







学习视频:B站 刘二大人《PyTorch深度学习实践》完结合集
六、多维度的输入
1. 数据集
糖尿病的数据集:(对其进行分类)
- 每一行是一个样本
- 每一列x为一个特征/字段
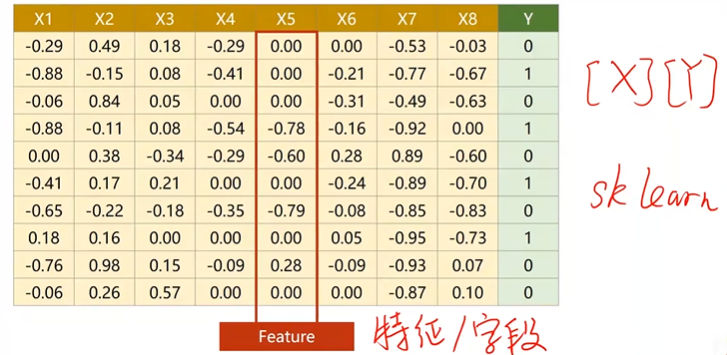
在机器学习和数据库中处理数据的方式略有不同,在机器学习里面,拿到数据表之后,把内容分为两部分,一部分作为输入x,另一部分作为输出y,如果训练是从数据库读数据,就把x读出来构成一个矩阵,把y字段读出来构成一个矩阵,就把输入的数据集准备好了
一个样本多个特征的计算图:
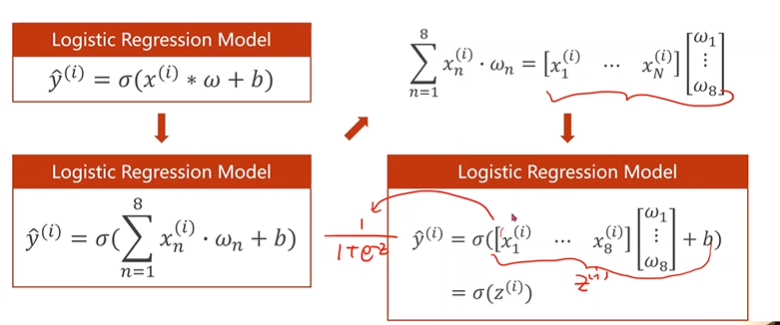
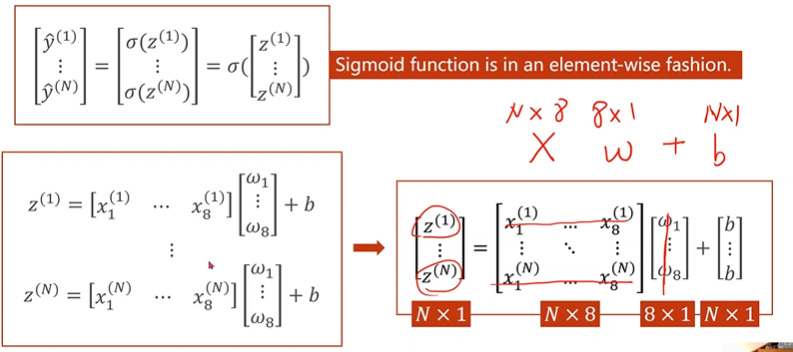
合成矩阵运算(多个样本多个特征的计算图)
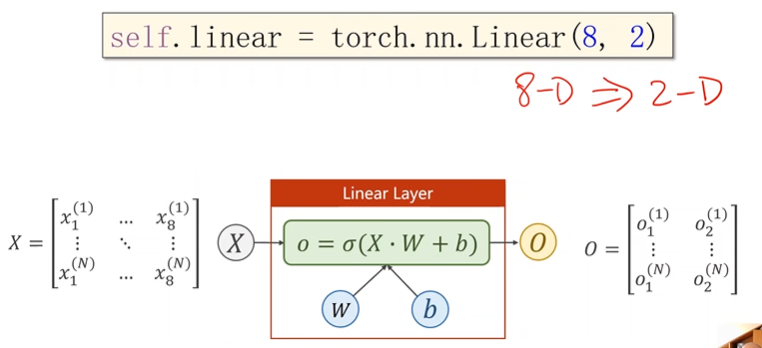
模型设置:
输入维度为8维,输出维度为1维
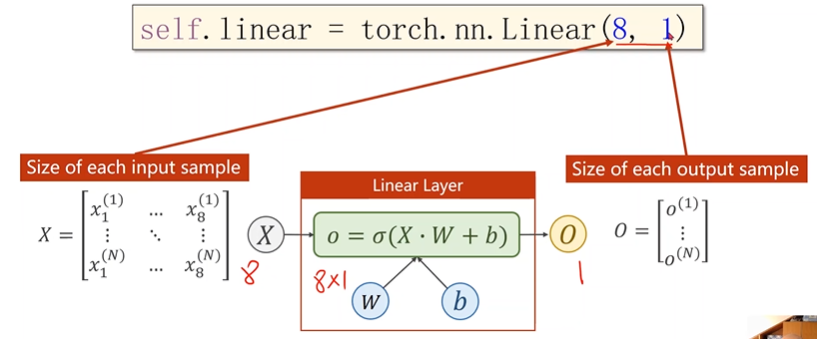
把任意8维向量映射为2维向量,空间维度的改变
引入sigmoid函数,引入非线性计算
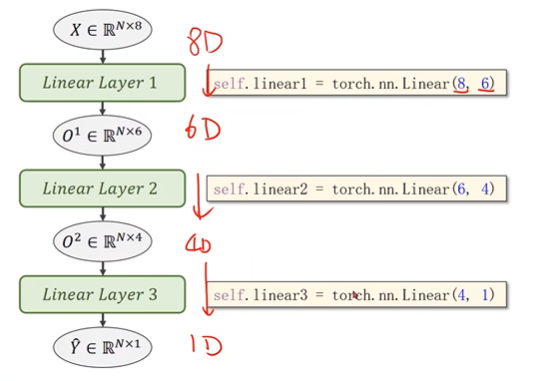
多层神经网络模型:
2. 计算步骤
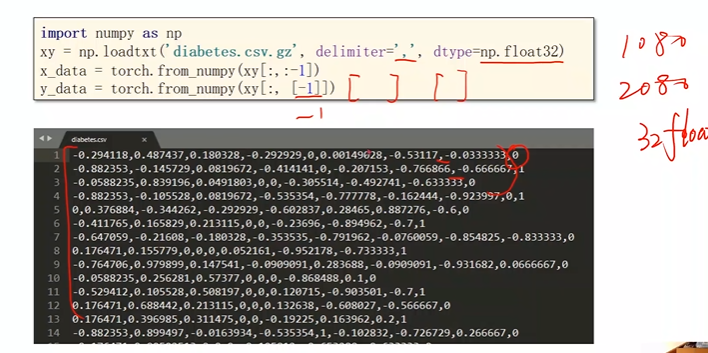
1.加载数据集
2.定义模型
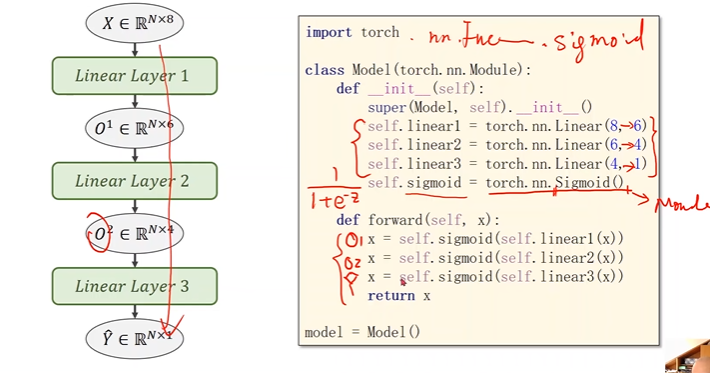
3.构造损失函数和优化器

3. 代码实现
import numpy as np
import torch
import matplotlib.pyplot as plt
xy = np.loadtxt('diabetes.csv.gz',delimiter=',',dtype=np.float32)
x_data = torch.from_numpy(xy[:,:-1])
y_data = torch.from_numpy(xy[:,[-1]])
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
self.linear1 = torch.nn.Linear(8,6)
self.linear2 = torch.nn.Linear(6,4)
self.linear3 = torch.nn.Linear(4,1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self,x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
#构造损失函数
criterion = torch.nn.BCELoss(size_average=True)
optimizer = torch.optim.SGD(model.parameters(),lr=0.1)
#训练的过程
epoch_list =[]
loss_list=[]
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred,y_data)
print(epoch,loss.item())
optimizer.zero_grad() #梯度归零
loss.backward()
optimizer.step() #梯度更新
epoch_list.append(epoch + 1)
loss_list.append(loss.item())
#画图
plt.plot(epoch_list,loss_list)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.grid()
plt.show()
运行结果:
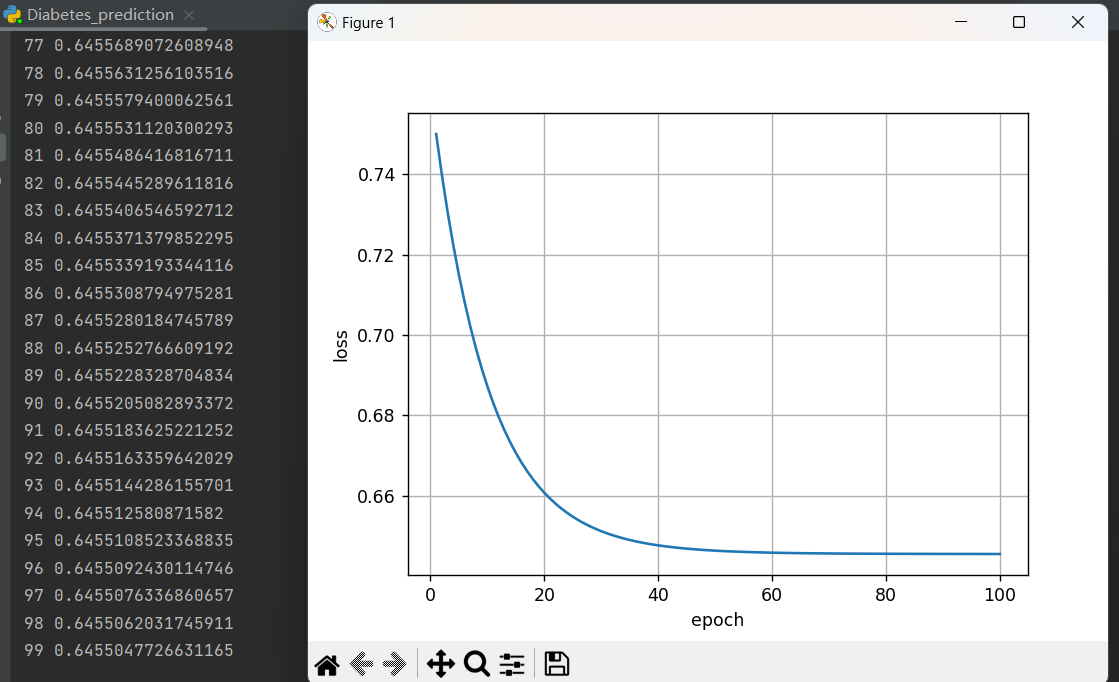
4. 课后练习
尝试不同的激活函数
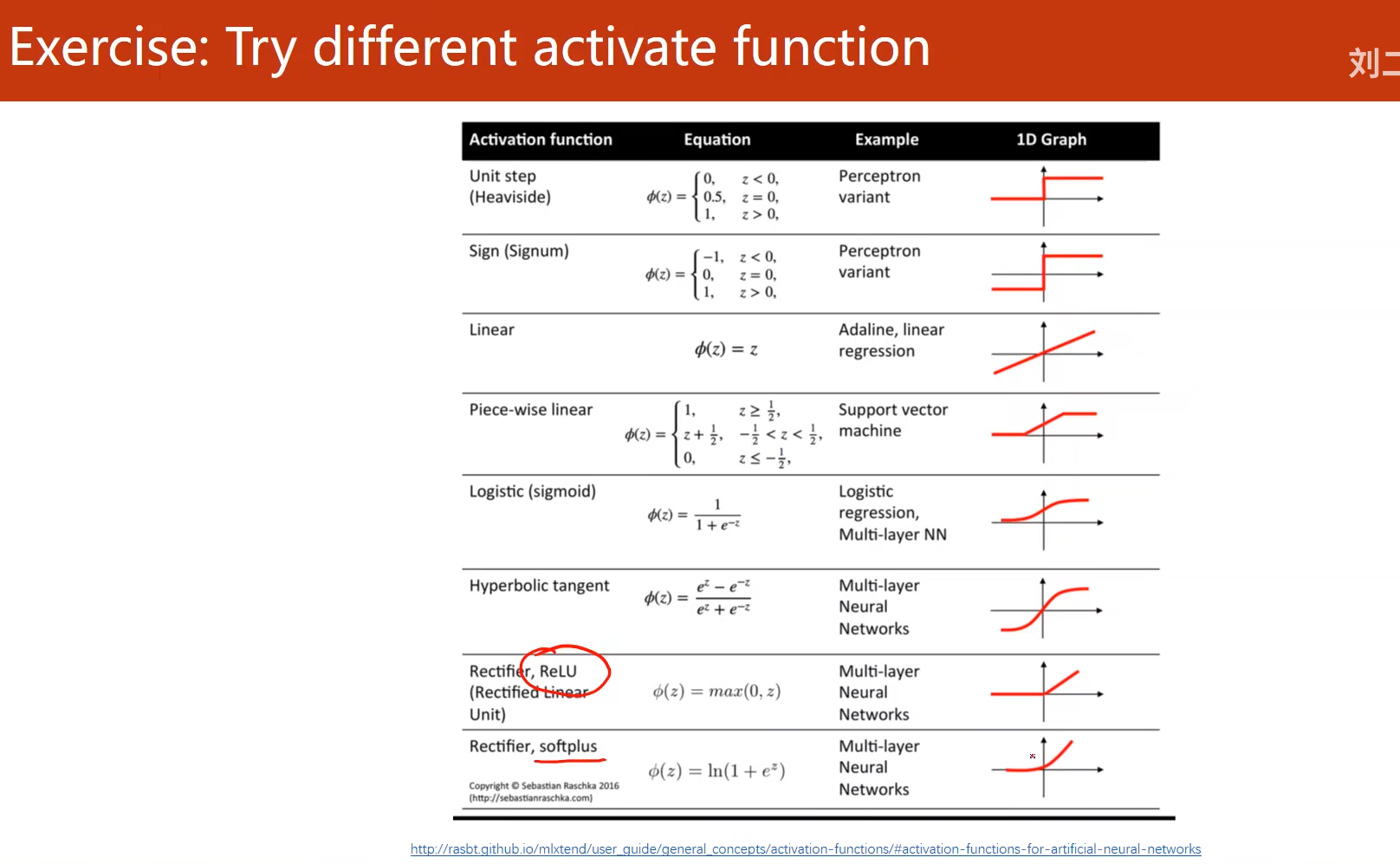

注意:
ReLU激活函数存在的问题是当激活函数的输入小于0时,激活函数的梯度就变为0,不会继续更新维度,所以采用ReLU需要注意,一般如果做分类,采用ReLU激活函数都是在前面的层数,最后一层激活函数不要使用ReLU,一般采用sigmoid
代码:
import numpy as np
import torch
import matplotlib.pyplot as plt
import torch.nn.functional as F
xy = np.loadtxt('diabetes.csv.gz',delimiter=',',dtype=np.float32)
x_data = torch.from_numpy(xy[:,:-1])
y_data = torch.from_numpy(xy[:,[-1]])
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
self.linear1 = torch.nn.Linear(8,6)
self.linear2 = torch.nn.Linear(6,4)
self.linear3 = torch.nn.Linear(4,1)
self.activate = torch.nn.ReLU()
def forward(self,x):
x = self.activate(self.linear1(x))
x = self.activate(self.linear2(x))
x = F.sigmoid(self.linear3(x))
return x
model = Model()
#构造损失函数
criterion = torch.nn.BCELoss(size_average=True)
optimizer = torch.optim.SGD(model.parameters(),lr=0.1)
#训练的过程
epoch_list =[]
loss_relu=[]
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred,y_data)
print(epoch,loss.item())
optimizer.zero_grad() #梯度归零
loss.backward()
optimizer.step() #梯度更新
epoch_list.append(epoch + 1)
loss_relu.append(loss.item())
#画图
plt.plot(epoch_list,loss_relu)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.grid()
plt.show()
运行结果:
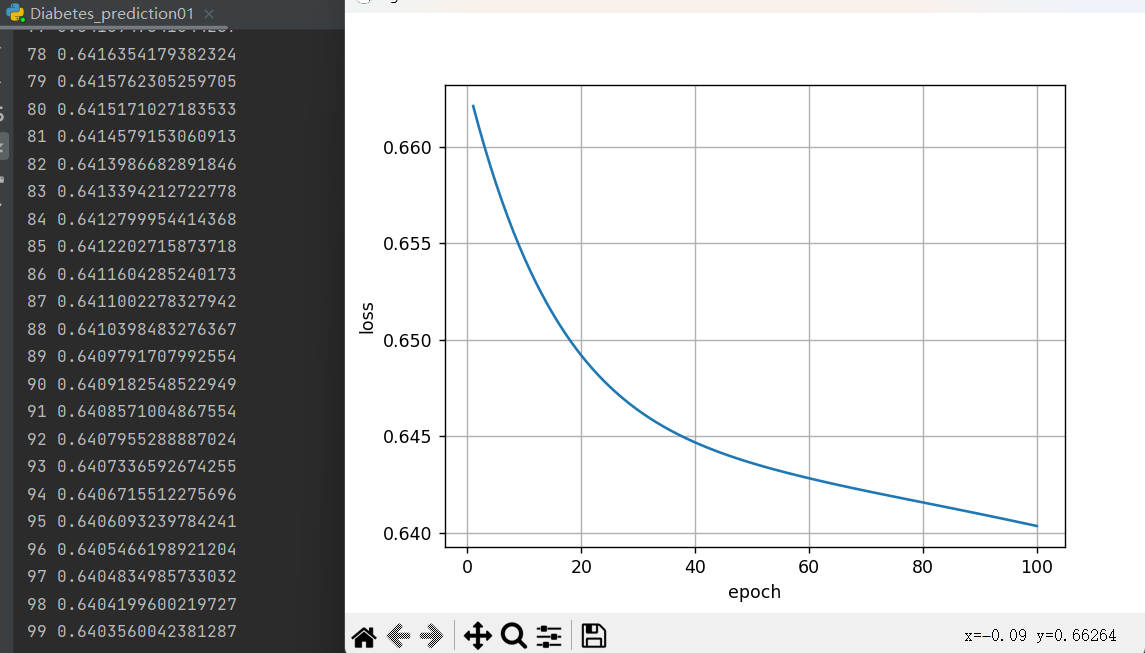
补充
- 如果想查看某一层的参数,以神经网络的第一层参数为例:
# 参数说明
# 第一层的参数:
layer1_weight = model.linear1.weight.data
layer1_bias = model.linear1.bias.data
print("layer1_weight", layer1_weight)
print("layer1_weight.shape", layer1_weight.shape)
print("layer1_bias", layer1_bias)
print("layer1_bias.shape", layer1_bias.shape)
- 更改epoch为100000,以准确率acc为评价指标,源代码为:
import numpy as np
import torch
import matplotlib.pyplot as plt
# prepare dataset
xy = np.loadtxt('diabetes.csv', delimiter=',', dtype=np.float32)
x_data = torch.from_numpy(xy[:, :-1]) # 第一个‘:’是指读取所有行,第二个‘:’是指从第一列开始,最后一列不要
print("input data.shape", x_data.shape)
y_data = torch.from_numpy(xy[:, [-1]]) # [-1] 最后得到的是个矩阵
# print(x_data.shape)
# design model using class
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 2)
self.linear4 = torch.nn.Linear(2, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x)) # y hat
x = self.sigmoid(self.linear4(x)) # y hat
return x
model = Model()
# construct loss and optimizer
# criterion = torch.nn.BCELoss(size_average = True)
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
# training cycle forward, backward, update
for epoch in range(100000):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
# print(epoch, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch%100000 == 99999:
y_pred_label = torch.where(y_pred>=0.5,torch.tensor([1.0]),torch.tensor([0.0]))
acc = torch.eq(y_pred_label, y_data).sum().item()/y_data.size(0)
print("loss = ",loss.item(), "acc = ",acc)
参考资料:
https://blog.csdn.net/qq_43800119/article/details/126415596














 365
365











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









