









本文仅为本人的学习笔记
文章目录
什么是协同过滤?
协同过滤(Collaborative Filtering)就是协同大家的反馈,评价和意见一起对海量的信息进行过滤,从中筛选出目标用户可能感兴趣的信息的推荐过程。
其实它的算法思想就是:物以类聚,人以群分
协同过滤算法一般有2种,一种是基于用户的协同过滤算法,一种是基于物品的协同过滤算法。
基于用户(user-based):跟你喜好相似的人喜欢的东西你也很可能喜欢;
基于物品(item-based):跟你喜欢的东西相似的东西你也很可能喜欢;
用户相似度计算(Similarity Calculation)
1.余弦相似度(Cosine Similarity)
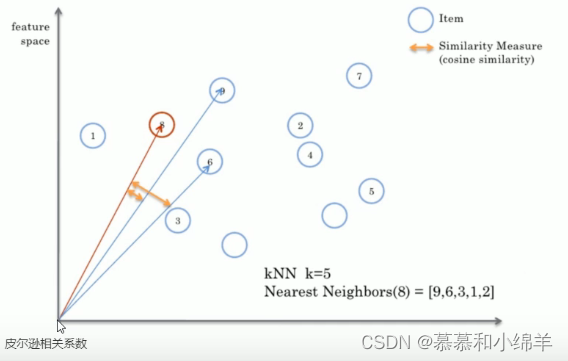
余弦相似度衡量了用户向量i和用户向量j之间的向量夹角大小,夹角越小,证明余弦相似度越大,两个用户越相似。
如下图所示,但是很明显,余弦相似度这个方法不考虑长度,只考虑大方向。所以使用余弦相似度计算出的相似度结果有时是不靠谱的。
2.皮尔逊相关系数(Pearson’s Correlation)
皮尔逊相关系数是对余弦相似度的一个优化,它通过使用用户平均分对各独立评分进行修正,比余弦相似度更多的考虑了长度。即向量a,b各自减去向量的均值后,再计算余弦相似度
3.杰卡德相似度计算(Jaccard coefficient)
以上2种,都是针对于 评分数据是连续的数值,那么如果评分是0,1这种布尔类型的,那么它的相似度通常使用杰卡德相似度计算方法。杰卡德计算方法是 交集/并集
杰卡德相似度计算代码实现
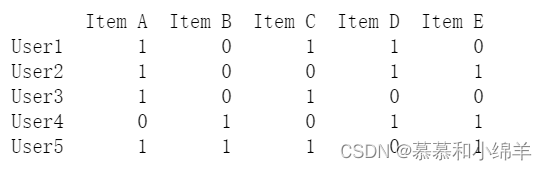
1.构造数据集
创建一个数据集,下面我们使用1和0来表示用户是否购买过该用品
users=["User1","User2","User3","User4","User5"]
items=["Item A","Item B","Item C","Item D","Item E"]
datasets=[
[1,0,1,1,0],
[1,0,0,1,1],
[1,0,1,0,0],
[0,1,0,1,1],
[1,1,1,0,1]
]
import pandas as pd
df=pd.DataFrame(datasets,
columns=items,
index=users)
print(df)
运行结果:
2.只计算2个用户之间的相似度
很明显我们的数据是1,0这种布尔类型的,所以比较适合用杰卡德相似度计算的方法
from sklearn.metrics import jaccard_similarity_score
jaccard_similarity_score(df['Item A'],df['Item B'])
结果正确,但是有报错:

原因是:

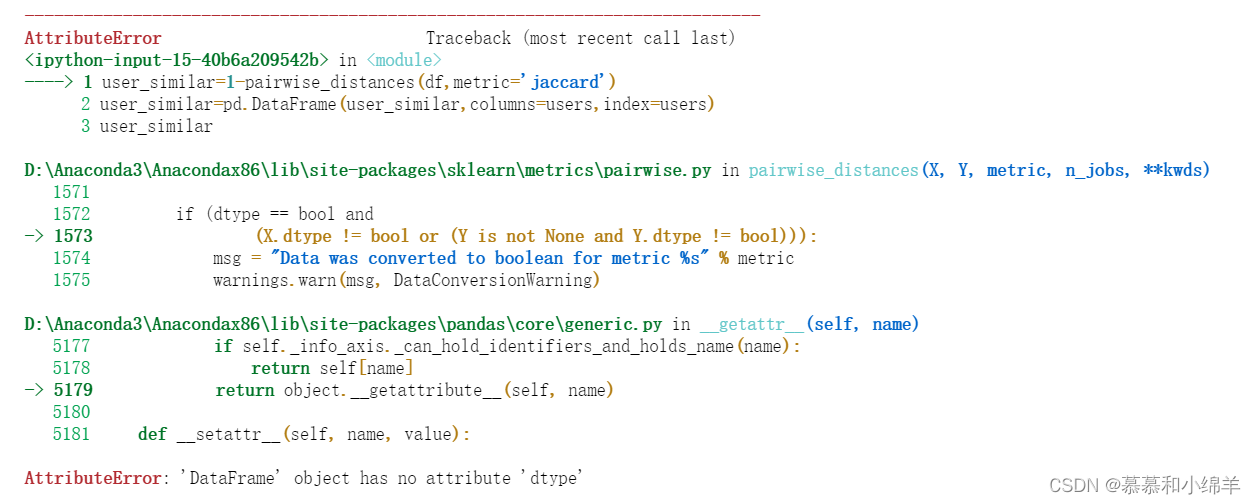
3.计算所有用户之间的相似度
from sklearn.metrics.pairwise import pairwise_distances
user_similar=1-pairwise_distances(df,metric='jaccard')
user_similar=pd.DataFrame(user_similar,columns=users,index=users)
user_similar
但是结果报错:
 解决方法,改成以下代码即可:
解决方法,改成以下代码即可:
参考链接:为什么会出现’DataFrame’ object has no attribute ‘dtype’
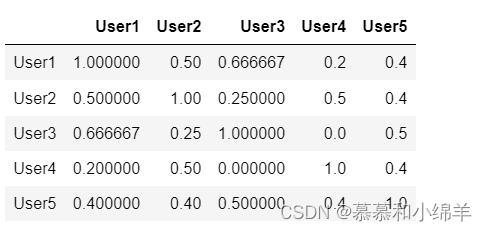
user_similar=1-pairwise_distances(df.values,metric='jaccard')
user_similar=pd.DataFrame(user_similar,columns=users,index=users)
user_similar
运行结果:
4.构建推荐结果(基于用户相似度)
为每一个用户找到最相似的2个用户
- loc[i]:通过行标签索引数据
- pandas中的sort_values()函数原理类似于SQL中的order by,可以将数据集依照某个字段中的数据进行排序。ascending值表示是否按指定列的数组升序排列,默认为True,即升序排列
- index[:2]表示从排序之后的结果中切片,取出前两条(相似度最高的两个)
topN_users={}#用来记录相似度最高的几个用户
#遍历每一行数据
for i in user_similar.index:
#取出每一列数据,并删除自身,然后排序数据,你会发现自身的相似度都是1,下面这句话也就是删除了对角线上的元素。
_df=user_similar.loc[i].drop([i])
_df_sorted=_df.sort_values(ascending=False)
top2=list(_df_sorted.index[:2])
topN_users[i]=top2
print("Top2相似用户:")
topN_users
运行结果如下:

**根据topN的相似用户构建推荐结果
- List item
import numpy as np
rs_results = {}
# 构建推荐结果
for user, sim_users in topN_users.items():
rs_result = set() # 存储推荐结果
for sim_user in sim_users:
# 构建初始的推荐结果
rs_result = rs_result.union(set(df.ix[sim_user].replace(0,np.nan).dropna().index))
# 过滤掉已经购买过的物品
rs_result -= set(df.ix[user].replace(0,np.nan).dropna().index)
rs_results[user] = rs_result
print("最终推荐结果:")
rs_results
运行结果:















 431
431











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









