







分类模型:概率生成模型
概念
分类是寻找一个函数,当输入一个对象,输出为该对象所属的类别。
输入数值化
对于分类问题来说,要把一个对象当作一个函数的输入,则需要对对象进行数值化操作。
特征数值化:用以组数字来描述一个对象的属性。
分类问题和回归问题(为什么回归问题不适合做分类)
二元分类:在训练时让输入为类别1的输出为1,类别2的输出为-1,在测试的时候回归的输出是一个数值,我们可以将接近1的归为类别1,将接近-1的归为类别2.
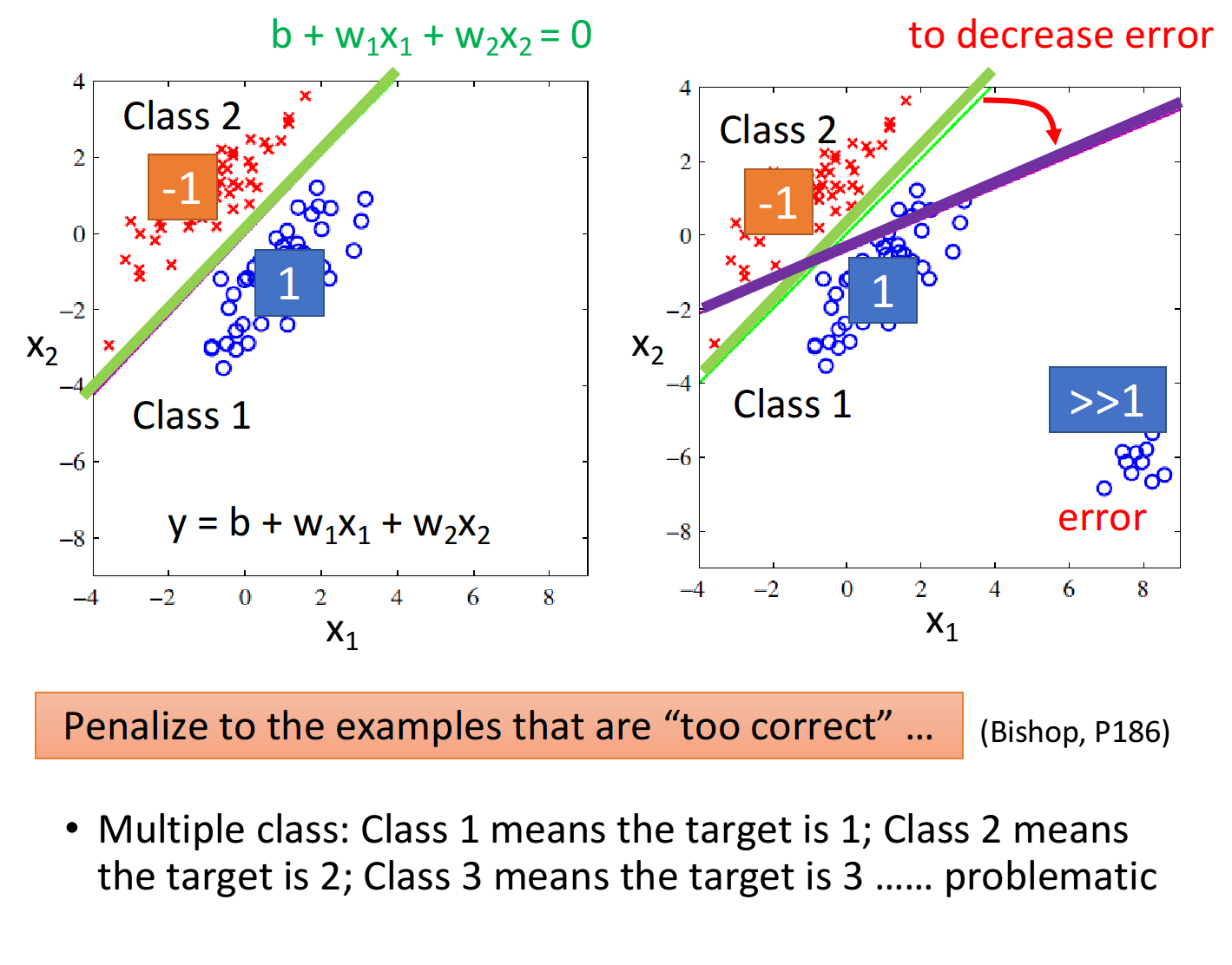
如图所示:当样本比较集中的时候,即图1,绿色线是最好的模型分界线。对于样本不集中的右下角的那些点来说,用绿色线模型时,它的左上角的值小于0,右下角的值大于0,越往右值越大,考虑右下角的这些点的话,用绿线对应的模型在做回归时,它的输出会远远大于1,但是因为已经给所有点打上,-1,1,的标签,训练中希望这些点在模型中的输出都接近于1(接近真值),那些远远大于1的点,他们对于绿线模型来说是error,是不好的,所以这组样本点通过回归训练出来的模型,会是紫色的分界线对应的模型,相对于绿线,它可以减少右下角带来的error。回归的输出是一个连续型的值,而分类的输出是离散性的值,在训练中很难找到一个回归的函数使得大部分样本点的输出都集中在某几个离散的点的附近,因此回归定义的模型对分类问题不适用。
对于多分类问题把类别1标记为1,类别2标记为2,类别3标记为3,这种方法对于回归来说,会认为类别1和类别2的关系比较近,类别2和类别3的关系比较近,而类别1和类别3的关系比较疏远,但是当这些类别间没有什么特殊关系的时候,这样的标签用回归是没有办法得到好的结果的。
Function(model):

如图:分类模型的大致定义。
损失函数:
损失函数可以定义为:
即这个模型在所有训练集上预测的错误的次数,就是分类错误的次数,错误次数越少,这个函数表现越好。
生成模型(概率分布)&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 510
510











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









