






文章目录
主要记录李宏毅机器学习的一些笔记,视频链接:李宏毅2021/2022春机器学习课程
1. 机器学习
1.1 基本概念

机器学习就是具备找一个函数的能力
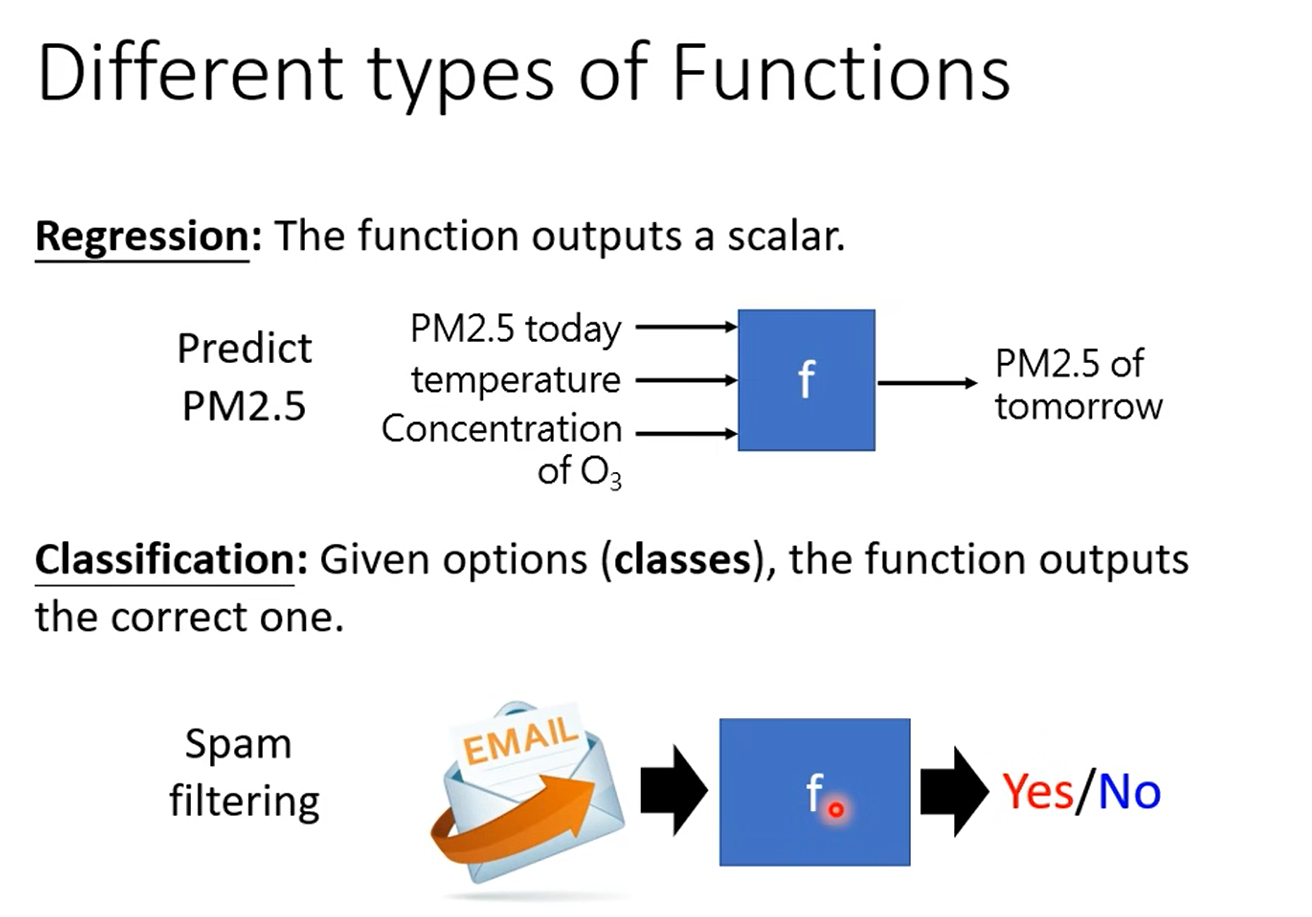
回归:函数输出值为数值
分类:给你一个选项,函数输出正确的选型
1.2 机器学习训练的过程
1.写出一个带有未知参数的函数

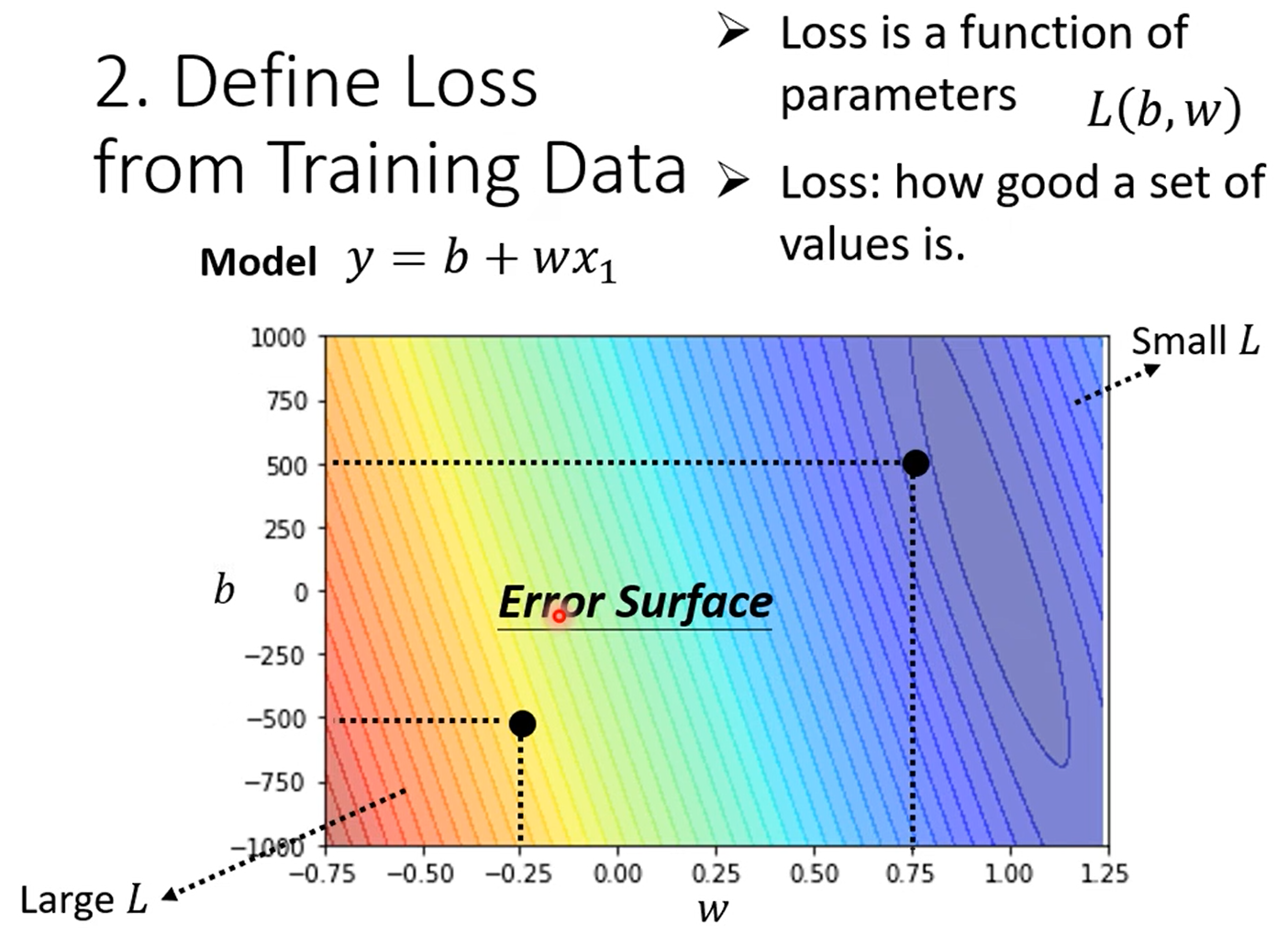
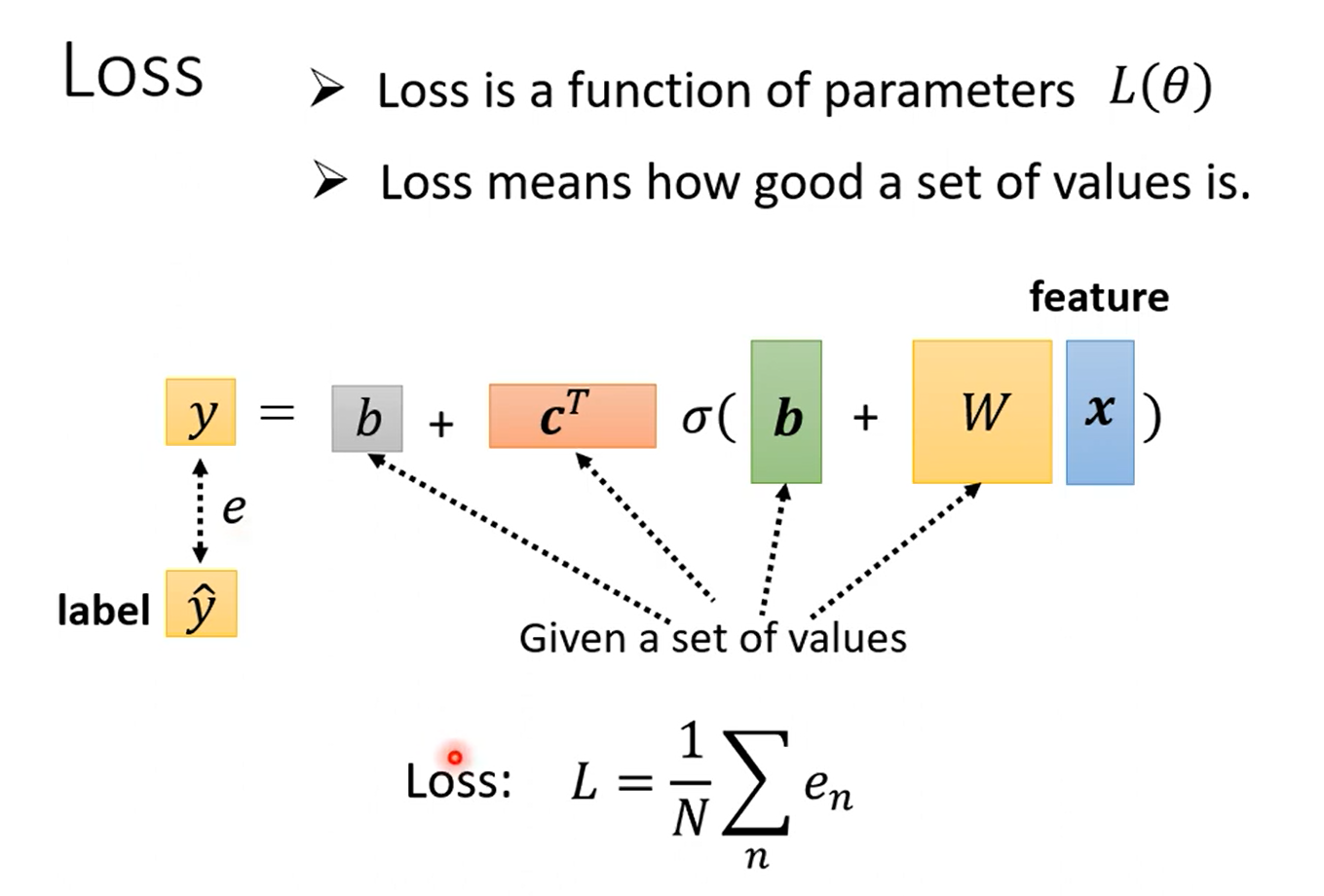
2.定义Loss

损失函数是一个基于参数的函数,例如L(b,w)
假设b=0.5k,w=1,将其带入预测函数,然后用训练数据计算预测出来的结果,计算预测的结果与真实的结果。

Loss就是真实结果与预测结果差值之和
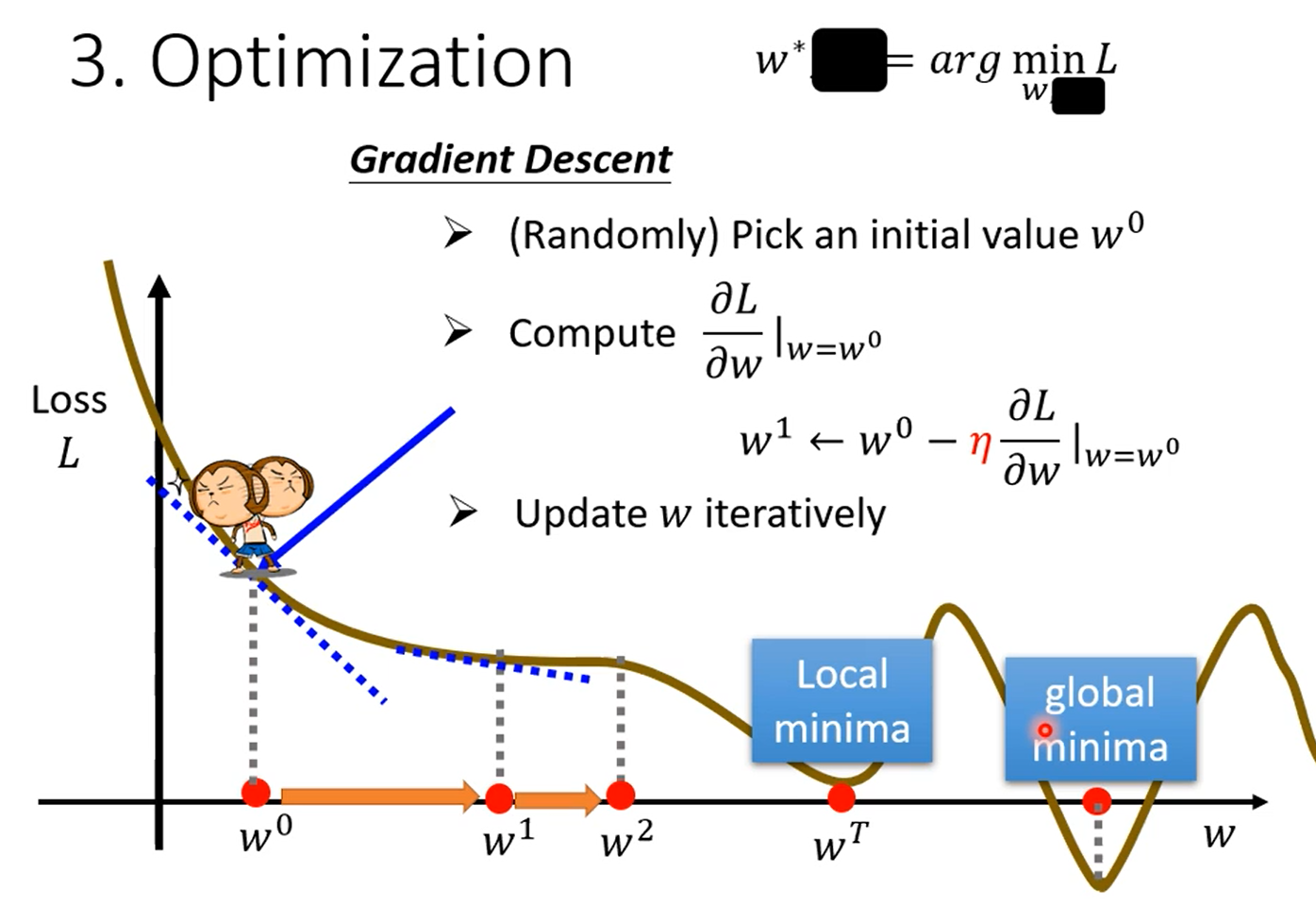
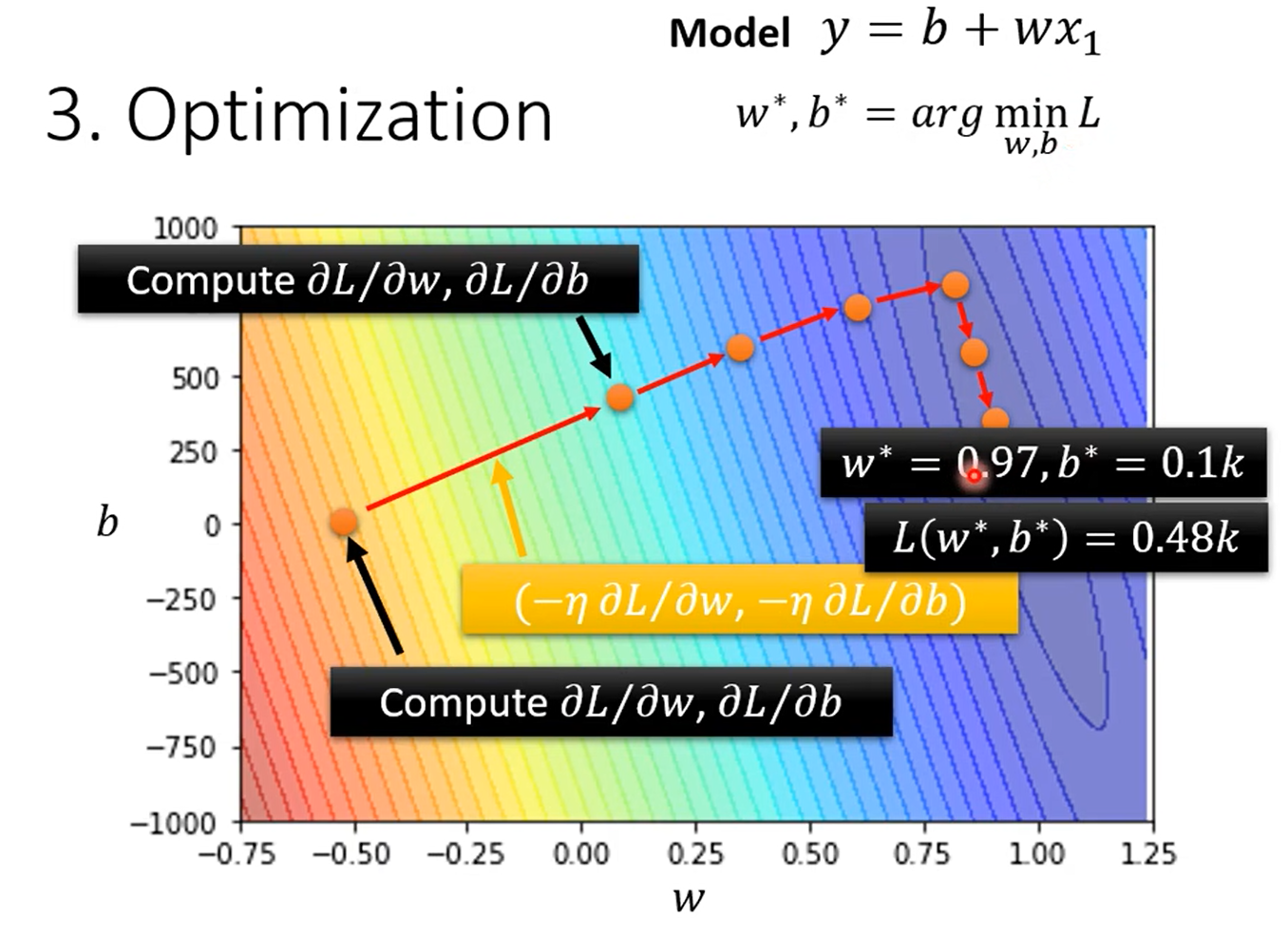
3.优化
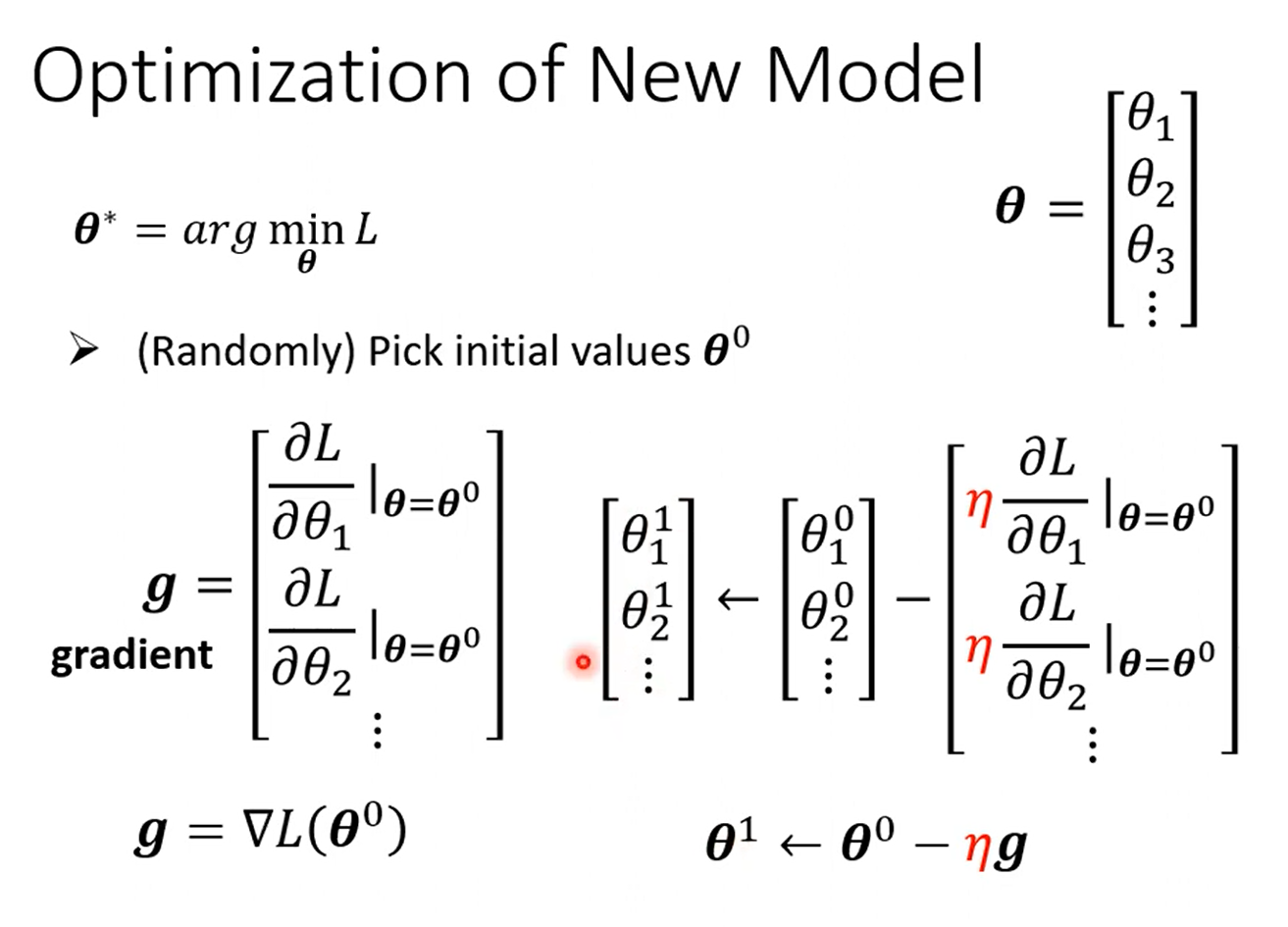
梯度下降:(找到一个w使得loss值最小)
-
随机初始化一个值 w 0 w_0 w0
-
计算微分值(切线斜率)
- 结果为正值:减小w
- 结果为负值:增大w
- 减小与增大w的多少是由增长率决定的
-
重复以上过程
梯度下降会找到局部最小值,但不一定是全局最小

1.3 模型的改进
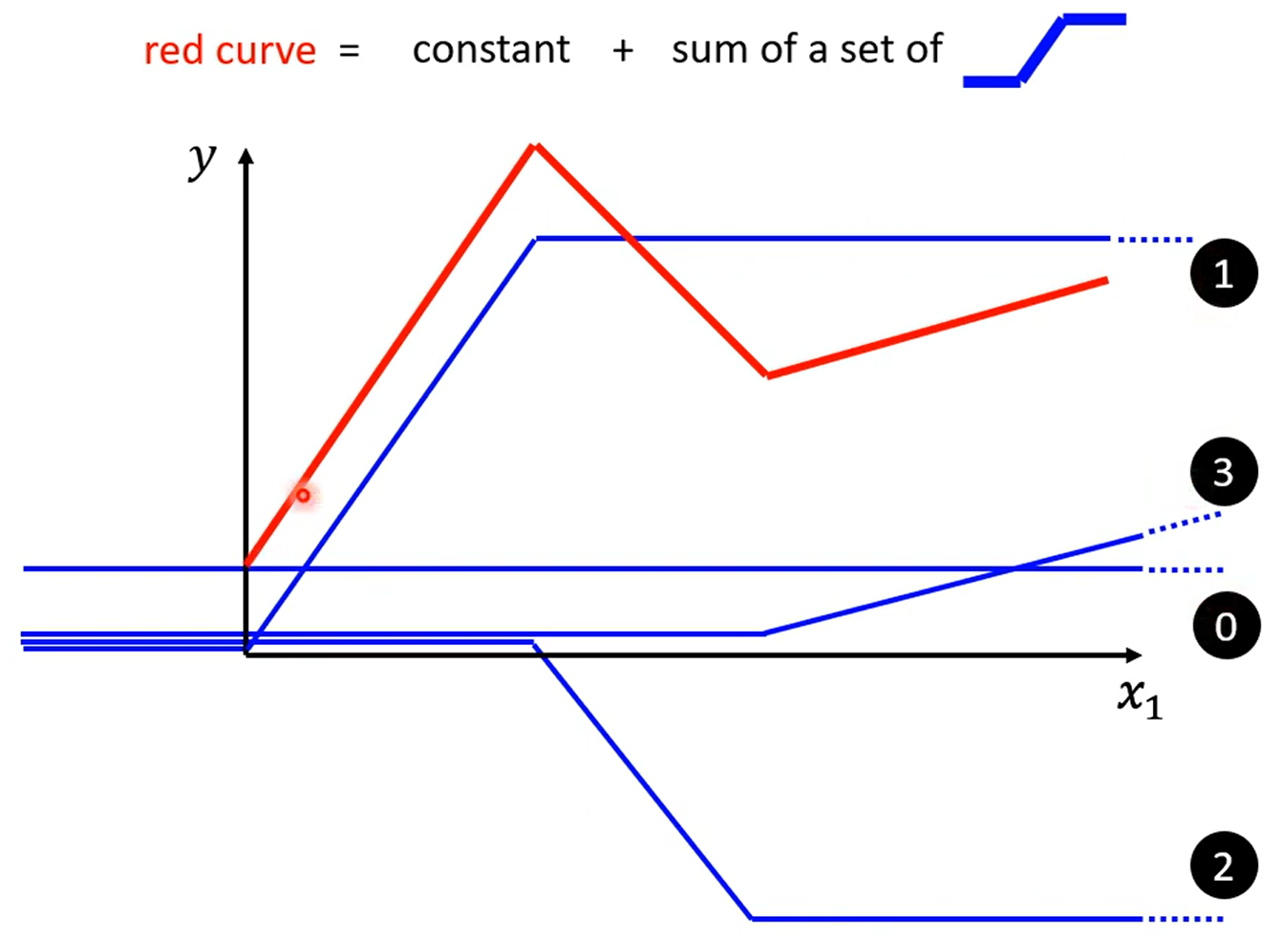
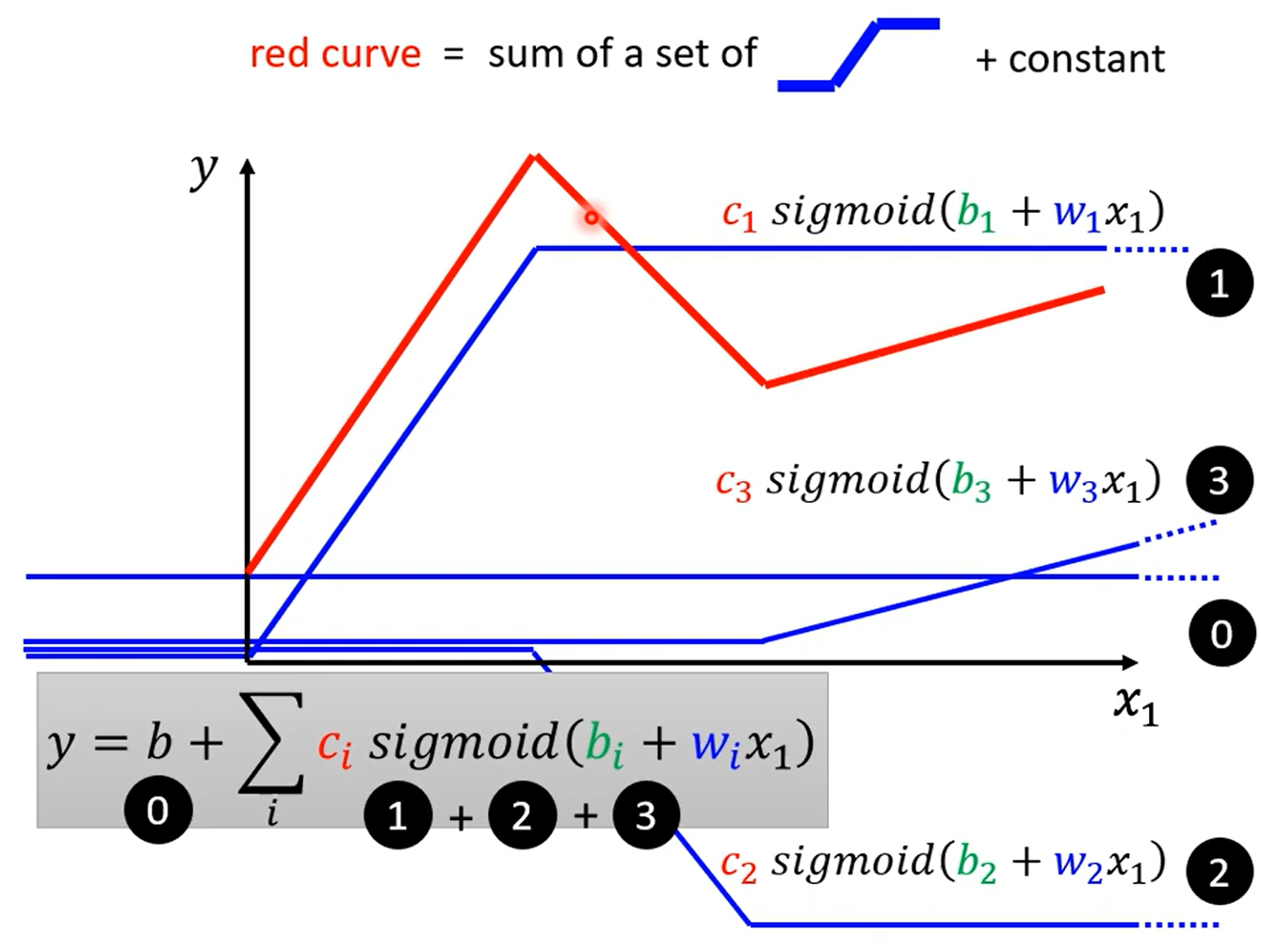
可以看出,红色的线段可以由常数项+蓝色线段组成的
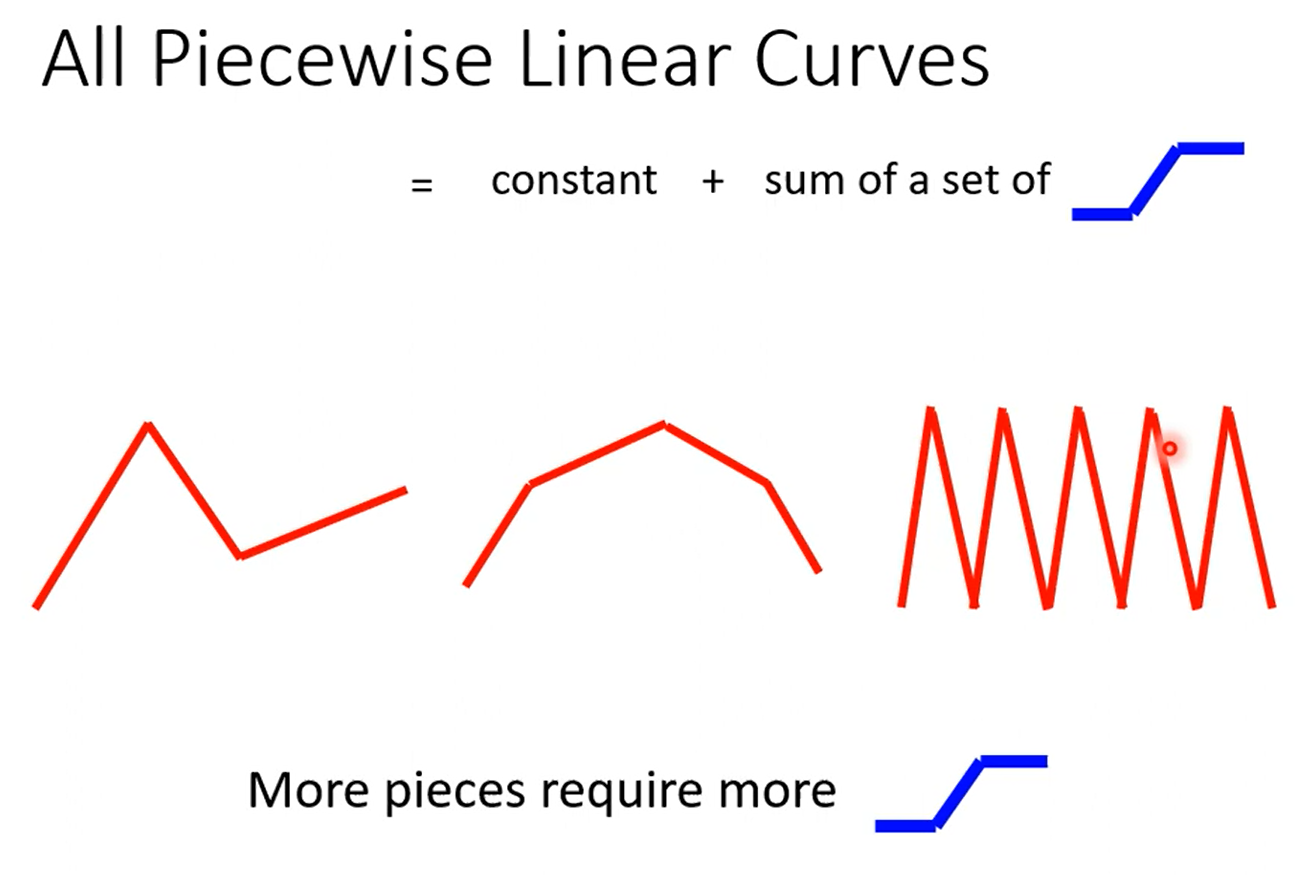
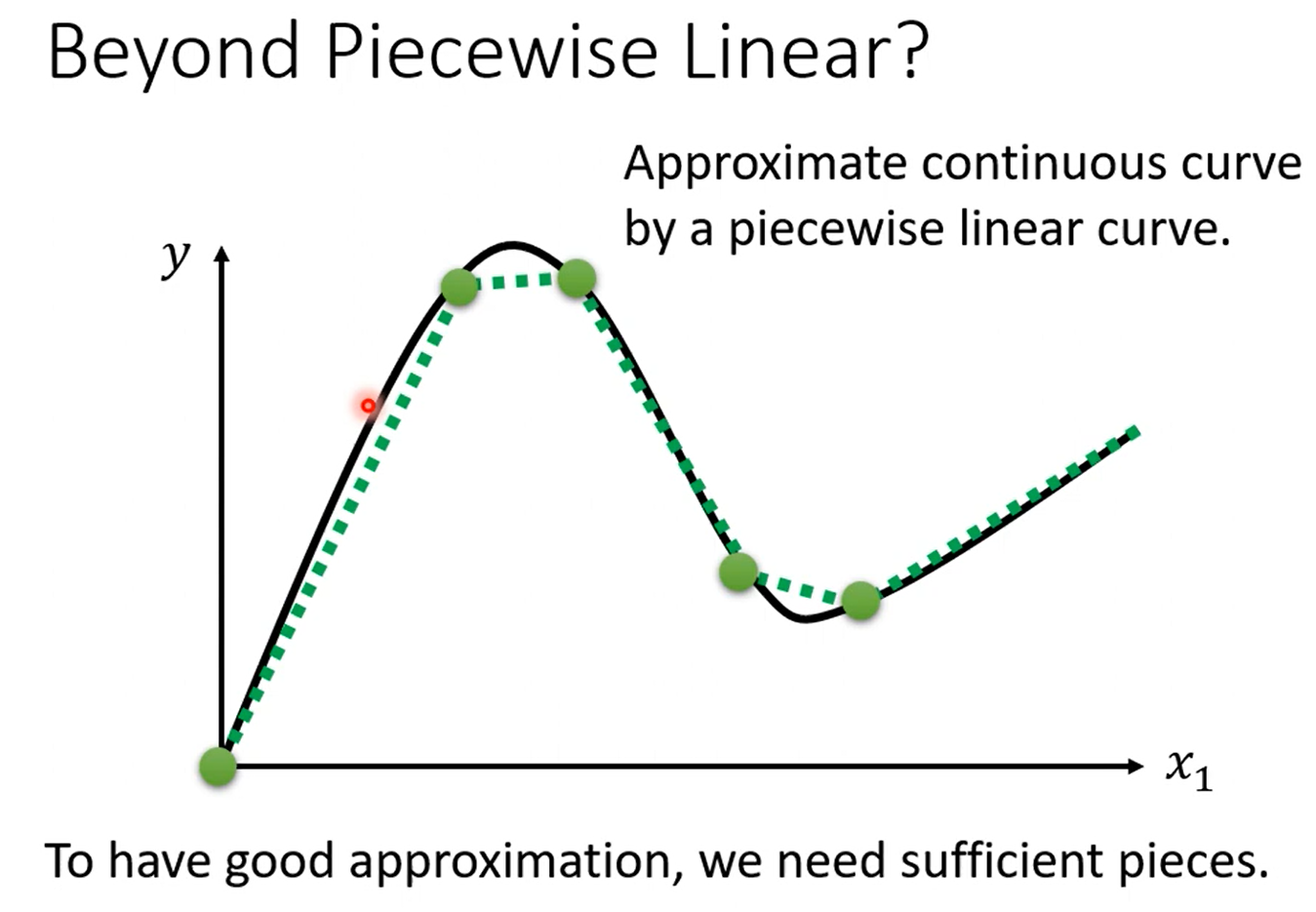
对于不同的曲线,可以在曲线上取不同的点,然后使得线段逼近曲线
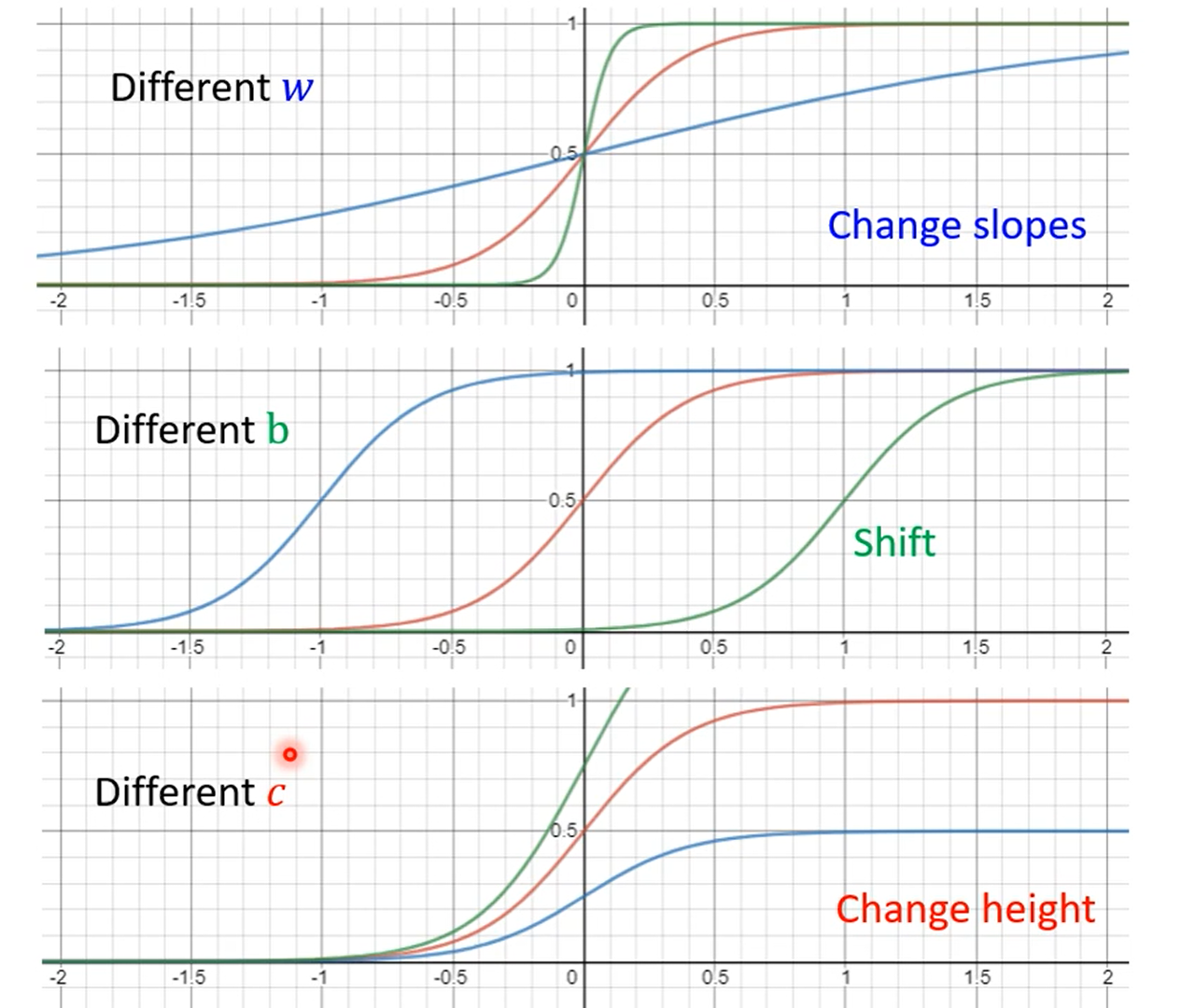
量化蓝色曲线:
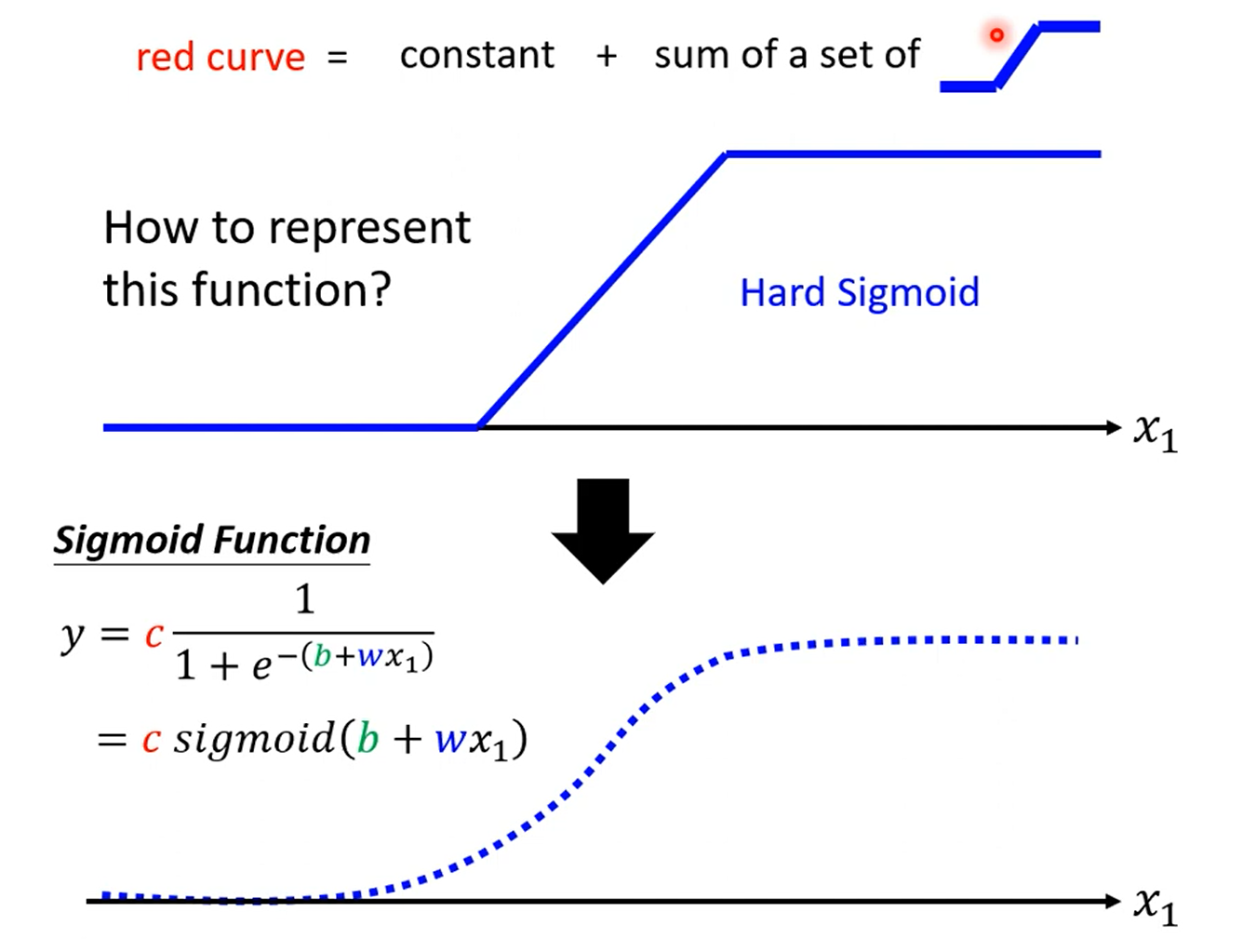
调整b、w、c可以获得不同的sigmoid函数
计算上述红色曲线的函数,此时是单个特征:
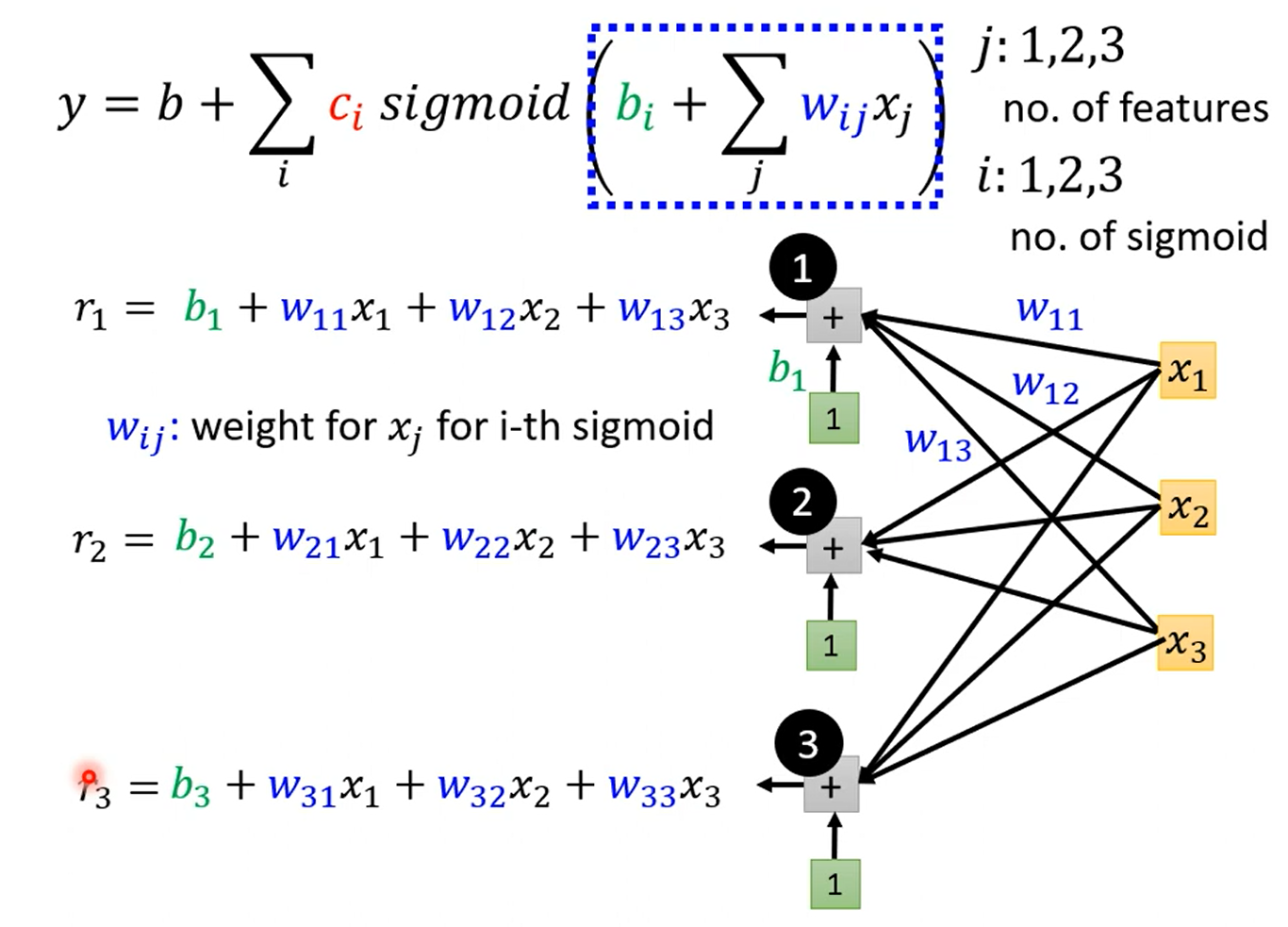
有更多的特征时,下图有3个特征 x 1 , x 2 , x 3 x_1,x_2,x_3 x1,x2,x3

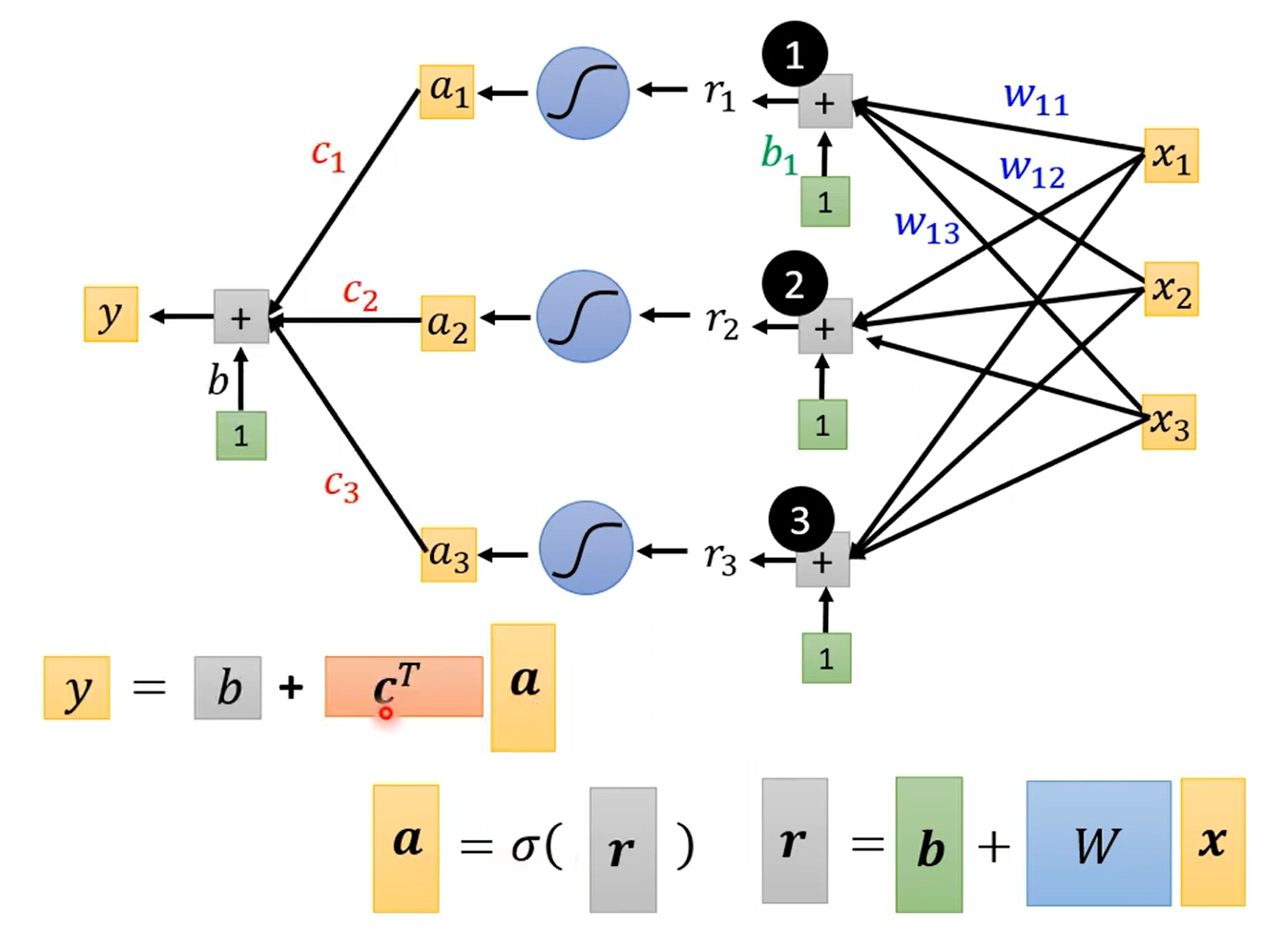
参数的定义:
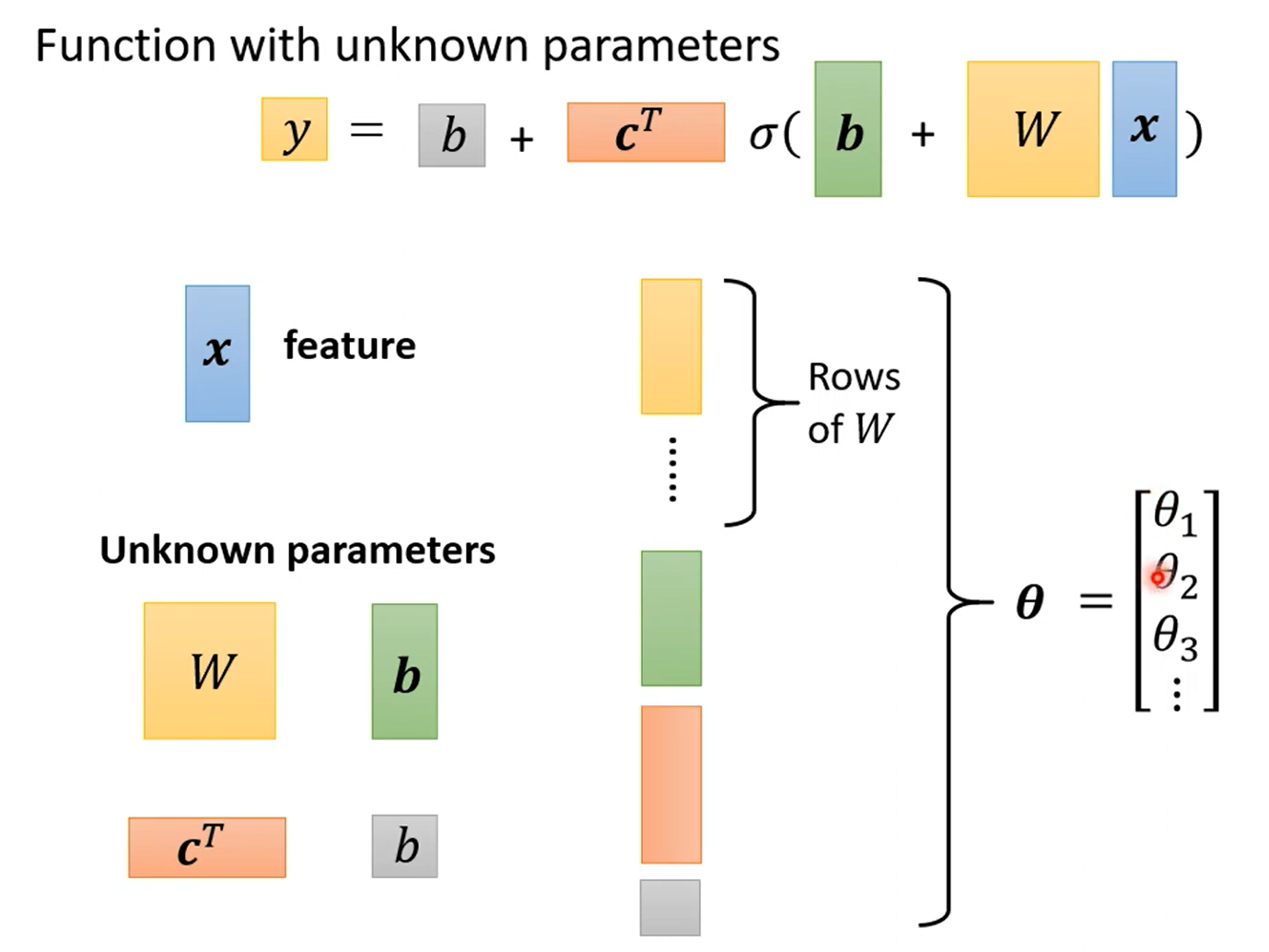
计算loss:
优化:
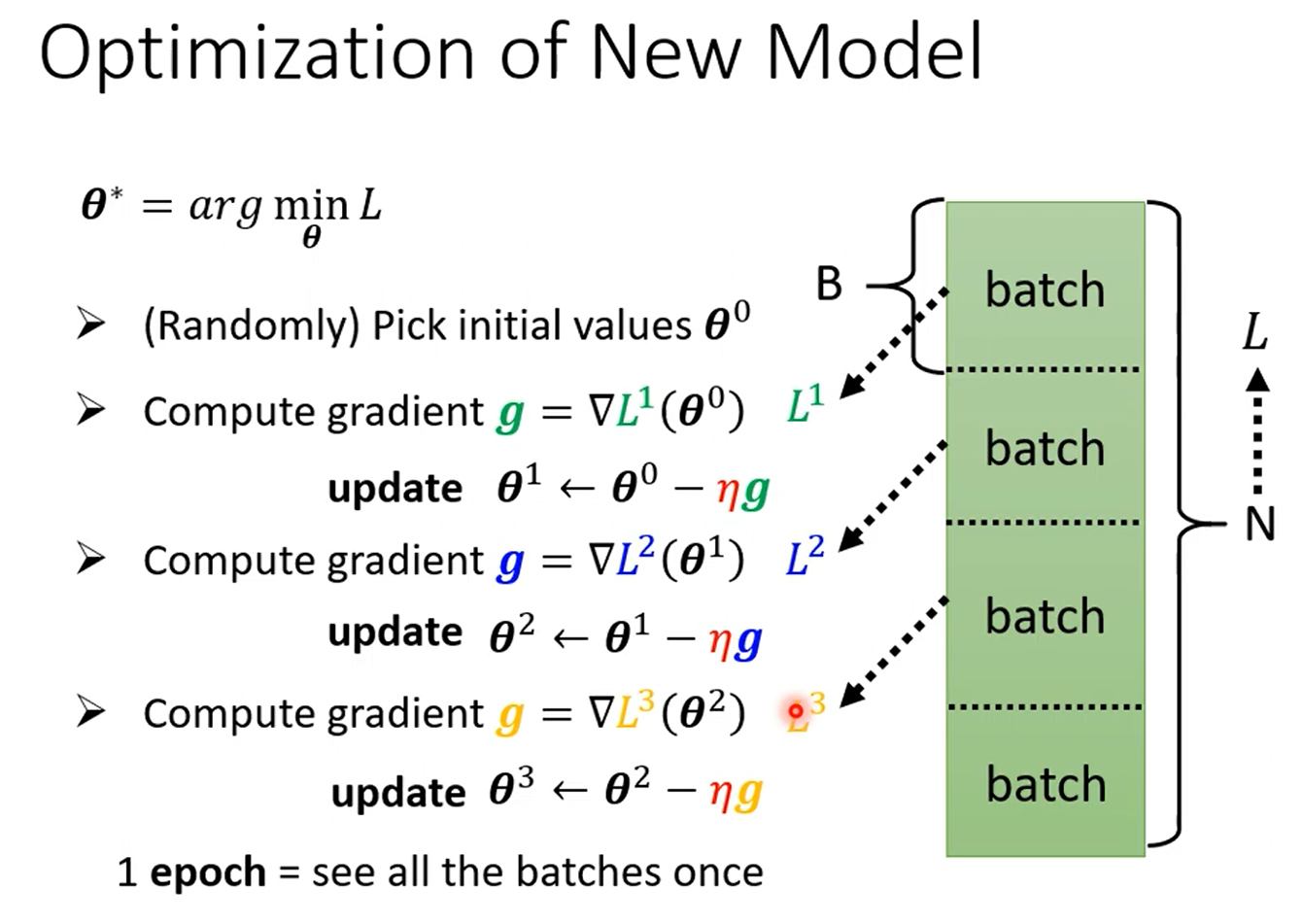
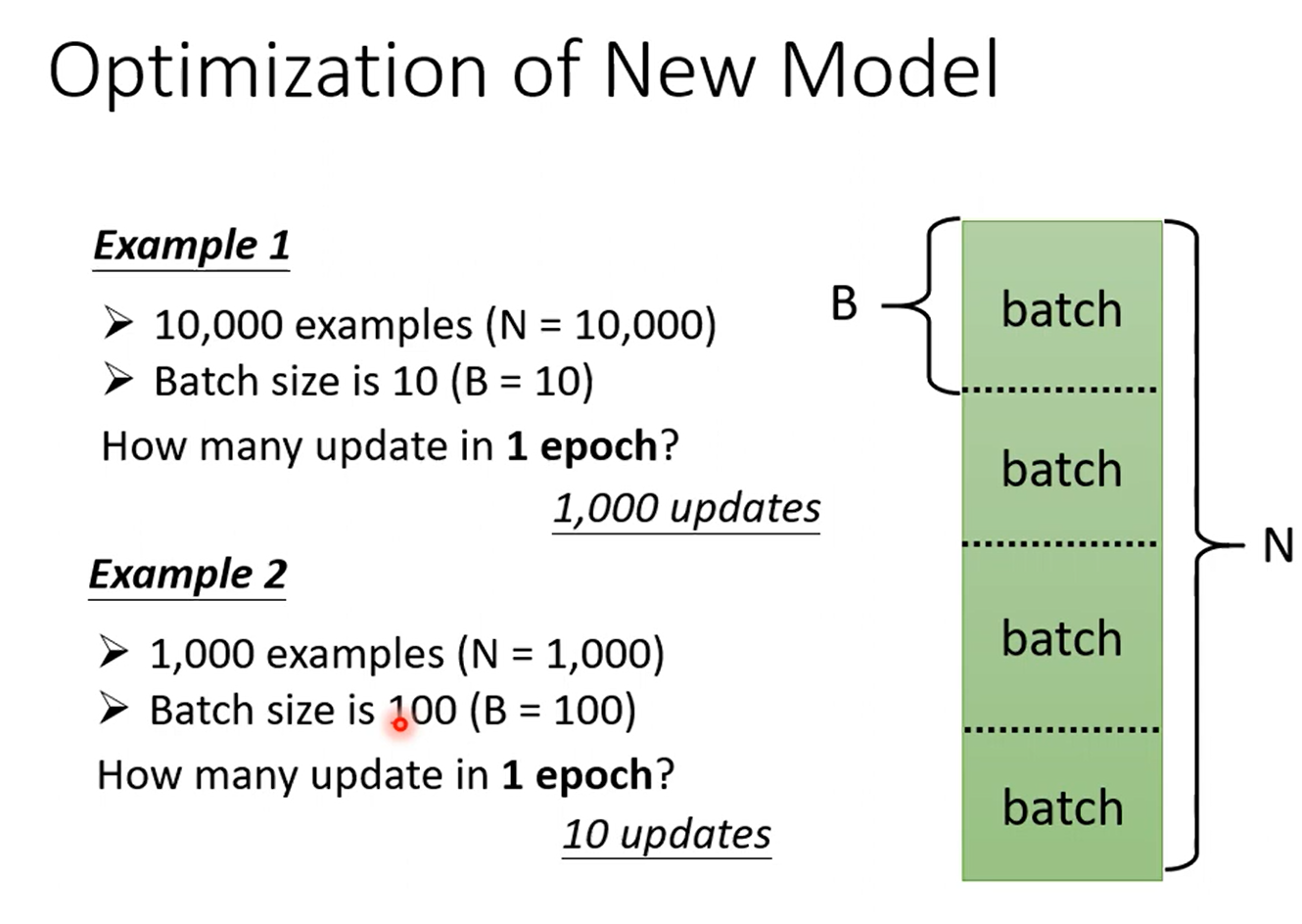
在实际操作中:
将样本随机分为几个batch,第一个batch计算L1,然后更新参数,再计算L2,继续更新参数
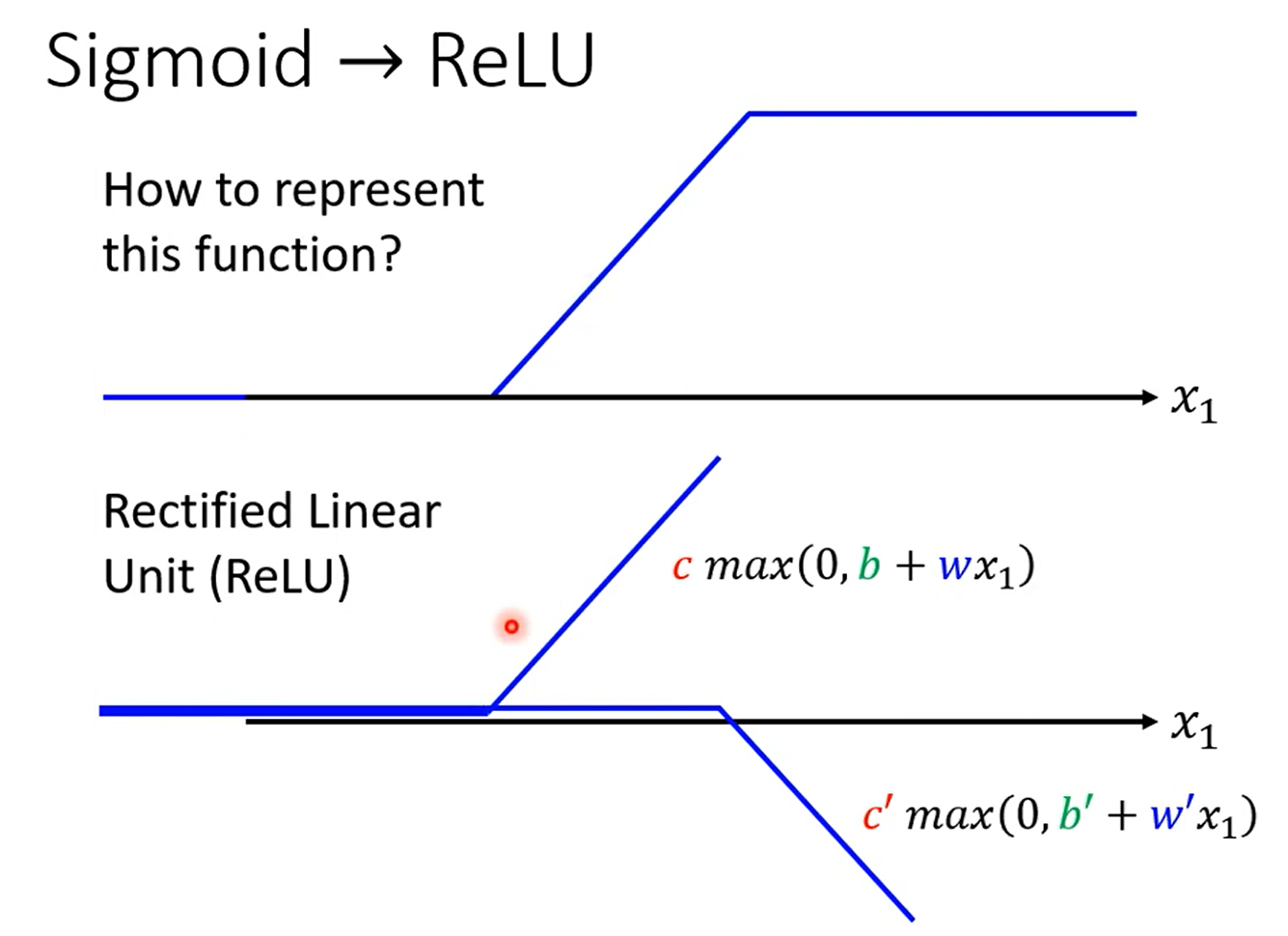
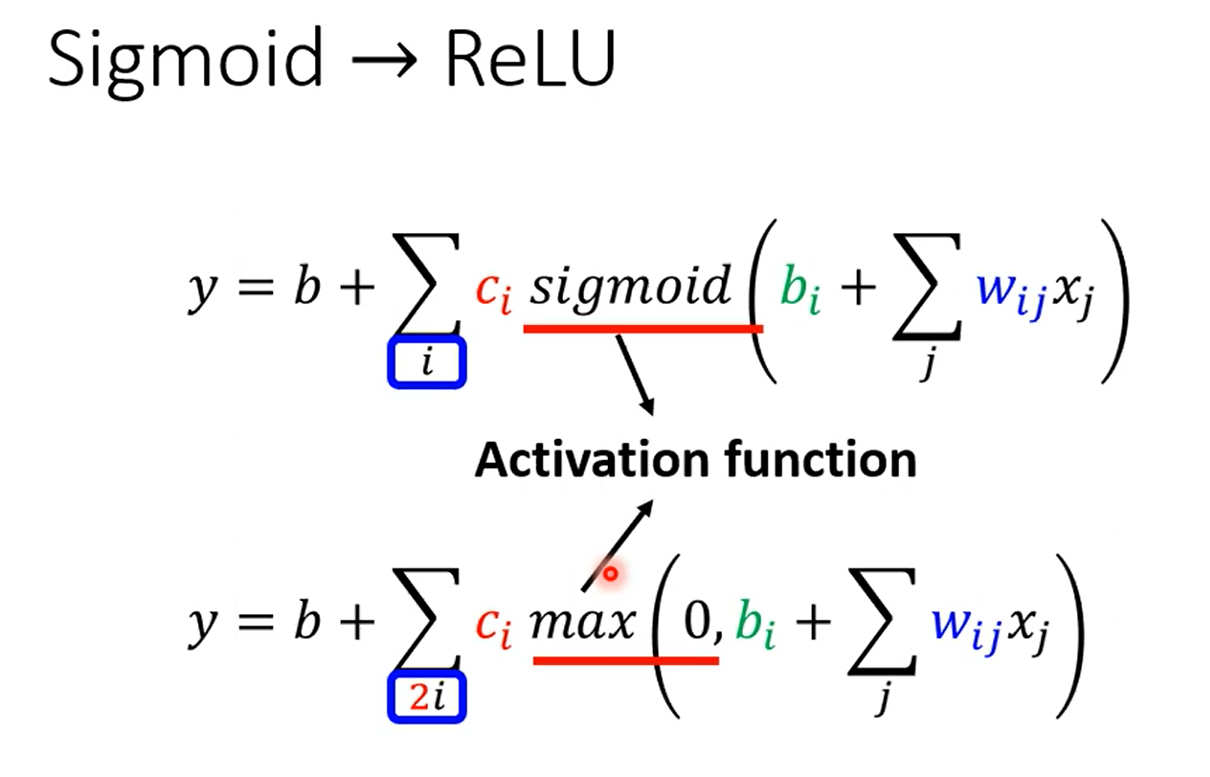
模型的选择:(激活函数)
2. 深度学习
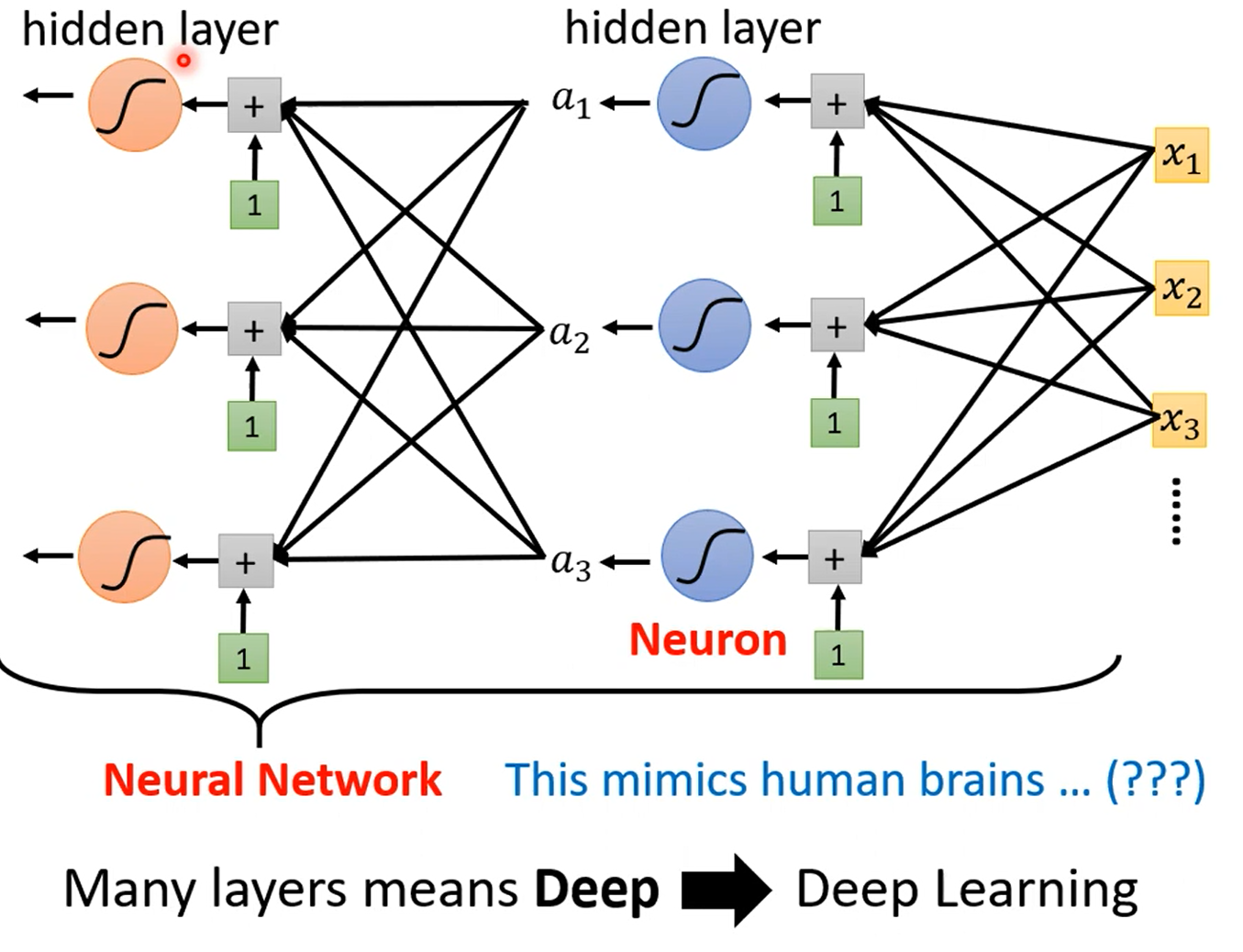
2.1 反向传播
链式法则:

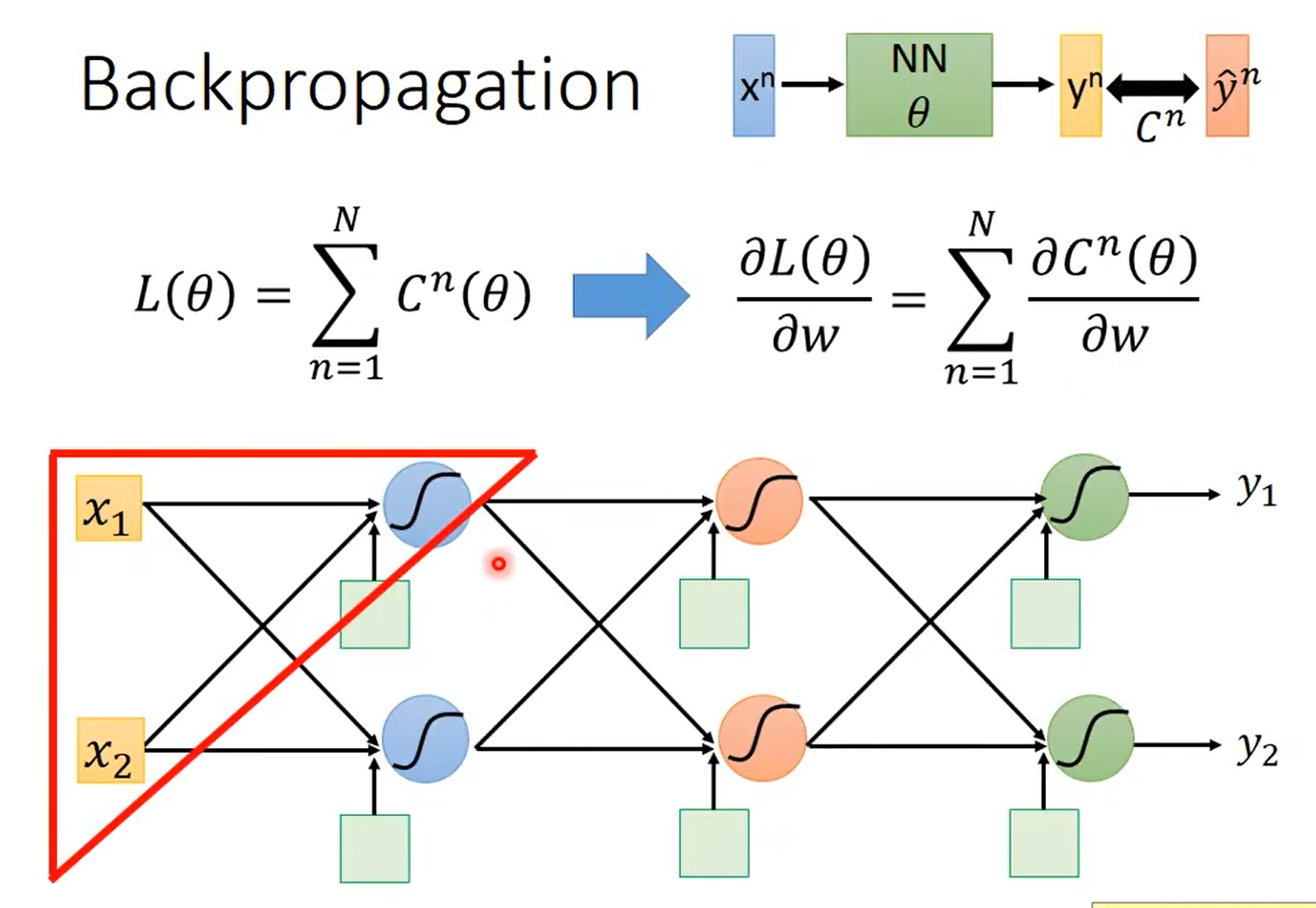
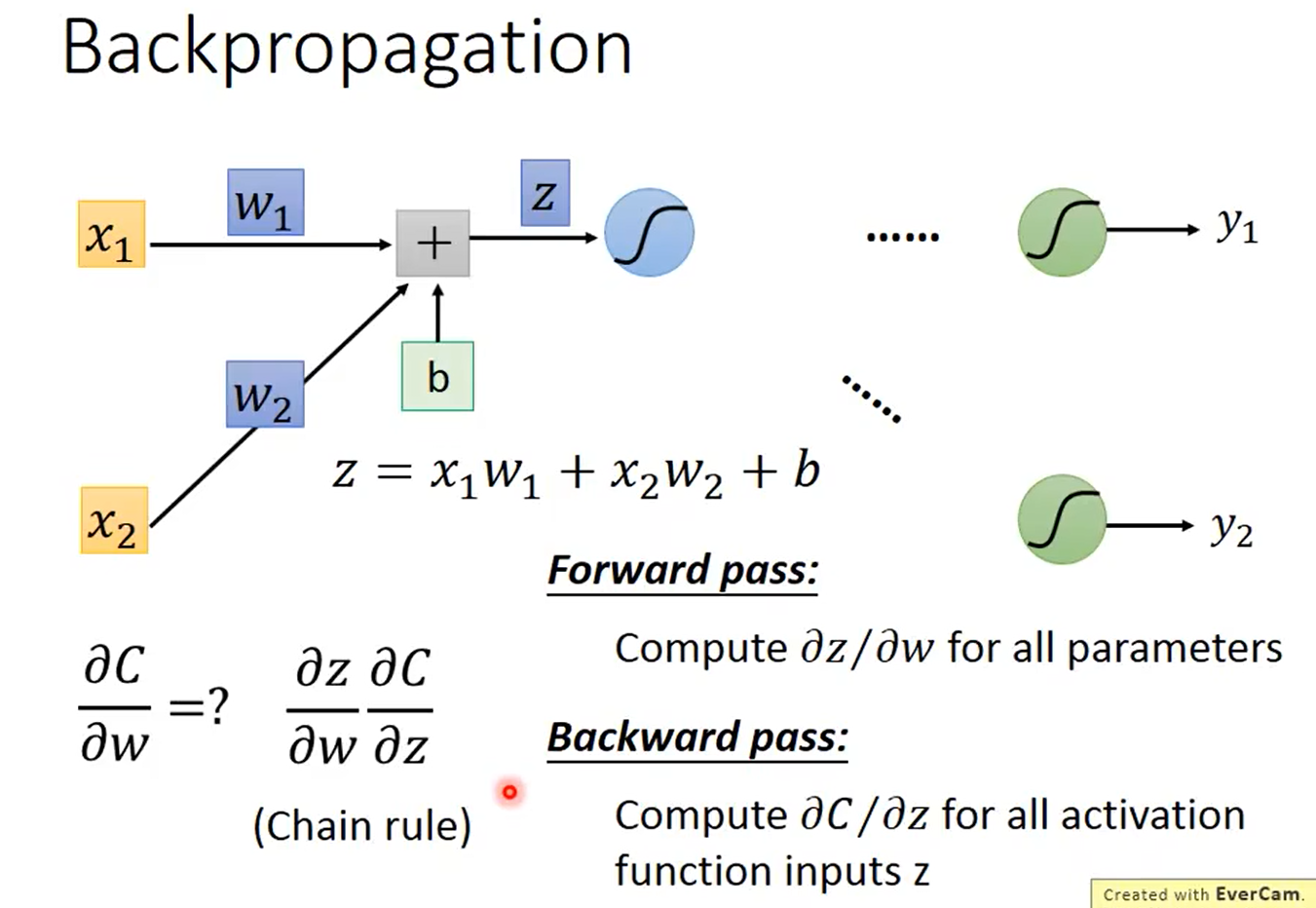
2.1.1前向传播
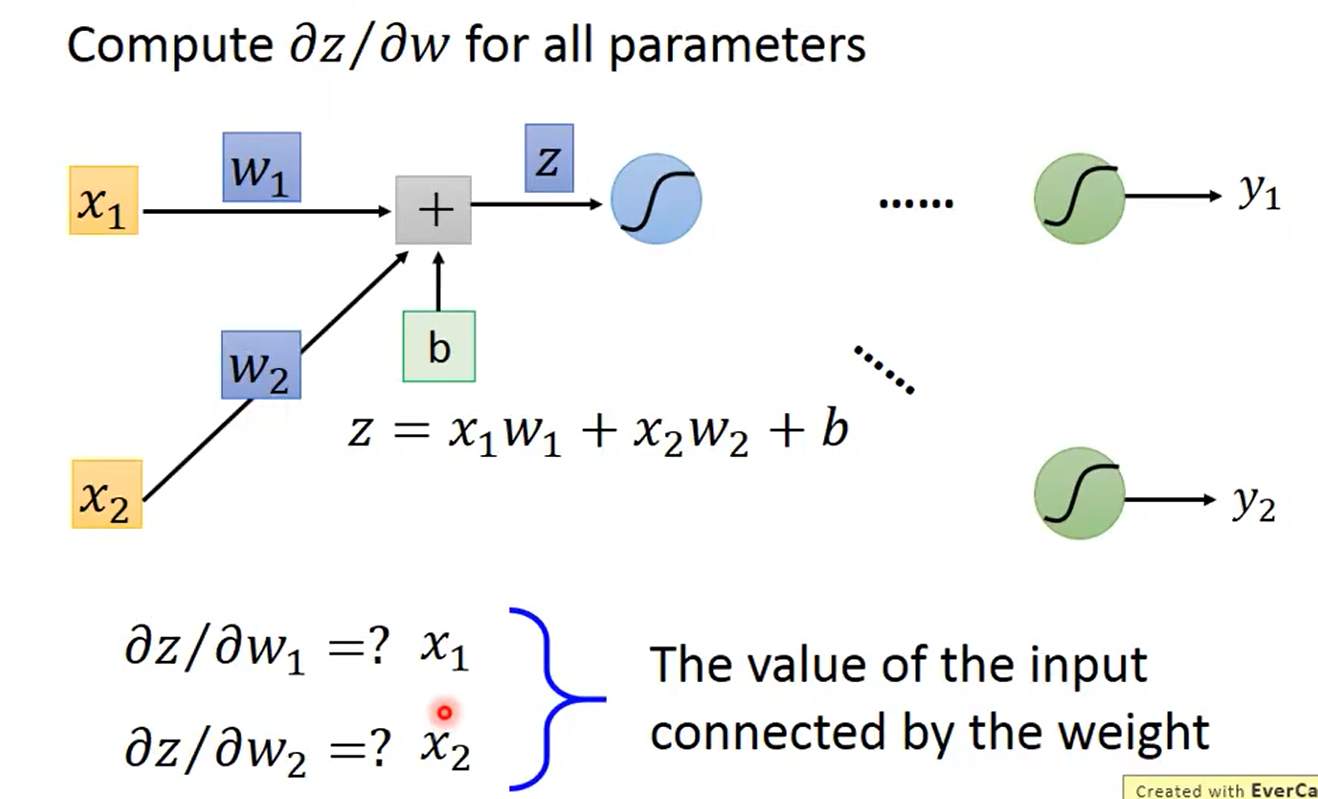
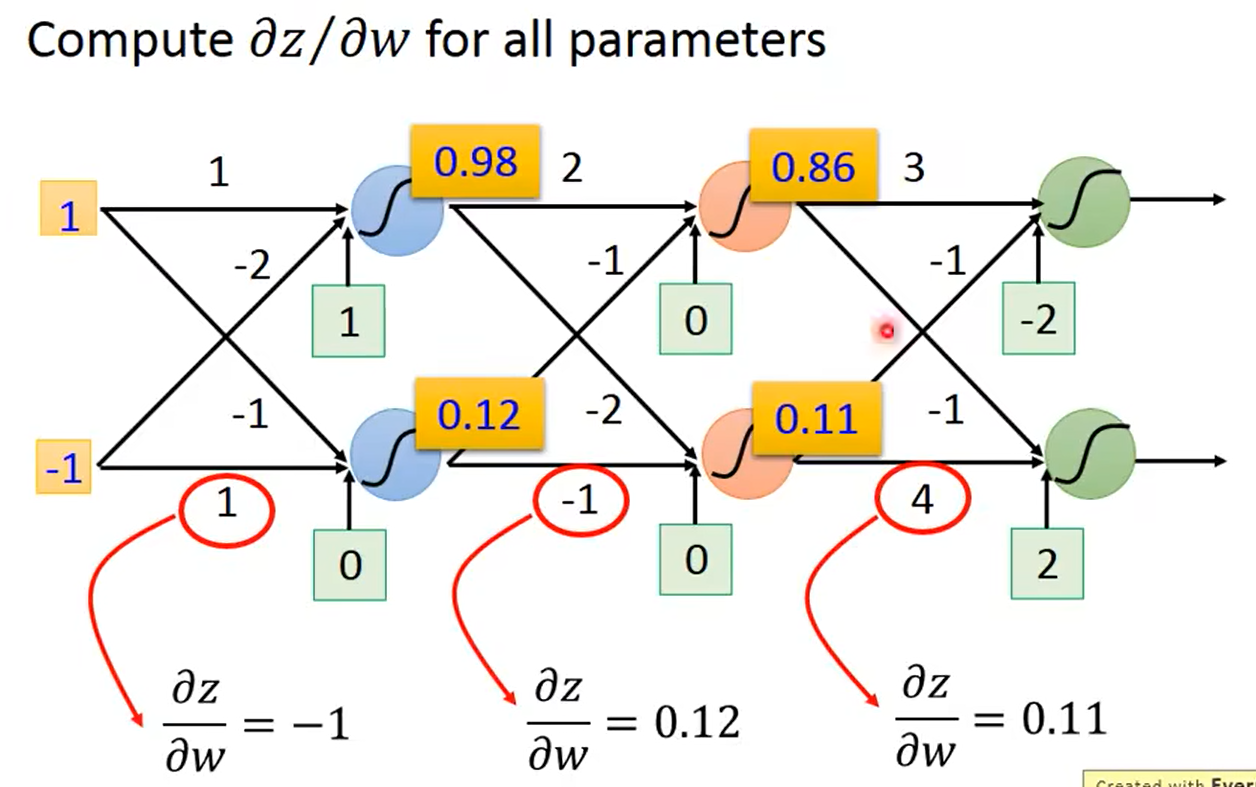
2.1.2 反向传播
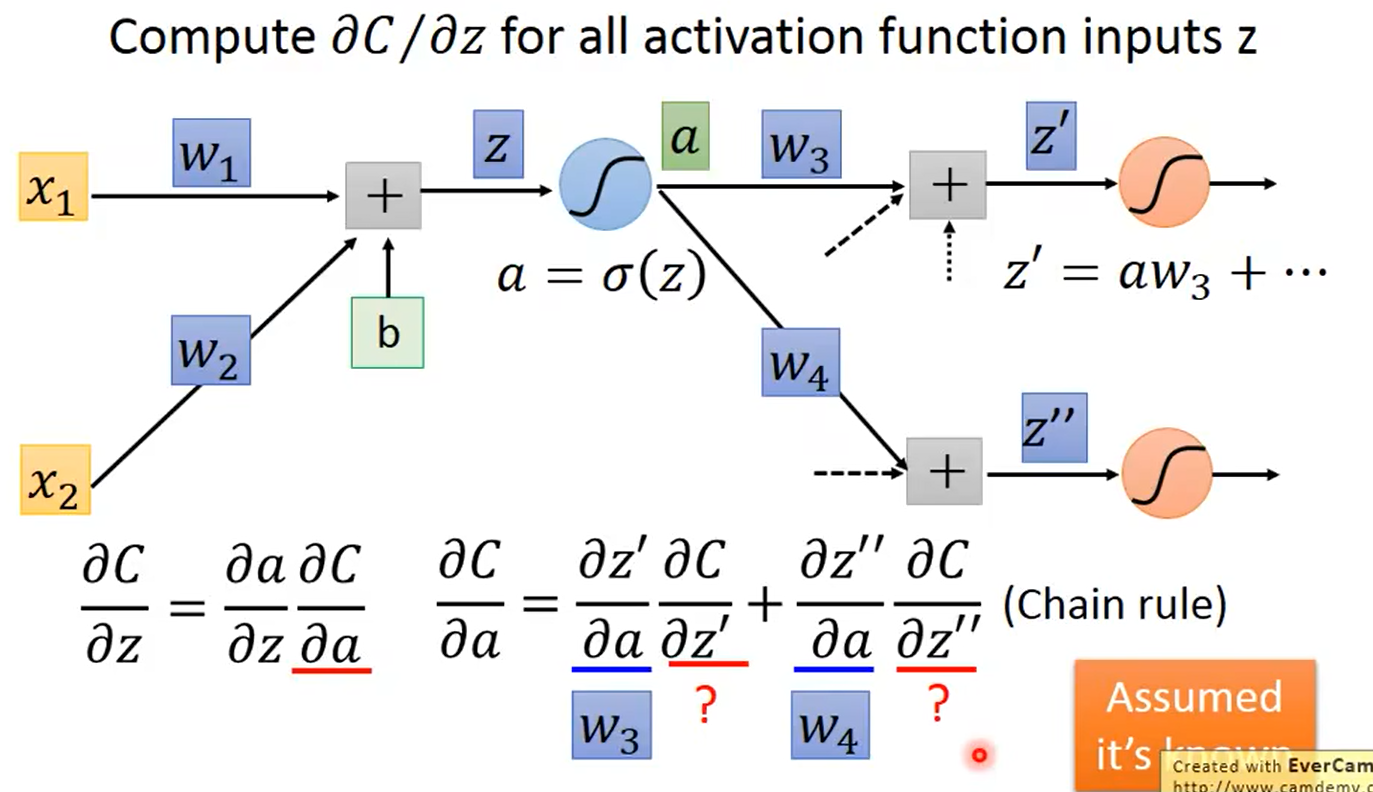
假设已知 ∂ C ∂ z ′ \frac{\partial C}{\partial z'} ∂z′∂C和 ∂ C ∂ z ′ ′ \frac{\partial C}{\partial z''} ∂z′′∂C,将其作为输入可得:
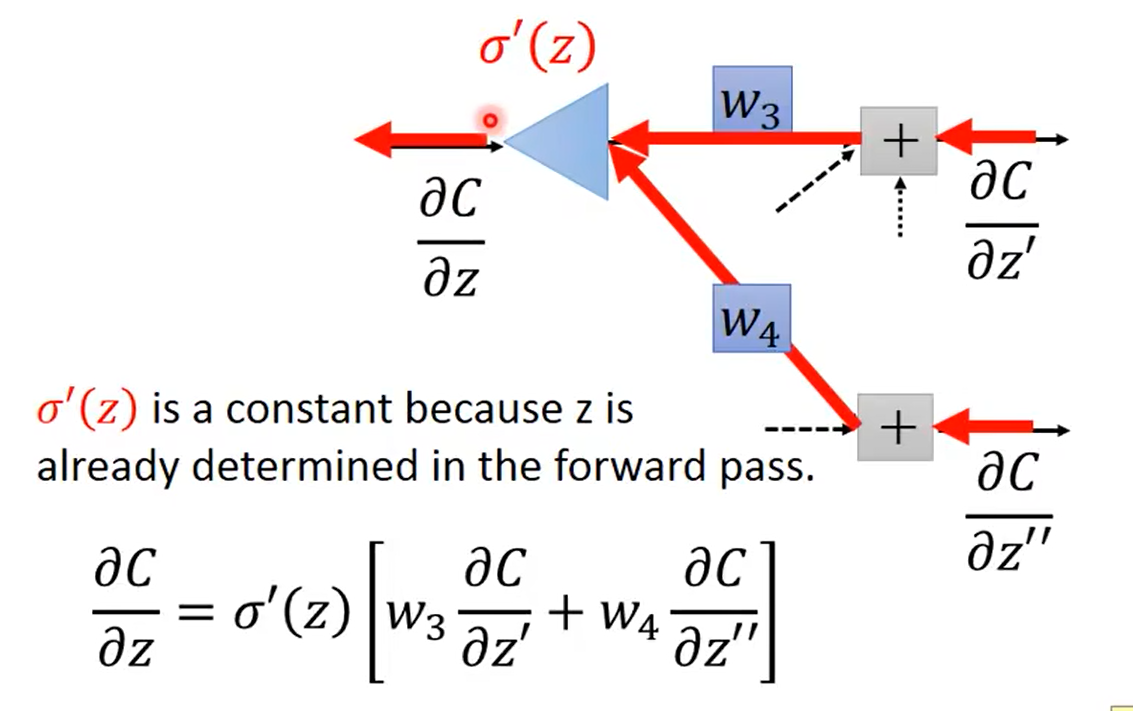
计算 ∂ C ∂ z ′ \frac{\partial C}{\partial z'} ∂z′∂C和 ∂ C ∂ z ′ ′ \frac{\partial C}{\partial z''} ∂z′′∂C:
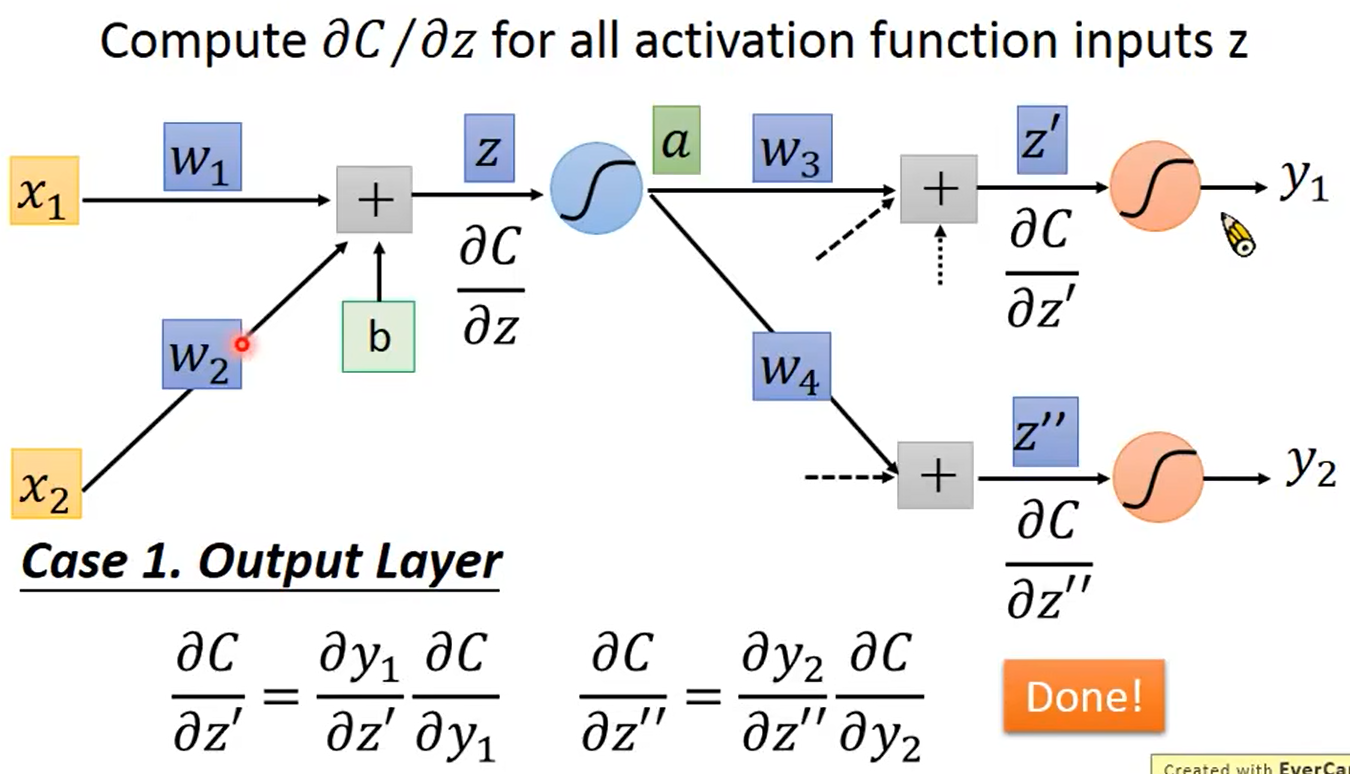
1.有输出层的情况
2.没有到输出层
继续往下走,直到找到输出层
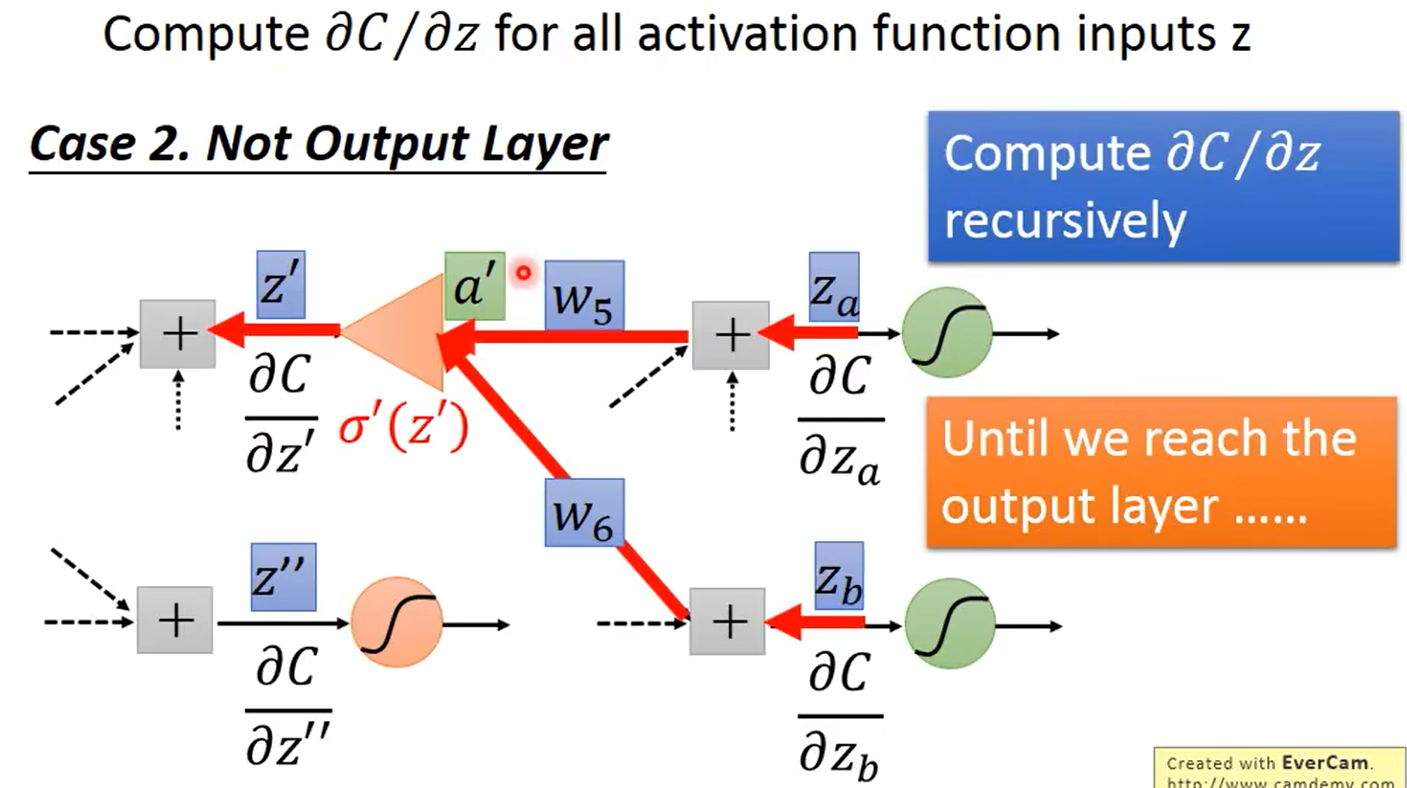
换个方向计算,即从输出层 y 1 , y 2 y_1,y_2 y1,y2算到输入层
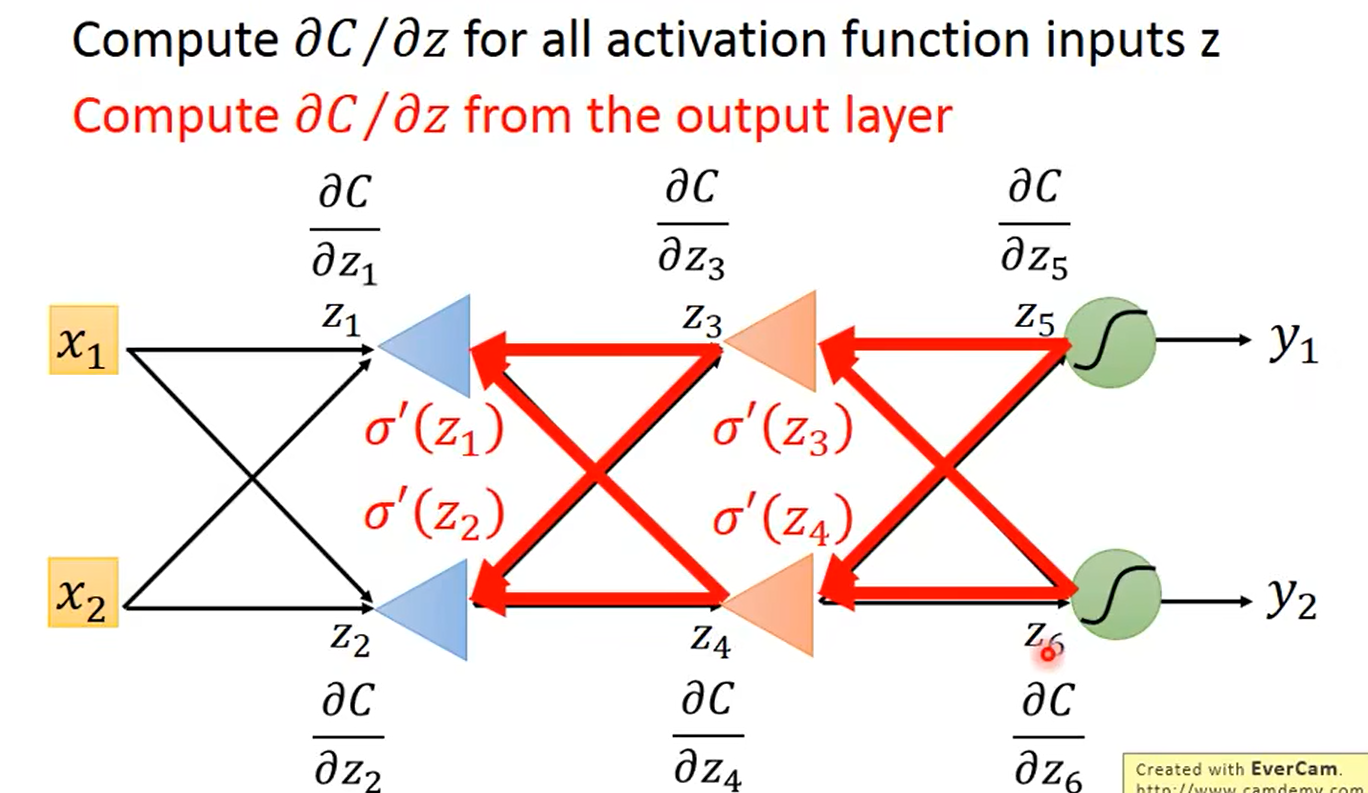
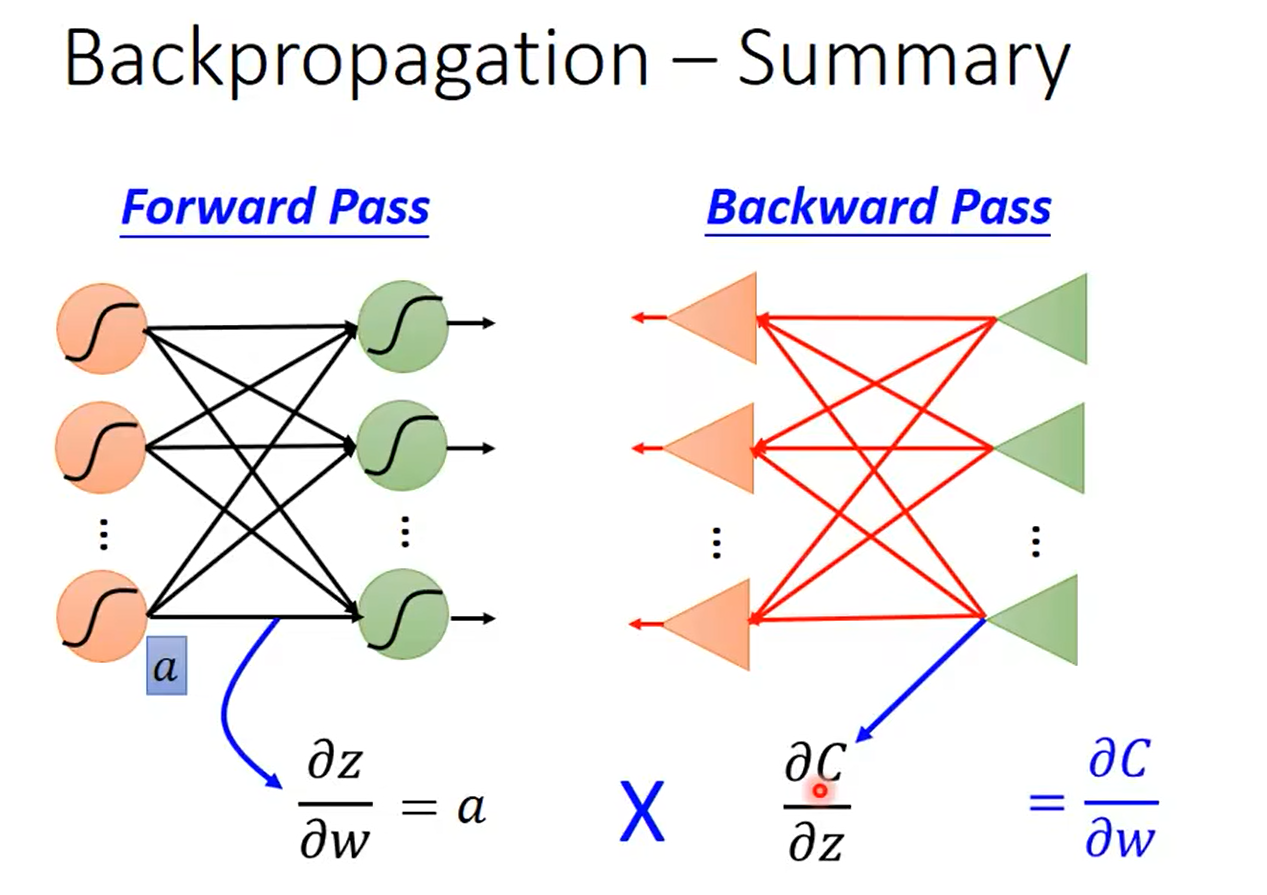
总结:
前向传播vs反向传播
3. 回归
回归的应用:

3.1 线性回归
1.定义线性模型

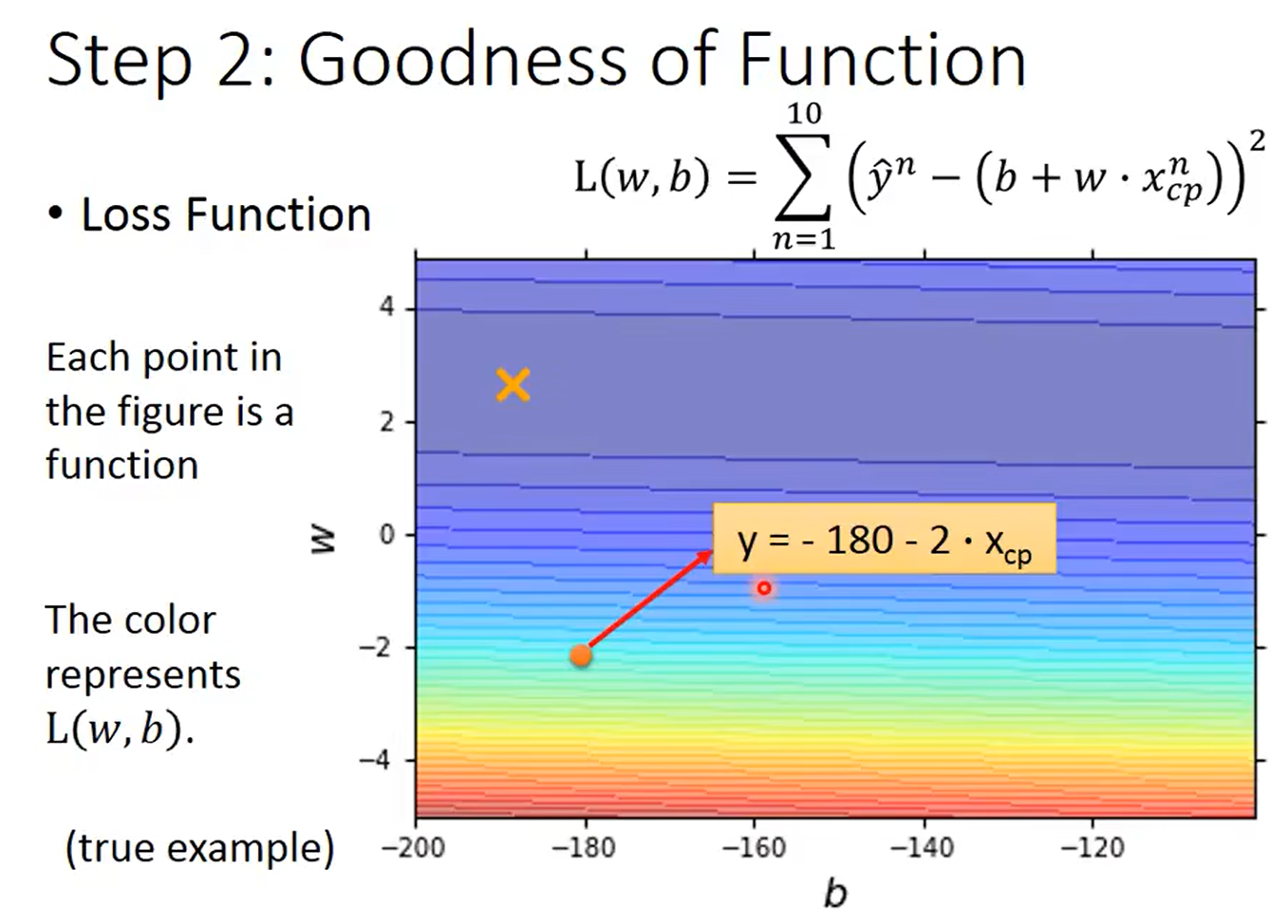
2.评价模型的好坏
定义损失函数(真正的数值 - 预测的值)用两者之间的差来衡量函数的好坏

3.优化函数
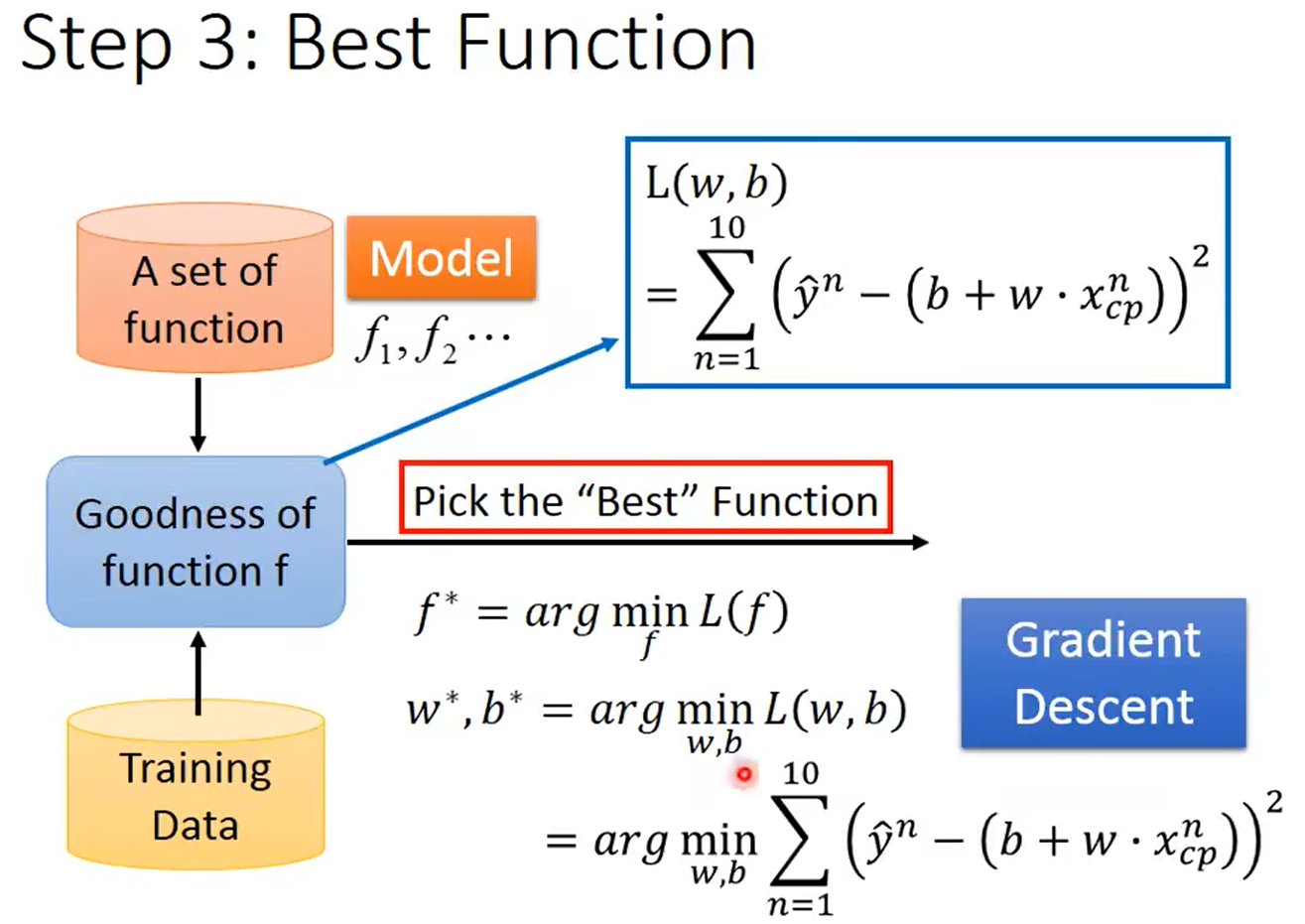
利用梯度下降计算:(具体流程和上面所写的相同)

对于线性回归,它的损失函数是凸函数,即没有局部最优
模型的结果:
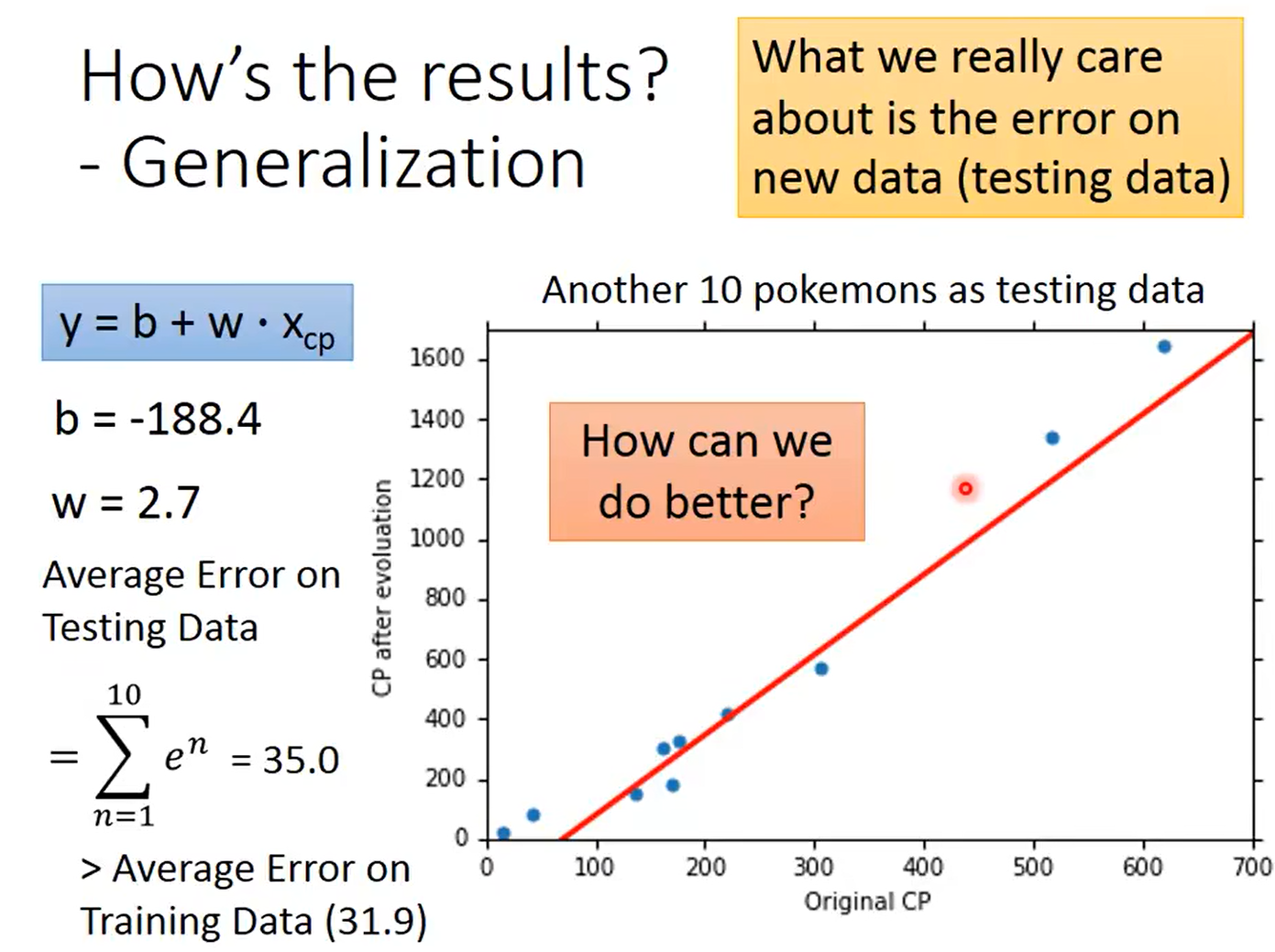
选择更复杂的模型:

在训练数据上,选择更复杂的模型会有更小的误差

但是在测试数据上不会一直有更好的表现,这就是过拟合,需要选择一个最适合的模型
3.2 优化模型
考虑有隐藏的因素:


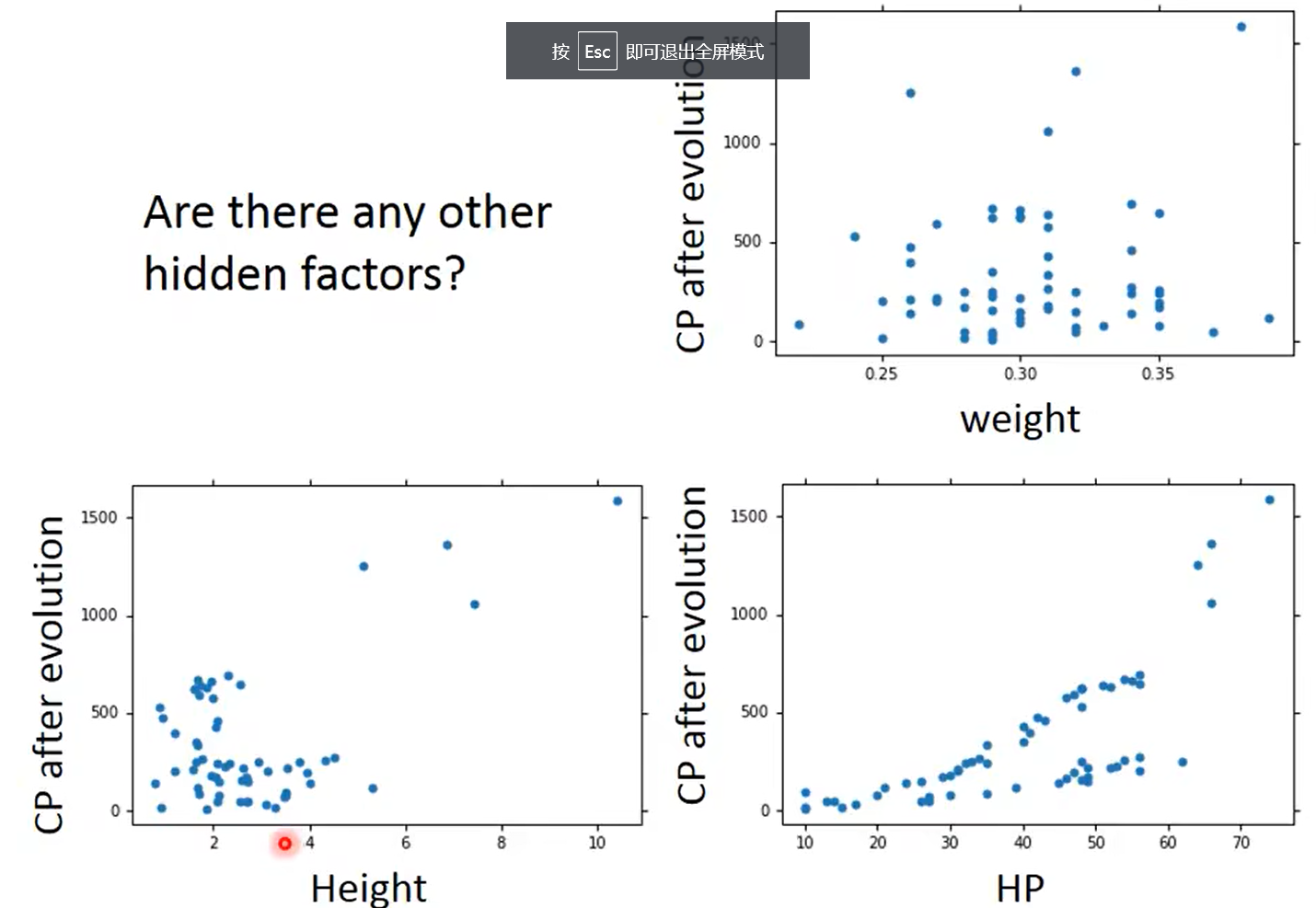
但是注意,如果把所有考虑的特征都加进去,可能会造成过拟合,可以进一步使用正则化
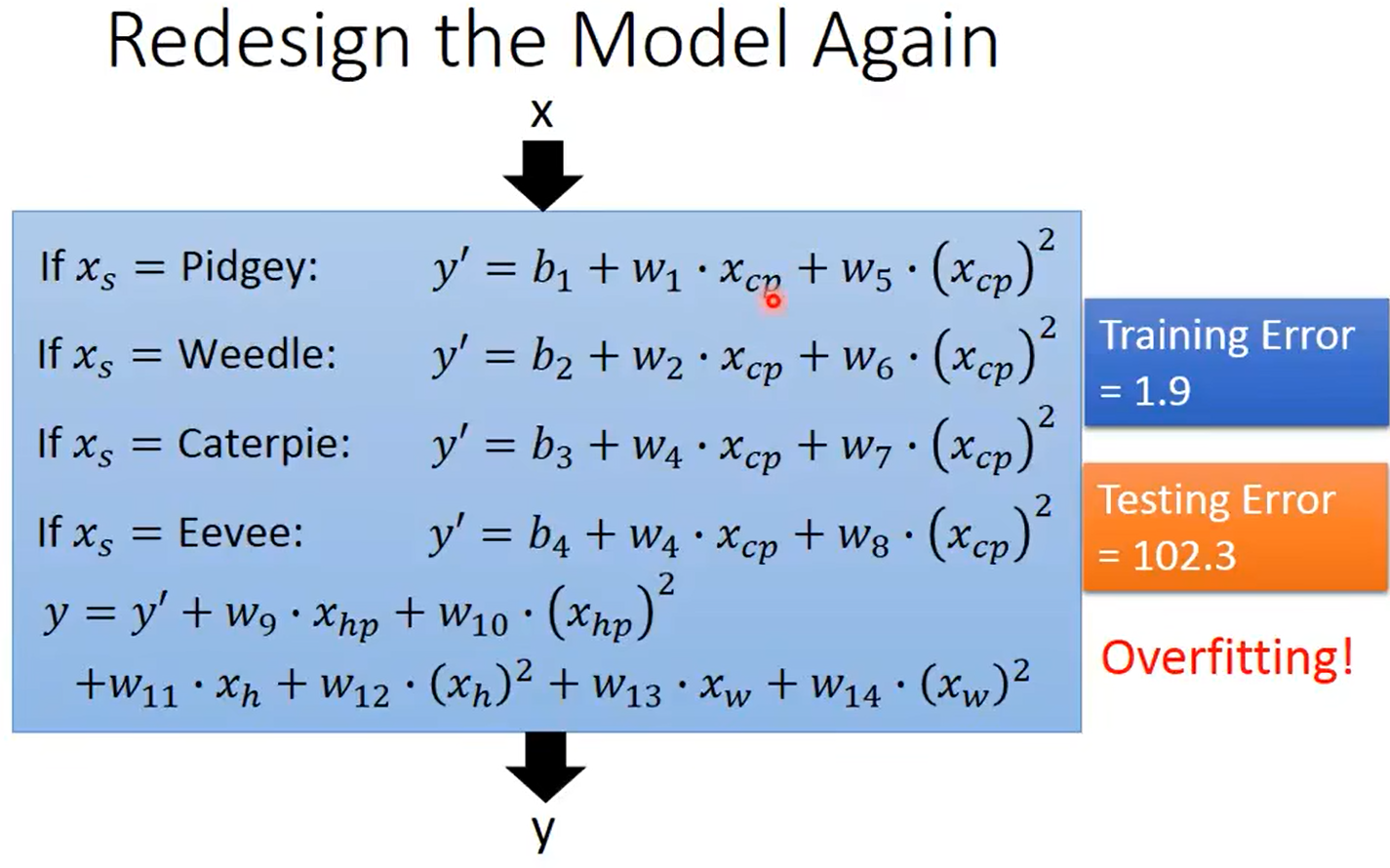
正则化优化:使得模型更加平滑

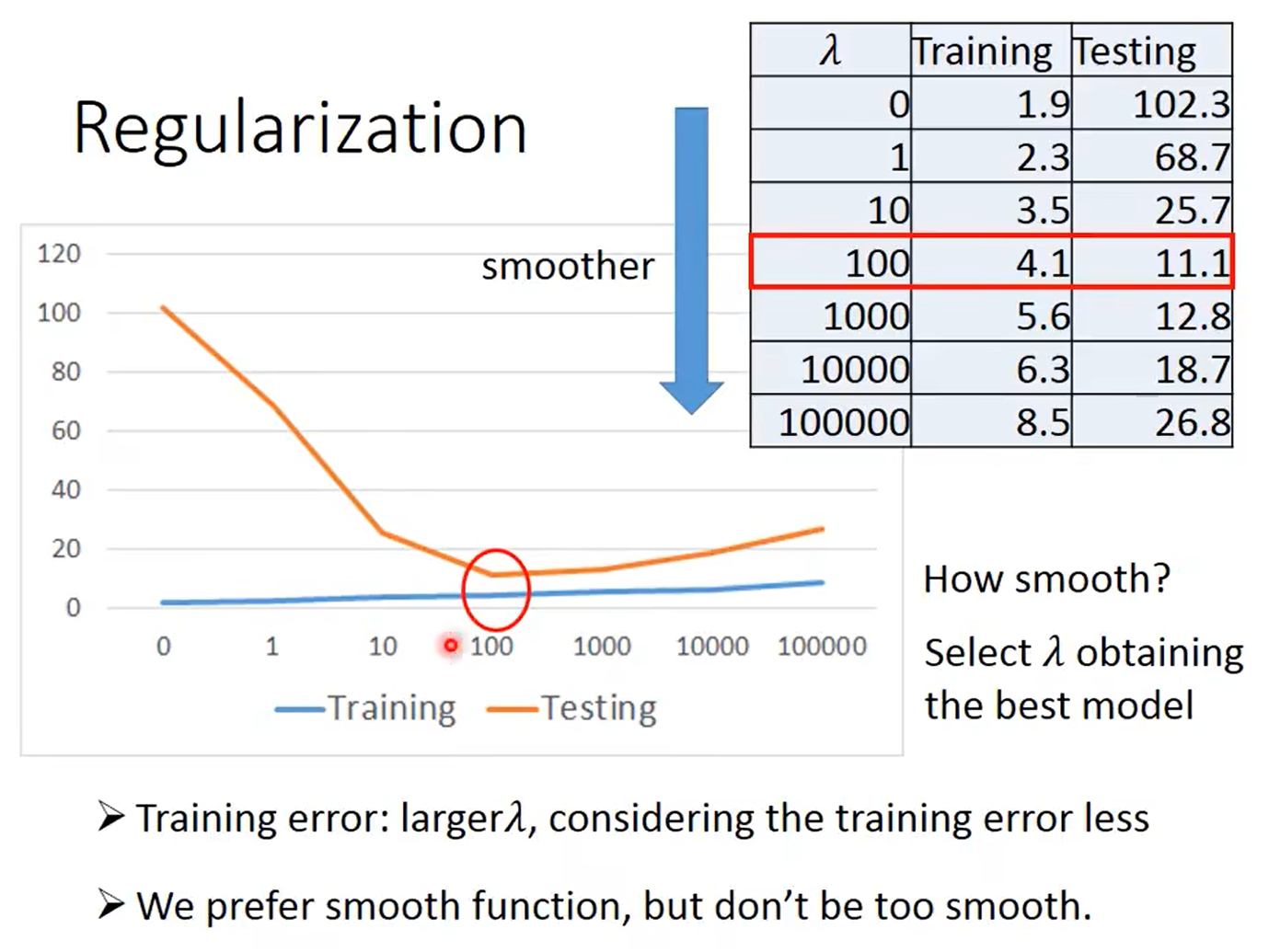
λ \lambda λ越大,模型就越平滑,考虑训练数据的误差就越少,与之对应,训练数据的误差就会变大,但测试数据上的误差反而会减小,因此需要选择合适的 λ \lambda λ
4. 分类
分类的应用:

具体分类做法

把分类当作回归来看:
- 训练时可以把一个样本定义为1,第2个样本定义为-1
- 测试时:越接近于1,则为1;越接近于-1,则为样本2
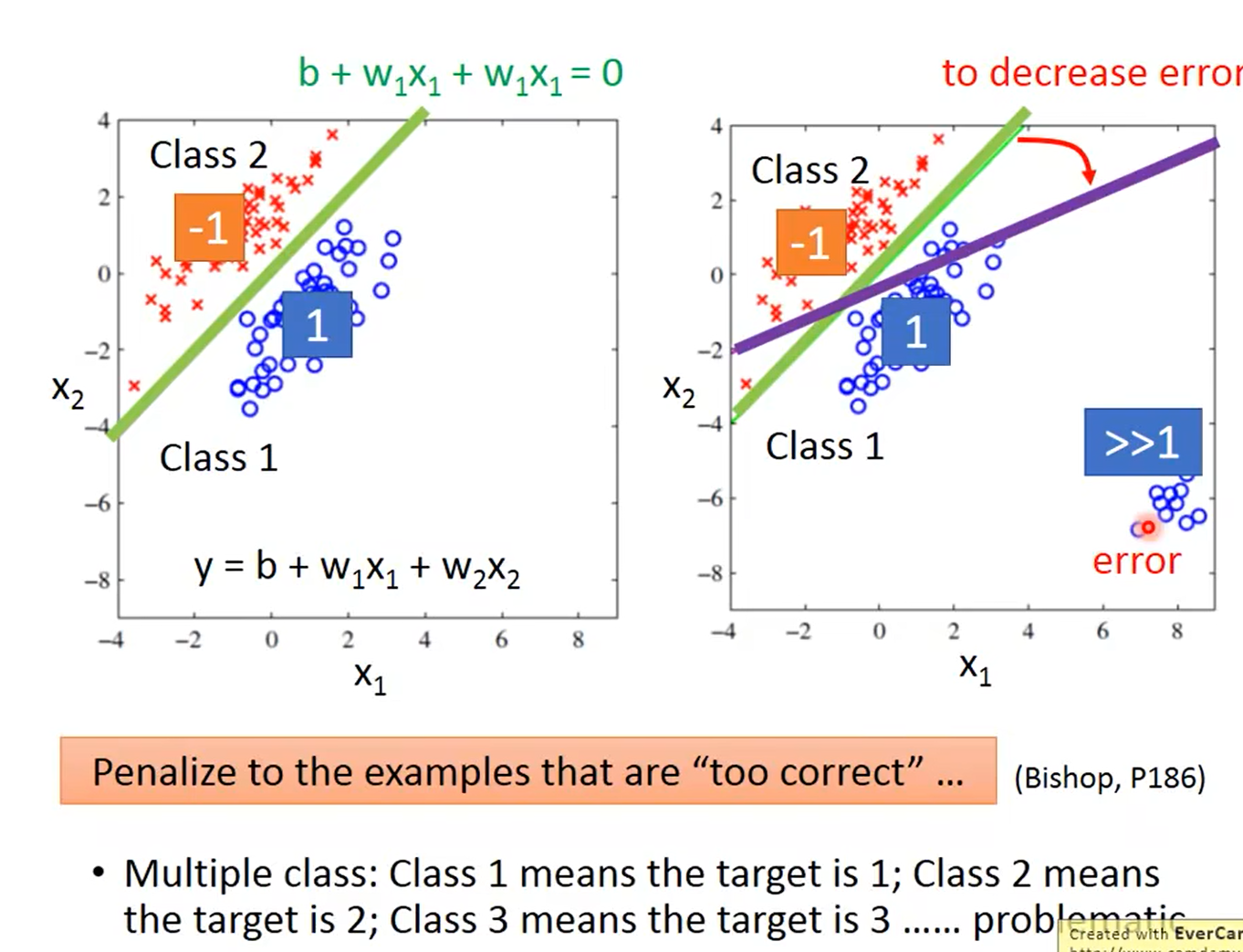
利用上述算法进行处理会出现问题,会惩罚那些太正确的样本,如右图,利用回归算法,为了减少误差会得到紫色的那条线,但是实际分类确实绿色的线,运用该算法会出现一些问题
4.1 分类算法
算法的流程:

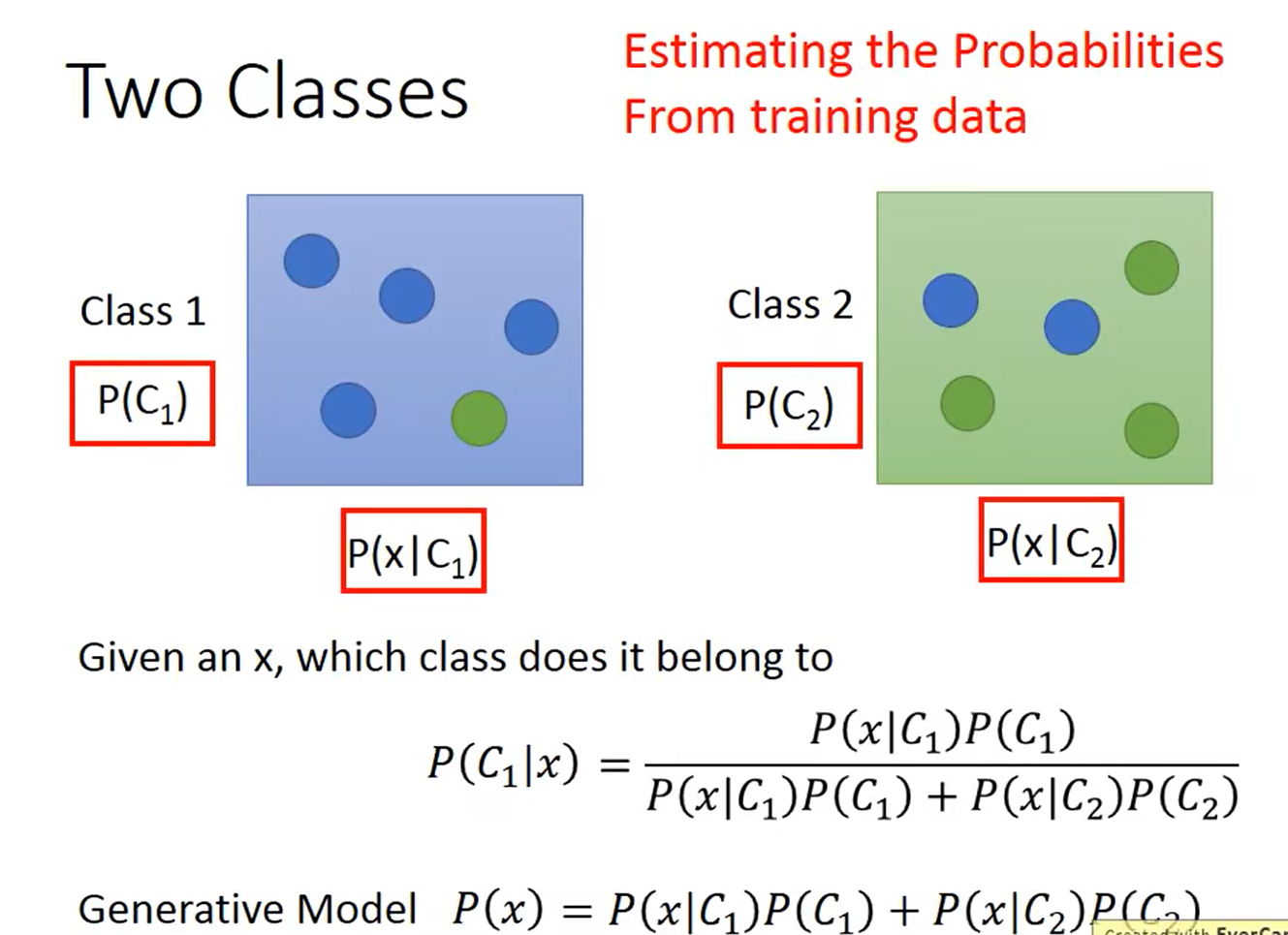
4.2 生成模型
假设有两个类别 C 1 , C 2 C_1,C_2 C1,C2, P ( C 1 ∣ x ) = P ( x ∣ C 1 ) P ( C 1 ) P ( x ∣ C 1 ) P ( C 1 ) + P ( x ∣ C 2 ) P ( C 2 ) P(C_1|x) = \frac{P(x|C_1)P(C_1)}{P(x|C_1)P(C_1) + P(x|C_2)P(C_2)} P(C1∣x)=P(x∣C1)P(C1)+P(x∣C2)P(C2)P(x∣C1)P(C1),其中 P ( C 1 ) 、 P ( C 2 ) P(C_1)、P(C_2) P(C1)、P(C2)为先验分布, P ( x ∣ C 1 ) 、 P ( x ∣ C 2 ) P(x|C_1)、P(x|C_2) P(x∣C1)、P(x∣C2)都是高斯分布
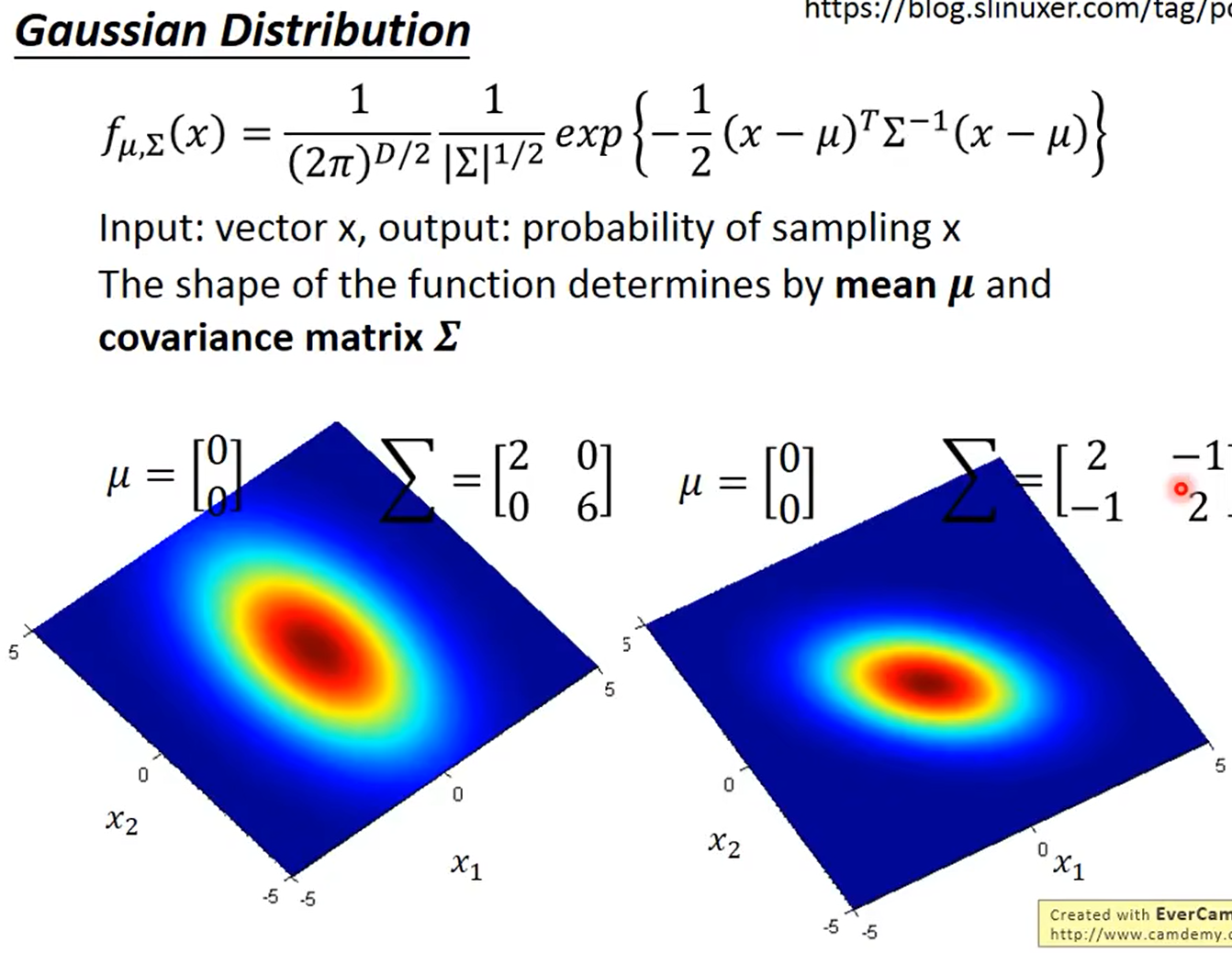
高斯分布:(正态分布)
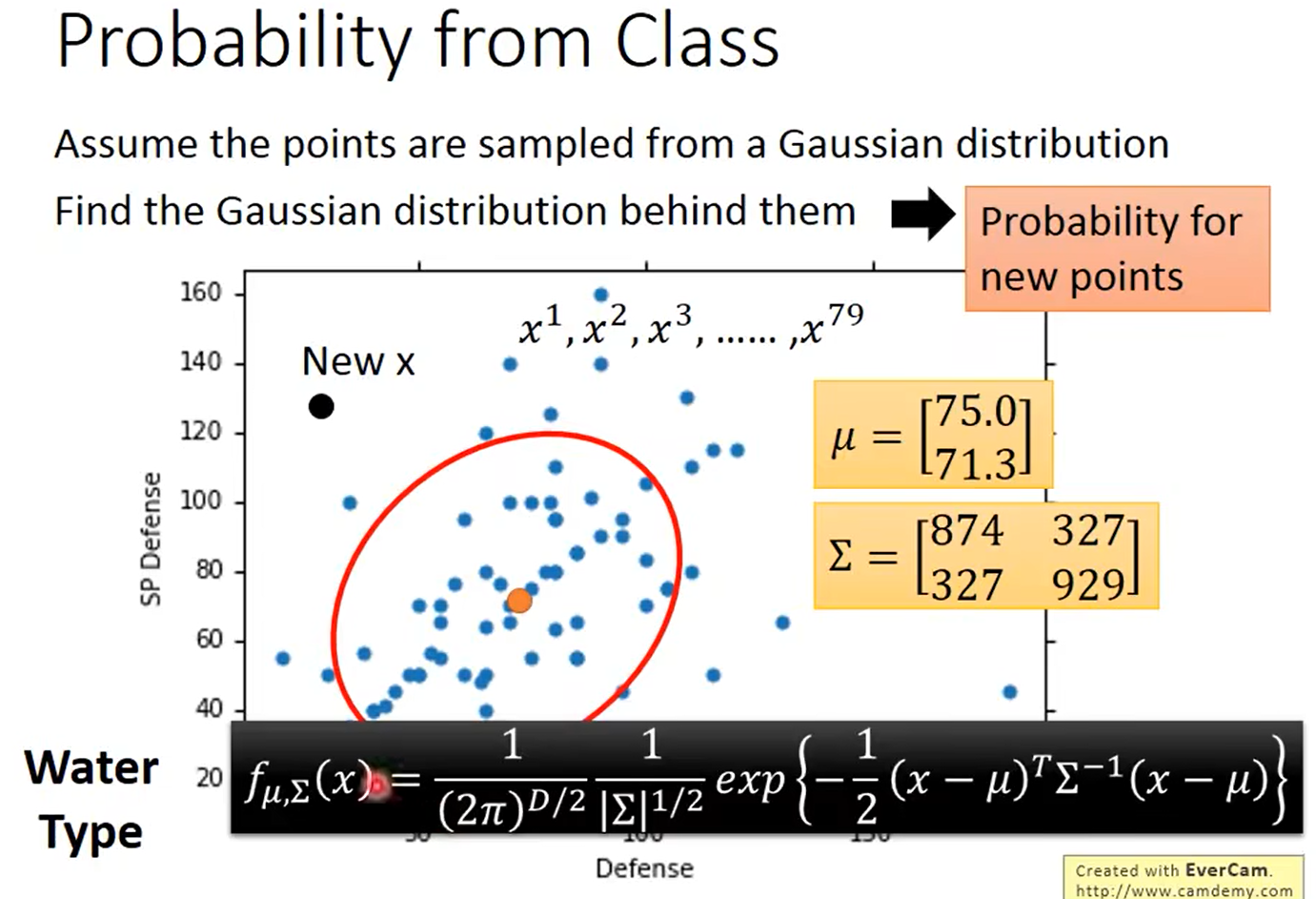
假设样本服从高斯分布,根据已有的标签数据可以求得每一类均值和方差的估计:
极大似然估计:
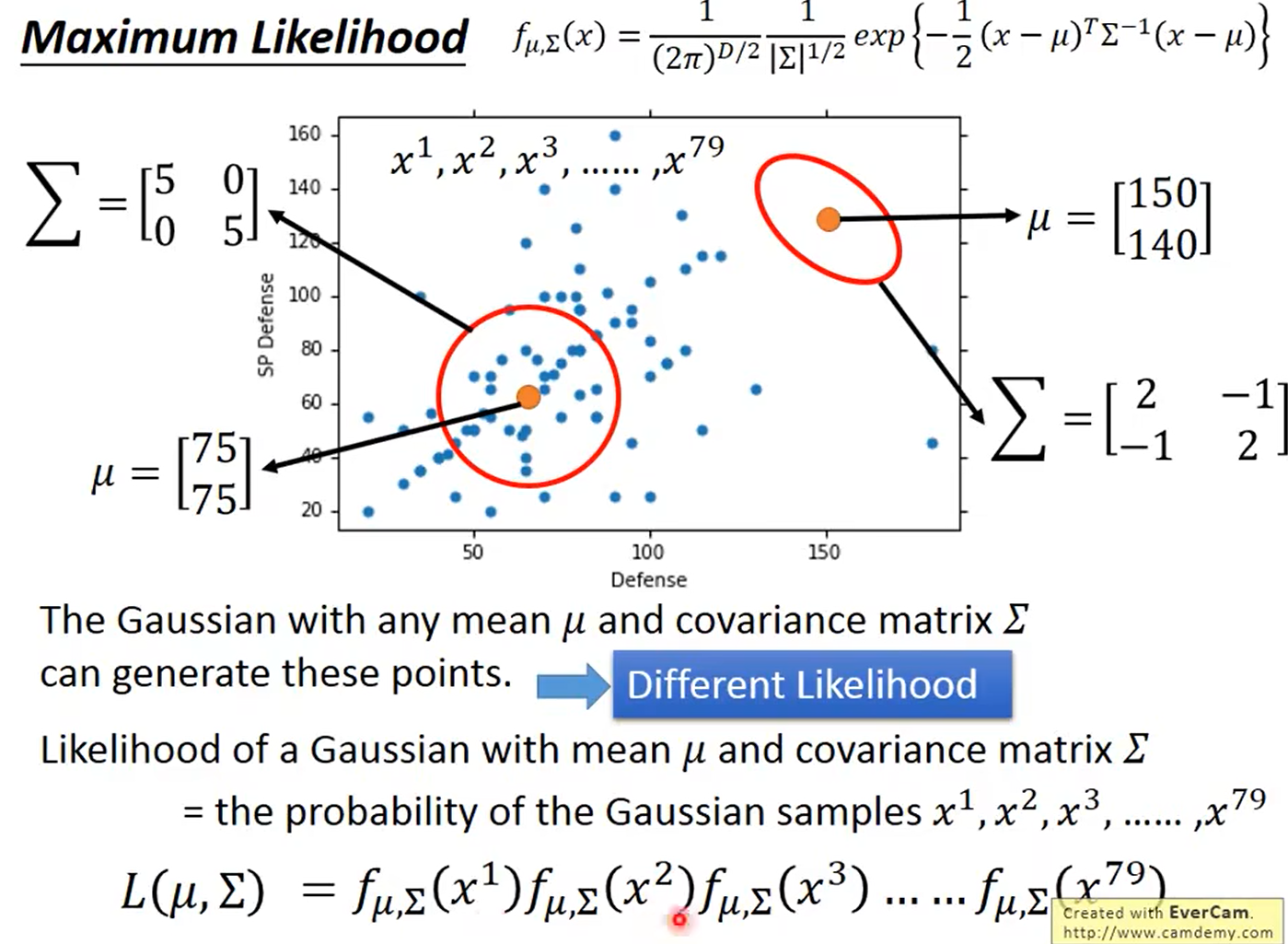
可以求出均值 μ ∗ \mu^* μ∗和方差 Σ ∗ \Sigma^* Σ∗的估计:

计算出均值和方差:
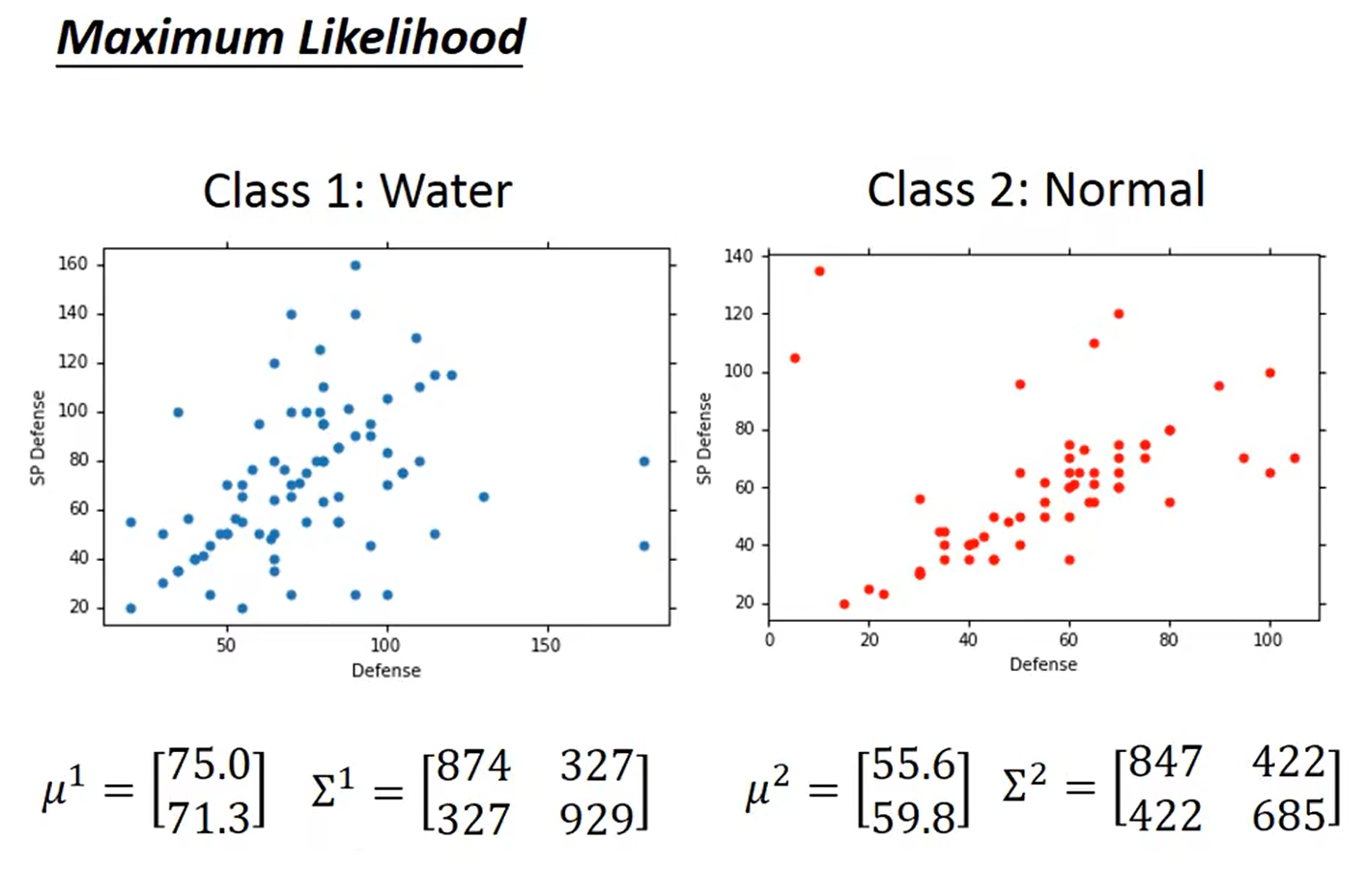
计算分类:

总结

4.3 后验概率公式推导

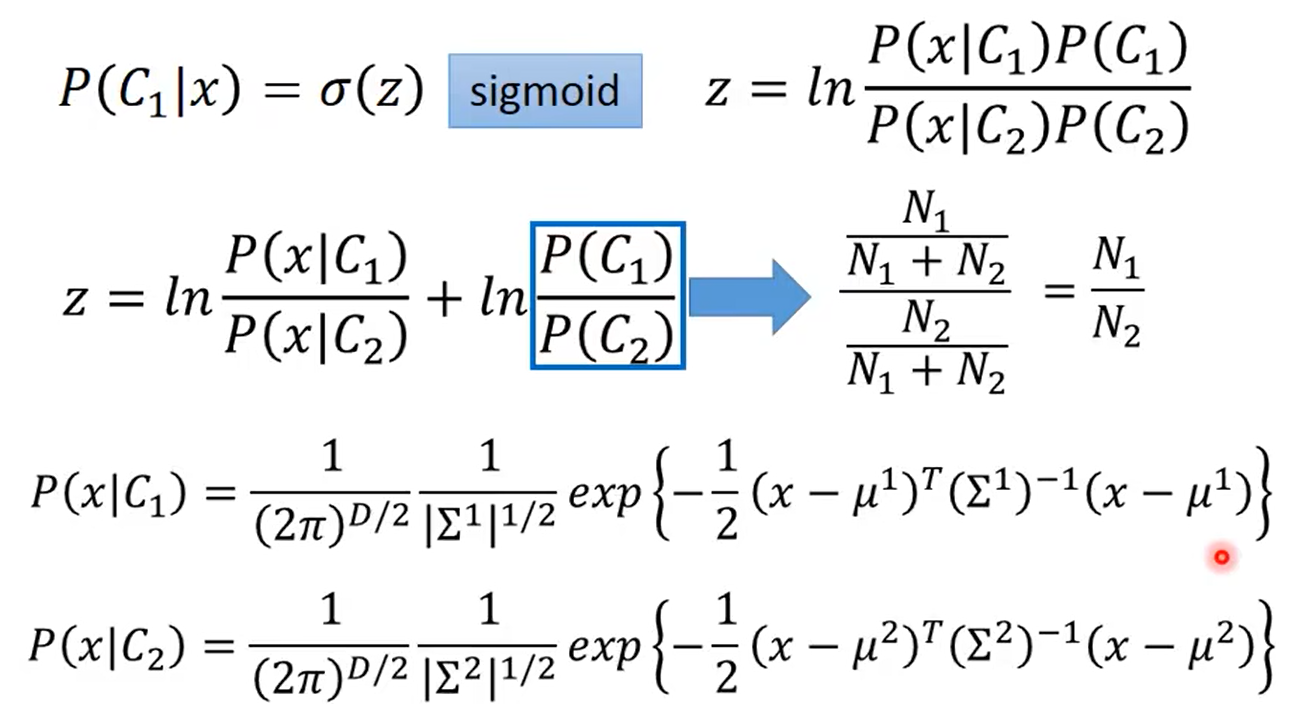



即现在模型可以简化为只需要估计w和b
4.4 逻辑回归
1.算法模型:
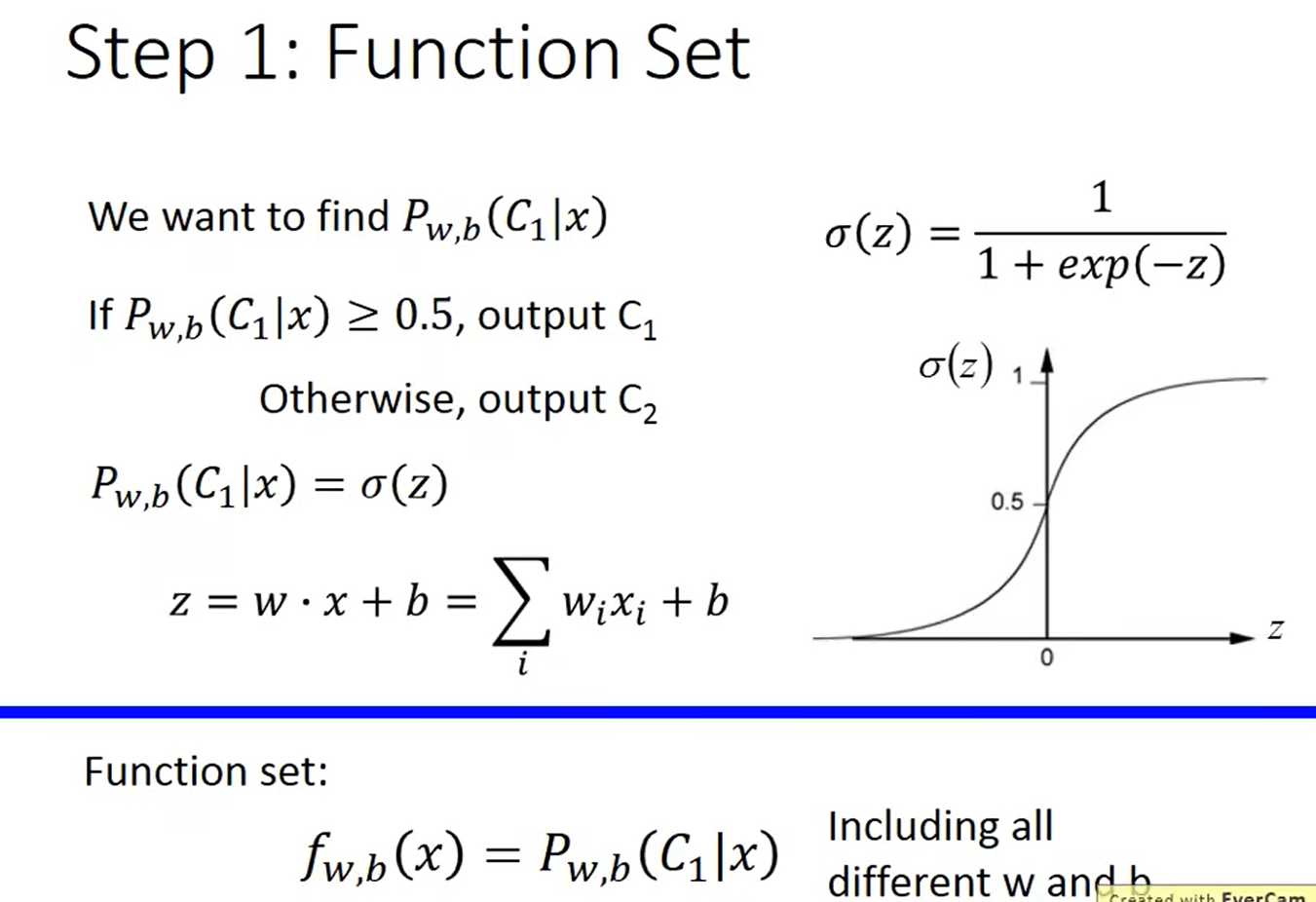
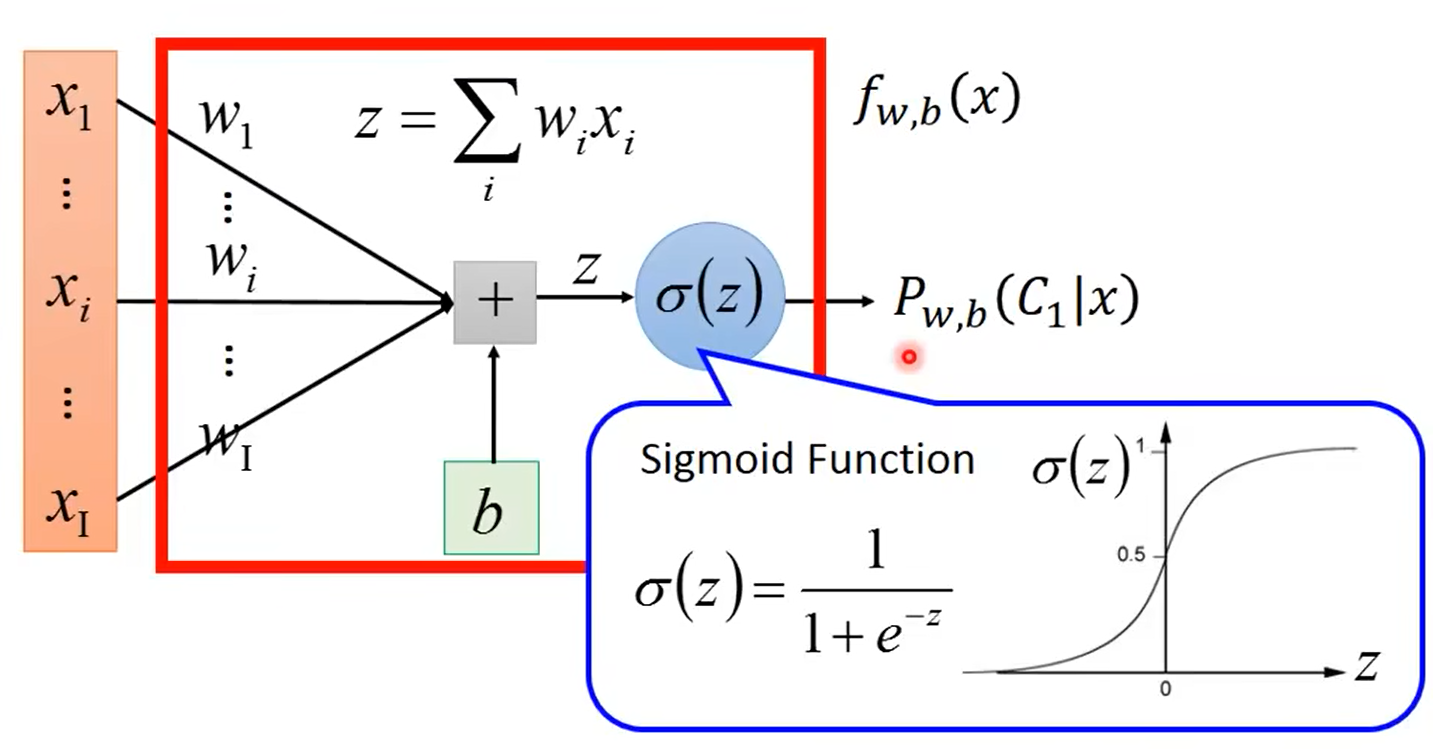
2.评价算法的好坏
交叉熵损失函数
令 f w , b ( x ) = σ ( w x + b ) f_w,b(x) = \sigma(wx+b) fw,b(x)=σ(wx+b),则逻辑回归的损失函数为L(w,b):



H(p,q)即为交叉熵损失函数
3.优化函数
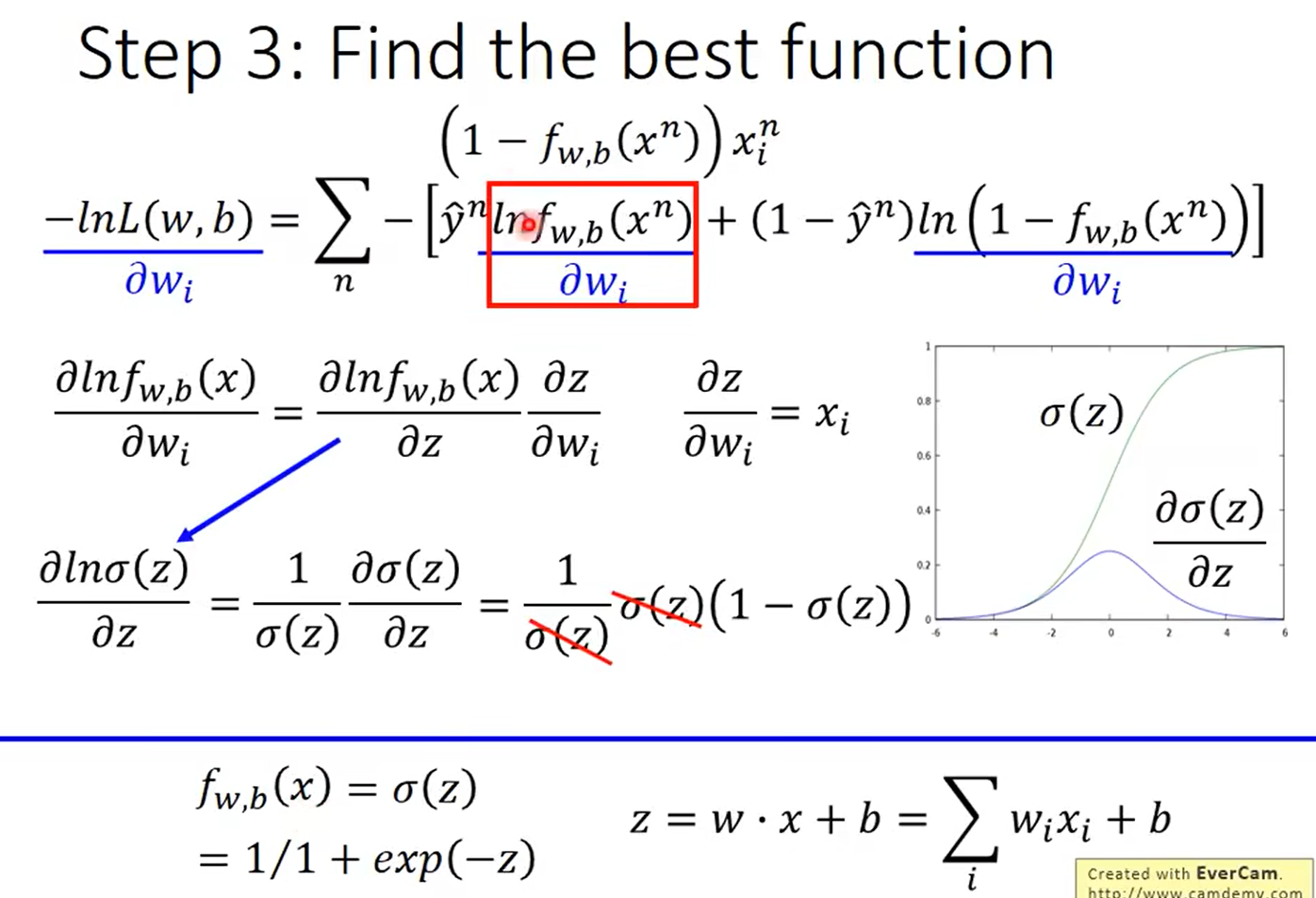


逻辑回归vs线性回归

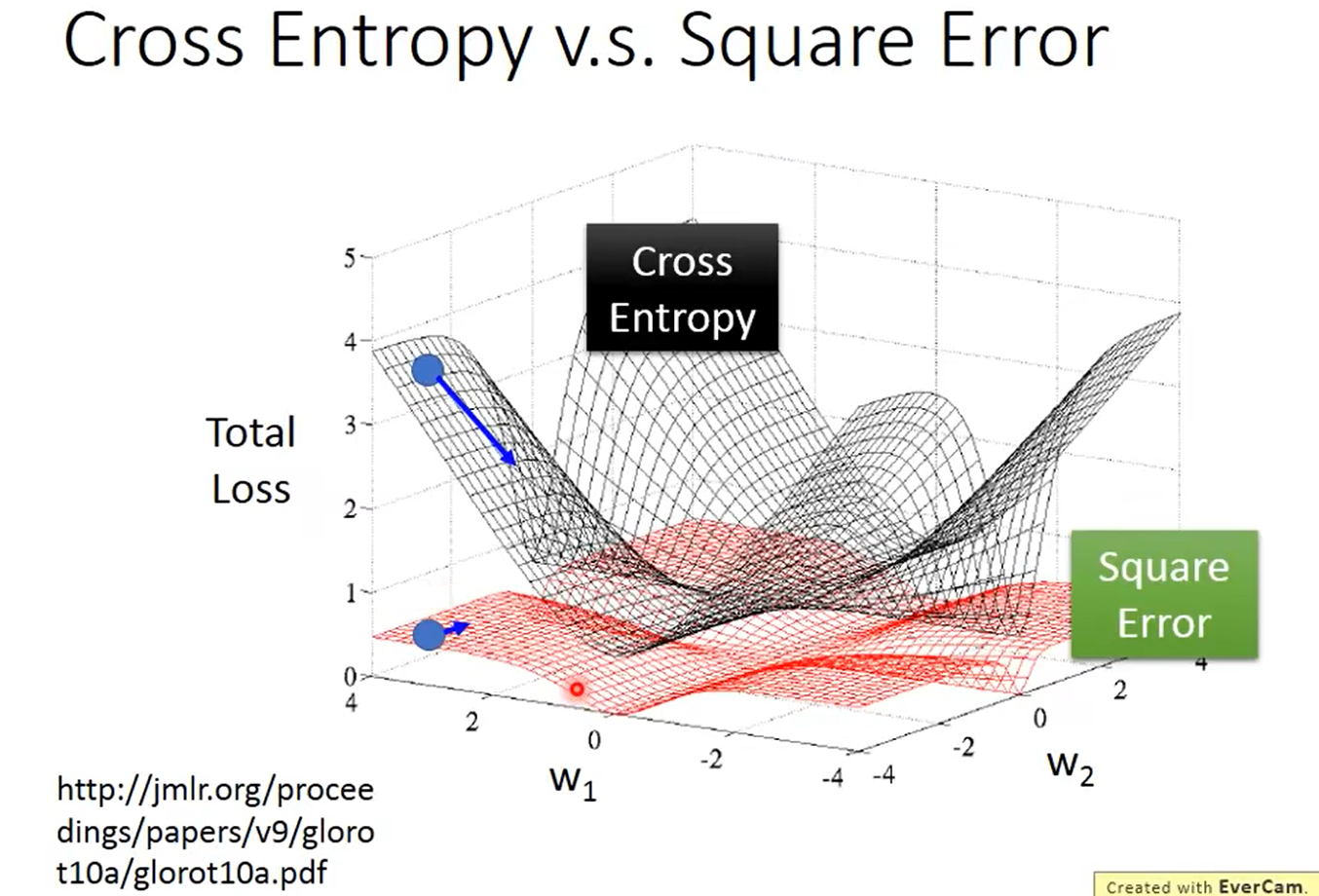
逻辑回归运用均方误差:

进行梯度下降的时候,后面计算微分的时候,在距离目标很近以及距离目标很远的时候都会出现微分为0的情况,具体图像如下所示:
逻辑回归的限制:
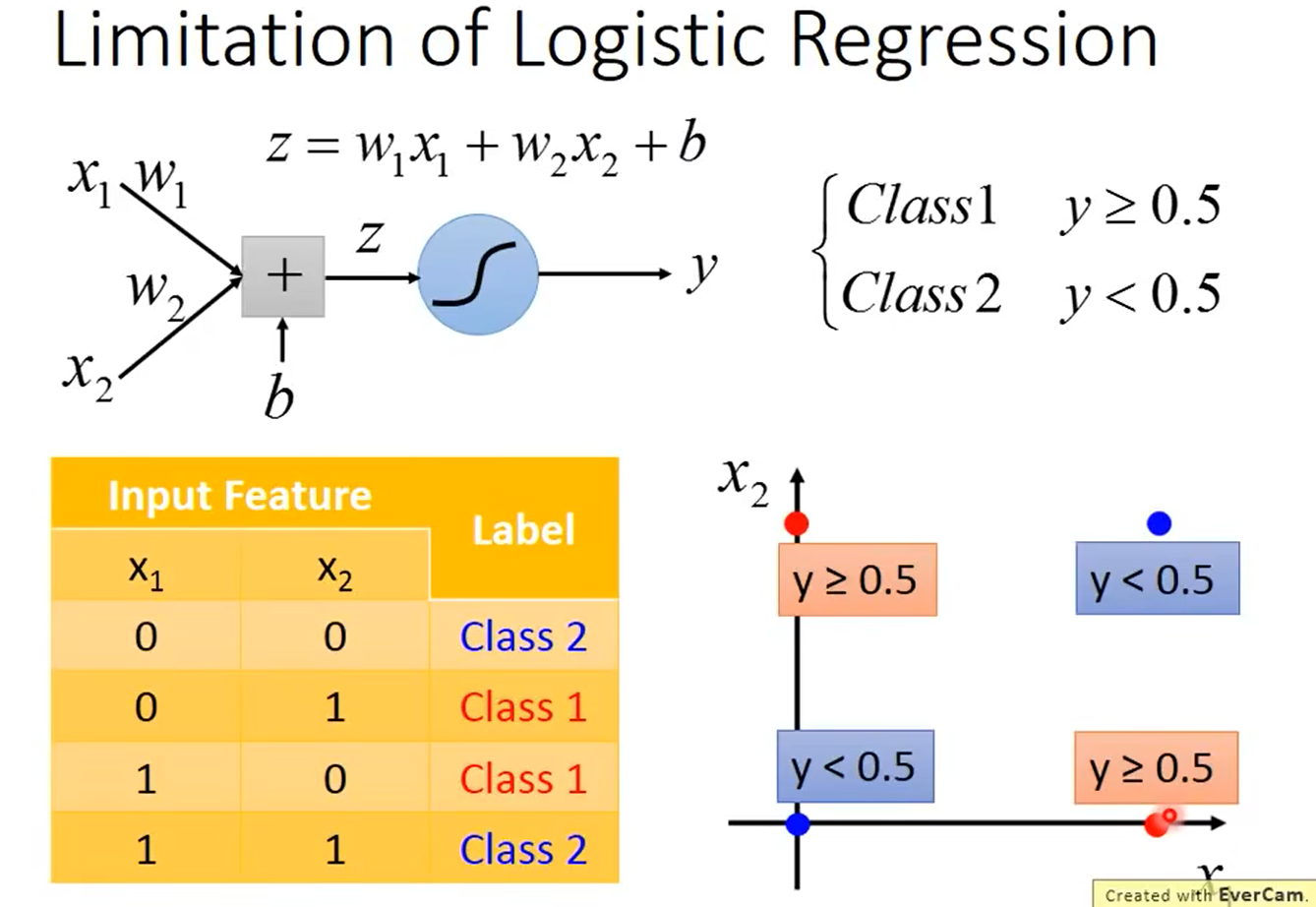
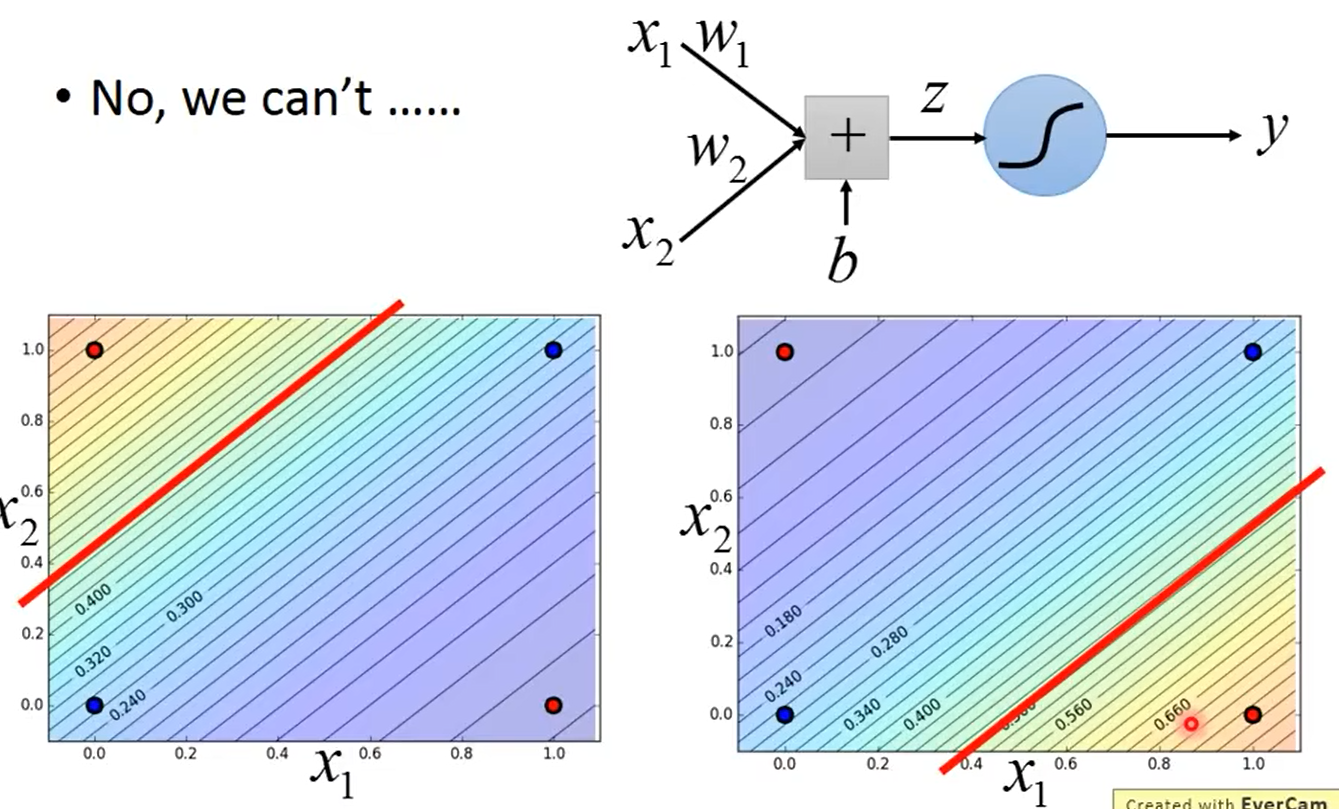
逻辑回归的边界就是一条直线,对于上述的图形会发现逻辑回归无法划分出红色的点和蓝色的点
解决方法是:将特征转换
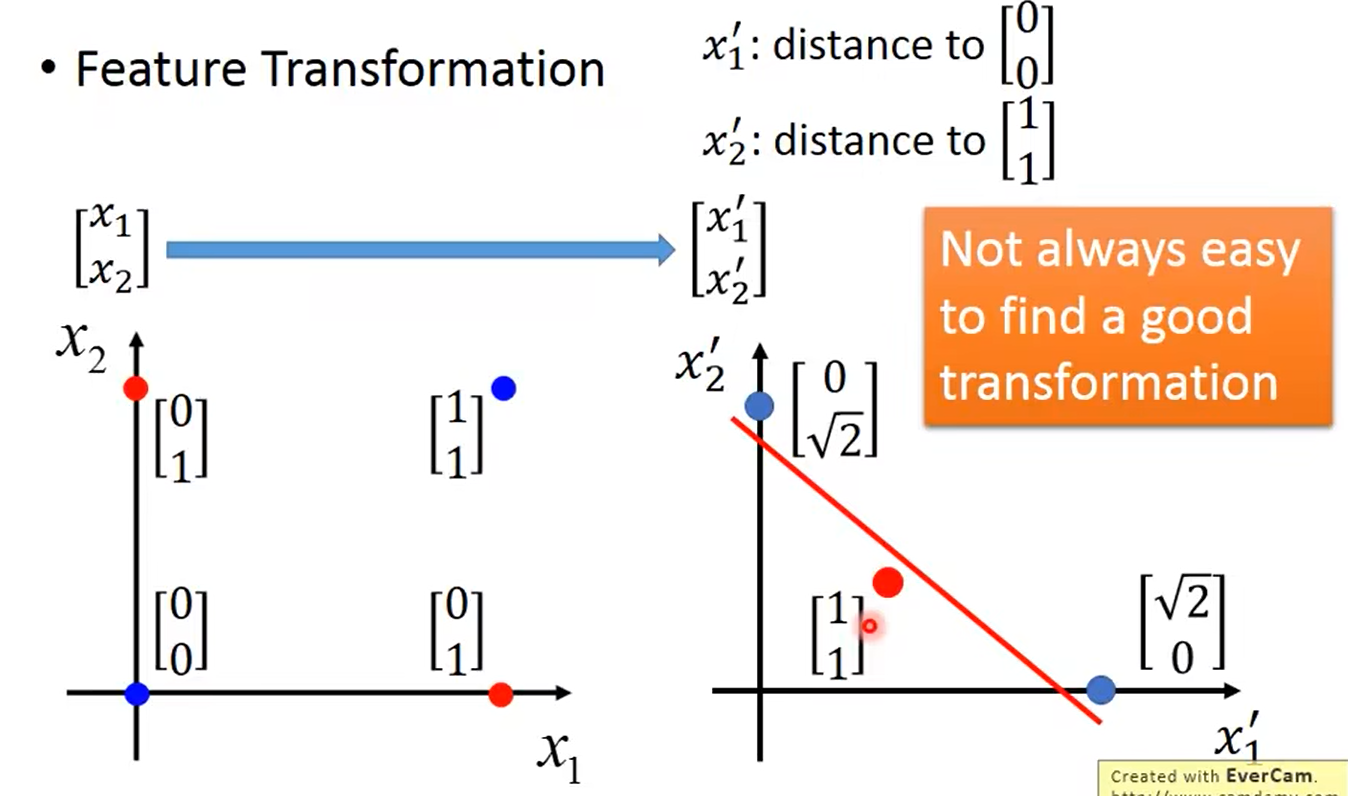
但是并不能一直可以找到一个好的转换,所以需要新的解决方法
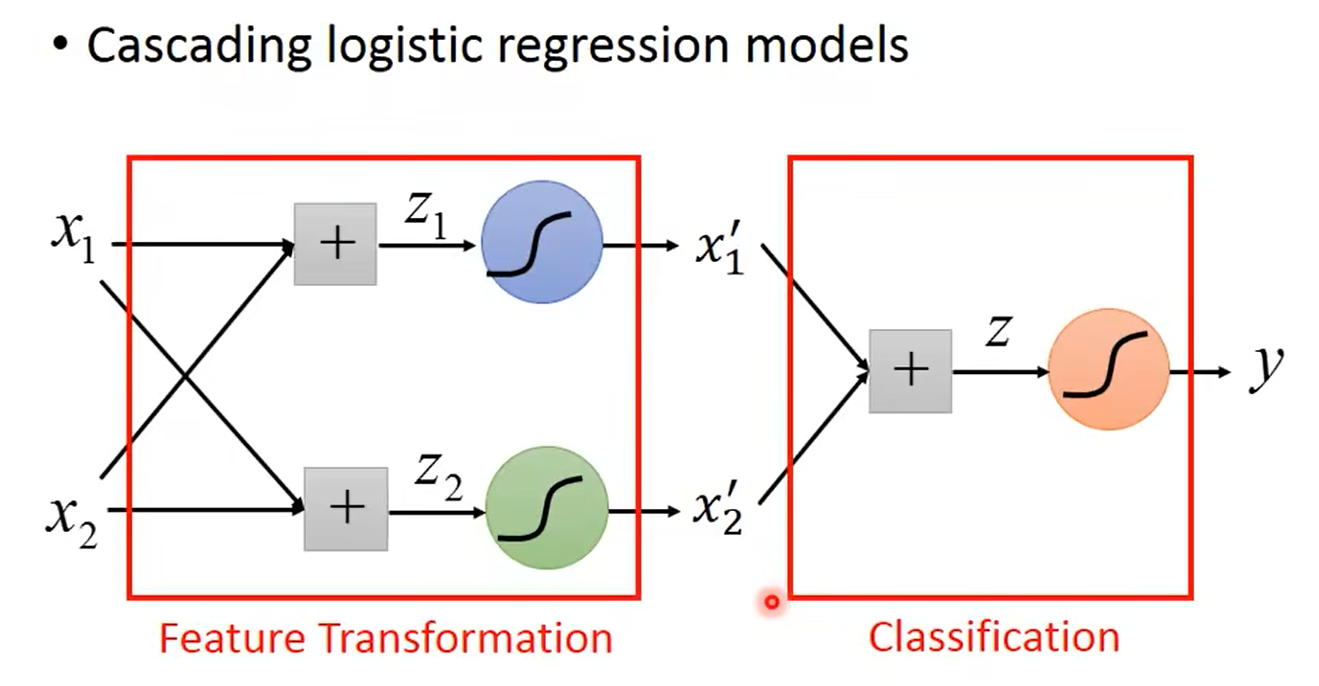
将逻辑回归模型级联起来:
前面所做的就是将特征转换,而后面的才是进行分类
4.5 判别模型 vs 生成模型

一般情况下,两者的w和b不一定相同
生成式模型的优点:
- 因为生成模型有一个先验的假设,所以需要更少的训练数据,而且对噪声有更高的鲁棒性。
- 先验分布和类别依赖的概率分布可以从不同的来源估计。
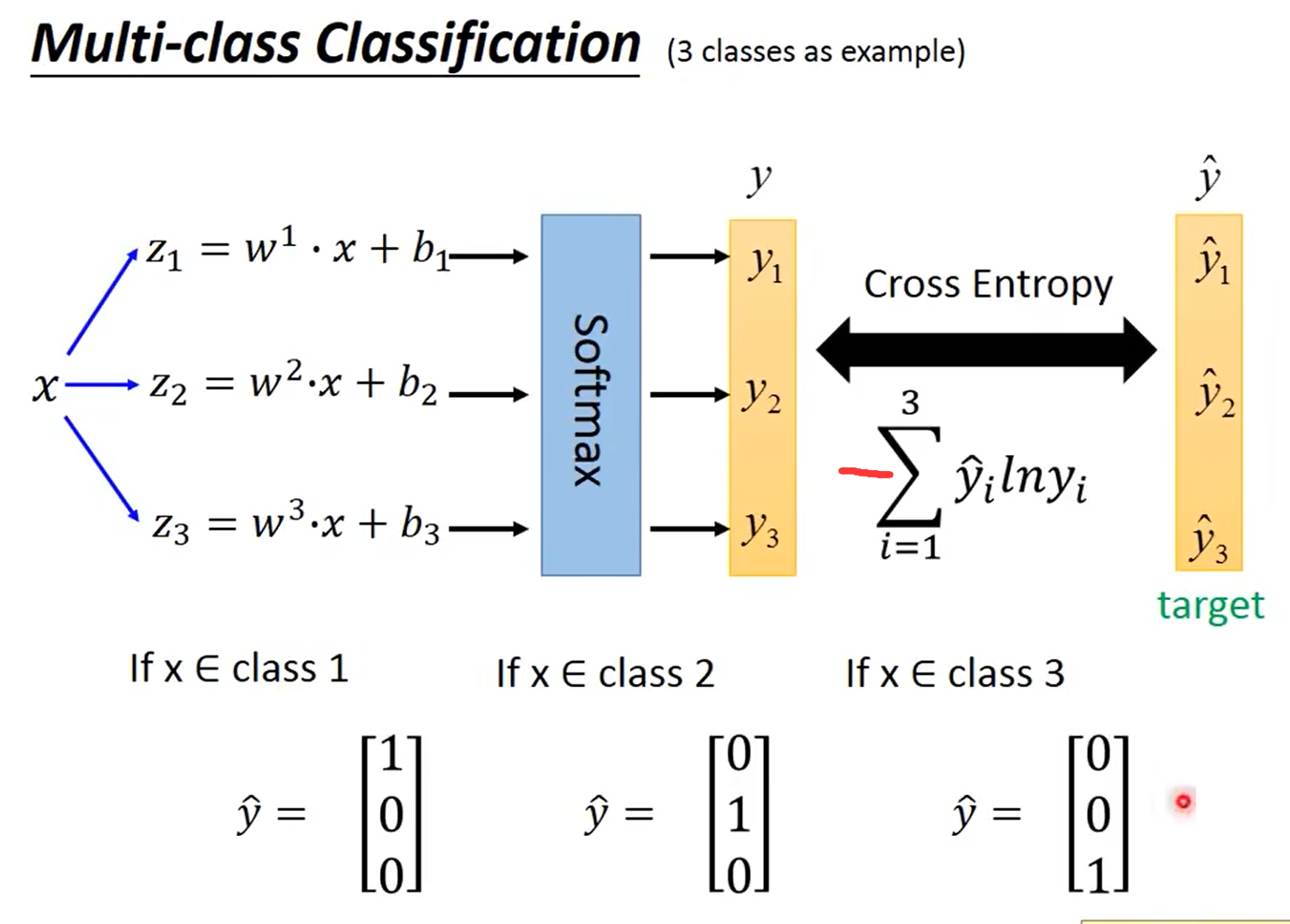
4.6 多分类
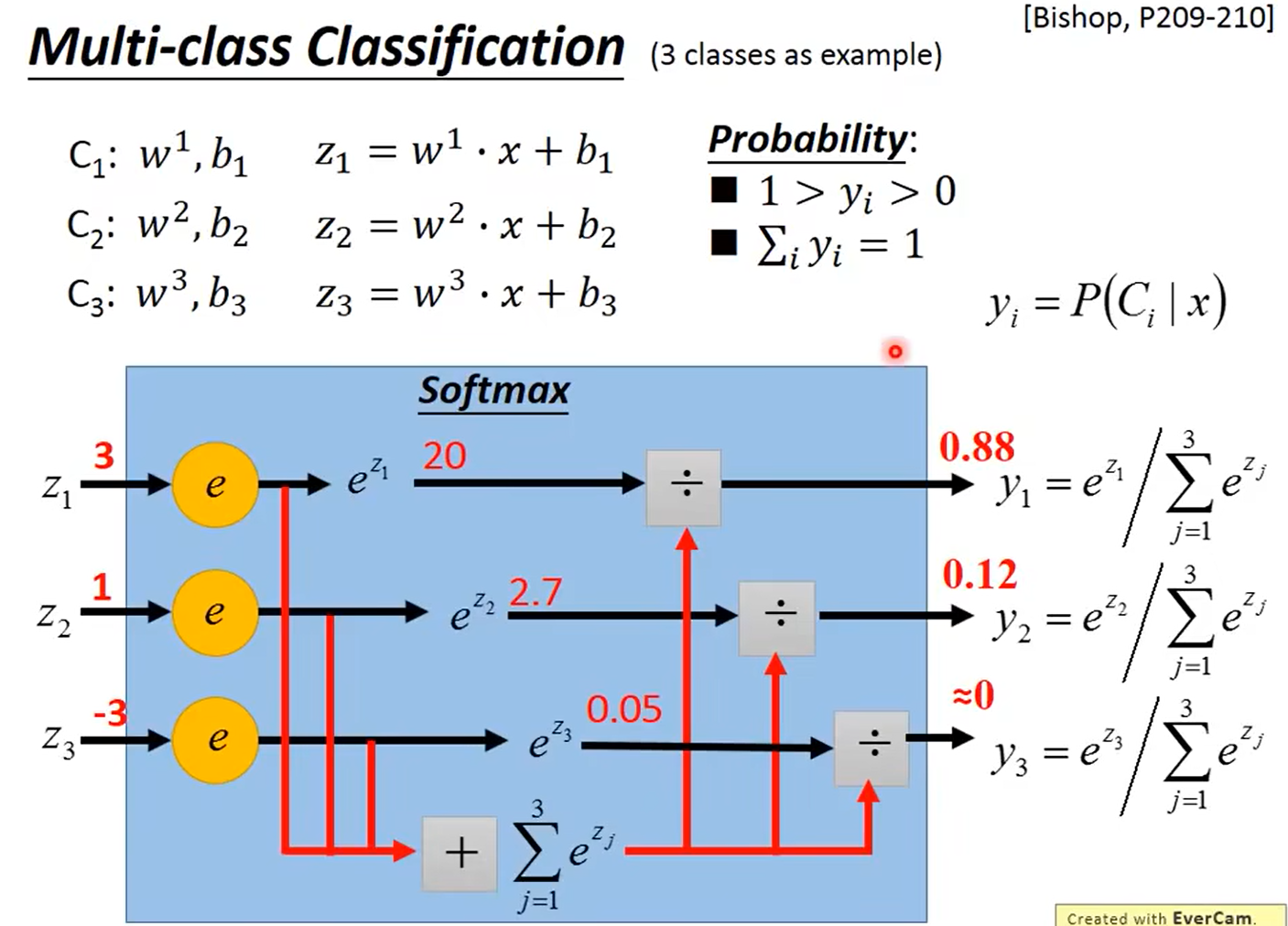















 660
660











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









