







一、PyTorch简介
1. 基本介绍
2017 年 1 月,FAIR(Facebook AI Research)发布了 PyTorch。PyTorch 是在 Torch 基础上用 python 语言重新打造的一款深度学习框架。Torch 是采用 Lua 语言为接口的机器学习框架,但是因为 Lua 语言较为小众,导致 Torch 学习成本高,因此知名度不高。
Pytorch优点
- 上手快,掌握 Numpy 和基本深度学习概念即可上手。
- 代码简洁灵活,使用 nn.Module 封装使得网络搭建更加方便 。基于动态图机制,更加灵活。
PyTorch实现模型训练的5大要素

- 数据:包括数据读取,数据清洗 ,进行数据划分和数据预处理,比如读取图片如何预处理及数据增强
- 模型:包括构建模型模块,组织复杂网络,初始化网络参数,定义网络层
- 损失函数:包括创建损失函数,设置损失函数超参数,根据不同任务选择合适的损失函数。
- 优化器:包括根据梯度使用某种优化器更新参数,管理模型参数,管理多个参数组实现不同学习率,调整学习率。
- 迭代训练:组织上面 4 个模块进行反复训练。包括观察训练效果,绘制 Loss/ Accuracy 曲线,用 TensorBoard 进行可视化分析
主要围绕这5个方面介绍
2. PyTorch基础知识
2.1 Tensor(张量)介绍
Tensor 中文为张量。张量的意思是一个多维数组,它是标量、向量、矩阵的高维扩展。
标量可以称为 0 维张量,向量可以称为 1 维张量,矩阵可以称为 2 维张量,RGB 图像可以表示 3 维张量。你可以把张量看作多维数组。

常见构造Tensor的函数:
| 函数 | 功能 |
|---|---|
| torch.tensor() | 直接创建tensor |
| torch.from_numpy(ndarry) | 从 numpy 创建 tensor |
| torch.zeros(*sizes) | 全0 |
| torch.ones(*sizes) | 全1 |
| torch.eye(*size) | 对角为1,其余全为0 |
| torch.arange(s,e,step) | 从s到e,步长为step |
| torch.linspace(s,e,steps) | 从s到e,均匀分成step份 |
| torch.rand/randn(*sizes) | rand是[0,1)均匀分布;randn是服从N(0,1)的正态分布 |
| torch.normal(mean,std) | 正态分布(均值为mean,标准差是std) |
| torch.randperm(m) | 生成从 0 到 m-1 的随机排列 |
| torch.bernoulli(n) | 以n为概率,生成伯努利分布 (0-1 分布,两点分布) |
张量的操作:
torch.cat()
torch.cat(tensors, dim=0, out=None)
功能:将张量按照 dim 维度进行拼接
torch.stack()
torch.stack(tensors, dim=0, out=None)
功能:将张量在新创建的 dim 维度上进行拼接
torch.chunk()
torch.chunk(input, chunks, dim=0)
功能:将张量按照维度 dim 进行平均切分。若不能整除,则最后一份张量小于其他张量。
torch.split()
torch.split(tensor, split_size_or_sections, dim=0)
功能:将张量按照维度 dim 进行平均切分。可以指定每一个分量的切分长度。
torch.index_select()
torch.index_select(input, dim, index, out=None)
功能:在维度 dim 上,按照 index 索引取出数据拼接为张量返回。
torch.mask_select()
torch.masked_select(input, mask, out=None)
功能:按照 mask 中的 True 进行索引拼接得到一维张量返回。
torch.reshape()
torch.reshape(input, shape)
功能:变换张量的形状。当张量在内存中是连续时,返回的张量和原来的张量共享数据内存,改变一个变量时,另一个变量也会被改变
torch.transpose()
torch.transpose(input, dim0, dim1)
功能:交换张量的两个维度。常用于图像的变换,比如把c*h*w变换为h*w*c。
torch.t()
功能:2 维张量转置,对于 2 维矩阵而言,等价于torch.transpose(input, 0, 1)。
torch.squeeze()
torch.squeeze(input, dim=None, out=None)
功能:压缩长度为 1 的维度。
torch.unsqueeze()
torch.unsqueeze(input, dim)
功能:根据 dim 扩展维度,长度为 1。
2.2 计算图与梯度求导
计算图
计算图是用来描述运算的有向无环图,有两个主要元素:节点 (Node) 和边 (Edge)。节点表示数据,如向量、矩阵、张量。边表示运算,如加减乘除卷积等。
用计算图表示: y = ( x + w ) ∗ ( w + 1 ) y=(x+w)*(w+1) y=(x+w)∗(w+1),如下所示:
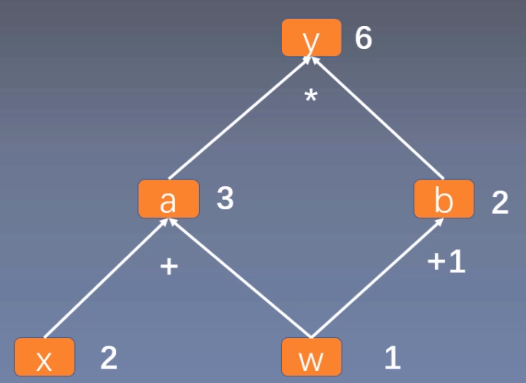
可以看作, y = a × b y=a \times b y=a×b ,其中 a = x + w a=x+w a=x+w, b = w + 1 b=w+1 b=w+1。
梯度求导
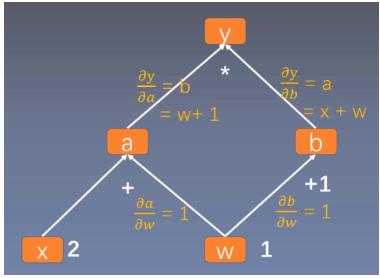
这里求 y y y 对 w w w 的导数。根复合函数的求导法则,可以得到如下过程。
∂ y ∂ w = ∂ y ∂ a ∂ a ∂ w + ∂ y ∂ b ∂ b ∂ w = b ∗ 1 + a ∗ 1 = b + a = ( w + 1 ) + ( x + w ) = 2 ∗ w + x + 1 = 2 ∗ 1 + 2 + 1 = 5 \begin{aligned} \frac{\partial y}{\partial w} =\frac{\partial y}{\partial a} \frac{\partial a}{\partial w}+\frac{\partial y}{\partial b} \frac{\partial b}{\partial w} =b *1+a* 1 =b+a =(w+1)+(x+w)=2 *w+x+1 =2* 1+2+1=5\end{aligned} ∂w∂y=∂a∂y∂w∂a+∂b∂y∂w∂b=b∗1+a∗1=b+a=(w+1)+(x+w)=2∗w+x+1=2∗1+2+1=5
体现到计算图中,就是根节点
y
y
y 到叶子节点
w
w
w 有两条路径 y -> a -> w和y ->b -> w。根节点依次对每条路径的孩子节点求导,一直到叶子节点w,最后把每条路径的导数相加即可。
代码:
import torch
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
# y=(x+w)*(w+1)
a = torch.add(w, x) # retain_grad()
b = torch.add(w, 1)
y = torch.mul(a, b)
# y 求导
y.backward()
# 打印 w 的梯度,就是 y 对 w 的导数
print(w.grad)
输出:
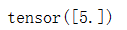
2.3 自动求导
在深度学习中,权值的更新是依赖于梯度的计算,因此梯度的计算是至关重要的,在 PyTorch 中,只需要搭建好前向计算图,然后利用torch.autograd自动求导得到所有张量的梯度。
torch.autograd.backward()
torch.autograd.backward(tensors, grad_tensors=None, retain_graph=None, create_graph=False, grad_variables=None)
功能:自动求取梯度
- tensors: 用于求导的张量,如 loss
- retain_graph: 保存计算图。PyTorch 采用动态图机制,默认每次反向传播之后都会释放计算图。这里设置为 True 可以不释放计算图。
- create_graph: 创建导数计算图,用于高阶求导
- grad_tensors: 多梯度权重。当有多个 loss 混合需要计算梯度时,设置每个 loss 的权重。
retain_graph参数
代码:
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
# y=(x+w)*(w+1)
a = torch.add(w, x)
b = torch.add(w, 1)
y = torch.mul(a, b)
# 第一次执行梯度求导
y.backward()
print(w.grad)
# 第二次执行梯度求导,出错
y.backward()
其中y.backward()方法调用的是torch.autograd.backward(self, gradient, retain_graph, create_graph)。但是在第二次执行y.backward()时会出错。因为 PyTorch 默认是每次求取梯度之后不保存计算图的,因此第二次求导梯度时,计算图已经不存在了。在第一次求梯度时使用y.backward(retain_graph=True)即可。如下代码所示:
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
# y=(x+w)*(w+1)
a = torch.add(w, x)
b = torch.add(w, 1)
y = torch.mul(a, b)
# 第一次求导,设置 retain_graph=True,保留计算图
y.backward(retain_graph=True)
print(w.grad)
# 第二次求导成功
y.backward()
grad_tensors参数
代码:
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x)
b = torch.add(w, 1)
y0 = torch.mul(a, b) # y0 = (x+w) * (w+1)
y1 = torch.add(a, b) # y1 = (x+w) + (w+1) dy1/dw = 2
# 把两个 loss 拼接都到一起
loss = torch.cat([y0, y1], dim=0) # [y0, y1]
# 设置两个 loss 的权重: y0 的权重是 1,y1 的权重是 2
grad_tensors = torch.tensor([1., 2.])
loss.backward(gradient=grad_tensors) # gradient 传入 torch.autograd.backward()中的grad_tensors
# 最终的 w 的导数由两部分组成。∂y0/∂w * 1 + ∂y1/∂w * 2
print(w.grad)
输出:
tensor([9.])
该 loss 由两部分组成: y 0 y_{0} y0 和 y 1 y_{1} y1。其中 ∂ y 0 ∂ w = 5 \frac{\partial y_{0}}{\partial w}=5 ∂w∂y0=5, ∂ y 1 ∂ w = 2 \frac{\partial y_{1}}{\partial w}=2 ∂w∂y1=2。而 grad * tensors 设置两个 loss 对 w 的权重分别为 1 和 2。因此最终 w 的梯度为:$ \frac{\partial y_{0}}{\partial w} \times 1+ \frac{\partial y_{1}}{\partial w} \times 2=9$
torch.autograd.grad()
torch.autograd.grad(outputs, inputs, grad_outputs=None, retain_graph=None, create_graph=False, only_inputs=True, allow_unused=False)
功能:求梯度
- outputs: 用于求导的张量,如 loss
- inputs: 需要梯度的张量
- create_graph: 创建导数计算图,用于高阶求导
- retain_graph:保存计算图
- grad_outputs:多梯度权重计算
torch.autograd.grad()的返回结果是一个 tuple,需要取出第 0 个元素才是真正的梯度。
下面使用torch.autograd.grad()求二阶导,在求一阶导时,需要设置 create_graph=True,让一阶导数 grad_1 也拥有计算图,然后再使用一阶导求取二阶导:
x = torch.tensor([3.], requires_grad=True)
y = torch.pow(x, 2) # y = x**2
# 如果需要求 2 阶导,需要设置 create_graph=True,让一阶导数 grad_1 也拥有计算图
grad_1 = torch.autograd.grad(y, x, create_graph=True) # grad_1 = dy/dx = 2x = 2 * 3 = 6
print(grad_1)
# 这里求 2 阶导
grad_2 = torch.autograd.grad(grad_1[0], x) # grad_2 = d(dy/dx)/dx = d(2x)/dx = 2
print(grad_2)
输出:
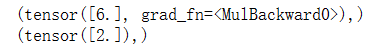
注意:
- 在每次反向传播求导时,计算的梯度不会自动清零。如果进行多次迭代计算梯度而没有清零,那么梯度会在前一次的基础上叠加。
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
# 进行 4 次反向传播求导,每次最后都没有清零
for i in range(4):
a = torch.add(w, x)
b = torch.add(w, 1)
y = torch.mul(a, b)
y.backward()
print(w.grad)
输出:

每一次的梯度都比上一次的梯度多5,这是由于梯度不会自动清零,使用w.grad.zero_()将梯度清零
总结:
- autograd包:提供张量上的自动求导机制
- 原理:如果设置.requires_grad为True,那么将会追踪张量的所有操作。当完成计算后,可以通过调用.backward()自动计算所有的梯度。张量的所有梯度将会自动累加到.grad属性
- Function:Tensor和Function互相连接生成了一个无环图 (acyclic graph),它编码了完整的计算历史。每个张量都有一个.grad_fn属性,该属性引用了创建Tensor自身的Function
参考资料
https://blog.csdn.net/qq_36816848/article/details/123560830
https://pytorch.zhangxiann.com/














 7027
7027











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









