






论文:《ESimCSE: Enhanced Sample Building Method for Contrastive Learning of Unsupervised Sentence Embedding》
研究背景
- 研究问题:这篇文章要解决的问题是如何改进无监督句子嵌入的学习方法,特别是针对现有方法中由于句子长度信息导致的偏差问题。
- 研究难点:该问题的研究难点包括:如何在不改变句子语义的情况下调整句子长度,以及如何有效地扩展负样本数量以提高模型性能。
- 相关工作:该问题的研究相关工作有:使用对比学习进行无监督句子嵌入学习的方法(如SimCSE),以及其他数据增强方法(如随机插入和删除)。
研究方法
这篇论文提出了Enhanced SimCSE(ESimCSE)用于解决无监督句子嵌入学习中存在的长度偏差问题。具体来说,
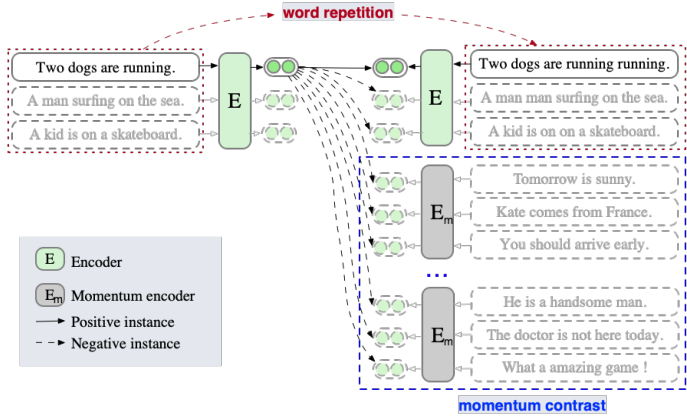
- 正样本构建:首先,提出了一种简单的“词重复”方法来调整句子长度,而不改变其语义。具体操作是从子词序列中随机选择一些子词进行重复。公式如下:
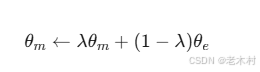
- 负样本扩展:其次,引入了动量对比(momentum contrast)方法来扩展负样本数量。通过维护一个固定大小的队列,队列中的嵌入逐步替换,从而在不增加计算开销的情况下扩展负样本。公式如下:θm←λθm+(1−λ)θe其中,θm是动量更新的编码器参数,θe是原始编码器参数,λ是动量系数。
- 损失函数:最后,修改了对比学习的损失函数,将动量更新队列中的嵌入也纳入负样本
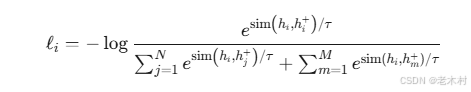 其中,hm+是动量更新队列中的句子嵌入,M是队列的大小。
其中,hm+是动量更新队列中的句子嵌入,M是队列的大小。
实验设计
- 数据收集:实验语言为英语,训练数据从英文维基百科中随机抽取100万句。评估数据来自七个标准的语义文本相似性(STS)数据集(STS12-STS16)。
- 实验设置:实验主要遵循SimCSE的设置,使用BERT(基础版和大版本)和RoBERTa(基础版和大版本)作为预训练模型。在[CLS]表示上添加一个MLP层以获取句子嵌入。
- 训练细节:使用Adam优化器,批量大小为64,温度参数τ=0.05。学习率设置为3e-5(ESimCSE-BERTbase)和1e-5(其他模型)。dropout率为0.1(基础模型)和0.15(大模型)。动量对比中选择较大的动量系数λ。
- 评估方法:使用Spearman相关系数评估模型性能,并在STS-B的开发集上每125个训练步骤评估一次,最终保留最佳检查点进行评估。
结果与分析
-
主要结果:在七个STS测试集上,ESimCSE在不同模型设置下均优于SimCSE。具体来说,ESimCSE在BERTbase上平均提高了Spearman相关系数2.02%。
-
消融研究:单独使用词重复或动量对比都能显著提升SimCSE的性能,且这两种方法可以叠加使用(ESimCSE)以获得进一步改进。
-
句子长度扩展方法:子词重复效果最佳,词重复也带来了良好的改进。插入[MASK]也有轻微提升,但插入停用词会降低效果。
-
训练句子长度分组:按长度分组训练并未带来显著改进,甚至在某些设置下有所下降。
-
相似性与长度差异的关系:ESimCSE显著减少了>3和≤3的句子对之间的平均相似性差异差距,从1.84降至0.71,缓解了学习偏差。
-
词重复引入新偏差:词重复不会给学习过程引入新的偏差,与SimCSE相比,ESimCSE的相似性增加仅为0.05。
-
超参数影响:重复率在0.32时,ESimCSE性能最佳;动量对比队列大小在2.5倍批量大小时效果最佳。
-
迁移任务:与SimCSE相比,ESimCSE在迁移任务上的表现略有提升,保持相对稳定。
总体结论
本文提出了两种优化方法来改进SimCSE的正负样本构建,并将其与SimCSE结合,形成了Enhanced SimCSE(ESimCSE)。通过广泛的实验,证明了所提出的优化方法在不同标准语义文本相似性任务上显著提升了SimCSE的性能。未来的工作将集中在设计更精细的目标函数以改善不同负样本之间的区分度,并尝试优化在语义文本相似性任务和迁移任务上的性能。
论文评价
优点与创新
- 观察到的正对构建偏差:论文观察到SimCSE在构建正对时使用了相同长度的句子,这会导致学习过程的偏差。提出的“词重复”方法可以有效地缓解这一问题。
- 动量对比方法的引入:为了增加负对的数量,论文提出了使用动量对比方法,这样可以在不增加额外计算的情况下扩大负对的规模,从而鼓励模型进行更精细的学习。
- 广泛的实验验证:论文在多个基准数据集上进行了广泛的实验,结果表明所提出的优化方法相比SimCSE有显著的提升。
- 改进的句子嵌入方法:通过结合“词重复”和动量对比方法,提出了增强的句子嵌入方法(ESimCSE),并在语义文本相似性任务中取得了显著的性能提升。
关键问题及回答
问题1:ESimCSE是如何解决由于句子长度信息导致的偏差问题的?
ESimCSE通过两种方法来解决由于句子长度信息导致的偏差问题:
-
词重复(Word Repetition):这种方法通过随机重复句子中的一些词或子词来调整句子长度,而不改变其语义。具体操作是从子词序列中随机选择一些子词进行重复,公式如下:
\text{dup_set}=\operatorname{uniform}([1, N],\text{ num}=\text{ dup_len})其中,dup_len是随机选择的重复子词数量,dup_rate是最大重复率。这种方法能够保持句子的语义不变,同时增加句子长度的多样性。
-
动量对比(Momentum Contrast):为了扩展负样本数量,ESimCSE引入了动量对比方法。通过维护一个固定大小的队列,队列中的嵌入逐步替换,从而在不增加计算开销的情况下扩展负样本。公式如下:
θm←λθm+(1−λ)θe其中,θm是动量更新的编码器参数,θe是原始编码器参数,λ是动量系数。这种方法能够有效地增加负样本的数量,使模型在训练过程中接触到更多的负样本,从而提高模型的鲁棒性和性能。
问题2:在实验中,ESimCSE在不同模型设置下的表现如何?
ESimCSE在不同模型设置下均优于现有的SimCSE方法。具体来说,在七个语义文本相似性(STS)测试集上,ESimCSE在不同模型设置下均取得了显著的提升。例如,在BERTbase模型上,ESimCSE平均提高了Spearman相关系数2.02%。此外,ESimCSE在BERTlarge、RoBERTabase和RoBERTalarge模型上也分别取得了0.90%、0.87%和0.55%的提升。这些结果表明,ESimCSE在不同预训练模型上的泛化能力较强,能够有效提升无监督句子嵌入的质量。
问题3:ESimCSE在消融研究中验证了其优化方法的有效性吗?
是的,ESimCSE在消融研究中验证了其优化方法的有效性。具体来说,消融研究探讨了单独使用词重复或动量对比对SimCSE性能的提升效果,结果显示这两种方法都能显著提升SimCSE的性能。此外,消融研究还表明,这两种优化方法可以叠加使用(即ESimCSE),以获得进一步的性能提升。这表明ESimCSE的综合优化策略在解决句子长度偏差问题上具有显著效果。
代码复现数据集用的蚂蚁的语义匹配数据集,示例如下

完整代码奉上:
import copy
from tqdm import tqdm
import torch.nn as nn
import numpy as np
from torch.utils.data import DataLoader, Dataset
import os
import json
import random
import torch
import pandas as pd
from transformers import BertTokenizer, BertModel, BertConfig
from torch.nn.utils.rnn import pad_sequence
import torch.nn.functional as F
from transformers.modeling_outputs import SequenceClassifierOutput
from sklearn.metrics import f1_score, accuracy_score, recall_score
class CFG:
model_path = "D:\\Users\\stkj\\PycharmProjects\\pythonProject\\nlp\\self_text_classfication\\model_weight\\roberta_data"
data_path = os.path.join("..", "data", "ants")
test_data_path = os.path.join("..", "data", "ants", "test.json")
learn_rate = 1e-5
epochs = 1000
max_len = 510
batch_size = 32
device = "cuda"
print_step = 50
save_path = os.path.join("..", "model_weith", "roberta_esimcse.bin")
throshold = 0.6
data_save_path = os.path.join("..", "data", "ants", "output_esimcse.csv")
qeuee_len = batch_size*32
sita = 0.99
def seed_everything(seed=42):
"""
固定各种库的随机种子,保证模型效果可以复现(random、pandas、numpy)
:param seed:
:return:
"""
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
def word_repetion(sentence,repu_rate=0.4):
"""
利用单词重复的办法生成正例
:param sentence:
:param repu_rate:
:return:
"""
import random
max_len = len(sentence)
sentence = list(sentence)
repu_len = max(2,int(repu_rate*max_len))
repetion_len = min(random.choice(range(repu_len+1)),max_len)
repetion_index = random.sample(range(max_len),repetion_len)
res=[]
for index,word in enumerate(sentence):
res.append(word)
if index in repetion_index:
res.append(word)
return "".join(res)
class EsimcseDataSet(Dataset):
def __init__(self, sentence_a, sentence_b, labels, tokenizer, mode="train"):
self.sentence_a = sentence_a
self.sentence_b = sentence_b
self.labels = labels
self.tokenizer = tokenizer
self.pad_token = tokenizer.pad_token
self.mode = mode
self.pad_token_id = tokenizer.pad_token_id
self.sentence = np.concatenate((sentence_a, sentence_b), axis=0)
def __len__(self):
if self.mode == "train":
return len(self.sentence)
assert len(self.sentence_b) == len(self.sentence_b) == len(self.labels), "数据长度不一样,玩个锤子!!!"
return len(self.sentence_b)
def __getitem__(self, index):
if self.mode == "dev":
sentence_a = self.sentence_a[index]
sentence_b = self.sentence_b[index]
input_a = self.tokenizer(sentence_a, truncation=True, max_length=CFG.max_len)
input_b = self.tokenizer(sentence_b, truncation=True, max_length=CFG.max_len)
return {
"input_ids_a": torch.as_tensor(input_a["input_ids"], dtype=torch.long),
"input_ids_b": torch.as_tensor(input_b["input_ids"], dtype=torch.long),
"attention_mask_a": torch.as_tensor(input_a["attention_mask"], dtype=torch.long),
"attention_mask_b": torch.as_tensor(input_b["attention_mask"], dtype=torch.long),
"label": torch.as_tensor(int(self.labels[index]), dtype=torch.long)
}
senten_source = self.sentence[index]
items1 = self.tokenizer(senten_source, truncation=True, max_length=CFG.max_len)
senten_pos = word_repetion(senten_source)
items2 = self.tokenizer(senten_pos, truncation=True, max_length=CFG.max_len)
return {
"source_input_ids": torch.as_tensor(items1["input_ids"]),
"source_attention_mask": torch.as_tensor(items1["attention_mask"]),
"position_input_ids": torch.as_tensor(items2["input_ids"]),
"position_attention_mask": torch.as_tensor(items2["attention_mask"])
}
class TestDataSet(Dataset):
def __init__(self, sentence_a, sentence_b, tokenizer):
self.sentence_a = sentence_a
self.sentence_b = sentence_b
self.tokenizer = tokenizer
self.pad_token = tokenizer.pad_token
self.pad_token_id = tokenizer.pad_token_id
def __len__(self):
assert len(self.sentence_a) == len(self.sentence_b), "数据长度不一样,玩个锤子!!!"
return len(self.sentence_b)
def __getitem__(self, index):
sentence_a = self.sentence_a[index]
sentence_b = self.sentence_b[index]
input_a = self.tokenizer(sentence_a, truncation=True, max_length=CFG.max_len)
input_b = self.tokenizer(sentence_b, truncation=True, max_length=CFG.max_len)
return {
"input_ids_a": torch.as_tensor(input_a["input_ids"], dtype=torch.long),
"input_ids_b": torch.as_tensor(input_b["input_ids"], dtype=torch.long),
"attention_mask_a": torch.as_tensor(input_a["attention_mask"], dtype=torch.long),
"attention_mask_b": torch.as_tensor(input_b["attention_mask"], dtype=torch.long),
}
def collate_test_fn(self, batch):
input_ids_a = [item["input_ids_a"] for item in batch]
input_ids_b = [item["input_ids_b"] for item in batch]
attention_mask_a = [item["attention_mask_a"] for item in batch]
attention_mask_b = [item["attention_mask_b"] for item in batch]
input_ids_a = pad_sequence(input_ids_a, batch_first=True, padding_value=0.0)
input_ids_b = pad_sequence(input_ids_b, batch_first=True, padding_value=0.0)
attention_mask_a = pad_sequence(attention_mask_a, batch_first=True, padding_value=0.0)
attention_mask_b = pad_sequence(attention_mask_b, batch_first=True, padding_value=0.0)
return {
"input_ids_a": input_ids_a,
"input_ids_b": input_ids_b,
"attention_mask_a": attention_mask_a,
"attention_mask_b": attention_mask_b,
}
def collate_trian_fn(batch):
source_input_ids = [item["source_input_ids"] for item in batch]
source_attention_mask = [item["source_attention_mask"] for item in batch]
position_input_ids = [item["position_input_ids"] for item in batch]
position_attention_mask = [item["position_attention_mask"] for item in batch]
source_input_ids = pad_sequence(source_input_ids,batch_first=True,padding_value=0.0)
source_attention_mask = pad_sequence(source_attention_mask,batch_first=True,padding_value=0.0)
position_input_ids = pad_sequence(position_input_ids,batch_first=True,padding_value=0.0)
position_attention_mask = pad_sequence(position_attention_mask,batch_first=True,padding_value=0.0)
return {
"source_input_ids":source_input_ids,
"source_attention_mask":source_attention_mask,
"position_input_ids":position_input_ids,
"position_attention_mask":position_attention_mask
}
def collate_dev_fn(batch):
input_ids_a = [item["input_ids_a"] for item in batch]
input_ids_b = [item["input_ids_b"] for item in batch]
attention_mask_a = [item["attention_mask_a"] for item in batch]
attention_mask_b = [item["attention_mask_b"] for item in batch]
labels = [item["label"] for item in batch]
input_ids_a = pad_sequence(input_ids_a, batch_first=True, padding_value=0.0)
input_ids_b = pad_sequence(input_ids_b, batch_first=True, padding_value=0.0)
attention_mask_a = pad_sequence(attention_mask_a, batch_first=True, padding_value=0.0)
attention_mask_b = pad_sequence(attention_mask_b, batch_first=True, padding_value=0.0)
labels = torch.as_tensor(labels, dtype=torch.long)
return {
"input_ids_a": input_ids_a,
"input_ids_b": input_ids_b,
"attention_mask_a": attention_mask_a,
"attention_mask_b": attention_mask_b,
"labels": labels,
}
def get_loader():
tokenizer = BertTokenizer.from_pretrained(CFG.model_path)
trian_sentence_a, trian_sentence_b, train_labels = read_data(f"{CFG.data_path}\\train.json")
dev_sentence_a, dev_sentence_b, dev_labels = read_data(f"{CFG.data_path}\\dev.json")
train_set = EsimcseDataSet(trian_sentence_a, trian_sentence_b, train_labels, tokenizer, mode="train")
dev_set = EsimcseDataSet(dev_sentence_a, dev_sentence_b, dev_labels, tokenizer, mode="dev")
train_loder = DataLoader(train_set, batch_size=CFG.batch_size, collate_fn=collate_trian_fn, shuffle=True)
dev_loder = DataLoader(dev_set, batch_size=CFG.batch_size, collate_fn=collate_dev_fn, shuffle=True)
return train_loder, dev_loder
class MeanPoling(nn.Module):
def __init__(self):
super().__init__()
pass
def forward(self, embed, attention_mask):
attention_mask_copy = attention_mask.unsqueeze(-1).expand(embed.size()).float()
embed = embed * attention_mask_copy
sum_sql_emb = torch.sum(embed, dim=-2)
sum_sql_attetion = torch.sum(attention_mask_copy, dim=-2)
sum_sql_attetion = torch.clamp(sum_sql_attetion, min=1e-8)
return sum_sql_emb / sum_sql_attetion
def cal_esimcse_loss(embed_source,position_source,qeuee,tao=0.05):
N, C = embed_source.shape[0],embed_source.shape[1]
embed_source = F.normalize(embed_source,dim=1)
position_source = F.normalize(position_source,dim=1)
qeuee = F.normalize(qeuee,dim=-1)
fenzi = torch.exp(torch.div(torch.bmm(embed_source.view(N,1,C),position_source.view(N,C,1)).view(N,1),tao)) #bmm:一对一
fenmu_one = torch.sum(torch.exp(torch.div(torch.mm(embed_source.view(N,C) , torch.t(position_source.view(N,C))),tao)),dim=-1) #mm:一对多
fenmu_two = torch.sum(torch.exp(torch.div(torch.mm(embed_source , torch.t(qeuee)),tao)),dim=-1)
loss = torch.mean(-torch.log(torch.div(fenzi,(fenmu_two+fenmu_one))))
return loss
def get_qeuee(key_model,trian_loader,queeue_num=CFG.qeuee_len,device = CFG.device):
"""
把key_embed,当作负例填充到队列中,错位填充的目的是防止sentenc_embed的负例是他本身,这显然是不科学的
:param key_model: 生成负例的embedding的模型
:param trian_loader: 训练集的dataloader
:param queeue_num: 队列的长度
:return: 返回生成的embeddding队列
"""
for para in key_model.parameters():
para.requires_grad=False
key_model.eval()
key_model.to(device)
queuee = None
while True:
for index,item in enumerate(trian_loader):
if index<15:
continue
source_input_ids = item["source_input_ids"].to(device)
source_attention_mask = item["source_attention_mask"].to(device)
position_input_ids = item["position_input_ids"].to(device)
position_attention_mask = item["position_attention_mask"].to(device)
embed_query = key_model.cal_sentence_emb(source_input_ids,source_attention_mask)
if queuee == None:
queuee = embed_query
else:
if len(queuee)<=queeue_num:
queuee = torch.cat((queuee,embed_query),dim=0)
else:
break
if len(queuee) > queeue_num:
break
# key_model.to("cpu")
return queuee[-queeue_num:]
class ESimcse(nn.Module):
def __init__(self):
super().__init__()
config = BertConfig.from_pretrained(CFG.model_path)
config.output_hidden_states = True
config.attention_probs_dropout_prob=0.3
config.hidden_dropout_prob=0.3
self.bert = BertModel.from_pretrained(CFG.model_path, config=config)
self.pooling = MeanPoling()
def forward(self, input_ids_1, attention_mask_1,input_ids_2, attention_mask_2,queuee=None,mode="dev"):
embed_source = self.cal_sentence_emb(input_ids_1,attention_mask_1)
position_source = self.cal_sentence_emb(input_ids_2,attention_mask_2)
return SequenceClassifierOutput(logits = (embed_source,position_source),
loss=None) if mode == "dev" else SequenceClassifierOutput(logits = (embed_source,position_source),
loss=cal_esimcse_loss(
embed_source,position_source,queuee))
def cal_sentence_emb(self,input_ids, attention_mask):
last_hidden_state = self.bert(input_ids, attention_mask).hidden_states[-1]
sentence_embed = self.pooling(last_hidden_state, attention_mask)
return sentence_embed
def get_metric(pres, labels):
return f1_score(labels, pres), accuracy_score(labels, pres), recall_score(labels, pres)
def train_fn(query_model, train_loader, optimizer, epoch,queuee,key_model,sita=CFG.sita):
query_model.train()
for index, item in tqdm(enumerate(train_loader), total=len(train_loader), desc="单论训练进度:"):
source_input_ids = item["source_input_ids"].to(CFG.device)
source_attention_mask = item["source_attention_mask"].to(CFG.device)
position_input_ids = item["position_input_ids"].to(CFG.device)
position_attention_mask = item["position_attention_mask"].to(CFG.device)
out = query_model(source_input_ids, source_attention_mask,position_input_ids, position_attention_mask,queuee, mode="trian")
query_embed, key_embed = out.logits
loss = out.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
#更新队列,使用detach消除队列的梯度信息,因为我们是手动维护这个队列所以不需要梯度信息
queuee = torch.cat((queuee,query_embed),dim=0)[-CFG.qeuee_len:].detach()
# 手动更新key_model,保险起见,在此冻结key_model的参数,我们手动使用动量更新key_model的参数
for q_para,k_para in zip(query_model.parameters(),key_model.parameters()):
k_para.data.copy_(sita*k_para.data+(1-sita)*q_para.data)
k_para.requires_grad = False
if (index + 1) % CFG.print_step == 0 or index == len(train_loader) - 1:
print(f"epoch:{epoch} step:{index} loss:{loss.item():.6f}")
def dev_fn(model, dev_loader, epoch):
model.eval()
prediction, labels = [], []
with torch.no_grad():
for index, item in tqdm(enumerate(dev_loader), total=len(dev_loader), desc="单论训练进度:"):
input_ids_a = item["input_ids_a"].to(CFG.device)
input_ids_b = item["input_ids_b"].to(CFG.device)
attention_mask_a = item["attention_mask_a"].to(CFG.device)
attention_mask_b = item["attention_mask_b"].to(CFG.device)
label = item["labels"]
emb_a,emb_b = model(input_ids_a, attention_mask_a,input_ids_b,attention_mask_b, mode="dev").logits
pre = F.cosine_similarity(emb_a, emb_b, dim=-1)
pre = (pre > CFG.throshold).long().detach().cpu().numpy()
label = label.detach().cpu().numpy()
prediction.extend(pre)
labels.extend(label)
f1, acc, rec = get_metric(prediction, labels)
print(f"epoch:{epoch} f1:{f1:.4f} acc:{acc:.6f} rec:{rec:.4f}")
return f1, acc, rec
def read_data(path, num=None):
datas = []
with open(path, "r", encoding="utf-8") as f:
for line in f:
data = json.loads(line)
datas.append(data)
f.close()
datas = pd.DataFrame(datas)
sentence_a, sentence_b, labels = datas["sentence1"].values, datas["sentence2"].values, datas["label"].values
assert len(sentence_a) == len(sentence_b) == len(labels)
return (sentence_a[:num], sentence_b[:num], labels[:num]) if num else (sentence_a, sentence_b, labels)
def train_loop():
train_loader, dev_loader = get_loader()
query_model = ESimcse().to(CFG.device)
key_model = copy.deepcopy(query_model)
key_model.eval()
for para in key_model.parameters():
para.requires_grad=False
optimizer = torch.optim.Adam(query_model.parameters(), lr=CFG.learn_rate)
best_acc = 0
for epoch in range(CFG.epochs):
queuee = get_qeuee(key_model, train_loader)
print(f"总训练进度:{epoch + 1}/{CFG.epochs}")
train_fn(query_model, train_loader, optimizer, epoch,queuee,key_model)
f1, acc, rec = dev_fn(query_model, dev_loader, epoch)
if acc > best_acc:
best_acc = acc
torch.save(query_model.state_dict(), CFG.save_path)
print("training endding!!!")
def read_test_data(test_path):
datas = []
with open(test_path, "r", encoding="utf-8") as f:
for line in f:
data = json.loads(line)
datas.append(data)
f.close()
datas = pd.DataFrame(datas)
sentence_a, sentence_b = datas["sentence1"].values, datas["sentence2"].values
assert len(sentence_a) == len(sentence_b)
return datas, sentence_a, sentence_b
def infer_fn():
tokenizer = BertTokenizer.from_pretrained(CFG.model_path)
pd_data, test_sentence_a, test_sentence_b = read_test_data(CFG.test_data_path)
test_set = TestDataSet(test_sentence_a, test_sentence_b, tokenizer)
test_loder = DataLoader(test_set, batch_size=CFG.batch_size, collate_fn=test_set.collate_test_fn, shuffle=True)
model = ESimcse().to(CFG.device)
model.load_state_dict(torch.load(CFG.save_path, map_location="cuda"))
model.eval()
prediction = []
with torch.no_grad():
for index, item in tqdm(enumerate(test_loder), total=len(test_loder), desc="单论训练进度:"):
input_ids_a = item["input_ids_a"].to(CFG.device)
input_ids_b = item["input_ids_b"].to(CFG.device)
attention_mask_a = item["attention_mask_a"].to(CFG.device)
attention_mask_b = item["attention_mask_b"].to(CFG.device)
emb_a, emb_b = model(input_ids_a, attention_mask_a,input_ids_b,attention_mask_b, mode="dev").logits
pre = F.cosine_similarity(emb_a, emb_b, dim=-1)
pre = (pre > CFG.throshold).long().detach().cpu().numpy()
prediction.extend(pre)
pd_data["label"] = prediction
pd_data.to_csv(CFG.data_save_path, index=False)
pass
if __name__ == '__main__':
seed_everything()
train_loop()
infer_fn()

















 778
778

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









