







1. PyTorch环境的配置及安装
anacond安装及配置
点击下载链接进入anaconda历史版本,选择Anaconda3-5.2.0-Windows-x86_64.exe版本安装
记录安装位置:

配置环境变量:
安装成功:
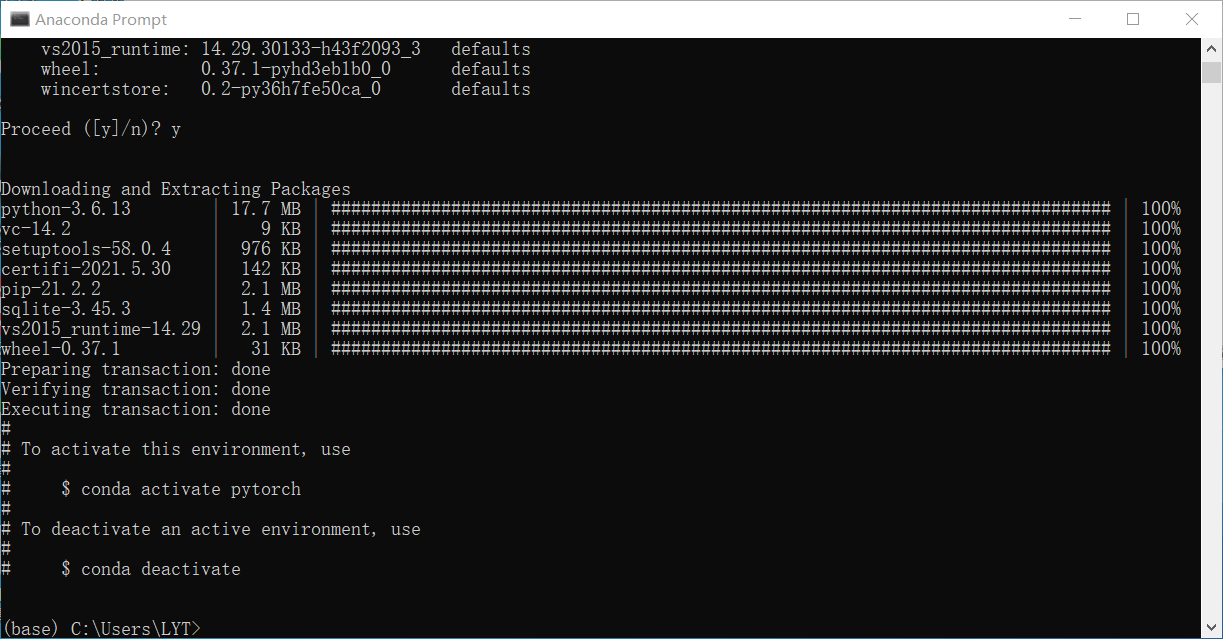
使用anaconda prompt创建一个pytorch环境
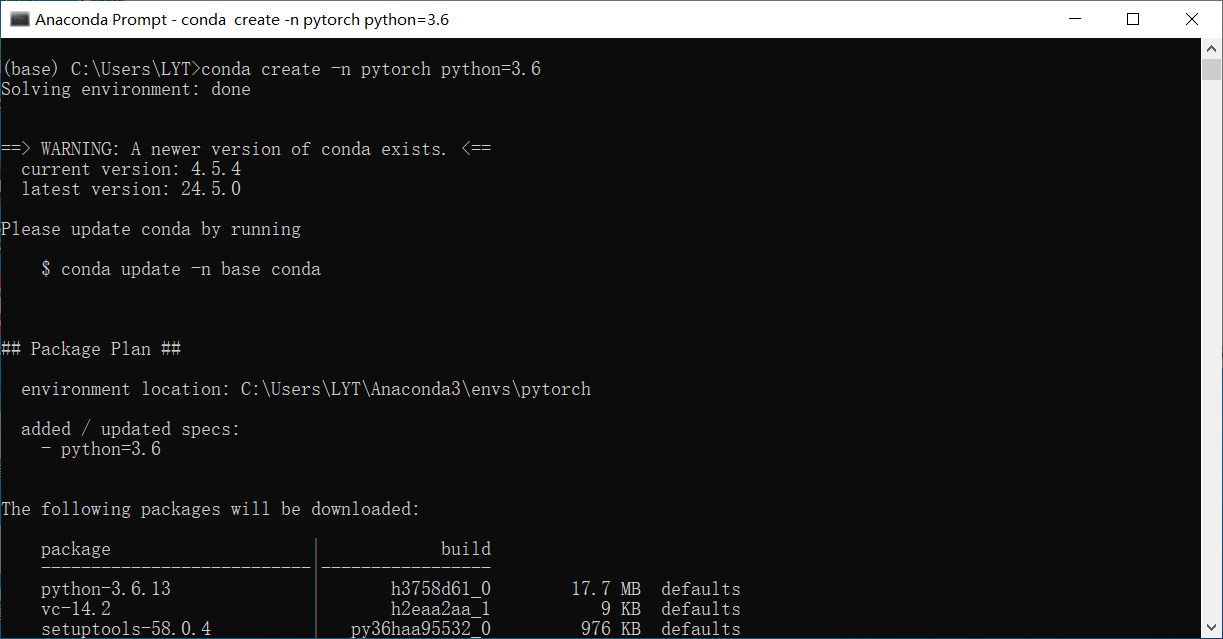
中间遇到Solving environment: failed报错可以看一下这篇文章方法二
安装成功如下图:
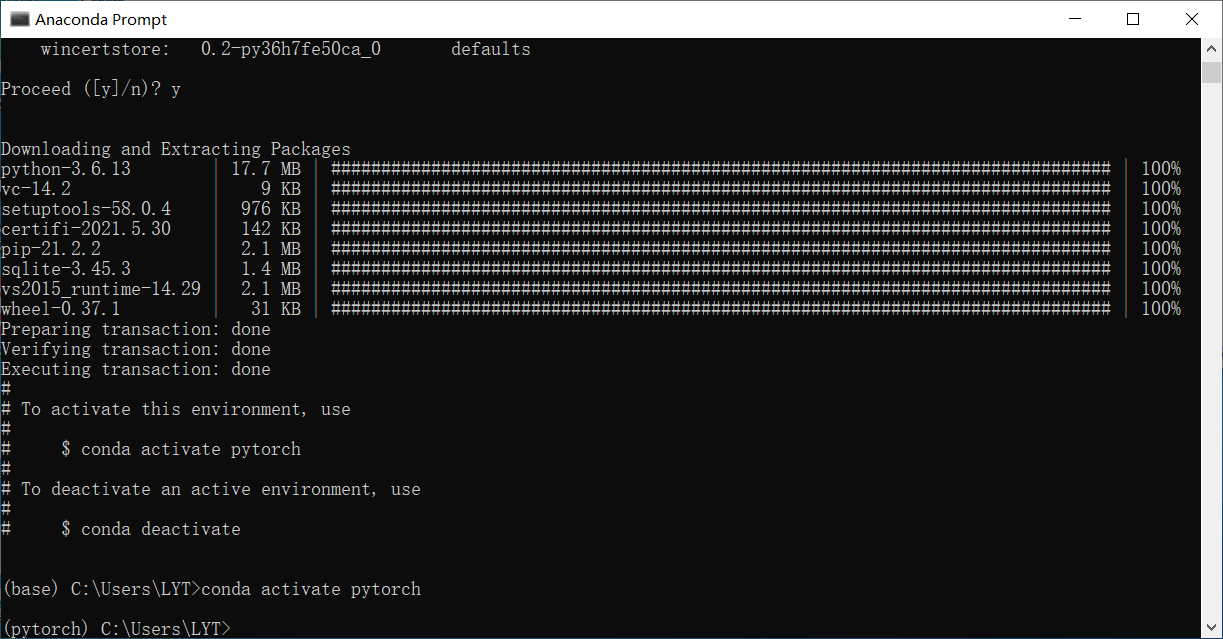
pytorch安装
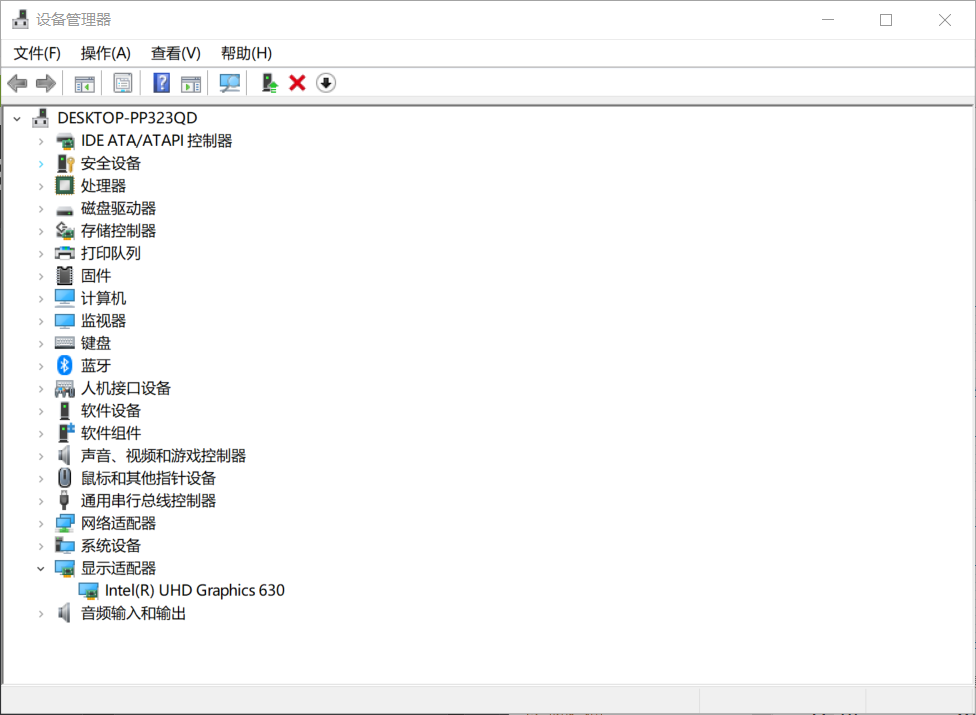
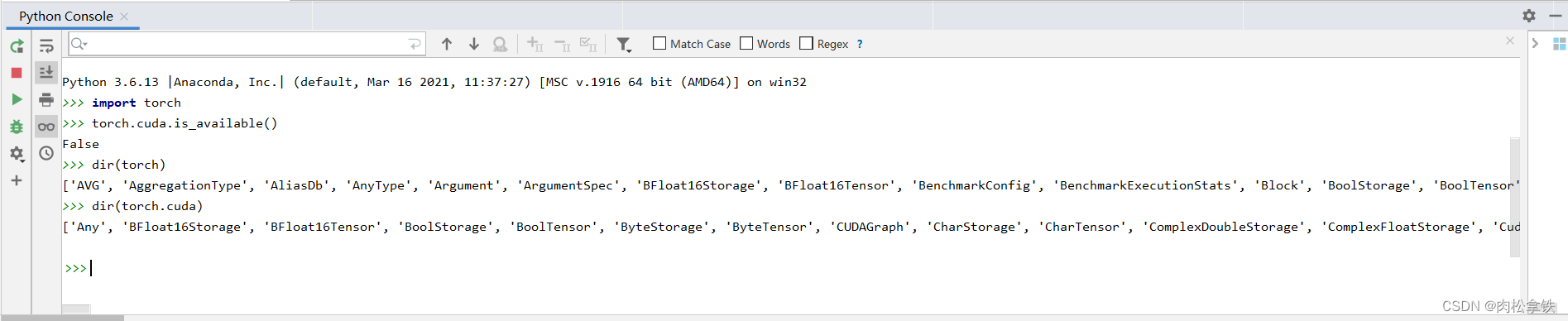
查看GPU型号
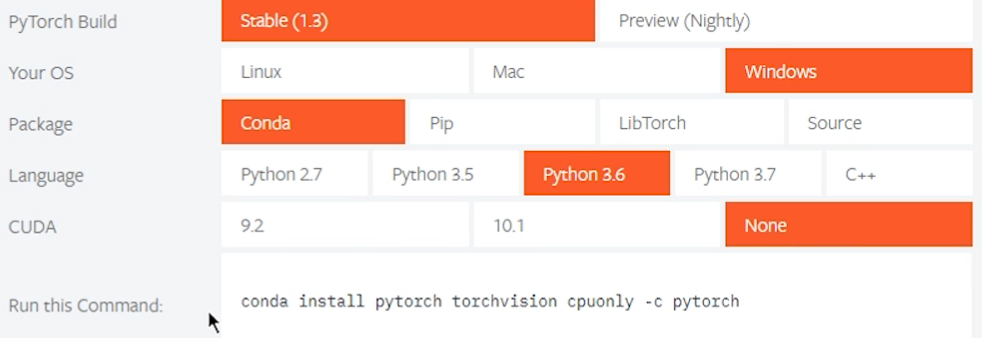
我的电脑没有Nvidia独立显卡,安装pytorch时不选择cuda版本
无显卡安装命令如下,在anaconda prompt中输入该命令:
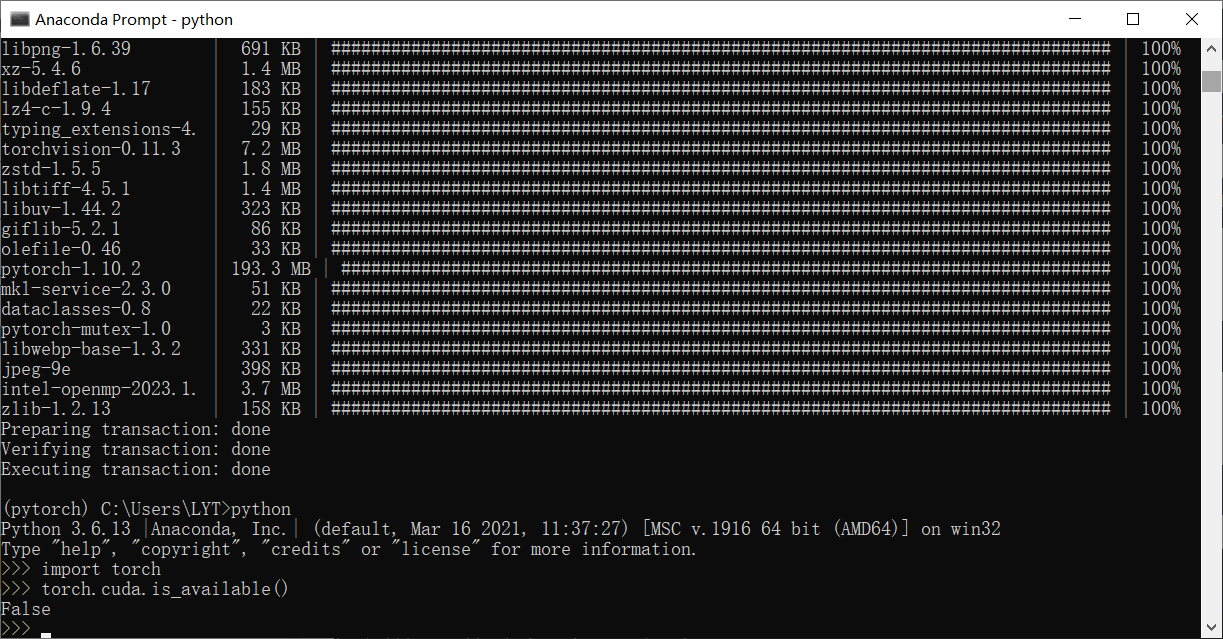
安装成功,因为我的电脑没有nvidia显卡所以返回false:
python编译器的选择、安装及配置
pycharm安装
下载地址 我选择的是社区版2019.2.4-Windows(exe)

记录安装位置
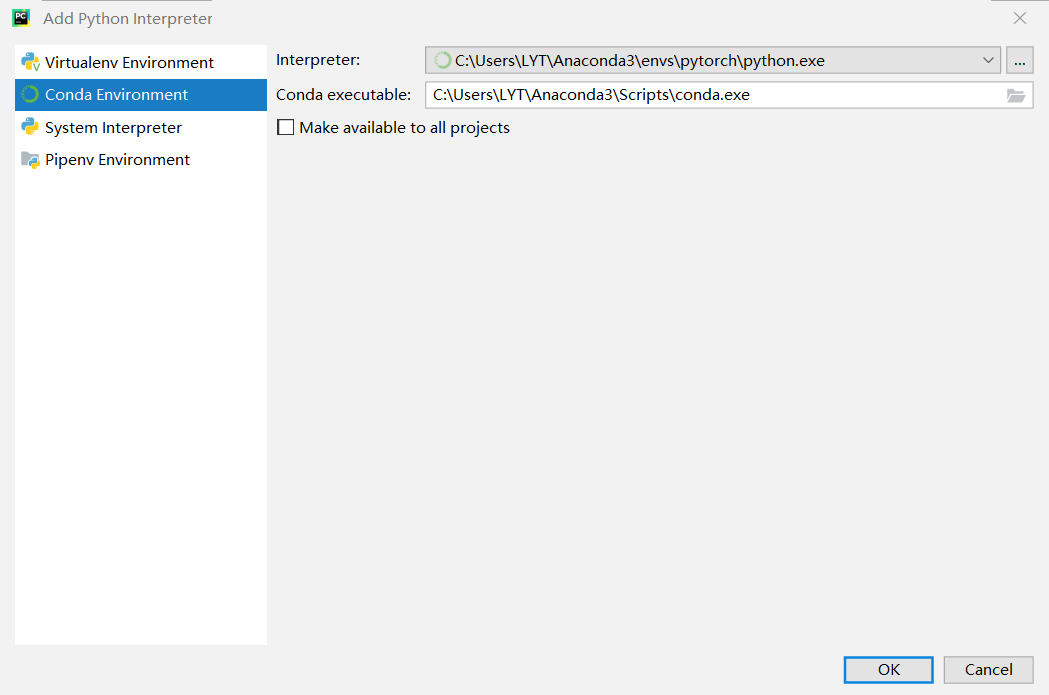
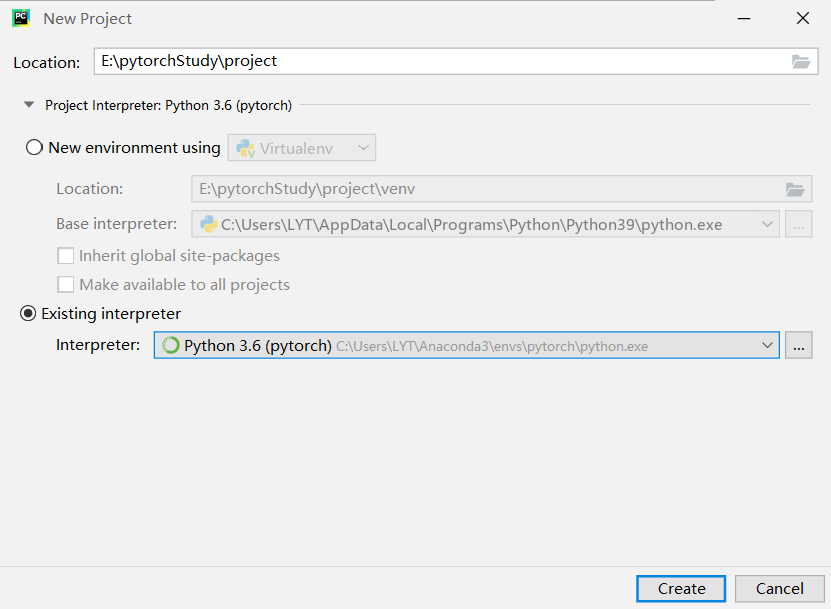
安装成功后创建项目:
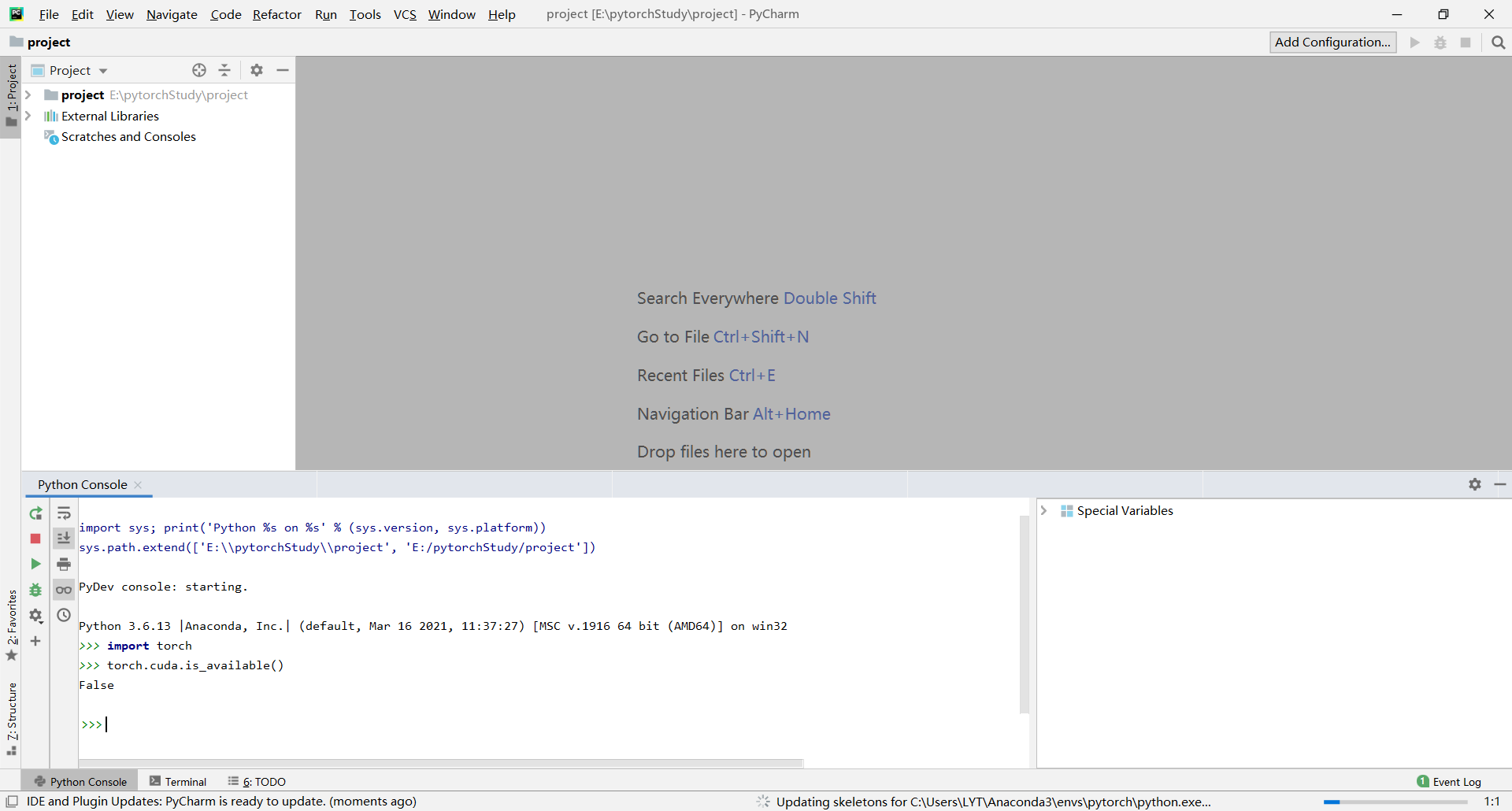
显示如下则成功:
Jupyter
Jupyter地址
annaconda安装后jupyter也安装成功啦
在pytorch环境中安装Jupyter,打开anaconda prompt
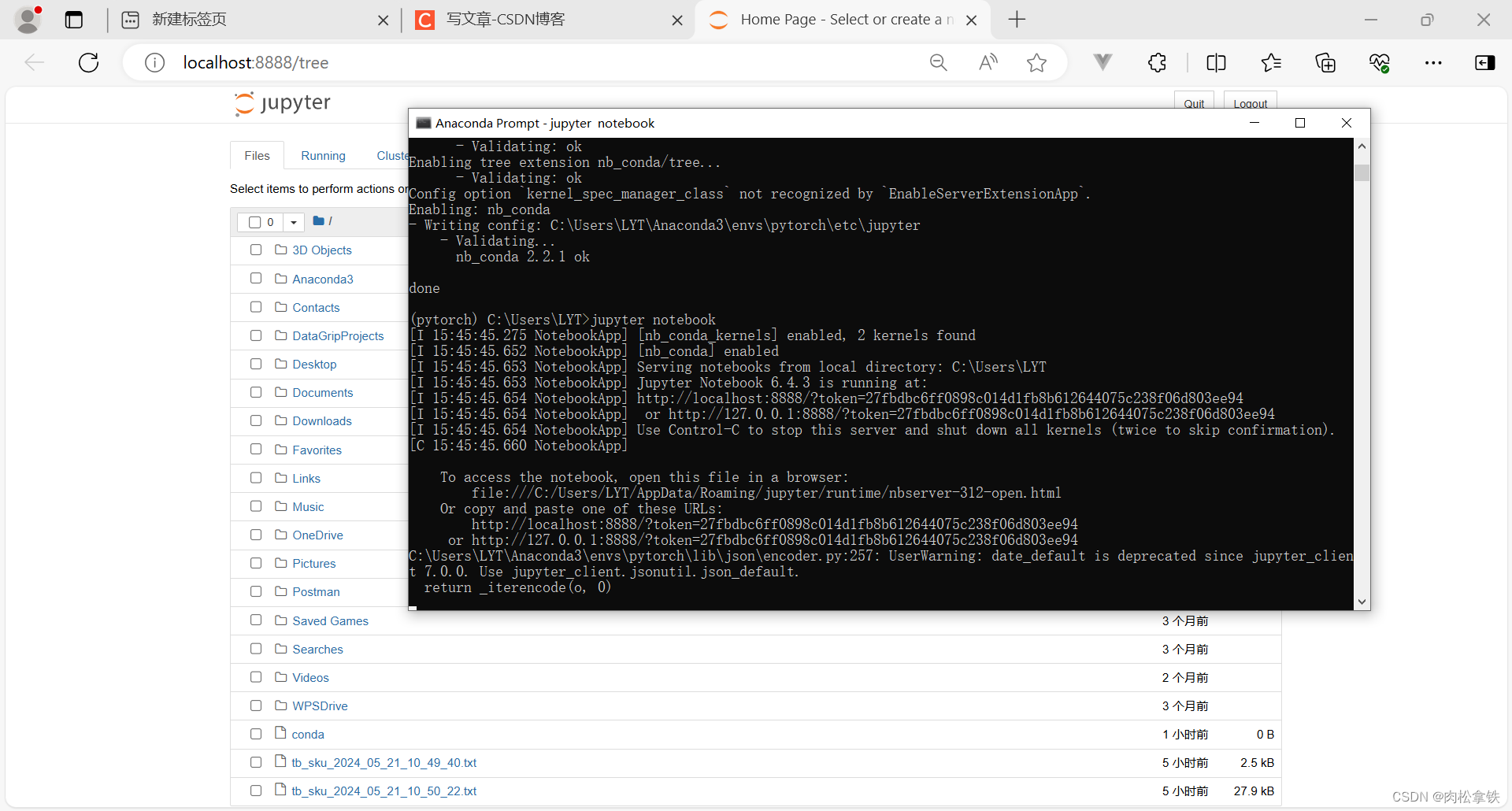
安装完成输入jupyter notebook弹出Home Page页面则成功
点击new
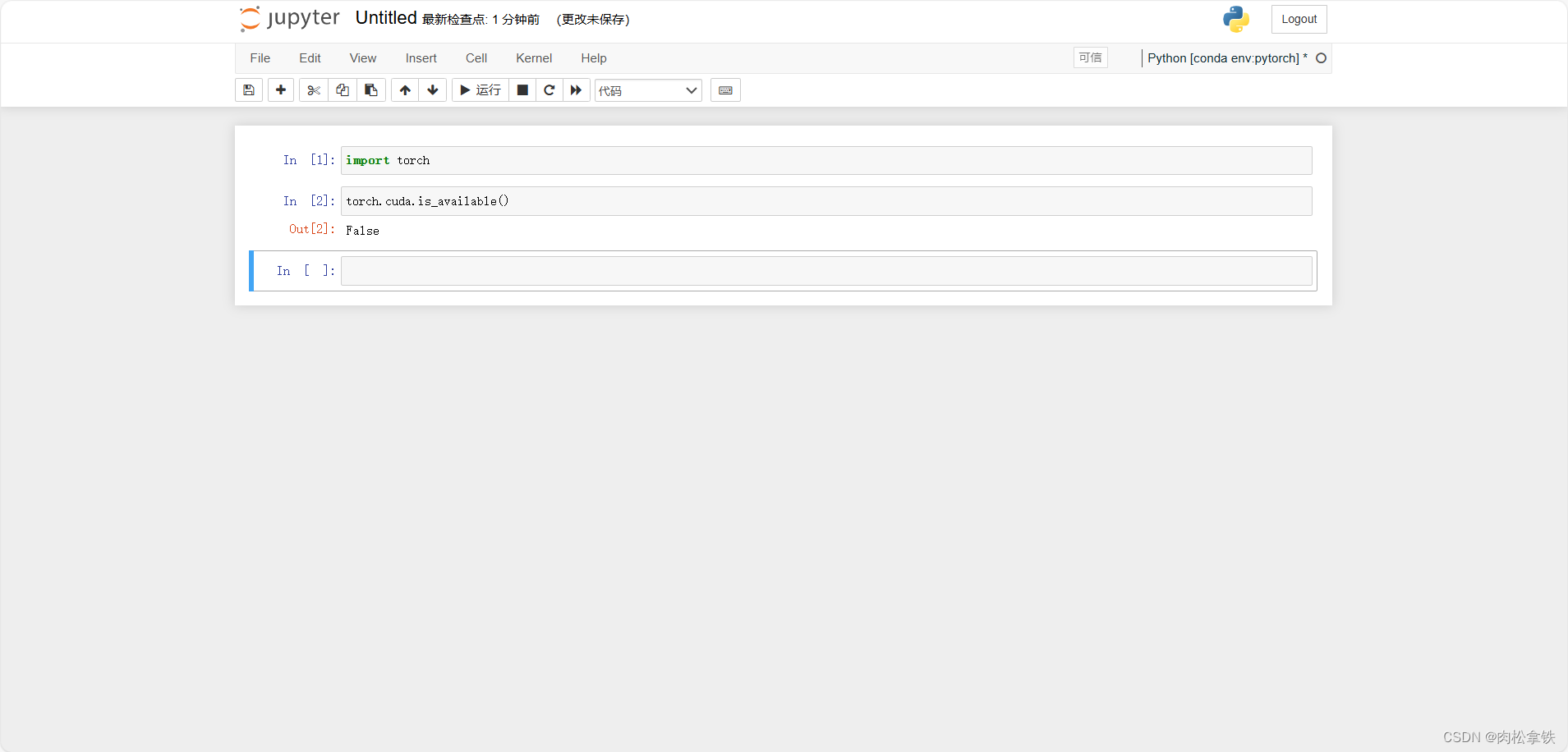
测试pytorch,成功如下图:
python学习中的两大法宝函数
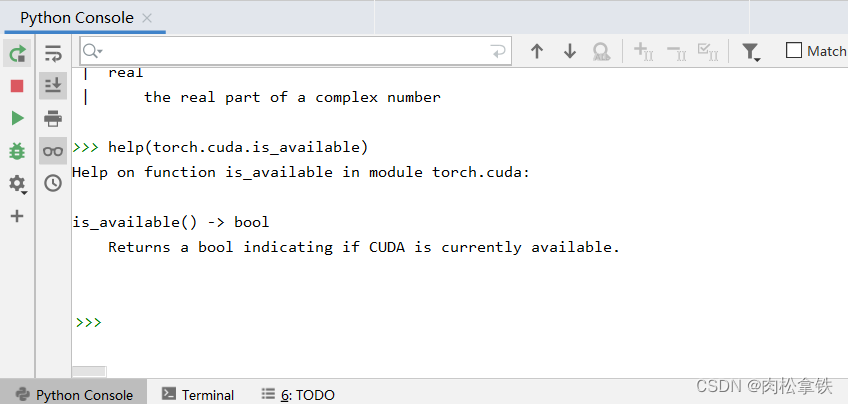
dir():打开,看见
help():说明书
Pytorch加载数据
Dataset:提供一种方式去获取数据及label
- 如何获取每一个数据及label
- 告诉我们总共有多少个数据
Dataloader:为网络提供不同数据形式
下载一个数据集
数据集 hymenoptera_data(识别蚂蚁和蜜蜂的数据集,二分类)
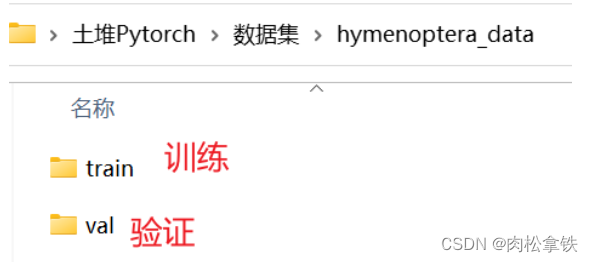
- train 里有两个文件夹:ants 和 bees,其中分别都是一些蚂蚁和蜜蜂的图片
- train_images是一个文件夹,train_labels是另一个文件夹,如OCR数据集
- label直接为图片的名称
from torch.utils.data import Dataset
from PIL import Image
import os
class MyData(Dataset):
def __init__(self, root_dir, label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir, self.label_dir)
self.img_path = os.listdir(self.path)
def __getitem__(self, idx):
img_name = self.img_path[idx]
img_item_path = os.path.join(self.root_dir,self.label_dir,img_name)
img = Image.open(img_item_path)
label = self.label_dir
return img, label
def __len__(self):
return len(self.img_path)
root_dir = "dataset/train"
ants_label_dir = "ants"
bees_label_dir = "bees"
ants_dataset = MyData(root_dir, ants_label_dir)
bees_dataset = MyData(root_dir, bees_label_dir)
train_dataset = ants_dataset + bees_dataset
TensorBoard
安装tensorboard
pip install tensorboard
SummaryWriter类
add_scalar() 方法的使用
def add_scalar(
self,
tag, # Data指定方式,类似于图表的title
scalar_value, # scalar_value:需要保存的数值(y轴)
global_step=None, # global_step:训练到多少步(x轴)
walltime=None,
new_style=False,
double_precision=False,
):

# writer.add_image()
# y = x
for i in range(100):
writer.add_scalar("y = 2x", 2 * i, i)
writer.close()

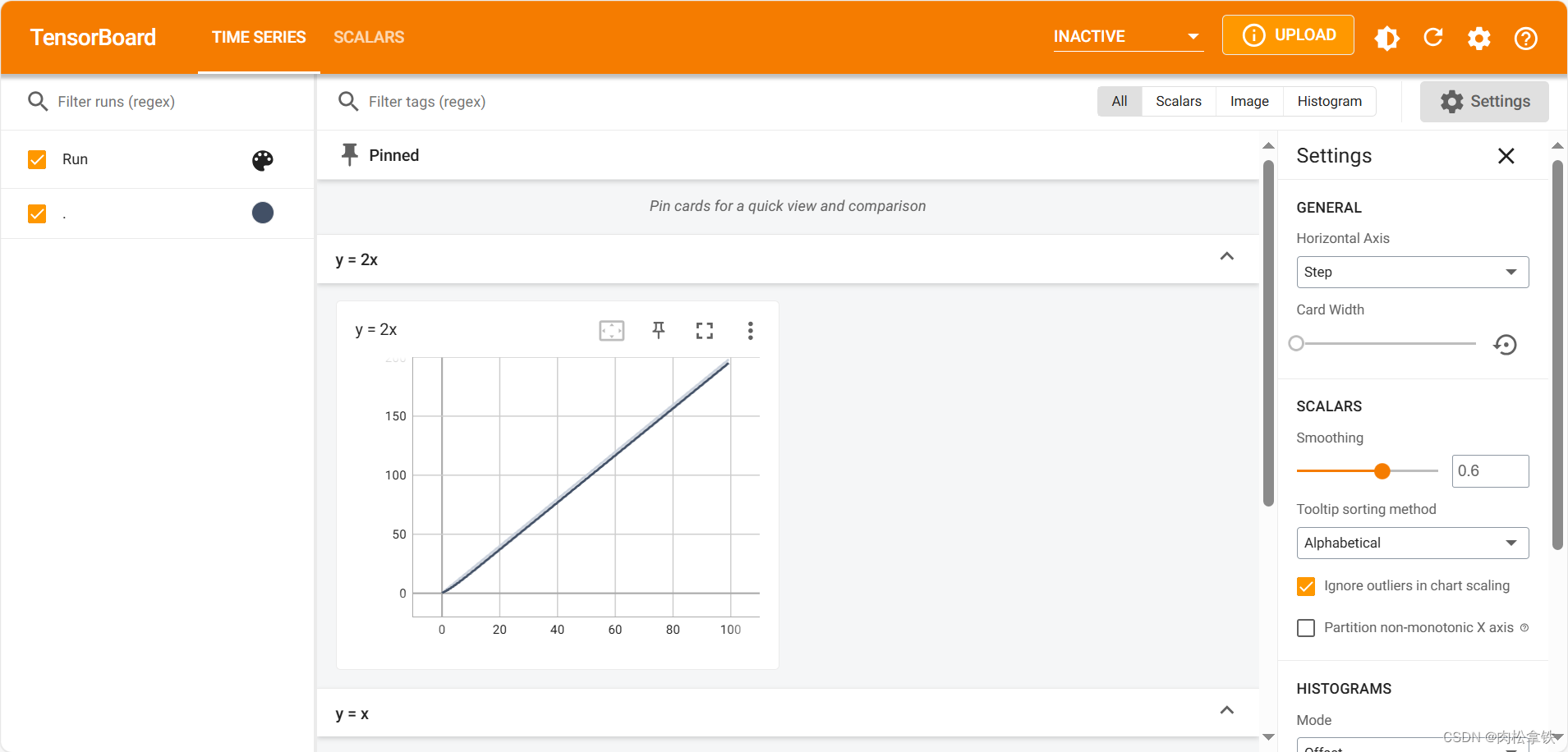
每向 writer 中写入新的事件,也记录了上一个事件
如何解决?
把logs文件夹下的所有文件删掉,程序删掉,重新开始
或:重新写一个子文件,即创建新的 SummaryWriter(“新文件夹”)
删掉logs下的文件,重新运行代码,在 Terminal 里按 Ctrl+C ,再输入命令: tensorboard
–logdir=logs --port=6007
以上即是显示 train_loss 的一个方式
add_image() 的使用
def add_image(self, tag, img_tensor, global_step=None):
1. tag:对应图像的title
2. img_tensor:图像的数据类型,只能是torch.Tensor、numpy.array、string/blobname
3. global_step:训练步骤,int 类型
在python控制台输入
# 打开控制台,其位置就是项目文件夹所在的位置
# 故只需复制相对地址
image_path = "data/train/ants_image/0013035.jpg"
from PIL import Image
img = Image.open(image_path)
print(type(img))
利用numpy.array(),对PIL图片进行转换
在Python控制台,把PIL类型的img变量转换为numpy类型(add_image() 函数所需要的图像的数据类型),重新赋值给img_array:
import numpy as np
img_array=np.array(img)
print(type(img_array)) # numpy.ndarray
从PIL到numpy,需要在add_image()中指定shape中每一个数字/维表示的含义
step1:蚂蚁为例
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
# 创建实例
writer = SummaryWriter("logs") # 把对应的事件文件存储到logs文件夹下
image_path = 'dataset/train/ants/5650366_e22b7e1065.jpg'
img_PIL = Image.open(image_path)
img_array = np.array(img_PIL)
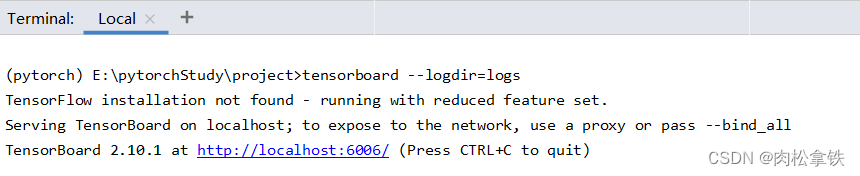
writer.add_image('test', img_array, 2, dataformats='HWC')
writer.close()
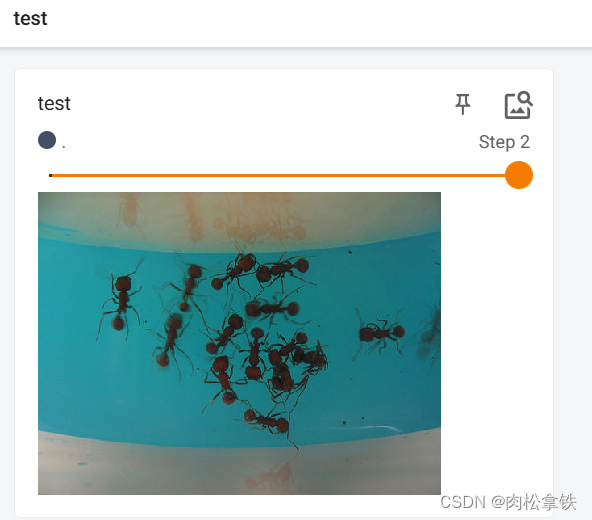
在一个title下,通过滑块显示每一步的图形,可以直观地观察训练中给model提供了哪些数据,或者想对model进行测试时,可以看到每个阶段的输出结果
如果想要单独显示,重命名一下title即可,即 writer.add_image() 的第一个字符串类型的参数
transforms
图像变换
transforms的结构及用法
from torchvision import transforms
transforms一些类:
- Compose类:结合不同的transforms
- ToTensor类:把一个PIL的Image或者numpy数据类型的图片转换成 tensor 的数据类型
- ToPILImage类:把一个图片转换成PIL Image
- Normalize类:归一化
- Resize类:尺寸变换
- CenterCrop类:中心裁剪
python的用法
tensor数据类型
通过transforms.ToTensor去看两个问题
- transforms该如何使用
from PIL import Image
from torchvision import transforms
# 相对路径
img_path = 'dataset/train/ants/0013035.jpg'
img = Image.open(img_path)
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img) # 将img类型转换为Tensor
print(tensor_img)

- Tensor数据类型
在Python Console输入:
from PIL import Image
from torchvision import transforms
img_path= "data/train/ants_image/0013035.jpg"
img = Image.open(img_path)
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
再打开tensor_img,看一下它有哪些参数:
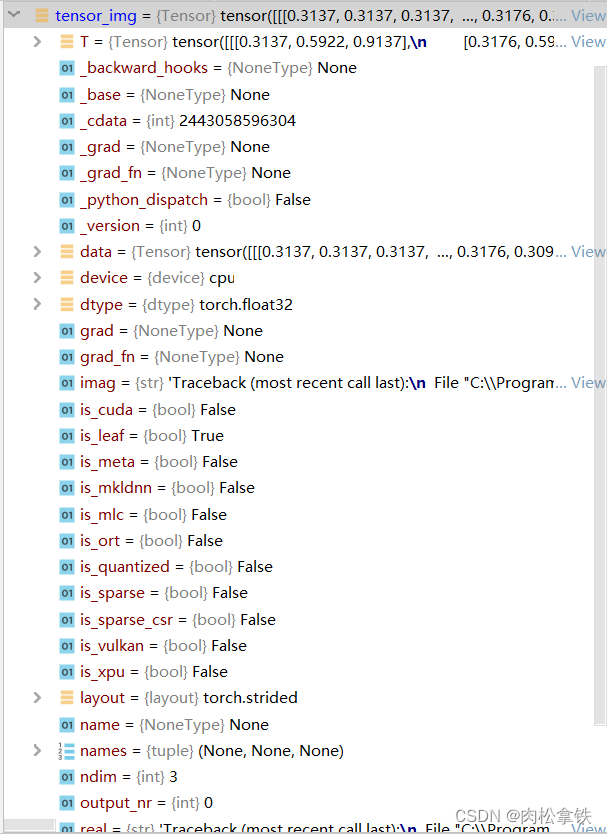
Tensor 数据类型包装了反向神经网络所需要的一些理论基础的参数,如:_backward_hooks、_grad等(先转换成Tensor数据类型,再训练)
两种读取图片方式
- PIL Image
from PIL import Image
img_path = "xxx"
img = Image.open(img_path)
img.show()
- numpy.ndarray(通过opencv)
下载opencv库:参考博文
import cv2
cv_img=cv2.imread(img_path)
使用torch.Tensor图片类型
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
# python的用法 ——> tensor数据类型
# 通过 transforms.ToTensor去解决两个问题
# 1、Transforms该如何使用
# 2、Tensor数据类型与其他图片数据类型有什么区别?为什么需要Tensor数据类型
# 绝对路径 C:\Users\11842\Desktop\Learn_torch\data\train\ants_image\0013035.jpg
# 相对路径 data/train/ants_image/0013035.jpg
img_path = "dataset/train/ants/0013035.jpg" # 用相对路径,绝对路径里的\在Windows系统下会被当做转义符
img = Image.open(img_path) # Image是Python中内置的图片的库
writer = SummaryWriter("logs")
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
writer.add_image("Tensor_img", tensor_img)
writer.close()
运行后,在 Terminal 里输入:
tensorboard --logdir=logs
常见的Transforms
Compose 的使用
把不同的 transforms 结合在一起,后面接一个数组,里面是不同的transforms
transforms.Compose([
transforms.CenterCrop(10),
transforms.PILToTensor(),
transforms.ConvertImageDtype(torch.float),
])
call_ 的用法
内置函数 call ,不用.的方式调用方法,可以直接拿对象名,加上需要的参数,即可调用方法
class Person:
def __call__(self, name): #下划线__表示为内置函数
print("__call__"+"Hello "+name)
def hello(self,name):
print("hello"+name)
person = Person()
person("zhangsan")
person.hello("lisi")
输出结果如下:

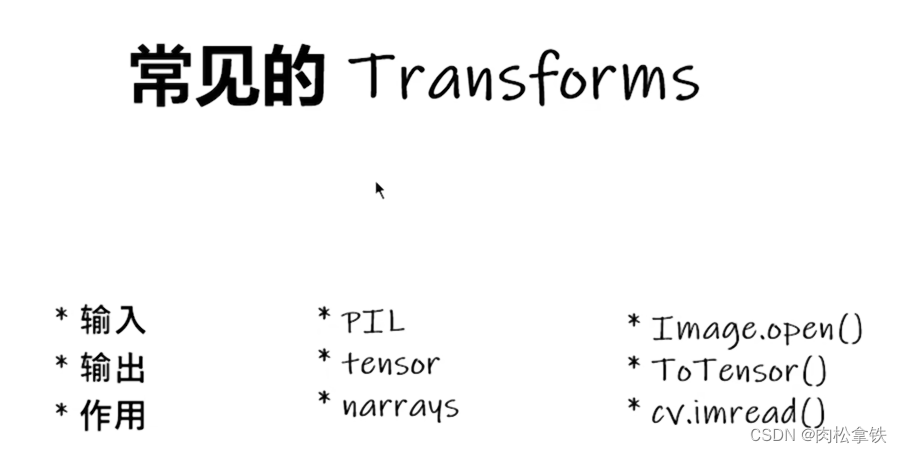
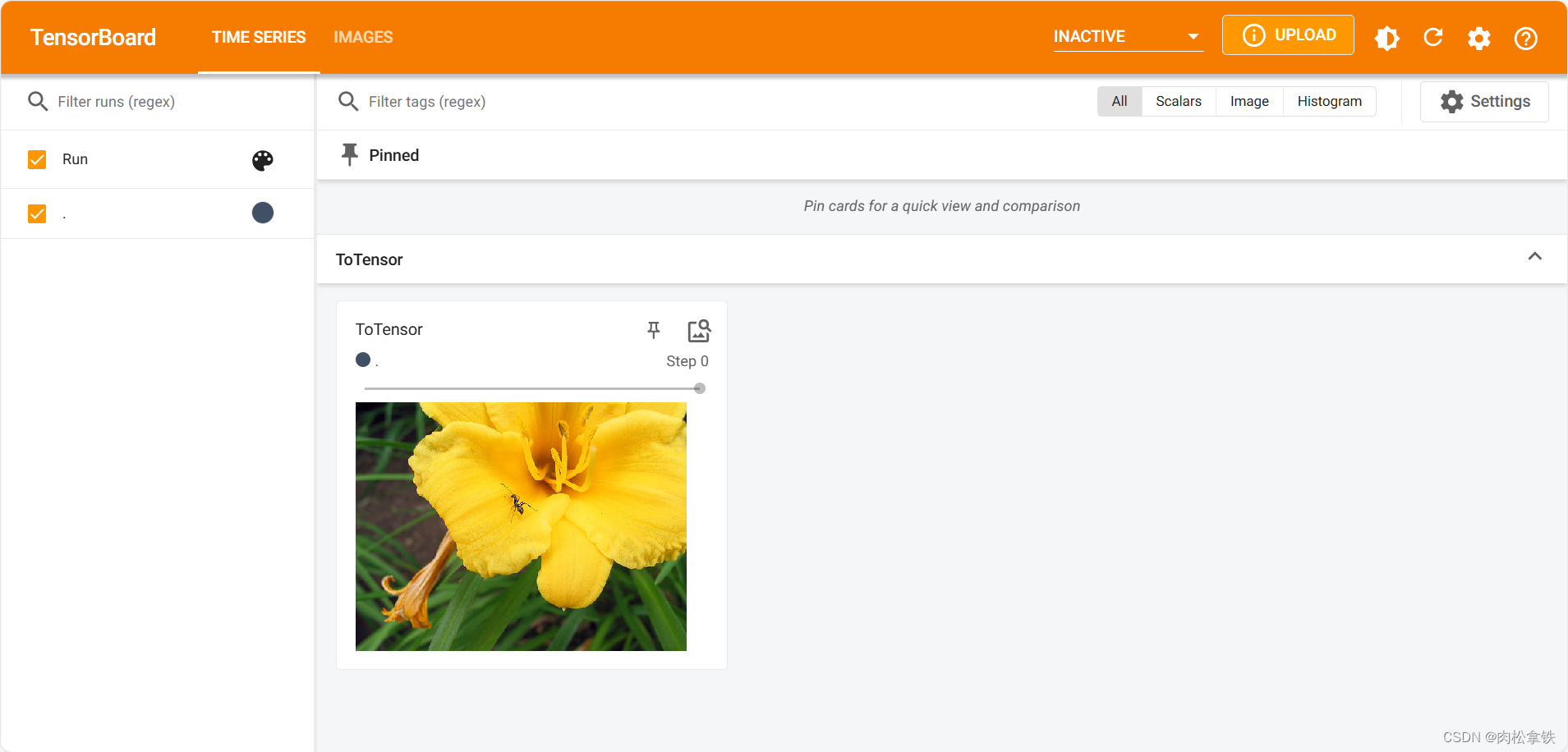
ToTensor 的使用
把 PIL Image 或 numpy.ndarray 类型转换为 tensor 类型(TensorBoard 必须是 tensor 的数据类型)
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter("logs")
img = Image.open("dataset/train/ants/24335309_c5ea483bb8.jpg")
print(img)
# ToTensor
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
writer.add_image("ToTensor", img_tensor)
writer.close()
运行后,在 Terminal 里输入:
tensorboard --logdir=logs
ToPILImage 的使用
把 tensor 数据类型或 ndarray 类型转换成 PIL Image
Normalize 的使用
用平均值/标准差归一化 tensor 类型的 image(输入)
图片RGB三个信道,将每个信道中的输入进行归一化
归一化计算公式
output[channel] = (input[channel] - mean[channel]) / std[channel]
设置 mean 和 std 都为0.5,则 output= 2*input -1。如果 input 图片像素值为0~1范围内,那么结果就是 -1~1之间
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter("logs")
img = Image.open("dataset/train/ants/24335309_c5ea483bb8.jpg")
print(img)
# ToTensor
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
writer.add_image("ToTensor", img_tensor)
writer.close()
# Normalize
# 第0层第0行第0列
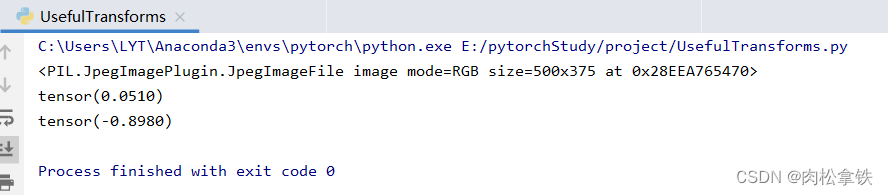
print(img_tensor[0][0][0])
# mean,std,因为图片是RGB三信道,故传入三个数
trans_norm = transforms.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
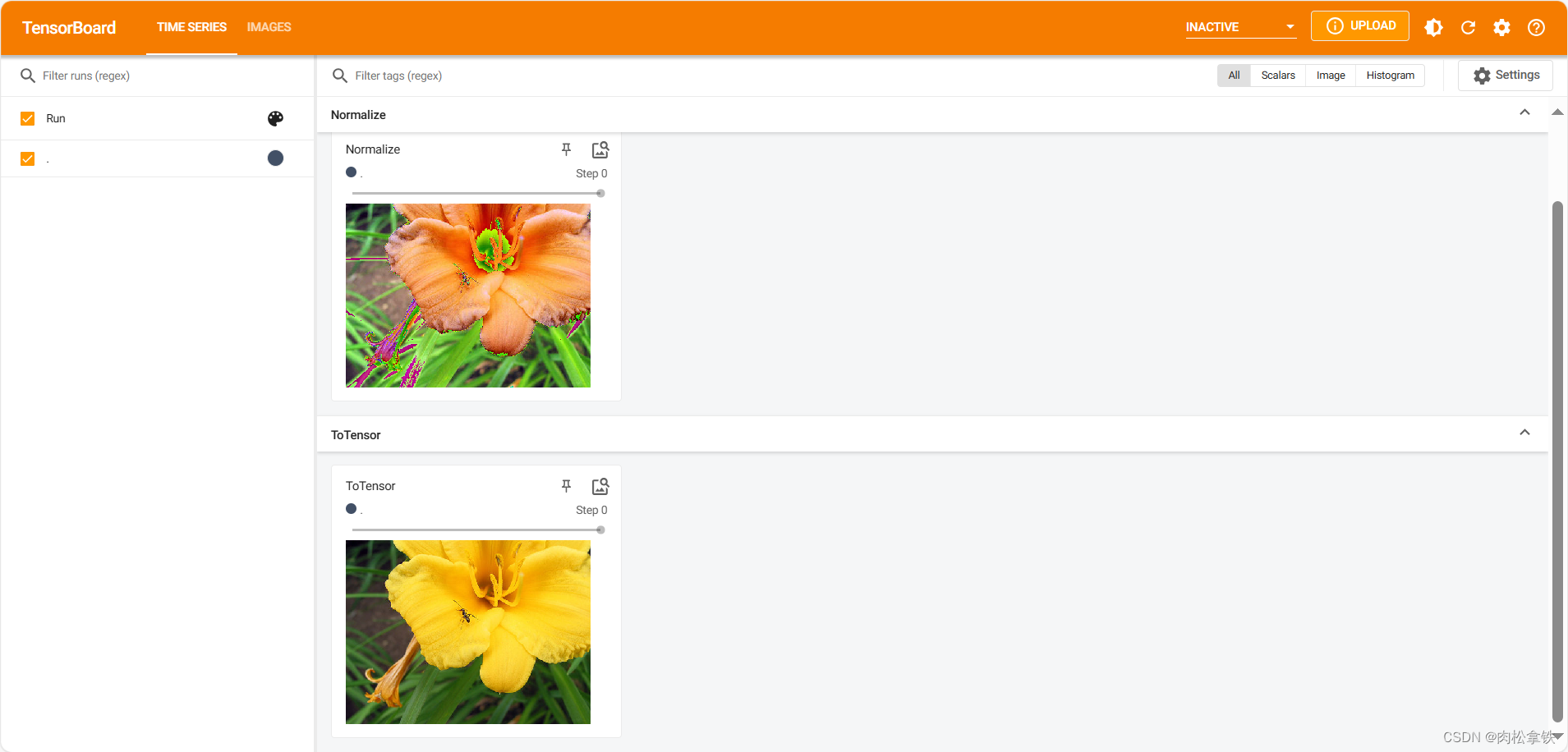
writer.add_image("Normalize", img_norm)
writer.close()
加入step(效果夸张一点):
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter("logs")
img = Image.open("dataset/train/ants/24335309_c5ea483bb8.jpg")
print(img)
# ToTensor
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
writer.add_image("ToTensor", img_tensor)
writer.close()
# Normalize
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([1,3,5], [2,4,6])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
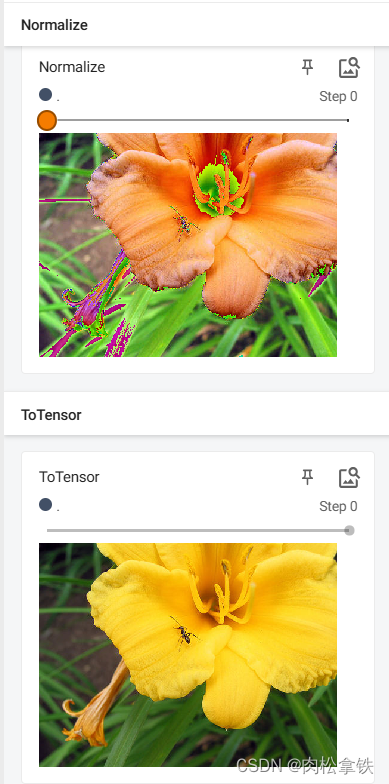
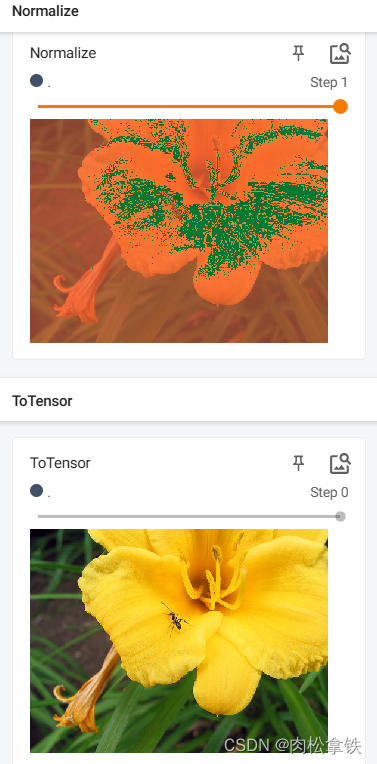
writer.add_image("Normalize", img_norm, 1)
writer.close()
step0:
step1:
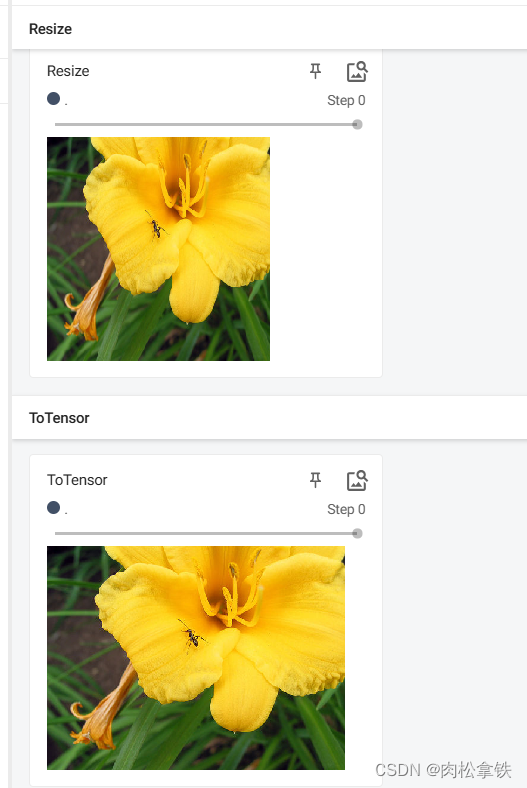
Resize() 的使用
输入:PIL Image 将输入转变到给定尺寸
- 序列:(h,w)高度,宽度
- 一个整数:不改变高和宽的比例,只单纯改变最小边和最长边之间的大小关系。之前图里最小的边将会匹配这个数(等比缩放)
PyCharm小技巧设置:忽略大小写,进行提示匹配
- 一般情况下,你需要输入R,才能提示出Resize
- 我们想设置,即便你输入的是r,也能提示出Resize,也就是忽略了大小写进行匹配提示
File—> Settings—> 搜索case—> Editor-General-Code Completion-去掉Match case前的√—>Apply—>OK
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter("logs")
img = Image.open("dataset/train/ants/24335309_c5ea483bb8.jpg")
print(img)
# ToTensor
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
writer.add_image("ToTensor", img_tensor)
writer.close()
# Normalize
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([1,3,5], [2,4,6])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize", img_norm, 1)
writer.close()
# Resize
print(img.size)
trans_resize = transforms.Resize((512,512))
# img PIL -> img_resize PIL
img_resize = trans_resize(img)
# img_resize PIL -> img_resize ToTensor
img_resize = trans_totensor(img_resize)
print(img_resize)
writer.add_image("Resize", img_resize, 0)
writer.close()
图片尺寸改变
Compose() 的使用
Compose() 中的参数需要是一个列表,Python中列表的表示形式为[数据1,数据2,…]
在Compose中,数据需要是transforms类型,所以得到Compose([transforms参数1,transforms参数2,…])
# Compose - resize - 2
# Compose的使用(将输出类型从PIL变为tensor类型,第二种方法)
trans_resize2 = transforms.Resize(512)
# img PIL -> img_resize PIL -> Tensor
trans_compose = transforms.Compose([trans_resize2, trans_totensor])
img_resize2 = trans_compose(img)
writer.add_image("Resize",img_resize2,1)
writer.close()
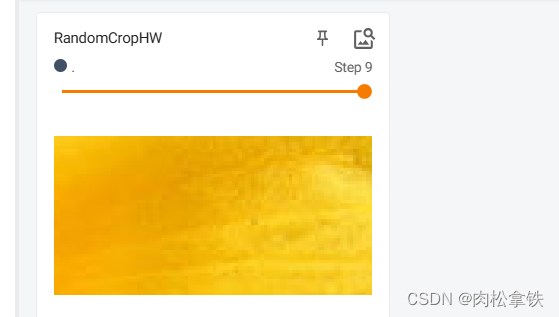
RandomCrop() 的使用
随机裁剪,输入PIL Image
参数size:
- sequence:(h,w) 高,宽
- int:裁剪一个该整数×该整数的图像
(1)以 int 为例:
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter("logs")
img = Image.open("dataset/train/ants/24335309_c5ea483bb8.jpg")
print(img)
# ToTensor
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
writer.add_image("ToTensor", img_tensor)
writer.close()
# Normalize
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([1,3,5], [2,4,6])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize", img_norm, 1)
writer.close()
# Resize
print(img.size)
trans_resize = transforms.Resize((512,512))
# img PIL -> img_resize PIL
img_resize = trans_resize(img)
# img_resize PIL -> img_resize ToTensor
img_resize = trans_totensor(img_resize)
print(img_resize)
writer.add_image("Resize", img_resize, 0)
writer.close()
# Compose - resize - 2
trans_resize2 = transforms.Resize(512)
# img PIL -> img_resize PIL -> Tensor
trans_compose = transforms.Compose([trans_resize2, trans_totensor])
img_resize2 = trans_compose(img)
writer.add_image("Resize",img_resize2,1)
# RandomCrop
trans_random = transforms.RandomCrop(50)
trans_compose_2 = transforms.Compose([trans_random,trans_totensor])
for i in range(10):
img_crop = trans_compose_2(img)
writer.add_image('RandomCrop',img_crop,i)
writer.close()

(2)以 sequence 为例:
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter("logs")
img = Image.open("dataset/train/ants/24335309_c5ea483bb8.jpg")
print(img)
# ToTensor
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
writer.add_image("ToTensor", img_tensor)
writer.close()
# Normalize
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([1,3,5], [2,4,6])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize", img_norm, 1)
writer.close()
# Resize
print(img.size)
trans_resize = transforms.Resize((512,512))
# img PIL -> img_resize PIL
img_resize = trans_resize(img)
# img_resize PIL -> img_resize ToTensor
img_resize = trans_totensor(img_resize)
print(img_resize)
writer.add_image("Resize", img_resize, 0)
writer.close()
# Compose - resize - 2
trans_resize2 = transforms.Resize(512)
# img PIL -> img_resize PIL -> Tensor
trans_compose = transforms.Compose([trans_resize2, trans_totensor])
img_resize2 = trans_compose(img)
writer.add_image("Resize",img_resize2,1)
# RandomCrop
trans_random = transforms.RandomCrop((50,100))
trans_compose_2 = transforms.Compose([trans_random,trans_totensor])
for i in range(10):
img_crop = trans_compose_2(img)
writer.add_image('RandomCropHW',img_crop,i)
writer.close()
总结使用方法
- 关注输入和输出类型
- 多看官方文档
- 关注方法需要什么参数:参数如果设置了默认值,保留默认值即可,没有默认值的需要指定(看一下要求传入什么类型的参数)
- 不知道变量的输出类型可以
- 直接print该变量
- print(type()),看结果里显示什么类型
- 断点调试 dubug
- 最后要 totensor,在 tensorboard 看一下结果(tensorboard需要tensor数据类型进行显示)
torchvision中的数据集使用
Pytorch官网的数据集链接
(1)torchvision.datasets
如:COCO 目标检测、语义分割;MNIST 手写文字;CIFAR 物体识别
(2)torchvision.io
输入输出模块,不常用
(3)torchvision.models
提供一些比较常见的神经网络,有的已经预训练好,如分类、语义分割、目标检测、视频分类
(4)torchvision.ops
torchvision提供的一些比较少见的特殊的操作,不常用
(5)torchvision.transforms
(6)torchvision.utils
提供一些常用的小工具,如TensorBoard
CIFAR10数据集
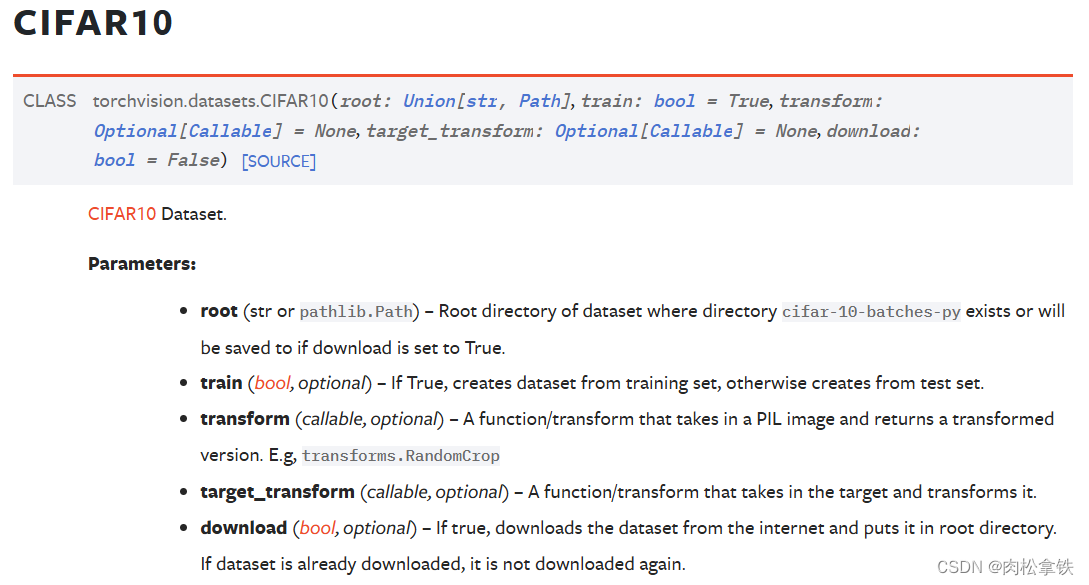
CIFAR10 数据集包含了6万张32×32像素的彩色图片,图片有10个类别,每个类别有6千张图像,其中有5万张图像为训练图片,1万张为测试图片

标准数据集如何下载、查看、使用
#如何使用torchvision提供的标准数据集
import torchvision
train_set=torchvision.datasets.CIFAR10(root="./dataset1",train=True,download=True) #root使用相对路径,会在该.py所在位置创建一个叫dataset的文件夹,同时把数据保存进去
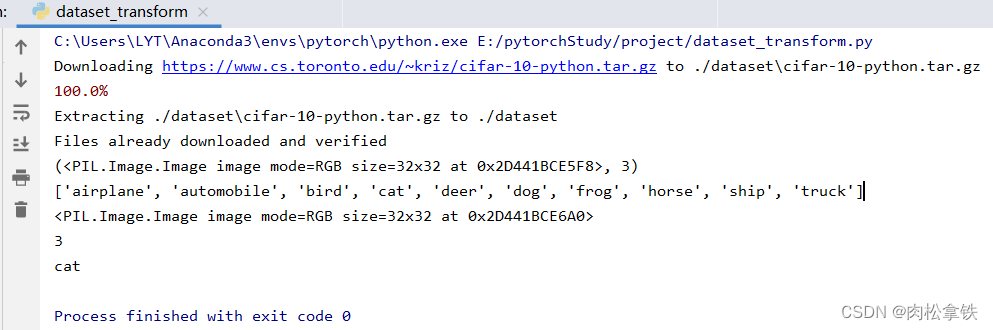
test_set=torchvision.datasets.CIFAR10(root="./dataset1",train=False,download=True)
print(test_set[0]) # 查看测试集中的第一个数据,是一个元组:(img, target)
print(test_set.classes) # 列表
img,target = test_set[0]
print(img)
print(target) # 3
print(test_set.classes[target]) # cat
img.show()
如何把数据集(多张图片)和 transforms 结合在一起
CIFAR10数据集原始图片是PIL Image,如果要给pytorch使用,需要转为tensor数据类型(转成tensor后,就可以用tensorboard了)
import torchvision
from torch.utils.tensorboard import SummaryWriter
#把dataset_transform运用到数据集中的每一张图片,都转为tensor数据类型
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=dataset_transform, download=True) # root使用相对路径,会在该.py所在位置创建一个叫dataset的文件夹,同时把数据保存进去
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=dataset_transform, download=True)
writer = SummaryWriter('logs')
#显示测试数据集中的前10张图片
for i in range(10):
img, target = test_set[i]
writer.add_image('test_set',img, i)
writer.close()
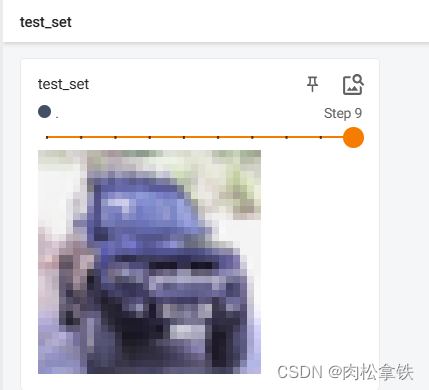
DataLoader 的使用
- dataset:告诉程序中数据集的位置,数据集中索引,数据集中有多少数据(想象成一叠扑克牌)
- dataloader:将数据加载到神经网络中,每次从dataset中取数据,通过dataloader中的参数可以设置如何取数据(想象成抓的一组牌)
测试代码:
import torchvision
from torch.utils.data import DataLoader
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data,batch_size=4,shuffle=True,num_workers=0,drop_last=False)
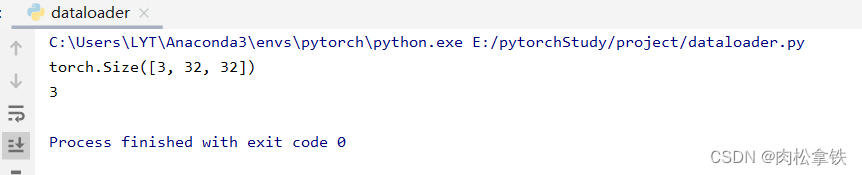
# 测试数据集中第一张图片,target
img,target = test_data[0]
print(img.shape)
print(target)
dataset
- getitem():return img,target
- dataloader(batch_size=4):从dataset中取4个数据
img0,target0 = dataset[0]
img1,target1 = dataset[1]
img2,target2 = dataset[2]
img3,target3 = dataset[3]
把 img 0-3 进行打包,记为imgs;target 0-3 进行打包,记为targets;作为dataloader中的返回
for data in test_loader:
imgs,targets = data
print(imgs.shape)
print(targets)
输出结果:
torch.Size([4, 3, 32, 32]) #4张图片,三通道,32×32
tensor([0, 4, 4, 8]) #4个target进行一个打包
数据是随机取的(断点debug一下,可以看到采样器sampler是随机采样的),所以两次的 target 0 并不一样
batch_size
import torchvision
from torch.utils.tensorboard import SummaryWriter
from torch.utils.data import DataLoader
# 准备的测试数据集
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
# 加载测试集
test_loader = DataLoader(dataset=test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
writer = SummaryWriter("logs")
step = 0
for data in test_loader:
imgs, targets = data
writer.add_images("dataloader", imgs, step)
step = step + 1
writer.close()
由于 drop_last 设置为 False,所以最后16张图片(没有凑齐64张)显示如下:
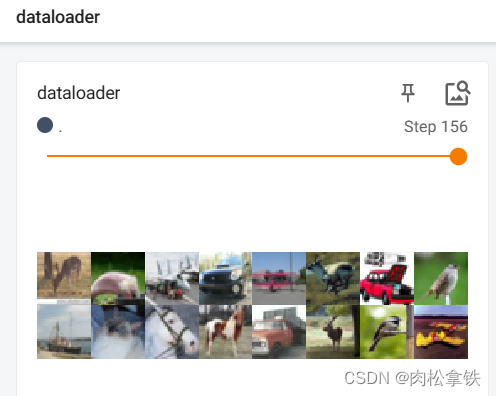
drop_last
若将 drop_last 设置为 True,最后16张图片(step 156)会被舍去,结果如图:
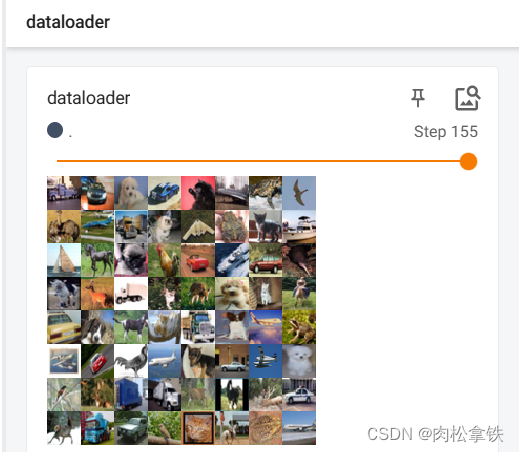
shuffle
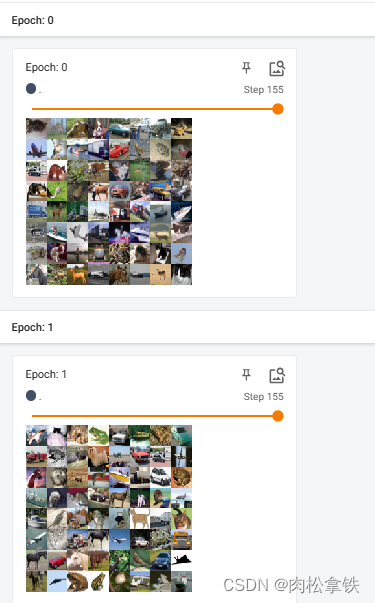
一个 for data in test_loader 循环,就意味着打完一轮牌(抓完一轮数据),在下一轮再进行抓取时,第二次数据是否与第一次数据一样。值为True的话,会重新洗牌(一般都设置为True)
shuffle为False的话两轮取的图片是一样的
在外面再套一层 for epoch in range(2) 的循环
# shuffle为True
for epoch in range(2):
step=0
for data in test_loader:
imgs,targets = data #imgs是tensor数据类型
writer.add_images("Epoch:{}".format(epoch),imgs,step)
step=step+1
两次返回图片顺序不同
神经网络的基本骨架 - nn.Module 的使用
关于神经网络的工具主要在torch.nn里

Containers
包含6个模块:
- Module
- Sequential
- ModuleList
- ModuleDict
- ParameterList
- ParameterDict
其中最常用的是 Module 模块(为所有神经网络提供基本骨架)所搭建的神经网络必须从Containers类里面继承
模板:
import torch.nn as nn
import torch.nn.functional as F
# 定义神经网络名字
class Model(nn.Module):
# 初始化
def __init__(self):
# 调用父类初始化函数
super(Model, self).__init__()
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
# input -> (经过神经网络的forword,前向传播)output
def forward(self, x):
# conv为卷积,relu为非线性处理
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))
上述代码执行过程:

自己创建一个神经网络:
import torch
import torch.nn as nn
import torch.nn.functional as F
class August(nn.Module):
def __init__(self):
super().__init__()
def forward(self, input):
output = input + 1
return output
august = August()
# 将1.0这个数转换成tensor类型
x = torch.tensor(1.0)
output = august(x)
print(output)

卷积操作
卷积层

二维神经网络卷积层(常见,图像)
torch.nn.functional
torch.nn 和 torch.nn.functional 的区别:前者是后者的封装,更利于使用

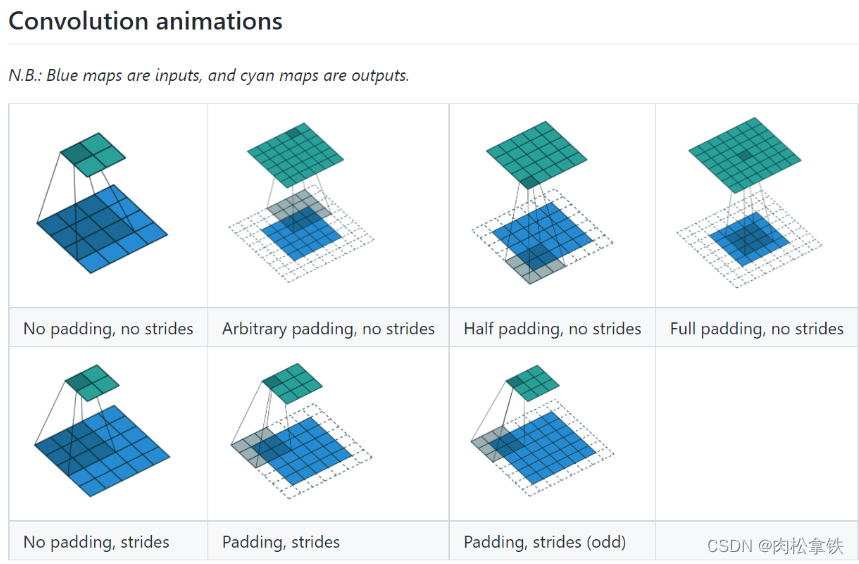
stride(步进)
可以是单个数,或元组(sH,sW) — 控制横向步进和纵向步进,当 stride = 2 时,横向和纵向都是2,输出是一个2×2的矩阵
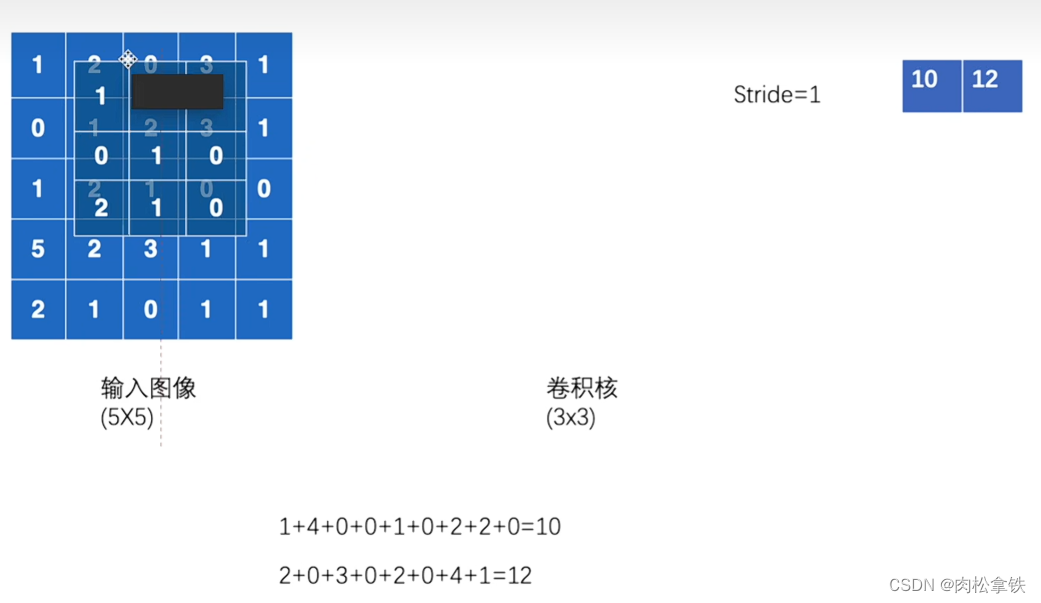
卷积计算 = 输入图像和卷积核对应数字相乘,再求和
要求输入的维度 & reshape函数
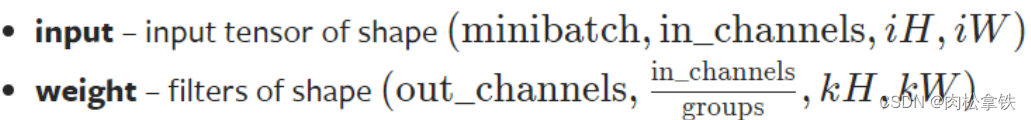
- input:尺寸要求是batch,几个通道,高,宽(4个参数)
- weight:尺寸要求是输出,in_channels(groups一般为1),高,宽(4个参数)
使用 torch.reshape 函数,将输入改变为要求输入的维度
import torch
import torch.nn.functional as F
# 输入图像
input = torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]])
# 卷积核
kernel = torch.tensor([[1,2,1],
[0,1,0],
[2,1,0]])
# 修改尺寸
input = torch.reshape(input, (1, 1, 5, 5))
kernel = torch.reshape(kernel, (1, 1, 3, 3))
# print(input.shape)
# print(kernel.shape)
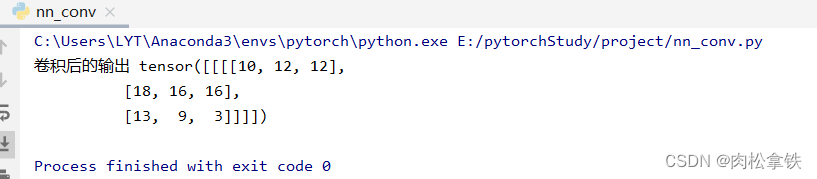
output = F.conv2d(input, kernel,stride=1)
print('卷积后的输出',output)

当将步进 stride 改为 2 时:
output2 = F.conv2d(input,kernel,stride=2)
print(output2)
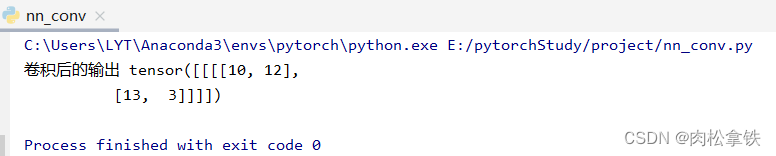
padding(填充)
在输入图像左右两边进行填充,决定填充有多大。可以为一个数或一个元组(分别指定高和宽,即纵向和横向每次填充的大小)。默认情况下不进行填充
padding=1:将输入图像左右上下两边都拓展一个像素,空的地方默认为0
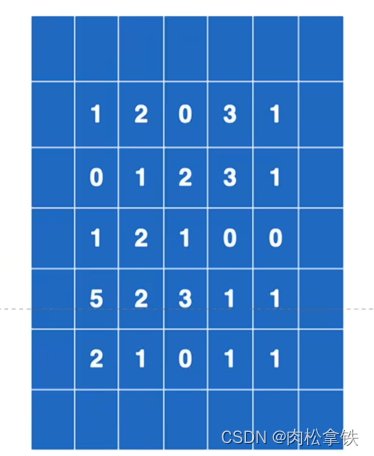
修改padding = 1,输出尺寸变大:
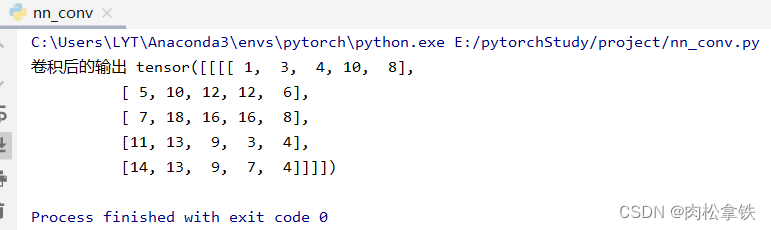
神经网路——卷积层
conv2d

参数介绍
CLASS torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
# in_channels 输入通道数
# out_channels 输出通道数
# kernel_size 卷积核大小
#以上参数需要设置
#以下参数提供了默认值
# stride=1 卷积过程中的步进大小
# padding=0 卷积过程中对原始图像进行padding的选项
# dilation=1 每一个卷积核对应位的距离
# groups=1 一般设置为1,很少改动,改动的话为分组卷积
# bias=True 通常为True,对卷积后的结果是否加减一个常数的偏置
# padding_mode='zeros' 选择padding填充的模式

kernel_size
定义了一个卷积核的大小,若为3则生成一个3×3的卷积核
- 卷积核的参数是从一些分布中进行采样得到的
- 实际训练过程中,卷积核中的值会不断进行调整
in_channels & out_channels
- in_channels:输入图片的channel数(彩色图像 in_channels 值为3)
- out_channels:输出图片的channel数
in_channels 和 out_channels 都为 1 时,拿一个卷积核在输入图像中进行卷积
out_channels 为 2 时,卷积层会生成两个卷积核(不一定一样),得到两个输出,叠加后作为最后输出
CIFAR10数据集实例
import torch
from torch import nn
from torch.nn import Conv2d
from torch.utils.tensorboard import SummaryWriter
import torchvision
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset,batch_size=64)
class August(nn.Module):
def __init__(self):
super(August, self).__init__()
# 因为是彩色图片,所以in_channels=3
self.conv1 = nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return x
# 初始化网络
august = August()
writer = SummaryWriter("logs")
step = 0
for data in dataloader:
imgs, targets = data
output = august(imgs)
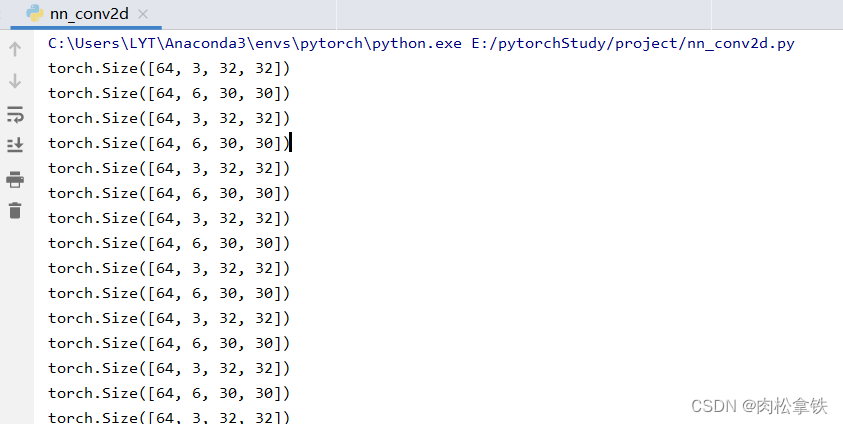
print(imgs.shape) #输入大小 torch.Size([64, 3, 32, 32]) batch_size=64,in_channels=3(彩色图像),每张图片是32×32的
print(output.shape) #经过卷积后的输出大小 torch.Size([64, 6, 30, 30]) 卷积后变成6个channels,但原始图像减小,所以是30×30的
# 6个channel无法显示。torch.Size([64, 6, 30, 30]) ——> [xxx,3,30,30] 第一个值不知道为多少时写-1,会根据后面值的大小进行计算
output = torch.reshape(output,(-1,3,30,30))
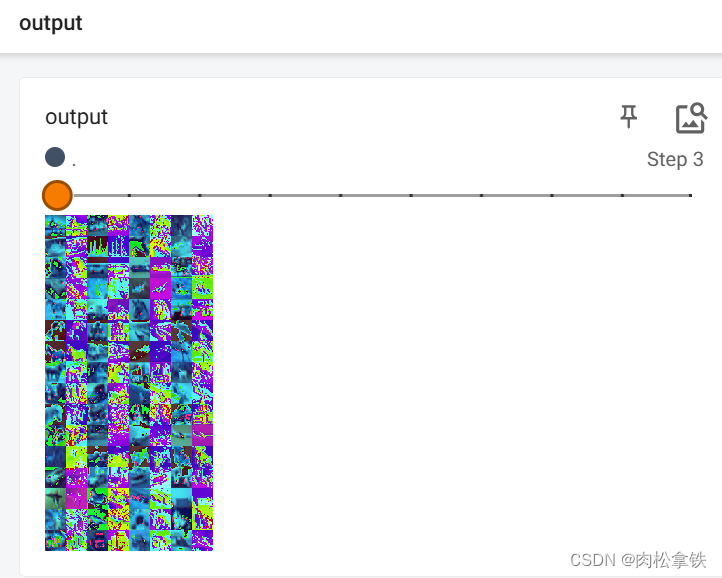
writer.add_images("input",imgs, step)
writer.add_images("output",output,step)
print(imgs.shape)
print(output.shape)
step = step + 1
writer.close()
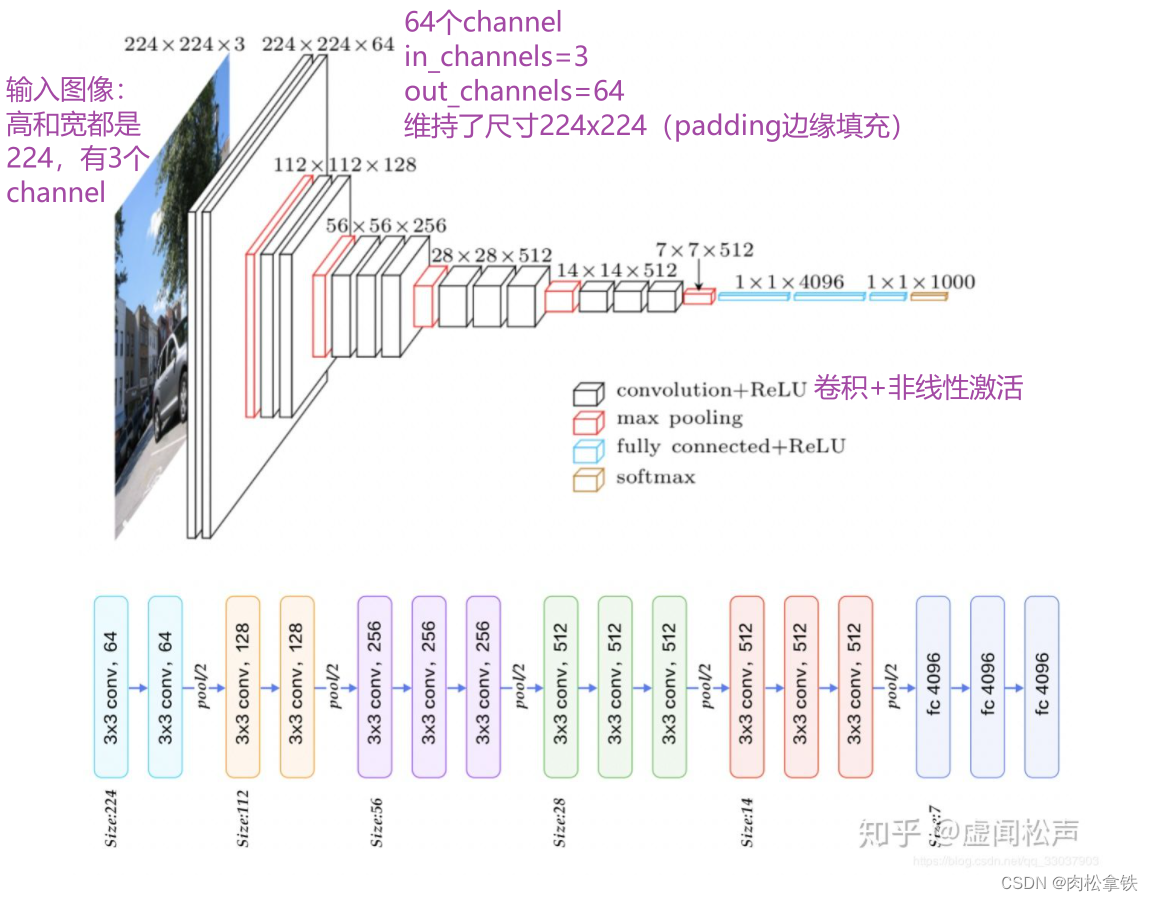
vgg16
卷积前后维度计算公式

神经网络 - 池化层
- MaxPool:最大池化(下采样)
- MaxUnpool:上采样
- AvgPool:平均池化
- AdaptiveMaxPool2d:自适应最大池化
最常用的是MaxPool2d


注意:
卷积中stride默认为1,而池化中stride默认为kernel_size
dilator:空洞卷积
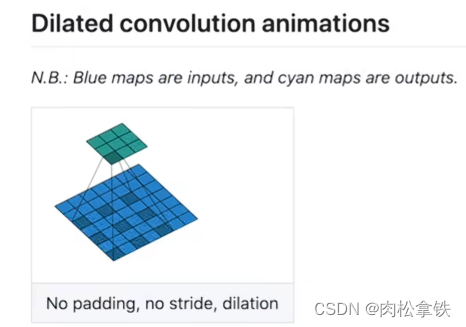
最大池化操作,ceil_mode参数
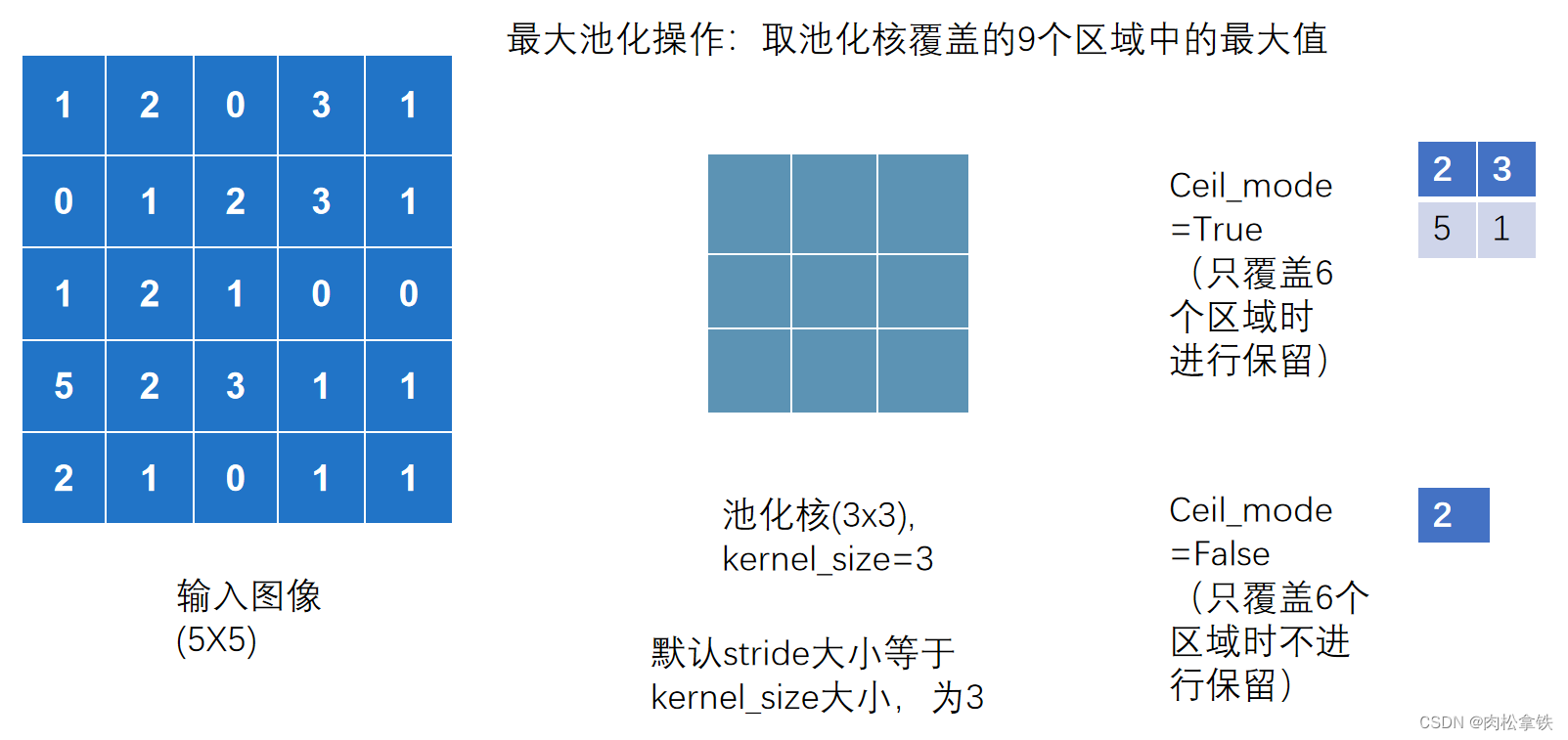
==Ceil_mode 默认情况下为 False,对于最大池化一般只需设置 kernel_size 即可 ==
输入输出维度计算公式

代码实现
要求的 input 必须是四维的,参数依次是:batch_size、channel、高、宽
上述图用代码实现:(以 Ceil_mode = True 为例)
import torch
from torch import nn
# 输入图像
from torch.nn import MaxPool2d
input = torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]], dtype=torch.float32)
input = torch.reshape(input, (-1, 1, 5, 5))
# print(input.shape) # torch.Size([1, 1, 5, 5])
# 神经网络
class August(nn.Module):
def __init__(self):
super(August, self).__init__()
# 最大池化层
self.maxpool = MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self,input):
# 将input放入最大池化层,返回给output
output = self.maxpool(input)
return output
# 创建神经网络
august = August()
# 把输入给创建的神经网络中,输出给output
output = august(input)
print(output)
结果与上图计算相符
Ceil_mode = True

Ceil_mode = False

为什么要进行最大池化?最大池化的作用是什么?
最大池化的目的是保留输入的特征,同时把数据量减小(数据维度变小),对于整个网络来说,进行计算的参数变少,会训练地更快
- 如上面案例中输入是5x5的,但输出是3x3的,甚至可以是1x1的
- 类比:1080p的视频为输入图像,经过池化可以得到720p,也能满足绝大多数需求,传达视频内容的同时,文件尺寸会大大缩小
池化一般跟在卷积后,卷积层是用来提取特征的,一般有相应特征的位置是比较大的数字,最大池化可以提取出这一部分有相应特征的信息
池化不影响通道数
池化后一般再进行非线性激活
使用tensorboard + CIFAR10数据集实现最大池化:
import torch
import torchvision
from torch import nn
from torch.utils.tensorboard import SummaryWriter
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10(root='./dataset',train=False,transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
# 神经网络
class August(nn.Module):
def __init__(self):
super(August, self).__init__()
# 最大池化层
self.maxpool = MaxPool2d(kernel_size=3, ceil_mode=False)
def forward(self,input):
# 将input放入最大池化层,返回给output
output = self.maxpool(input)
return output
writer = SummaryWriter("logs")
# 创建神经网络
august = August()
# 把输入给创建的神经网络中,输出给output
step = 0
for data in dataloader:
imgs,targets = data
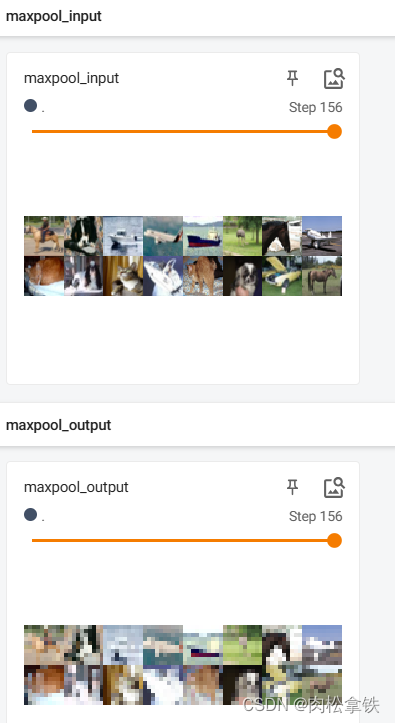
writer.add_images("maxpool_input",imgs,step)
output = august(imgs)
writer.add_images("maxpool_output",output,step)
step = step + 1
writer.close()
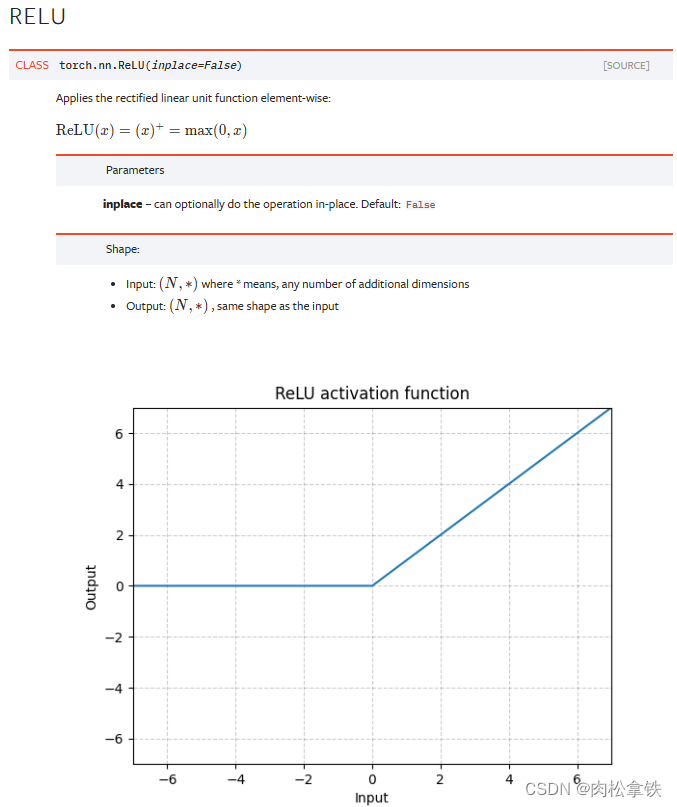
神经网络 - 非线性激活
非线性激活(为神经网络引入一些特质)
nn.ReLU比较常见
非线性激活:给神经网络引入一些非线性的特征
非线性越多,才能训练出符合各种曲线或特征的模型(提高泛化能力)
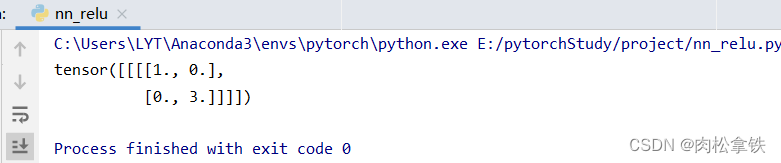
代码举例:RELU
import torch
from torch import nn
from torch.nn import ReLU
input = torch.tensor([[1,-0.5],
[-1,3]])
input = torch.reshape(input,(-1,1,2,2))
class August(nn.Module):
def __init__(self):
super(August, self).__init__()
self.relu1 = ReLU(inplace=False) # 默认选择false,保留原始数据
def forward(self,input):
output = self.relu1(input)
return output
august = August()
output = august(input)
print(output)

代码举例:Sigmoid
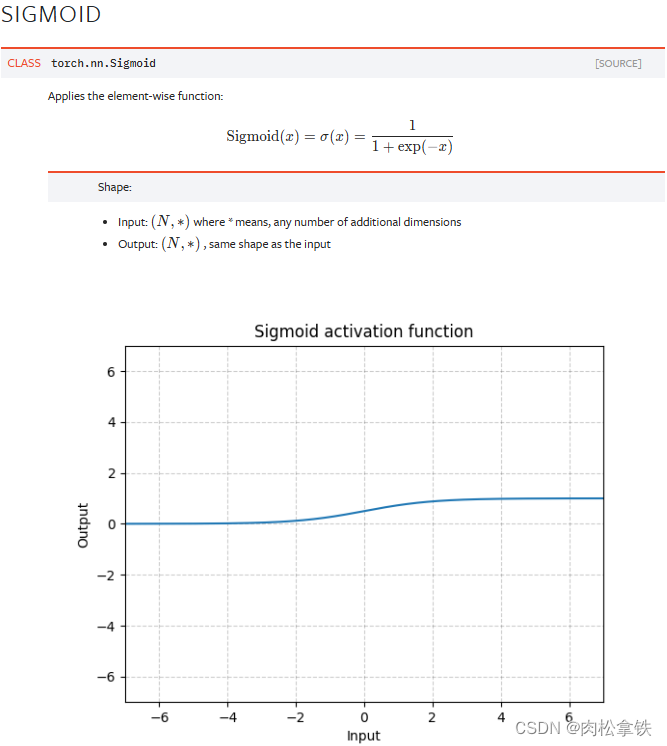
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
input = torch.tensor([[1,-0.5],
[-1,3]])
input = torch.reshape(input,(-1,1,2,2))
dataset = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
class August(nn.Module):
def __init__(self):
super(August, self).__init__()
self.sigmoid1 = Sigmoid() # 默认选择false,保留原始数据
def forward(self,input):
output = self.sigmoid1(input)
return output
august = August()
writer = SummaryWriter("logs")
step = 0
for data in dataloader:
imgs, targets = data
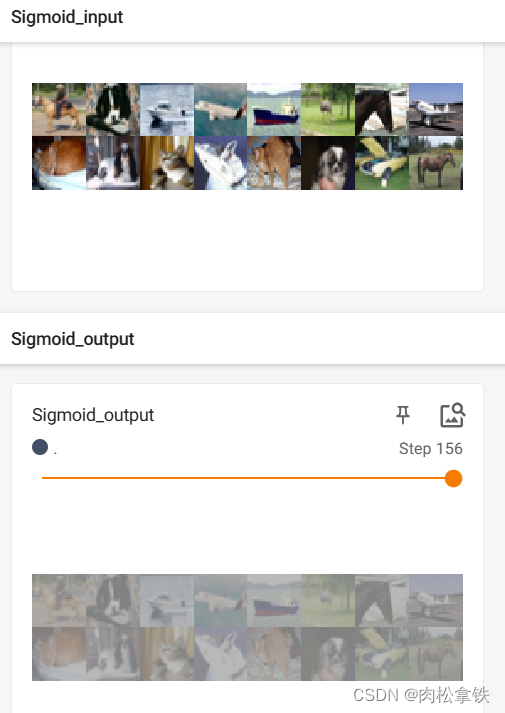
writer.add_images("Sigmoid_input", imgs, global_step=step)
output = august(imgs)
writer.add_images("Sigmoid_output",output, step)
step = step+1
writer.close()
神经网络 - 线性层及其他层介绍
Normalization layers


Recurrent Layers
Transformer Layers
Linear Layers
线性层
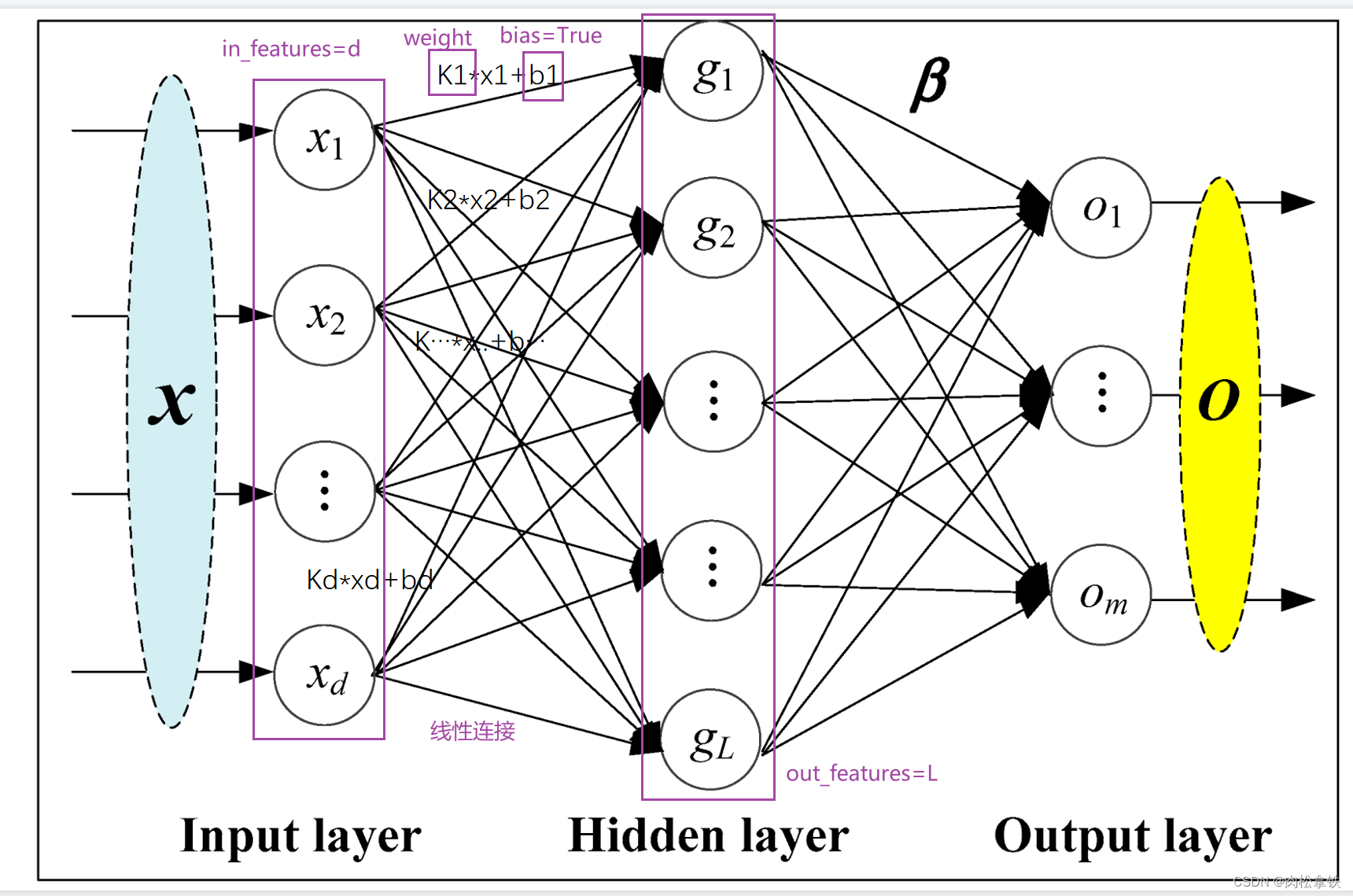

weight和bias:从分布中进行采样和初始化
vgg16 model
torch.flatten
将多维数组铺平成一维数组
- reshape():可以指定尺寸进行变换
- flatten():变成1行,摊平
import torch
import torchvision
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10('./dataset', train=False, transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
class August(nn.Module):
def __init__(self):
super(August, self).__init__()
# in_features的值为output.shape的torch.Size([1, 1, 1, 196608])[批处理维度,通道维度,高度维度,宽度维度]
self.liner1 = Linear(in_features=196608,out_features=10)
def forward(self, input):
output = self.liner1(input)
return output
august = August()
for data in dataloader:
imgs, targets = data
# input = torch.reshape(imgs,(1,1,1,-1))
input = torch.flatten(imgs)
output = august(input)
print(output.shape)
Dropout Layers
Dropout layers
在训练过程中,随机把一些 input(输入的tensor数据类型)中的一些元素变为0,变为0的概率为p
目的:防止过拟合
Sparse Layers
用于自然语言处理
Distance Functions
计算两个值之间的误差
Loss Functions
loss 误差大小
pytorch提供的一些网络模型
- 图片相关:torchvision torchvision.models — Torchvision 0.11.0 documentation分类、语义分割、目标检测、实例分割、人体关键节点识别(姿态估计)等等
- 文本相关:torchtext 无
- 语音相关:torchaudio torchaudio.models — Torchaudio 0.10.0 documentation
神经网络 - 搭建小实战和 Sequential 的使用
Sequential
CIFAR10 进行分类的简单神经网络
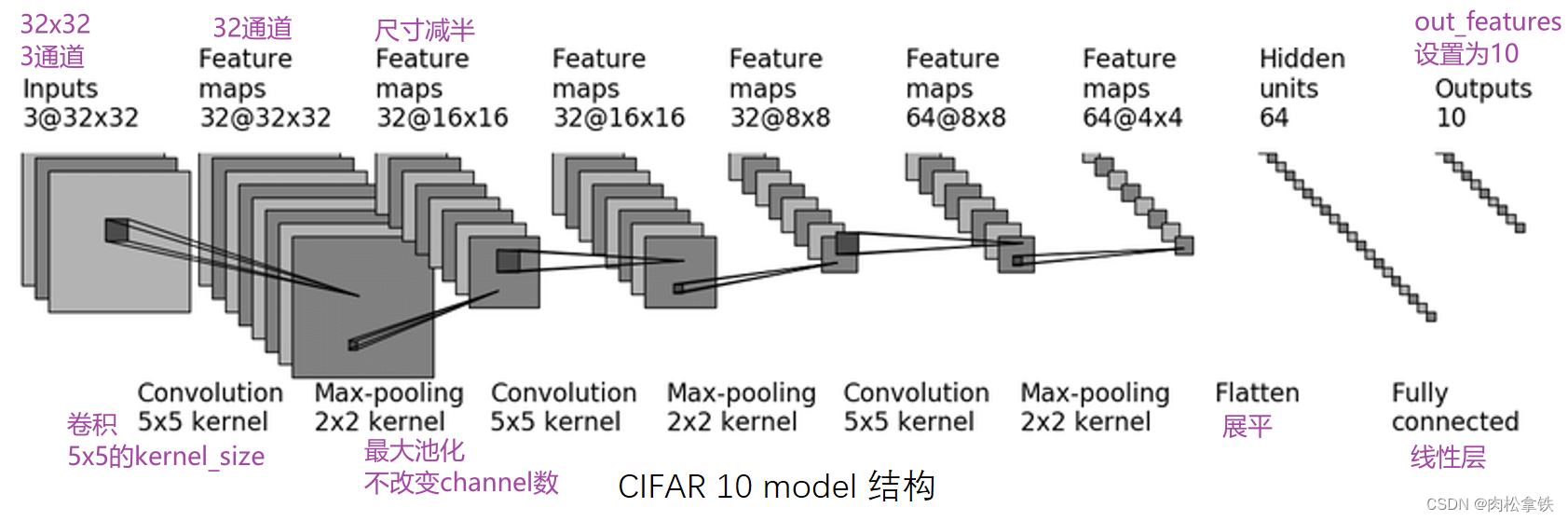
第一次卷积:首先加了几圈 padding(图像大小不变,还是32x32),然后卷积了32次
- Conv2d — PyTorch 1.10 documentation
- 输入尺寸是32x32,经过卷积后尺寸不变,如何设置参数? —— padding=2,stride=1
- 计算公式:

几个卷积核就是几通道的,一个卷积核作用于RGB三个通道后会把得到的三个矩阵的对应值相加,也就是说会合并,所以一个卷积核会产生一个通道
任何卷积核在设置padding的时候为保持输出尺寸不变都是卷积核大小的一半
通道变化时通过调整卷积核的个数(即输出通道)来实现的,在 nn.conv2d 的参数中有 out_channel 这个参数,就是对应输出通道
kernel 的内容是不一样的,可以理解为不同的特征抓取,因此一个核会产生一个channel
实现上图 CIFAR10 model 的代码
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
class August(nn.Module):
def __init__(self):
super(August, self).__init__()
self.conv1 = Conv2d(in_channels=3,out_channels=32,kernel_size=5,padding=2,stride=1)
self.maxpool1 = MaxPool2d(2)
self.conv2 = Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2, stride=1)
self.maxpool2 = MaxPool2d(2)
self.conv3 = Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2, stride=1)
self.maxpool3 = MaxPool2d(2)
self.flatten = Flatten()
self.linear1 = Linear(in_features=1024,out_features=64)
self.linear2 = Linear(in_features=64, out_features=10)
def forward(self, x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.maxpool3(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.linear2(x)
return x
august = August()
print(august)
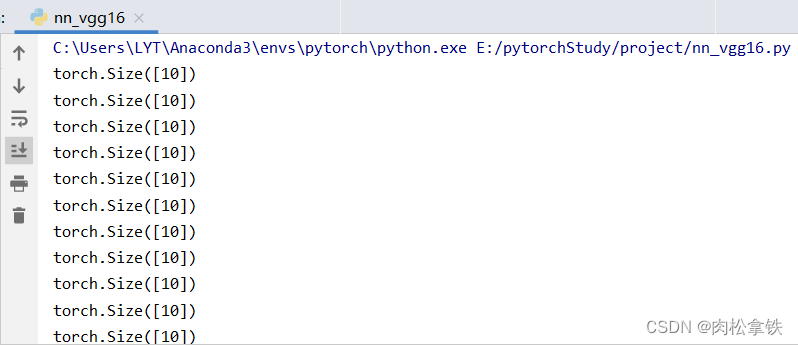
实际过程中如何检查网络的正确性?
核心:一定尺寸的数据经过网络后,能够得到我们想要的输出
对网络结构进行检验的代码:
input = torch.ones((64,3,32,32))
output = august(input)
print(output.shape)

若不知道flatten之后的维度是多少该怎么办?
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
class August(nn.Module):
def __init__(self):
super(August, self).__init__()
self.conv1 = Conv2d(in_channels=3,out_channels=32,kernel_size=5,padding=2,stride=1)
self.maxpool1 = MaxPool2d(2)
self.conv2 = Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2, stride=1)
self.maxpool2 = MaxPool2d(2)
self.conv3 = Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2, stride=1)
self.maxpool3 = MaxPool2d(2)
self.flatten = Flatten()
self.linear1 = Linear(in_features=1024,out_features=64)
self.linear2 = Linear(in_features=64, out_features=10)
def forward(self, x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.maxpool3(x)
x = self.flatten(x)
return x
august = August()
input = torch.ones((64,3,32,32))
output = august(input)
print(output.shape)

输出的维度是(64,1024),64可以理解为64张图片,1024就是flatten之后的维度了
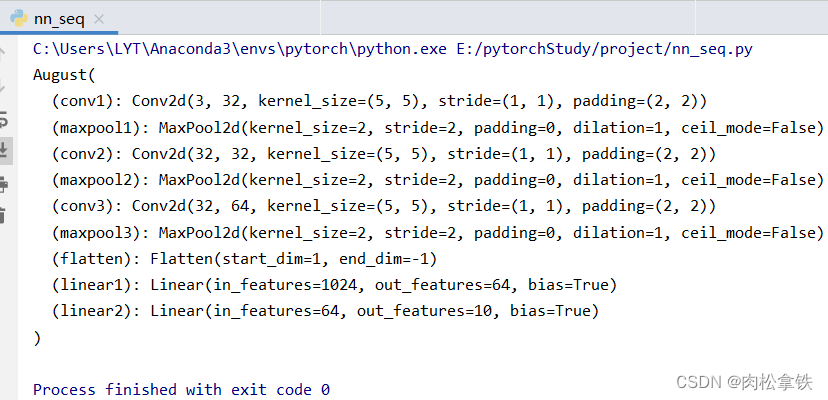
Sequential 搭建,实现上图 CIFAR10 model 的代码
简化代码,和上面的一样
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
class August(nn.Module):
def __init__(self):
super(August, self).__init__()
# self.conv1 = Conv2d(in_channels=3,out_channels=32,kernel_size=5,padding=2,stride=1)
# self.maxpool1 = MaxPool2d(2)
# self.conv2 = Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2, stride=1)
# self.maxpool2 = MaxPool2d(2)
# self.conv3 = Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2, stride=1)
# self.maxpool3 = MaxPool2d(2)
# self.flatten = Flatten()
# self.linear1 = Linear(in_features=1024,out_features=64)
# self.linear2 = Linear(in_features=64, out_features=10)
self.model1 = Sequential(
Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2, stride=1),
MaxPool2d(2),
Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2, stride=1),
MaxPool2d(2),
Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2, stride=1),
MaxPool2d(2),
Flatten(),
Linear(in_features=1024, out_features=64),
Linear(in_features=64, out_features=10)
)
def forward(self, x):
# x = self.conv1(x)
# x = self.maxpool1(x)
# x = self.conv2(x)
# x = self.maxpool2(x)
# x = self.conv3(x)
# x = self.maxpool3(x)
# x = self.flatten(x)
x = self.model1(x)
return x
august = August()
input = torch.ones((64,3,32,32))
output = august(input)
print(output.shape)
使用tensorboard可视化模型结构
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
class August(nn.Module):
def __init__(self):
super(August, self).__init__()
# self.conv1 = Conv2d(in_channels=3,out_channels=32,kernel_size=5,padding=2,stride=1)
# self.maxpool1 = MaxPool2d(2)
# self.conv2 = Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2, stride=1)
# self.maxpool2 = MaxPool2d(2)
# self.conv3 = Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2, stride=1)
# self.maxpool3 = MaxPool2d(2)
# self.flatten = Flatten()
# self.linear1 = Linear(in_features=1024,out_features=64)
# self.linear2 = Linear(in_features=64, out_features=10)
self.model1 = Sequential(
Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2, stride=1),
MaxPool2d(2),
Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2, stride=1),
MaxPool2d(2),
Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2, stride=1),
MaxPool2d(2),
Flatten(),
Linear(in_features=1024, out_features=64),
Linear(in_features=64, out_features=10)
)
def forward(self, x):
# x = self.conv1(x)
# x = self.maxpool1(x)
# x = self.conv2(x)
# x = self.maxpool2(x)
# x = self.conv3(x)
# x = self.maxpool3(x)
# x = self.flatten(x)
x = self.model1(x)
return x
august = August()
input = torch.ones((64,3,32,32))
output = august(input)
print(output.shape)
writer = SummaryWriter('logs')
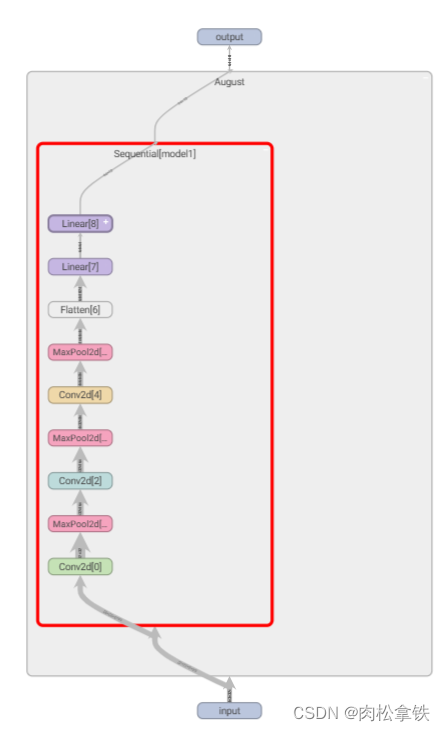
writer.add_graph(august, input)
writer.close()
终端输入tensorboard --dirlog=logs
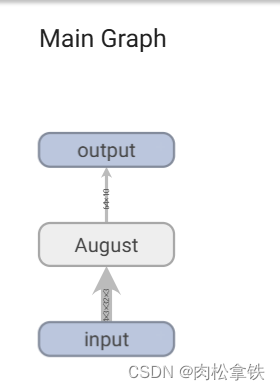
双击图片中的矩形,可以放大每个部分:
损失函数与反向传播
torch.nn 里的 loss function 衡量误差,在使用过程中根据需求使用,注意输入形状和输出形状即可
loss 衡量实际神经网络输出 output 与真实想要结果 target 的差距,越小越好
作用:
- 计算实际输出和目标之间的差距
- 为我们更新输出提供一定的依据(反向传播):给每一个卷积核中的参数提供了梯度 grad,采用反向传播时,每一个要更新的参数都会计算出对应的梯度,优化过程中根据梯度对参数进行优化,最终达到整个 loss 进行降低的目的
L1Loss
官方文档
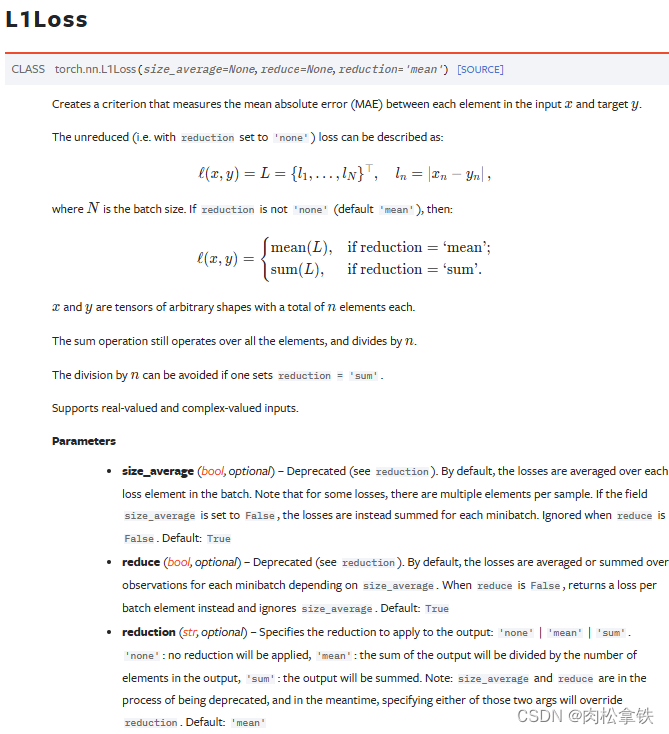

例子:
import torch
from torch.nn import L1Loss
inputs = torch.tensor([1,2,3],dtype=torch.float32)
targets = torch.tensor(([1,2,5]),dtype=torch.float32)
inputs = torch.reshape(inputs,(1,1,1,3))
targets = torch.reshape(targets,(1,1,1,3))
loss = L1Loss()
res = loss(inputs,targets)
print(res)
损失计算 = (abs(1-1)+abs(2-2)+abs(3-5))/3 -> reduction = ‘mean’

损失计算 = abs(1-1)+abs(2-2)+abs(3-5) -> reduction = ‘sum’

MSELoss(平方差)


import torch
from torch.nn import L1Loss, MSELoss
inputs = torch.tensor([1,2,3],dtype=torch.float32)
targets = torch.tensor(([1,2,5]),dtype=torch.float32)
inputs = torch.reshape(inputs,(1,1,1,3))
targets = torch.reshape(targets,(1,1,1,3))
loss1 = MSELoss()
res1 = loss1(inputs,targets)
print(res1)
损失计算 = ((1-1)² + (2-2)² + (3-5)²) / 3

CrossEntropyLoss(交叉熵)
适用于训练分类问题,有C个类别
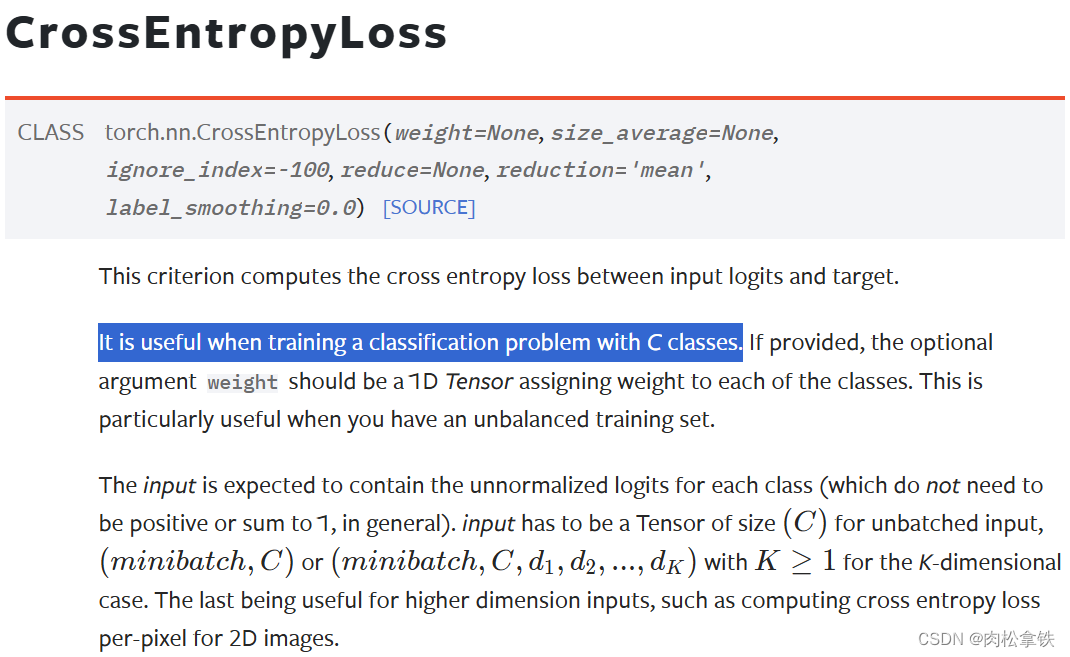
例:有一个三分类问题Person,dog,cat

这里的output不是概率,是评估分数
参数

输入类型

input 为没有进行处理过的对每一类的得分
例子:
x = torch.tensor([0.1,0.2,0.3])
y = torch.tensor([1])
x = torch.reshape(x,(1,3))
loss_cross = CrossEntropyLoss()
res_loss = loss_cross(x,y)
print(res_loss)

如何在之前写的神经网络中用到 Loss Function(损失函数)
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential, CrossEntropyLoss
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import torchvision
dataset = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset,batch_size=1)
class August(nn.Module):
def __init__(self):
super(August, self).__init__()
self.model1 = Sequential(
Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2, stride=1),
MaxPool2d(2),
Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2, stride=1),
MaxPool2d(2),
Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2, stride=1),
MaxPool2d(2),
Flatten(),
Linear(in_features=1024, out_features=64),
Linear(in_features=64, out_features=10)
)
def forward(self, x):
x = self.model1(x)
return x
august = August()
loss = CrossEntropyLoss()
for data in dataloader:
imgs,targets = data
outputs = august(imgs)
loss_res = loss(outputs,targets)
print(loss_res)
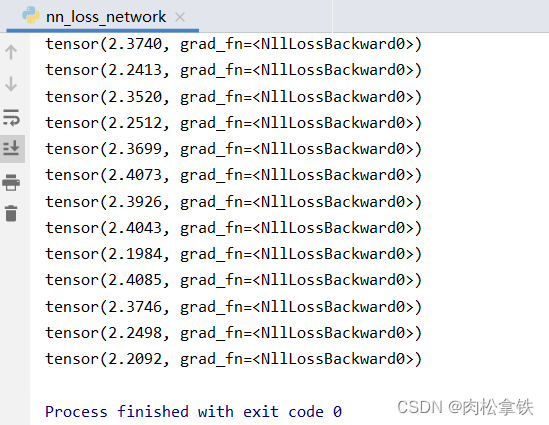
backward 反向传播

1.是损失函数的作用
2.是方向传播的作用,反向传播计算出每一个节点参数的梯度,必须backword后grad才有值(才可以计算出每个结点的参数)
优化器
当使用损失函数时,可以调用损失函数的 backward,得到反向传播,反向传播可以求出每个需要调节的参数对应的梯度,有了梯度就可以利用优化器,优化器根据梯度对参数进行调整,以达到整体误差降低的目的。
优化器官方文档
如何使用优化器?
(1)构造
# Example:
# SGD为构造优化器的算法,Stochastic Gradient Descent 随机梯度下降
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9) #模型参数(必备)、学习速率、特定优化器算法中需要设定的参数
optimizer = optim.Adam([var1, var2], lr=0.0001)
(2)调用优化器step方法
# Example:
for input, target in dataset:
optimizer.zero_grad() # 必须要做,循环操作,对上一个优化器参数清零操作
output = model(input) # 输入经过一个模型得到输出
loss = loss_fn(output, target) # 计算输出和真实target的误差loss
loss.backward() # 计算loss的反向传播,得到每一个要更新参数的梯度
optimizer.step() # 调用优化器,根据梯度进行优化,对卷积核参数进行调整
算法
如Adadelta、Adagrad、Adam、RMSProp、SGD等等,不同算法前两个参数:params、lr 都是一致的,后面的参数不同
CLASStorch.optim.Adadelta(params, lr=1.0, rho=0.9, eps=1e-06, weight_decay=0, foreach=None, *, maximize=False, differentiable=False)
# params:模型参数,优化器可以知道模型长什么样
# lr:学习速率,设置太大模型训练不稳定,设置太小训练太慢。一般开始的时候选择一个较大lr,后面选择一个较小lr
# 后续参数都是特定算法中需要设置的
SGD为例
SGD:随机优化算法
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential, CrossEntropyLoss
from torch.optim import SGD
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import torchvision
dataset = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=1)
class August(nn.Module):
def __init__(self):
super(August, self).__init__()
self.model1 = Sequential(
Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2, stride=1),
MaxPool2d(2),
Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2, stride=1),
MaxPool2d(2),
Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2, stride=1),
MaxPool2d(2),
Flatten(),
Linear(in_features=1024, out_features=64),
Linear(in_features=64, out_features=10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = CrossEntropyLoss()
august = August()
optim = torch.optim.SGD(august.parameters(), lr=0.01)
# 一次 data 循环相当于对数据训练一次,加了 epoch 循环相当于对数据训练 20 次
for epoch in range(20):
running_loss = 0.0
for data in dataloader:
imgs, targets = data
outputs = august(imgs)
loss_res = loss(outputs, targets)
optim.zero_grad()
loss_res.backward()
optim.step()
running_loss = running_loss + loss_res
print(running_loss)
部分运行结果:
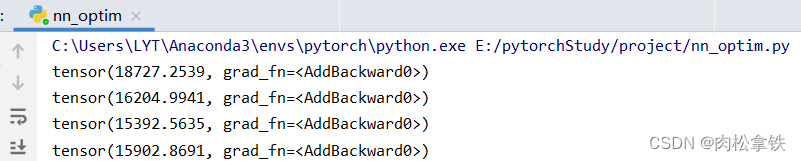
优化器对模型参数不断进行优化,每一轮的 loss 在不断减小















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









