







Alexnet:
使用卷积层分类,Dropout在训练时随机失活设定比例参数,减少过拟合,在测试时不使用,
batch_size,设定单次提交给程序的样本数,GPU训练时显存大小影响
VGG:
相比于Alexnet使用多层小尺寸卷积核代替一个大尺寸卷积核,使用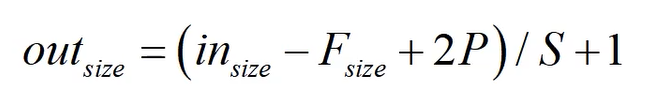 的反推公式
的反推公式
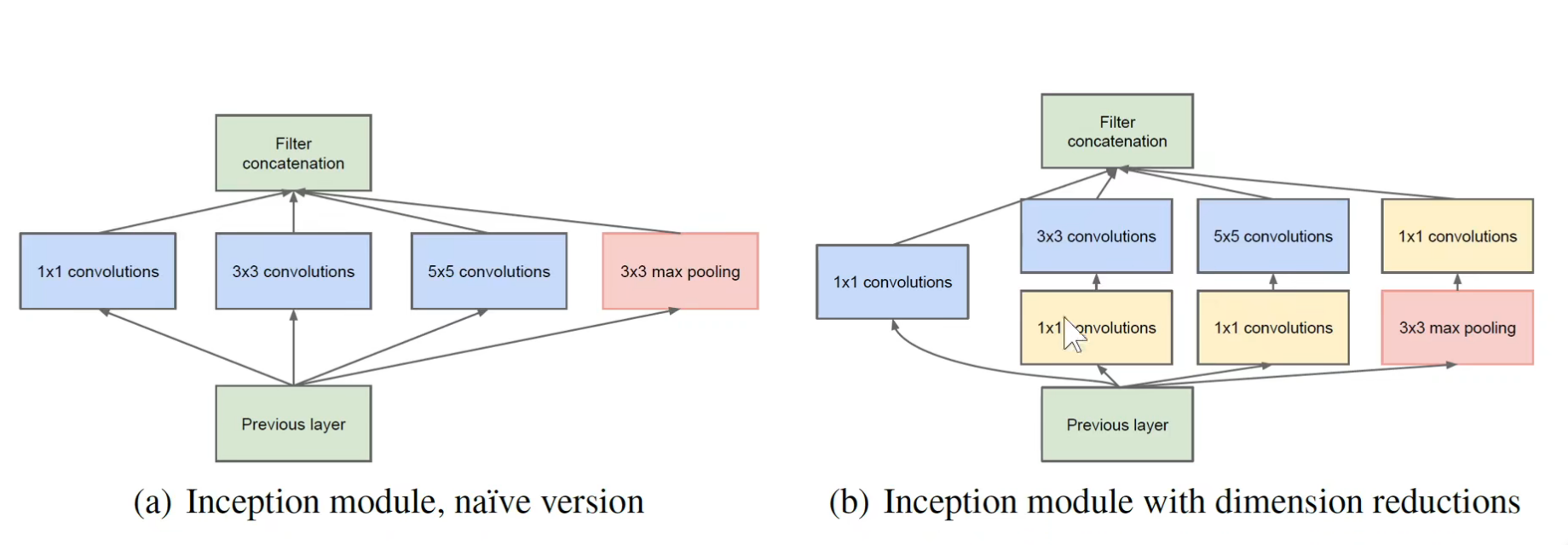
Google net:
相比于Alexnet和VGG,使用1x1的卷积核减少参数,使用inception结构,添加两个辅助分类器,没用全连接层
基础知识:每个卷积核的深度都和输入数据深度一致,输出数据深度和卷积核个数有关,使用1x1的卷积核可以减少输出深度,减少神经网络参数数量(卷积核参数,w),提升非线性表示能力

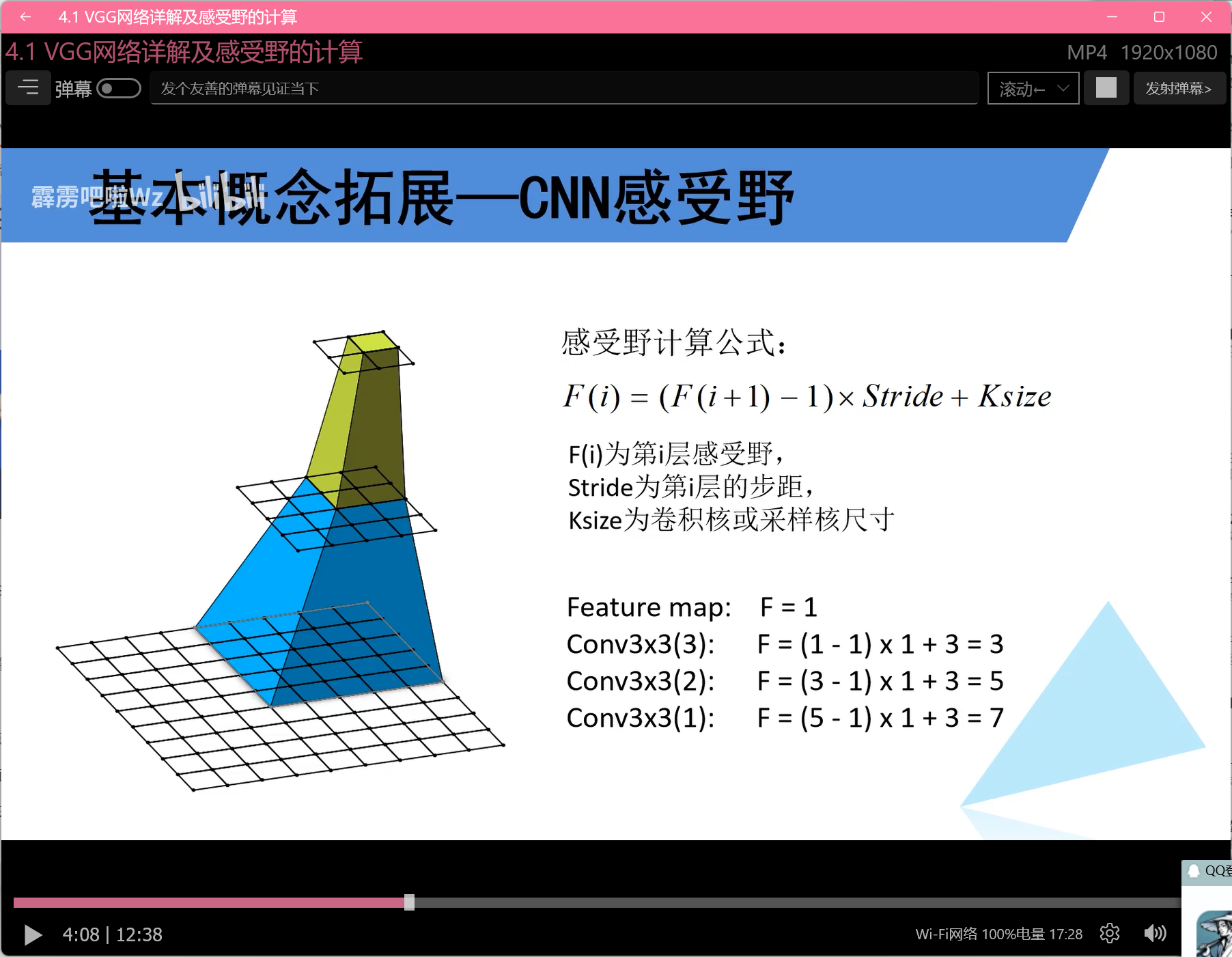
inception模块:
a会越叠加越厚,b优化a,借助1x1卷积先对输入降维,变薄
对输入数据进行不同处理,但是要求不同处理的输出长宽相同,深度可以不同,然后将不同处理的输出叠加变成下一结构的输入
辅助分类器:
辅助分类器是在模型中间部分比如inception b、d模块输出时直接进行分类操作,在最后计算损失函数时,占一定权重
ResNet:
问题:梯度消失或梯度爆炸–解决方法:输入数据正态分布处理、权重初始化、BN处理(取代Dropout)
退化问题(解决了梯度消失或爆炸还是储存在层数越深效率差)–解决方法:残差结构
下采样:
缩小图像的大小,比如通过池化操作(最大池化、平均池化)来缩小图像的宽和高
对应的,上采样就是放大图像的宽和高
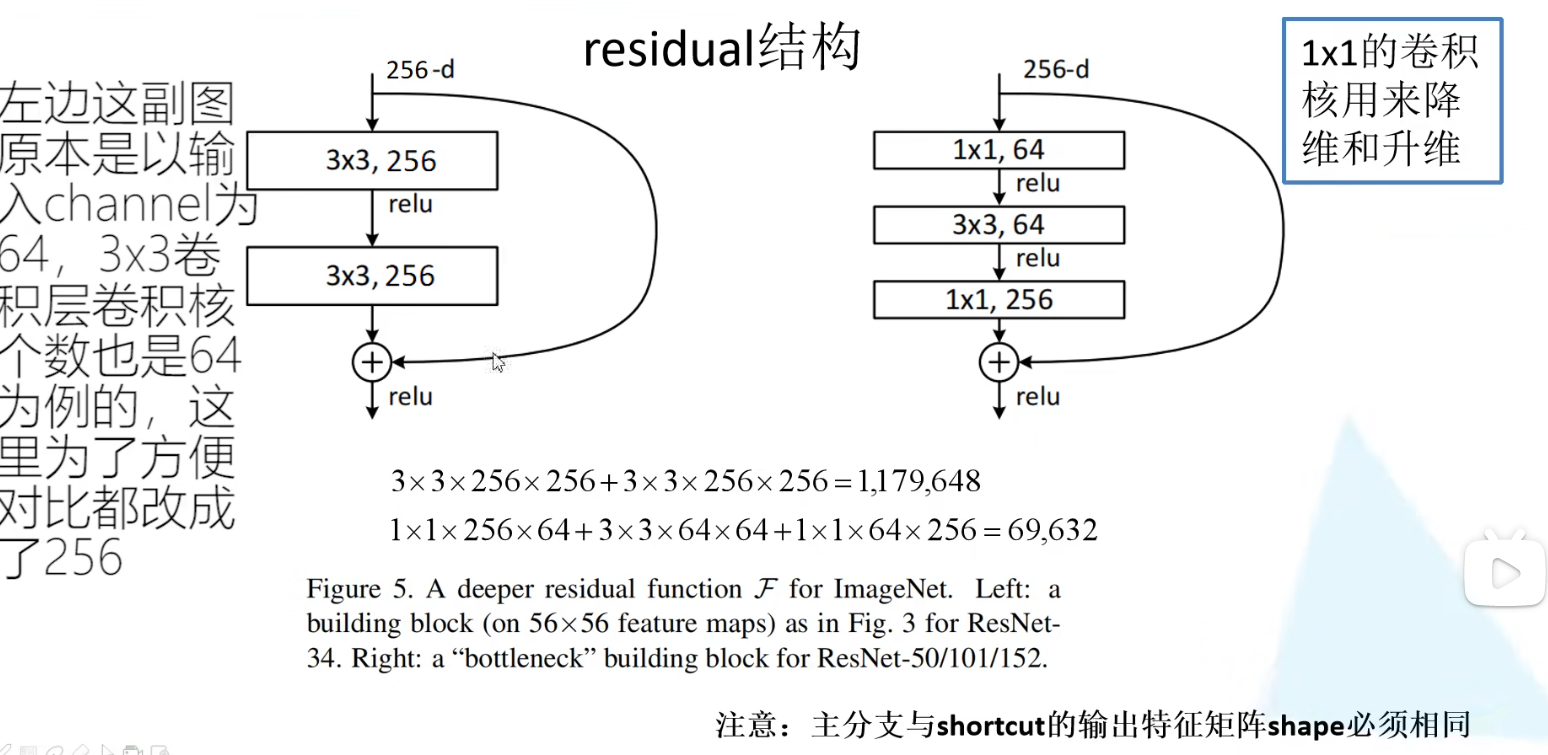
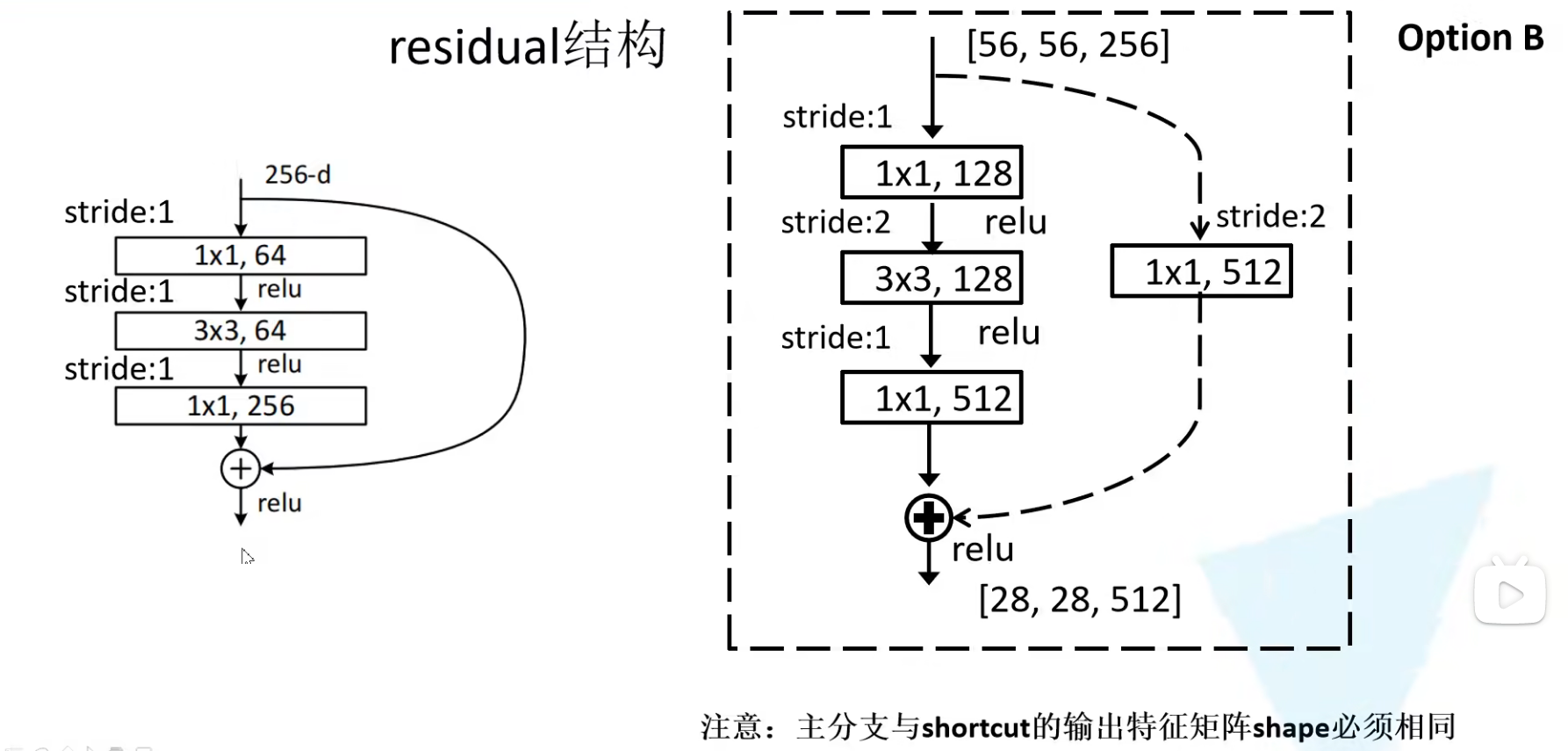
残差结构(residual模块):
将进行一系列卷积处理得到的输出矩阵和卷积处理前的输入矩阵相加(对应参数相加)—这就要求输出矩阵的长宽深度要和输入矩阵的相同,才能相加—此处先相加在设置激活函数
数据预处理-标准化:
为什么进行标准化处理:
为了消除样本不同属性具有不同量级时产生的影响:
(RGB格式中,某一颜色数值大、两张相同图案图片曝光度、色差等不同,特征值不同,导致计算机无法判定为同类型图片)
数量级的差异将导致量级较大的属性占据主导地位–很多目标函数都是假设数据集均值为0,方差为1;
数量级的差异将导致迭代收敛速度减慢;
依赖于样本距离的算法对于数据的数量级非常敏感;

规范化方法:
标准化:新数据 = (原数据 - 均值) / 标准差

归一化:新数据 = (原数据 - 最小值) / (最大值 - 最小值)
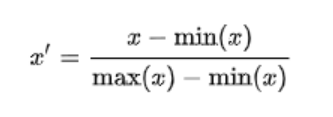
去中心化:新数据= 原数据 - 均值
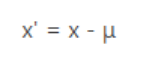

标准化,将数据变为均值为0,方差为1的数据集,但是不一定满足正态分布,标准化之前满足什么分布,标准化之后仍满足什么分布,只是将均值和方差进行修改,同时
归一化,将数据值压缩到一定的范围,可能缩小不同特征的差异,模型收敛变慢

Batch-Normalization:
采用标准化的思想,但是不是对全体数据集进行标准化,而是将每一个batch里面的数据集看作整体进行标准化
公式

均值和方差都是向量,每一个向量元素是每一个特征值的均值、方差
举例
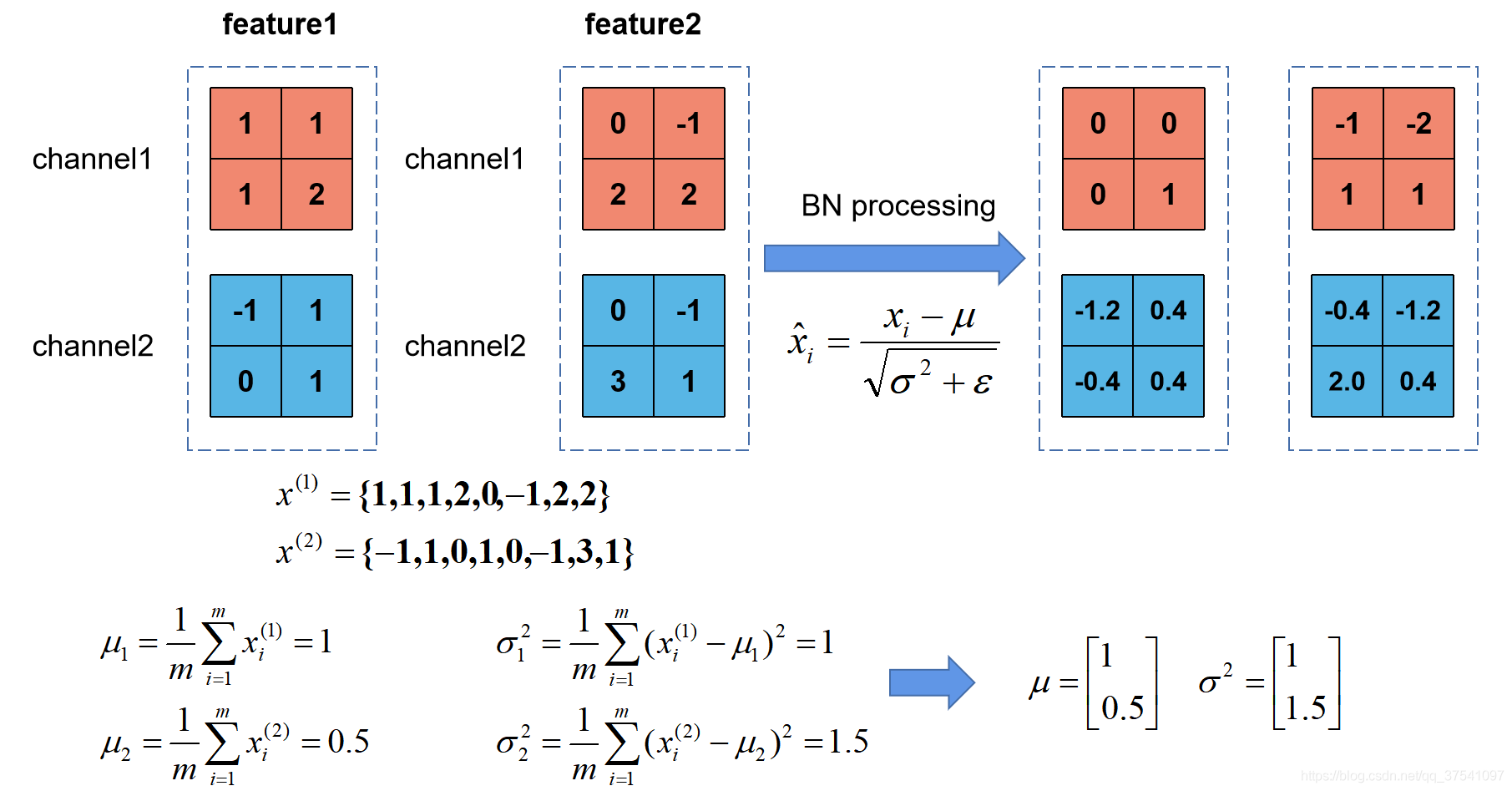
这是一个batch=2的情况,分别计算每个特征值(channel1、channel2)的均值、方差,公式中所谓的m就是单个特征值的数据个数。
注意
默认情况,BN是将batch数据集变为均值=0,方差=1,y函数是指用来修改这个默认值,γ的默认值是1,β的默认值是0,默认此时效率最好。但是在训练时可以通过反向传播学习。
训练时要将traning参数设置为True,在验证时将trainning参数设置为False。在pytorch中可通过创建模型的model.train()和model.eval()方法控制。
batch size尽可能设置大点,设置小后表现可能很糟糕,设置的越大求的均值和方差越接近整个训练集的均值和方差。
建议将bn层放在卷积层(Conv)和激活层(例如Relu)之间,且卷积层不要使用偏置bias,因为没有用,参考下图推理,即使使用了偏置bias求出的结果也是一样的yi b = yi,bias就是y=wx+b中的b。
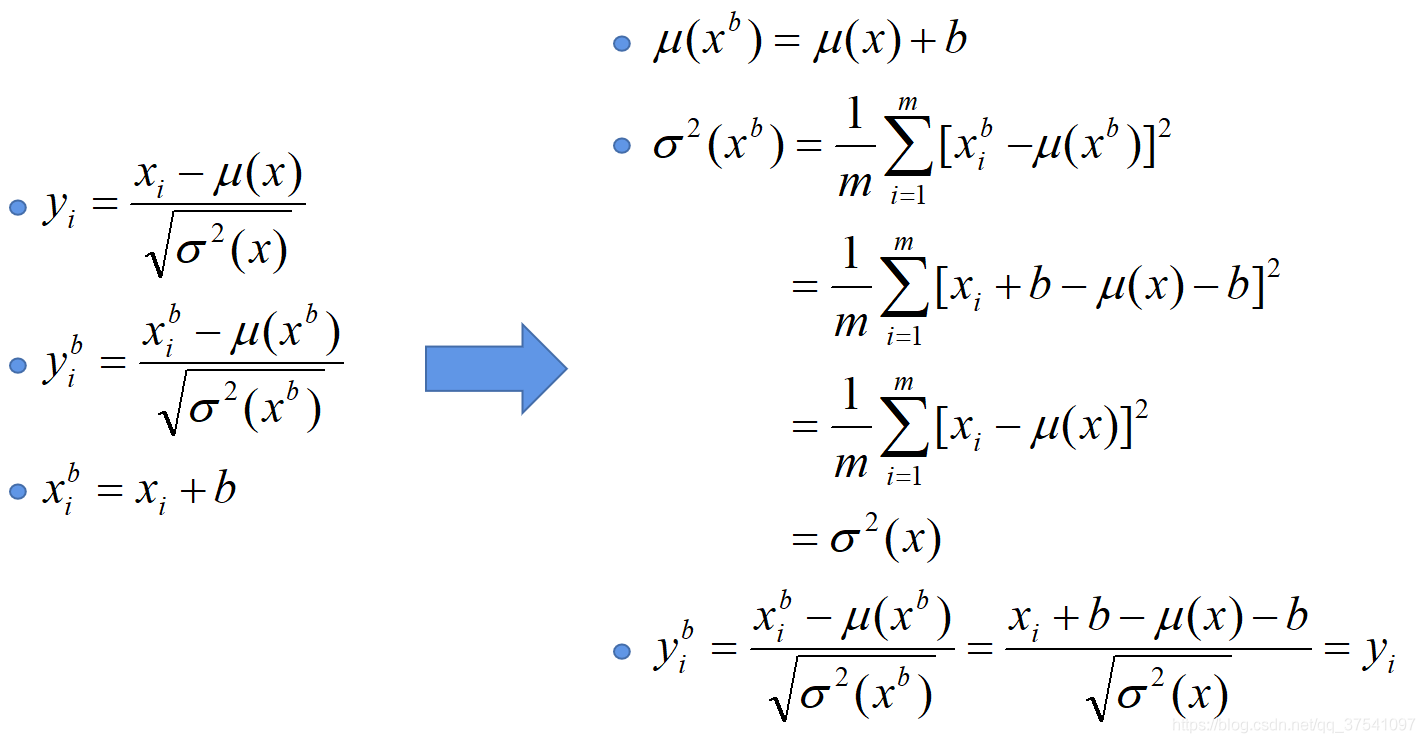
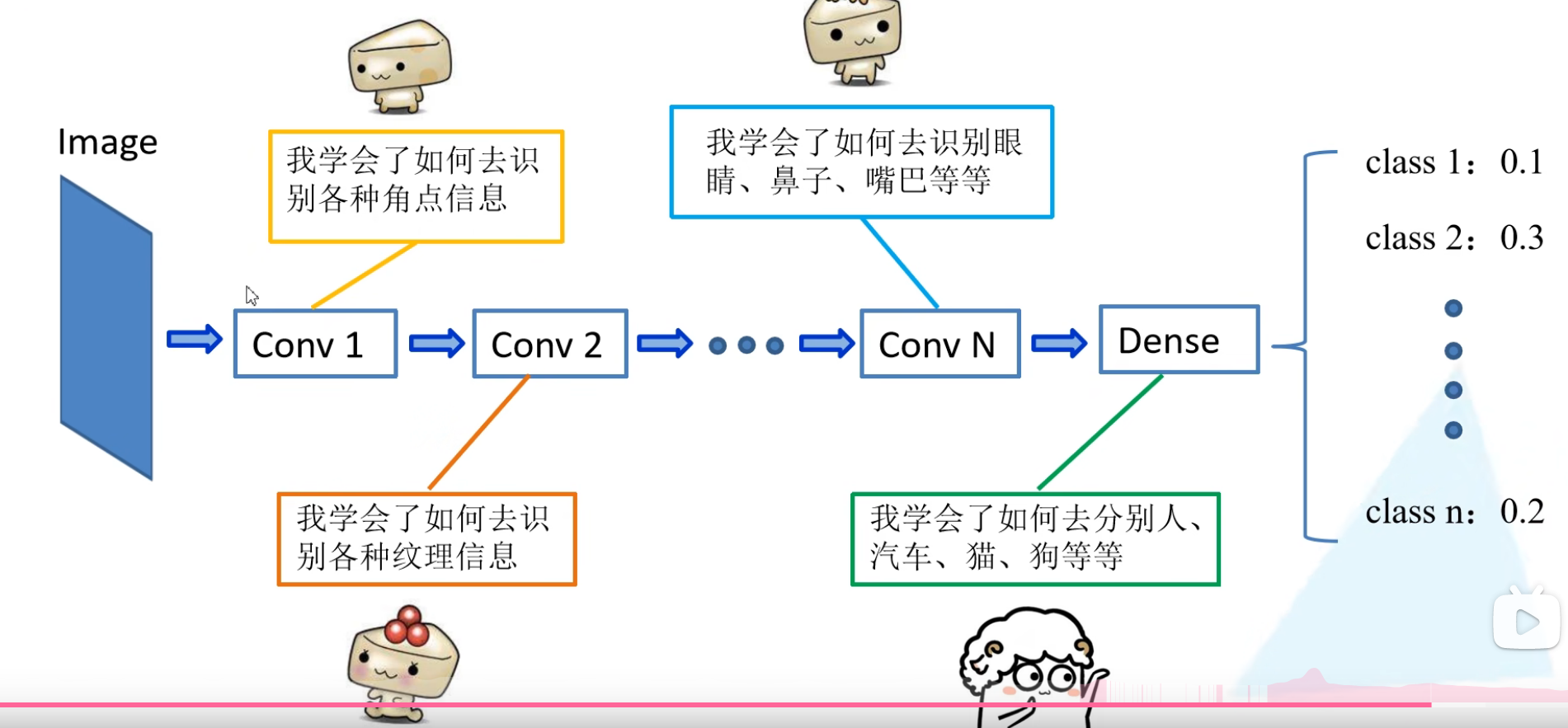
迁移学习
迁移学习是将别人已经训练好的数据部分带入自己的初始模型,再根据自己的数据集进行训练
















 7909
7909











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









