






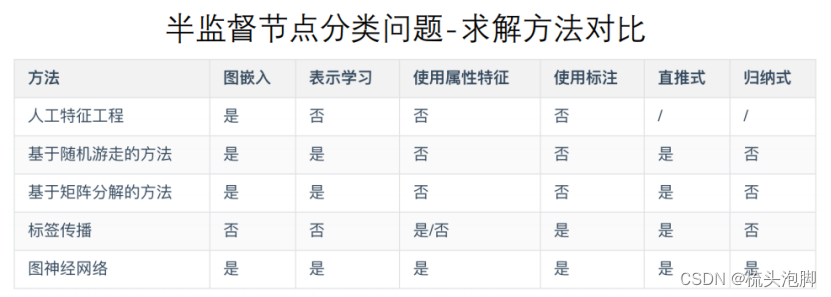
图神经网络(GNN)及图卷积网络GCN
图上面有三种常规类型的预测任务:图层面,节点层面,边层面。GNN是对保持图对称性(排列不变性)的图的所有属性(节点、边、全局上下文)的可优化转换。对称信息指的是把这个顶点进行另外一个排序后,整个结果是不会变的。一个函数f将节点映射到d维嵌入,以便图中的相似节点紧密嵌入在一起。
编码器(encode)
将每个节点映射到一个低维向量,直观上解释为将我们图中的节点转化为计算机可输入的矩阵(向量),如下图所解释:
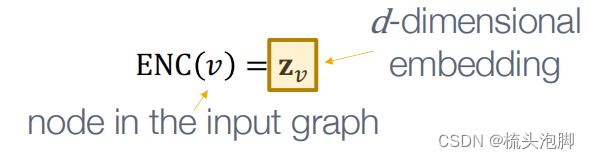

相似度函数:指定向量空间中的关系如何映射到原始网络中的关系:

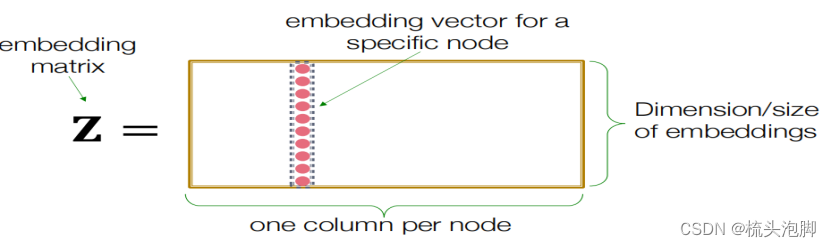
浅层编码:
最简单的编码方法:编码器只是一个嵌入查找:
浅层嵌入方法的局限性:
1.需要个参数:节点之间不共享参数;每个节点都有自己独特的嵌入
2.固有的“转换”:不能为训练中看不到的节点生成嵌入
3.不包含节点特征:许多图中的节点有我们可以而且应该利用的特征
深度图编码器:
现在将讨论基于图神经网络(GNNS)的深度学习方法:(ENC)=基于图结构的多层非线性变换。所有这些深度编码器都可以与前面定义的节点相似度函数相结合。通过GNNS,我们可以解决:节点分类(预测给定节点的类型)、连接预测(预测两个节点是否连接)、社区检测(识别节点的密集连接)、簇网络相似性(两个(子)网络的相似程度)。

现代深度学习工具箱是为简单的序列和网格而设计的,但是网络要复杂得多:任意大小和复杂的拓扑结构(即,没有像网格那样的空间局部性);没有固定的节点排序或参考点;通常是动态的和具有多模态的特性。
深度学习的基础知识
损失函数:,f可以是一个简单的线性层,一个MLP,或其他神经网络(例如,稍后的GNN);采样一小批输入x;向前传播:计算给定x的L;反向传播:使用链式规则获取梯度
;使用随机梯度下降(SGD)在多次迭代中优化Θ的L。
局部网络邻域:描述聚合策略、定义计算图
叠加多层:描述模型、参数、训练;如何拟合模型;无监督和有监督训练的简单例子
假设我们有一个图:V是顶点集,A是邻接矩阵(假设为二进制矩阵),是一个包含节点特征的矩阵;v:在V中的节点; N(v)表示v的邻域(与节点v相连的所有节点的集合)。一个直接的想法是连接邻接矩阵和特征,将它们输入一个深度神经网络,如下图,
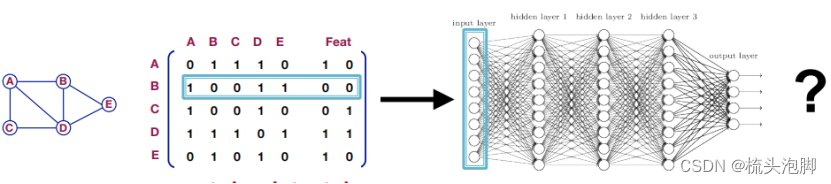
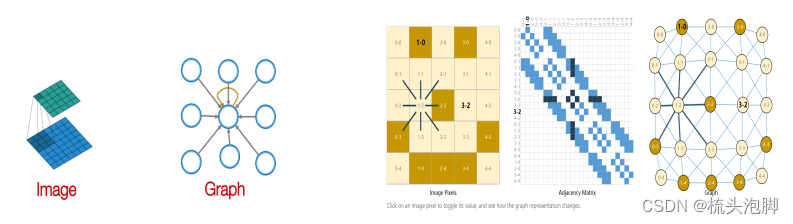
但这个想法的问题是:个参数,参数量爆炸会发生过拟合;对节点排序敏感,不具备变换不变形;不适用于不同大小的图形,没法泛化。邻接矩阵与节点编号顺序密不可分,用邻接矩阵是行不通的。我们需要的是一个置换不变性的函数。另一个想法是我们可以用卷积网络,例如我们将CNN用在图像image上,目标是利用节点特征/属性(例如,文本、图像)来推广简单格之外的卷积。但是我们的图是这样的:
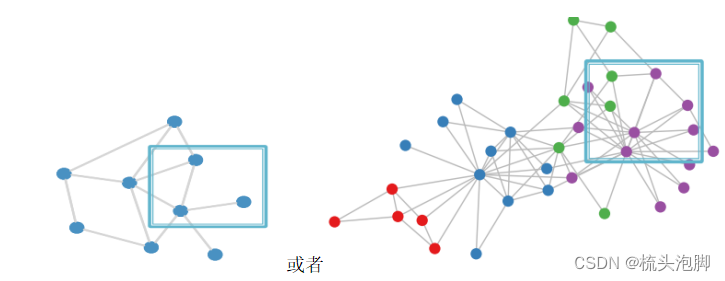
在图上没有固定的参考点或也没有滑动窗口,并且图自身具有变换不变性。
图卷积神经网络GCN
图的深度学习
通过传递和聚合来自邻居的信息,设计出排列不变/等变的图神经网络!
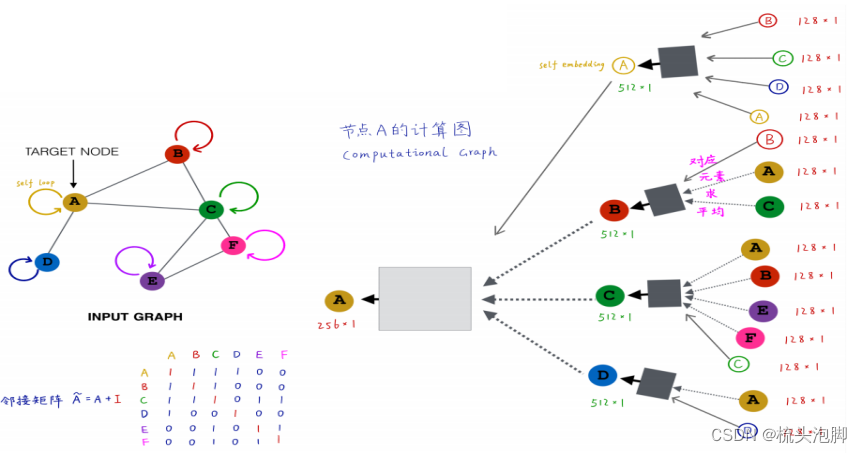
基于局部邻域生成节点嵌入(构建计算图):
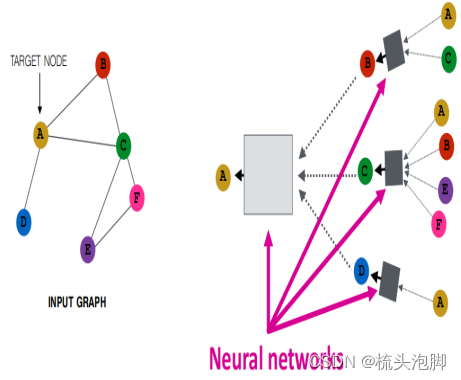
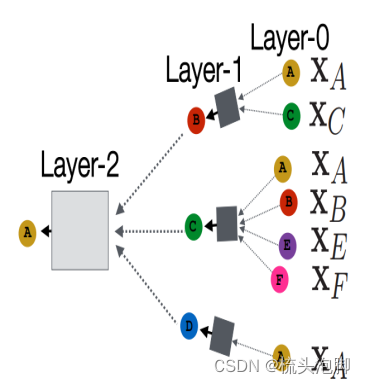
上图我们构建A节点的计算图:找到节点A的邻居B、C、D,再分别找出他们的邻居,每个节点的邻居是固定的和他的取名没有关系,将AC属性特征输入黑箱得到B的属性特征、依次ABEF输入得到C,A输入得到D;再结合BCD属性得到A的embedding。
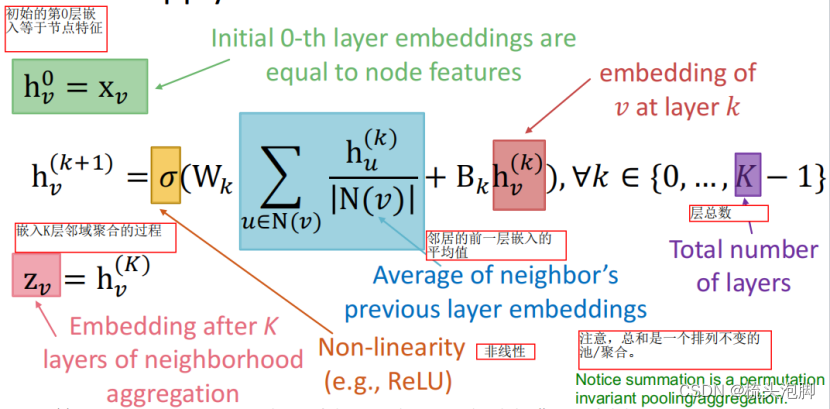
类似的,没给节点都能构建自己的计算图。计算图结构相同则节点功能角色相同。模型理论上可以具有任意的深度:节点在每一层都有嵌入;节点的第0层嵌入是它的输入特征x_v;k层嵌入从k跳后的节点中获取信息;图神经网络的层数是计算图的层数而不是神经网络的层数。
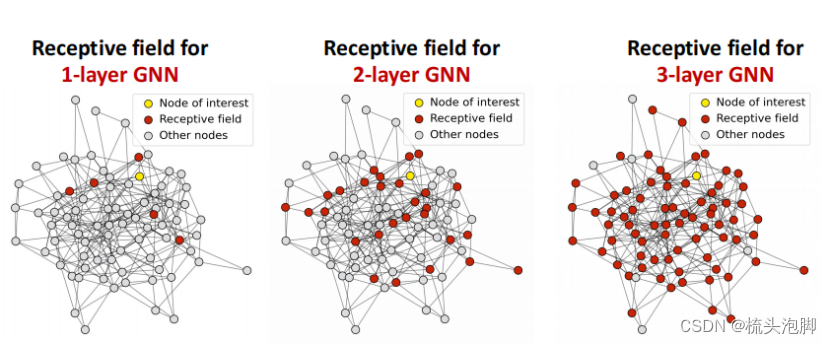
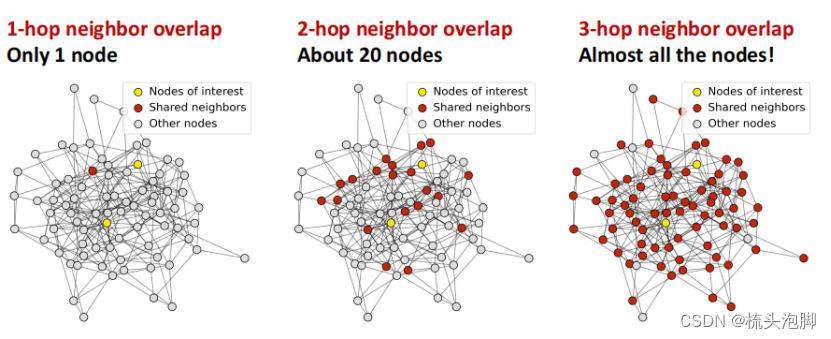
K层GNN的感受野:确定感兴趣节点的嵌入的节点集,每个节点都有一个k跳邻域的接受域;两个节点的接受域重叠,当我们增加跳跃数(GNN层数)时,共享邻居迅速增长。
一个GCN的不变性和等方差性质
给定一个节点,计算其嵌入的GCN是排列不变
考虑到图中的所有节点,GCN的计算是置换等变的,详细的推理方法:1。输入节点特征和输出嵌入的行对齐2。我们知道用GCN计算一个给定节点的嵌入是不变的。 3.因此,经过置换后,改变给定节点在输入节点特征矩阵中的位置,给定节点的输出嵌入保持不变(节点特征和嵌入的颜色匹配),这是置换等变的。如下图:
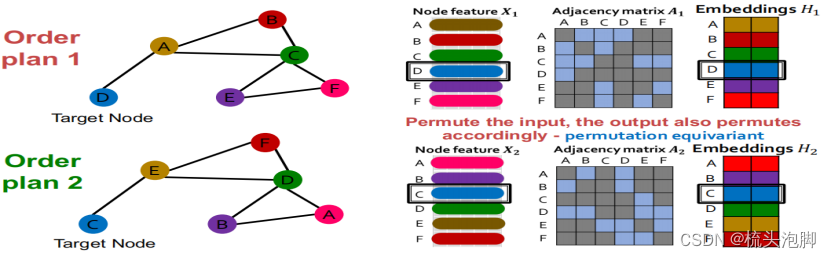
邻域聚合
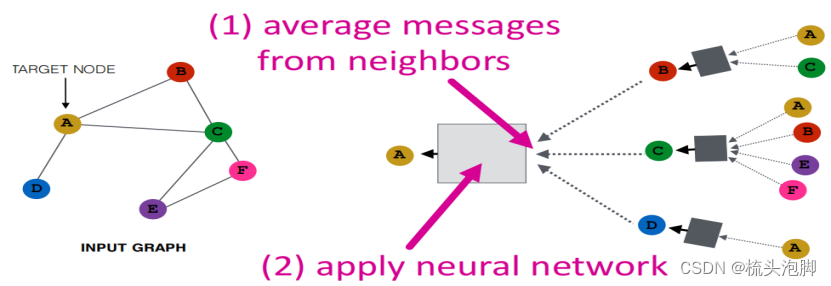
关键的区别在于不同的方法如何跨层聚合信息
基本方法:获取来自邻居的平均信息,并应用一个神经网络(改进是加上自己的信息并赋予不同的权重)
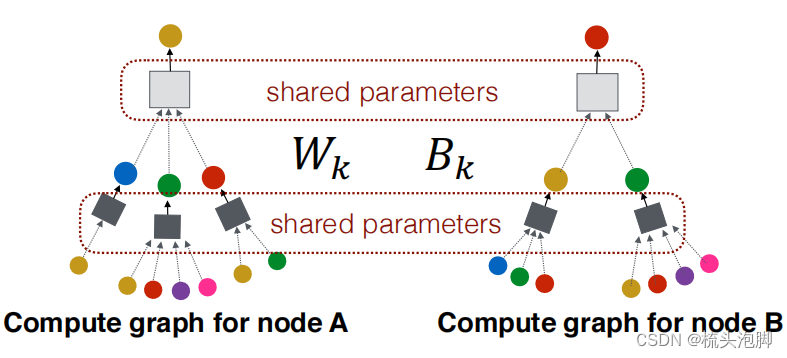
在训练GCN来生成嵌入时,需要在嵌入上定义一个损失函数:我们可以将这些嵌入输入到任何损失函数中,并运行SGD来训练权重参数。W_k:邻域聚合的权重矩阵,B_k:变换自隐向量的权值矩阵。
矩阵表示:令D为一个对角矩阵,
也是对角阵:
。令
,则 :
。其中
表示邻接矩阵的第 v 行,因此:
。
所以,,其中,
。上式子中,红色表示邻域聚合;蓝色表示自转化。
(稀疏的)叫做行归一化矩阵,其最大特征值为1。固有对称标准矩阵
是一个对称,矩阵既考虑了自己的度也考虑了对方的度,但特征值在(-1,1),输入向量左乘该矩阵之后幅值会变小。对称归一化矩阵:
, 最大特征值为1。
GNN 的训练
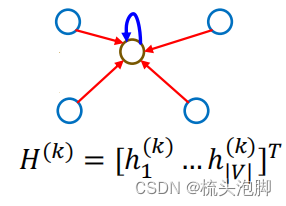
节点嵌入 Z_v 是一个输入图的函数
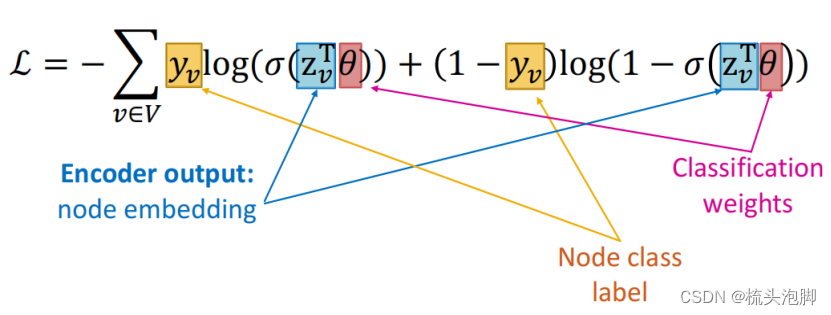
有监督学习:我们想最小化损失 其中 y: 节点标签,如果 y 是实数,则£可以是 L2,如果 y 是分类则£ 可以是交叉熵。直接训练模型以执行监督任务 (例如,节点分类)。使用交叉熵损失:
无监督学习:没有可用的节点标签,使用图形结构作为监督!一个可能的想法是:“相似的” 节点有类似的嵌入:,当 u,v 是相似的时候
和 DEC(·,·)是点积。CE 是交叉熵的损失:
和
是第 i类的实际值和预测值;损失越低,预测越接近一。节点相似性可以是前面的任何内容, 例如,基于随机游走(node2vec,DeepWalk,struc2vec)、矩阵分解等。
GCN步骤
- 定义一个邻域聚合函数
- 在嵌入上定义一个损失函数
- 在一组节点上进行训练,即一批计算图
- 根据需要为节点生成嵌入信息,即使是对于我们从未训练过的节点!
对于所有节点,都将共享相同的聚合参数:
GNNs与CNN的区别
GNN 的公式为: 而CNN 的公式本来为
, 我 们可以把它写 成
.类比两个式子,再看如下两图
我们可以把4*4的卷积看成一个图有9个节点。但是在CNN中,不同位置的邻域分别学习到不同的权重,但是在 GCN 中,卷积核权重由预定义。CNN 可以看作是一个特殊的 GNN, 具有固定的邻居大小和顺序:过滤器的大小是为 CNN 预先定义的。GNN 的优点是它对每个节点处理不同程度的任意图。CNN不是排列不变/等变的。切换像素的顺序会导致不同的输出。
GNN与Tansformer区别
Tansformer是最流行的架构之一,在许多序列建模任务中取得了良好的性能。它的重要部分是注意力机制,注意力的一般定义:给定一组向量值和一个向量查询,注意是一种计算依赖于查询的值的加权和的技术。每个标记/单词都有一个值向量和一个查询向量。
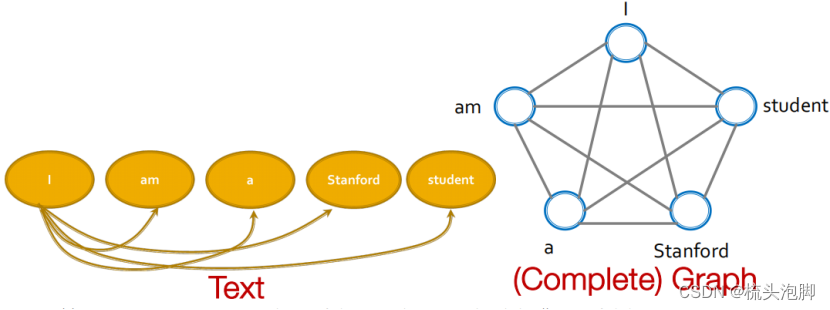
 值向量可以看作是标记/单词的表示。我们使用查询向量来计算注意力分数(加权和中的权重)。通过自注意力机制,使得每个单词之间都相互影响。Tansformer可以当成一个特殊的GNN,它运行在一个完全相连的“单词”图上!由于每个单词都关注所有其他单词,所以Tansformer层的计算图与全连接的“单词”图上的GNN的计算图是相同的。
值向量可以看作是标记/单词的表示。我们使用查询向量来计算注意力分数(加权和中的权重)。通过自注意力机制,使得每个单词之间都相互影响。Tansformer可以当成一个特殊的GNN,它运行在一个完全相连的“单词”图上!由于每个单词都关注所有其他单词,所以Tansformer层的计算图与全连接的“单词”图上的GNN的计算图是相同的。















 2104
2104











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









