






本次课程由OpenCompass 贡献者曹茂松、刘卓鑫老师讲解【OpenCompass 大模型评测实战】课程
课程视频:https://www.bilibili.com/video/BV1Pm41127jU/
课程文档:https://github.com/InternLM/Tutorial/blob/camp2/opencompass/readme.md

四个方面,促进模型发展
- 扩展能力维度,如数学、代码等。
- 聚焦垂直行业,如医疗、金融等。
- 开发高质量中文基准
- 性能评测,能力迭代

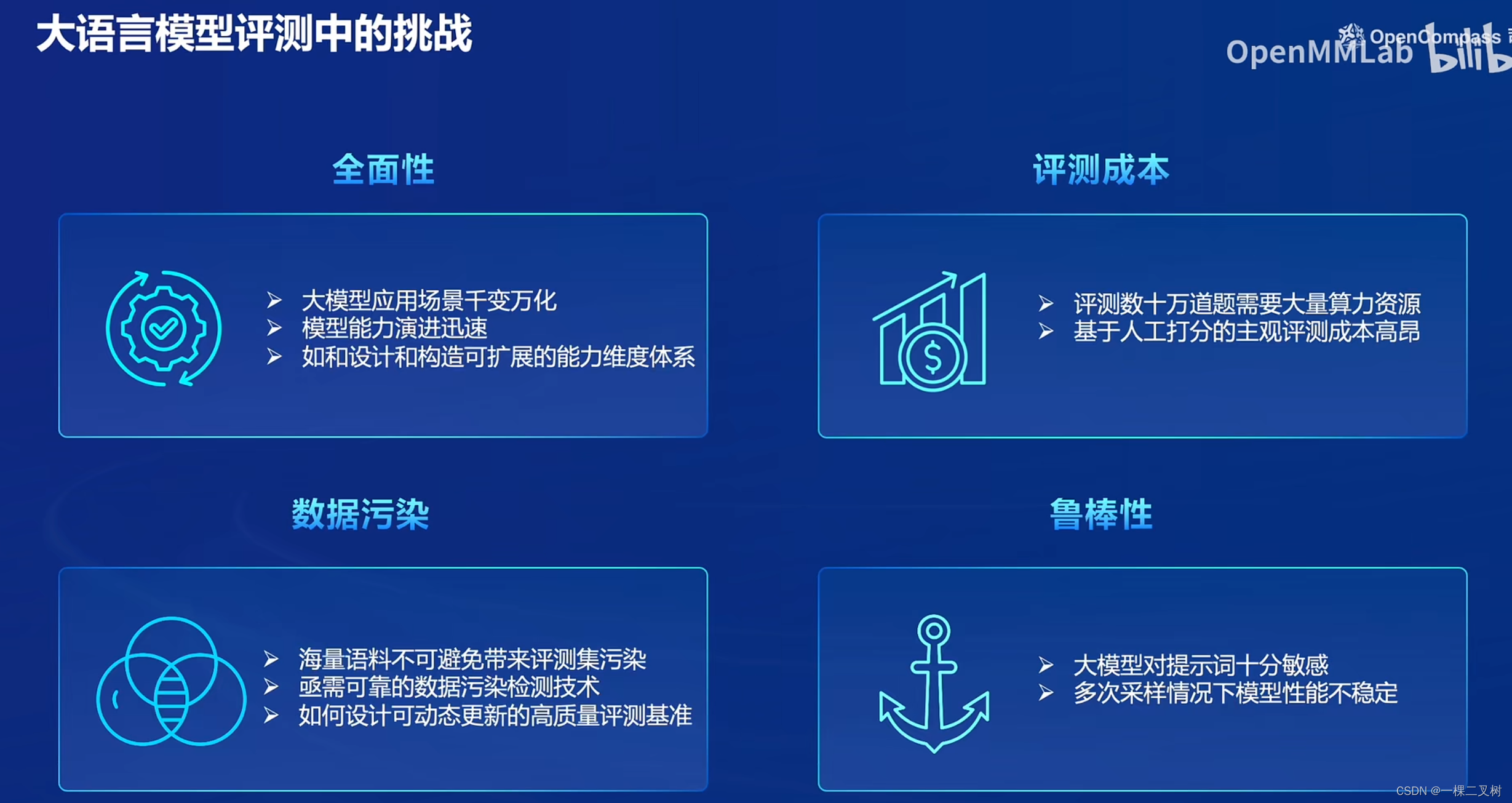
评测中的挑战
- 评测维度全面性
- 评测成本
- 数据污染
- 鲁棒性
OpenCompass 2.0司南大模型评测体系开源历程:

OpenCompass广泛应用于头部大模型企业和科研机构
 评测大模型种类:基座模型、公开权重的开源模型、对话模型、API模型
评测大模型种类:基座模型、公开权重的开源模型、对话模型、API模型
 评测种类:
评测种类:
1.客观评测,客观问答题,客观选择题
针对具有标准答案的客观问题,我们可以我们可以通过使用定量指标比较模型的输出与标准答案的差异,并根据结果衡量模型的性能。同时,由于大语言模型输出自由度较高,在评测阶段,我们需要对其输入和输出作一定的规范和设计,尽可能减少噪声输出在评测阶段的影响,才能对模型的能力有更加完整和客观的评价。 为了更好地激发出模型在题目测试领域的能力,并引导模型按照一定的模板输出答案,OpenCompass 采用提示词工程 (prompt engineering)和语境学习(in-context learning)进行客观评测。 在客观评测的具体实践中,我们通常采用下列两种方式进行模型输出结果的评测:
- 判别式评测:该评测方式基于将问题与候选答案组合在一起,计算模型在所有组合上的困惑度(perplexity),并选择困惑度最小的答案作为模型的最终输出。例如,若模型在 问题? 答案1 上的困惑度为 0.1,在 问题? 答案2 上的困惑度为 0.2,最终我们会选择 答案1 作为模型的输出。
- 生成式评测:该评测方式主要用于生成类任务,如语言翻译、程序生成、逻辑分析题等。具体实践时,使用问题作为模型的原始输入,并留白答案区域待模型进行后续补全。我们通常还需要对其输出进行后处理,以保证输出满足数据集的要求。
2.主观评测,开放式主观问答(比较、打分)
语言表达生动精彩,变化丰富,大量的场景和能力无法凭借客观指标进行评测。针对如模型安全和模型语言能力的评测,以人的主观感受为主的评测更能体现模型的真实能力,并更符合大模型的实际使用场景。 OpenCompass 采取的主观评测方案是指借助受试者的主观判断对具有对话能力的大语言模型进行能力评测。在具体实践中,我们提前基于模型的能力维度构建主观测试问题集合,并将不同模型对于同一问题的不同回复展现给受试者,收集受试者基于主观感受的评分。由于主观测试成本高昂,本方案同时也采用使用性能优异的大语言模拟人类进行主观打分。在实际评测中,本文将采用真实人类专家的主观评测与基于模型打分的主观评测相结合的方式开展模型能力评估。 在具体开展主观评测时,OpenComapss 采用单模型回复满意度统计和多模型满意度比较两种方式开展具体的评测工作。

如何构造好的提示词?遵循5个标准:明确性、概念无歧义、逐步引导、具体表述、迭代反馈
 提示方法:小样本学习、思维链技术
提示方法:小样本学习、思维链技术
 长文本评测举例:
长文本评测举例:
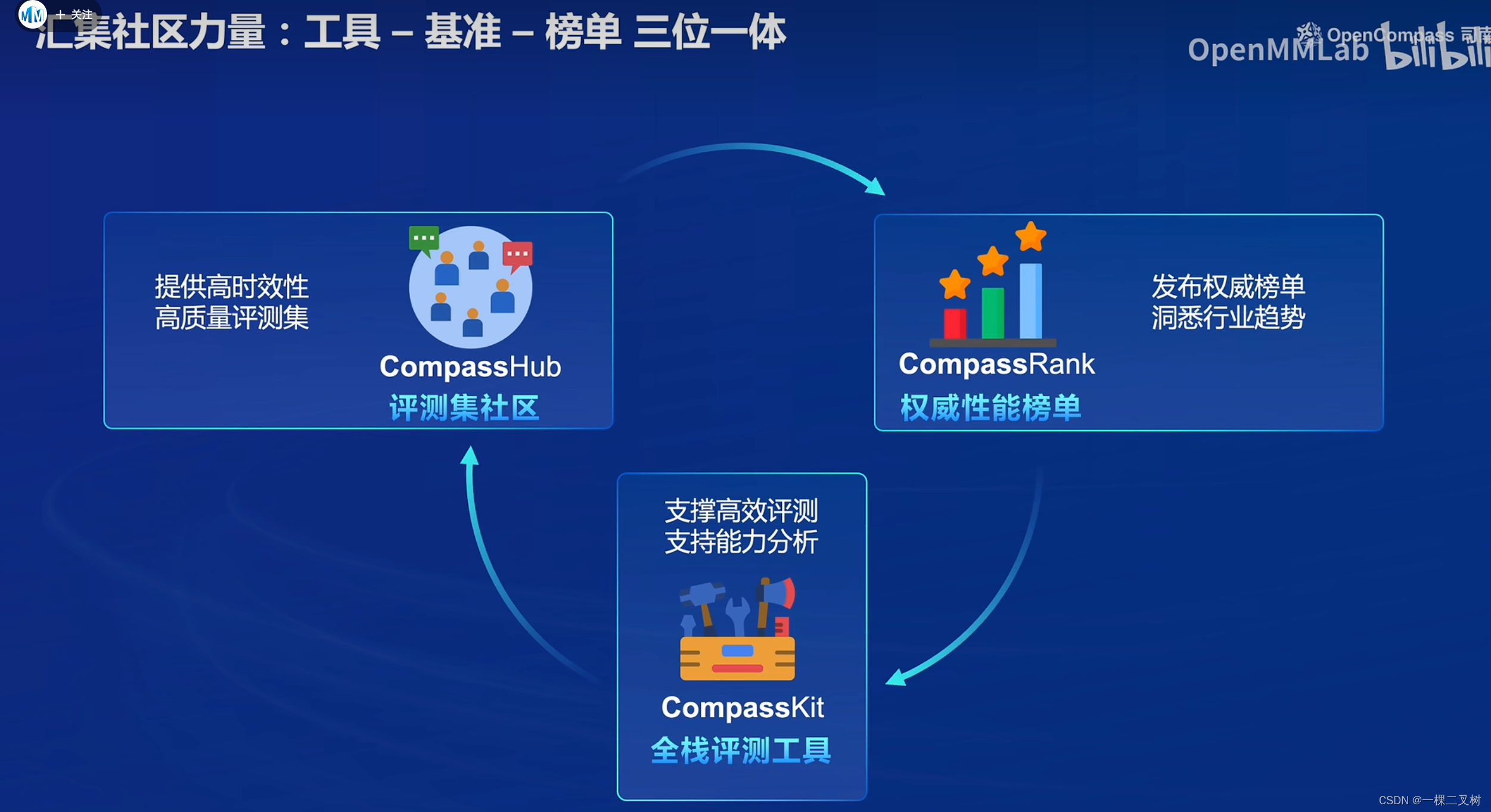
OpenCompass作用:
1. Compass Hub:提供高时效性、高质量评测集
2. CompassRank: 发布权威榜单
3. CompassKit: 全栈评测工具
 CompassRank:
CompassRank: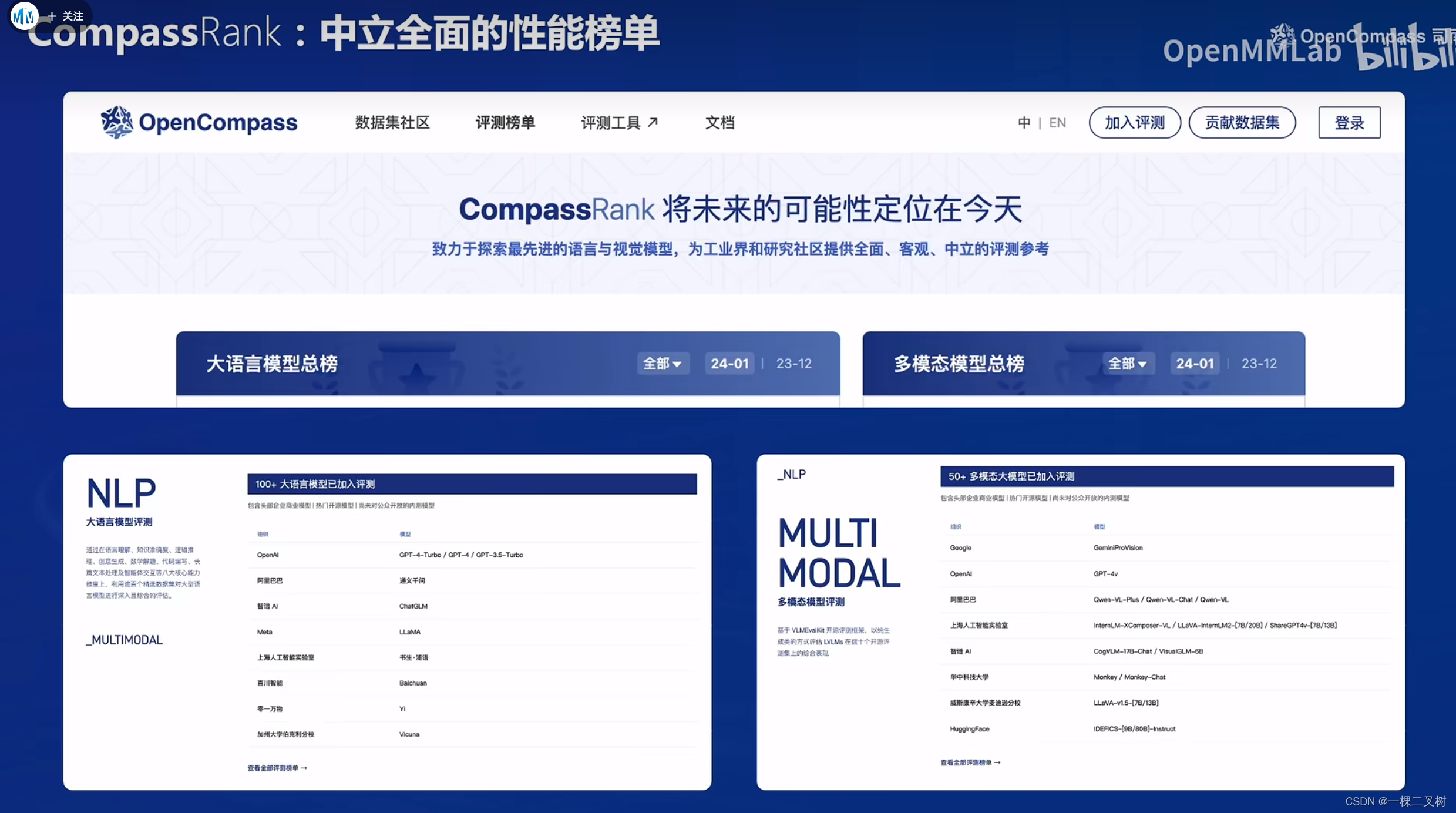
CompassKit:

 Compass Hub:
Compass Hub:

在 OpenCompass 中评估一个模型通常包括以下几个阶段:配置 -> 推理 -> 评估 -> 可视化。
- 配置:这是整个工作流的起点。您需要配置整个评估过程,选择要评估的模型和数据集。此外,还可以选择评估策略、计算后端等,并定义显示结果的方式。
- 推理与评估:在这个阶段,OpenCompass 将会开始对模型和数据集进行并行推理和评估。推理阶段主要是让模型从数据集产生输出,而评估阶段则是衡量这些输出与标准答案的匹配程度。这两个过程会被拆分为多个同时运行的“任务”以提高效率,但请注意,如果计算资源有限,这种策略可能会使评测变得更慢。如果需要了解该问题及解决方案,可以参考 FAQ: 效率。
- 可视化:评估完成后,OpenCompass 将结果整理成易读的表格,并将其保存为 CSV 和 TXT 文件。你也可以激活飞书状态上报功能,此后可以在飞书客户端中及时获得评测状态报告。 接下来,我们将展示 OpenCompass 的基础用法,展示书生浦语在
C-Eval基准任务上的评估。它们的配置文件可以在configs/eval_demo.py中找

能力维度:基础能力;综合能力
 自研高质量大模型评测基准
自研高质量大模型评测基准




















 518
518











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









