






一、环境配置
作者在docker环境中实现的,为避免莫名其妙的问题,就照做喽,不在docker中的没提供也没试,不知道行不行

-
1. Docker
1. 官网Install Docker Engine | Docker Docs
在官网上用packages 安装的,选择对应的操作系统
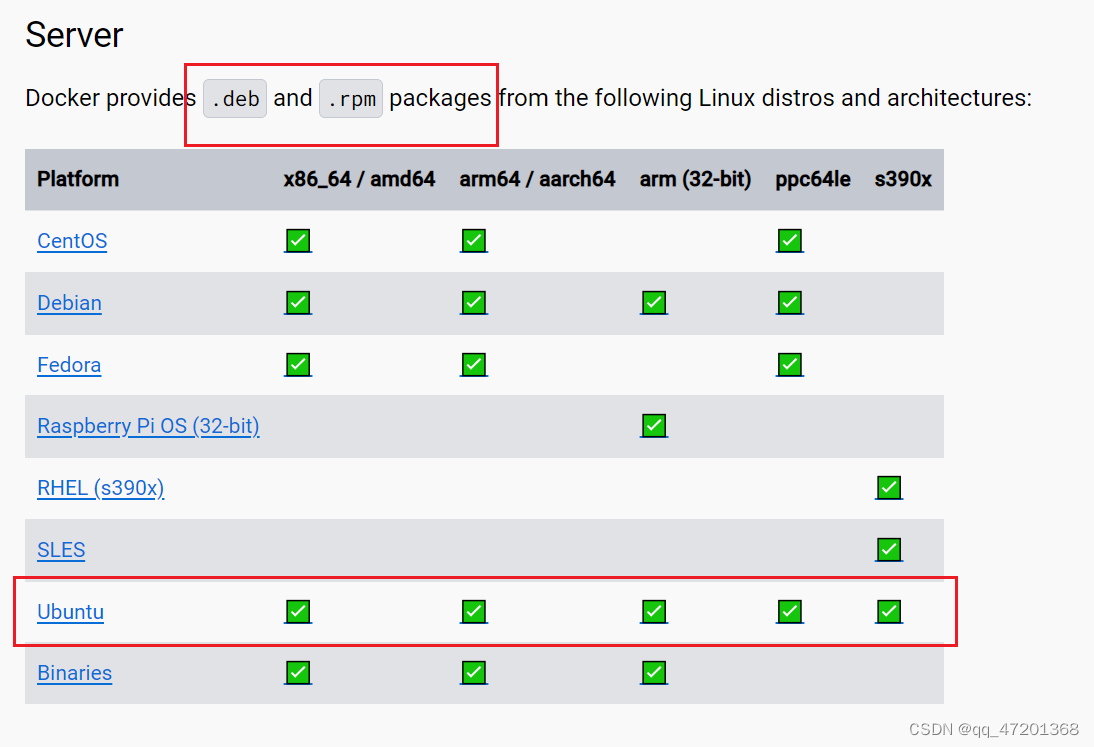
2. 清除历史版本,本人第一次安装,跳过

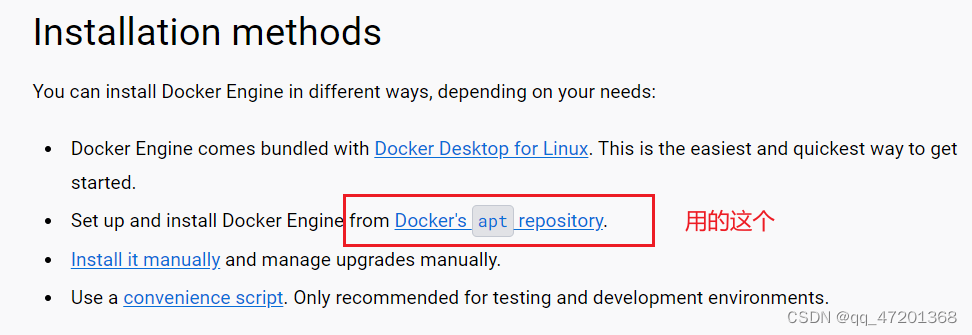
3. 安装方法
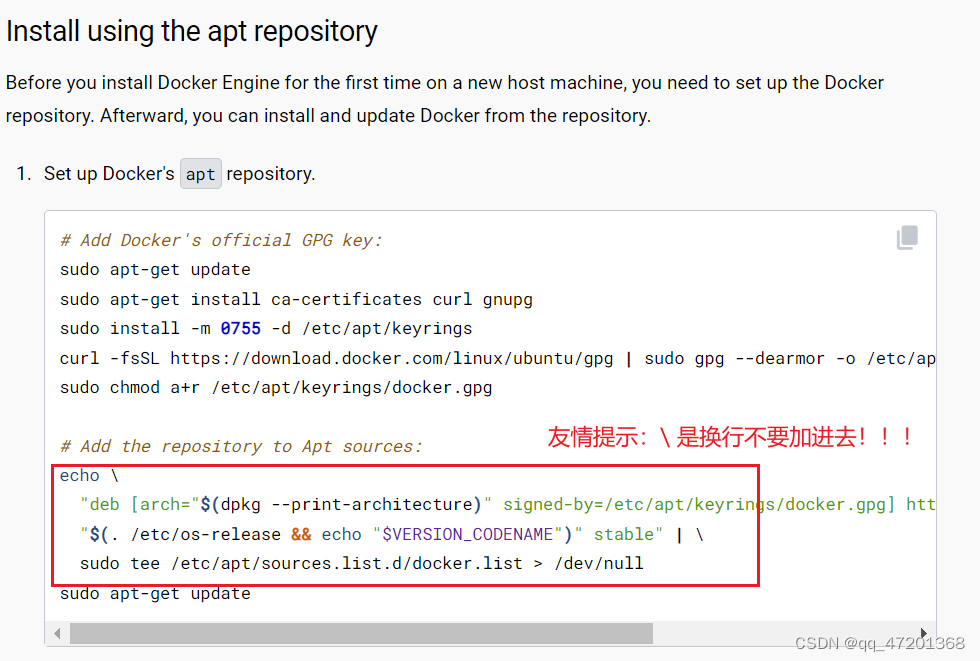
4. 开始安装,按照官网一步步来就行
-
2. nvidia-docker2
https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html
按这个一步步来,没啥大问题
二、创建Docker
1. 创建容器
出现的错误
1. 权限问题

- 可以进入build.sh,在docker build -t前加上sudo,但是后面每次运行docker命令都需要sudo,且连接docker是也会显示没有权限,因此采用下面的方法一劳永逸
- 将用户加入docker group中,还没有权限,可以重启更新一下
sudo groupadd docker
sudo usermod -aG docker $USER
newgrp docker
2. rosdep init && rosdep update失败
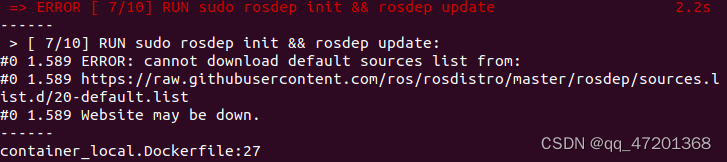
- 手动更新
sudo apt-get install python-pip
sudo pip install rosdepc
sudo rosdepc init
rosdepc update
- 打开container_local.Dockerfile文件,把rosdep init && rosdep update这一行注释掉,重新跑一下 ./build.sh
2. 运行docker

三、 VScode 连接本地docker
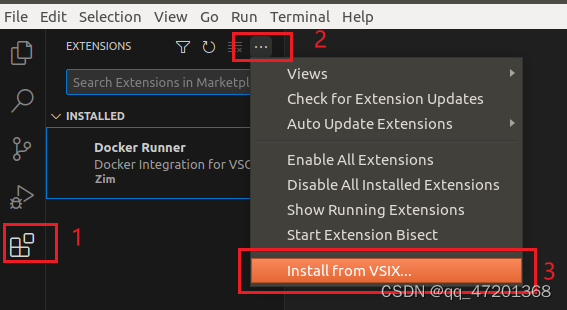
1. 安装扩展
服务器上的vscode没法直接安装扩展,报XHR ERROR,选择了手动安装,也挺简单的
- 官网上下载需要的扩展:DockerExtensions for Visual Studio family of products | Visual Studio Marketplace
- 按下图在vscode内安装
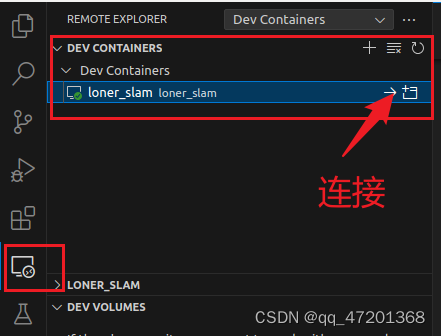
- 重启一下
四、下载数据
FusionPortable - FusionPortable Research
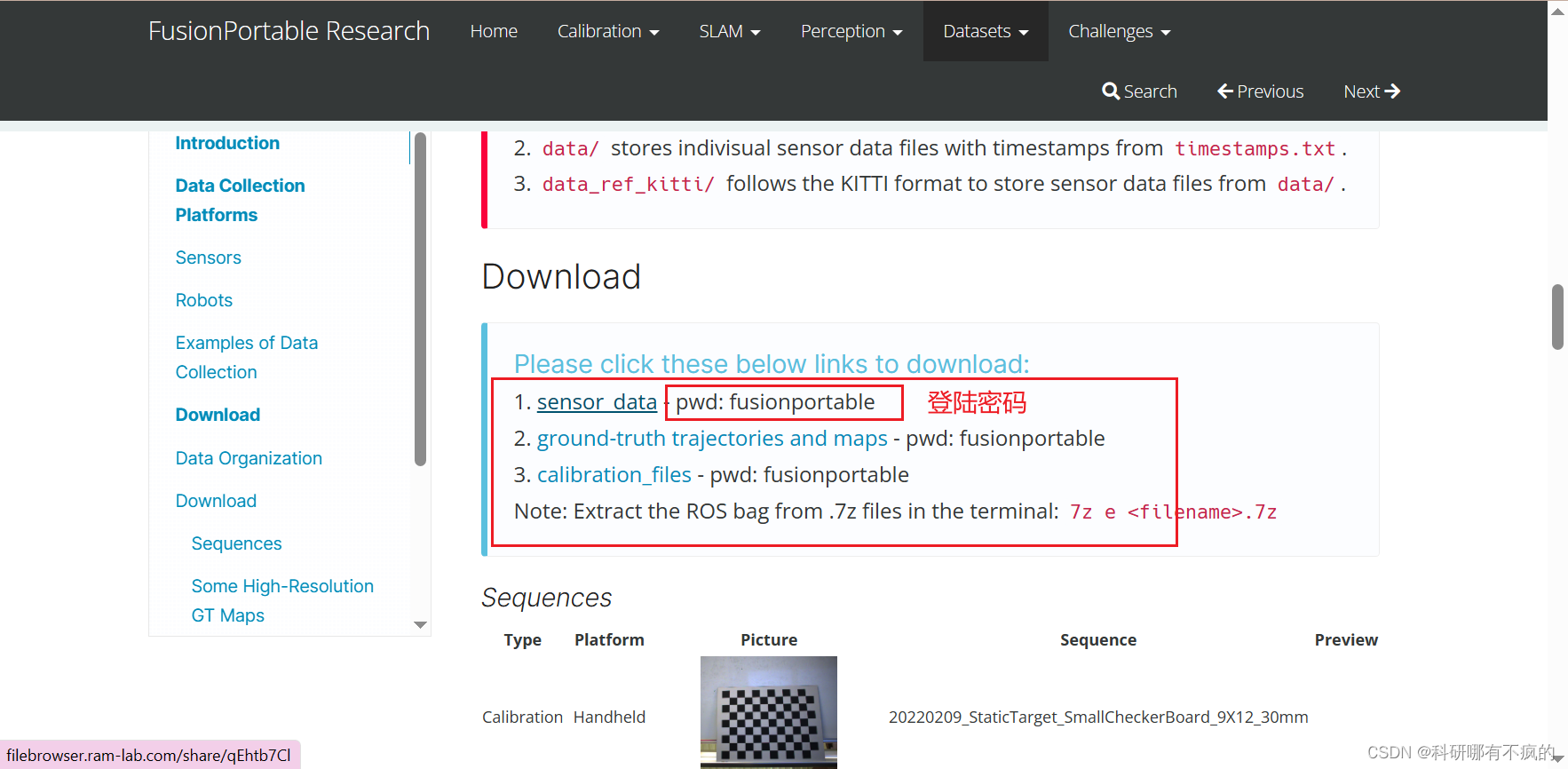
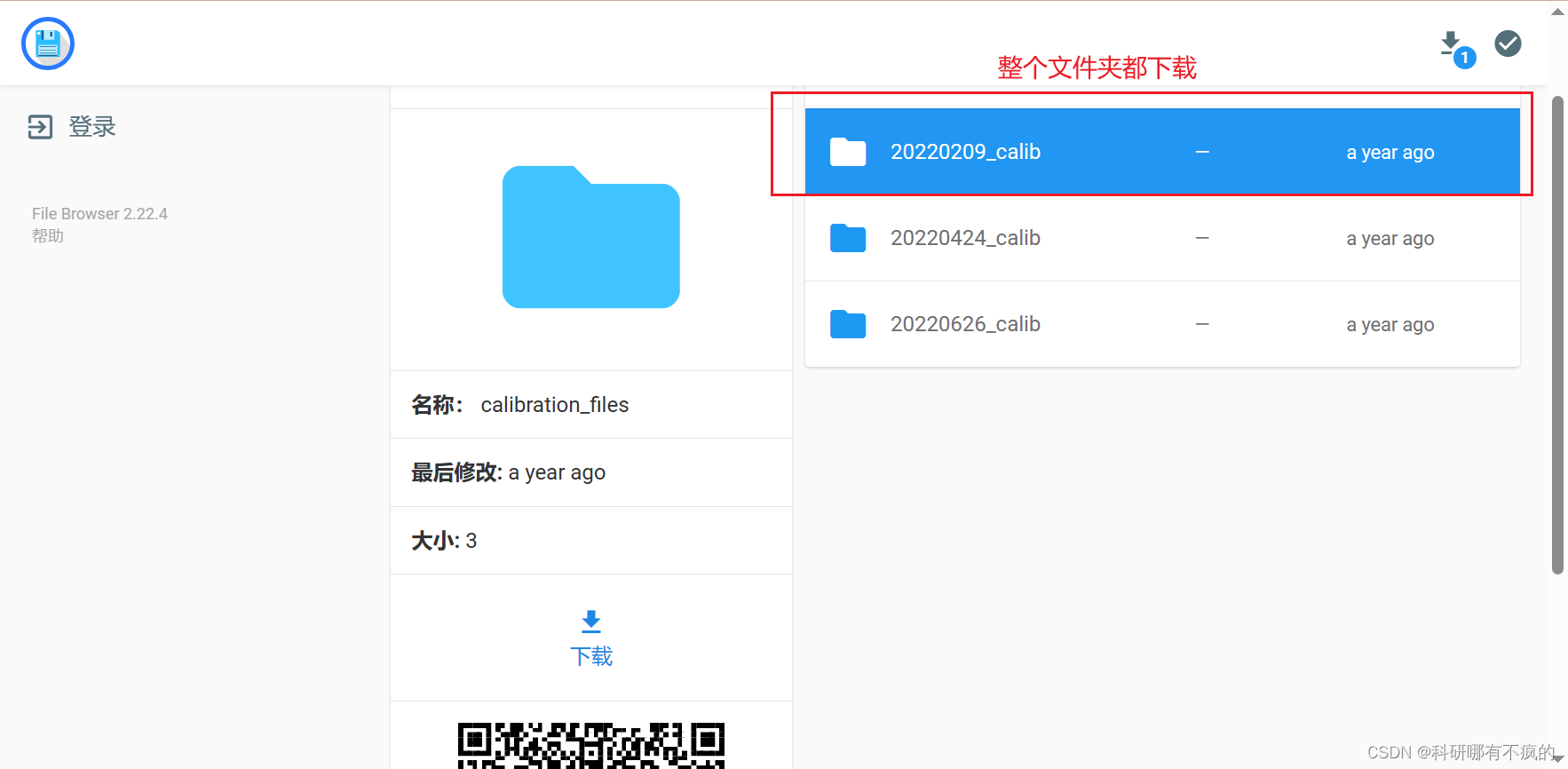
- 图中三类文件都需要下载,点进去需要密码,这边也给出了,作者跑了这些数据

- 每个里面都有很多组数据,选择你需要的下载就行,标定文件只有一组,我只下载了20220216_canteen_day这组数据,具体下什么可以看源码里面的配置文件
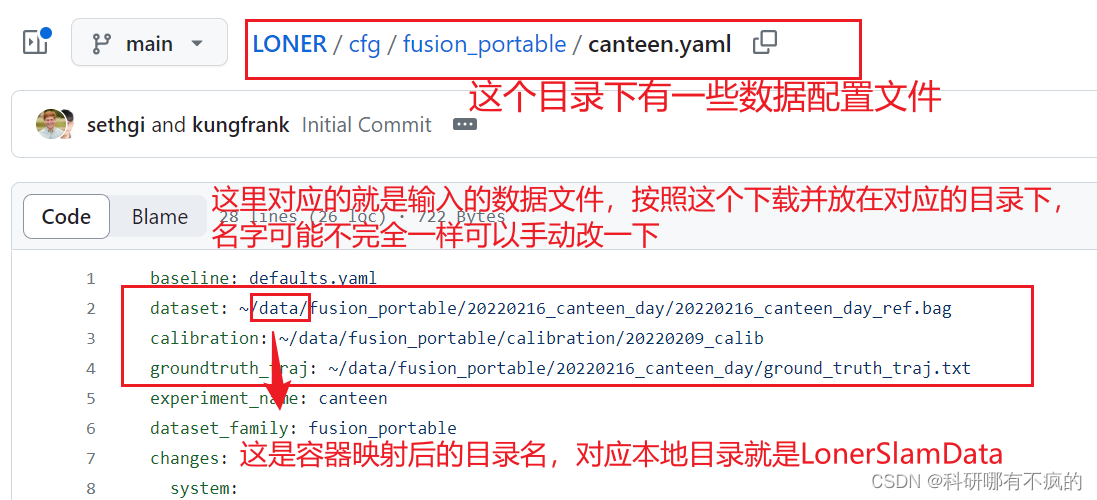
- sensor data
- ground truth
- calibration
五、开始运行
又又又出错啦,gpu算力太低了,pytorch不支持,NVS 510算力太低了
- 方案一:重装对应的环境,版本之间的关系大概是:显卡型号决定算力多少,查看显卡支持的驱动版本及对应的cuda版本,根据安装cuda版本选择pytorch版本
- 方案二:如果有多块gpu,指定使用更高的gpu进行计算
- 下面是出现过的问题以及对应解决方案
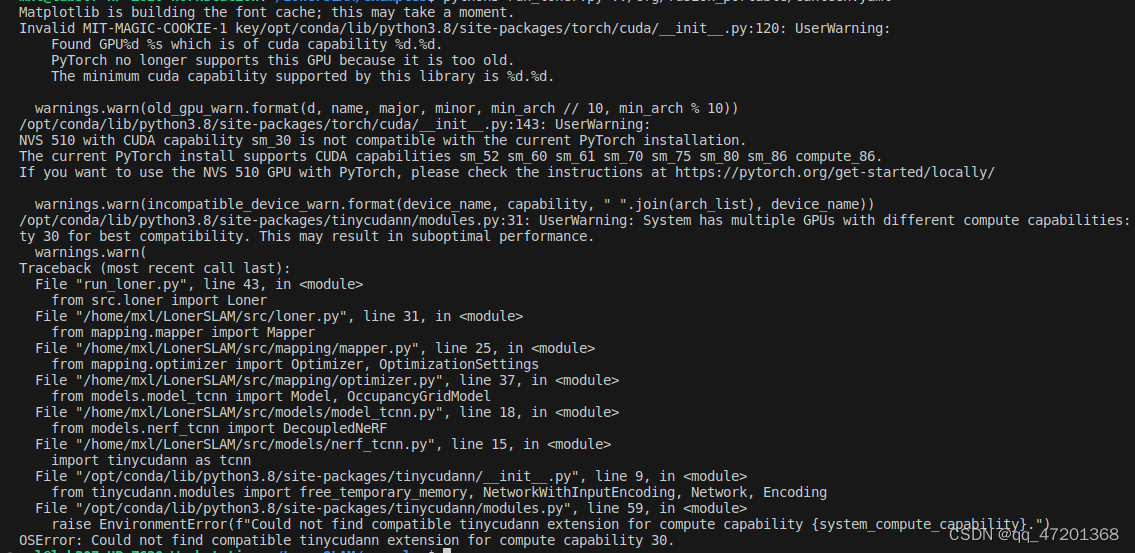
尝试重新装cuda11.8(这块尝试好像没能帮我解决问题可以先跳过)
- 安装显卡驱动
- 安装命令 sudo apt install nvidia-driver-535
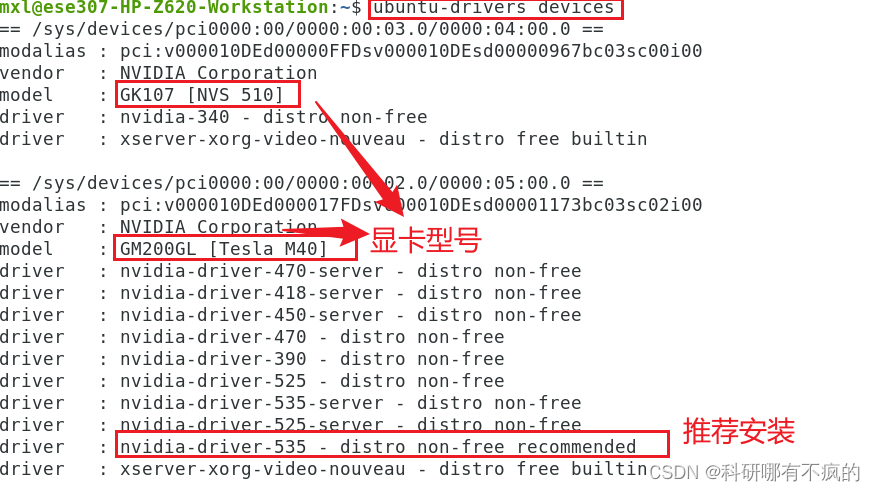
- 查看GPU对应的算力 CUDA GPUs - Compute Capability | NVIDIA Developer
- CUDA官网 CUDA Toolkit Archive | NVIDIA Developer
- 之前装过cuda,卸载参考ubuntu完全卸载CUDA_ubuntu卸载cuda和cudnn-CSDN博客
- 安装参考Ubuntu18.04安装CUDA+cuDNN+Pytorch_ubuntu18.04+cuda+cudnn+pytorch-CSDN博客
报错啦
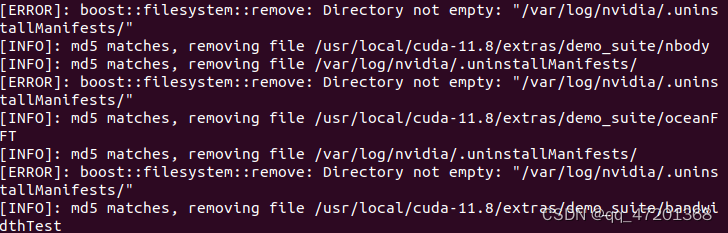
-
查了一下说在后面加上路径 --librarypath=/usr/local/cuda-11.8,但是还是报错
- 在安装的时候会跳出来 Existing installation of CUDA Toolkit 11.8 found 选择了第二个选项(好像是部分更新),然后后面又跳出来了一个类似的选择,也选择了第二个(更新,后面的也都更新),然后安装成功
- 配置环境变量,等号前后不要加空格
echo 'export PATH=/usr/local/cuda-11.8/bin:$PATH' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/local/cuda-11.8/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc
source ~/.bashrc
安装cudnn deb包安装
运行第五步的时候可能会报错找不到对应的包,有可能是cuda版本不对应,可以去deb包里面control相关的文件中找到对应的版本
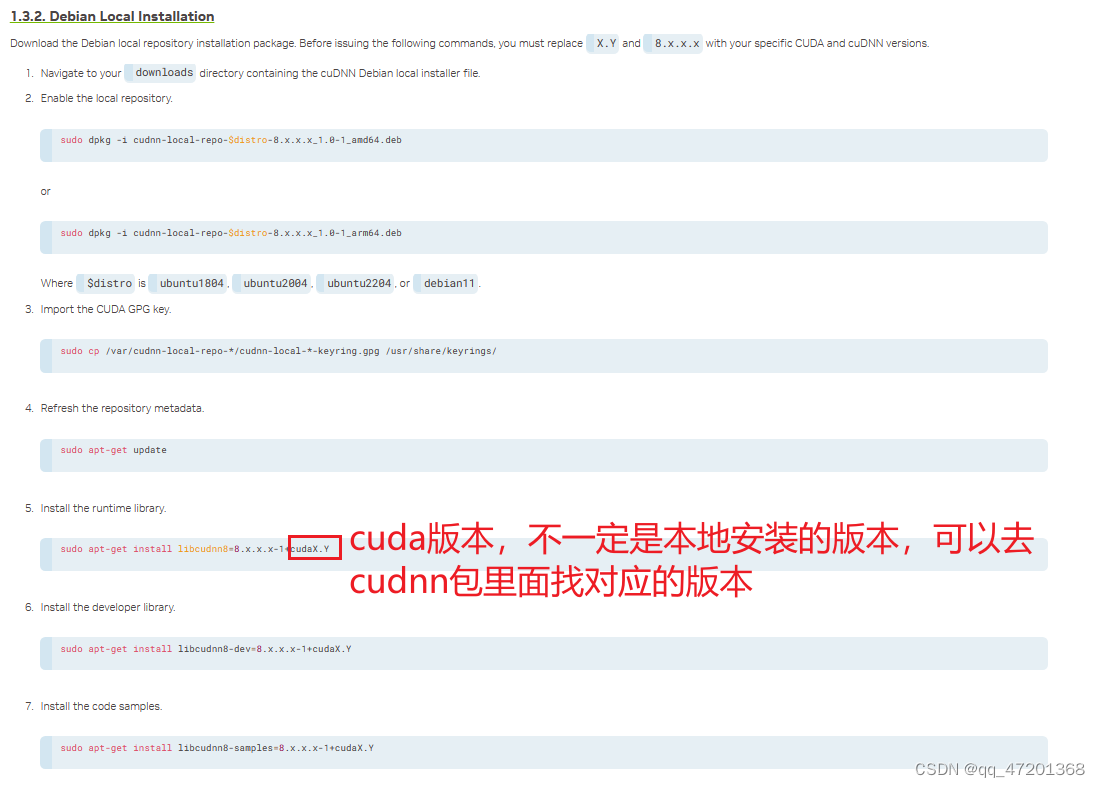
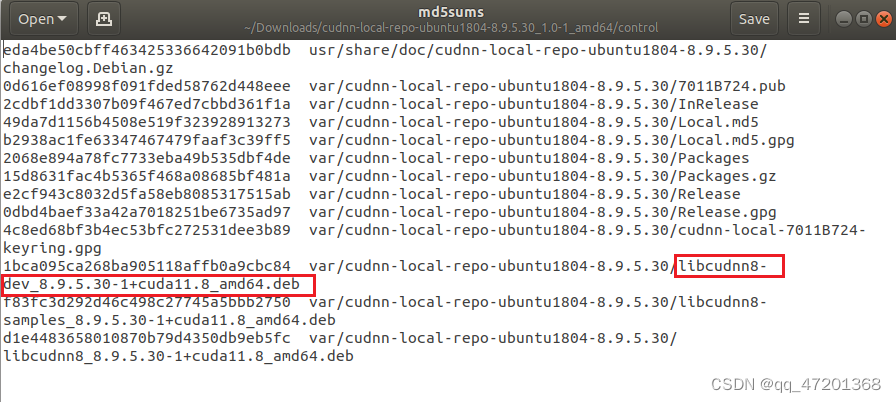
尝试使用第二块GPU
- 装了之后还是一样的错误,根本还是算力不匹配的问题,我重新装了pytorch1.8,在运行的时候出现下面报错,可以识别出来有两块gpu,之前没识别出来(我也不知道到底是不是和这个有关系,抓狂),然后在运行的时候指定gpu
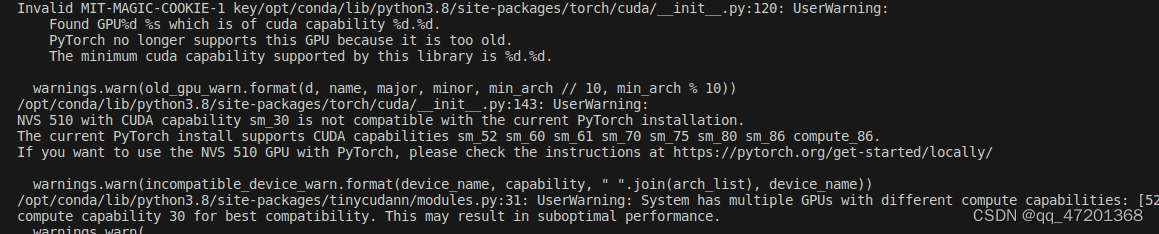
-
CUDA_VISIBLE_DEVICES=0 python3 run_loner.py ../cfg/fusion+portable/canteen.yaml
这里出现了另一个奇怪的问题,我是用nvidia-smi指示算力低的序号为0,算力高的那块GPU序号为1,结果我在运行python代码时,指定为0看到的才是那块高算力的gpu(why???)
- 又报错啦,不过错少了点,这次只有tinycudann不匹配的问题啦
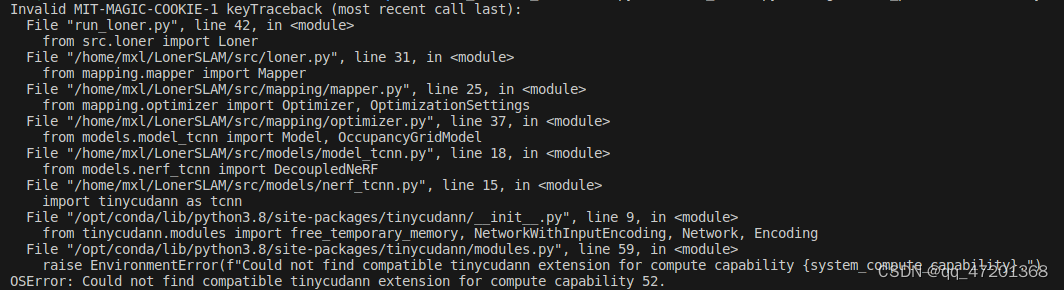
- 参考OSError: Could not find compatible tinycudann extension for compute capability 75 · Issue #330 · NVlabs/tiny-cuda-nn · GitHub
- 在终端运行下面代码,重新安装tinycudann,再次运行之后终于不报这个错啦!然后就出现了另外一个错误啦(啊啊啊啊啊,怎么不算进展呢
-
export TCNN_CUDA_ARCHITECTURES=52 pip install git+https://github.com/NVlabs/tiny-cuda-nn/#subdirectory=bindings/torch















 9116
9116











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









