







一.链表
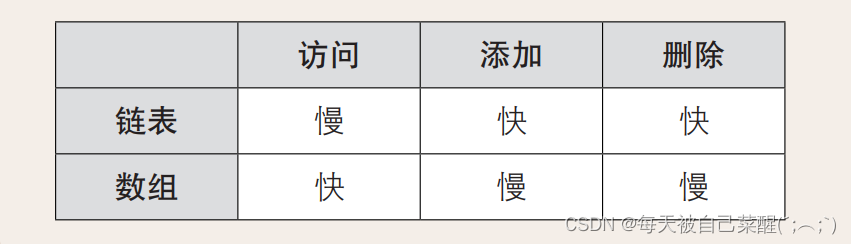
链表是数据结构之一,其中的数据呈线性排列。在链表中,数据的添加和删除都较为方便, 就是访问比较耗费时间。
链表中的数据呈线性排列,就像是一条铁链。不论顺序如何混乱,都可通过环与环之间的纽带——“指针”来指明其前后的顺序。
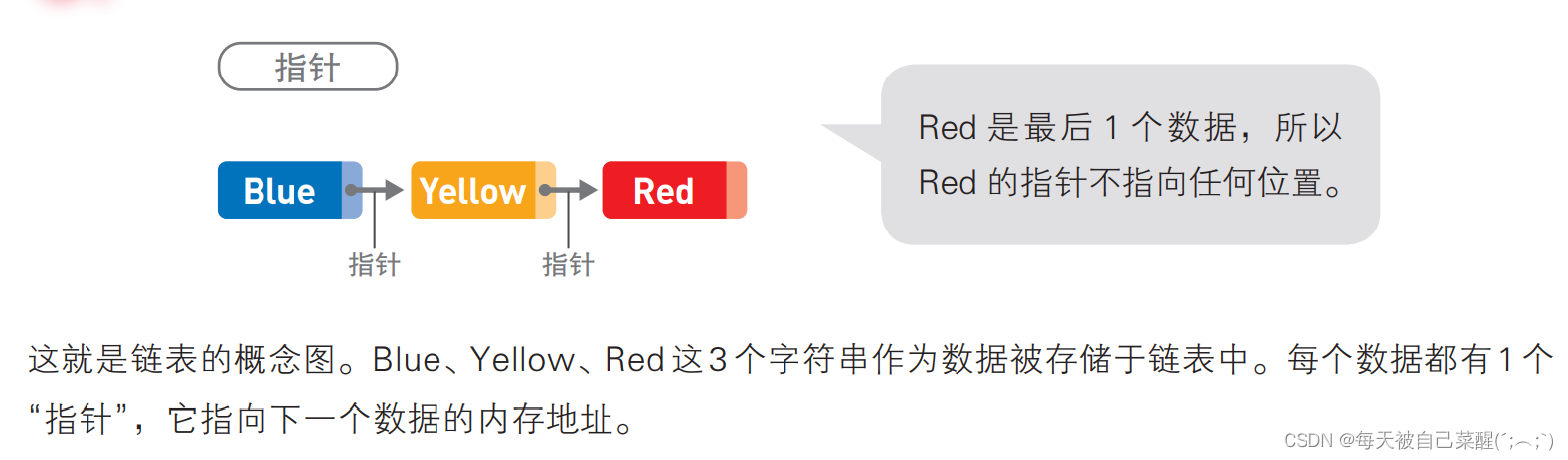
1.访问数据
数据一般分散存储于内存中,链表必须顺序访问。
因为数据都是分散存储的,所以如果想要访问数据,只能从第1个数据开始,顺着指针的指向——往下访问(这便是顺序访问)。比如,想要找到Red这—数据,就得从Blue开始访问。这之后,还要经过 Yellow,我们才能找到 Red。
2.添加或删除数据
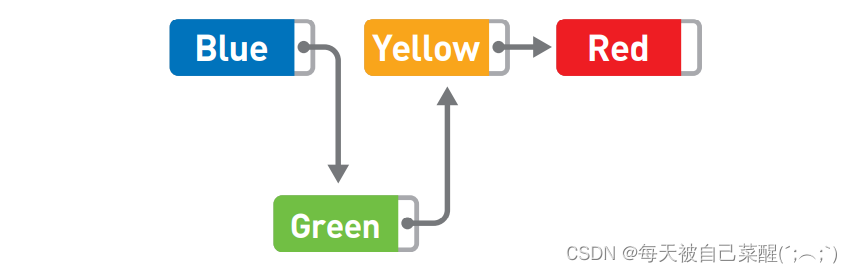
如果想要添加数据,只需要改变添加位置前后的指针的指向就行了。删除同理。
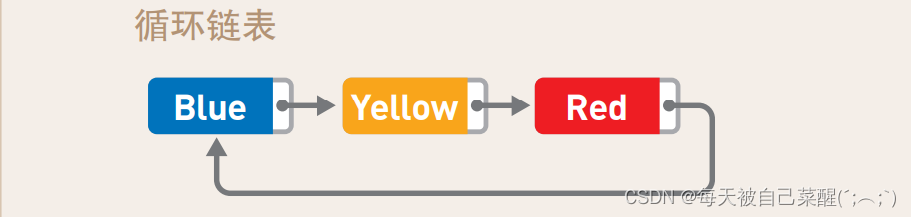
循环链表:
链表末尾有指针,且指针指向链表的头部数据,将链表变成环形。
这便是“循环链表”,也叫“环形链表”。 循环链表没有头和尾的概念。想要保存数量固定的最新数据时通常会使用这种链表.
双向链表:

二.数组
数组也是数据呈线性排列的一种数据结构。在数组中,访问数据十分 简单,而添加和删除数据比较耗工夫。数组按顺序存储在内存的连续空间内。
由于数据是存储在连续空间内的,所以每个数 据的内存地址(在内存上的位置)都可以通过 数组下标算出,我们也就可以借此直接访问目 标数据(这叫作“随机访问”)。
如果想要在数组中添加元素。首先,在数组的末尾确保需要增加的存储空间。为了给新数据腾出位置,要把已有数据一个个 移开。最后在空出来的位置上写入新元素。删除也是同理。

三.栈
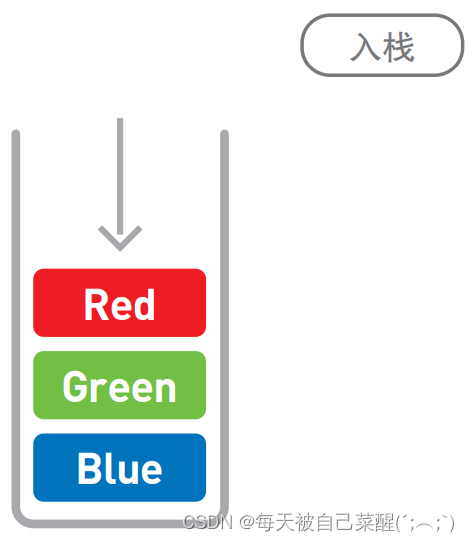
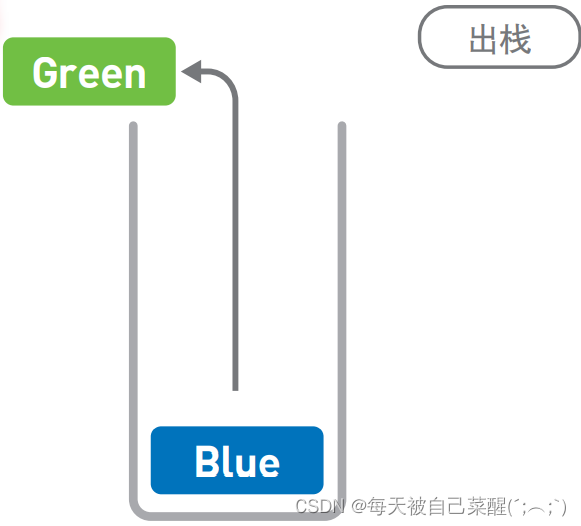
栈也是一种数据呈线性排列的数据结构,不过在这种结构中,我们只能访问最新添加的数 据。栈就像是一摞书,拿到新书时我们会把它放在书堆的最上面,取书时也只能从最上面的新书开始取。
像栈这种最后添加的数据最先被取出,即“后进先出”的结构,我们称为 Last In First Out,简称 LIFO。
与链表和数组一样,栈的数据也是线性排列,但在栈中,添加和删除数据的操作只 能在一端进行,访问数据也只能访问到顶端的数据。想要访问中间的数据时,就必须通 过出栈操作将目标数据移到栈顶才行。
四.队列
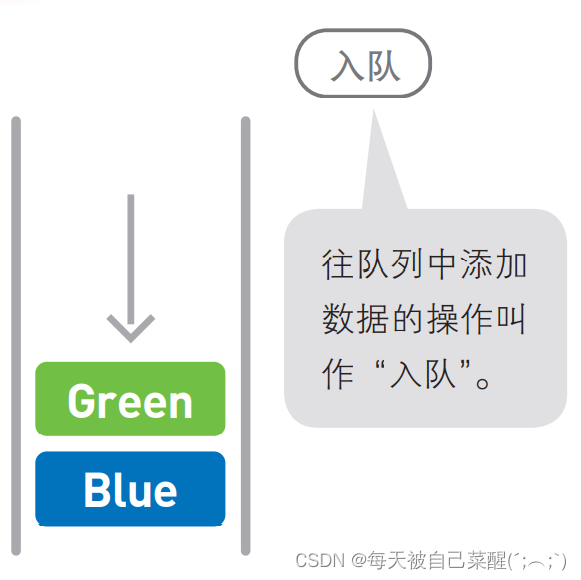
队列中添加和删除数据的操作分别是在两端进行的。
像队列这种最先进去的数据最先被取来,即“先进先出”的结构,我们称为 First In First Out,简称 FIFO。
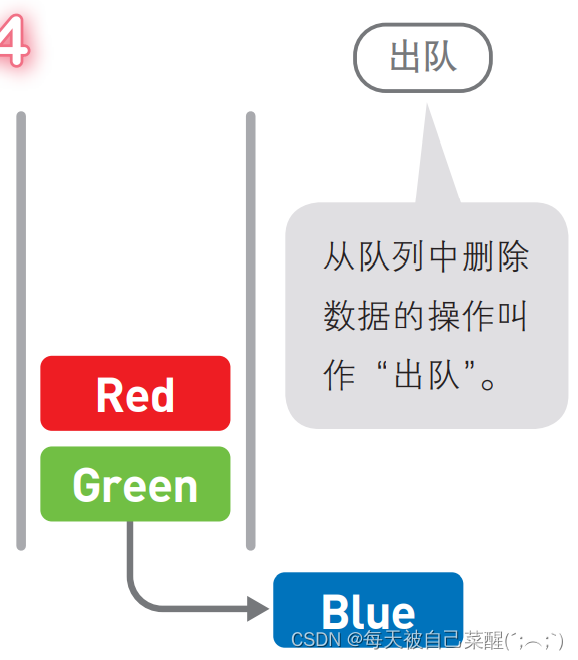
与栈类似,队列中可以操作数据的位置也有一定的限制。在栈中,数据的添加和删 除都在同一端进行,而在队列中则分别是在两端进行的。队列也不能直接访问位于中间 的数据,必须通过出队操作将目标数据变成首位后才能访问。
五.哈希表
哈希表存储的是由键(key)和值(value)组 成的数据。例如,我们将每个人的性别作为数据进行存储,键为人名,值为对应的性别。运用哈希表查找数据,比传统的线性查找耗时短,高效。
制作哈希表:
使用哈希函数(Hash)计算 字符串的键,也就是 字符串的哈希值。将得到的哈希值除以数组的长度,求得其余数。这样的求余运算叫作“mod 运算”。若遇到存储位置重复了的情况,可使用链表在已有数据的后面 继续存储新的数据。
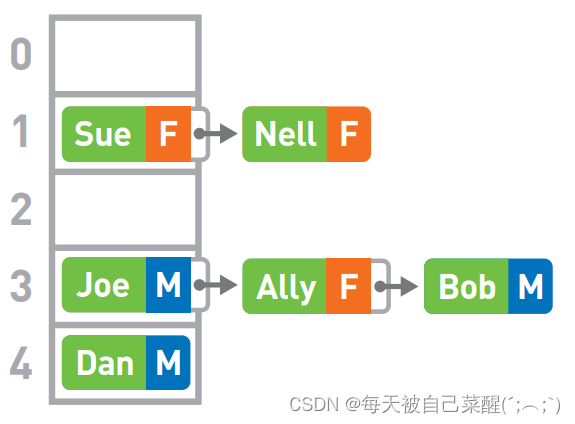
查询方法:
首先需要算出 字符串的键的哈希值,然后对其进行mod运算。若其中的数据的键与字符串 一致, 于是取出对应的值。
在哈希表中,我们可以利用哈希函数快速访问到数组中的目标数据。如果发生哈希 冲突,就使用链表进行存储。这样一来,不管数据量为多少,我们都能够灵活应对。 如果数组的空间太小,使用哈希表的时候就容易发生冲突,线性查找的使用频率也 会更高;反过来,如果数组的空间太大,就会出现很多空箱子,造成内存的浪费。因此, 给数组设定合适的空间非常重要。
六.堆
堆是一种图的树形结构,被用于实现“优先队列”。优先队列是一种数据结构,可以自由添加数据,但取出数据时要从最小值开始按顺序取出。在堆的树形结构中,各个顶点被称为“结点”(node),数据就存储在这些结点中。
结点内的数 字就是存储的数据。堆中的每 个结点最多有两个子结点。树 的形状取决于数据的个数。另 外,结点的排列顺序为从上到 下,同一行里则为从左到右。
在堆中存储数据时必须遵守这 样一条规则 :子结点必定大于父 结点。因此,最小值被存储在顶 端的根结点中。
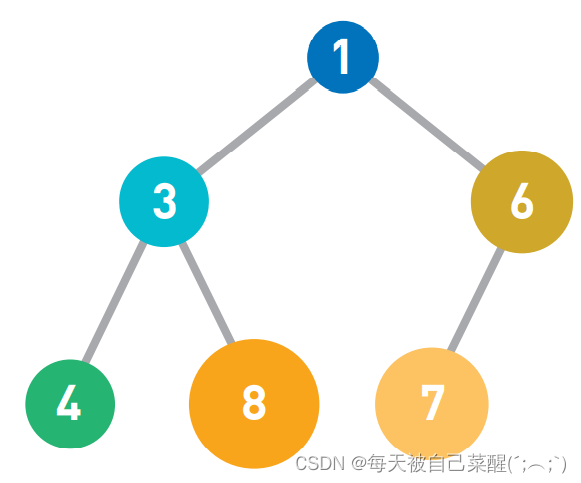
添加元素:
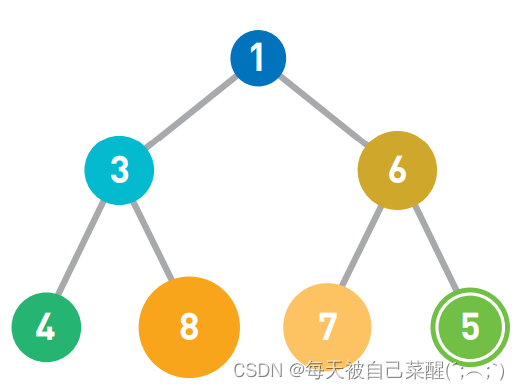
往堆中添加数据 时,为了遵守“子结点必定大于父 结点。”的规则,一般会 把新数据放在最下面一行靠左 的位置。当最下面一行里没有多 余空间时,就再往下另起一行, 把数据加在这一行的最左端。若要添加元素5。首先按照说明寻找新数据的位置。图中最 下面一排空着一个位置,所以将数据加在此处。
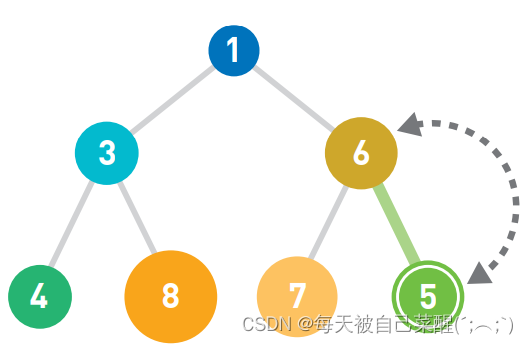
如果父结点大于子结点,则不符合上文提到的 规则,因此需要交换父子结点的位置。
7.二叉树
二叉查找树是一种数据结构,采用了图的树形结构 。数据存储于二叉查找树的各个结点中。
每个结点最多有 两个子结点。
二叉查找树有两个性质。第一个是每个结点的 值均大于其左子树上任意一个结点的值。第二个是每个结点的值均小于其右子树上任意 一个结点的值。
根据这两个性质可以得到以下结论。首先,二 叉查找树的最小结点要从顶端开始,往其左下 的末端寻找。反过来,二叉查找树的最大结点要从顶端开 始,往其右下的末端寻找。
添加元素(节点):
若添加元素1。首先,从二叉查找树的顶端结点开始寻找添加 数字的位置。将想要添 加的1与该结点中的值进行比较,小于它则往左移,大于它则往右移。
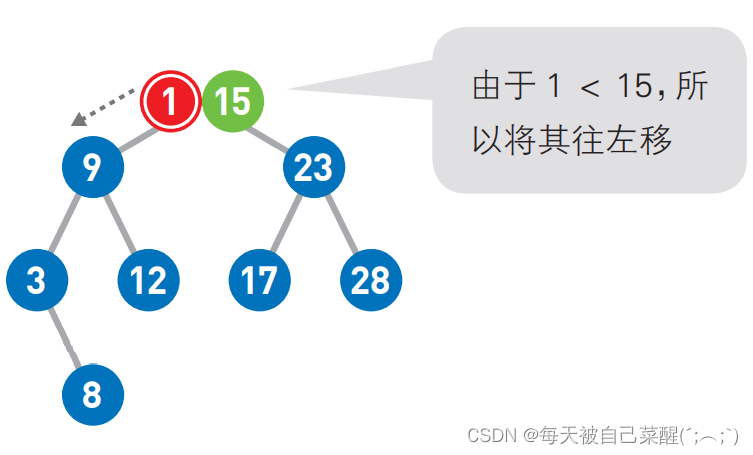
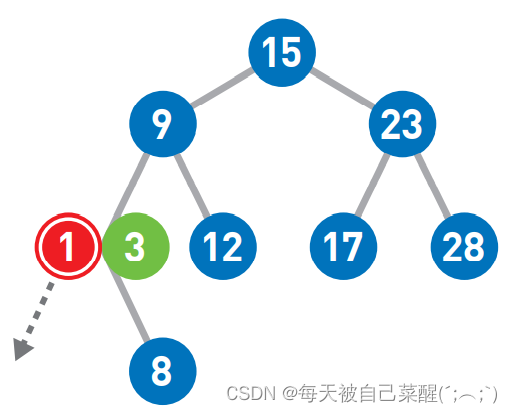
由于1<3,所以继续将1往左移,但前面已经没 有结点了,所以把 1 作为新结点添加到左下方。
删除元素(节点):
如果需要删除的结点没有子结点,直接删掉该 结点即可。如果需要删除的结点只有一个子结点,那么先 删掉目标结点,然后把子结点移到被删除结点的位置上即可。如果需要删除的结点有两个子结点,那么先删掉目标结点,然后在被删除结点的左子树中寻找最大结点。最后将最大结点移到被删除结点的位置上。这样一来,就能在满足二叉查找树性质的前提下删除结点了。 如果需要移动的结点还有子结点,就递归执行前面的操作。
查找元素(节点):
从二叉查找树的顶端结点开始往下查找。和添 加数据时一样,把目标值和结点中的值进行比较, 小于该结点的值则往左移,大于则往右移。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









