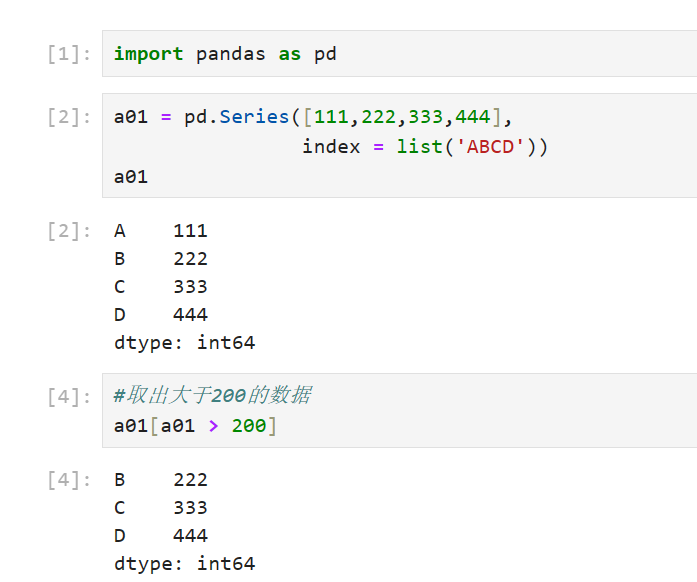
Series索引和切片操作:
Series索引和切片操作和一维的ndarray数组操作相同,同时可以使用标签索引
使用索引切片:

Series布尔掩码操作和一维数组的ndarray掩码操作相同:
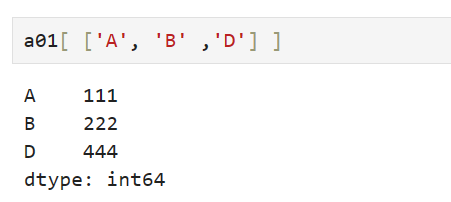
Series标签筛选操作:
在索引过程中使用整数或自定义标签列表或数组可以对Series的数据进行筛选
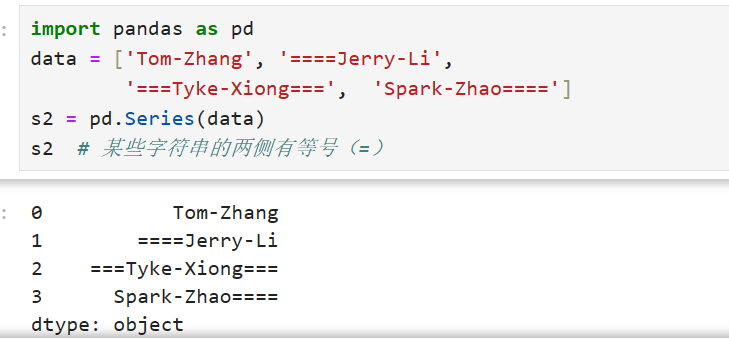
Series的字符串操作:
Pandas中的Series对象支持许多字符串操作,这些操作可以方便地处理Series对象中的文本数据。一些常见的字符串操作包括:
- 字符串长度:使用str.len()方法获取每个字符串的长度。

- 大小写转换:使用str.lower()、str.upper()、str.capitalize()等方法进行大小写转换。
- 字符串拼接:使用str.cat()方法可以将两个字符串的Series对象进行拼接。
- 字符串分割:使用str.split()方法可以按照指定的分隔符将字符串拆分成Series对象。

- 字符串替换:使用str.replace()方法可以替换字符串中的指定子串。

- 字符串匹配:使用str.contains()方法可以判断字符串中是否包含指定的子串。

- 字符串提取:使用str.extract()方法可以提取指定模式的子字符串。
- 字符串去除空格:使用str.strip()方法可以去除字符串两端的空格。

- 字符串索引:使用.str[]可以对字符串进行索引,获取指定位置的字符。
Series的其他常用方法:
Series.isna()/Series.isnull()判断是否为缺失值
Series.fillna(value,inplaceFalse) 填充缺失值
Series.isin(列表或Series) 判断元素是否在指定的容器中
Series.unique() 元素去重
Series. nunique() 去重计数(返回类别个数)
Series.value counts() 元素频数统计
Series.map(函数或字典) 根据输入字典或函数映射Series的值
Series.shift(periods=1) 按索引的方向移动指定的步数

Pandas之DataFrame数据帧:
DataFrame是Pandas中最重要的数据结构之一,它类似于电子表格或数据库中的数据表,是一个二维的、大小可变的、带有行标签和列标签的数据结构。DataFrame可以包含多种数据类型的数据,并且可以进行许多类似于SQL的操作,比如筛选、合并、连接、分组、聚合等。
创建DataFrame可以通过多种方式,比如从字典、数组、列表等数据结构中创建。DataFrame中的每一列都是一个Series对象,可以按列名来访问数据,也可以按照行索引来访问数据。DataFrame也提供了许多方法来处理数据,比如描述性统计、缺失值处理、数据透视等。
Pandas中使用DataFrame可以方便快速地进行数据处理和分析,适用于各种数据分析任务,比如数据清洗、数据可视化、模型训练等。
DataFrame具有以下特点:
1.列可以是不同的类型
2.大小可变
3.行和列都支持自定义索引
4.针对行与列进行轴向统计(水平,垂直)
函数:
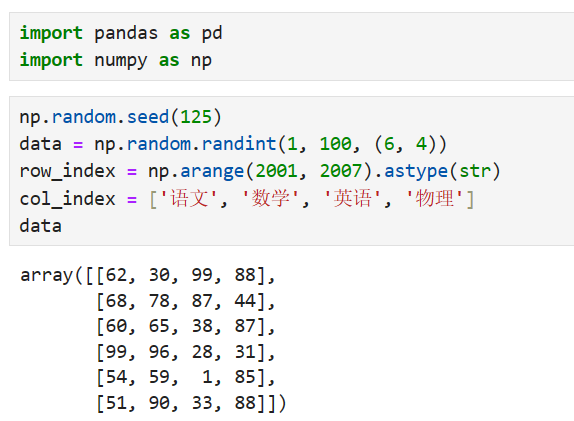
pandas.DataFrame(data=数据,index=索引,columns=列标签,dtype=类型,copy=False)
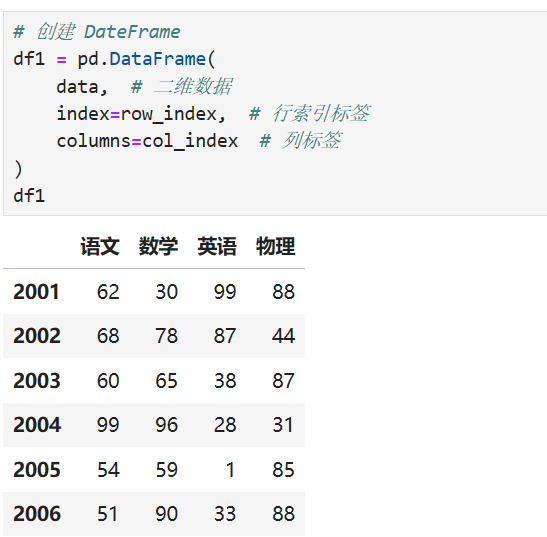
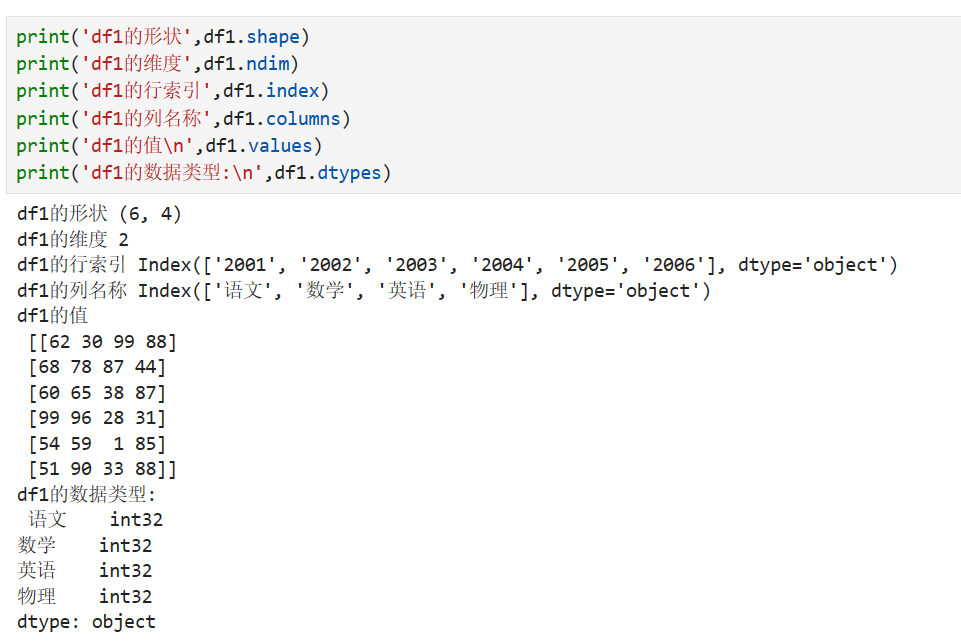
DataFrame的属性:
DataFrame具有许多属性,这些属性可以帮助我们了解DataFrame的结构和内容。以下是一些常用的DataFrame属性:
- shape:返回DataFrame的行数和列数。
- columns:返回DataFrame的列标签。
- index:返回DataFrame的行索引。
- dtypes:返回DataFrame每一列的数据类型。
- values:返回DataFrame中的数据,以二维数组的形式呈现。
- empty:返回一个布尔值,表示DataFrame是否为空。
- size:返回DataFrame中的总元素个数。
- ndim:返回DataFrame的维度,一般为2。
- loc:用标签来访问行和列的数据。
- iloc:用整数位置来访问行和列的数据。
- head():返回DataFrame的前几行,默认前5行。
- tail():返回DataFrame的后几行,默认后5行。
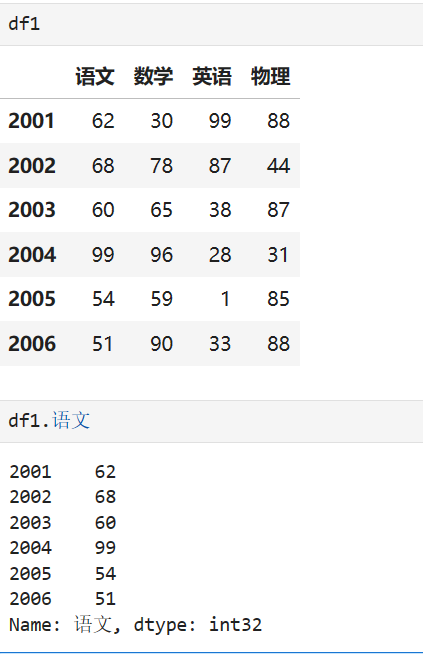
DataFrame的索引操作:
对单列数据的访问并返回Series
DataFrame['列名']
#或
DataFrame.列名 #列名必须为 变量名的命名规则
对多列数据的访问并返回DataFrame
DataFrame[['列名1,'列名2,'列名3'...]]
DataFrame添加列:
用等长度的数组或者系列增加一列
DataFrame['新列名']= 数组或系列
示例
df1['化学’] =np.random.randint(1,100, 6)
df1

DataFrame删除列:
用del语句删除一列
del DataFrame['列名']
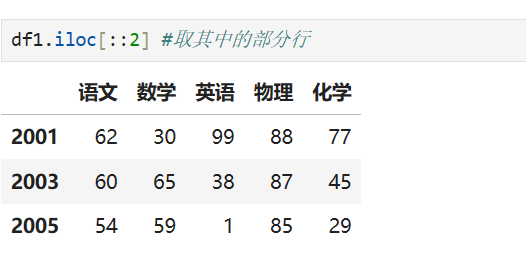
DataFrame行的访问
如果只是需要访问DataFrame某几行数据的实现方式则采用数组的切片直接选取并返回切片后的DataFrame。
语法
DataFrame[开始行索引:结束行索引:步长]
DataFrame的loc和iloc属性
用DataFrame.iloc属性,可以将DataFrame看成是二维数组,可以使用整数对DataFrame的行进行索引和切片操作。
- 语法
DataFrame.iloc[整数、整数列表、切片或者布尔掩码的数组]
用DataFrame.oc属性,可以使用标签对DataFrame的行进行索引和切片操作。
- 语法
DataFrame.loc[标签索引或切片]
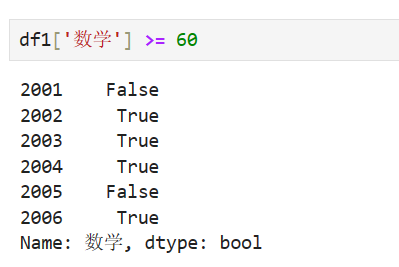
DataFrame的掩码操作同numpy 的ndarray掩码操作基本一致,掩码可以使用存储布尔数据类型的Series或者numpy的一维数组。
DataFrame常用的方法:包括数据选择、筛选、排序、合并、聚合以及数据处理等,以下是一些常用的DataFrame方法:
- head():返回DataFrame的前几行,默认前5行。
- tail():返回DataFrame的后几行,默认后5行。
- describe():对DataFrame中的数值型数据进行描述性统计分析。
- info():显示DataFrame的基本信息,包括每列的非空值个数和数据类型。
- dropna():删除包含缺失值的行或列。
- fillna():填充缺失值。
- drop_duplicates():删除重复行。
- groupby():按照指定的列或列组进行分组。
- sort_values():按照指定的列对数据进行排序。
- merge():合并两个DataFrame。
- concat():沿指定轴合并多个DataFrame。
- apply():对DataFrame中的数据进行自定义函数处理。
- plot():绘制DataFrame中数据的图表。
- to_csv():将DataFrame保存为CSV文件。
- to_excel():将DataFrame保存为Excel文件。















 1495
1495











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









